基于MapReduce的垂直FP-growth挖掘算法研究∗
2018-07-31王嵘冰徐红艳魏莲莲
王嵘冰 徐红艳 魏莲莲
(辽宁大学信息学院 沈阳 110036)
1 引言
随着大数据时代的来临,在科学计算、商业计算等诸多领域蕴含着海量数据[1]。从这些海量数据中挖掘出其潜在价值已经成为当今学术界关注的热点。在大数据处理方面,Google提出的Ma⁃pReduce框架[2]以其适用于大数据计算而成为大数据环境的关键计算模型。与常规分布式算法相比较,MapReduce的优势如下:
1)并行化程度高:在大数据处理过程中使用集群技术,以达到常规分布式算法无法实现的高效率。
2)经济性:普通的PC机可作为集群节点用于处理数据。
3)容错性好:MapReduce使用多副本冗余机制。
4)扩展性强:可用于PB级数据的处理,而且可以根据实际需要来扩展集群节点。
因此,将分布式数据挖掘技术与MapReduce模式相融合是大数据挖掘的主要研究方向[3]。
关联规则挖掘算法FP-growth,其思想是分而治之[4],相较于需多次扫描数据库、产生大量候选集的Apriori算法[5],在分布式环境中使用更广泛,但弊端是局部站点通信量较大。Chen等[6]为解决此问题,采用垂直模式树存储数据,提出了高性能并行算法HPFP,克服了原FP-growth算法通信大的弊端。徐杰等[7]采用了数据并行和任务并行来提高挖掘效率,提出了基于垂直FP树的并行频繁项集挖掘算法。冯勇等[8]提出分布关联规则挖掘算法VFP-LBDM,通过提高站点的负载均衡程度来缩小节点执行时间差异,提高了整体的执行效率。以上算法在分布式环境中一定程度上提高了算法效率,但在大数据环境中,并行化程度远不及MapRe⁃duce模式。
针对分布式垂直FP-growth算法在大数据环境下CPU、内存、I/O开销大和计算效率低的问题,本文提出基于MapReduce的垂直FP-growth挖掘算法(Vertical FP-growth Mining Algorithm Based on Ma⁃pReduce,MR-VFP),通过将分布式垂直FP-growth算法与MapReduce模式相融合,实现高度并行化计算以减少硬件资源的消耗。
2 MR-VFP算法框架
2.1 算法思想
垂直FP-growth算法是一个基于全局树结构的关联规则算法[11],它不仅继承了FP-growth算法分而治之的优点,同时又具有以垂直压缩树结构减少局部合并过程通信消费的优势[12]。在每次迭代过程中,需要对每个局部事务数据项做统计。在数据量较大的环境中,节点能力更是有限,无法承担计算大规模数据的任务。MapReduce模型是典型的IPSS计算抽象[13],具有高度并行化计算集群上大规模数据的特点,而垂直FP-growth算法挖掘的事务数据库中的每条记录都是相互独立的,因此可以利用MapReduce模型将事务数据库分割成若干块,Map阶段对每个事务块进行预处理,然后shuffle根据项的不同执行分组,combine阶段局部合并相同项的记录,Reduce阶段经全局合并输出最终结果,形成全局频繁项集和关联规则。MapReduce模型通过并行化集群计算,使挖掘效率得到极大提高。综上分析,本文提出了一种基于MapReduce的垂直FP-growth算法——MR-VFP算法。
2.2 算法工作机理
MR-VFP算法分为数据划分、预剪枝、VFP-tree序列化、生成全局频繁树四个部分。
1)数据划分,频繁一项集生成。该步骤的主要任务是将事务数据划分到各个处理机上。各站点并行MapReduce操作,计算出频繁项,其过程如图1。

图1 MapReduce处理数据项过程
在数据划分阶段,局部站点执行map操作并行挖掘局部数据库,统计出局部频繁项,以<itemid,itemcount>格式输出,然后reduce操作合并具有相同itemid的项,得出全局频繁项。
