间隔执行的异步副本放置策略*
2018-08-15谢纪东武继刚
谢纪东,武继刚
广东工业大学 计算机学院,广州 510006
1 引言
数据网格已经广泛应用在科学研究中,其目的是将许多分布遥远的存储资源连接起来,以方便网格用户分享数据[1],这种数据一般需要消耗大量存储以至于无法集中存储在一个节点中[2]。
一般而言,计算密集型的应用需要用到大量数据,尤其在科学计算型应用[3-4],比如高能物理[5]、天气模拟以及卫星图像处理等[6-7]。而且随着最近一段时间数据挖掘和机器学习的发展,越来越多的数据需要进行复杂的实验和分析。
然而,由于硬件成本的限制,在本地存储和维护大量数据的代价有时是难以接受的,而如果将数据全部放置在远程服务器中,比如云端[8-9],由于网络带宽的限制,取回数据的时间代价又太大,因此副本放置技术应运而生,副本技术利用用户对文件请求的历史数据,利用有限的本地存储资源只存储用户最需要文件的副本,而所有文件的原本存储在云端,这样不仅能有效利用本地存储资源,也能充分利用云端的资源,同时方便共享数据资源。
本文通过改进文献[10]中对文件热度的定义,利用间隔执行机制以及异步策略来设计算法,算法由两部分组成,一部分是全局算法,负责收集各个集群的用户文件请求计算候选副本,另一部分为局部(本地)算法,由集群中心控制,局部算法负责放置副本到合适位置以适应集群网络环境。本文主要有3点贡献:
(1)通过边际分析方法改进了文献[10]中对文件流行度的定义从而能选择更合适的候选副本。
(2)通过异步机制,分而治之的思想重构文献[10]中的算法。
(3)通过高斯分布、幂律分布来模拟用户行为进行模拟实验,实验结果表明本文提出的策略有效改善了网络传输环境。
2 相关工作
副本技术的两个主要挑战:副本的选择和副本放置。副本选择主要负责选择用户最需要的副本,而一般用流行度表示用户需要的迫切程度。副本放置主要负责将副本放置到网络中最合适的节点以使用户在请求文件时能拥有较小的网络延迟和带宽消耗[11]。
文件流行度的概念主要用来描述文件被需要的程度,大部分方法[1,10,12-19]都利用文件的请求频率来定义文件流行度。
