一种基于可编程逻辑器件的卷积神经网络协处理器设计
2018-07-25杨一晨张国和梁峰何平吴斌高震霆
杨一晨, 张国和, 梁峰, 何平, 吴斌, 高震霆
(西安交通大学电子与信息工程学院, 710049, 西安)
人工智能作为一门模拟人类能力和智慧行为的跨领域学科,机器学习是人工领域以及学术界的研究热点[1]。伴随着大数据时代的到来,深度神经网络结构愈加复杂与参数集规模愈加巨大对计算力与存储系统带来了前所未有的压力。目前,关于提供深度学习专用加速芯片成为半导体业界的热门研究方向之一,特别是在2012年以后涌现出大量优秀科研成果。值得注意的是,仅在2016年集成电路界的顶级会议ISSCC(IEEE international solid-state circuits conference)的“下一代处理器”主题中,就有6篇有关深度学习专用芯片的优秀论文[2]。而2017年的 ISSCC直接将主题定为了“智能世界、智能芯片[3]”。ISSCC 2018中的5个全天活动围绕机器学习与推理硬件方法[4],国内各高校与研究机构也积极从事本方向的研究。中科院计算所研制的通用架构神经网络处理器“寒武纪”不但取得了从2014年到2016年间多个计算机体系结构国际会议的最佳论文[5],并顺利投入商业化。清华大学的团队开展了基于神经网络压缩技术的神经网络处理器DPU的设计并提供了完整的开发系统,其团队目前创立了专门进行FPGA加速研究的科技公司。百度公司提出了“百度大脑”计划[6],早在2012年就开始使用图形处理器GPU、FPGA进行异构加速,在数以万计的GPU集群中进行高性能计算,百度无人车计划也在研究相关嵌入式计算平台,华为“2012实验室”、阿里云[7]、腾讯云也在进行关于使用FPGA进行加速的大规模研究,并开始提供基础服务。
本文的研究工作在课题组中属于探索性工作,目的是为课题组未来涉及机器学习与硬件相结合的研究领域建立理论与流程体系,并提供一个稳定可用的卷积神经网络协处理器IP,成为一个更大规模基于深度学习的嵌入式计算机视觉片上系统SoC中的关键组件。通过对深度学习中的卷积神经网络进行算法的分析,并结合FPGA系统的特点进行硬件实现与优化,设计出一款基于FPGA的高性能、可配置的卷积神经网络协处理器。本文着重探讨了在硬件架构层级的算法实现与优化机制,并阐述了一个详细的设计方案,并全面进行了设计验证、FPGA硬件实现与性能评估。
1 卷积神经网络分析
卷积神经网络起源于标准神经网络并提供了一种端到端的学习模型,与此同时作为神经网络领域一个重要的研究分支,卷积神经网络的特点在于其每一层的特征都是由上一层的局部区域通过共享权值的卷积核激励而得到。因此,卷积神经网络是计算机视觉领域的研究焦点,特别适用于二维数据处理的应用场景。
