中国户籍登记系统覆盖评估研究
2018-07-24胡桂华
胡桂华,薛 婷
(重庆工商大学 数学与统计学院,重庆 400067)
一、引 言
为了及时了解人口的动态变化,美国、北欧等西方发达国家和部分非洲国家的政府行政机构建立起类似于中国户籍登记系统的民事登记系统,如全国人口登记册、就业登记册、学历学位登记册、学生入学登记册等[1]。这种系统通过登记人口的出生、死亡、迁移等人口事件获得某个时点上的总体或其子总体的人口数。由于主客观原因,民事登记系统可能多登、少登或滞后登记人口[2]。联合国统计司要求各国政府统计部门使用双系统估计量估计民事登记系统的净误差率,把通过净误差率调整后的民事登记系统作为人口统计数据来源[3]。净误差率定义为总体实际人数与民事登记系统人数之差除以前者的比值。可见,民事登记系统净误差率估计的关键是总体实际人数的估计。
中国、朝鲜和贝宁未建立民事登记系统,而是建立户籍登记系统。户籍登记系统的宗旨与民事登记系统不同,它是一种行政管理手段,目的是实现对人口的管理,而不是提供准确的人口数。尽管中国户籍登记制度规定,每个人都有资格申报户口,每个出生者应该在规定时间申报户口且只能申报一个户口,每个死亡者应该及时注销户口,但在现实中并未得到严格执行。中国“六普”前的户籍整顿结果显示,户籍系统由于长期计划生育政策的实施或受其他因素的制约而存在一定比例的一人多户、死亡未注销户口、超生婴儿未入户等现象。从短期内来看,这些现象还难以消除。以上事实表明,虽然从户籍系统能够如民事登记系统一样获得某个时点的人口数,但这个人口数是有偏差的[4]。为了确保基于这个人口数所做计划或决策的科学性,对户籍登记系统进行质量评估是必要的。根据评估得到的净误差率来判断这种偏离的程度,从而决定是否使用及如何使用它提供的人口数。
在民事登记系统覆盖评估中,依据同一样本普查小区相互独立的民事登记系统和人口普查(或人口抽样调查)资料构造的基于两次捕获模型的双系统估计量是目前估计民事登记系统实际人口数及其净误差率的主流方法[5]。然而,双系统估计量有一个重要的限制条件,那就是它要求两个资料系统必须独立。如果不能满足这个条件,就会产生交互作用偏差而导致估计量有偏[6]。在人口普查质量评估工作中,用人口普查资料和人口普查质量评估时的人口登记资料构造双系统估计量,由于很难保证这两个资料系统独立,所以用这个估计量来估计实际人口数是有偏的。正是由于这个问题,有学者曾撰文建议在人口普查质量评估工作中估计实际人口数时,舍弃双系统估计量,而用三系统估计量来取代它[7]。现在情况有所不同。本文是用民事登记系统与人口普查登记资料来构造双系统估计量。从直观上来分析,这两个资料系统非独立的风险似乎较前者要小些,用来估计实际人口数的双系统估计量有偏的风险也会小些[8]。但是,我们还是建议用三系统估计量来取代它。这是因为双系统估计量只是利用了人口普查登记资料这一种辅助信息。抽样调查理论中,在构造估计量的时候,利用的辅助信息越多,估计量的精度也会越高。在上述两个系统的基础上,如果把人口普查质量评估时所做的人口登记资料添加进来,构造基于三次捕获模型的三系统估计量,就会比双系统估计量更充分地利用了辅助信息,因而可进一步提高总体实际人口数估计的精度[9-10]。
