深度卷积神经网络的立体彩色图像质量评价*
2018-08-15李朝锋
陈 慧,李朝锋
江南大学 物联网工程学院,江苏 无锡 214122
1 引言
立体图像的附加维度(深度和视差)[1],使得在评价其质量时不能只简单地考虑左视图和右视图。人类的眼睛作为图像的最后接受者,主观评价被认为是最可靠的感知图像质量的评价方法[2]。主观评价是由观察者对立体图像的主观感受进行评价,准确性较高,但费时费力,且易受到观察者的情绪、疲劳度和测试环境等因素的影响,在实际应用中受到严重的限制,为此客观质量评价必不可少。
客观立体图像质量评价根据是否有原始图像作为参考,可以分为3类:全参考(full reference,FR)立体图像质量评价方法、半参考(reduced reference,RR)立体图像质量评价方法和无参考(no reference,NR)/盲(blind)立体图像质量评价方法。
全参考立体图像质量评价需要原始图像的全部信息。Benoit等人[3]提出了一种立体图像质量评价方法,采用一些2D的全参考质量评价算法计算左参考图像和左失真的图像、右参考图像和右失真图像以及参考图像和失真图像之间的视差图的图像质量得分。然后将这些得分组合得到立体图像的质量得分。You等人[4]将多种2D图像质量评价方法应用在评价立体图像的图像对和视差图中,并采用了多种方法计算视差图。证明了视差是立体视觉的重要因素。Geng等人[5]提出了一种基于独立成分分析和双目组合的全参考度量,计算参考图像和失真图像的图像特征相似度和局部亮度一致性。
半参考图像质量评价方法仅需要参考图像的部分信息。Hewage等人[6]通过利用深度图的边缘信息提出了半参考图像质量评价方法。Ma等人[7]通过评估重组离散余弦变换域中的失真,提出了用于立体图像的半参考图像质量评价方法。Wang等人[8]依赖于轮廓域中的自然图像统计来设计用立体图像的半参考评价方法。
在实际应用中,由于参考图像通常难以获得,无参考的图像质量评价方法显然更有价值。Chen等人[1]从立体图像的独眼图中提取2D自然场景统计特征,从视差图和不确定性图中提取3D的特征,将这些特征组合预测得分,取得了能和全参考图像质量评价相提并论的性能。Sazzad等人[9]使用立体图像对的局部特征的感知差异,开发了基于时空分割的无参考立体图像质量评价方法。Akhter等人[10]从立体图像对和视差图中提取特征,采用逻辑回归模型来预测质量得分。