基于YOLO_v2模型的车辆实时检测
2018-08-17黄妙华
黎 洲 黄妙华
1.武汉理工大学现代汽车零部件技术湖北省重点实验室,武汉,430070
2.汽车零部件技术湖北省协同创新中心,武汉,430070
3.武汉理工大学汽车工程学院,武汉,430070
0 引言
面对居高不下的交通事故率,良好的辅助驾驶系统成为一种日益迫切的需要。如果汽车本身能够检测到周围环境中的车辆,通过合理的控制策略,就能提前提醒驾驶员注意危险车辆甚至自行采取紧急措施。行车记录仪的普遍使用,使得在汽车上实现基于机器视觉的车辆目标检测成为了可能。本文基于车载视频进行车辆目标的检测。
传统的车辆目标检测方法一般是分区域选择、候选区域特征提取、分类器分类三步完成。KACHACH等[1]通过提取滑动窗口内方向梯度直方图(histogram of gradient,HOG)特征,并用线性支持向量机(support vector machine,SVM)来进行车辆的检测。FELZENSZWALB等[2-3]提出了一种多尺度可变形部件模型(deformable parts model,DPM)来进行包括汽车在内的目标检测。传统的车辆检测方法虽能较为准确地检测出车辆,但区域选择时经常发生窗口冗余,整个过程复杂度高,提取出合理的特征难度较大。
文献[4]的发表,拉开了基于深度学习目标检测算法的序幕。R-CNN[5]算法是深度学习目标检测领域的新秀,该算法在生成候选区域过程中采用选择性搜索(selective search)[6]方法,为后来出现 的 SPP-net[7]、Fast R-CNN[8]、Faster RCNN[9]、R-FCN[10]开创了一种基于候选区域的深度学习目标检测的思路。
REDMON等[11]提出了基于回归思想的深度学习目标检测算法YOLO,极大地提高了目标检测速度。但初始版本的YOLO算法由于在网格划分以及预测边框数量的选取方面不太成熟,出现了定位不精准等问题。SSD[12]、YOLO_v2[13]等算法在YOLO算法的基础上进行改进,使得检测效果有了进一步提升。
许多学者针对YOLO_v2算法进行了研究。ZHANG等[14]运用YOLO_v2算法进行了中文交通标志的实时检测研究,JO等[15]运用YOLO_v2算法进行了多目标的实时跟踪研究,SEO[16]运用YOLO_v2算法和无人机对高速公路上的车辆进行了实时检测研究,魏湧明等[17]运用YOLO_v2算法对航拍图像进行了目标定位研究。
笔者在进行车辆检测时发现,传统的车辆检测算法仅能识别出车辆及该车辆在图片中的位置,这种单一的检测结果无法获取足够的有用信息,无法知道被检测车辆的运动趋势及距离,对周围车辆的预警效果差,难以对自身车辆进行合理的控制。为了解决上述问题,本文在YOLO_v2算法基础上改进网络结构模型,优化模型关键参数,使其能够对采集到的车载视频信息进行多维度的判断。
