Parallel Reinforcement Learning:A Framework and Case Study
2018-07-31TengLiuMemberIEEEBinTianYunfengAiLiLiFellowIEEEDongpuCaoMemberIEEEandFeiYueWangFellowIEEE
Teng Liu,Member,IEEE,Bin Tian,Yunfeng Ai,Li Li,Fellow,IEEE,Dongpu Cao,Member,IEEE,and Fei-Yue Wang,Fellow,IEEE
Abstract—In this paper,a new machine learning framework is developed for complex system control,called parallel reinforcement learning.To overcome data deficiency of current data-driven algorithms,a parallel system is built to improve complex learning system by self-guidance.Based on the Markov chain(MC)theory,we combine the transfer learning,predictive learning,deep learning and reinforcement learning to tackle the data and action processes and to express the knowledge.Parallel reinforcement learning framework is formulated and several case studies for real-world problems are finally introduced.
I.INTRODUCTION
M ACHINE learning especially deep reinforcement learning(DRL)experiences an ultrafast development in recent years[1],[2].No matter in traditional visual detection[3],dexterous manipulation in robotics[4],energy efficiency improvement[5],object localization[6],novel Atari game[7],[8],Leduc poker[9],Doom game[10]and text-based games[11],these data-driven learning approaches show great potential in improving performance and accuracy.However,there are still several issues to impede researchers applying DRL to handle the real complex system problems.
One of the issues is lack of generalization capability to new goals[3].DRL agents need to collect new data and learn new model parameters for a new target.It is computationally expensive to retrain the learning model.Hence,we need to utilize the limited data well to accommodate the environments via learning.
Another issue is data inefficiency[8].Acquiring large-scale action and interaction data of real complex systems is arduous.To explore control policy by themselves is very difficult for the learning systems.Thus,it is necessary to create a large number of observations for action and knowledge from the historical available data.
Finally,the issue is data dependency and distribution.In practical systems,data samples dependency is often uncertain and probability distribution is usually variant.So,it is hard for DRL agents to consider the state,action and knowledge of a learning system in an integrated way.
In order to address these difficulties,we develop a new parallel reinforcement learning framework for complex system control in this paper.We construct an artificial system analogy to the real system via modelling to constitute a parallel system.Based on the Markov chain(MC)theory,transfer learning,predictive learning,deep learning and reinforcement learning are exhibited to tackle data and action processes and to express knowledge.Furthermore,several application cases of parallel reinforcement learning are introduced to illustrate its usability.It is noticed that the proposed technique in this paper can be regarded as the specification of the parallel learning in[12].
Fei-Yue Wang first initialized the parallel system theory in 2004[13],[14].In[13]and[14],ACP method was proposed to deal the complex system problem.ACP approach represents artificial societies(A)for modelling,computational experiments(C)for analysis,and parallel execution(P)for control.An artificial system is usually built by modelling,to explore the data and knowledge as the real system does.Through executing independently and complementally in these two systems,the learning model can be more efficient and less data-hungry.ACP approach has been applied in several fields to discuss different problems in complex systems[15]-[17].
Transfer learning focuses on storing knowledge gained while solving one problem and applying it to a different but related problem.Taking driving cycles of vehicle as an example,we introduce mean traction force(MTF)components to achieve equivalent transformation of them.By transferring limited data via MTF,the generalization capability problem can be relieved.

Fig.1.Parallel reinforcement learning framework.
Predictive learning tries to use prior knowledge to build a model of environment by trying out different actions in various circumstances.Taking power demand for example,we introduce fuzzy encoding predictor to forecast the future power demand in different time steps.Based on the MC,historical available data can be used to solve the data inefficiency.
Deep learning is defined via learning data representations,including multiple layers of nonlinear processing units and the supervised or unsupervised learning of feature representations in each layer.Reinforcement learning is concerned with how agents ought to take actions in an environment so as to maximize some notion of cumulative reward.The main contribution of this paper is combining parallel system with transfer learning,predictive learning,deep learning and reinforcement learning to formulate the parallel reinforcement learning framework to dispose the data dependency and distribution problems in real-world complex systems.
The rest of this paper is organized as follows.Section II introduces the parallel reinforcement learning framework and relevant components,then several case studies for real-world complex system problems are described in Section III.Finally,we conclude the paper in Section IV.
II.FRAMEWORK AND COMPONENTS
A.The Framework and the Parallel System
The purpose of parallel reinforcement learning is building a closed loop of data and knowledge in the parallel system to determine the next operation in each system,as shown in Fig.1.The data represents the inputs and parameters in artificial and real systems.The knowledge means the records from state space to action space,which we name in the real system as experience and that in the artificial system as policy.The experience can be used to rectify the artificial model and updated policy is utilized to guide the real actor along with feedback from environment.
Cyber physical systems have attracted increasingly more concerns for their potentials to fuse computational processes with the physical world in the past two decades.Furthermore,cyber-physical-social systems(CPSS)augment the cyber physical system capacity by integrating the human and social characteristics to achieve more effective design and operation[18].The ACP-driven parallel system framework is depicted in Fig.2.The integration of the real and artificial system as a whole is called parallel system.
