基于卷积网络的车辆定位与细粒度分类算法
2018-07-31柳思健
柳思健
(武汉理工大学 现代汽车零部件技术湖北省重点实验室 汽车零部件技术湖北省协同创新中心,武汉 430070)
目前,交通卡口对车辆的甄别方式主要是车牌识别,它具有速度快、精度高的特点,但无法对伪造车牌、套牌等车辆进行有效的认证。车型识别作为智能交通领域的关键技术,能够与车牌识别产生良好的互补,因而受到国内外研究者的广泛关注。车型识别具体分为2个部分,即车辆的目标检测和对检测目标的分类。
近年来,目标检测领域取得了迅速的发展。2014年R-CNN[1]理论在PASCAL VOC数据库上提升了近20%的精度,开创了卷积神经网络[2]应用于目标检测的先河。此后的Fast R-CNN[3]和Faster R-CNN[4]在检测速度和精度上均有较大的提升。
图像识别分类是卷积神经网络的成功应用之一,而在车辆分类的任务上,则是预测出图像中车辆所属类别的置信度。借鉴深度学习在人脸识别中的成功应用[5],其在车型识别分类方面也有了一些研究成果,如采用一种5层网络进行3种车型(小车、客车、货车)的识别[6]。然而为了防止套牌现象的发生,仅对车辆外观进行粗略分类是远远不够的,还需要更为细粒度的分类。在此,研究了以车牌定位来构建推荐区域生成模块,并行2个深度卷积网络构建车辆定位与细粒度分类算法。
1 车辆定位与细粒度分类的快速识别算法
对于检测框架中推荐区域的生成,Fast R-CNN采用了Selective Search[7],但耗时较长,较难适用实时性较强的领域;Faster R-CNN采用全卷积的RPN网络生成推荐区域,计算量大,对运算设备的要求较高。与现有的方法相比较,文中所研究的车辆定位与细粒度分类的快速识别算法具有以下优势:
1)交通卡口中,图像的拍摄以地感线圈的感应为依据,车辆图像多为正面,包含车牌区域。车牌包含诸多利于检测的先验知识:颜色、形态、纵横比等,更加易于检测,算法的速度得到提升。使用车牌定位车辆然后进行检测,也比Selective Search,RPN等方法更具目的性;
2)采用2个并行的卷积网络可提升算法的性能。以Fast R-CNN和Faster R-CNN为例,网络具有区域微调和物体分类2个输出目标,在前向传播时,区域微调和分类信息是同时输出的,即分类的时候并没有使用微调后的选框。对于车辆分类而言,这将极大地降低识别后的精度。对此,文中采用检测网络与分类网络分别完成定位、分类的任务。此外,还将并行2个卷积网络的特征提取步骤,将空间金字塔池化策略引入分类网络,在兼容了选框调整的同时,极大地提升了算法的速度。