1 YOLO_v2车辆目标实时检测模型架构
本文设计的实时车辆检测模型架构见图1。定义满足车辆实时检测的网络结构,并在VOC2007数据集中筛选出包含汽车的数据集作为训练样本,再将获得的汽车数据集输入到网络模型中进行训练,最终对训练收敛的网络模型进行性能测试。
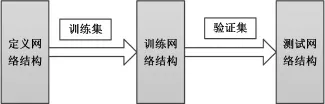
图1 YOLO_v2车辆实时检测模型架构Fig.1 YOLO_v2 vehicle real-time detection model architecture
1.1 YOLO_v2网络结构介绍
YOLO_v2是在YOLO_v1的基础上采用一系列优化方法得到的。YOLO_v1的网络结构由卷积层、池化层和全连接层组成[18],在YOLO_v2中,为获得更多空间信息,全连接层被移除并使用锚点框[9]来预测边框。
基于YOLO_v2的车辆实时检测网络结构见图2。首先将输入图片归一化为长宽均为416像素、3通道的标准输入图片,此时具有416×416×3个数值,经过13层卷积和4次池化将图片转换为26像素、26像素和512通道的特征图。随后从2个方向处理特征图:第1个方向是将26×26×512个数值按照一定规律重新组合成13像素、13像素和2 048通道的特征图,第2个方向是经过1层池化和7层卷积将特征图转换为13像素、13像素和1 024通道的特征图。再将2个方向处理的结果进行融合,得到13像素、13像素和3 072通道的特征图。最后经过2层卷积得到最终的特征图。
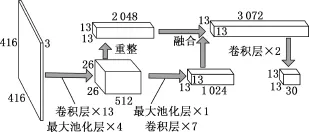
图2 基于YOLO_v2的车辆实时检测网络结构Fig.2 Real-time detection network structure of vehicle based on YOLO_v2
YOLO_v2车辆目标实时检测基本流程如下:
(1)将待测图像输入检测模型,得到13像素、13像素和30通道的特征图;
(2)13个像素与13个像素形成了169个网格,对于每个网格,都预测5个边框,每个边框中包括6维信息(包括4维坐标信息、1维边框置信度和1维是否为汽车的类别信息),总共形成1个30维的向量,即为最终得到的30个通道;
(3)将上一步预测出的13×13×5个目标边框,先根据阈值消除概率小的目标边框,再用非极大值抑制(non-maximum suppression,NMS)[19]去除冗余窗口。
其中,边框置信度代表了该边框中含有车辆类别的置信度和边框预测准确度两重信息,其计算表达式为

式中,Pr(Object)表示是否有汽车落入相应的单元格中,有汽车则取1,无汽车则取0;IOUtruthpred为预测框和标记框的交并除,表示重合度大小;Detection为系统预测出来的边框;GroundTruth为原图中标记的边框。