In this framework,the physically-defined real system interacts with the software-defined artificial system via three coupled modules within the CPSS.The three modules are control and management,experiment and evaluation,learning and training.The first module belongs to decision maker in these two systems,the second one represents the evaluator and the final one indicates the learning controller.
ACP=Artificial societies+Computational experiments+Parallel execution.Artificial system is often constructed by descriptive learning based on the observation on the real system due to the development in information and communication technologies.It can help learning controller store more computing results and make more flexible decisions.Thus,the artificial system is parallel to the real system and runs asynchronously to stabilize the learning process and extend the learning capability.

Fig.2.ACP-driven parallel system framework.
In the computational experiment stage,the specifications of transfer learning,predictive learning and deep learning are illustrated by the MC theory,as we will discuss them later.For the parallel system,combining these learning processes with reinforcement learning,the parallel reinforcement learning is formulated to derive the experience and policy and to clarify the interaction of them.For a general parallel intelligent system,such knowledge can be applied in different tasks because the learning controller can handle several tasks via rational reasoning[19].
Finally,parallel execution between the artificial and real systems is expected to enable an optimal operation of these systems[20].Although the artificial system is drawn by the prior data of real system,it will be rectified and improved by the further observation.The consecutive updated knowledge in the artificial system is also used to instruct the real system operation in an efficient way.Owing to the communication of data and knowledge by parallel execution,these two systems can improve by self-guidance.
B.Transfer Learning
In this paper,we choose driving cycles as an example to introduce transfer learning,which can be easily popularized for other data in the MC domain.A general driving cycle transformation methodology based on the mean tractive force(MTF)components is introduced in this section.This transformation can convert the existent driving cycles database into an equivalent one with a real MTF value to relieve the data lacking problem.
MTF is defined as the tractive energy divided by the distance traveled for a whole driving cycle,which is integrated over the entire time interval[0,T]as follows

where xTis the total distance traveled in a certain driving cycle and calculated as∫v(t)dt,v is the vehicle speed with respect to a certain driving cycle.F is the longitudinal force to propel the vehicle and computed as
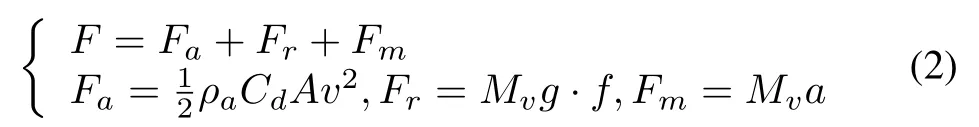
where Fais aerodynamic drag,Fris rolling resistance and Fmis inertial force.ρais the air density,Cdis the aerodynamic coefficient,and A is the frontal area.Mvis the curb weight,g is the gravitational acceleration,f is the rolling friction coefficient and a is the acceleration.
The vehicle operating modes are divided as traction,coasting,braking and idling according to the force imposed on the vehicle powertrain[21].Hence,the time interval is depicted as
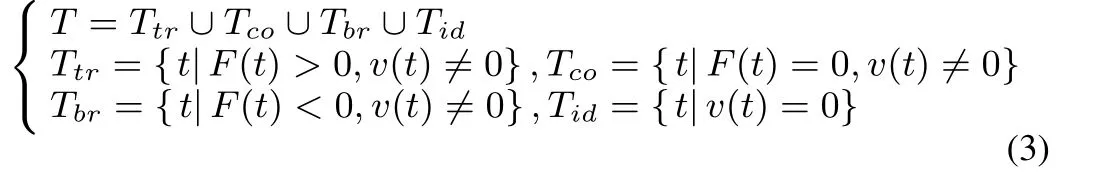
where Ttrand Tcoare the traction-mode and coasting-mode regions,respectively.Tbrrepresents the vehicle brakes and Tidis the idling set.
From(3),it is obvious that the powertrain only provides positive power to wheels in the traction regions.MTF in(1)is specialized as follows:
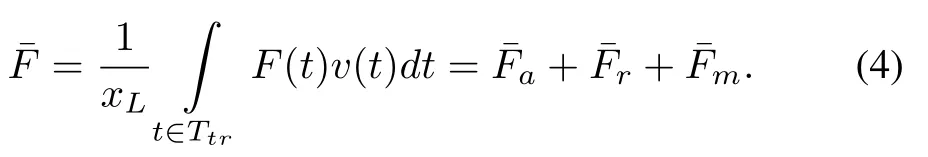
Then,MTF components(α,β,γ)are the statistic characteristics measures for a driving cycle that are defined as[22]

Note that MTF components are related to the speed and acceleration for a specific driving cycle.These measures are employed as the constraints for driving cycle transformation.