1.1 基本概念
卷积神经网络中,各层对应的神经元组织形式是一个三维矩阵,分别定义为长、宽、深度(也可称为通道数)。以尺寸为32×32的RGB图像作为输入层,三个维度的尺寸分别为32、32与3,权值同样以三维矩阵的形式存在。因此,卷积神经网络中的每一层都完成了把输入的三维矩阵转换为输入的另一个三维矩阵的过程,卷积神经网络由一系列具有功能不同的层按序单向连接组织。当前使用的卷积神经网络结构多种多样,但均会包含以下最基本的层:卷积层;池化层;全连接层,每一层的输出还需要经过在Alex Net[8-9]以及各种CNN模型中常见的ReLU激活函数。
1.2 卷积层与其运算模式
卷积层是整个卷积神经网络结构的核心,对于卷积层的算法及硬件结构的优化至关重要。卷积层的输入数据是若干组分辨率相同的图像,按照卷积核的尺寸进行卷积运算,输出若干组分辨率相同的图像。图像的卷积运算通过利用一个卷积核,把对应行列的权值与输入图像的像素值进行对应的累乘及累加运算,卷积核计算的数学表达式为


1.3 其他模块其运算模式
卷积层的输出往往需要经过池化或子采样。池化操作用于减小输入特征对应的每一个通道二维尺寸,进而减小了下一层计算的参数量,同时在训练效果上也可以控制过拟合[10]。以步长为2、尺寸为2×2的非交叠池化为例, 二维尺寸上从每2×2的非交叠子区域中输出一个值,即在长宽方向上的尺寸均缩减为原特征的1/2,数据量缩减为1/4。全连接层的输入特征与神经元是一一连接的[11],与标准的神经网络结构相同。全连接层的计算过程可视为普通的矩阵乘法:将输入特征延展为一维行向量,通过乘以规模比较大的二维矩阵,其输出为一个一维行向量。假设前一层的输出特征为4×4×64,延展为1×1×1 024的行向量,其权值矩阵为1 024×64的二维矩阵,输出特征为1×1×64。由于全连接层也可视为一个与输入特征尺寸相同的卷积核作用下的特殊卷积运算,因此现有研究中也出现了全卷积的概念,将现有网络中的全连接层全部转化为卷积进行计算。
2 协处理器概述
协处理器是辅助主处理器进行计算的模块,主要承担加速任务处理的功能。一般情况下,协处理器使用硬件设计实现几种运算复杂、耗时长的软件指令。通过简化多条指令代码为单一指令,以及直接在硬件中实现指令的方式,加速代码的计算,提升系统整体的运行效率。
2.1 卷积神经网络协处理器的意义