在整个检测流程中不难发现,YOLO_v2算法不再需要基于候选区域寻找目标,可直接采用回归的思想就完成了位置与类别的判断。正是由于YOLO_v2算法将汽车的检测转化为一个回归问题,才使得检测速度大大提升,从而使得该算法能够轻易满足实时性要求。
1.2 训练
在训练过程中,采用小批量随机梯度下降法,每36个样本更新一次权重参数。电脑内存为8G,为防止内存不够,多次实验后最终决定将36个样本分割成6个大小为6的子样本来进行训练,迭代次数为32 000。采用动量系数使训练过程加速收敛。为防止过拟合,设置权重衰减系数,并采用数据增广方法进行处理(包括随机裁剪、旋转,调整饱和度、色调、曝光度等)。通过该方法增大了训练集的样本容量,并提高了模型的泛化能力。学习率的选取采用多分布方法,具体训练参数见表1。

表1 训练参数Tab.1 Training parameters
为保证该模型对不同尺寸的图像具有良好的鲁棒性,采用了多尺度训练方法[13],在训练过程中,每隔几轮便随机选择一种新的输入图像尺寸来进行训练,该方法使得模型对不同分辨率下汽车的检测精确度均保持在较高水平。
2 实验及结果分析
2.1 实验平台
主要硬件配置为①处理器:Intel(R)Core(TM)i7-6800K CPU@3.40GHz;②GPU卡:NVIDA GeForce GTX 1060 3GB;③内存:8G。
YOLO_v2算法的程序设计语言为C++语言,整个开发环境为Windows7 X64+VS2013+CUDA 8.0+CUDNN 5.1。通过NVIDIA公司的基于并行编程模型和指令集架构的通用计算架构CUDA,配合应用基于深度神经网络的GPU加速库CUDNN,对数据进行快速训练及实时性验证。
2.2 评价方法
在本文中,目标检测只需要判断检测到的目标是否为汽车,是一个二分类问题,故本文最终目的是:能够检测到验证集中所有的汽车,且没有将其他目标检测成汽车。为了较为正确地评价本文模型的效果,在此先作True Car、True N-car、False Car、False N-car 4种定义。①True Car:目标为汽车,且被系统正确地检测成了汽车;②True N-car:目标不为汽车,且系统没有将其误检测为汽车;③False Car:目标不为汽车,但被系统错误地检测成了汽车(误检);④False N-car:目标为汽车,但系统没有将其检测为汽车(漏检)。
在评价过程中一般采用精确度和召回率来评价算法性能的优劣。精确度指的是被正确检测出的汽车占检测出的汽车的比例,其计算表达式为

召回率指的是被正确检测出的汽车占验证集中所有汽车的比例,其计算表达式为
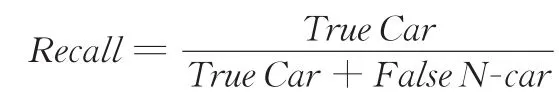
2.3 实验结果及分析
