基于轮式机器人平台的语音识别系统
2018-08-18任丽莉闫冬梅
任丽莉,丁 浩,康 冰,闫冬梅
(1.长春师范大学网络中心,吉林长春 130032;2.吉林大学通信工程学院,吉林长春 130022;3.吉林大学大数据和网络管理中心,吉林长春 130012)
语音识别技术改变了人与计算机的互动模式。人们只需动动口,就能打开或关闭程序,改变工作界面。这种使电脑人性化的结果是使人的双手得到解放,使每个人都能操作和应用计算机。这种变化不仅体现在计算机行业还体现在其它方面,比如电话手机、导航控制、检索文件、控制仪器等。语音识别技术涉及很多领域的知识,语音识别技术与其他学科的科学技术相结合,可以构建出更加复杂的系统。随着技术的发展,语音识别系统应用于机器人领域成为必然趋势[1-3]。语音识别系统具有很强的专业性,有很强大的市场潜力。无论是目前还是未来,研制出识别能力强、识别语种多的语音识别系统,并将其应用于机器人领域,对提高作业安全性、生产快捷性、操作简单性都有积极意义,在服务型机器人和家庭型机器人应用方面更是有不可替代的作用。用户可以通过语音识别交互系统直接控制机器人,省去了非语音识别机器人的复杂操作流程。像敬老院、医院等场所可以通过安装有语言识别系统的机器人完成老人、病人的无人化照顾,具有一定的现实意义。
1 语音识别原理
从根本上讲,语音识别系统是一种特别的模式识别系统,由三个基本结构单元组成,分别是参考模板库、特征提取和模式匹配,基本结构如图1所示。

用户通过语音输入装置输入语音,将输入语音转换为电信号,并添加到语音识别系统的输入端口。首先对信号进行预处理。由特定算法提取出能够有效地表现语音特征的特征参数,以区别不同的语音命令。然后将提取的特征参数与模板库中以同一方法在训练阶段保存的其它语音的特征参数进行匹配,利用搜索匹配法进行匹配比较之后将最佳结果作为识别结果,将识别结果输出或存储到其它操作中[4-5]。
2 系统整体设计
本系统设计更倾向于程序算法的设计,加之简单的组件添加。程序设计是在VC++6.0的MFC下进行编程实现的,在设计过程中,硬件方面要求有一个带有Windows操作系统的轮式机器人、一个装有VC++6.0的Windows PC、一个电源、一个麦克风装置等。在MFC平台中使用微软语音SDK 5.1开发语音识别的主要步骤如下:下载安装完程序后,首先配置VC环境,然后在编程前添加相应的头文件,再进行程序编写。其中,编程部分可分为文字转语音(语音输出)和语音识别两部分。
2.1 文字转语音
文字转语音步骤如下:
(1)导入所需的语音头文件。
(2)文字转语音函数的设置。在这里调用CBodyBasics∶∶MSSSpeak(LPCTSTR speakContent)函数即可将需要输出的文字转为语音,speakContent为LPCTSTR型的字符串。
(3)在进行输入输出设置之前要用ISpVoice*pVoice=NULL指令进行com初始化,并检测是否成功给予反馈。
(4)获取SpVoice接口,之后进行语音输出音量的设置,pVoice->SetVolume((USHORT)100)指令设置语音输出的音量,其有效范围是0至100,再用pVoice->SetRate(2)指令设置输出语音的速度,其有效范围是-10至10。
(5)利用pSpeech->Speak(L"……")指令输出所需语音,“……”为输出内容。语音输出功能整体代码设置完毕后释放com资源。至此文字转语音编程设置完毕。
2.2 语音转文字
语音转文字步骤如下:
(1)首先设置工程属性。在VC中打开属性选项,打开配置属性,点击C/C++预处理器,点击预处理器定义,勾选_WIN32_DCOM选项。若不如此设置编译将无法通过。
(2)导入所需头文件,语音头文件库、语音识别头文件、要用的CString头文件等。
(3)在程序的.h头文件中定义变量,添加入头文件后还需对头文件中的变量进行定义,否则在运行时会出现错误。需要定义的变量有:语音识别引擎(recognition)的接口、识别引擎上下文(context)的接口、识别文法(grammar)的接口、流()的接口、语音特征的(token)接口、音频(Audio)的接口(用来保存原来默认的输入流)。
(4)进行语音识别初始化函数创建。在创建之前与语音输出部分相同要进行com接口初始化,并检测是否成功加以反馈。微软语音识别开发包提供了两种模式:一种是共享模式(Share);另一种是独享模式(InProc)。一般情况下选用共享模式,大型的服务程序使用独立模式。本系统使用共享模式(Share)。具体的编程设置如下:利用hr=m_cpRecoEngine.CoCreateInstance(CLSID_SpSharedRecognizer)指令来创建共享模式,执行完创建指令后要进行检测,检查识别引擎是否创建成功。成功后进行以下操作:首先创建识别上下文接口,再设置识别消息,随后设置我们感兴趣的事件,即需要识别的事件。要进行语音识别需要在工程中添加需要的语音,也就需要创建语法规则C&C命令式,此时语法文件使用xml格式,具体在(6)中介绍。创建语法规则后要加载语法才能使用,在进行识别前,首先要激活语音识别函数,之后再进行识别,在主体程序设置完毕后释放com资源。至此语音识别部分编程设置完毕。
(5)定义消息处理函数。消息处理函数需要和上文所述的其他代码放在一起。根据本文上述部分进行编程,在其后添加修改消息反应模块即可实现所需功能。先参照前文进行语音识别部分的编程设置,当输入语音后系统进行识别,取出识别结果等待消息反应模块做出反应。在消息处理函数中利用识别结果进行进一步操作,如当机器人识别出语音“机器人”后给出“你好”的回应,在工程中通过Recstring=="机器人"指令保存识别出的语音,随后通过pSpeech->Speak(L"你好!");指令回应,实现语音识别、语音输出的交互。
(6)修改语法文件。对Strkeyword.xml文件进行修改,可以增添删减关键词,使某些特殊词汇的识别度提高,使其识别效果变得更好,像名字、专有名词等。
通过以上方法进行语音识别编程,整体编程实现方法如图2和图3所示。在硬件上只需在机器人上连接麦克风。