2)预剪枝。中心站点的预剪枝将根据各局部节点返回的频繁项集进行。各站点预先删除父节点为非频繁项的分支,不再收集该项的支持数信息,然后构造局部垂直模式树,从而有效减少通信量。
3)VFP-tree序列化。对局部垂直模式树使用深度优先遍历树,每个节点的输出格式为:项与该项所对应的计数。节点的输出分为以下三种情况:(1)该节点有子节点输出“-”;(2)没有子节点有兄弟节点输出“|”;(3)没有兄弟节点输出“+”,并返回该节点的上一层继续扫描。用符号“-”“|”“+”表示树节点之间的关系,以减少站点间的通信开销。
4)生成全局频繁树。本文选取的规则只由根节点项出发而生成以避免规则冗余。在各局部站点上执行MapReduce操作,各站点按照任务分配表,将生成的规则发送给相应站点,以<itemid,itemseq>格式将以Ii开头的序列合并到指定的站点,生成全局频繁模式树,最终输出全局频繁森林,其过程如图2。

图2 MapReduce处理局部频繁树序列过程
3 MR-VFP算法描述与效率分析
3.1 算法描述
MR-VFP算法按照MapReduce框架的结构,划分为频繁项集构建算法、全局频繁模式树构建算法两部分。
算法1.MapReduce框架下频繁项集构建算法
输入:数据集D
输出:全局频繁项集
Begin
Step1:m个mappers并行地读取输入的数据切片,对map函数读取的某项itemid,依次进行下述操作:
IF(项item不为空)
则累计项item出现的次数,输出<itemid,temcount>键值对,其中,itemid 指不同的itemcount为常量;ELSE忽略此对象
Step2:所有key为相同itemid的值集将被一个reducer接收,并由reduce函数对itemcount值集进行累加,形成一个关于某项的局部支持数;
按照下面的步骤构建全局项集:
Step3:m个mappers采用并行的方式将输入的数据切片读入,统计map函数读取的每个项itemid,输出键值对<itemid,value<itemid,itemcount>>;
Step4:r个reducers将所有划分到该reducer分区的对象子集接收并执行下面的操作步骤:1:将对象子集中每个元组itemid插入到列表L中;2:对列表L按itemcount值进行排序,形成全局项集;END
算法2.MapReduce框架下全局频繁模式树构建算法
输入:局部树的序列
输出:全局频繁模式森林
Begin
Step1:m个mappers并行地读取输入的局部树序列,对map函数读取的某项itemid,依次进行下述操作:
IF(项item不为空)
则输出<itemid,itemseq>键值对,其中,itemid指
同的项,itemseq为以itemid为根节点的局部树;
ELSE忽略此对象
Step2:一个reducer接收所有key为相同itemid的序列。reduce函数对itemseq进行合并,形成一个关于某项的频繁模式树;
按照下述操作步骤构建全局频繁模式森林:
Step3:m个mappers将输入的数据切片并行读取,统计map函数读取的每个项itemid,输出键值对<itemid,value<itemid,itemseq>>;
Step4:r个reducers接收所有划分到该reducer分区的对象子集并执行下属操作步骤:
1:将对象子集中每个频繁模式树进行合并,形成全局频繁模式树;
2:对频繁树按根节点itemcount进行排序,形成全局频繁模式森林;
END
3.2 算法时间复杂度分析