虽然三系统估计量的理论基础是三次捕获模型,但它们之间有本质区别。第一,三次捕获模型利用三次全面捕获资料估计动物总体规模,而三系统估计量利用三次抽样资料估计人类总体规模。换句话说,所构造的三系统估计量,应该是基于全面调查总体值的三系统估计量的估计量。第二,三次捕获模型在灵敏性、生活习性、体型、年岁等诸多方面大致相同的动物总体内估计动物数目。国外学者在使用三次捕获模型时,都未曾考虑过对总体中的动物分层,在默认动物总体中的动物具有同样特性这种背景下研究和使用三次捕获模型。在构造三系统估计量时要求总体中的人口在人口普查及其质量评估调查、户籍登记系统中各自的登记概率相同。但事实上,在进行上述每一种登记的时候,都会由于某些人口统计特征变量的影响,使得总体中的人口在进行此种登记时,登记的概率有所差别。于是就需要把影响每一种登记概率的特征变量找出来,用所有变量对总体中的人口交叉分层[11],使得分在同一交叉层中的人口进行每一种登记时都具有相同的登记概率,在这样的层中构造三系统估计量,然后再将各层的估计量在整个总体合成。第三,三次捕获模型未考虑各次捕获之间动物的移动,采用较为简单的无移动模型估计动物总体数目。三系统估计量则需要考虑各个系统之间在不同时间上人口的移动,构造人口移动的三系统估计量,从而完成总体实际人口数估计的任务。第四,计算三次捕获模型与三系统估计量的抽样方差公式不一样,其中后者通常使用复制抽样方差估计量近似计算所估计人口数的抽样方差估计值。该抽样方差估计量用来解决复杂估计量的抽样方差计算,在西方抽样领域应用广泛,但在中国应用甚少。复制抽样方差估计量要求每一层的第一重样本不少于5个抽样单位,否则高估总体参数估计量的抽样方差。第五,根据三次捕获之间的各种统计关系构造与之相适应的三次捕获模型,将既定数据代入各种三次捕获模型,使用皮尔逊卡方检验统计量或对数似然比估计量完成最佳三次捕获模型的选择。但是三系统估计量中的三个系统(人口普查、人口普查的质量评估调查和户籍登记系统)在现实中的统计关系是客观固定的,能够分析出哪一种统计关系最可能发生,并构造与之相应的三系统估计量,无需进行各种统计关系下的三系统估计量选择。
从以上分析可以看出,使用三系统估计量需要具备如下条件或做好以下工作。首先,对总体使用反映人口在三个系统登记概率的变量对总体人口分层,在等概率人口层构造三系统估计量。其次,先构造三个系统对总体全面登记的三系统估计量,然后使用有限总体概率样本构造上述三系统估计量的每一个构成部分的线性估计量,得到三个系统对总体抽样登记的三系统估计量。然后,在人口普查、户籍登记系统与质量评估调查之间,总体人口会从一个普查小区移动到另外一个普查小区。为了适应这一情况,需要构造人口移动的三系统估计量。最后,获取同一普查小区三个系统人口登记的微观资料,这是一项十分困难的工作。
国外学者在一些人群或地区做三系统估计量试点工作[12],取得了较为理想的估计结果,为在民事(户籍)登记系统的覆盖率评估中应用三系统估计量奠定了基础。国外学者在这些试点中使用的是三个系统对总体全面登记的三系统估计量。在民事(户籍)登记质量覆盖评估中,三系统资料是经过有限总体概率抽样所抽出的各个普查小区的三种人口的登记名单。在中国户籍登记系统覆盖评估中想要借鉴外国学者在试点工作中构造的三系统估计量的经验时,须对有关的研究成果做进一步的拓展,使其适用于民事(户籍)登记质量覆盖评估[13]。
根据中国人口统计调查的实际情况,对户籍登记系统的覆盖评估可以在人口普查年或非人口普查年实施。如果安排在人口普查年,就构造人口普查、人口普查的质量评估调查及户籍登记系统资料的三系统估计量估计总体实际人口数。如果安排在非人口普查年,就构造人口抽样调查、人口抽样调查的质量评估调查及户籍登记系统的三系统估计量估计户籍登记系统净误差率。本文只研究人口普查年户籍登记系统的覆盖评估。