2 车辆定位与分类系统架构
所研究算法的整体架构如图1所示。
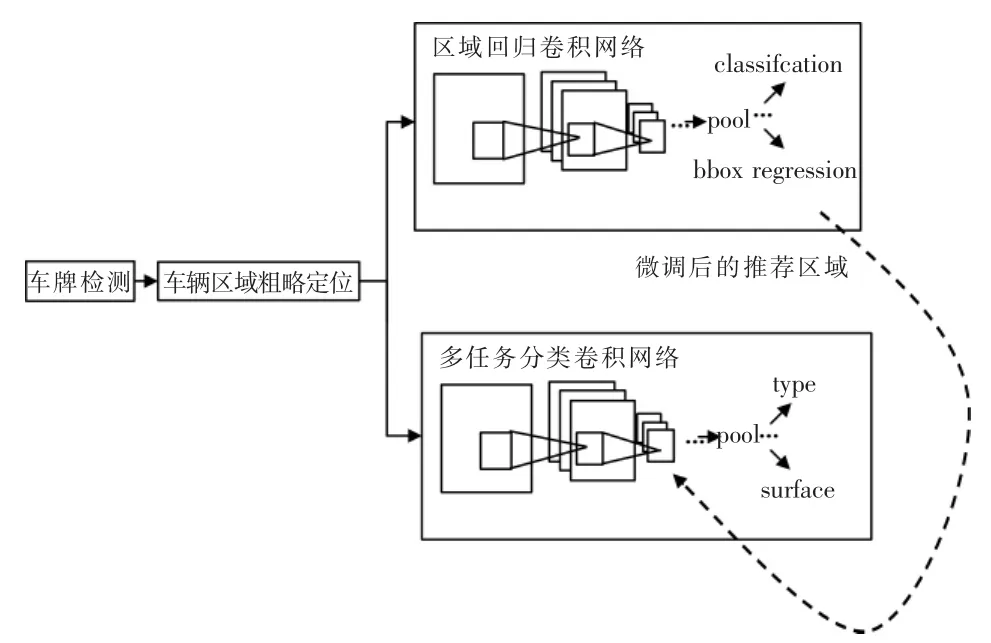
图1 算法整体架构Fig.1 Overall structure of algorithm
在车辆区域粗略定位阶段会生成2个区域,分别为裁剪区域和推荐区域。裁剪区域包含了推荐区域,从原图像上裁剪以后再送入2个卷积网络。
2.1 推荐区域的生成
文中采用开源库EasyPR构建车牌检测模块。EasyPR是一个在Github上开源的车牌识别项目,提供了基于边缘信息、颜色定位、文字特征这3种车牌检测方法。与EasyPR原算法不同的是,文中摒弃了其采用支持向量机算法进行车牌判断的步骤,仅仅采用文字特征定位和颜色区域定位并行的方法来进行车牌的检测。在此情况下,认定的非车牌区域可能会增多,但相对而言,漏检会有所减少,且速度会提升近2倍。检测效果如图2所示。

图2 2个可能的车牌区域Fig.2 Two possible license plate areas
然后,采用非极大值抑制[8]算法对这些检测出的区域进行处理,去除冗余选项。对于筛选后的某个区域,以图像的左上方为零点,设中心点坐标为C(x,y),其宽为w,高为h;分别定义4个方向上的缩放参数,形成裁剪区域,如图3所示。

图3 裁剪区域示意Fig.3 Cutting area diagram
由于交通卡口拍摄的图像可能包括大型货车,因此需要将缩放参数尽可能地放大。经过测试,取tw1=tw2=3,th1=16,th2=3,生成裁剪区域。 再在裁剪区域内,以坐标(w,h),(2tw2·w-w,2th2·h-h)为左上角和右下角生成推荐区域,若产生越界,则取越界边的边线为推荐区域的边线,如图4所示。

图4 裁剪区域和推荐区域Fig.4 Cutting area and recommended area
2.2 推荐区域的精细化
推荐的车辆区域并不十分精确。在此,采用Fast R-CNN中的边框回归 (bounding-box regression)的方法去学习一组对推荐区域微调的变换。
对于某个窗口框P(Px,Py,Pw,Ph),其中:(Px,Py)为该窗口中心区域的坐标;Pw,Ph分别为窗口的宽和高。 若要将P变换为窗口G(Gx,Gy,Gw,Gh),则需要一组变换d(dx,dy,dw,dh)来完成,即
