基于Hadoop高校共享云平台实现方法与性能测试*
2018-07-26许景贤郭建宏
许景贤 郭建宏
(1泉州师范学院;2陈守仁工商信息学院 福建泉州 362000)
教育信息化十年发展规划(2011-2020年)中指出,利用先进网络和信息技术,整合资源,构建先进、高效、共享的高等教育信息基础设施,开发整合各类优质教育教学资源,建立高等教育资源共建共享机制[1]。探索建设高校优质的共享数字资源公共服务平台,鼓励高校建设各类教育优质的共享数字资源库[2]。云平台给高校的教育资源共享提供了相关的技术支持,由几十万台乃至百万台以上的服务器组成的计算机网络,能够让高校学生很容易地得到更多、更丰富的资源[3]。教育部计划在2020年以前,建设2000门左右的优质网络课程和相关教学资源的共享云平台,将对全国所有高校的网络基础设施进行整合,努力建设一个共享的和资源开放型的云平台[4]。
目前,云平台的解决方案有很多,Hadoop是最实用和最经济的一个[5]。Hadoop是Apache基金会的一个开源项目,它已经积累了大量用户,它在业界也得到了广泛的认可。很多知名企业都将Hadoop应用于它们自己的商业领域,这些知名企业包含了阿里巴巴、腾讯等[6]。Hadoop作为云计算技术的一种实现方法,允许用户在Hadoop框架之上实现自己的应用逻辑。云计算的目的之一,是以尽可能低的开销提供高可用性的计算机资源[7]。Hadoop 能够处理数千个计算机节点和 巨大量的数据,可以自动地处理作业调度和负载平衡,因此,它是实现云计算的完美工具。Hadoop具有成本低、安全性高等优点,因此研究Hadoop平台的实现方法以及测试平台性能是非常有意义[8]。文章首先研究Hadoop平台在虚拟机上的实现,然后进行Hadoop平台的基准测试,最后对测试结果进行分析。文章采用虚拟环境下搭建云平台,这种搭建方式有很多优点,如节省资金和能够测试平台的性能。
1 Hadoop 高校共享云平台实现方法
介绍在Linux 操作系统环境下安装和配置 Hadoop 的方法,Linux操作系统版本是Centos 6.5, Java版本是1.7, Hadoop的版本是2.7,安装和配置的主要步骤如下所述。
该集群中包括4个节点:1个Master,3个Salve。首先,虚拟软件VMware被安装在主机上,然后由 Vmare克隆出4个计算机节点,4个节点由1个是Master节点和3个 Slave节点组成。可以先安装Master节点, 再使用VMware克隆出3个Slave节点, 同时对4个节点进行网络配置,使得虚拟节点之间能够进行网络通信。4个节点都安装CentOS 6.5系统,并且有一个相同的用户hadoop。Master节点负责管理分布式数据和分解任务;3个Salve节点负责存储分布式数据和执行任务。具体的服务器节点规划如表 1所示。

表1 服务器节点规划
1.2配置主机
要成功搭建 Hadoop 集群,实现集群中各结点之间的信息传递,首先需要修改主机名和配置网络环境。
(1)修改主机名成为Master,命令是 HOSTNAME=master,Slave 结点的设置参照上面的命令。
(2)在进行配置Hadoop集群的网络环境,需要在"/etc/hosts"文件中添加所有机器的IP与主机名。这样Master与所有Slave机器之间的通信,不仅可以通过IP进行通信,而且还可以通过主机名进行通信。因此,在所有的机器上的"/etc/hosts"文件末尾中都要添加如下内容:
192.3.30.1 master,
192.3.40.1 slave1,
192.3.40.2 slave2,
192.3.40.3 slave3。
1.3 SSH(secure shell)无密码验证配置
在Hadoop启动以后,NameNode是需要通过远程启动和停止DataNode上的各种守护进程的。一方面NameNode要登录Slave节点并启动DataNode上的进程,另一方面DataNode上也要登录到NameNode。如果集群中各结点需要通过密码进行登陆,这给访问数据和传递信息带来了不便 。因此,需要配置SSH 无密码验证登陆的设置,释放各结点对文件的控制权限。
Master节点配置过程为:(1)在Master机器上生成两个密钥对文件,这两个文件是id_rsa和id_rsa.pub,它们默认存储在"/home/hadoop/.ssh"目录下;(2)公钥文件id_rsa.pub的内容被追加到authorized_keys文件尾部;(3)修改authorized_keys 的权限;(4)复制Master上的authorized_keys文件到Slave1结点;(5)在 Master 结点上,通过 ssh 登陆另3个Slave结点,如果无需密码验证,则表示Master节点的无密码登陆设置成功;(6) Slave上配置SSH 无密码登录与Master的步骤一样。配置成功后,Master结点与3个Slave结点之间就可以互相登录了而不需要输入密码。
1.4 Java 环境配置
所有的节点上都要安装JDK,先在Master节点安装JDK,然后安装其他Slave结点的JDK就可以完成。安装JDK和配置环境变量,需要以"root"身份登录。在"/etc/profile"文件后面添加Java的3个变量的内容,它们是"JAVA_HOME"、"CLASSPATH"和"PATH"。
1.5 Hadoop 集群配置
所有节点必须都要安装Hadoop。首先Hadoop要被安装在Master节点,然后Hadoop被安装在其他Slave结点上。安装和配置Hadoop需要以"root"的身份登录。要配置Hadoop,需要上传Hadoop-2.7.tar.gz文件到 Master机器的/usr文件夹中,并对它进行解压。根据系统的实际情况修改7个配置文件,这7个文件分别是Hadoop-env.sh,yarn-env.sh,core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml。在7个文件中,要重点配置hdfs-site.xml文件,这个文件主要的作用是设置HDFS相关的信息。云计算平台中的具体配置信息见表2。
表2 hdfs-site.xm的配置信息

