基于贝叶斯网络的压缩语音信息隐藏检测
2018-08-27李松斌邓浩江
杨 洁,李松斌,邓浩江
(1.中国科学院 声学研究所,北京 100190; 2.中国科学院大学 电子电气与通信工程学院,北京 100049)(*通信作者电子邮箱lisb@dsp.ac.cn)
0 引言
信息隐藏,亦称为隐写术,是一种将秘密信息嵌入到载体中而使秘密信息难于被监管者察觉的技术,它通常把秘密信息隐藏在可公开的媒体信息中,如文本、图像、语音以及视频等多媒体对象。随着带宽的持续增长以及网络融合趋势的增强,基于网络数据通信的网络流媒体服务得到了空前的发展,网络压缩语音码流成为隐蔽通信常用载体之一。它给人们的生活和工作带来便利的同时,也给犯罪分子带来了可乘之机。对于敏感机构而言,需要对机构中的语音码流进行评估审查,确定是否存在隐蔽通信信道进行秘密信息的外泄。信息隐藏检测技术作为隐蔽通信的对抗技术,能够有效地监控网络压缩语音码流中的隐蔽通信,实现对敏感机构中的语音码流信息隐藏检测。
网络压缩语音编码信息隐藏根据嵌入时机的不同可分为两类。第一类是在编码结束后直接修改压缩语音码流[1-8],该类方法通常基于信噪比(Signal-to-Noise Ratio, SNR)和语音感受质量评估(Perceptual Evaluation of Speech Quality, PESQ)选出对语音质量影响小的语音码字中的比特作为秘密信息嵌入载体,并结合其他的编码方式或者技术,如覆盖码[1]、多进制编码[3]、矩阵编码和交织技术[6]来提高嵌入效率和隐蔽性。第二类是在编码过程中通过调制编码系数进行秘密信息嵌入,主要包括基于线性预测编码(Linear Predictive Coding, LPC)系数调制的信息隐藏方法[9-14]、基于固定码本系数调制的信息隐藏方法[15-19]和基于基音调制的信息隐藏方法[20-24],相对于第一类方法,该类方法由于是结合编码过程进行信息隐藏,对语音质量影响更小,隐蔽性更高。目前,绝大多数低速率语音编码器(如G.729和G.723.1)都基于LPC模型,因此,在LPC过程中进行水印信息嵌入具有较高的普适性。此外,基于合成—分析法的LPC模型已被广泛应用于各类低速率语音编码器,该模型能够自适应地减小LPC系数矢量量化过程中引入的失真。
量化索引调制(Quantization Index Modulation, QIM)隐写算法最早由麻省理工学院Chen等[25]提出,适用于包含矢量量化过程的图像、数字音频和视频编码。该方法对载体信号的失真、信息嵌入率和抗干扰性作了有效的平衡,非常适合在数字媒体的压缩编码过程中进行信息隐藏。互补邻居顶点QIM(Complementary Neighbor Vertex QIM, CNV-QIM)算法[9]是首个在LPC矢量量化过程中进行信息嵌入的算法,该算法基于图论将码书划分为两个部分,保证了每个码字和其最近邻码字被划分到不同的分组中,嵌入秘密信息比特0和1时分别从这两个码组进行LPC量化。文献[12]在CNV-QIM算法的基础上,提出了一种称为安全QIM(Secure QIM, Sec-QIM)的隐写方法,该方法引入了一种遵从柯克霍夫准则的基于密钥的码书划分策略以提升安全性,并结合矩阵编码提高嵌入效率来减少嵌入对语音质量的影响并提升算法抗隐写分析能力。