Definition decides MTF is unique for a specific driving cycle,thus inequality and equality constraints are employed to determine the transferred driving cycle.A cost function can be defined by the designer to choose an optimal equivalent one from a set of feasible solutions.This transformation is formulated as a non-linear program(NLP)as

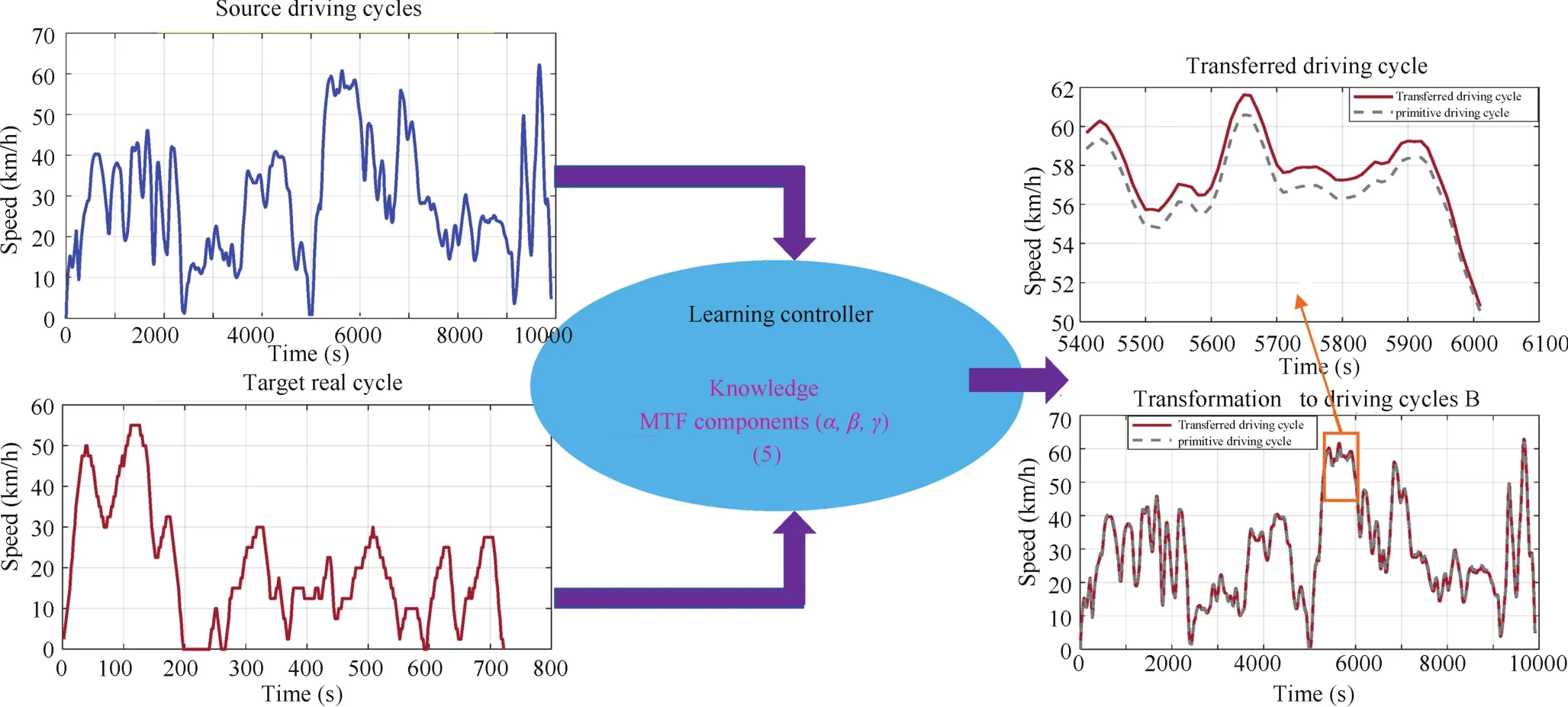
Fig.3.Transfer learning for driving cycles transformation.
The purpose of transfer learning is converting historical available data into equivalent one to expand the database.The transferred data is strongly associated with the real environments.Thus,it can be used for generating adaptive control and operations in complex systems,so as to solve the generalization capability and data hungry problems.
C.Predictive Learning
Taking power demand of vehicle for example,we introduce predictive learning to forecast the future power demand based on the observed data and processes in parallel system.A better understanding of the real system can then be described and applied to update the artificial system from these new experiences.A power demand prediction technology based on fuzzy encoding predictor(FEP)is illustrated in this section.This approach can also be used to draw more future knowledge from experiences for other parameters in the complex systems.
Power demand is modelled as a finite-state MC[23]and depicted as Pdem={pj|j=1,...,M}⊂X,where X⊂R is bounded.Transition probability of power demand is calculated by maximum likelihood estimator as
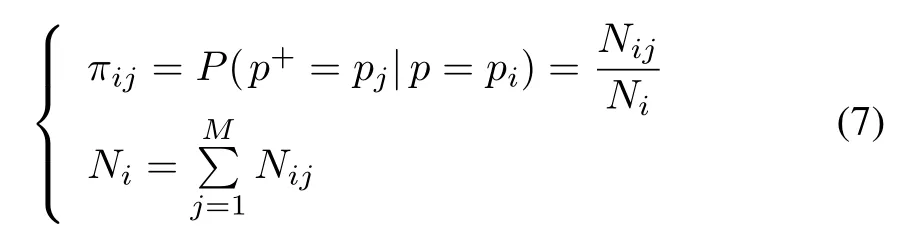
where πijis the transition probability from pito pj.p and p+are the present and next one-step ahead power demands,respectively.Furthermore,Nijindicates the transition count number from pito pj,and Niis the total transition count number initiated from pi.