迄今,中国尚未开展户籍登记系统覆盖评估工作。《中国统计年鉴》每年提供存在一定误差的户籍人口数。我们应该改变这一状况,尽早开展户籍登记系统覆盖评估工作,为未来实施以户籍登记系统为核心的行政记录式人口普查创造条件。
二、三系统估计量理论
三系统估计量建立基础为最初用来估计动物总体规模的三次捕获模型。没有三次捕获模型就没有三系统估计量。在三次捕获模型发展历史上,国外学者做出了突出贡献。他们通过对同一动物总体的三次全面捕获,以及三次捕获之间的统计关系(独立还是相关),使用对数线性模型和最大似然估计等方法构造了各种统计关系的三次捕获模型。将三次捕获模型移植到人类总体构造三系统估计量,我们需要了解和掌握三次捕获模型[14]。
(一)三次捕获模型
三次捕获模型由两次捕获模型拓展而来。从两次捕获模型入手有助于三次捕获模型的理解,解决三次捕获模型构建中的疑难问题。二维列联表是分析和构造两次捕获模型的重要工具。把每一次捕获的动物总体中的动物数目及通过比对两次捕获的动物名单得到的同时出现在两次捕获中的动物数目填入二维列联表,见表1。用{xij}表示每个单元(ij)的观察值。第一,x11,x10,x1+分别表示同时在两次捕获中捕获到的动物数目,在第一次捕获中捕获到但未在第二次捕获中捕获到的动物数目,在第一次捕获中捕获到的动物数目(x1+=x11+x10);第二,x01,x00,x0+分别表示未在第一次捕获中捕获到但在第二次捕获中捕获到的动物数目,两次捕获中均未捕获到的动物数目(未知,需要估计),未在第一次捕获中捕获到的动物数目(x0+=x01+x00);第三,x+1,x+0,N分别表示在第二次捕获中捕获到的动物数目(x+1=x11+x01),未在第二次捕获中捕获到的动物数目(x+0=x10+x00),动物总数目(未知,需要估计)。N=n+x00,n=x11+x10+x01为在两次捕获中捕获到的动物数目,是已知的。现在所要做的工作是,构造N和x00的估计量。它们分别为:
(1)
(2)
式(1)或式(2)成立的前提条件是两次捕获相互独立。下面将要讨论的三次捕获模型则不受各次捕获之间是否独立的限制。讨论三次捕获模型的工具是三维列联表,见表2。

表2 三次捕获的三维列联表
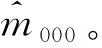
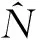
(3)
(4)
(二)三系统估计量
前面探讨的8种三次捕获模型是针对三次捕获之间可能发生的统计关系构造的,而不是针对某个特定统计关系构建的。在将三次捕获模型移植到人类总体构造三系统估计量时,并不需要构造8种三系统估计量,而是要根据研究的特定对象,选择1种与研究对象有关的三次捕获模型来构造三系统估计量。
本文讨论的三系统估计量中的三个系统为普查年的人口普查、人口普查的质量评估调查及户籍登记系统,也就是说,要讨论人口普查年的户籍登记系统覆盖评估问题。
在决定使用哪一种三次捕获模型构造三系统估计量时,要分析这三个系统之间的统计关系,从中选择最可能发生的统计关系,使用与这种统计关系相一致的三次捕获模型构造该种统计关系的三系统估计量。