最近,Liu等在文献[13]和文献[14]中分别提出了名为矩阵嵌入QIM(Matrix Embedding QIM, ME-QIM)和最近邻投影点QIM (Nearest-neighbor Projection Point QIM, NPP-QIM)两种线性预测语音编码信息隐藏方法。ME-QIM方法基于LPC矢量最小距离准则构建映射表进行嵌入,并结合嵌入位置选择和嵌入模板选择算法,进一步提升算法的隐蔽性。NPP-QIM方法将LPC量化索引集合视为三维LPC量化索引空间中的一个点,并基于最近投影点替换方法进行信息嵌入,NPP-QIM方法相较于Sec-QIM方法嵌入容量、嵌入效率和隐蔽性都有所提高。
为了检测QIM信息隐藏方法,Li等[26]发现QIM信息隐藏算法会导致LPC量化索引取值发生变化,提出了一种基于索引分布特征(Index Distribution Characteristics, IDC)的方法,该方法以矢量量化(Vector Quantization, VQ)码字VQ1、VQ2、VQ3直方图分布和相邻帧间转移概率作为特征向量,利用支持向量机(Support Vector Machine, SVM)训练分类器实现对QIM隐写算法的检测。IDC方法在检测CNV-QIM隐写算法时具有很高的检测准确率,但是在检测对量化索引分布影响更小的NPP-QIM隐写算法时检测准确率有所降低。其他盲检测算法如梅尔频率倒频系数(Derivative Mel-Frequency Cepstral Coefficients, DMFCC)[27]方法以时域衍生频谱和梅尔倒频系数作为特征,利用SVM训练分类器实现压缩语音信息隐藏检测,但是DMFCC方法对NPP-QIM隐写算法检测准确率也不高。为了提升对压缩语音NPP-QIM隐写算法的检测准确率,本文提出了基于码字贝叶斯网络(Codeword Bayesian Network, CBN)的信息隐藏检测方法,以VQ1、VQ2、VQ3时空转移关系构建CBN,并以Dirichlet分布作为先验分布学习网络参数,实现对NPP-QIM隐写算法的有效检测。不同于现有基于特征提取与SVM分类的信息隐藏检测方法,本文使用贝叶斯网络进行隐写分类,可以避免人工设计特征带来的特征维度大及难于表达复杂关联的缺陷,同时为信息隐藏检测的研究提供一种新的思路。
1 码字转移网络
LPC是网络压缩语音编码中最有效的语音信号分析方法之一,其利用线性预测模型实现对语音信号谱包络压缩表示,能够提供非常精确的语音参数预测。LPC合成滤波器为:
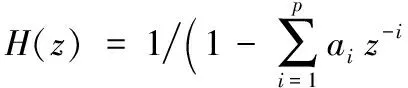
(1)
其中a1,a2,…,ap为语音信号的p阶LPC预测系数。由于LPC系数波动较大,某个LPC系数的误差对信号整个频域都会产生影响,因此LPC系数并不适合直接量化,需要进一步转换为线谱对(Line Spectrum Pair, LSP)系数。在G.723.1中,p=10,对每帧中最后一个子帧的LPC系数进行预测分裂矢量量化,令A(z)=1/H(z),则A(z)为:
(2)
令A(z)的和、差多项式分别为P(z)和Q(z),P(z)和Q(z)表示为:
(3)
则A(z)可进一步表示为:
A(z)=[P(z)+Q(z)]/2
(4)