Ryu和Sohn[11]提出了一种基于双目质量感知的无参考立体图像质量评价算法。对在模糊性和块效应的情况下人类视觉系统的双目质量感知进行建模。Shao等人[12]构造了双目导引质量查询和视觉码本,通过简单的合并过程实现无参考图像质量评价。Lv等人[13]提出了一种基于双目自相关和双目合成的无参考立体图像质量评价算法。Tian等人[14]对立体图像的左右视图进行Gabor滤波提取单目特征,对独眼图提取双目特征,将这些特征放入深度信念网络预测立体图像的质量得分。Li等人[15]提出了一种基于双目特征联合的无参考立体图像质量评价算法,在对称失真和非对称失真库上都有较好的主观一致性。
这些无参考质量度量大多基于手工制造的特征来表示立体图像的特性,手工设计图像特征困难复杂,需要丰富的经验和知识。Kang等人[16]在讨论CNN(convolution neural network)用于评价2D图像质量的能力方面做了开创性的工作,将特征提取和学习过程结合在一起。Bosse等人[17]设计了一种深度的CNN,用于对2D图像进行质量评价,并且取得了很好的结果。Zhang等人[18]设计了一个CNN模型,将亮度对比度归一化后的左视图、右视图和视差图作为网络的输入,用于评价立体图像质量。不同于文献[18],采用切块后的彩色图像直接作为网络的输入,设计了12层的深度CNN模型,用于无参考的立体图像质量评价。
2 3D图像质量评价的深度CNN结构设计
立体图像与2D图像不同,除了要同时考虑左右视图的质量,还需要将立体的深度信息考虑进去。因此,本文的模型将切块后的立体图像的左视图、右视图和视差图作为网络的输入,以便网络能够更好地感知立体信息。本文提出的深度CNN模型结构如图1所示。三通道的CNN分别输入切块后彩色的左视图、右视图和视差图,每个通道后面接有12个卷积层来提取特征,在每两次卷积后进行一次池化层操作,以降低特征图的维数。然后将3个通道得到的特征向量进行线性拼接,得到的拼接向量与一个具有512个节点全连接层连接,最后在输出节点预测图像的质量得分。
2.1 网络输入
在立体图像质量评价算法中,视差图像比立体图像的左视图和右视图更重要,原因是视差图像不仅考虑了图像的内容,而且还考虑了立体图像的深度信息和视差信息[9]。在本文中,视差图采用左右视图直接相减获得:

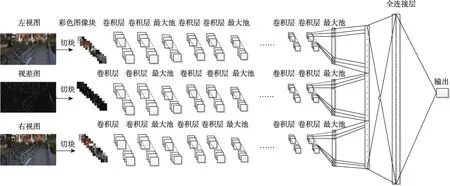