人口普查、人口普查的质量评估调查及户籍登记系统可能的统计关系有8种:第一,人口普查、质量评估调查及户籍登记系统相互独立;第二,人口普查与质量评估调查相关,分别与户籍登记系统独立;第三,人口普查与户籍登记系统相关,分别与质量评估调查独立;第四,质量评估调查与户籍登记系统相关,分别与人口普查独立;第五,人口普查与质量评估调查相关,户籍登记系统与质量评估调查相关,人口普查与户籍登记系统独立;第六,质量评估调查与人口普查相关,户籍登记系统与人口普查相关,质量评估调查与户籍登记系统独立;第七,人口普查与户籍登记系统相关,质量评估调查与户籍登记系统相关,人口普查与质量评估调查独立;第八,人口普查与质量评估调查相关,质量评估调查与户籍登记系统相关,人口普查与户籍登记系统相关。
在上述8种关系中,现实中最可能发生的是第2种统计关系。包括美国和中国在内的许多国家的人口普查及其质量评估调查工作都是由各国的政府统计部门统一组织开展的,其工作目标也都是为了获得普查标准时点上的全国及各个地区的人口总数。另外,为了节约调查员的培训时间和调查经费,在质量评估调查中,往往使用本次的优秀普查员,充其量只是将他们派往到不同于普查时的调查小区做质量评估工作。这就决定了人口普查与质量评估调查是统计相关,而不是统计独立。中国户籍登记系统的登记机构是公安局下属的户籍科,登记目标是人口管理。这表明户籍登记系统与人口普查或质量评估调查是统计独立,而不是统计相关。也就是说,这种统计关系在现实中成立的依据很充分,在构造三系统估计量时应该予以重点关注。有鉴于此,只讨论这种统计关系的三系统估计量构造方法。美国当今三系统估计量研究著名学者Griffin也只是构造这种统计关系的三系统估计量。相应地,只需要构造第2种统计关系下的三系统估计量。
在将三次捕获模型移植到人类总体构造三系统估计量时,还需要考虑的一个重要问题是,如何使得总体中的人口如同动物总体中的动物那样具有同样的捕获概率。总体中的人口由于这样或那样的原因,在人口普查或质量评估调查或户籍系统中的登记概率存在差异。这就需要选择反映登记概率大小的变量对总体中的人口等概率分层,在等概率层(用l表示)构造三系统估计量。
在人口普查、质量评估调查、户籍系统对总体全面登记假定条件下,依据式(3)的三次捕获模型构造的等概率层l的未知单元{000}的三系统估计量为:
(5)
(6)
其中,xl=x111,l+x101,l+x110,l+x100,l+x011,l+x001,l+x010,l。
为区别于下面的三系统估计量,把式(5)或式(6)称为三个系统对总体全面登记的、无人口移动的三系统估计量。这样的三系统估计量是三个系统对总体全面登记的、人口移动的三系统估计量及三个系统对总体抽样登记的、人口移动的三系统估计量的基础。
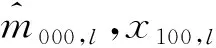
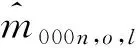
=[(x001n,l+x001o,l)(x110n,l+x110o,l+
x100n,l+x100o,l+x010n,l+x010o,l)]/
[x111n,l+x111o,l+x101n,l+x101o,l+
x011n,l+x011o,l]
(7)
由于在普查标准时点和质量评估调查时点之间迁出本小区的向外移动者不可能登记在本小区的质量评估调查人口名单中,即x111o,l=x011o,l=x110o,l=x010o,l=0。把这些数据代入式(7)得到式(8):