当A(z)的零点在z平面单位圆内时,P(z)和Q(z)的零点都在单位圆上,并且沿着单位圆交替出现。记P(z)和Q(z)的零点分别为e±jωi和e±jθi,则P(z)和Q(z)可因式分解为:
(5)
系数ωi(i=1,2,…,5)和θi(i=1,2,…,5)称为LSP系数。得到当前帧LSP系数后,利用前一帧的LSP系数预测得到当前帧的LSP残差矢量,并将残差矢量按照维度分别为3、3、4分为3个子矢量进行量化,量化后的每个子矢量用8比特码字表示,记为VQ1、VQ2、VQ3。
1.1 码字时空转移网络构建
语音信号的基本组成单位为音素,根据音素可以将语音信号分为浊音和清音两种。浊音又称有声语音,携带着语音中大部分的能量,在时域上具有明显的周期性;清音类似于白噪声,没有明显的周期性。语音信号是一个非平稳信号,但在10 ms至30 ms内语音信号是平稳的,即短时平稳性,因此,语音压缩编码之后,语音帧内码字取值具有一定的相关性。此外,语音信号局部存在周期性,如果不同帧语音信号正好对应周期性重复的信号,那么这些相邻帧间码字取值也具有一定的相关性,因此由码字VQ1、VQ2、VQ3的帧内帧间取值关系可以构建一个码字时空转移网络(Codeword Spatiotemporal Transition Network, CSTN),如图1所示。
CSTN是由三个码字作为顶点,帧内帧间转移关系作为边的有向图,记为D=〈V,E〉,其中V,E具体表示为:
(6)
其中:V表示有向图D中顶点的集合,VQ1[m]、VQ2[m]、VQ3[m]分别表示第m帧的三个码字;E表示D中边的集合,由顶点v1指向顶点v2的有向边,包含3种帧内转移边和9种相邻帧间转移边。当表示帧内转移边时,q-p=0;当表示帧间转移边时,q-p=1。为了便于描述,将帧内3条边分别记为a、b、c,帧间9条边分别记为d、e、f、g、h、i、j、k、l,如图1所示。
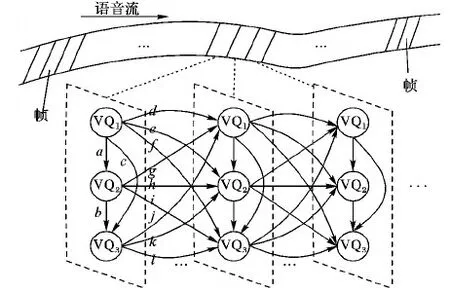
图1 码字时空转移网络
1.2 转移网络隐写敏感分析及化简
图1中的CSTN能够描述语音中码字转移关系,然而该网络的结构较为复杂,且每条边表示的转移关系强弱不一样,可以将转移关系较弱的边去掉。在CSTN中,每个顶点的取值范围为[0,255],则由每条边的两个顶点v1和v2取值可生成一个255×255的转移矩阵R,如式(7)所示:
(7)
其中,Pi, j(i,j=0,1,…,255)表示v1=i,v2=j的概率。在转移矩阵R中,共有65 536种取值,这些取值直观上并没有明显的特点。由语音信号具有一定周期性知,码字间取值也具有一定的周期性。本文统计了12条边对应两个顶点取值之差的概率,发现在差值为0时,同一码字帧间边的概率明显高于其他边;而差值为其他时,并没有明显的特点。因此,本文以两个顶点间取值相同的概率作为CSTN中边的转移指数,记为RE,用来衡量码字间的转移关系强弱程度,两个顶点间取值相同的概率即为R对角线之和,则RE可表示为:
(8)
压缩语音进行QIM信息隐藏后,VQ1、VQ2、VQ3取值会发生变化,相应的RE也会改变,将根据转移指数对网络进行化简,本文随机选择了3 000段语音样本计算12条边的转移指数,结果如图2所示。