Fig.1 Framework of proposed deep CNN图1 本文提出的深度CNN模型结构图

Fig.2 Stereoscopic image sample图2 失真图像示例
其中,Il和Ir分别为左视图和右视图;Id为左右图像的视差图。图2为图像库中的一组左右视图以及对应的视差图。对得到的视差图和立体图像的左视图与右视图进行不重叠的切块处理,图像块的大小取32×32。立体图像的质量得分作为每个图像块的质量得分。然后将对应的图像块分别作为3个通道的输入同时输入到网络中进行计算。
不同于文献[18]中将切块后的图像进行局部亮度对比度归一化后再输入网络,本文采用切块后的彩色图像直接作为网络的输入,这样可以最大程度地保证图像的所有信息都输入到网络,使网络更全面地学习到相应的特征。
2.2 卷积层
卷积层是卷积神经网络的核心,通过图像与卷积核进行卷积计算和特征提取,具有局部连接和权值共享特征的属性。卷积核的大小就是对图像的感受视野大小,当卷积过小时,无法提取有效的特征,而当卷积核过大时,提取的特征的复杂度可能会超过后面网络的表示能力。因此设置适当的卷积核对于提高卷积神经网络的性能至关重要。本文采用的卷积核的大小为3×3。卷积的计算过程定义如下:

其中,ωk和bk为第k个滤波器的卷积核与偏置;xij是与滤波器进行卷积的局部图像块;hij是得到的第k个特征图。
2.3 最大池
池化层是卷积神经网络的重要组成部分,通过减少卷积层之间的连接,降低运算复杂度。在本文中,采用最大池对特征图进行子采样。最大池过程定义如下:

其中,Ω为最大池的局部窗口,模型中的池化窗口大小为2×2,这样每一个特征图经过池化运算后,数据量将减少一半;表示卷积后的第k个特征图;表示第k个特征图经过池化运算后的特征值。
2.4 全连接层
在经过多层的卷积池化操作后,3个通道分别可以得到3个一维的特征向量,将这3个特征向量进行如下线性拼接:

其中,η表示组合后的特征向量;α、β、λ分别表示左视图、右视图、视差图3个通道得到的特征向量。然后,将拼接后的向量与一个全连接层连接,用于计算图像的质量得分。
3 实现细节
3.1 网络参数
由于神经网络的输入通常是固定尺寸大小的,而图像库中的图像尺寸有时不一定相同,因此将原来的彩色图像切块为32×32大小的图像块作为输入。因为LIVE 3D图像质量评价数据库中的图片失真为均匀失真,所以每个输入块被赋予与其原图像相同的质量分数,最后预测的图像质量得分为一幅图像所有图像块质量得分的均值。
