汉语水平考试的研究现状与文献特征
2018-08-14马春雨

摘 要:本文运用统计和数学建模方法,对1988年以来收录在中国知网(CNKI)中的有关汉语水平考试(HSK)研究的论文进行分析。在论文年度分布、作者分布、机构分布、出版物分布等方面进行数学建模。应用普赖斯公式和布拉德福定律推算出49名核心作者、9个核心机构、15种核心出版物等。本文论述了HSK研究现状与发展趋势,总结文献特征及其分布规律,为HSK计量研究提供依据和参考。
关键词:汉语水平考试(HSK) 洛特卡定律 布拉德福定律 逻辑斯蒂模型
一、引言
汉语水平考试(HSK)是为母语非汉语考生(如外国人、华侨及国内少数民族)设立的官方标准化汉语能力测试[1]。汉语水平考试从1984年开始研制,1990年在国内组织实施,1991年正式推向海外,1992年升为国家级考试。1992年《汉语水平词汇与汉字等级大纲》[2]、1996年《汉语水平等级标准与语法等级大纲》[3]、2007年《国际汉语能力标准》[4]、2009年《汉语水平考试HSK(基础、初中等、高等)大纲》[5]、2013年《新汉语水平考大纲(一至六级)》[6]相继出版,并推出了新HSK[7],在实现“以考促教、以考促学”方面,发挥了积极作用。HSK已成为考核汉语交际能力和掌握语言知识面的衡量标尺,受到了对外汉语教学工作者和汉语学习者的广泛关注。截至2016年底,全球125個国家(地区)设立1066个考点(中国大陆371个,海外695个),全年各类汉语考试考生达600万人[8],这说明HSK需求强劲。同时,关于汉语水平考试的相关研究也不断出现,如HSK科学性质和特点[9],汉语水平考试历史演变[10],HSK词汇等级表[11],相关词汇教学研究[12],汉字偏误分析[13]等等。为了更好地发挥HSK测试平台的作用,推进汉语水平考试发展,有必要对过去的30年间(1988~2017年)HSK研究状况进行分析,挖掘文献特征及其分布规律,预测HSK今后发展趋势,对HSK的完善具有重要意义。
本文以1988~2017年CNKI收录的3188篇HSK论文作为研究对象,对论文增长、作者分布、发文机构和载文出版物等进行了统计。首次将科学计量方法应用到HSK研究,并阐明HSK发展现状、趋势和文献特征及其分布规律,为HSK的深入研究提供参考。
二、数据采集
本文研究数据收集于中国知网CNKI的学术文献总库n,其中包括:学术期刊、学术辑刊全文数据库、博士学位论文和优秀硕士学位论文。学科领域=人文与社会科学文献+信息科技;时段=1988~2017年,主题=“汉语水平考试”或含“HSK”进行精确检索,共检索到4252篇。删除无作者、无单位、书讯、会讯、新闻报道、简介等非规范文献后,得到有效论文3188篇。对这部分数据先采用Excel进行统计,再使用Origin软件对这些文献进行数学建模分析。
三、结果与分析
(一)年度分布
自1984年汉语水平考试研制以来,不少学者对其进行了相关研究,相关论文发表情况见表1。
1988~1996年,年均论文发表量少于20篇,年均5.2篇;1997~2003年,年均论文发表量少于30篇,年均22.9篇;2004~2010年,年均论文发表量68.9篇;2011~2017年,年均论文发表超过200篇,年均论文357篇,总体来说,汉语水平考试研究量呈增长态势。
从1984年开始研制,到1996年《汉语水平等级标准与语法等级大纲》发布,相关研究也处于萌芽阶段;从1997年到2003年新HSK大纲发布之前,相关研究处于起步阶段;自2003年新HSK大纲发布之后,2004年至2010年,研究处于缓慢发展阶段;2011年至今,论文数量飞速增长,处于快速增长阶段。
图1是论文增长曲线,横坐标为时间(t=实际年度-1987),纵坐标为论文累计量。根据马春雨(2017)的方法[15],利用Origin软件分析,采用指数函数:y=aexp(bt),对表1数据进行数学建模,得到理论拟合曲线:y=7.825e0.2028t,其拟合度为R2=0.992,拟合效果达99.2%,数据拟合度越高,拟合效果越高,说明理论结果与实际观察数据越符合,表明HSK研究论文符合指数增长规律。其文献增长速度,即文献翻倍所需要的时间=ln2÷b=ln2÷0.2028=3.4年。总体来说,从1988年至今,汉语水平考试相关研究越来越受关注。
(二)作者分布与核心作者
1.作者分析
根据只统计第一作者的原则,采集数据,列表2。
利用洛特卡定律(Lotas Law)描述论文与作者之间的数量关系,其一般形式[16]:
,C>0,x=1,2,3,…,m(1)
x为每位作者发文量,其取值从1到最大值(m);n是指数常量;y为作者人数,为作者总数(=2853,表2),洛特卡定律常数是,即发表1篇论文的作者百分比。在表2中,C=92.114%,即发表1篇HSK论文的作者占92.114%,高于经典洛特卡定律常数C经典=60.79%[17],反映新作者不断参加HSK研究,汉语水平考试不断受到关注,拥有广泛的研究群体,也代表HSK属于热点课题之一。