在图2中,“Cover”和“Stego”分别表示未隐写和使用NPP-QIM隐写后的转移指数,隐写使边d、h、l的转移指数明显减弱,而其他边的转移指数变化不明显,因此在化简CSTN时只保留对隐写敏感的三条边d、h、l,化简后的隐写敏感码字时空转移网络(Steganography-Sensitive Codeword Spatiotemporal Transition Network, SS-CSTN)如图3所示。
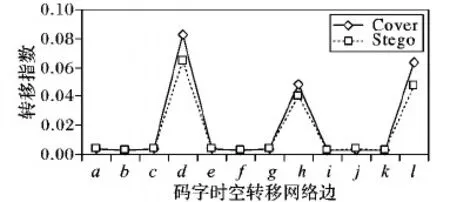
图2 码字转移指数
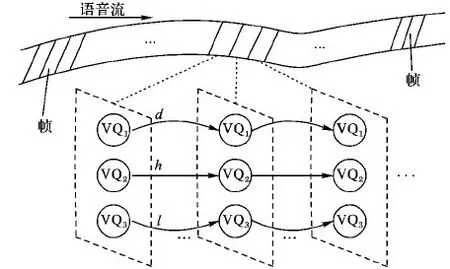
图3 隐写敏感码字时空转移网络
2 码字贝叶斯网络
贝叶斯网络是一种概率图模型,其网络拓扑结构是一个有向无环图,由网络节点、有向边和条件概率表(Condition Probability Table, CPT)组成。上述的SS-CSTN与贝叶斯网络非常相近,可以利用SS-CSTN进一步构建码字贝叶斯网络(CBN)分类器进行隐写分析。
2.1 码字贝叶斯网络的构建
QIM隐写算法以帧为单位进行秘密信息嵌入,鉴于此,本文以帧为单位构建贝叶斯网络。QIM隐写算法的直接影响是改变了VQ1、VQ2、VQ3的取值,由SS-CSTN知,不同码字间取值相互独立,同一码字相邻帧间取值不独立,CBN构建过程如下。
步骤1 以语音帧类别作为根节点C,有未隐写(记为0)和隐写(记为1)两种。
步骤2 分别以VQ1、VQ2、VQ3的取值作为节点C的子节点,构成由C到VQ1、C到VQ2、C到VQ3的三条有向边。
步骤3 分别以VQ1、VQ2、VQ3相邻帧间取值关系作为节点VQ1、VQ2、VQ3的子节点S1、S2、S3,构成由VQ1到S1、VQ2到S2、VQ3到S3的三条有向边,有取值不同(记为0)和取值相同(记为1)两种。由于S1、S2、S3的取值与语音帧类别有关系,因此将有向边C到S1、C到S2、C到S3添加到贝叶斯网络中。
最终所构建的CBN如图4所示,CBN为一个由7个节点组成的三层网络,其中第一层包含一个语音帧类别根节点,第二层包含三个码字节点VQ1、VQ2、VQ3且相互独立,第三层包含三个码字的帧间关系节点S1、S2、S3且相互独立。
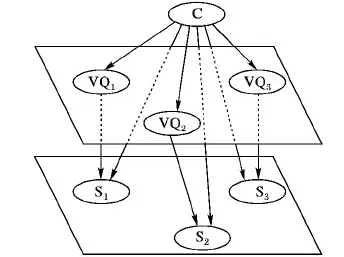
图4 CBN码字贝叶斯网络
2.2 码字贝叶斯网络参数学习
为了便于描述,图4中的贝叶斯网络节点C、VQ1、VQ2、VQ3、S1、S2、S3分别记为随机变量X1、X2、X3、X4、X5、X6、X7,随机变量的取值分别记为x1,x2,x3,x4,x5,x6,x7,其中x1,x5,x6,x7∈{0,1},x2,x3,x4∈{0,1,…,255},则网络的联合概率分布为:
(9)
其中:Pa(Xi)表示随机变量Xi的父节点;P(Xi|Pa(Xi))表示随机变量Xi的条件概率。P(Xi|Pa(Xi))具体如式(10)所示:
(10)
记随机变量Xi共有Ki个取值,θijk表示Xi取其第k个取值,Pa(Xi)取其第j个取值时的条件概率,则θijk可表示为:
θijk=P(Xi=xik|Pa(Xi)=Pa(Xi)j)
(11)
网络参数的学习实质上是学习各个θijk的取值,贝叶斯网络参数学习通常采用式(12)所示模式:
π(θ)+χ⟹π(θ|χ)
(12)