All elements πijconstitute the transition probability matrix Π.For fuzzy encoding technique,X is divided into a finite set of fuzzy subsets Φj,j=1,...,M,where Φjis a pair(X,µj(·))and µj(·)is called Lebesgue measurable membership function and defined as

whereµj(p)reflects the membership degree of p∈X inµj.It is noticed that a continuous state p∈X in the fuzzy encoding may be associated with several states pjof the underlying finite-state MC model[24].
Two transformations are involved in FEP.The first transformation allocates an M-dimensional possibility(not probability)vector for each p∈X as
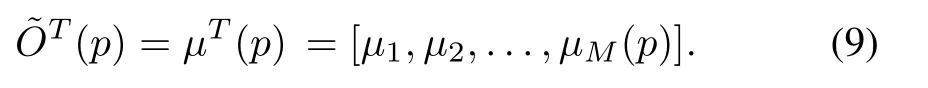
This transformation is named fuzzification and maps power demand in the space X to the vector in M-dimensional possibility vector space˜X.Note that it is not necessary for the sum of the elements in possibility vector˜O(p)to equal 1.
The second transformation is called proportional possibilityto-probability transformation,in which the possibility vector ˜O(p)is converted into a probability vector O(p)by normalization[23],[24]:

where this transformation maps˜X to an M-dimensional probability vector space, X.The element πijin the transition probability matrix(TPM)Π is interpreted as a transition probability between Φiand Φj.To decode vectors in X back to X,the probability distribution O+(p)is utilized to aggregate the membership functionµ(p)to encode the probability vector of the next state in X:
The expected value over the possibility vector leads to the next one-step ahead power demand in FEP:
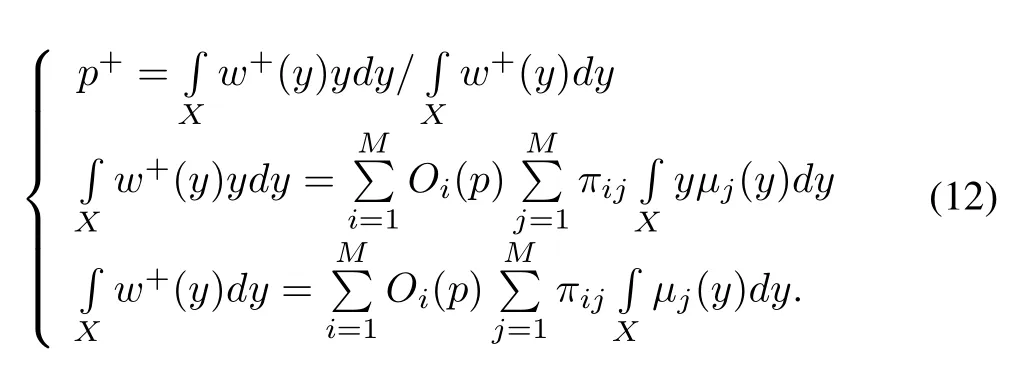
The centroid and volume of the membership functionµj(p)is expressed as

Thus,(12)is reformulated as

where expression(14)is the predicted one-step ahead power demand using FEP.Fig.4 shows an example of predictive learning used for power demand prediction.By doing this,the future power demand of vehicle in different time steps can be determined,and then these data will be used for improving the management and operations in the parallel system by selfguidance.
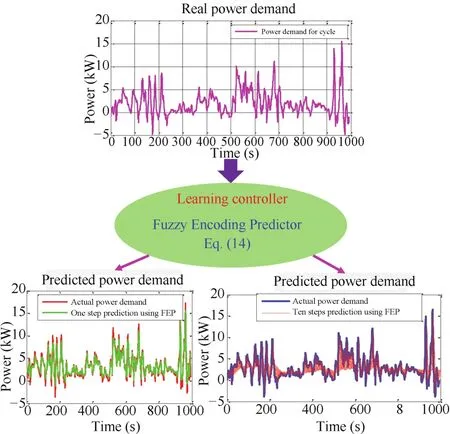
Fig.4.Predictive learning for future power demand prediction.
The goal of predictive learning is generating reasonable data from the prior existed data and real-time observations in the real world.We aim to minimize the differences between real samples and generated samples by tuning the parameters in the predictive learning methodology.Therefore,these generated data are responsible for deriving various experiences and guiding the complex system by learning process,so as to settle the data inefficiency and distribution problem.