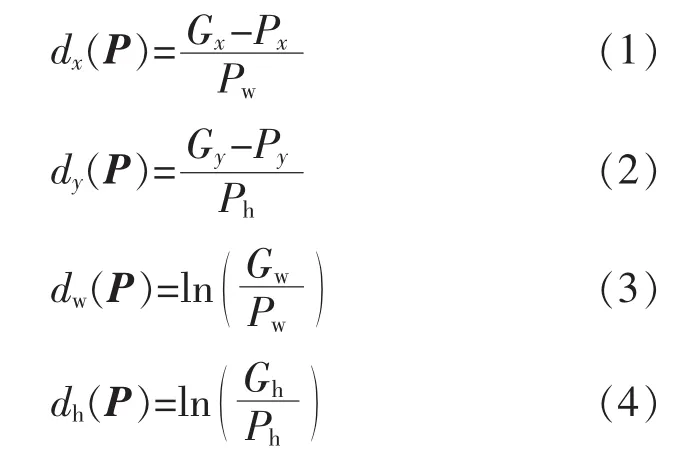
假定窗口P是给定的,就可以通过变换d得到窗口G,即
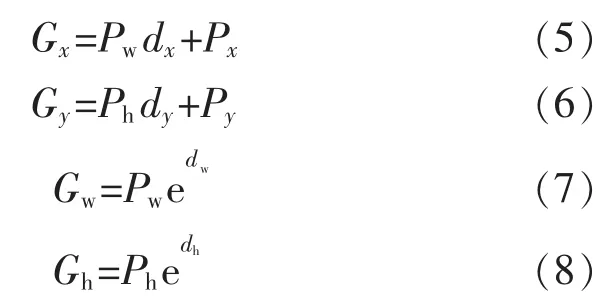
故研究的目标就是得到对应于每一个窗口框的一组变换,在卷积神经网络中,目标函数为
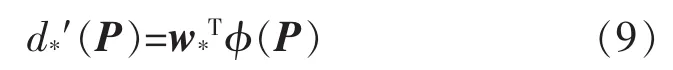
式中:φ(P)为窗口框的特征向量;w*为需要进行学习的一组参数;d*′(P)为得到的预测变换。学习目标为使预测变换d*′(P)的与真实的变换d*(P)差距最小,得到损失函数为
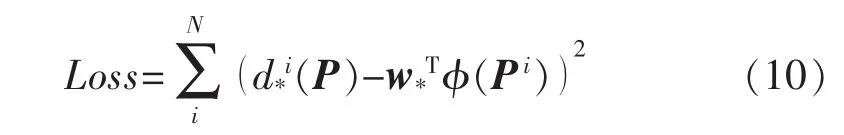
在测试时,可以直接采用推荐区域T得到变换,d*′(T)就可以依据式(5)~式(8)调整T,得到精细化后的选框T。
2.3 多标签分类网络构建
BIT-Vehicle DataSet[9]中,对于车辆有以下分支:Truck(货车)、Bus(公共汽车)、Sedan(小型轿车)、Microbus(小型客车)、MiniVan(小型货车)、SUV(运动型多用途汽车)。文中采用对于车辆外形的分支,并另为网络增添汽车品牌分类。
在卷积神经网络用于单个分类问题时,常用的计算损失的方法是Softmax函数与交叉熵代价函数的结合。给定数量为N,类别为m类的训练样本集,其数据为ri,标注li∈{1,2,…,t,…,m},假设全连接层输出的对第t个类别的输出结果为ft(ri),那么样本ri从属于该类别的概率为
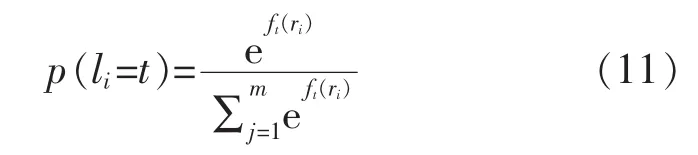
若样本ri的真实标注为li=t′,则需要使得p(li=t′)的值最大,即最小化-log(p(li=t′))的值。 对于样本中所有数据均做以上处理,就可以得到优化目标,即
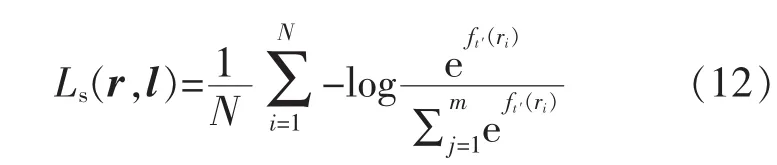
而假设对于样本ri,其具有2个标注li和vi,回溯到车型分类问题上,汽车品牌与车辆外形这2类信息互相没有影响,故可以认为li和vi是不相关的。则总的优化目标为
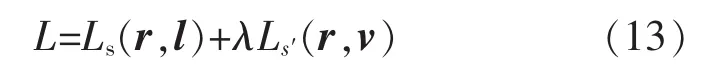
式中:λ为2种损失函数之间的权重。
为避免网络的参数过多,对于每一个损失层只单独设立1个全连接层,如图5所示。
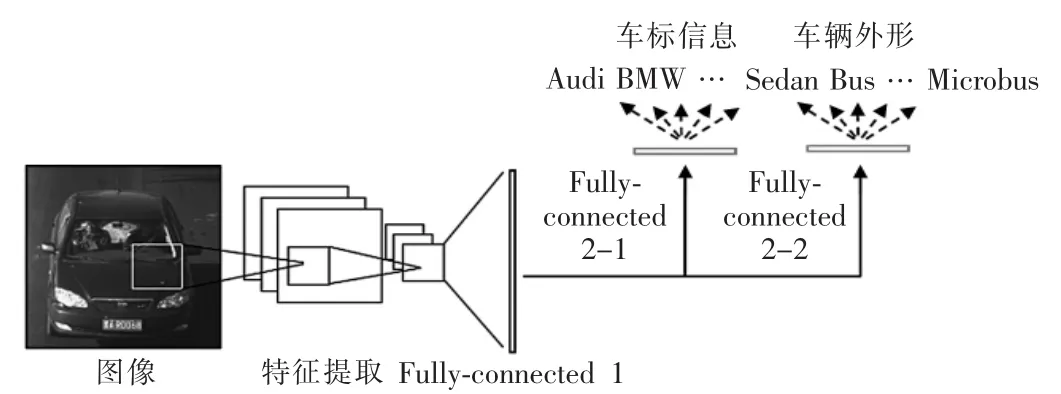