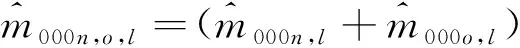
(8)
xn,o,l=x111n,l+x101n,l+x101o,l+x110n,l+x100n,l+
x100o,l+x011n,l+x001n,l+x001o,l+x010n,l
(9)
(10)
2.等概率人口层l的三个系统对总体抽样登记的、人口移动的三系统估计量。这样的三系统估计量适合于人口普查年的户籍登记系统覆盖率估计。人口普查和户籍登记系统是对全国所有调查小区的人口登记,而质量评估调查是对全国样本调查小区的人口登记。三次捕获模型建立的前提条件是,三次捕获都是对总体的全部动物捕获。人口普查与户籍登记系统是对全国人口的全面登记,这一点无法改变。为了依据三次捕获模型构造三系统估计量,只能假设质量评估调查是对全国人口的全面登记,并在这样的假设条件下构造基于三次捕获模型的三系统估计量。这种假设是有科学依据的。首先,统计理论模型大多建立在一些假设条件基础上。其次,质量评估调查理论上可以对总体人口进行全面登记,只是为了节约成本开支及时间才采取抽样登记方式。再次,包括美国、瑞士在内的许多国家在构造双系统估计量时也是假设质量评估调查是对总体人口的全面登记,三系统估计量是双系统估计量的自然延伸,对双系统估计量所做假设自然适合于三系统估计量。考虑到质量评估调查实际上是对总体人口的抽样登记,因而需要用有限总体概率样本表示三个系统对总体全面登记的三系统估计量的各个构成元素,使其成为三个系统对总体抽样登记的三系统估计量。包括美国普查局在内的所有政府统计机构和其他相关研究人员迄今尚未构造出三个系统对总体抽样登记的、人口移动的三系统估计量,他们只是构造了基于三次捕获模型的三个系统对总体全面登记的三系统估计量。
构造三个系统对总体抽样登记的三系统估计量,只需要将式(8)或式(9)中的每一个单元用估计量的形式表示即可,结果见式(11)或式(12):
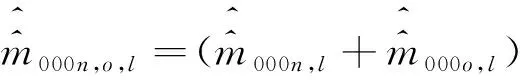
(11)
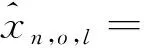
(12)
(13)
为了构造式(11)、式(12)等式右边的每一个估计量,需要先了解质量评估调查的抽样方法。在大规模质量评估抽样调查中,通常使用二重抽样法抽取样本[15-18]。相比一重抽样,二重抽样的优势是,在同样的成本下,总体参数估计量的抽样方差较小。应用二重抽样的一个前提条件是,在对第一重样本普查小区的现场观察中发现了较多的住房单元地址登记误差或者其他对第一重样本进一步分层的变量,以便抽取代表性更大的第二重样本。另外一个条件是,发现第一重样本的规模过大,为节省调查经费或减少调查误差而压缩其规模。二重抽样在以美国为代表的发达国家政府统计部门应用广泛。迄今中国国家统计局尚未将二重抽样应用于人口统计调查。
在抽取第一重样本之前,为提高样本对总体的代表性及便于编制抽样框,按照规模对普查小区分层,分为两层(H=2):80个及以上住房单元的普查小区层(h=1);80个以下住房单元的普查小区层(h=2)。每一层的普查小区总数用Nh表示。在每一层,以普查小区为抽样单位,采取简单随机不重复抽样方式抽取普查小区,抽取的普查小区数用nh表示。每一h层的第i普查小区的抽样权数用whi表示。hi样本普查小区人口分配到等概率人口层l的人口数用ylhi表示。