文献[12]提出了最近请求文件最大权重算法(latest access largest weight,LALW)。该算法对不同的文件请求计算不同的权重,时间越近的请求拥有越大的权重,这样能使用户最近的偏好得以凸显。文献[15]提出了基于主动删除技术的最近请求最大权算法(closest access greatest weight with proactive deletion,CAGWPD),该算法基于历史请求记录以及主动删除技术,通过设置阈值来控制副本数量,选择文件流行度大于平均流行度的文件作为副本。这种方式能更加有效地利用资源节点的存储容量。文献[18]提出了公平分享算法(fair-share replication,FSR),该方法通过平衡资源节点的工作量和存储容量来更有效地放置副本到合适的节点。这几种方法都没有考虑到用户的行为变化对系统的影响,在定义文件热度时,其偏向于将小文件作为副本进行放置,而忽略了大文件的传输能显著影响网络传输条件的事实。
流行文件优先复制算法(popular file replicate first,PFRF)由文献[1]提出,该算法基于星型拓扑网络,在节点存储资源有限的情况下通过历史文件请求判断文件热度并进行副本放置,其采用间隔执行的算法运行机制充分考虑了用户行为变化,并进行了复杂的实验来评测PFRF算法。但是其文件热度定义和之前的工作一样,偏向于选择小文件,同样忽略了大文件请求对网络造成的影响。
改进的流行文件优先复制算法(improved popular file replicate first,IPFRF)由文献[10]提出,该算法同样基于间隔执行的运行机制,所谓间隔执行,即将时间划分为等间隔时间段,算法会在一个时间段结束时运行。这种机制有利于动态调整副本选择和放置。IPFRF改进了PFRF中没有考虑节点地理位置而进行副本放置的缺点。IPFRF通过调节文件请求权重,对集群进行个性化推荐,增加副本删除机制更加有效利用了本地存储资源,提高了副本命中率,有效减少了网络平均延迟和消耗带宽。但是由于IPFRF的算法需要等待收集所有集群的信息才能进行计算,一旦有集群离线,系统会发生不可预知错误,缺乏健壮性,同样由于和PFRF采用了相似的文件热度定义,对大文件的请求不敏感。
基于以上缺点,本文提出了一种改进流行度的基于间隔执行机制的异步文件副本放置策略。本文从三方面对IPFRF进行了改进。第一,通过对文件请求产生的边际延迟分析,大文件在一定条件下需要进行优先放置,而不是一味地用文件请求密度来进行定义造成在选择副本时偏好小文件的问题。第二,通过异步机制打破同步算法所带来的低容错缺点。第三,本文引入高斯分布来模拟用户对文件请求的行为变化。