网络的参数配置如表1所示。在所有的卷积层中,采用的卷积核大小均为3×3,并且使用ReLUs(rectified linear units)作为激活函数。卷积过程的补零处理可以让卷积层的输入与输出保持相同的尺寸大小。所有最大池的窗口大小为2×2。在全连接层,对输出的值进行dropout处理,将输出的值按照50%的概率设置为0,通过对信号的随机屏蔽处理,可以防止网络训练出现过拟合现象。

Tabel 1 Parameters of CNN表1 网络参数配置
3.2 训练
对于一个质量得分为qt的图像,假设被切块后共有Np个图像块。预测的图像质量得分q为所有图像块经过CNN后输出值yi的均值,即:

本文模型中的目标函数定义为:
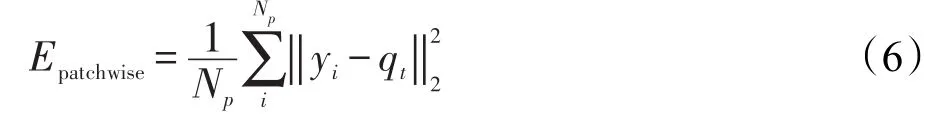
采用Adam算法优化网络参数,最小化目标函数,其中学习率设置为r=0.000 1。每次迭代随机从训练集中挑选32个图像块输入网络。动量momentum设置为0.9。
4 实验及分析
4.1 图像数据库及性能指标
本文采用LIVE实验室提供的立体图像测试库Ⅰ和Ⅱ作为实验数据。LIVE 3D PhaseⅠ数据库包括20种图像,5种失真类型,总共365组失真图像和参考图像。其中包括Gaussian blur(BLUR)失真45组,JPEG2000 compression(JP2K)、JPEG compression(JPEG)、white noise(WN)和fast fading(FF)失真各80组以及每组失真立体图像的DMOS(difference mean opinion score)值。LIVE 3D PhaseⅡ数据库包含8对原始立体图像和360幅对称失真和非对称失真立体图像对,失真类型为Gblur、WN、JPEG、JP2K和FF共5种失真,并给出每组失真立体图像的DMOS值。
为了评估模型的性能,选取两种评价指标:斯皮尔曼等级相关系数SROCC(Spearman rank order correlation coefficient)和皮尔逊线性相关系数PLCC(Pearson linear correlation coefficient)。SROCC主要用于测量两组顺序样本的次序相关系数,即质量得分单调性的指标;PLCC主要用于客观评价得分与主观得分之间的线性相关性。SROCC和PLCC的值区间都为[-1,1],其绝对值越接近于1表明主客观之间的相关性越好。