对抽取的第一步样本普查小区,现场了解每一个样本普查小区住房单元所在街道、建筑物类型、门牌号码、家庭成员等辅助信息,并把它们作为第二重抽样的辅助变量,对第一重抽样每一层的样本普查小区重新分层。按照户籍人口占全部人口比例对普查小区分层,分为两层(G=2):户籍人口比例不足50%的普查小区层(g=1),户籍人口比例超过50%的普查小区层(g=2)。每一新g层的普查小区总数用Mhg表示。从每一新层,以普查小区为抽样单位,采取简单随机不重复抽样方式抽取第二重样本普查小区,抽取的普查小区数用mhg表示。层hg的hgi小区在层l的人口数用ylhgi表示。
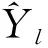
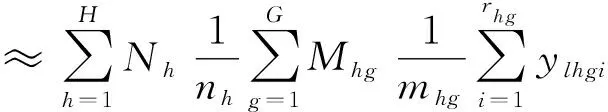
(14)
式(14)中,如果hi普查小区属于g层,xhgi=1,否则xhgi=0;如果hi普查小区进入第二重样本,Ihgi=1,否则Ihgi=0;αhgi是hi样本调查小区经过两重抽样的抽样权数,如果这两重抽样都是简单随机抽样,那么αhgi=(Nh/nh)(Mhg/mhg)。
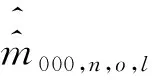
(15)
(16)
式(16)中:
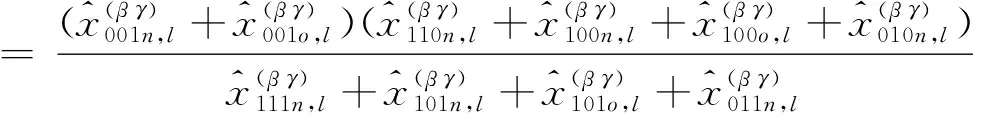
(17)
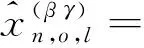
(18)
(19)
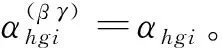
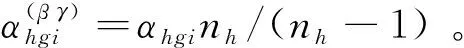
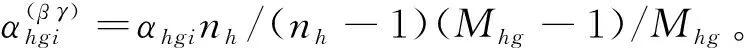
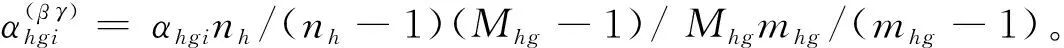
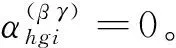
根据上面的讨论,写出hgi普查小区复制权数的完整计算公式:
(20)
3.总体的三个系统对总体抽样登记的、人口移动的三系统估计量。在构造了等概率人口层l的三系统估计量后,只需要进行简单的合成操作,即可得到总体的三系统估计量及其抽样方差估计量[20]。
(21)
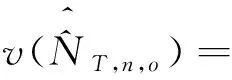
(22)
(23)
4.总体户籍登记系统净误差率估计量。分别用TCR和THR表示总体户籍登记系统净误差率及户籍登记系统人口数。根据前面的净误差率定义,以及式(21)和式(22)写出TCR估计量及其抽样方差估计量。
(24)
(25)
三、实证研究
(一)调查范围及资料来源
实证调查的范围为重庆市南岸区管辖下的铜元局街道、花园路街道、南坪街道、海棠溪街道、龙门浩街道、弹子石街道、南山街道和涂山镇。为叙述便利,统一称为重庆市南岸区部分街道,共有普查小区2 200个,并估计其2017年6月1日户籍登记系统的净误差率。
实证研究的目标是:发现理论与方法阐述中的纰漏,从而及时更正;验证理论和方法的合理性和实用性;帮助读者更加直观地了解三系统估计量的计算方法;向国家统计局提交2016年立项的重点课题《我国户籍登记系统覆盖评估研究》研究报告,作为制订中国2020年及以后户籍登记系统覆盖评估方案的重要参考。