其中:π(θ)表示先验分布;χ表示样本信息;π(θ|χ)表示后验分布,参数学习综合了它的先验信息和样本信息。在贝叶斯网络参数学习中,先验分布一般选取共轭分布,即先验分布π(θ)和后验分布π(θ|χ)属于同一类型分布,本文选用常用的Dirichlet分布作为先验分布,则:
π(θij)=Dir(αij1,αij2,…,αijKi)=
(13)
其中Γ(·)为gamma函数。设在样本χ中满足Xi=xik且Pa(Xi)=Pa(Xi)j的个数为βijk,由于后验分布π(θ|χ)也服从Dirichlet分布,则π(θ|χ)可表示为:
π(θij|χ)=Dir(αij1+βij1,αij2+βij2,…,αijKi+βijKi)=
(14)
网络参数θ的最大后验估计为:
(15)
学习贝叶斯网络参数后即得到每个节点处的CPT,在CBN中,节点C的CPT大小为2,VQ1、VQ2、VQ3的CPT大小均为2×256=512,S1、S2、S3的CPT大小均为2×256×2=1 024。由于条件概率表较大不能直观显示,因此本文以图的形式展示部分节点在3 000个语音片段上的条件概率,VQ1、VQ2、VQ3在未隐写和隐写两种条件下的概率分别如图5(a)、5(b)、5(c)所示。
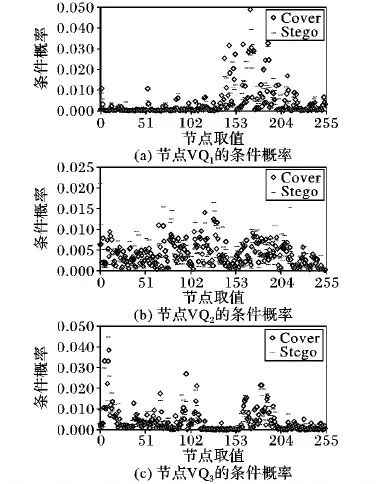
图5 部分节点条件概率示意图
图5中,“Cover”和“Stego”分别表示在未隐写条件下和隐写条件下的概率,可以看出节点VQ1、VQ2、VQ3在两种条件下的概率不同,且部分取值概率差异比较大,说明本文构建的CBN能够有效地反映隐写前后条件概率的变化情况。
3 隐写检测过程
贝叶斯网络构建和CPT学习之后,本文采用自下而上的诊断推理对样本进行分类,即已知子节点参数分布,来计算父节点的概率。CBN推理过程为利用随机变量X2、X3、X4、X5、X6、X7的取值及相应的条件概率来计算语音帧是未隐写和隐写的后验概率,其推理公式为:
P(X1=x1|X2,X3,X4,X5,X6,X7)=
(16)
x1=0和x1=1分别表示语音帧在随机变量Xi=xi(i=2,3,…,7)时为未隐写帧和隐写帧的后验概率。给定一段包含N帧的语音片段,由式(16)可以计算出每一帧为未隐写帧和隐写帧的概率,记第i帧为未隐写帧的概率为pui,为隐写帧的概率为psi,本文定义语音隐写指数J为:
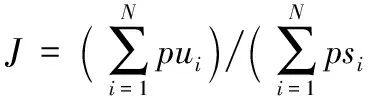
(17)
隐写指数J表示了一段语音中所有帧未隐写概率之和与隐写概率之和的比值。图6显示了50段语音在不同嵌入率下的J值。
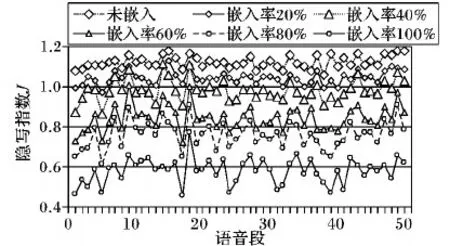
图6 不同嵌入率下的隐写指数
由图6可知,语音进行隐写后隐写指数J发生明显变化,且嵌入率越大J值越小。本文通过设置阈值Jthr来判断语音是否隐写:当J≥Jthr时,判定为未隐写语音;当J CNT(JS:Jsj (18) 其中:CNT(JU:Juj≥Jthr)和CNT(JS:Jsj 首先利用未隐写和隐写的语音训练网络参数,即学习CPT;然后利用CPT分别计算未隐写训练样本的隐写指数集合JU和隐写训练样本的隐写指数集合JS;接着从隐写指数集合JU和集合JS的并集中找出一个元素作为区分隐写样本和未隐写样本的隐写指数阈值Jthr,使得在训练样本中准确率最高;最后利用CPT和对未知类型的语音隐写样本进行分类,以判断其是否为隐写样本。 