3 系统模型
3.1 拓扑结构
本文模型和文献[10]保持一致,如图1,整个模型由m个集群和一个主站(master site)组成,主节点通过GRC(global replica controller)和各个集群交流,主站包含所有文件,即其容量足够大总是能存储所有文件。主站一般是专业的存储服务提供者,比如存储云等。每个集群都有本地副本控制服务器LRC(local replica controller),通过集群内部路由和集群内各个资源节点相连,资源节点容量有限,只能存储一部分文件。
集群内资源节点地理分布较为接近,而集群之间地理分布较为遥远。此模型由树形拓扑简化而来,文献[1]已证明其合理性。每个集群内部的LRC负责管理存储在集群中资源节点中的副本,并提供策略在适当的时间和位置存储副本,由于服务器容量有限,同时也要在适当的时机删除一部分不太重要的副本,为后续更重要的副本腾出空间。
用户通过向存储服务器发出副本请求来获取副本,如果本地服务器中没有对应副本,则需要从远程服务器中请求对应文件。当副本放置策略无法有效满足用户需求时,远程服务器需要满足大量用户需求,而受限于网络带宽,用户获取文件的延迟有可能会变得非常大,因此,可以通过在此模型上模拟多种用户偏好变化来检测副本放置策略的有效性。
3.2 评价指标
评价指标包括三部分:平均请求延迟、平均消耗带宽、副本发现比率。
平均请求延迟。请求延迟反映了用户下载文件的时长,延迟越大,用户需要等待越久。平均请求延迟越小,证明越多的文件请求在本地得到满足,副本放置算法越有效。
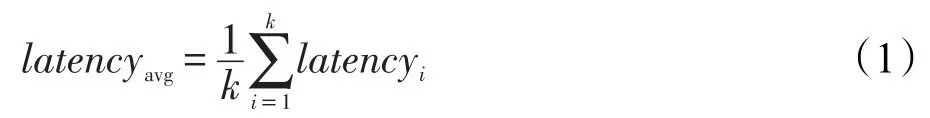
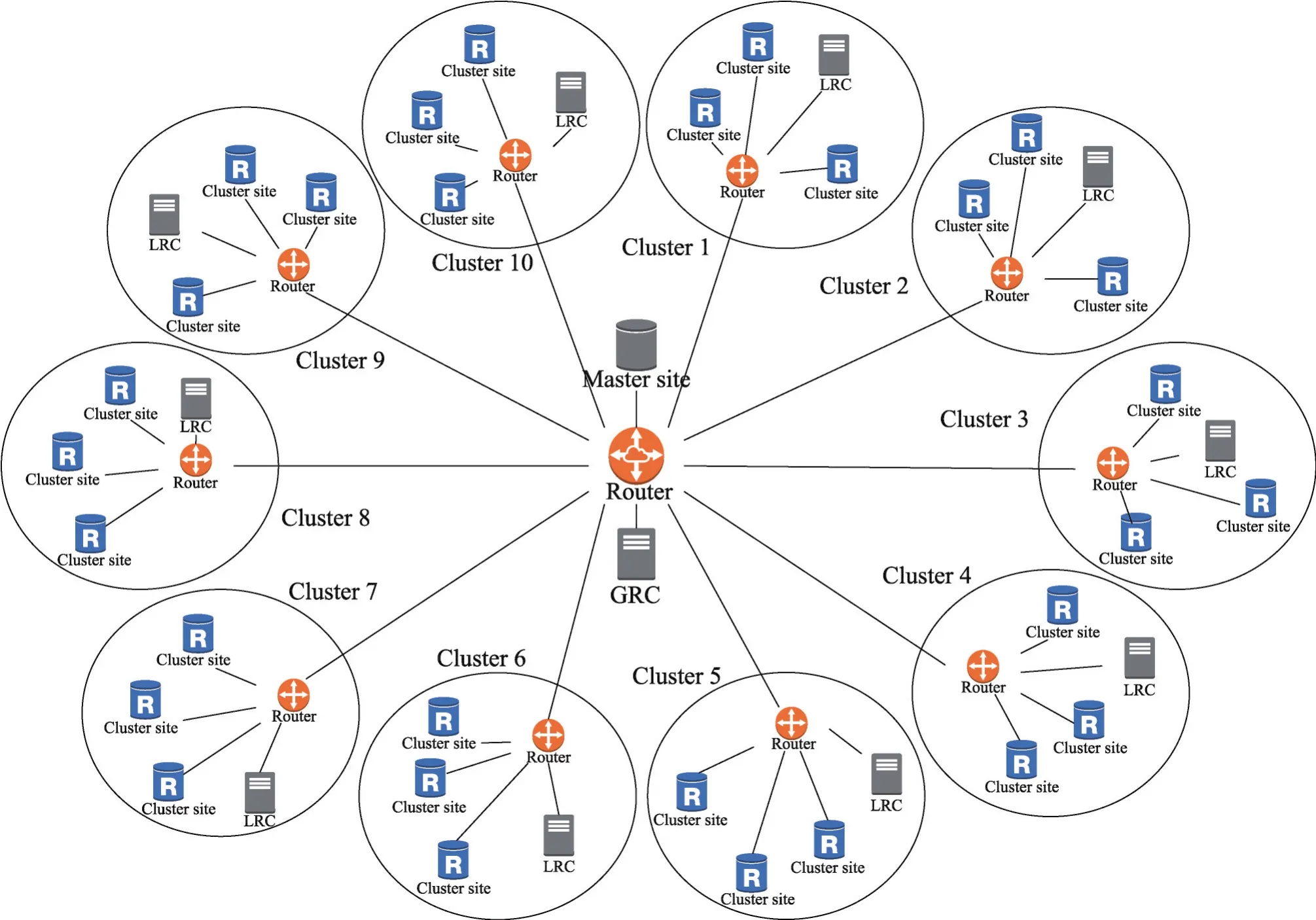
Fig.1 Simulation topology图1 模拟系统拓扑结构
平均消耗带宽。文件消耗带宽根据文件大小和传输时经过的中间节点数量计算,文件传输带宽消耗越大,表示文件越大或者需要经过越多的中间节点。平均文件消耗带宽越小,副本放置算法越有效。
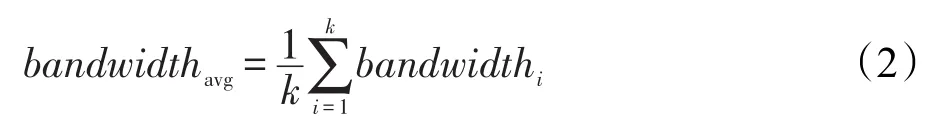