D.Reinforcement Learning
In the reinforcement learning framework,a learning agent interacts with a stochastic environment.We model the interaction as quintuple(S,A,Π,R,γ),where s∈ S and a∈ A are state variables and control actions sets,Π is the transition probability matrix,r ∈ R is the reward function,and γ∈(0,1)denotes a discount factor.
The action value function Q(s,a)is defined as the expected reward starting from s and taking the action a:

The action value function associated with an optimal policy can be found by the Q-learning algorithm as in[25]

When the state and action space is large,for example the action atconsists of several sub-actions,modelling Q-values Q(s,a)becomes difficult.In this situation,we use both state and action representations as input to a deep neural network to approximate the action value function.
A deep neural network is composed of an input layer,one or more hidden layers and an output layer.As shown in Fig.5(a),the input vector g=[g1,g2,...,gR]is weighted by elements w1,w2,...,wR,and then summed with a bias b to form the net input n as
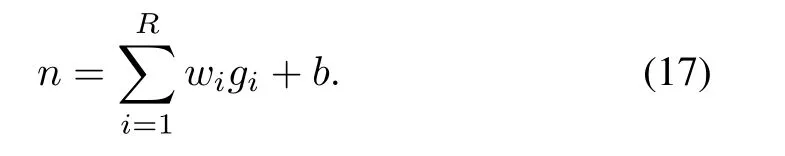
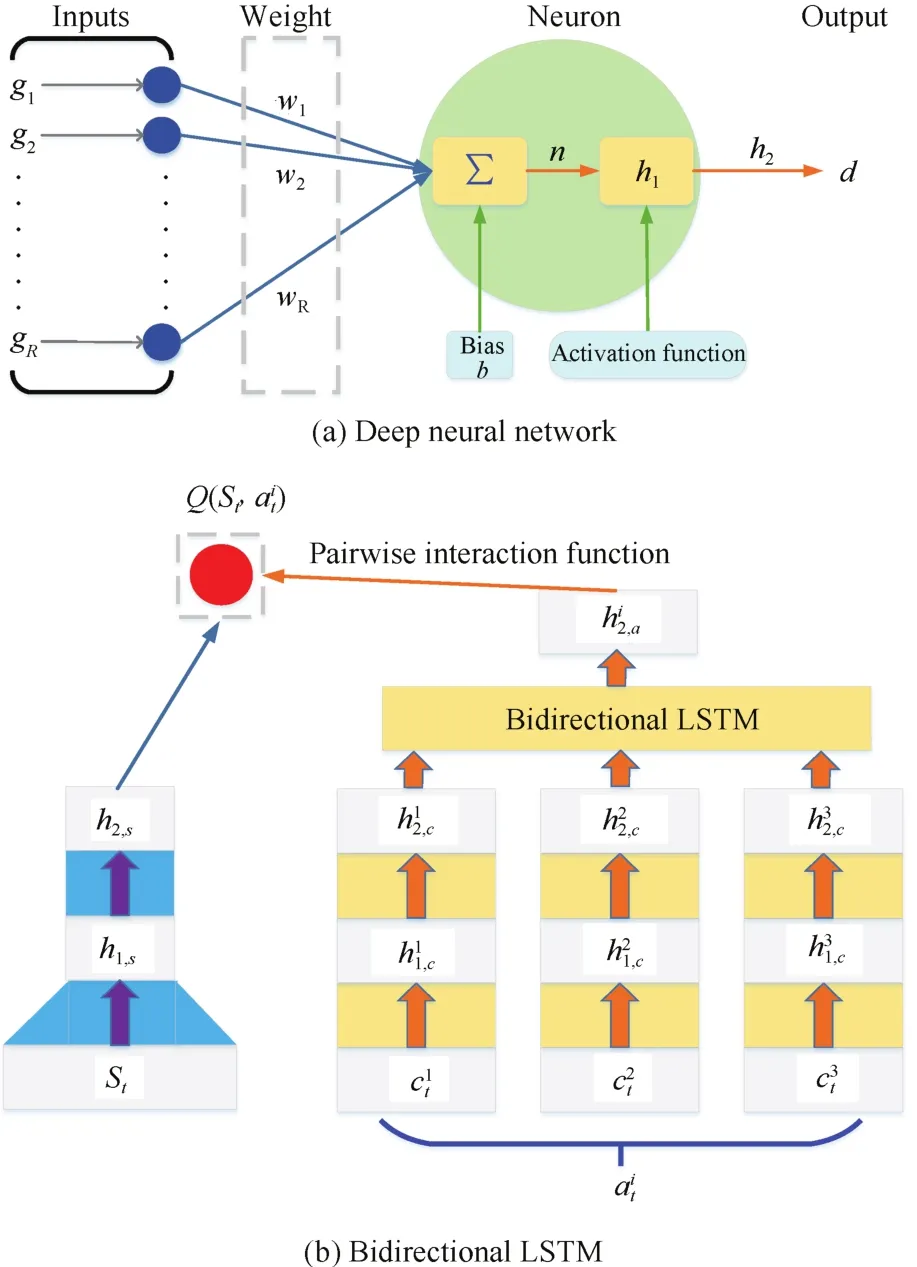
Fig.5.Deep neural network and bidirectional long short-term memory.