协处理器作为高速度和高精度的关键运算部件,其性能直接影响系统的运算能力。大数据时代的来临,卷积神经网络结构日趋复杂,大规模、深层次的网络利用了海量数据样本,其学习能力与表现能力不断提升,然而随之而来的是训练参数与计算量的成倍增加。复杂的深度学习网络的训练与预测过程需要消耗巨额浮点计算资源以及极高访存带宽,由于硬件体系结构的限制,仅利用通用架构CPU进行深度学习计算效率低、速度慢,难以部署大规模的计算任务。使用协处理器进行加速计算成为业内主流选择。
2.2 协处理器的通用实现
通用实现方面,CPU可以访问加速器及存储器而加速器通过访问存储器对数据进行处理,即协处理器作为主从复合机实现整个系统的加速。通过任务内部的并行机制和自定义大小的存储器,能够为每一个计算任务优化数据路径,从而很好地处理数据。
2.3 基于FPGA协处理器
传统使用通用CPU以及CPU+GPU的解决方案,结构复杂硬件开销大,并且对资源的利用率不高,而导致其工作能耗高。高端的CPU、GPU价格昂贵,基于FPGA的协处理器加速方案越来越受到学术界的关注认可。在处理模型结构复杂、数据量大、深层次的计算时,通用CPU仅需发送所需算法以及运算规模的计算指令给FPGA协处理器,由FPGA协处理器完成相应数据的读取以及运算实现硬件加速的功能[12]。
2.4 卷积神经网络协处理器设计思想
参考近年来新出的CNN模型,得到不同CNN模型都需要卷积层、池化层、填充单元、全连接层这些必要的基本组件,而各种模型的不同之处在于卷积层和池化层的数量以及它们的连接方式。本设计将每个组件都独立实现,并利用资源复用的思想,通过不同组件按一定顺序配置,在硬件资源允许的情况下就能实现任意结构的CNN模型,从而实现了卷积CNN的协处理器加速。
3 硬件实现细节
本协处理器设计包含了卷积处理器的完整的计算流程,具有高效能、低功耗的特点。考虑到未来应用场景对可配置性、可编程性的要求,设计了可支持不同规模,具有标准的接口、可扩展性与可定制性的卷积、池化、全连接、填充、非线性激活函数的计算模块。卷积协处理器结构图如图1所示。
卷积计算模块是整个卷积神经网络中的核心,具有计算量大、占用资源多的特点。高效能的卷积计算模块是卷积神经网络整体框架的性能分析的基础,需要着重优化卷积计算模块进而提高卷积神经网络的性能。
3.1 卷积计算特点分析
卷积计算是将卷积核和对应输入特征图的数据进行累加,其基本计算是矩阵乘法计算,由一系列的乘加计算组成。在运算中,数据会有高度的复用性以及不相关性:输入特征图数据对应多组卷积核,并且运算相互无依赖;输入特征图数据中的卷积子区域共享同一个卷积核;输入特征图像数据中的不同卷积子区域数据在空间上有大量重叠。