副本发现比率。验证副本放置算法是否有效的直接指标,就是计算副本命中率。命中率越高,表示集群内部的副本能满足更多的请求。但是副本发现率在文献[10]提出的算法下对小文件有明显的偏心。虽然副本发现率能在一定程度上反映算法的有效性,但是不一定能反映网络传输环境的改善情况。比如,当副本服务器的容量一定时,文献[10]的算法更偏向于选择体积较小的文件作为副本,因此,副本服务器能放置更多的副本,自然能拥有更大的副本命中率。但是,网络的拥塞,体积较大的文件的传输产生的影响不可忽视。同时,由于大文件的边际延迟更大,如果只是偏向于对小文件放置副本,网络中每增加一次对大文件的请求,网络传输环境恶化得更严重,边际延迟将在第4章详述。
4 流行度定义和算法
IPFRF是一个基于间隔执行机制(round-based)的副本放置策略,它将时间分成固定长度的时间片段,在每个时间片段结束时,它会采取4个步骤来进行副本放置。第一步,IPFRF从所有集群收集文件请求信息。第二步,IPFRF计算每个文件在对应集群中的流行度,然后再取平均作为文件的全局流行度。第三步,将每个集群中请求的文件按照流行度降序排序,并且选择排名靠前的一定数量的文件作为候选副本。第四步,IPFRF根据集群中资源节点的地理位置分布、容量和已有副本,将候选副本放置到最合适的资源节点中。本文从两方面对IPFRF进行了优化:文件流行度定义和算法结构。
4.1 文件流行度
文件流行度是一个评价文件是否应该被复制到集群中资源节点的重要因素,IPFRF对文件流行度(FPi,c,n)的定义:
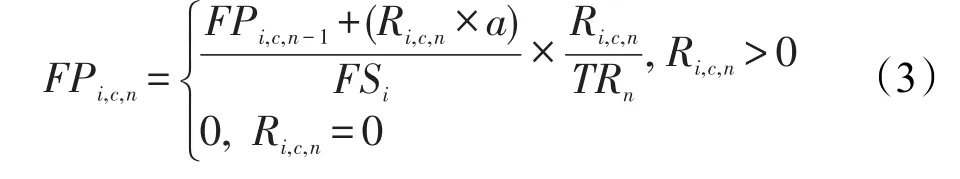
其中,Ri,c,n为集群c在第n个时间间隔对文件i收集的请求次数;TRn为第n个时间间隔内对所有集群收集的文件请求总数;FSi为文件i的大小;a是一个常量,在文献[10]中并没有显式给出,本文根据文献[1]进行取值。IPFRF中平均流行度(APi,n)的定义如下:

其中,noc表示集群数量。IPFRF的文件热度定义考虑了文件数量、文件大小,其权重也根据不同集群不同时期的总需求量动态变化。但是仍然有不足之处。本文通过边际分析方法,重新对文件热度进行了定义。定义边际延迟(marginal delay,MD)如下:
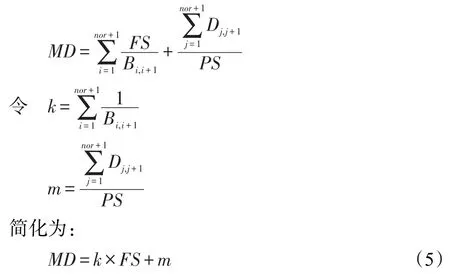
其中,nor表示文件传输过程中经过的路由数量;Bi,i+1表示从发送节点i到接收节点i+1的网络带宽;Di,i+1表示从发送节点i到接收节点i+1的距离;在真实环境下,k和m的取值是一定的。