参数参数值DFS. name.dir/home/hadoop/hadoop-2.7/dfs/nameDfs.replication3dfs.blocksize131072dfs.namenode.handler.count20
完成上述配置后,将Master上配置好的Hadoop2.7目录复制到其他Slave节点,这样Hadoop 云平台就安装完成了。
2 Hadoop高校共享云平台基准测试
测试可以验证云平台的正确性,分析云平台的性能,因此测试是非常重要的,但是测试经常容易被忽视。为了能对云平台有更全面的了解,找到云平台的瓶颈,对平台的性能做更好的改进,因此,对Hadoop平台进行4种测试。
2.1 Mrbench测试
为了检测小作业执行的效率,Mrbench会多次地执行一个小作业。该实验使用 Mrbench程序测试小作业,结果如表3所示。

表3 Mrbench测试结果
从图1可以看出, 随着小作业数量的增加,作业执行的平均时间逐渐变得稳定并缓慢下降。从最后两次测试的结果可以看出这两次时间没有多大差别,虽然次数增加1倍多,但是执行时间并没有减少1倍。说明小作业执行500次已经达到这个集群的极限。

图1 Mrbench测试结果
2.2 WordCount测试
WordCount程序主要的功能是统计文章件中每个单词出现的次数。WordCount程序是按照一定的规则把文文章件分割成小文件,然后输入到Map任务中。在Map任务中WordCount程序只是输出所有不相同单词的频数,然后由Shuffle模块和Reduce模块来共同完成单词的统计。因此,该任务的CPU资源需求非常小,实验的结果也验证了这一点。该实验使用WordCount程序分别对100M、300M、500M、1G、2G的文件进行测试,结果如表4所示。

表4 WordCount测试
图2表明,随着数据大小的增加 ,WordCount程序执行时间呈曲线增加。在文件比较小的时候,执行时间增加比较慢,在文件大小达到1G以上,执行时间增加比较快。总体上文件大小增大1倍,执行时间也增大1倍多。