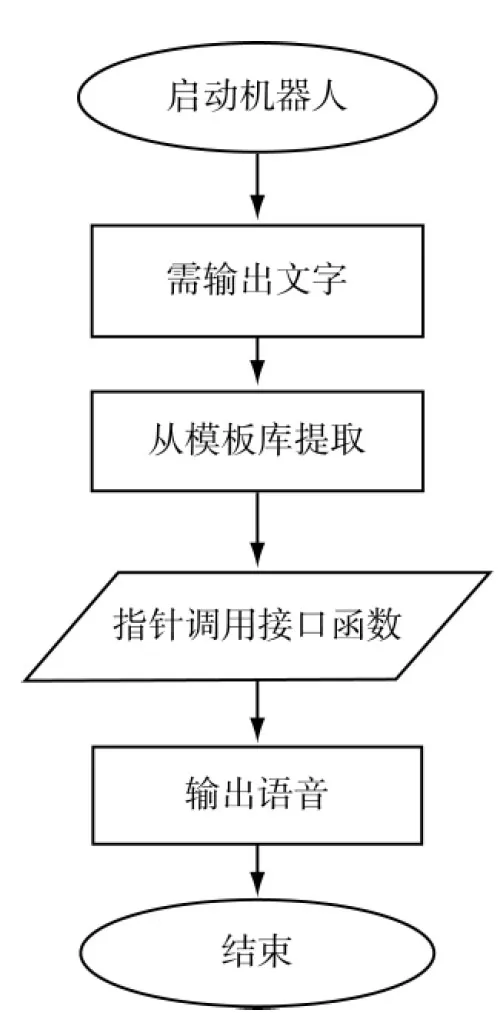
3 设计结果

在MFC平台运行完成程序加载后,形成相应的可执行文件即应用软件。启动应用软件后(启动后图标状态如图4所示),机器人会进入语音识别状态,用户通过麦克风输入语音指令,系统对接收到的语音信号进行识别并提取相应的特征参数,如果与程序中设定目标语音的特征参数一致,那么就可以将其作为最终的识别结果,语音识别结果会暂时被保存,在机器人执行周期执行函数时使用,作为条件对机器人行动进行控制。

经过设计可实现如下功能:点击启动图标,屏幕显示“开始聆听”即可进行语音识别。机器人发出“准备饮料获取演示”声音,输入“机器人”,回应“你好,请问需要饮料吗”,输入“是的”,回答“好的,我将为你取回饮料”,之后机器人开始行动。图5所示为轮式机器人。
如果要进行其他语音识别设置,可进行如下操作:
(1)语音识别。语音识别的关键词文件放置在工程的Grammar子目录下,根据需要对里面的关键词进行自由增减,在微软官方网站可以找到相关语法规则。语音识别到的关键词,最后会以字符串变量的形式被传递到CRobotEvent∶∶SR_KeyWord()回调函数中。
(2)语音输出。在类CRobotEvent中,可随时通过pSpeech指针调用CSpeech类的Speak()函数接口将文字转换成语音播放出来。
(3)接口函数进行语音输出,函数为pSpeech->Speak(CString inStr),其中参数inStr为字符串类型,指代内容为需要进行语音输出的语句。