所谓边际延迟,即网络中每增加一个文件请求所增加的传输和发送延迟。显而易见的是,一个请求对两个大小不一的文件所造成的延迟是不一样的,文件越大,所造成的延迟越多,因此,网络中每增加一个对于大文件的请求所造成的延迟,远大于网络中每增加一个对小文件请求所造成的延迟。即大文件的边际延迟大于小文件的边际延迟,虽然网络中对于大文件的请求不一定比小文件多,但是其重复传输所产生的延迟依然很大。比如:现有两个文件存储在主站中,文件大小如表1。

Table 1 Files'information表1 文件信息
用户对文件的请求需要经过两次路由才能到达,假设用户在两个时间段内都对两个文件进行了请求,网络带宽为100 Mb/s,传播延迟相等,请求数量如表2。

Table 2 The first interval表2 第一次间隔
按照IPFRF的计算方式,文件A和文件B的流行度如表3所示(因为传播延迟相等,所以只计算发送延迟,每个文件的初始流行度都为0.5,a=0.5)。

Table 3 Result after the first interval表3 第一次间隔后结果
如表3由于文件A的流行度远大于文件B,因此IPFRF选择将文件A作为候选副本,但是由边际分析可知,文件B的额外请求会造成更多延迟,虽然文件B比文件A需要更多存储空间,但是在一定条件下,需要优先放置文件B。按照IPFRF的方法将文件A作为副本放置后,第二个时间间隔假设用户对文件A和文件B的请求数量和第一个时间间隔一样,第二个时间间隔产生的延迟如表4。

Table 4 Delay caused by files using IPFRF in the 2nd interval表4 IPFRF第二个间隔产生延迟
如果第一轮不放置文件A为副本,而选择B为副本时,第二个时间间隔产生延迟如表5。

Table 5 If replicate file B表5 假设为文件B创建副本
由此可见,IPFRF在流行度定义上仍有不足,通过边际延迟考虑文件大小对延迟的影响,本文定义改进的流行度如下:
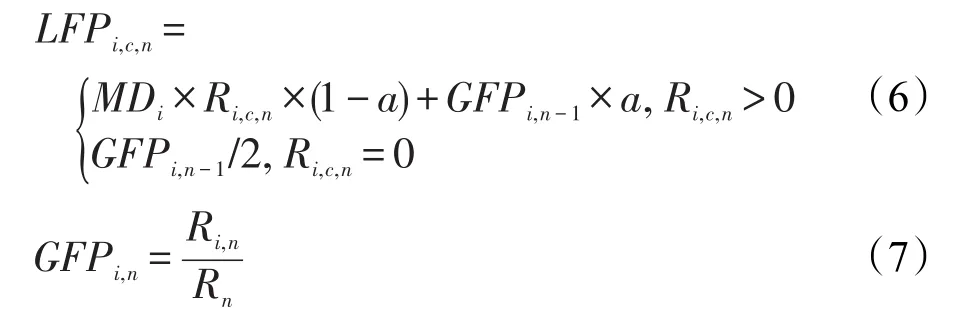
其中,GFPi,n表示全局流行度;Ri,n表示第n个时间间隔文件i在所有集群中的请求次数;Rn表示所有文件在所有集群中的总请求次数;LFPi,c,n表示集群c中文件i在第n个时间间隔的本地流行度;MDi表示文件i的边际延迟;0≤a≤1。如果采用本文流行度定义,则上文举例中第一个间隔结束后结果如表6。