硬件设计过程中需要在性能、控制灵活度、硬件资源使用方面进行折中权衡,片上的运算资源理论上可以全部并行使用,但其需要的数据会受到外部存储器的限制。当数据重复利用率较低的时候,运算单元需要在完成计算时立即从外部存储器中取数据,并行开启的计算单元数量会受限制于有限的外部存储器带宽单指令多数据的架构(SIMD)更适合面对大量数据的处理任务,可以大幅增强卷积神经网络的运算能力。为满足SIMD构架以及提升等效带宽,需要对外部存储器进行连续的读写操作,但卷积计算单元所请求的数据在存储器中的地址并不连续,会出现跨区域访存数据的情况,此时灵活的控制逻辑则是整体框架运行的保障。在硬件资源限制之内,充分利用卷积计算数据复用特性可以减小对外部存储器带宽的依赖,缩小硬件面积,提高计算能力并节约存储空间。
在确定各层级指标权重的基础上,建立县域乡村旅游公路选线适宜性评价模型为:式中:B为乡村旅游公路选线适宜性的综合评价值,ai表示评价因子的权重,ri表示评价因子的评分值。

图2 卷积协处理器结构图
3.2 卷积模块硬件设计
依据上一小节所阐述的设计思路,本设计中的卷积模块架构如图2所示,各基本组件主要分为以下4个子模块:①控制模块,包含配置表与卷积单元控制器;②数据输入模块,包含输入缓存LIB和移位器;③计算模块,包含多组向量计算单元;④数据输出模块,包含输出缓存LOB。
计算模块由多组向量计算单元组成,在本设计中,每组向量计算单元长度为8个单精度浮点型,即256 bit,其结构如图3所示。

图3 向量单元结构图示
向量计算结构中浮点加法单元,运算复杂,耗时较长。为了获得更高整体性能,并满足高频率下的时序要求,本设计选用了3级流水浮点加法器。由于加法器输出还要进行累加操作还需要一级的时钟节拍,所以运算结果需要4个时钟节拍传给下一级。由于累加计算具有依赖性,即下一组的累加计算需要等待上一组累加计算结果得出,因此需要有合理的控制逻辑保障卷积计算在流水线的正确节拍上,浮点加法流水线填充示意图如图4所示,其中Ai、Bi、Ci、Di(i=0,1,2,3)为填入加法器流水线的数据,Sai、Sbi、Sci、Sdi为有效的运算结果。

图4 浮点流水线填充示意图
为了避免浪费流水线出现空闲节拍而造成的效率降低,在流水线的3个节拍上控制器需要插入3个属于不同输出通道的卷积核进行计算,从而保障流水线的使用效率以及整体框架的性能。输入特征将会与多组不同的卷积核进行卷积运算操作,因此输入端移位器输出的数据可被多组向量计算单元共享使用。本设计中,设置有双端口全局缓存与两组向量计算单元相连接,实现两组卷积的并行计算,同时输出两组不同通道的输出特征。如果充分利用硬件资源,保证卷积计算单元流水线4个节拍不出现气泡,那么一次卷积迭代可以输出8组来自连续输出通道的输出特征。
