面向试卷累分系统的数字图像处理技术∗
2018-07-31张方舟
张方舟 袁 野
(东北石油大学计算机与信息技术学院 大庆 163318)
1 引言
国民教育行业中,为了减轻教职工们的负担,提高他们的工作效率,越来越多的应用软件、实用性系统被应用于日常的学习工作中[1~3]。在现有的评卷模式中,尽管有读卡机的存在,但主观题无法被彻底摒弃,评卷人员的任务仍旧繁重,不仅要对答案的正确性及合理性做出评判,还要对最后的分数进行汇总,且汇总分数占用了大量的时间,无形中降低了评卷人员的工作效率[4]。而累分系统的提出可以有效解决人工分数汇总的问题[5],相对于人工进行的分数汇总来说,累分系统的正确率及可靠性更高,速度更快。
本研究基于图像处理的累分系统主要是指对采集到的图片信息依次做降噪处理、利用霍夫变换提取直线、对偏斜直线按照偏转角度做旋转校正得到水平直线、搜寻红色数字所在具体位置并对分数实行分割、最后分数累加。该系统对分数实行分割后,采用人工神经网络算法对手写数字进行字符识别,并通过错误回馈法得到更高准确率的字符识别结果。
2 数字图像处理
2.1 霍夫变换
霍夫变换是一种使用表决原理的参数估计技术[6],主要用来从原始图像中分离出某种具有统一特征的几何形状。其将原始图像中的直线或曲线上的所有点集投影到参数空间中所有直线的相交点上,在参数空间里对各个分割出来的累加器单元内存在的点进行简单的累加运算,寻找各个累加器的峰值[7],而这些峰值所存在的参数空间中累加器单元所对应的原始图像中的位置便是直线或曲线的存在之处,由此可以检测出图像中的直线或曲线。
1)霍夫变换检测直线
依据点线的对偶特性[8],输入空间中每一个点对应输出空间中的一条直线,当同一条直线上的不同点映射到输出空间上有共同的交点,在x-y空间上有 (xi,yi),(xj,yj)两点确定一条直线,由此申请一个累加器A(q,k),用一个二维数组来表示记录q-k空间直线经过该点的次数,初始记录为0。对于点(xi,yi),映射到参数q-k空间为一条直线方程:

将对直线经过的所有的点对应为累加器空间:

同理,对于点(xj,yj)得到直线方程:

累加器加1,此时两条直线的交点 (q′,k′)的累加器,q′值为就为两点确定的直线的截距,k′为斜率。为了增加精确性,将直线 y=kx+q上所有的点都进行Hough映射[9],得到映射空间k-q中一系列的直线,并对累加器投票,这些直线的交点的票数一定是局部最高的。此时设定一个阈值T,可以认为累加器值大于T的都是直线的参数。具体的输入空间直线与对应输出空间直线分别如图1和图2所示。

图1 输入空间直线

图2 对应输出空间直线
2)霍夫变换检测曲线
对于曲线视为圆上的一段弧,若圆的方程(x-a)2+(y-b)2=r2,因为有3个参数,如果要映射到参数空间会是三维的,无论是计算速度还是逻辑上难度都增加了很多。但是很多情况下,可以认为待检测目标的半径是固定的或者是在一定的范围内的,这样就可以将圆的方程也映射到只有a、b两个参数的二维空间。例如点对应的输入空间a-b的参数方程为

由方程可以知道,在a-b空间该曲线是一个半径为r的圆,因此在半径已知的情况下,圆的输入空间与输出空间是一个点圆的关系。同样申请一个累加器空间 A(a,b,r),则圆上所有点对应的累加器值:

当输入空间多个点映射到输出空间时可以发现,这些圆也都有一个共同的交点,这个交点即为输入空间中图形圆心的坐标,如图3所示。
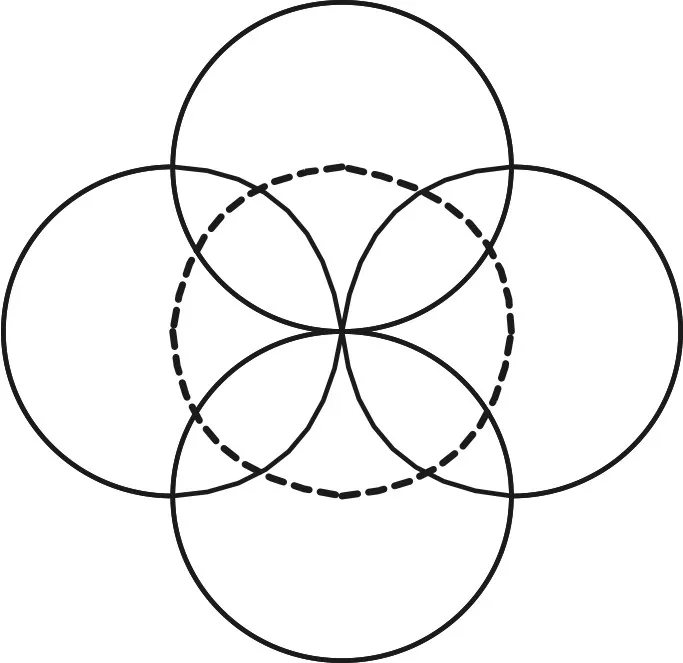
图3 多点映射到输出空间
反应到累加器中,A(a',b',r')的值为局部最高,如果有多个圆我们可以同样设定一个阈值T,对于A(a,b,r)内所有大于T的点都可以认为是半径为r,圆心为(a,b)的圆。
2.2 红色字迹搜寻
HSV彩色模型是从CIE三维颜色空间演变而来的[10]。在HSV彩色模型中,每一种颜色都是由色调(H),饱和度(S)和色明度(V)所表示的。如图4所示的六棱锥立体示意图即是它的三维空间表示图。
在该模型中,六棱锥的底面位于坐标系的水平面上,该平面上包括了模型的两个重要参数,一个是色调一个是饱和度。色调是围绕着坐标系的纵轴旋转变化的,图上标示出了六个标准色的位置,相邻纯色之间相隔60°。饱和度是沿着水平方向变化的,最低的饱和度位于坐标系的原点位置。色明度是位于坐标系的纵轴上的,沿垂直方向不断变化。

图4 六棱锥立体示意图
从RGB色彩空间到HSV色彩空间通过非线性变换,如图4所示,假设椭圆的中心坐标点为“白”,H轴在椭圆上的焦点与“白”之间的距离为半径r,其中“黄”与“白”之间为最大半径 rmax,“绿”与“白”之间为最小半径rmin,对于色调H控制着红、黄、绿、青和品红的色差区域,从H轴逆时针旋转过程中距离最大半径rmax和最小半径rmin的距离分别设为g和h,则每一种颜色在色调H上的变换依据“黄”与“白”之间最大半径rmax与g、b和r共同控制,具体的变换形式为

对于饱和度S的变换则可仅依据最大半径rmax控制,具体变换形式如下:

对于色明度V即为“黄”与“白”之间最大半径rmax:

3 累分系统的实现
3.1 实现步骤
本文中所研究的累分系统的实现步骤如下:
Step.1:图像输入:将要待处理照片传入计算机后载入识别系统;
Step.2:图像预处理:对图像进行图像转换、图像边缘检测、去噪、直线提取和图像旋转等;
Step.3:区域定位与分割:从预处理后的登分区域图像中搜寻到手写体分数所在的大致位置,对图像形态学去噪然后分割出试卷中分数所在的矩形区域;
Step.4:字符分割:从分数所在的矩形区域中分离出各个题目的分数,再对每个分数进行单个字符的分离;
Step.5:单字符识别:该步骤是在上一步骤所得中间结果的基础上进行的,对于分割出的每一个字符图像分析并提取特征,利用建立好的神经网络不断学习训练,确定字符的类别;
Step.6:分数汇总:对识别出的字符在分数中所占用的权值进行判断,确定它是处于十位还是个位,然后计算各个题目的分数,再将所有题目分数取和,输出结果。
3.2 图像预处理
图像预处理是本文实验的第一个环节,起着至关重要的作用。原始图像中不仅仅有图像的轮廓、边缘信息,更有图像的颜色信息,而这些信息都将占用一定量的存储空间,这就导致了系统解决问题时执行速度在一定程度上的降低,如图像输入为图5所示。

图5 图像输入
图像预处理是对图像进行分析之前所必须做的准备工作,这样能够使图像中所包含的各种信息得到简化,使我们更加清晰、直接地了解图像中的客体特征。图像的边缘指的是图像中局部亮度变化相对来说较明显的部分,它可以充分体现图像的纹理和形状等基本特征。为了方便之后利用霍夫变换这一方法来提取图像中的直线从而完成我们所需目标位置的确定与校正,这里先对图像进行边缘检测。具体步骤如下:
Step.1:对图像进行灰度转换,把原始图像变成二值图像;
Step.2:采用canny算子对图像进行边缘检测并在此过程中去噪[11];
Step.3:利用霍夫变换提取图像中的直线;
Step.4:对倾斜图像进行适当角度的调整校正。
具体的边缘检测和图像旋转矫正如图6和图7所示。