Then,the net input n is affected by an activation function h to generate the neuron output d.

where activation function usually includes activation function in the hidden layer h1and activation function in the output layer h2.
In this paper,we propose a bidirectional long short-term memory[26]based deep reinforcement network(BiLSTMDRN)to approximate the action value function in reinforcement learning,see Fig.5(b)for an illustration.This structure consists of a pair of deep neural networks,one for state variable stembedding and the other for control sub-actionsembeddings.As the bidirectional LSTM has a larger capacity due to its nonlinear structure,we expect it will capture more details on how the embeddings in each sub-action are combined into an action embedding.Finally,a pairwise interaction function(e.g.,inner product)is used to compute new Q(st,at)via combining the state and sub-actions neuron output as

where K is the number of the sub-actions,and Q(st,)represents the expected accumulated future rewards by including this sub-action.
Combining the ideas of parallel system,transfer learning,predictive learning and reinforcement learning,we can formulate a closed loop of data and knowledge,named parallel reinforcement learning,as described in Fig.1.Several case studies for real-world complex system problems are introduced and discussed in the next section.
III.CASE STUDIES OF PARALLEL REINFORCEMENT LEARNING
A.Existing Case Studies in Parallel Reinforcement Learning Framework
Parallel reinforcement learning serves as a reasonable and suitable framework to analyse the real world complex system.It consists of a self-boosting process in the parallel system,a self-adaptive process by transfer learning,a self-guided process by predictive learning and big data screening and generating process by BiLSTM-DRN.Learning process becomes more efficient and continuous in the parallel reinforcement learning framework.
Several complex systems have been researched and analysed in the perspective of parallel reinforcement learning,such as transportation systems[27],[28],and vision systems[29].A traffic flow prediction system was designed in[27],which considered the spatial and temporal correlations inherently.First,an artificial system named stacked autoencoder model was built to learn generic traffic flow features.Second,the synthetic data were trained by a layer-wise greedy method in the deep learning architecture.Finally,predictive learning was used to achieve traffic flow prediction and self-guidance for the parallel system.A survey on the development of the data-driven intelligent transportation system(D-DITS)was introduced in[28].The functionality of D-DITS’s key components and some deployment issues associated with its future research were addressed in[28].
Also,a parallel reinforcement learning framework has also been applied to address the problems in visual perception and understanding[29].To draw an artificial vision system based on the observations from real scenes,the synthetic data can be used for feature analysis,object analysis and scene analysis.This novel research methodology,named parallel vision,was proposed for perception and understanding of complex scenes.
Furthermore,autonomous learning system for vehicle energy efficiency improvement in[30]can also be put into parallel reinforcement learning framework.First,a plug-in hybrid electric vehicle was imitated to construct the parallel system.Then,historical driving record for the real vehicle was collected to learn autonomously the optimal fuel use via a deep neural network and reinforcement learning.Finally,this trained policy can guide the real vehicle operations and improve control performance.A better understanding of the real vehicle can then be obtained and used to adjust the artificial system from these new experiences.
B.New Applications Using Parallel Reinforcement Learning Methods
Recently,we designed a driving cycles transformation based adaptive energy management system for a hybrid electric vehicle(HEV).There exist two major difficulties in the energy management problem of HEV.First,most of energy management strategies or predefined rules cannot adapt to changing driving conditions.Second,model-based approaches used in energy management require accurate vehicle models,which bring a considerable model parameter calibration cost.Hence,we apply parallel reinforcement learning framework into the energy management problem of HEV,as depicted in Fig.6.More precisely,the core idea of this methodology is bi-level.
The up-level characterizes how to transform driving cycles using transfer learning by considering the induced matrix norm(IMN).Specially,TPM of power demand are computed and IMN is employed as a critical criterion to identify the differences of TPMs and to determine the alteration of control strategy.The lower-level determines how to set the corresponding control strategies with the transferred driving cycle by using model-free reinforcement learning algorithm.In other words,we simulate the HEV as an artificial system to sample the possible energy management solutions,use transfer learning to make the computed strategies adaptive to real world driving conditions,and use reinforcement learning to generate the corresponding controls.Tests demonstrate that the proposed strategy exceeds the conventional reinforcement learning approach in both calculation speed and control performance.