3.3 其他函数单元
3.3.1 池化单元 池化层也称为抽象层,计算过程较为简单,分为最大池化和平均池化,计算本质并不是神经元计算,其主要作用是对特征图的数据进行采样,缩小数据规模。
根据学术界的研究成果,池化区域的尺寸多为2×2与3×3,滑动步长为2,本设计为实现更好的兼容性,同时支持这两种尺寸的池化计算。独立设计的池化单元有着更高的灵活性,实现兼容不同规模与结构的卷积神经网络。池化操作较为简单,且输入数据复用度低,在整个卷积神经网络框架中消耗时间和硬件资源较少,可以不必注重优化,故设计较为简洁。池化计算模块包含了输入数据缓冲区、控制器、最大池化计算模块、平均池化计算单元。池化操作开始时,池化控制器会从全局缓存中将特征数据读入到池化输入缓存中,池化计算模块根据计算类型计算数据,运算完成后计算结果将写回全部数据缓存。
3.3.2 全连接单元全连接单元在整个构架中起到分类器的作用,全连接操作是向量的乘加操作,完成输入特征行向量与权值矩阵相乘,输出为另一个行向量的计算。根据全连接的计算特点,全连接模块支持的输入向量长度应与全局数据缓存及相应的权值缓存的带宽匹配,其性能主要受限于外部存储器的带宽。本设计中的全局数据缓存和权值的缓存位宽都是512 bit,因此设置了16组浮点乘法器,其运算结果送入如图5所示的16-8-4-2-1树形结构连接的乘加结构。
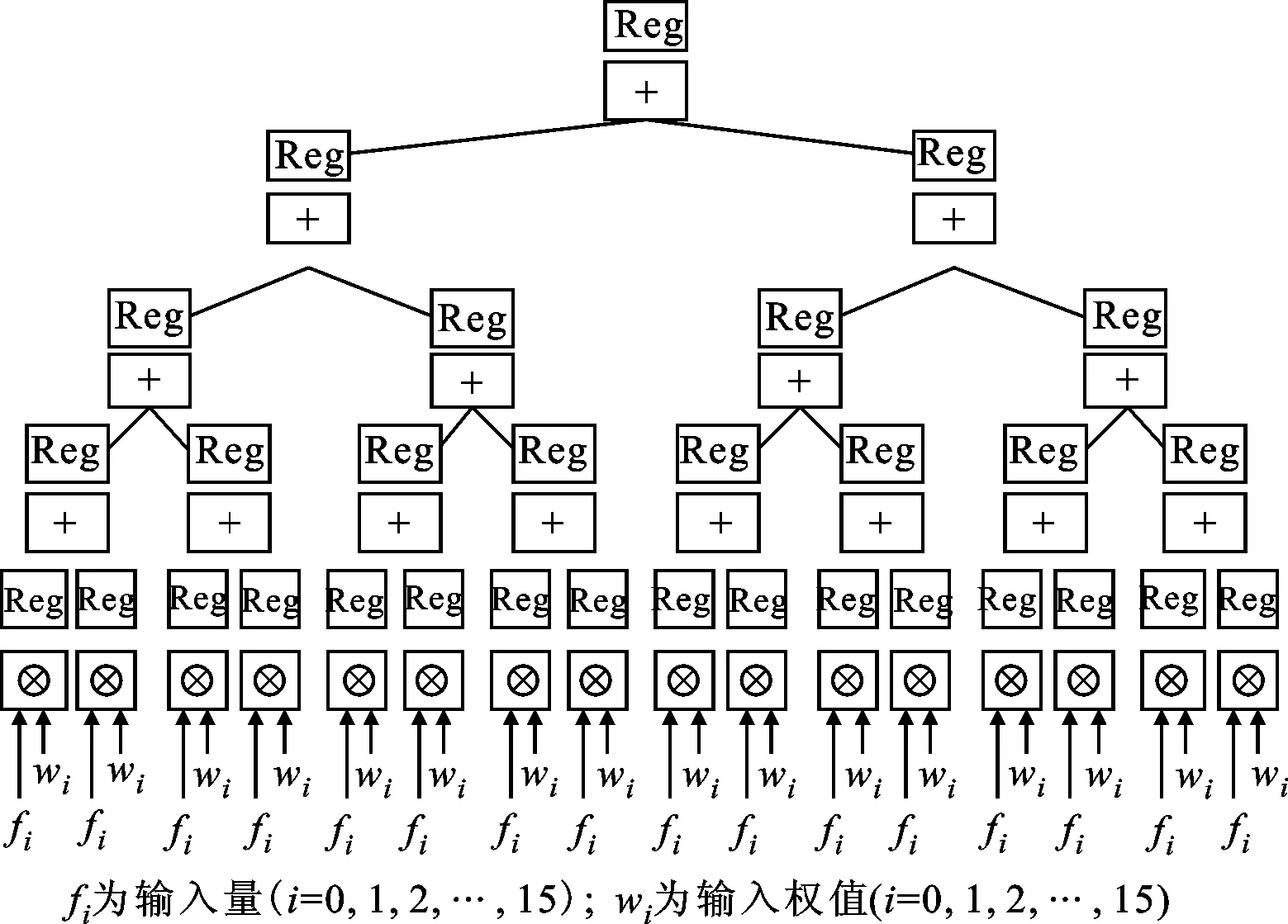
图5 全连接单元树形乘加结构
浮点加法器的速度较慢,不能满足高速主时钟的时序要求,这里的处理方案同前文中卷积浮点加法计算,采用了3级流水浮点加法器以及相应的控制器,来解决时序与数据依赖问题进而提高浮点加速器的速度。
3.3.3 I/O与存储体系 本设计设置了全局数据DDR3 SDRAM缓存器和局部数据权值缓存的多级存储结构[13]。协处理器的工作模式是配合通用CPU进行计算,其外部存储器采用与GPU配置外部单独显存相似的解决方案,采用了DDR3 SDRAM。
3.4 全局控制器与指令系统
3.4.1 全局控制器 全局控制器实现对本设计各个模块的控制,该模块可解析指令使得各单元进入不同的工作状态,完成相应的工作。本模块包含了8个32位寄存器组成的通用寄存器堆、指令译码单元、独立指令缓存,容量为4 kB、对应各个模块的控制接口。当外部主机或外部主控向协处理器发出启动信号后,协处理器从等待状态上线,自动进入启动状态,访问DDR3控制器的指令存储区域,指令指针自动从零地址开始读取指令,读取到的指令送入译码器之后执行,在执行上一条指令的同时读取下一条指令。