实验中随机选取数据库中80%的参考图像对应的所有失真图像用于训练,剩余20%的参考图像对应失真图像用来进行测试,这样保证学习训练图像与测试图像在内容上是完全独立的。
4.2 结果分析
表2和表3列出了不同方法在LIVE 3D PhaseⅠ数据库上得到的SROCC值和LCC值。为了使实验所得到的结果便于观察和对比,将实验结果中的最高值进行加粗显示。表中的全参考度量方法用斜体标出。
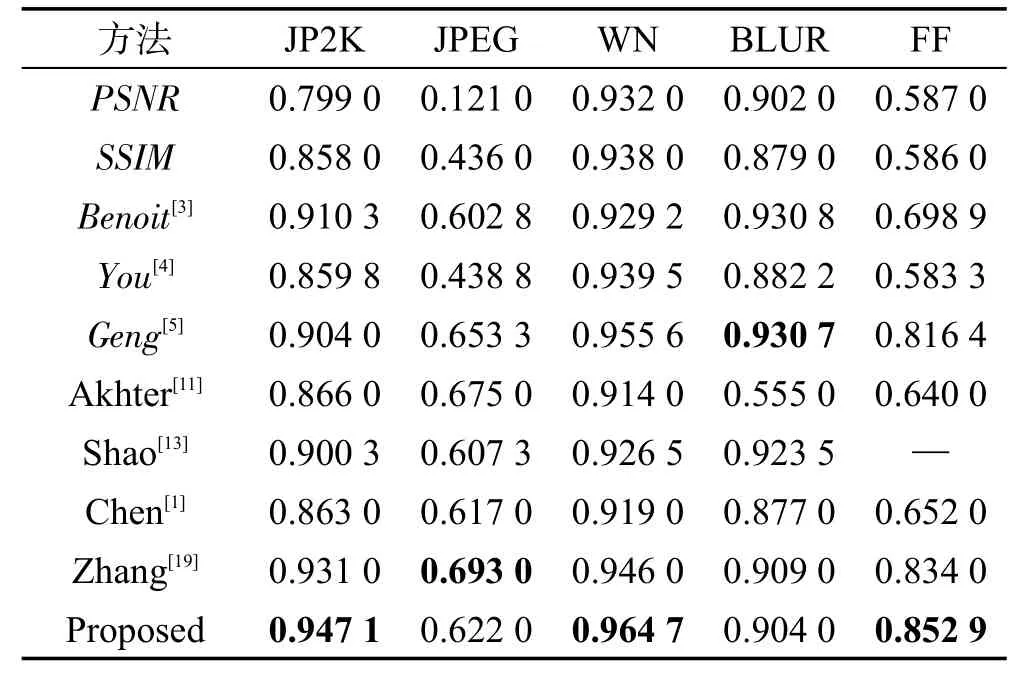
Table 2 SROCC on LIVE 3D PhaseⅠ表2 在LIVE 3D PhaseⅠ数据库上的SROCC
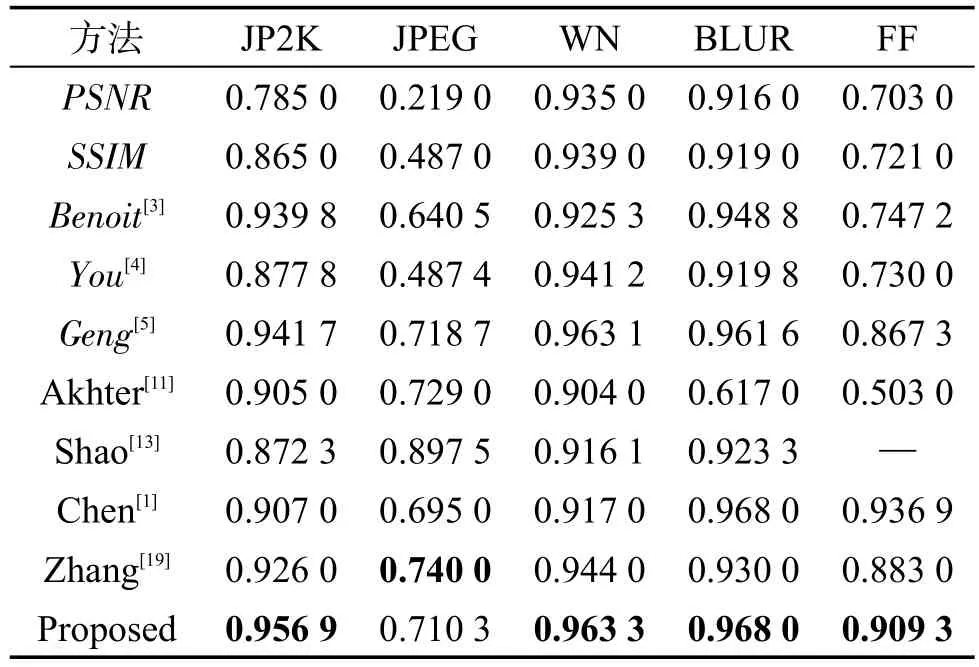
Table 3 LCC on LIVE 3D PhaseⅠ表3 在LIVE 3D PhaseⅠ数据库上的LCC
由表2和表3分析可以看出,本文模型在单一JP2K、WN、FF失真类型的结果最好,在JPEG失真类型表现较差。其他模型对于JPEG失真的预测结果也不是很理想,这是因为在LIVE 3D PhaseⅠ数据库中,对于JPEG失真,其DMOS的范围是-10到20,相比于其他失真类型范围更窄,这就意味着更少的感知失真和较小的感知差异[9]。如何提高模型对JPEG失真图像质量预测的准确性是将来需要研究的问题。
表4和表5列出了不同方法在LIVE 3D PhaseⅡ数据库上得到的SROCC值和LCC值。由表4和表5可以看出,模型在LIVE 3D PhaseⅡ库的JP2K和JPEG失真类型上的结果略低于其他算法,但在WN、BLUR和FF失真上效果比其他算法都好。图3和图4为本文算法在LIVE 3D PhaseⅠ和PhaseⅡ质量评价预测值与DMOS的散点分布图。由散点图的分布可以看出,本文提出的算法具有较好的主观一致性。
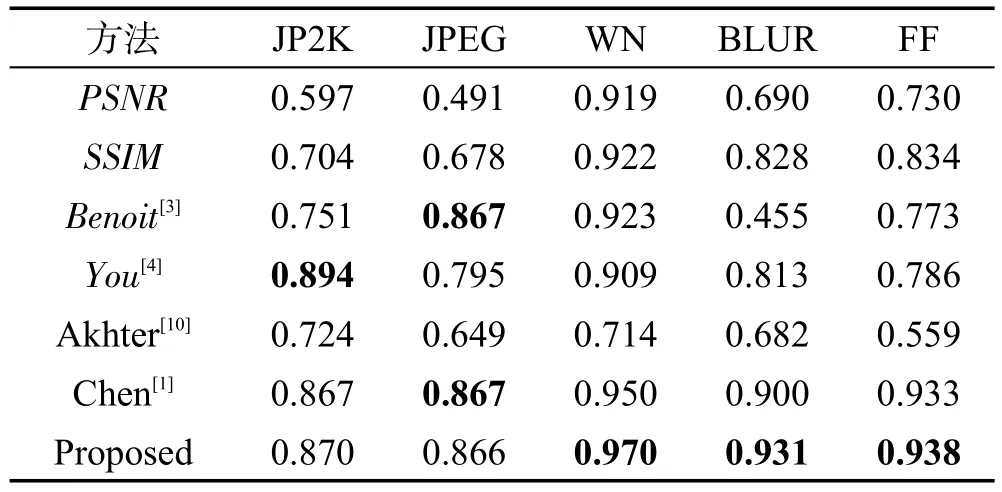
Table 4 SROCC on LIVE 3D PhaseⅡ表4 在LIVE 3D PhaseⅡ数据库上的SROCC
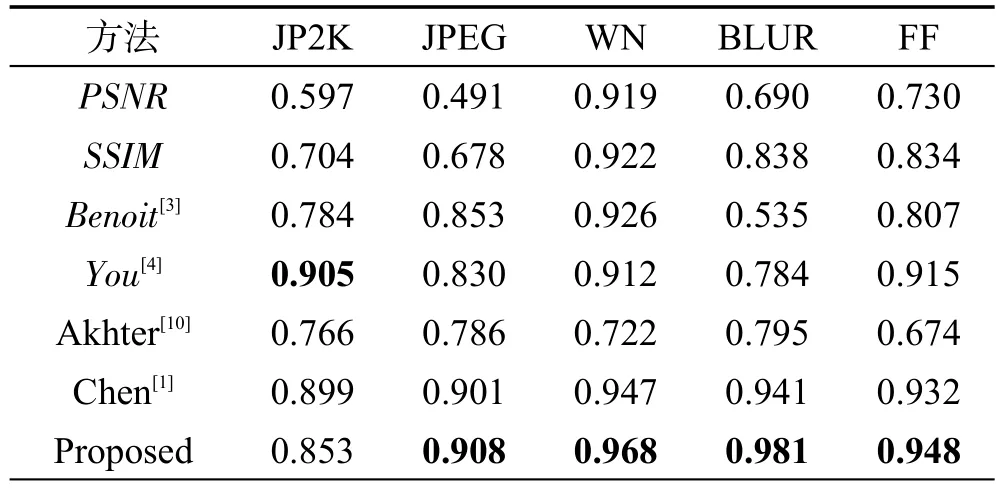