图2 WordCount程序执行时间
2.3 TestDFSIO基准测试
Hadoop有一些基准测试程序,这些基准测试程序被打包在测试程序JAR文件中。TestDFSIO是这些测试程序中的一个,TestDFSIO用来测试HDFS的I/O性能。大多数新云平台系统的故障都是硬盘。通过运行I/O密集型的测试,可以知道集群的硬盘的性能。TestDFSIO通过使用MapReduce作业来完成测试,它是并行读写文件的便捷方法。每个文件被读写都在单独的Map任务中进行, Map任务也可以用来统计处理过的文件,最后统计数据在Reduce任务中被累加起来。
下述实验条件是数据总量相同但文件数量不同,结果如表5、表6所示。
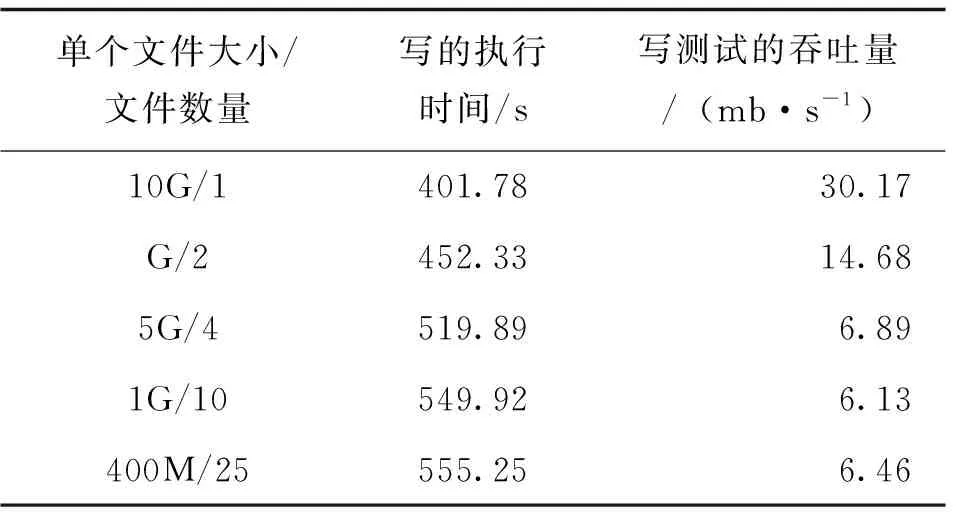
表5TestDFSIO的写测试
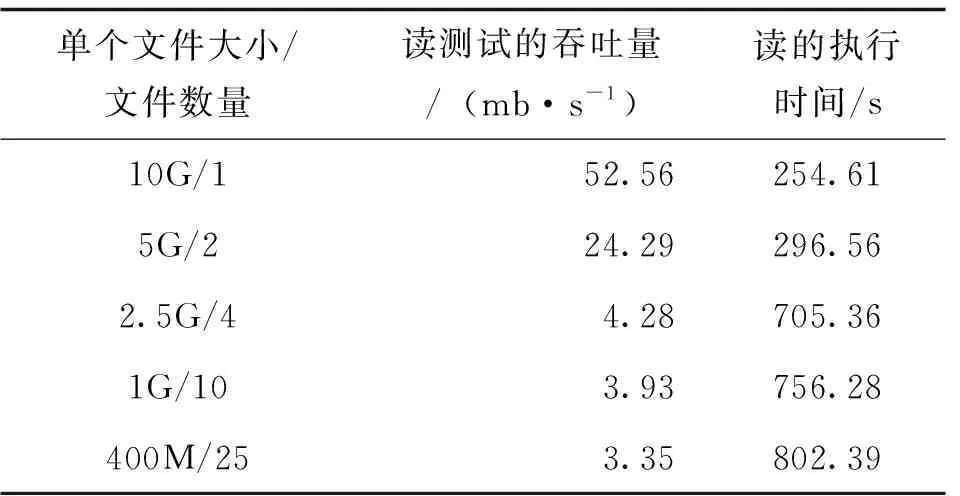
表6 TestDFSIO的读测试
图3表明,文件数量从2增加到4,执行时间增加较快,而文件数量在4个以上,执行时间增加没有显著增加。这些说明随着处理文件数量的增大,执行时间显著增加, 而当Reducer的参数接近集群节点数目云平台的执行速度变快。

图3TestDFSIO测试
2.4 TeraSort测试
TeraSort算法是由微软的数据库专家 Jim Gray 创建。2008年,Hadoop利用Tearsort算法对1TB的数据进行排序,耗时209s,排名第1。Tearsort算法是先对数据提取摘要,然后将Map输出结果分发到Reduce节点上,最后完成排序。TeraSort程序是通过对文文章件进行排序来测试 Hadoop平台的性能。实验分别对100M、300M、500M、1G和2G的文章件进行排序,测试结果如表6所示。

表6 TeraSort 执行的时间
图4表明,随着数据量的增加 ,Terasort程序执行时间呈曲线增加。当处理的数据量在1G以内执行时间增加比较慢,当数据量增到2G时执行时间增加非常快。
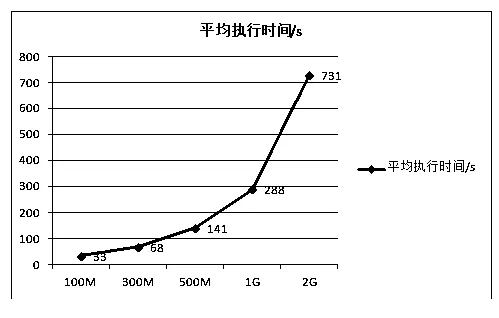
图4 Terasort程序执行时间
3结语
文章基于Hadoop高校共享云平台进行了4种基准测试,并对数据结果进行分析。从测试中可以看到,随着测试数据量的增大,Hadoop高校共享云平台的优势开始显现出来。实验只是在虚拟机上进行了平台实现与测试,数据量与真实情况仍有一定差距。因为在实际应用中,Hadoop高校共享云平台的网络规模与服务器性能都非常强大。该项目对Hadoop高校共享云平台性能测试对后续研究指明了方向。通过对上述测试结果的仔细分析和研究,发现Hadoop高校共享云平台可以从Hadoop软件架构的参数配置和实现算法等方面作进一步优化研究,以提高系统的性能。