将训练集里面的1 000组信息导入模型,在GPU加速情况下经过约21 h的训练,获取了迭代32 000次之后的参数权重,得到了YOLO_v2车辆目标检测模型。用验证集中的284组信息进行验证,并与另外2种经典的目标检测算法进行对比,结果见表2。
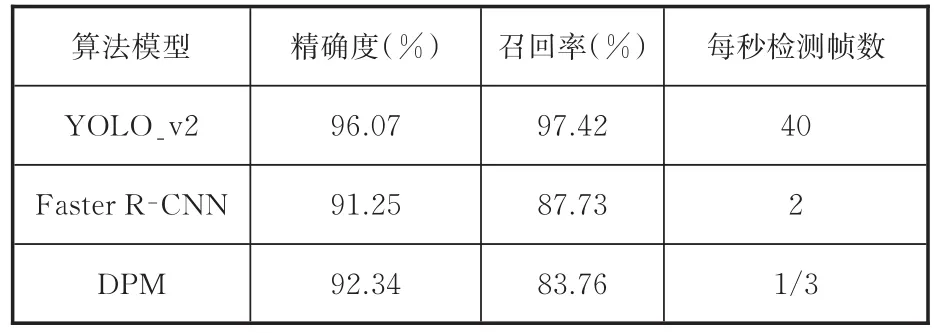
表2 实验结果Tab.2 The results of the experiment
Faster R-CNN是R-CNN系列算法不断优化的结果,目前是该系列算法中效果最好的算法,具有很强的代表性;DPM算法作为机器学习检测算法的顶峰,也具有很强的代表性。本文将YOLO_v2车辆目标检测算法与这2种算法进行对比,发现3种算法的精确度均较高,均有较好的检测效果;在召回率方面,YOLO_v2车辆目标检测算法的优势比较明显,达到了97.42%;在实时性方面,YOLO_v2车辆目标检测算法的每秒检测帧数远大于Faster R-CNN算法和DPM算法的每秒检测帧数。实验结果充分表明了YOLO_v2车辆目标检测模型在验证集上具有良好的检测效果,且每秒检测帧数为40,满足了实时性要求。YOLO_v2车辆目标检测模型的部分检测效果图见图3。

图3 YOLO_v2检测效果图Fig.3 Detection results of YOLO_v2
从图3中可以看出,虽然YOLO_v2检测效果好,但存在一些传统车辆检测算法共有的问题。由图3a~图3c可以看出,传统的YOLO_v2车辆检测算法仅能识别出车辆及该车辆在图片中的位置,这种单一的检测结果无法获取足够的有用信息,无法知道被检测车辆相对于摄像头的方位及被检测车辆的运动趋势;由图3d可以看出,当图片中有多辆汽车时,无法知道哪辆被检测车辆对自身车辆的行驶有潜在威胁,对周围车辆的预警效果差,难以对自身车辆进行合理的控制。
3 改进YOLO_v2算法的车辆实时检测
3.1 被检测车辆相对于摄像头的方位定义
本文根据被检测车辆相对于摄像头的空间位置及姿态,将检测到的车辆划分为车辆后部、车辆前部、车辆侧部。按照同车道车辆与异车道车辆2种情况进行具体的定义:
(1)同车道车辆方位分类定义。对于与自身车辆同向行驶的车辆(图4a),以正前方向左右30°范围为标准,定义为车辆后部;对于与自身车辆相向行驶的车辆(图4b),以正前方向左右30°范围为标准,定义为车辆前部;其他姿态的车辆定义为车辆侧部(图4c)。
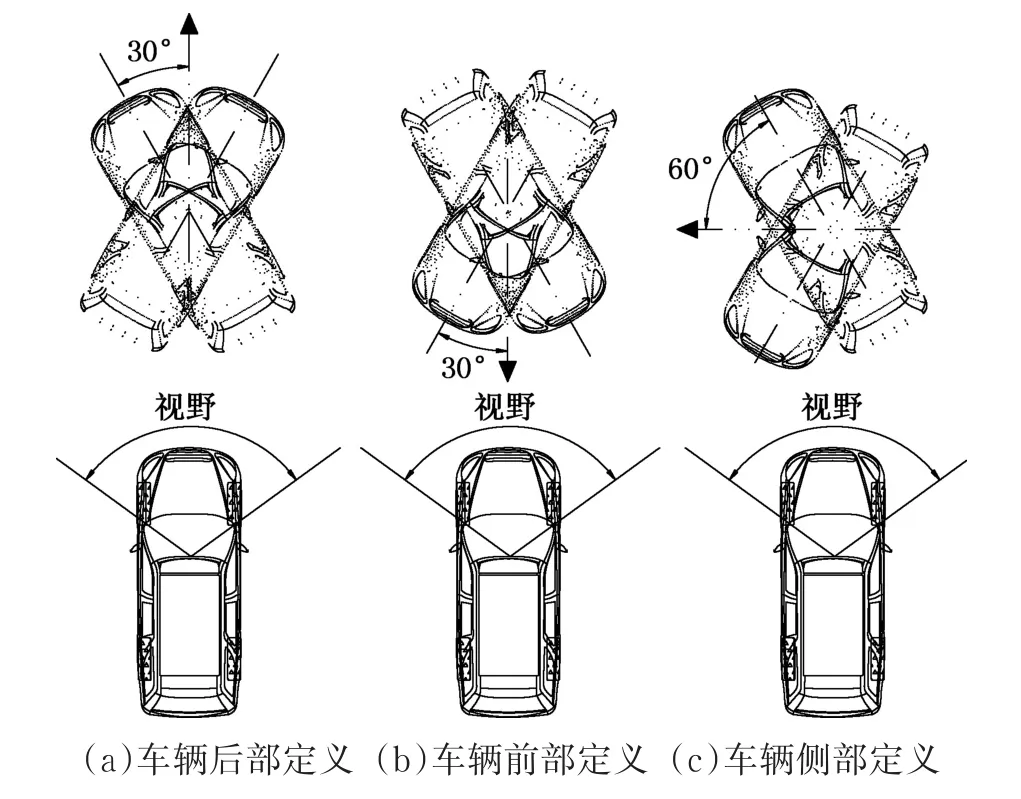
图4 同车道车辆方位定义图Fig.4 Same-lane vehicle orientation diagram
(2)异车道车辆方位分类定义。对于与自身车辆同向行驶的车辆(图5a),以摄像头采集到的图像中显示的被检测车辆是否有后轮为临界位置,若能观察到后轮,则定义为车辆后部,否则定义为车辆侧部;对于与自身车辆相向行驶的车辆(图5b),以摄像头采集到的图像中显示的被检测车辆是否有前轮为临界位置,若能观察到前轮,则定义为车辆前部,否则定义为车辆侧部。