Table 6 Result by refined definition表6 按本文热度定义结果
4.2 算法
IPFRF算法仅由主站完成副本选择和放置任务,这种集中式的算法不利于负载均衡且容错性较低,因此本文重新设计了算法框架,将副本选择和放置任务交给LRC执行,而GRC负责收集全局信息并记录维护全局流行度表。算法中符号意义如表7。
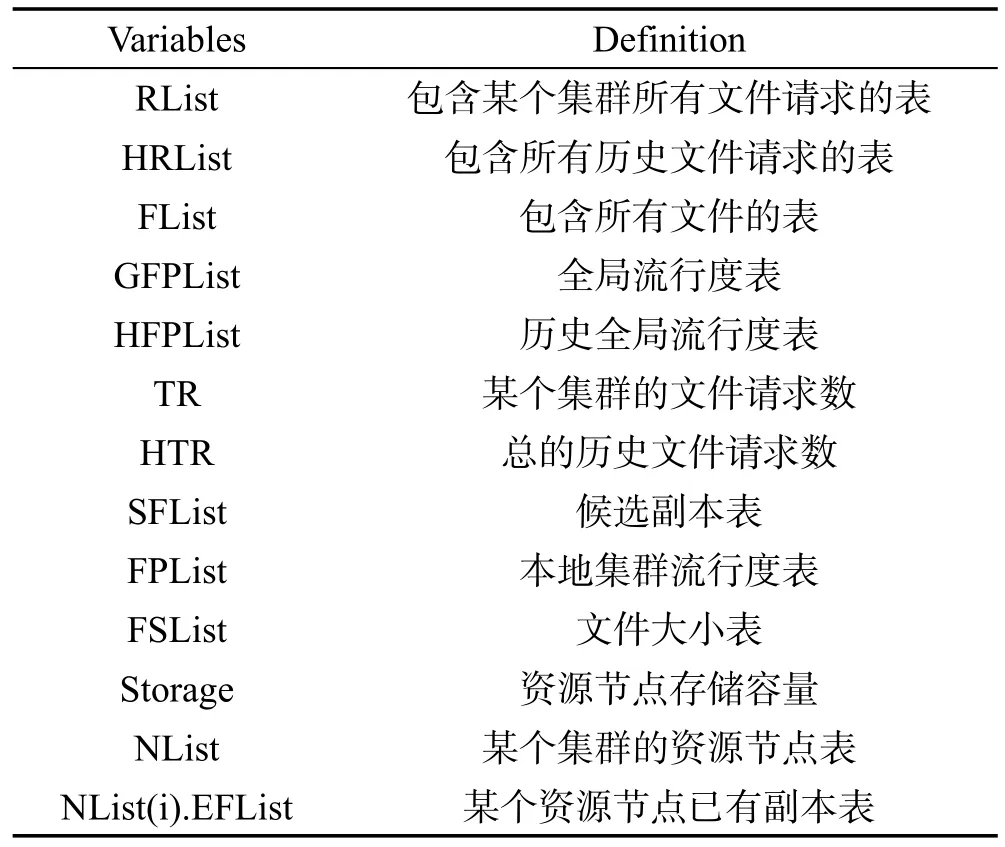
Table 7 Symbol table表7 符号表
GRC算法(算法1)由两部分组成,第一部分从各个集群中收集文件请求。第二部分利用历史文件流行度表以及新的文件请求更新文件流行度表,然后排降序。
贪心算法(算法2)负责根据文件大小、文件流行度贪心选择出候选副本。然后再将候选副本交由LRC算法,根据对应节点剩余容量、已有副本、文件流行度来放置副本,如果节点剩余容量充足,就直接将副本传输到对应节点,如果节点剩余存储容量不足,就根据文件大小和文件流行度的比较看是否值得替换已有文件副本。
LRC算法(算法3)为各个集群分别运行的算法,主要负责本集群的文件请求信息收集以及候选副本的选择和放置。经过式(4)计算文件流行度后排降序。
算法1收集文件请求,维护全局流行度


算法3副本选择和放置


4.3 存取模式
文献[10]使用了两种偏好模式来模拟用户的存取行为,第一种为均匀分布,如图2。第二种为Zipf,均匀分布对文件基本无偏好,如图3。可以检测算法在一般条件下的性能,Zipf分布能模拟用户带偏好的文件请求。所谓用户偏好,即用户对不同文件的喜好,比如一部分用户更偏向于使用视频文件,另一部分用户偏向于使用文本文件或者音频文件,不同类型的用户拥有不同的偏好。
Zipf分布中,不同集群的用户拥有不同偏好,第一个集群中的用户对文件0~20的文件更加喜好。第二个集群中对文件50~70的文件更加喜好。每个集群在每一个时间间隔都有不同的喜好。前两种存取模式应用在文献[10]中用来测试IPFRF算法的有效性。本文引入第三种存取模式:高斯分布来模拟用户偏好行为,如图4。
高斯分布的曲线没有Zipf分布陡峭,能比较好地适应当用户从无偏好状态逐渐转移到有偏好状态的情况。
Fig.2 Average distribution图2 平均分布
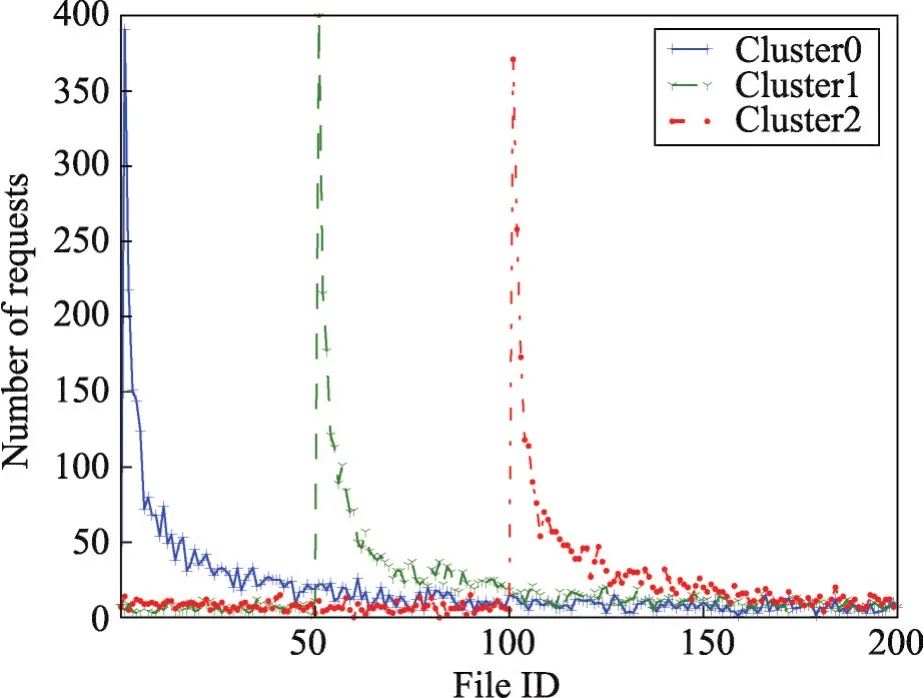
Fig.3 Zipf distribution图3 Zipf分布