迄今所有国家都未在户籍登记系统覆盖评估中使用三个系统对总体抽样登记的、人口移动的三系统估计量。因此,实证分析资料无法从各国政府统计部门获得。即使各国政府统计部门在户籍登记系统覆盖评估中使用过三系统估计量,从他们那里获得样本普查小区的三个系统的住户及个人微观资料也很困难。
在楼栋长的帮助下,我们获得了重庆市南岸区部分街道8个样本普查小区的三份人口登记名单,依次称为第一次调查人口登记名单、第二次调查人口登记名单,户籍登记系统人口名单。其中,第一次调查人口登记名单相当于人口普查中人口登记名单、第二次调查人口登记名单相当于人口普查的质量评估调查人口登记名单。
获取这些人口登记名单的具体步骤是:第一步,由我们所在单位开具介绍信,与所要获取的样本普查小区的楼栋长取得联系,询问获得人口登记名单的可能性,以及可能存在的问题,如部分家庭拒绝入户。在初步取得他们的同意后,明确具体提出需要他们提供哪些信息,并告知支付数据采集费。第二步,与楼栋长签订数据采集及使用保密协议。协议中规定支付费用的金额、时间及支付方式。我们只能在指定的地方及规定的时间内使用这些家庭及个人微观数据。具体来说,就是我们不能将这些涉及个人隐私的数据带回家中,只能在楼栋长的监督下按照研究任务的需要比对和汇总这些原始数据。汇总数据可以带回用于研究,原始数据楼栋长收回。这确保了个人涉密数据不外泄,打消了楼栋长及住户或个人的后顾之忧。第三步,设计问卷。其中,第一次调查问卷的项目涉及姓名、性别、出生年月、户籍所在地、目前所在地、婚姻关系、文化程度、与户主关系、一年前居住地,等等。第二次调查问卷的调查项目有每个家庭的详细地址、门牌号码、人口数、每个人的姓名及其性别、年龄等人口统计特征,每个家庭成员普查日居住在本样本普查小区还是其他普查小区。如果居住在其他普查小区,确定居住的准确地点;普查日居住在本样本普查小区某个住房单元的人的去向,等等。第四步,将设计好的问卷通过楼栋长交给家庭户主或其他家庭成员,由其填写问卷中要求填写的每一个项目。
对获得的三份人口登记名单,首先,剔除不属于本小区的人口(死亡人口、迁出人口及重复登记人口),确保每份人口名单中的人口都属于本小区,满足三系统估计量对每份名单允许有遗漏而不能错误包括人口的要求;其次,为了确保三份人口登记名单均是对同一总体同一时点上的人口登记,考虑到户籍系统往往滞后登记人口这一现实情况,将滞后登记的人口使用追索方法补充到户籍人口名单(新出生人口和迁入人口);最后,对名单中人口统计特征或居住地点信息登记不完整者,通过后续调查或估算方法补充完整,以确保三份人口登记名单之间的人口比对工作顺利进行,提高比对效率和减少比对误差。
在准备好三份人口登记名单后,紧接着是名单之间的人口比对。比对安排在人口普查质量评估调查数据采集结束后。比对的目标是查找三份名单之间的匹配者,即同时在两份名单或三份名单中登记的人口。这需要对一份名单中的每个人,查找其是否也在另外一份或二份名单中,若在另外一份或二份名单中找到了这个人,则称其为匹配者。欲确认三份名单中的两个登记或三个登记是否为同一个人,需要比对这两个或三个登记所填写的姓名、性别、年龄、与户主关系、婚姻状况、学历学位、出生地、户籍所在地、目前居住地点等项目。如果这两个登记或三个登记所填写的这些项目的内容全都对应相同,则可以断定这两个登记或三个登记为同一个人。除此之外,余下的有三种情况:第一,从两个登记或三个登记的人口统计特征项目的信息中可以没有疑问地断定这两个登记或三个登记不是同一个人;第二,两个登记或三个登记的大部分人口统计特征项目对应相同,只是有个别的项目不相对应,怀疑是否有登记错误;第三,所做登记的人口统计特征项目填写不全。对于第二、第三两种情况,称其为匹配状态悬而未决者,需要收集新信息再次比对。经过比对和再次比对后,同一样本普查小区的人口分为8种,即在三份名单登记人口(1种)、在两份名单登记人口(3种)、在一份名单登记人口(3种)、未在任何名单登记人口(1种)。