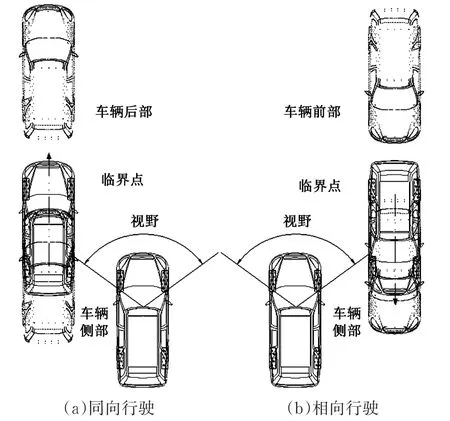
图5 异车道车辆方位定义图Fig.5 Side-lane vehicle orientation diagram
3.2 车距估计及预警
从图3d中可以发现,距离摄像头不同距离的被检测车辆在图片中的位置有差异。以被检测车辆边框的下边框为标准,可以发现被检测车辆越靠近摄像头,下边框在图片中的位置越接近下方。基于此特征,本文可以对被检测车辆的距离进行估计。
先在图片中确定自身车辆的运动趋势区域,并根据行驶到该区域所需时间的长短划分为3级预警:1级预警为浅度提醒,告知系统前方区域有车辆;2级预警为中度提醒,提醒车辆减速防碰撞;3级预警为深度提醒,执行减速停车行为,具体示意图见图6。然后判断被检测车辆的下边框是否在未来运动趋势区域内,若在,则进一步判断在哪一个安全等级的区域内,再根据被检测车辆相对于摄像头的方位,综合给出自身车辆的控制策略。
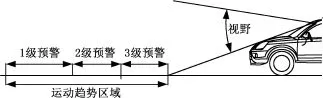
图6 车辆预警示意图Fig.6 Vehicle warning diagram
3.3 改进算法的实验结果及分析
完成改进的YOLO_v2车辆实时检测模型之后,将采集到的视频输入该模型进行检测,本文视频取自“上汽杯”汽车软件挑战赛复赛视频,将视频导入该模型后,部分检测效果图见图7。
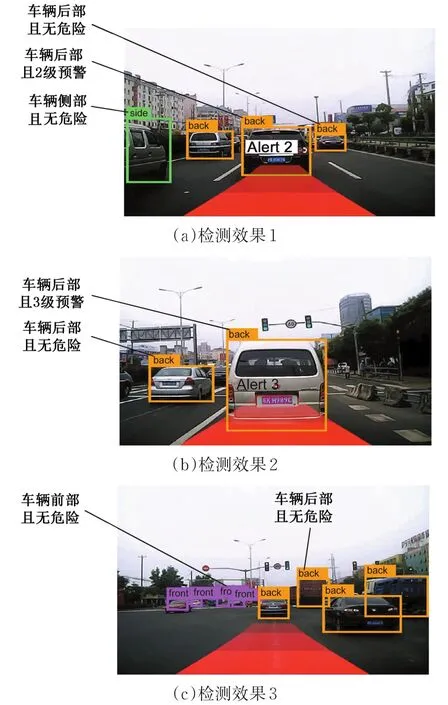
图7 车载视频检测效果图Fig.7 Detection results of vehicle video
从图7的测试结果中发现,该改进模型对道路上车辆的检测效果整体较好,在能准确检测到车辆的基础上,进一步判断了被检测车辆相对于自身车辆的位置及危险程度,达到了周围车辆实时检测及实时预警的目的。
结果表明,基于改进YOLO_v2算法的车辆实时检测模型在训练样本充足、迭代次数多的情况下,能够取得很好的效果,可以结合方位信息和预警信息来控制自身车辆运动,最终达到自动驾驶的目标,该改进模型可以很好地应用到车载摄像头领域进行周围车辆的检测及预警。
4 结语
本文应用YOLO_v2算法实现了车载视频中的车辆检测,解决了以往算法中目标检测实时性不足的问题。并针对传统车辆检测的局限性改进了YOLO_v2算法,将传统的单维度检测拓展为多维度检测,给基于机器视觉的车辆实时检测提供了研究方向。通过本文的研究,发现该改进模型可以很好地应用于车载摄像头领域中。笔者接下来将结合车载摄像头、毫米波雷达和激光雷达信息,对多传感器信息进行融合,并把基于视觉的方位信息和预警信息作为一种辅助距离估计方式,提高整车感知系统的稳定性。