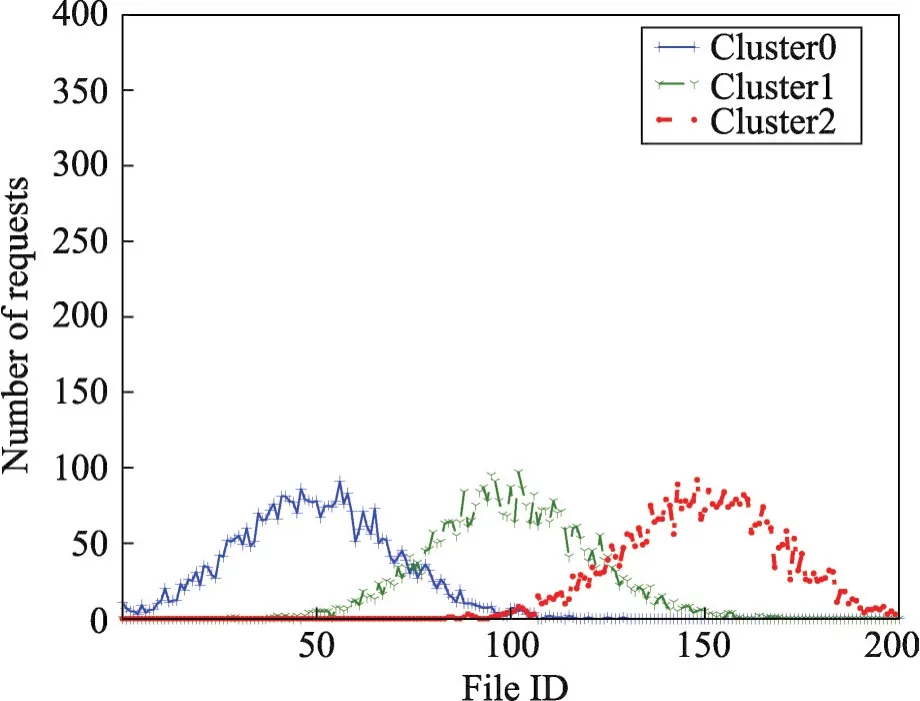
Fig.4 Normal distribution图4 高斯分布
均匀分布中用户对文件无特定偏好,用户对文件的请求次数总是在固定值上下小范围波动。
为了确保每一个时间间隔的用户偏好动态变化,每一次生成用户对文件的请求时进行一定程度的平移:
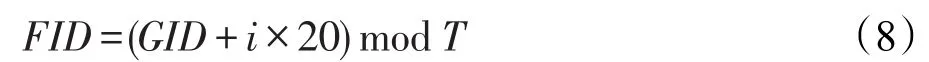
其中,FID为实际生成的文件ID;GID为由不同的存取模式生成的文件ID;T为文件数量。
5 实验
5.1 模拟实验
模拟实验的网络拓扑结构为星型拓扑,模拟参数如表8。
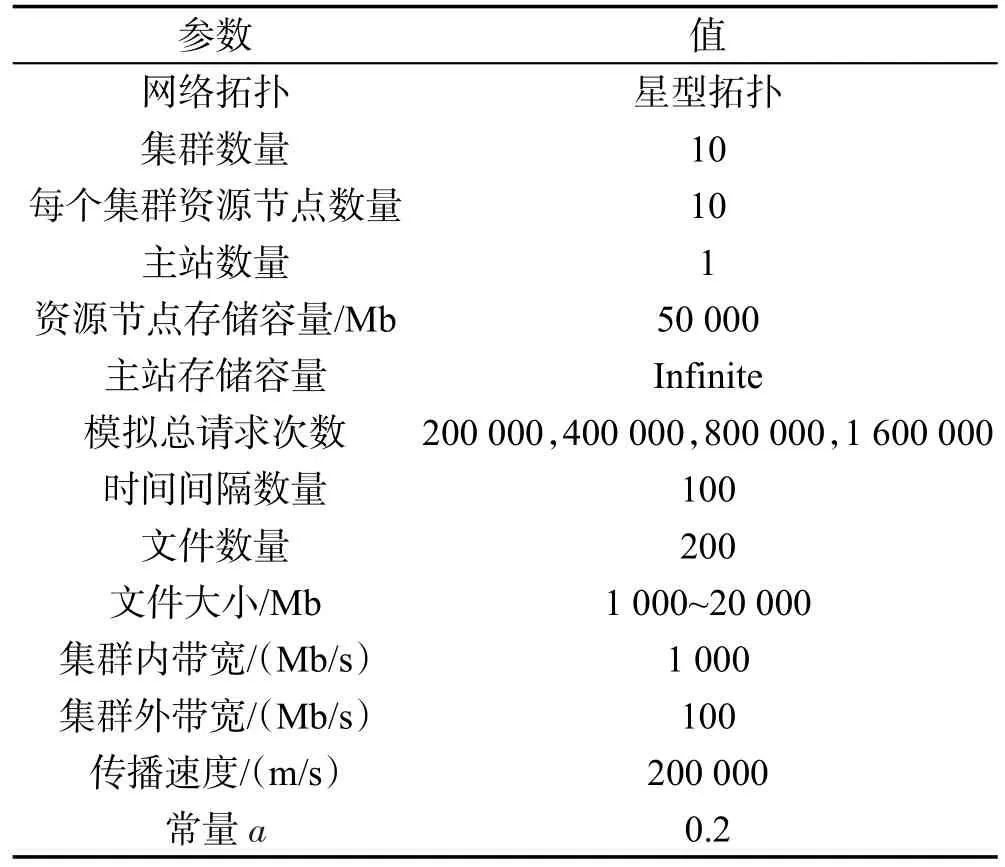
Table 8 Simulation parameters表8 模拟参数
每个集群内部的LRC负责管理存储在集群中资源节点中的副本,并提供策略在适当的时间和位置存储副本,由于服务器容量有限,同时也要在适当的时机删除一部分不太重要的副本,为后续更重要的副本腾出空间。
所有集群都和主站连接,集群之间无直接连接。为方便实验,假设主站容量为无限大,实际上,在现实生活中可以认为其为云端。本文的网络拓扑和文献[10]保持一致。模拟请求次数表示用户总共发出的文件请求次数。模拟将会分4次进行,每一次模拟的时间间隔100次,每一次时间间隔中产生的文件数量可以代表时间长短,数量越多,任务时间间隔越长。4次模拟文件请求总数分别为200 000、400 000、800 000、1 600 000次,在不同压力下来检测算法的有效性。集群内的资源节点和LRC连接,资源节点之间无直接连接。常量a的取值根据文献[1],由于IPFRF中没有对a的显示赋值,也无常量a取值的讨论,因此参考PFRF算法中对a的取值。
对集群地理位置的模拟采用以下公式在模拟时生成:

其中,region为集群偏移量;offset为集群内资源节点的偏移量;(x,y)为资源节点的位置。
5.2 模拟实验结果及分析
实验利用Java多线程编程实现。实验分三部分进行:第一部分模拟用户请求行为符合均匀分布时的场景;第二部分模拟用户请求行为符合Zipf分布时的场景;第三部分模拟用户请求符合高斯分布时的场景,每个场景进行8次实验取平均为最后实验结果。