图6 边缘检测

图7 图像旋转矫正
3.3 区域定位与分割
分数区域的定位与分割是本文实验中累分系统实现的重要步骤之一,随着这一步骤的实现,我们可以确定校正之后的图像中分数区域的具体位置,并准确地切分出手写体分数所在的区域子图。这一过程中得到的图像结果是用于之后步骤的,因此分割的准确率直接同整个累分系统最终的识别率密切相关。
1)分数区域的定位
为了完成区域的成功定位与分割,观察图像的基本特征,教师评判卷子时均采用红色签字笔,分数区域的颜色属性与周边区域有明显的不同,利用这一特征很方便对分数区域的定位。采用彩色分割的方法,首先将图像由RGB转换为HSV[12],同时得到图像的H、S、V三个分量,查阅资料得到红色的三个基本分量的大致范围,对于从HSV图像中得到的三个分量同时进行限定,便可定位出分数区域的位置,区域定位如图8所示。

图8 区域定位
2)分数区域的分割
对分数区域进行分割,找到分数区域所在位置的X和Y方向上的值,并记录其中的最小值和最大值,这样便可以个根据这四个数据勾画出分数所在的矩形区域,将其分割出来。由于图像的质量及清晰度等问题,在这里应用到了由开启和闭合这两个基本运算构成的所谓的形态学上的噪声滤波器[13],去除了对象中不相关的小对象,分数区域分割效果如图9所示。

图9 分数区域分割效果图
3.4 字符分割
对单字符进行分割这一环节在累分系统的实现过程中发挥着承上启下的作用。实现这一步骤的基本思想是采用矩阵投影的方式确定X方向上的值对应的位置是否有分数字符像素点的存在。以二维矩阵的形式存放在计算机中,矩阵中的每一个元素非0即1,对这个矩阵进行投影可以得到一个一维向量,这个一维向量中存放了非0元素,也存放了值为0的元素,其中0元素所存在的位置说明图像中相对应的位置没有字符的存在,这样可以根据0和非0元素的位置来分割字符。对于此实验中的图像,各个题目的分值不同,存在个位数的题目,同样存在两位数的题目,因此不仅需要将字符分割开来,同样需要将各个题目的分数分割开来。在此次实验中,首先将各个题目的分数分割开来,然后再进行字符的分割。为了区分题目分数的分割与单个字符的分割,实验中定义了一个一维数组来记录图像中存在的所有字符之间的间距,再对数组里保存的这些间距值求平均值,则对于大于所求平均值的间距值我们认定它就是图像中各个题目之间的间隔,而对于小于等于平均值的间距值我们认为是单个题目中各个单字符之间的间距,对应的字符分割效果如图10所示。

图10 字符分割
3.5 字符识别
在整个系统的研究、实现过程中,对于字符进行识别是非常重要的一个环节,它决定了最终结果的正确与否,我们可以利用的方法有很多种。而最常见的方法有利用模板匹配算法的实现方法和利用人工神经网络算法的实现方式[14]。对核分系统进行综合分析,由于试卷中分数字符均采用手写的方式,因此认为模式匹配算法的成功率应该不会很高,为了保证字符识别和最终结果的准确率,最终选择了自编码神经网络重构的算法,该算法是基于BP神经网络算法的。
实验中采用的自编码神经网络算法是利用分数字符分割后的单个字符的图像和它的Gabor特征作为网络的输入节点进行单个字符识别的实验[15],我们对前面基础上得到的每个单个字符图像构造一个自编码神经网络,利用建立好的网络训练样本对各个图像进行重构训练学习,并且根据训练学习之后得到的网络权重值重构出训练样本集中的各个字符的图像或特征。最后,输入我们之前已经得到的图像到网络中,计算样本与最终结果这二者间的相关值。比较各个样本字符类别与输入字符图像间相关数值的大小,其中数值最大的相关值对应的识别类型就是我们最终想要得到的结果。
3.6 分数汇总
分数汇总是整个实验的最后一步。这一过程中主要任务是计算各个题目的真实分值,最后做加法运算,输出结果。输出的分数汇总展示如图11所示。

图11 分数汇总展示
4 结语
本文通过对累分系统的研究并结合累分系统最终的实现过程,很大程度上减少了教师工作量。本文中累分系统的实现准确率较高,得益于选择了合理的图像处理方法,如对分割出的字符的大小、位置的归一化等方法。并通过改进神经网络,选择合适的参数,进一步提高分数计算的准确率。同时实验程序在满足一定要求下相对来说比较简洁,程序运行效率高。