Table 5 LCC on LIVE 3D PhaseⅡ表5 在LIVE 3D PhaseⅡ数据库上的LCC
为了说明视差图的有效性,将本文方法与只有两通道的深度CNN进行实验对比。两通道的深度CNN模型结构输入只有左视图和右视图,没有视差图,其余结构和三通道的CNN相同。表6和表7为两通道模型在LIVE 3D PhaseⅠ数据库上得到的SROCC值和LCC值。由表6和表7可以看出,有视差图输入的模型比没有视差图输入的模型具有更好的主观一致性,证明在立体图像质量评价算法中视差图的重要性。
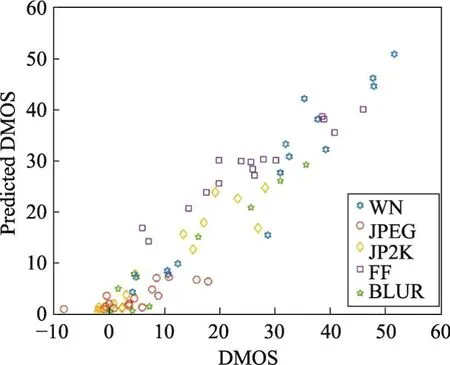
Fig.3 Result on LIVE 3D PhaseⅠ图3 在LIVE 3D PhaseⅠ库的预测散点图
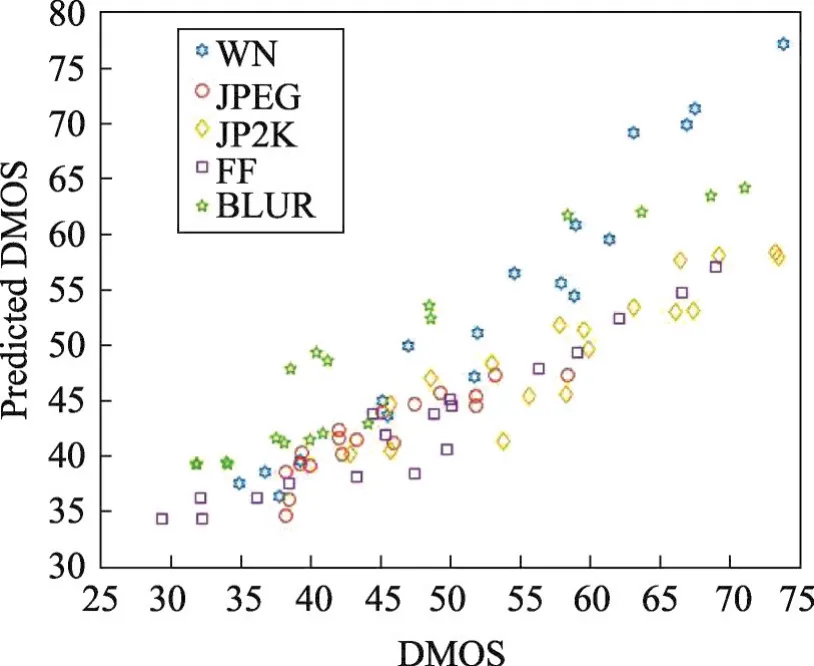
Fig.4 Result on LIVE 3D PhaseⅡ图4 在LIVE 3D PhaseⅡ库的预测散点图

Table 6 SROCC comparison between 2-channel and 3-channel表6 两通道和三通道CNN的SROCC对比

Table 7 LCC comparison between2-channel and 3-channel表7 两通道和三通道CNN的LCC对比
对于卷积神经网络模型来说,其训练时间与网络的深度以及机器设备的型号密切相关。更深的网络层数意味着更多的权重参数,也就需要更多的时间进行计算。本文提出的模型由3个通道构成,每次每个通道输入32张切块后的图片,即每次迭代输入96张图像块。训练采用caffe框架,实验采用的GPU型号为GTX660,每进行1 000次迭代需要耗时120 s。相比于其他算法耗时略长,但随着计算机显卡的计算能力的提升,其训练时间可以大大缩短从而提升算法的效率。
5 结论
本文提出了一种基于深度卷积神经网络的立体图像质量评价模型。将立体图像的左视图、右视图和视差图的彩色图像直接输入网络,每个通道由12层的深度网络结构组成,通过卷积层与最大池的多层堆叠,直接学习到立体图像的感知特征,避免了传统方法对于左右视图和视差图的复杂处理,能有效度量立体图像质量。在LIVE 3D PhaseⅠ库和LIVE 3D PhaseⅡ库上的实验结果表明,该模型能够较好地预测人眼对立体图像的主观感知。