图2是论文与作者分布图,它由表2数据绘制而成,从表2可知:发文1篇的作者占优(92.114%),发文2篇的作者居次(6.169%),发文≥3篇的作者仅占1.717%。利用公式(1)和Origin软件,对表2数据进行数学建模,得到理论拟合曲线是幂函数:,其曲线拟合度R2=0.99999,拟合效果达99.999%。说明HSK作者分布适合负幂律,即:随发文量的增加,作者数以负幂函数减少,说明许多学者已关注到HSK发展,并为此做出贡献。但是,作者数与论文数之间存在图2所示的“长尾巴”不均衡现象。
2.核心作者
在表2中,核心作者的发表论文最大值Nmax=13篇。依据普赖斯公式[17],核心作者发文阈值=2.7?3(邻近最大整数)。发文量≧3篇的49位高产作者,属于核心作者,他们共发表208篇论文,分别占作者总数和论文总数的6.52%和1.72%。普赖斯定律规定“核心作者群”条件:核心作者占作者总数的20%,论文占总数的50%。理论核心作者数=642人,与实际核心作者(49名)相差太大。由此可见,在汉语水平考试领域,还没有形成核心作者群。表2列出部分核心作者。
(三)机构分布
采用第一作者机构统计原则,本文研究的3188篇论文来自297个机构。按每个机构发文量的递减顺序编排制成表3,D是机构数量,机构累计量x=∑Di,E是每个机构发文量,论文累计量y=∑(Di×Ei)。
布拉德福定律认为,在发文量基本相同的情况下,表3的论文产出机构可分成:核心区、相关区和离散区,见表4。
在表4中,三个区的机构数存在等比关系,即9:28:260≈1:5:52≈1:a:a2,布拉德福系数a=5。表明HSK研究机构分布符合布拉德福定律的集中与离散规律[18],即核心区的9个机构,占机构总数的3.03%,集中发表论文32.999%;而离散区的260个机构,占总数87.54%,离散地发表论文33.501%。
布拉德福定律认为,核心区的机构就是“核心机构”,即发文量≧63篇的机构。表3列出了9个核心机构的名称,包括:4所综合大学、3所师范大学和1所语言大学。其中,北京语言大学居首。
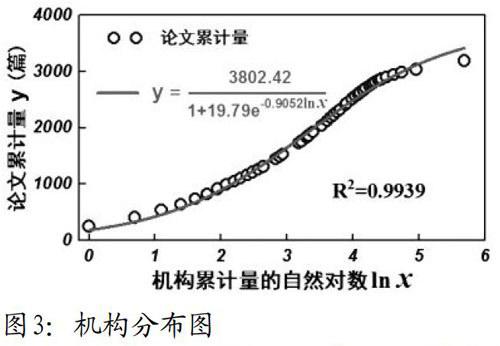
图3是论文与机构的分布图。它由表3数据绘制而成,从图3曲线形态可以看出,HSK机构分布近似“S”型曲线,即:随发文机构数量的增加,论文累计量呈现“缓慢发展期—快速递增期—稳定饱和期”的变化过程。通常“S型曲线”采用逻辑斯蒂函数(Logistic function)建模。因此,对表3数据进行数学建模分析[19],得到逻辑斯蒂增长函数:,曲线拟合度R2=0.9939,拟合效果达99.39%,表明HSK论文产出机构分布符合逻辑斯蒂增长规律。即HSK产出机构经过不断的累计,发文数量先经历一段缓慢增长期,之后,才进入快速增长阶段;随后,尽管机构累计增加,但发文量变化不大,处于稳定的饱和期,其饱和期越长,HSK研究就越接近完备状态。
(四)出版物分布与核心出版物
本文统计的3188篇论文登载于463种出版物(期刊、硕士和博士论文)。表5是按每种出版物发文量的递减顺序制成,F为出版物数量,出版物累计量x=∑Fi,G为每种出版物载文量,论文累计量y=∑(Fi×Gi)。
按发文数量基本相同原则,表5的出版物可分成:核心、相关和离散三个区,见表6。
在表6中,三个区的出版物数量构成比值为14:39:350≈1:5:52,即布拉德福系数a=5。说明HSK出版物分布也符合布拉德福定律。核心区的出版物就是HSK研究的“核心出版物”,即载文量≧43篇的出版物。在表5,列出了15种核心出版物,包括12篇高校硕士论文和3种期刊。其中,吉林大学硕士毕业论文居首。
图4是出版物与论文的关系曲线。HSK出版物分布也呈现“S”型曲线,即:随载文出版物数量的增加,论文累计量呈现“缓慢增长期—快速递增期—稳定饱和期”的变化过程。
利用逻辑斯蒂模型(Logistic model),对表5数据进行数学建模,获得逻辑斯蒂增长函数:,其擬合度R2=0.9978,拟合效果达99.78%。表明逻辑增长函数满足HSK论文出版物分布规律。说明有关汉语水平考试的出版物不断发展,相关研究日趋完善。
四、结语
通过上述统计和数学建模方法,我们可以得出以下结论:
(一)从论文增长规律来看,符合指数增长规律,HSK研究总体呈上升趋势。
(二)从作者来看,符合洛特卡定律,即随每人发文量的增加,作者人数呈负幂函数减少。从作者群体而言,HSK具有广泛的作者群体。但是,核心作者(49人)较少,没有形成“核心作者群(642人)”,这是HSK领域的不足,需要增加核心作者数量。
(三)从发文机构分布和载文出版物分布来看,符合集中与离散的布拉德福定律,且可用逻辑斯蒂增长函数表征。
总之,本文提出的HSK论文具有增长性;作者具有广泛性;发文机构和载文出版物具有集中性;论文的表述具有规律性(指数规律、洛特卡定律、布拉德福定律);可以采用数学建模(指数函数、Logistic模型)的方法进行分析,为HSK研究提供一种新的研究方法与思路。