本文从互联网上随机搜索了10类语音片段组成语音样本库,包含了7类人类说话语音和3类乐器音,分别为中文男生、中文女生、英文男生、英文女生、法语、德语、日语、吉他乐、钢琴乐、交响乐,每类人类说话语音由多个人的语音组成,每类数据集包含了1 000段语音,每段语音时长为10 s,采用单通道、8 kHz、16 b量化编码为脉冲编码调制(Pulse Code Modulation, PCM)格式,编码方式采用G.723.1高速率6.3 kb/s,每类数据集按照3∶2的比例划分为训练集和测试集。本文除了选用嵌入效率最高的NPP-QIM方法外,还选用对语音质量影响最小的CNV-QIM方法作为隐写方法,选用针对QIM隐写方法进行检测的IDC方法和盲检测方法DMFCC方法作为对比。本文将从嵌入率、语音时长和网络参数复杂度三个方面对算法进行性能分析。 对语音样本进行秘密信息嵌入时,为了提升安全性能和降低对语音质量的影响,可以采用降低嵌入率的方式实现。本文针对5种嵌入率进行了实验,表1列出了3种隐写检测方法CBN、IDC和DMFCC在数据集中分别使用两种隐写方法CNV-QIM和NPP-QIM的检测准确率。 由表1知,随着嵌入率的降低,3种隐写检测方法准确率都会有所下降。当嵌入率大于60%时,CBN方法和IDC方法对CNV-QIM隐写方法都具有很高的检测准确率;当嵌入率降低到20%时,IDC方法和DMFCC对CNV-QIM隐写方法检测准确率均低于70%,而CBN方法仍有77.59%的检测准确率。在检测NPP-QIM隐写方法时,IDC方法和DMFCC方法在各种嵌入率下准确率均低于70%,而CBN方法只有在嵌入率为20%时准确率才低于70%,且其他嵌入率下检测准确率明显高于IDC方法和DMFCC方法;在嵌入率为100%时,QIBM方法准确率高达95.23%。 为了更全面地评估本文提出的隐写检测算法性能,本文还评估了语音片段的时间长度对隐写检测结果的影响。在5种时长下进行了实验,表2列出了3种隐写检测方法对两种隐写方法的检测准确率。 表2 不同时长下隐写分析准确率 % 由表2可知,CBN方法对CNV-QIM隐写方法和NPP-QIM隐写方法在不同时长下均具有很高的检测准确率,随着语音时长变短准确率略微下降。在检测CNV-QIM隐写方法时,CBN方法和IDC方法检测准确率都大于90%,DMFCC方法检测准确率低于70%;在检测NPP-QIM隐写方法时,CBN方法在各种时长下准确率均具有明显高于IDC方法和DMFCC方法,在语音时长为2 s时,CBN方法对NPP-QIM隐写方法仍具有85.21%的检测准确率,而IDC方法和DMFCC方法准确率均低于60%。 由前文分析知,CBN中随机变量X1的CPT大小为2,X2、X3、X4的CPT大小为512,X5、X6、X7的CPT大小为1 024,X2、X3、X4、X5、X6、X7的CPT大小直接由X2、X3、X4的取值个数决定。在CBN中,随机变量X2、X3、X4的取值分别对应VQ1、VQ2、VQ3的取值。为了减小CPT的存储空间,可以使随机变量X2、X3、X4的取值分别对应VQ1、VQ2、VQ3的多个取值,即将VQ1、VQ2、VQ3的取值划分为多个区间,每个区间对应X2、X3、X4的一个取值。本文定义网络参数复杂度为VQ1、VQ2、VQ3的区间划分个数,记为Rn,且每个区间取值个数相同,为256/Rn,则X2、X3、X4的CPT大小为2Rn,X5、X6、X7的CPT大小为4Rn。