本算法开销主要包括:统计项的支持数从而得到每个项的全局支持数,以及在局部树合并成全局频繁模式树的两个过程。如果总共有m1条事务记录,平均每条记录包含n1个数据项,参与计算的节点为k个,每个节点上可以同时处理 p个Map、Re⁃duce。整个计算频繁项集的过程需要t1次迭代达到全局结果,则数据划分阶段,时间复杂度为同理,在全局频繁森林生成阶段,复,其中n2指数据项个数,每个数据项平均有m2个局部树,迭代次数为t2。由此可知,当整个集群越大,一次所能处理的Map和Reduce数越多,该算法的时间复杂度就越低、效率越高。
4 实验与对比分析
4.1 实验环境
Apache的Hadoop是MapReduce的开源实现。本文实验采用Hadoop平台0.20.2,每个节点上可并行运行的Mapper数和Reducer数设为5,其它采用默认设置。
为了进行对比实验,本文使用文献13中使用的环境:Hadoop集群包括1台主控节点和7个计算节点。每个节点配置为2quad-core 2.4GHZ CPU,16GB内存和167GB的本地存储磁盘,操作系统为Red Hat EnterpriseLinux 5.5,节点间通过 10-Giga⁃bit Infiniband网络互联。
4.2 算法的效率对比
为验证本文所提算法的性能,选取目前在垂直频繁树挖掘算法中应用较为广泛的两种算法作为对比:并行频繁项集挖掘算法DVFP算法采用垂直频繁树结构,通过计算并行和通信并行,在分布式环境中挖掘效率较高;基于垂直频繁模式树带有负载均衡的挖掘算法VFP-LBDM算法是改进的垂直挖掘算法,根据节点的CPU、内存、带宽资源进行挖掘任务划分,从负载均衡的角度提高运行效率。本文对此两种算法重新进行了实现,在本文实验环境下与本文所提算法进行实验对比,实验数据集为UCI的 Poker Hand[14]。
1)不同支持度下执行时间的对比。
三个算法分别计算4000000条记录。支持度小时,例如支持度为5%时,预剪去的非频繁树少,全局频繁项集较大,因此每个算法的执行时间比较多;随着支持度变大,频繁项集变小,挖掘速率会加快。MR-VFP算法由于并行化程度高,因此整体执行效率比较高,三种算法执行时间的对比如图3所示。

图3 三种算法在不同支持度下执行时间的对比
2)不同数据量下执行时间的对比。
采用数据复制的方法,将数据集扩大至200MB、400MB、600MB、800MB、1000MB,在节点数为16的条件下进行实验。随着数据规模增大,MR-VFP算法的MapReduce模式优势越明显。三种算法执行时间的对比如图4所示。
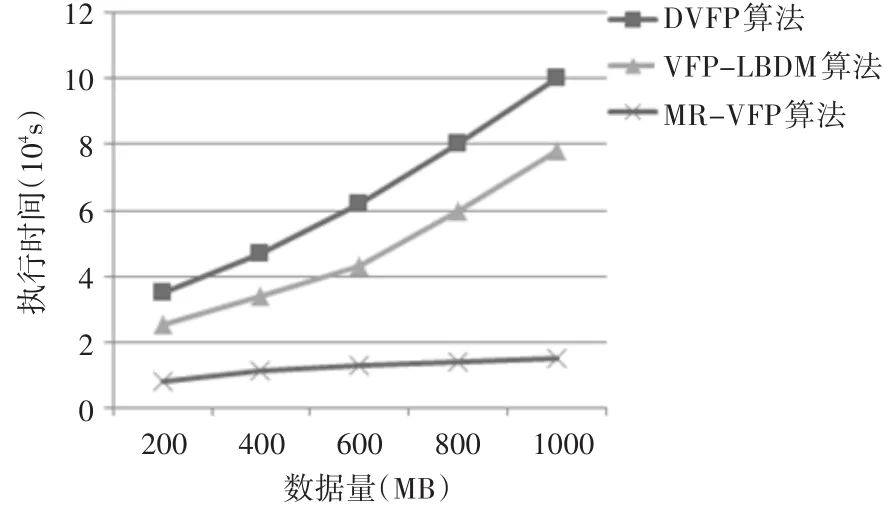
图4 三种算法在不同数据量下执行时间的对比
3)并行化水平对比
本文使用加速比作为体现算法并行化水平的指标。随着节点数的增加,MR-VFP算法在时间的减少上具有很好的优势,从而说明本算法具有高效并行性。三种算法并行化水平的对比如图5所示。
4)可扩展性对比
总数据量固定的情况下,随着节点数的增加,局部节点的任务量减少,局部节点的有效功率会减少(但因节点数增多,整体的效率是升高的),所以节点平均效率曲线呈下降趋势。MR-VFP算法是基于MapReduce模式,节点间呈串行和并行协同有序运行,因此节点平均效率要比另两种算法的节点无序运行效率高。在较大数据集上,MR-VFP算法的节点平均效率曲线较为平滑,不会因节点增加而使性能降低得过快。因此,本文所提算法对于集群计算具有良好的可扩展性,三种算法可扩展性的对比如图6所示。

图6 三种算法节点平均效率对比
5 结语
大数据环境下,为使传统数据挖掘算法发挥功效,本文提出一种基于MapReduce的垂直FP-growth挖掘算法。该算法先用Map函数对事务数据库数据项进行解析分块;然后用Reduce函数计算频繁项的支持度和合并全局频繁树,从而并行化垂直FP-growth算法中间迭代过程;最后通过计算全局频繁项,得到准确的频繁项集和关联规则。经实验证明,所提算法在大数据处理方面不仅保持原有垂直FP-growth算法挖掘准确性,而且具有较高的运行效率和较好的集群性能。