第一场景为均匀分布场景,各个集群的用户不会产生特定偏好,由于差异较小,算法容易产生误判断导致最后结果较差,但是从表9和表10可以看出本文提出的算法策略较IPFRF仍有一定程度的提升。由于文件请求数量差异性较小,因此由本文基于边际分析定义的流行度能选择边际延迟较大的文件放置副本,而IPFRF偏向选择小文件,虽然能放置更多副本,但是在请求数量差异较小的情况下,体积较大的文件产生的延迟远大于体积较小的文件产生的延迟。
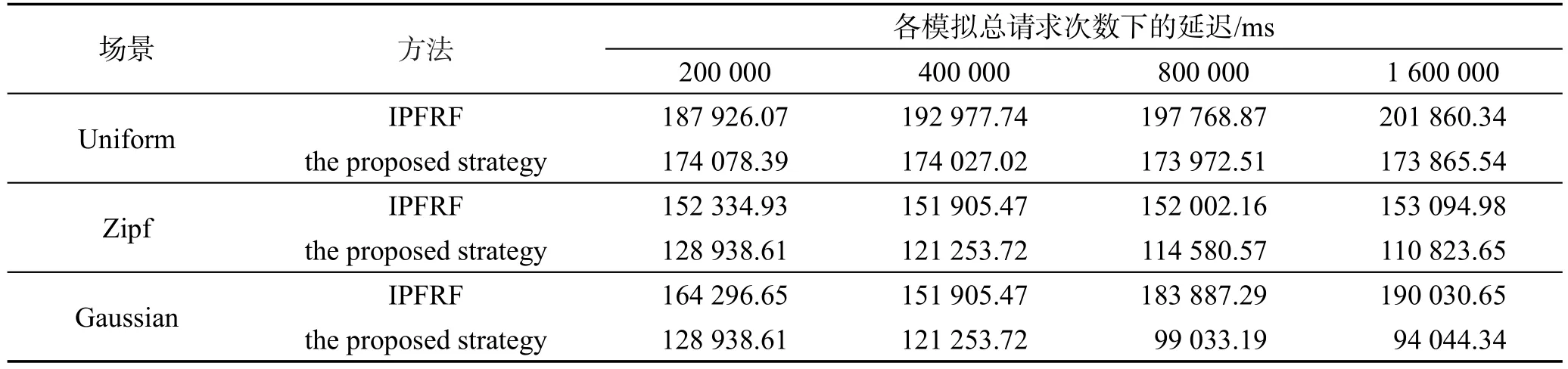
Table 9 Average latency表9 平均文件延迟
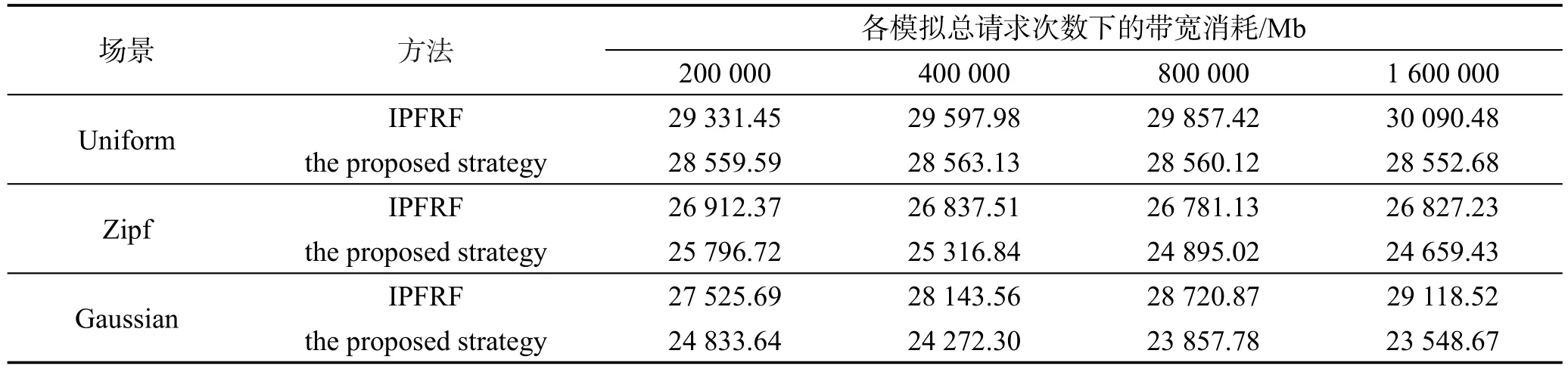
Table 10 Average bandwidth表10 平均带宽消耗
第二场景为Zipf分布,从其分布图中可以看出,各个集群的用户带有非常强烈的不同偏好,这种带有非常强烈偏好的用户一般为老用户。在此情境下,只需要预测命中少量的副本即可大幅度降低文件延迟,在资源节点容量有限的情况下,IPFRF达到了很好的性能,但是同样在副本命中率相似的情况下,优先大文件的放置相比优先小文件的放置能减少更多的延迟。
第三场景为高斯分布。这种情境适合新用户到老用户的过渡阶段,带有偏好但是对其他不同类型文件怀有好奇心,因此偏好差异没有Zipf剧烈。在这种情况下不仅考验算法的副本命中率,而且需要平衡文件大小和存储容量对资源节点的影响。
6 结束语
本文通过边际分析方法,改进了IPFRF利用请求密度(即文件请求数除以文件体积)来定义文件流行度的方法,IPFRF的定义偏向于选择体积较小的文件,而实际情况大文件在同等情况下会产生更大的延迟。本文根据边际延迟分析重新定义了文件流行度。同时,根据IPFRF的算法框架过于中心化的缺点,将副本放置算法分成两部分分别在GRC和LRC处执行,分散了主站的压力并将副本选择和放置任务交给集群自己处理,更能适应集群偏好变化,而主站对全局流行度的把握能更好地预防经验错误,提高副本选择的准确性。最后本文通过传统的两种存取模型模拟用户行为变化之外,引入了第三种分布模型:高斯分布,更能反映新老用户交替的文件请求的行为变化。但是本文提出的算法仍有不足之处,比如算法所适用拓扑模型比较局限,算法框架仍然属于中心式,但是集群和主站的异步交互方式让算法拥有良好的可扩展性。算法实验环境也需要在真实的用户网络中进行检测和验证。随着CDN和P2P的发展,如何在更加复杂的网络上部署副本放置技术也成为本文未来的研究方向。