图5 多标签输出的分类网络Fig.5 Multi-label output classification network
2.4 分类网络中的可变尺度最大池化
微调后的选框区域尺度不一,无法与固定维度输入的全连接层相匹配。假设,全连接层的输入维度为d,则要求池化层输出的特征图的宽w和高h为

式中:c为特征图的个数。针对于不同的区域,需要将其池化为固定维度。文中在分类网络中采用可变尺度最大池化。 对于修正后的区域T(Tx,Ty,Tw,Th),将其映射到卷积网络最后一个卷积层输出的特征图上,映射公式为
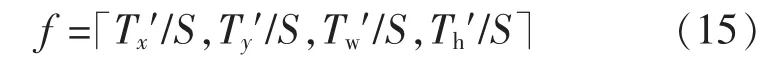
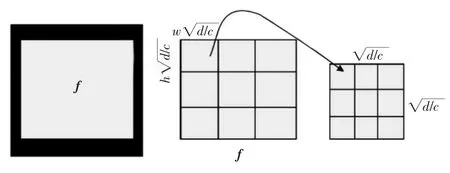
图6 可变尺度池化Fig.6 Variable scale pooling
3 卷积网络的训练
训练平台的硬件为CPU为i7-6700k,GPU为NVIDIA GTX 980,采用深度学习框架 Caffe[10]进行网络训练。为了加速网络的收敛,采用微调在Caffe Model Zoo上开源的参数文件(.caffemodel)的方法。由于区域回归网络中没有改变网络结构,只对输出类别进行了修改(车辆区域、背景区域),因此仅介绍分类网络的训练。
3.1 自建数据库ZnCar简介
由于在诸多车辆图像公开数据库中,如BITVehicle Dataset,Standford Car Dataset,均未包含汽车品牌与车辆外形的多标签数据,因此文中自建了图像数据库ZnCar。ZnCar是车辆图像的多标签数据库,总共包括40种主流汽车品牌,5种车辆外形(Truck,Sedan,Microbus,MiniVan,SUV)在内的共4928张车辆图像,部分样本如图7所示。

图7 ZnCar中的部分实例Fig.7 Some examples in ZnCar
3.2 多标签分类网络的训练
采用ZnCar中的2464张图片作为训练集,其他的作为测试集,采用AlexNet[11]结构搭建分类网络。对网络结构进行的修改见表1。
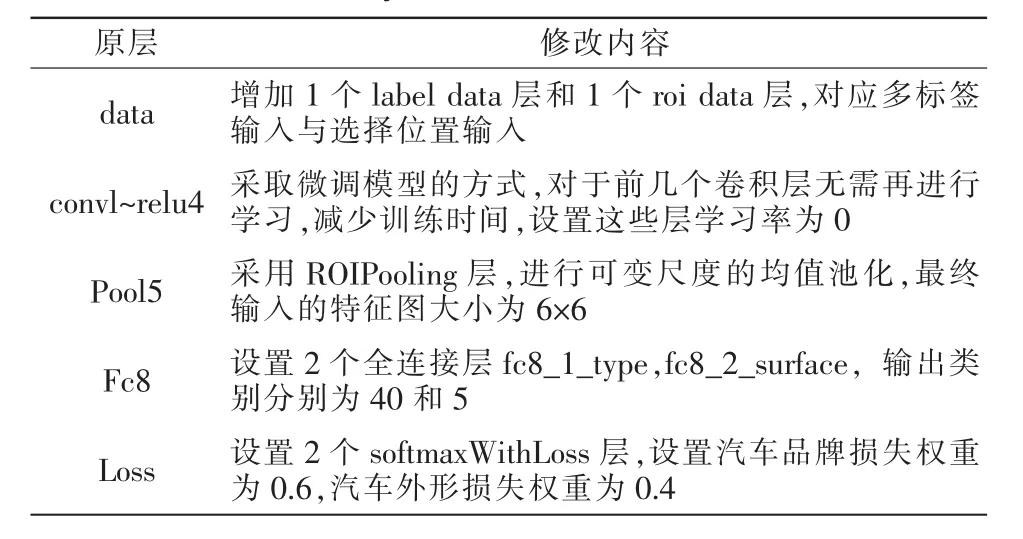
表1 修改AlexNet网络结构Tab.1 Modify AlexNet network structure
分别微调AlexNet在ImageNet上训练的分类模型和在PASCAL VOC上训练的检测模型。对于ROIPooling层与2个fc8层,适当加大学习率,加速网络收敛。训练结果如图8所示。