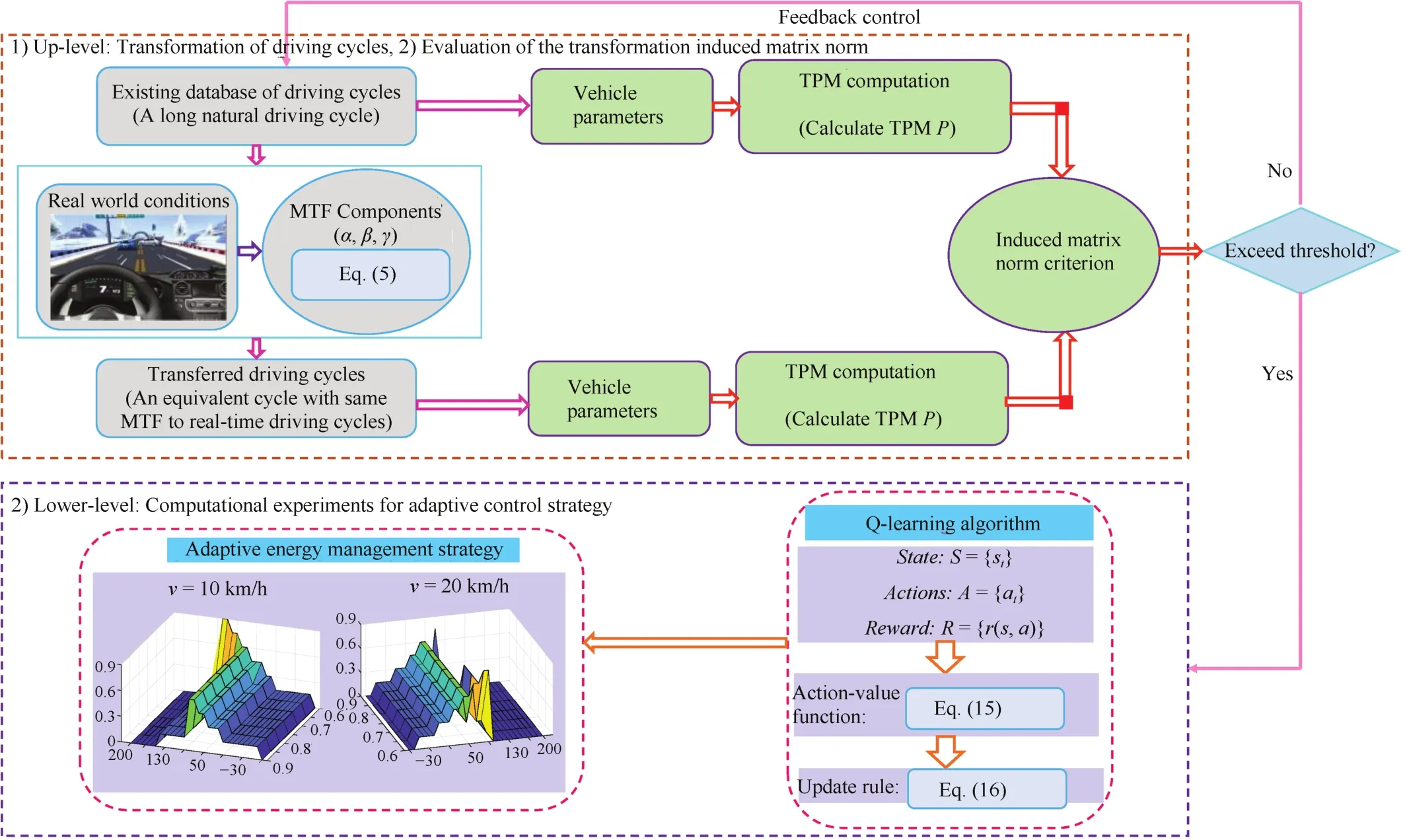
Fig.6.Parallel reinforcement learning for energy management of HEV.
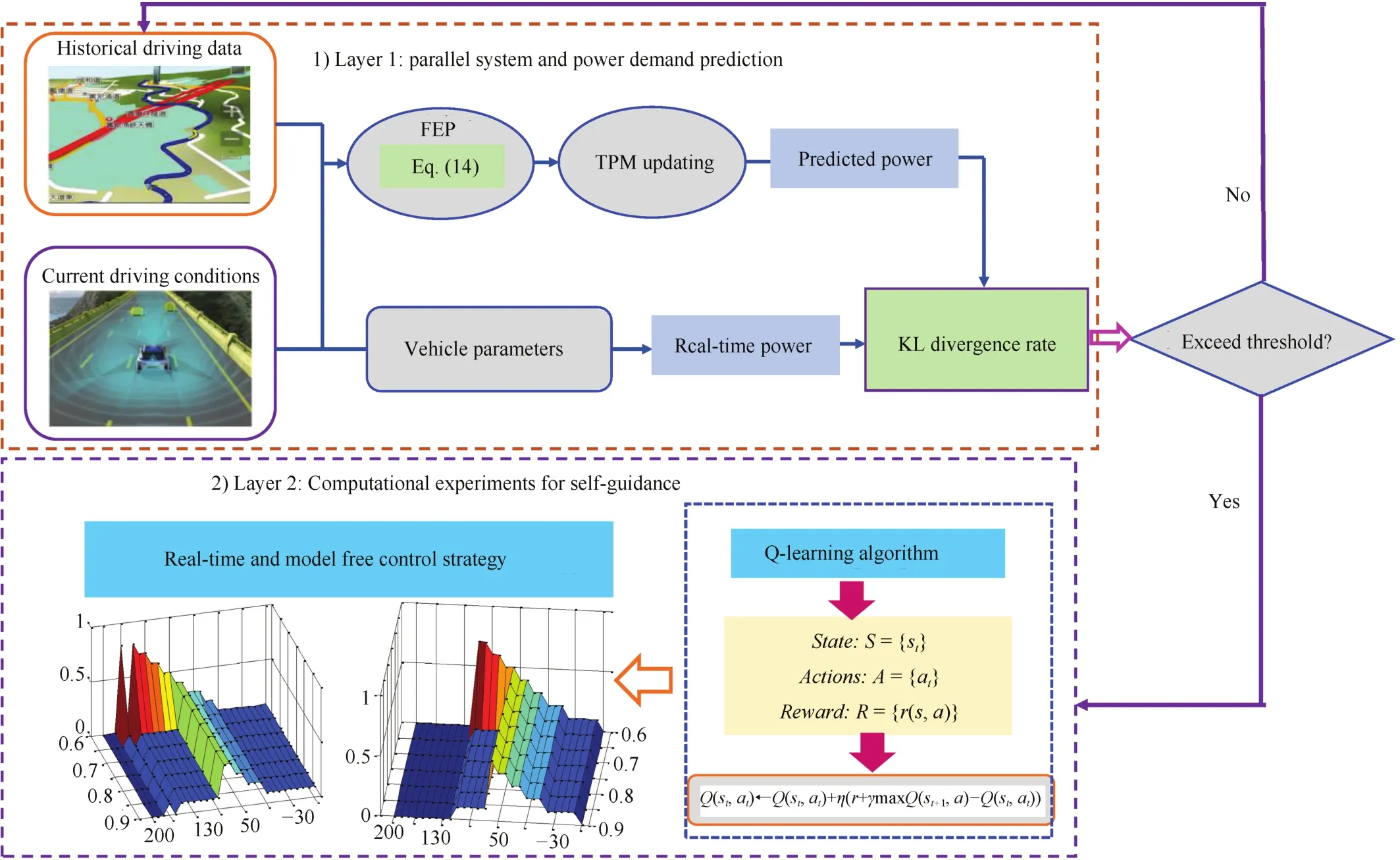
Fig.7.Parallel reinforcement learning for energy efficiency of HTV.
Furthermore,we construct an energy efficiency improvement system in parallel reinforcement learning framework for a hybrid tracked vehicle(HTV).Specifically,we combine the simulated artificial vehicle with real vehicle to constitute the parallel system,use predictive learning to realize power demand prediction for further self-guidance and use reinforcement learning for control policy calculation.This approach also includes two layers,see Fig.7 for a visualization of such idea.The first layer discusses how to accurately forecast the future power demand using FEP based on the MC theory.Kullback-Leibler(KL)divergence rate is employed to decide the differences of TPMs and updating of control strategy.The second layer computes the relevant control policy based on the predicted power demand and reinforcement learning technique.Finally,comparison shows that the proposed control policy is superior to the primary reinforcement learning approach in energy efficiency improvement and computational speed.
In the future,we plan to apply BiLSTM-DRN to process and train the large real vehicle data for optimal energy management strategy computation.The objective is to realize realtime control using the parallel reinforcement learning method in our self-made tracked vehicle.More importantly,we will apply parallel reinforcement learning framework into multimissions of automated vehicles[30],such as decision making,trajectory planning and so on.To address the existing disadvantages of traditional data-driven methods,we expect that parallel reinforcement learning can promote the development of machine learning.
IV.CONCLUSION