3.4.2 指令系统 控制器完成了任务的调度工作,本设计为了实现更高的灵活性兼容性,设计了指令系统来直接控制计算单元。采用位宽为32 bit的指令,指令的具体格式如表1所示。
4 实 验
本设计的硬件测试平台为XILINX公司的VC707评估套件,其搭载的FPGA芯片为Xilinx Virtex-7 VX485T,在VIVADO2016软件上进行综合,使用100 MHz的系统主时钟,由时序分析得知,本设计各条关键路径满足时需要求。本设计使用MNIST-LeNet、CIFAR-10测试集进行测试,得到较高的准确率,MNIST-LeNet的准确率高达99%,CIFAR-10可实现80%,与标准实现准确率一致。
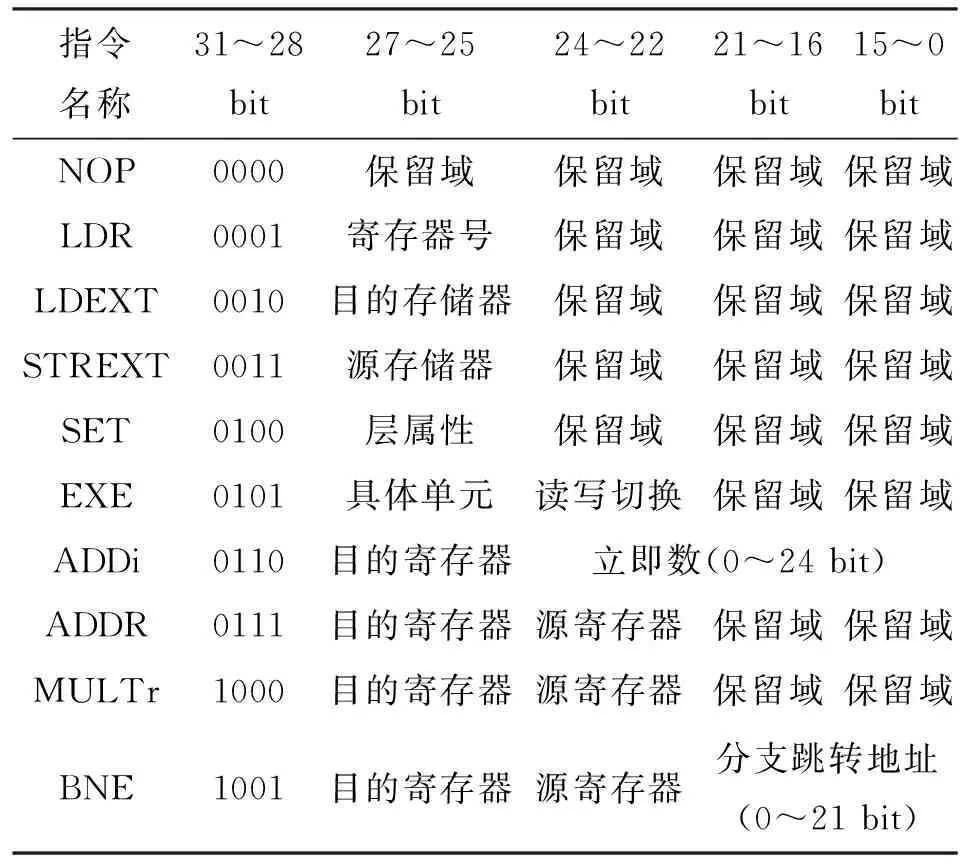
表1 指令格式说明
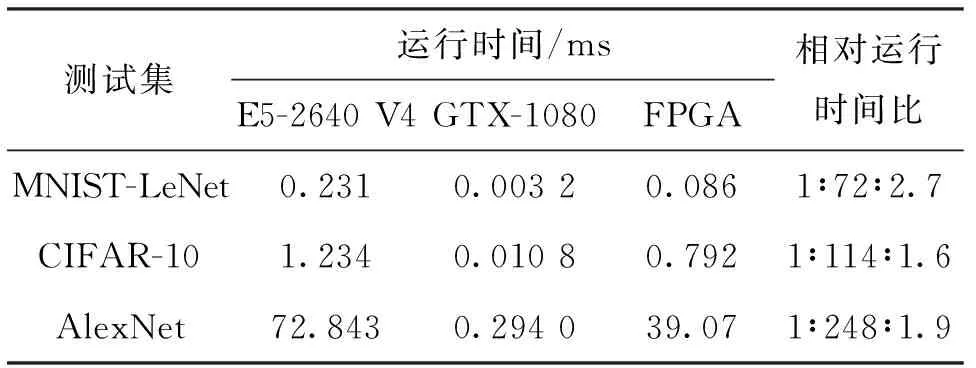
表2 不同平台的耗时比

本设计的卷积计算模块具有多核扩展性,在硬件资源允许的情况下,可以实现更高的运算性能。计算单元扩展,在XiLinx VC709评估板其核心FPGA芯片为Xilinx Virtex-7 VX690T上实现,卷积计算单元中,从每组两个计算向量扩展为每组4个计算向量,本设计方案与同期学术界对神经网络FPGA加速器的性能对比如表3所示。由表3可知,在单精度的设计方案中,本设计方案的性能达到同时期主流FPGA加速方案的水平。

表3 与其他文献的性能对比
5 结束语
本文提出一种针对卷积神经网络完整的协处理器加速方案,可实现卷积、池化、全连接等的计算操作,并采用硬件资源复用的思想,可以支持不同层数的计算。本设计的卷积计算单元,在硬件资源充裕的情况下,可以进行多核扩展,实现性能翻倍。通过指令系统通过不同的指令配置实现不同规模的网络运算,相较传统固定规模的硬件设计,有着更高的灵活性和通用性。
本设计充分利用了硬件并行计算带来的优势,通过与通用处理器方案对比,体现了本设计的能效比优势;着重利用了卷积的数据复用特点,设计了卷积计算单元;通过合理的多级缓存体系的设计,使用一定的片上资源,降低了协处理器对外部存储器读写频率和带宽的占用率,使得协处理器内部各模块通信更加高效,同时降低了功耗。
本文全面验证、测试与评估了本设计,完成了行为级仿真、RTL级仿真、FPGA上板验证,功能符合设计预期,关键路径满足时序要求。使用经典训练集MNIST-LeNet、CIFAR-10测试,与标准实现准确率一致,通过对CPU、GPU的性能对比,显示出本设计更高的运算效率。