图8 在ZnCar上的训练结果Fig.8 Training results on ZnCar
如图所示,浅色曲线为ImageNet分类模型的微调;深色曲线为PASCAL VOC检测模型的微调;Type和Surface分别为车的品牌、车辆外形;Loss为损失曲线。分类模型的正确率最终达到92.17%和94.76%;检测模型的正确率最终达到88.96%和94.69%。可以得出,对于类别较多的精细化分类,检测模型在浅层的参数相较于分类模型具有一定的差异,将区域精细与分类分离有利于正确率的提升。
4 算法的测试
4.1 算法的运行速度
文中搭建了算法的CPU版本和GPU版本。表2反映了算法处理单张图像的平均时间。

表2 算法的运行时间Tab.2 Algorithm running time
需要注意的是,区域回归网络的前向传播和分类网络传播至ROIPooling层这2个步骤是并行的,在对选框数组进行微调后才继续让分类网络传播。GPU版本的算法速度约为13 f/s,具备实时性;CPU版本的算法稍逊,为4 f/s。采用Selective Search和RPN网络对1张图片进行候选区域的推荐,分别耗时CPU为0.9 s和GPU为0.21 s,时间远远大于车牌检测和生成推荐区域步骤。
4.2 在交通卡口实拍图像上的测试
文中收集了492张交通卡口的实拍图像,部分测试效果如图 9。 如图所示,图 9(a)(b)(e)(f)中的外侧线框表示裁剪区域,内侧线框表示推荐区域;图 9(c)(d)(g)(h)中的线框代表微调后的选框。 汽车品牌的分类正确率达到85.6%,车辆外形的分类正确率为93.9%。造成汽车品牌分类偏低的原因主要有:①部分检测车辆离摄像头的距离较远,造成分类错误;②交通卡口的实拍图像的收集难度较大,导致模型训练未采用该环境下的图像,一定程度上降低了识别率。


图9 交通卡口实拍图像测试效果Fig.9 Traffic jams real shot image test results
5 结语
提出了一种适用于交通卡口的快速车辆检测和识别算法,通过车牌来产生推荐车辆区域,采用两个并行的卷积网络来微调选框,输出汽车品牌和车辆外形。该算法相较于Fast R-CNN与Faster R-CNN具有一定的速度优势,在交通卡口实拍图像上的测试结果证实了其有效性。由于训练数据集等原因,算法对于汽车品牌的分类正确率稍低,今后将在该问题上展开更为深入的研究工作。今后将在如何改进分类策略方面继续进行研究。