The general framework and case studies of parallel reinforcement learning for complex systems are introduced in this paper.The purpose is to build a closed loop of data and knowledge in the parallel system to guide the real system operation or improve the artificial system precision.Particularly,ACP approach is used to construct the parallel system that contains an artificial system and a real system.Transfer learning is utilized to achieve driving cycle transformation by mean of tractive force components.Predictive learning is applied to forecast the future power demand via fuzzy encoding predictor.To train data in the large action and state space,we introduce BiLSTM-DRN to approximate the action value function in reinforcement learning.
Data-driven models are usually viewed as a component irrelevant to the data in learning process,which results in the largescale exploration and observation-insufficiency problems.Furthermore,data in these models tend to be inadequate,and the general principle to organize these models remains absent.By combining parallel system,transfer learning,predictive learning,deep learning and reinforcement learning,we believe that parallel reinforcement learning can effectively address these problems and promote the development of machine learning.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Polyhedral Feasible Set Computation of MPC-Based Optimal Control Problems
- The Power Allocation Game on A Network:A Paradox
- Finite Frequency Fuzzy H∞Control for Uncertain Active Suspension Systems With Sensor Failure
- Analysis of the Caratheodory’s Theorem on Dynamical System Trajectories Under Numerical Uncertainty
- Modified Cuckoo Search Algorithm to Solve Economic Power Dispatch Optimization Problems
- Robust Leader-Following Output Regulation of Uncertain Multi-Agent Systems With Time-Varying Delay