参考文献:
[1]袁艺铭.浅析新汉语水平考试——口语测试[J].现代语文(语言研究版),2017,(10).
[2]国家汉办汉语水平考试部.汉语水平词汇与汉字等级大纲[Z].北京:北京语言学院出版社,1992.
[3]国家汉办.汉语水平等级标准与语法等级大纲[Z].北京:高等教育出版社,1996.
[4]国家汉办.国际汉语能力标准[M].北京:外语教学与研究出版社,2007.
[5]国家汉办/孔子学院总部.汉语水平考试HSK(基础、初中等、高等)大纲[Z].北京:商务印书馆,2009.
[6]国家汉办/孔子学院总部.新汉语水平考试大纲(一至六级)[Z].北京:商务印书馆,2013.
[7]张晋军,解妮妮,王世华,李亚男,张铁英.新汉语水平考试(HSK)研制报告[J].中国考试,2010,(9):38-43.
[8]国家汉办.2016孔子学院年度发展报告[EB/OL].
http://www.hanban.edu.cn/report/2016.pdf.(2017-10-20).
[9]劉英林,郭树军,王志芳.汉语水平考试(HSK)
的性质和特点[J].世界汉语教学,1988,(2):110-120.
[10]杨翼.对外汉语测试与评估的历史演变与发展趋势[J].中国考试,2009,(1):35-40.
[11]高松.《新汉语水平考试大纲》词汇等级表的名词考察[J].现代语文(语言研究版),2014,(10).
[12]辛慧.留学生HSK汉语水平考试词汇教学研究——以离合词类为例[J].现代语文(学术综和版),2017,(2).
[13]刘晓朦,高松.高级阶段日本留学生汉字偏误分析[J].现代语文(语言研究版),2013,(3).
[14]清华同方.CNKI数据库[EB/OL].(2017-10-20),http://epub.cnki.net/grid2008/index/ZKCALD.htm.
[15]马春雨.基于文献计量的孔子学院研究[J].云南
师范大学学报(对外汉语教学与研究版),2017,(2).
[16]Sen BK.Lotka's Law:a viewpoint[J].Ann Lib Inf Stu,2010,(2):166-167.
[17]邱均平.信息计量学[M].武汉:武汉大学出版社,2007.
[18]Goffman W,MorrisTG.Bradford's law and library acquisitions[J].Nature,1970,(5249):922-923.
[19]兰月新.基于动态logistic模型的文献增长规律研究[J].科学情报,2014,(3):86-89+97.
Research Status and Literature Characteristics of Chinese Proficiency Test(HSK)
Ma Chunyu
(School of Chinese Studies,Beijing Language University,Beijing 100083,China)
Abstract:By using statistics and mathematical modeling methods,This article analyses the literature on Chinese Proficiency Test(HSK)research that has been included in the CNKI database since 1988.The mathematical modeling is established in the annual distribution of the literature,the distribution of the authors,the distribution of institutions and the distribution of publications.Using Price's law and Bradford's law,49 core authors,9 core institutions and 15 core publications are calculated.This paper expounds thepresent status and development trend of HSK research, and the characteristics and rules of the literature are excavated to provide the basis and reference for the HSK bibliometric research.
Key words:Chinese Proficiency Test(HSK);Lotka's law;Bradford's law;Logistic model