区间划分过程为:首先统计原始载体样本中VQ1、VQ2、VQ3取值直方图;然后将直方图中的取值按从大到小降序排列,最后将排序后的取值化为Rn个区间,在本实验中,Rn={4,8,16,32,64,128,256}。不同网络参数复杂度的隐写检测准确率如图8所示。 图8 不同网络参数复杂度下的检测准确率 为了比较本文检测方法在不同网络参数复杂度与现有的IDC方法和DMFCC方法的检测性能,图8中以IDC-CNV和IDC-NPP分别表示使用IDC方法对CNV-QIM隐写方法和NPP-QIM隐写方法的检测准确率,DMFCC-CNV和DMFCC-NPP分别表示使用DMFCC方法对CNV-QIM隐写方法和NPP-QIM隐写方法的检测准确率。由图8可知,CBN方法的隐写检测准确率随着网络参数复杂度增大而变高,这是因为网络参数越复杂,网络越能反映隐写前后条件概率的变化。当网络参数复杂度等于8时,检测CNV-QIM隐写方法准确率大于85%;当网络参数复杂度等于64时,检测NPP-QIM隐写方法准确率大于85%。在检测CNV-QIM隐写方法和NPP-QIM隐写方法时,IDC方法检测准确率和CBN方法分别在网络参数复杂度为64和16时相当,CBN方法在每种网络参数复杂度下均比DMFCC方法检测准确率高。 由于网络参数复杂度只对CPT有影响,检测时只需查询CPT,因此网络参数复杂度对检测时间基本没有影响。本文在Inter i7- 4700MQ@ 2.4 GHz、8 GB内存的Windows 7系统上使用Microsoft Visual Studio 2010进行了检测时间测试,本文提出的CBN方法检测一段10 s长的语音平均时间为21 ms,可以达到实时检测的效果。 以上的实验结果和分析表明本文提出的CBN方法对QIM隐写算法具有良好的检测性能,比IDC方法和DMFCC方法在不同嵌入率下和不同时长下都有更高的检测准确率。 针对现有隐写分析方法对NPP-QIM隐写方法检测准确率不高的问题,本文提出了一种基于贝叶斯网络的QIM信息隐藏检测方法,从时空两个角度分析了压缩语音码字转移关系,并基于隐写敏感码字时空转移网络构建了码字贝叶斯网络,结合大量样本学习网络参数和训练隐写指数阈值,实现隐写检测分类。在不同嵌入率、不同语音时长和不同网络参数复杂度条件下的多组实验结果表明,本文提出的CBN方法能够有效地检测QIM信息隐藏,特别是在检测NPP-QIM时准确率有了明显的提升,在网络参数复杂度较低时,仍然具有较高的检测准确率;同时CBN方法检测所用时间很少,实现了对QIM信息隐藏的实时检测。此外,本文方法的思想可用于检测其他语言编码器中的QIM信息隐藏方法,如SILK、iLBC和G.729等。在接下来的工作中,将进一步研究贝叶斯网络在其他类型的压缩语音信息隐藏检测方法中的应用。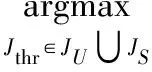
4 实验结果与分析
4.1 不同嵌入率下的检测性能分析
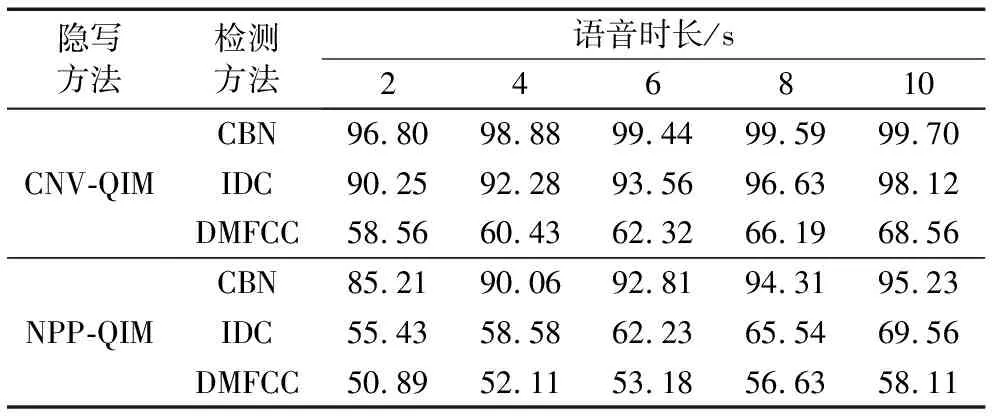
4.2 不同时长下的检测性能分析
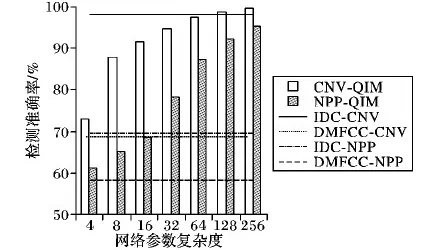
4.3 网络参数复杂度性能分析
5 结语