为满足三系统估计量在登记概率大致相等的人口层建立及使用的要求,将样本普查小区人口在比对后划分到登记概率大致相等的人口层中。为此,使用性别、年龄、房屋所有权、居住位置及地点、普查表回收率、种族、民族等变量对总体人口分层。每一个等概率人口层由上述变量交叉形成。一方面,增加一个分层变量,交叉层就相应增加,分配到每一个交叉层的样本量就少,使用三系统估计量估计的人口数抽样误差大;另一方面,研究目标并不是分层变量的选择及交叉层的构造,而是让读者理解和掌握三系统估计量及其抽样方差估计量的计算过程。因此,只是选择性别对总体人口分层:男性层及女性层,用l表示。
需要特别说明的是,本文为何不以全国(或是重庆市整个区域)为实证研究对象?一方面收集全国(或是重庆市整个区域)三个系统的三份人口登记名单将是一项我们无法完成的任务,就算是国家统计局或重庆市统计局做这项工作也需要周密的部署与安排,投入大量的人力、物力和财力;另一方面比对全国(或是重庆市整个区域)三份人口登记名单及对比对结果悬而未决的处理也是一项极其复杂、技术含量很高的工作,需要大量受过专门训练的计算机人员和比对人员参与,无论是国家统计局,还是重庆市统计局目前都没有能力完成这项工作。然而,不可否认的是,三系统估计量对研究区域有很好的适应性,可在城市、乡村,行政区(镇、县、省)或全国使用。当然,为了积累经验,往往应该先在地理区域较小的范围使用三系统估计量,然后逐步扩大其应用范围。美国普查局就是遵循这一思路。他们曾经在县里的黑人居民区使用三个系统对总体全面登记的三系统估计量评估人口普查计数质量。在2020年,美国普查局计划在全国和各个州使用三系统估计量估计人口普查净误差率。我们所提出的适合于户籍登记系统覆盖评估的三个系统对总体抽样登记的、人口移动的三系统估计量完全可以移植到全国或重庆市的户籍登记系统覆盖评估中。
(二)抽样方法及等概率人口层的样本人数
采用前面叙述的二重抽样方法,按照住房单元数目将重庆市南岸区部分街道的所有普查小区分为两层,分别用符号h=1和h=2表示,每一层的普查小区数及样本小区数分别用Nh和nh表示。对第一重样本小区按照户籍人口占全部人口比例进一步分为两个新层,分别用符号g=1和g=2表示,每一新层的小区总数及样本数分别用Mhg和mhg表示。样本形成过程如表3所示。

表3 样本形成表
注:为便于计算,对抽样权数四舍五入。
在获得三份人口登记名单、完成三份名单比对、对总体人口等概率分层(男性层、女性层,分别用l=m和l=w表示)、将比对结果划分到等概率人口层后,8个样本调查小区(分别用符号1~8表示)在男性层和女性层的样本人口数xijk见表4和表5。
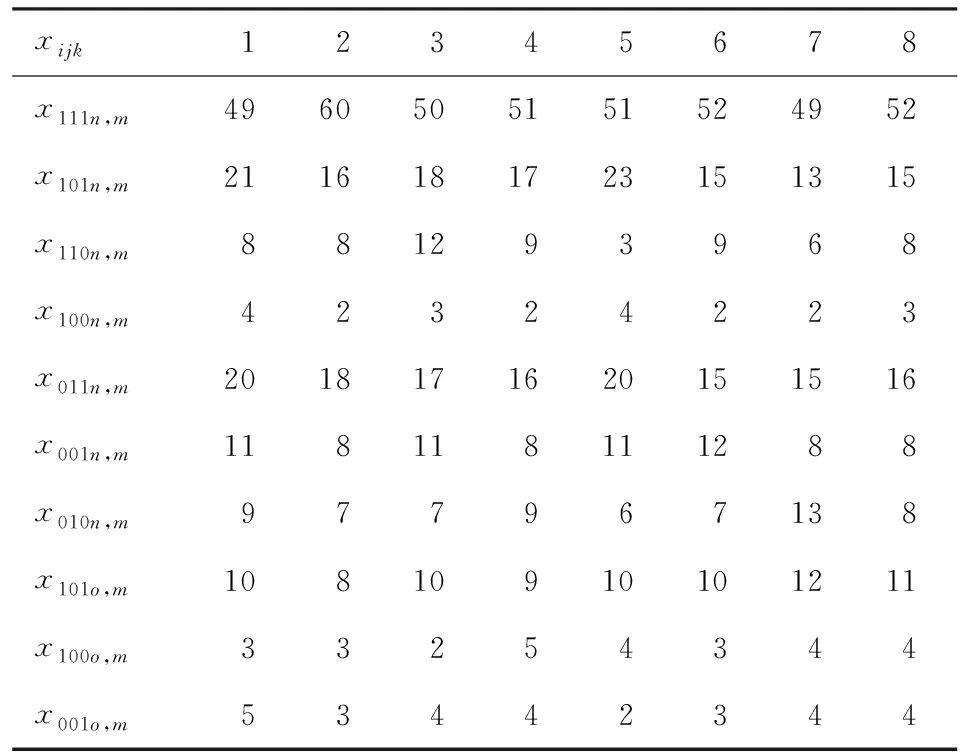
表4 男性层(l=m)样本人数表
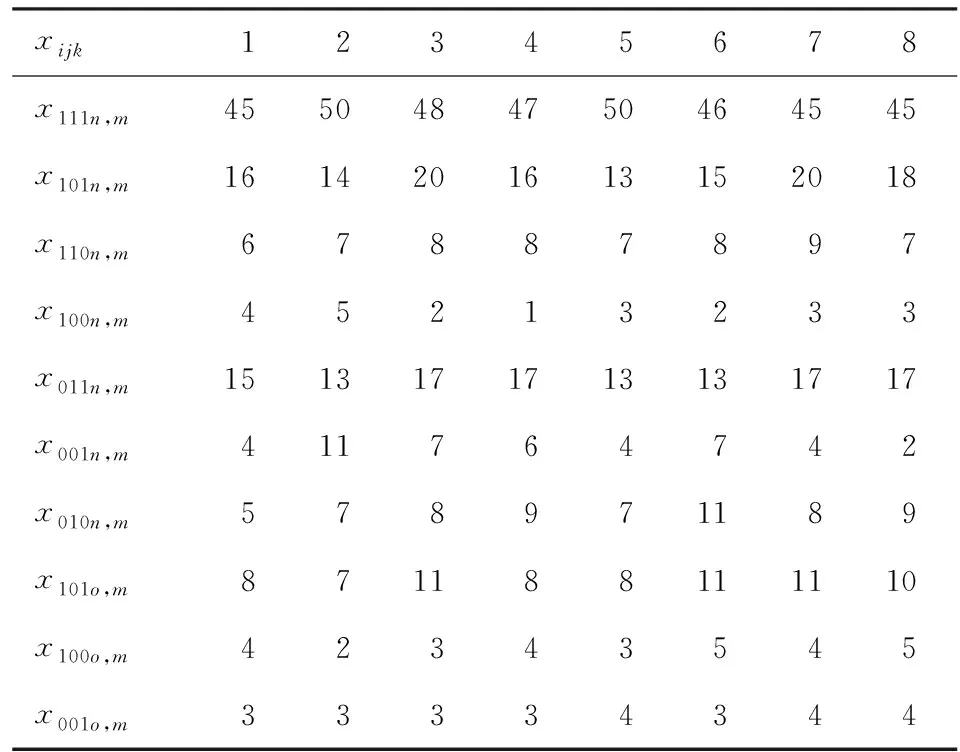
表5 女性层(l=w)样本人数表
(三)等概率人口层(男性层及女性层)人数的估计
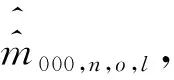
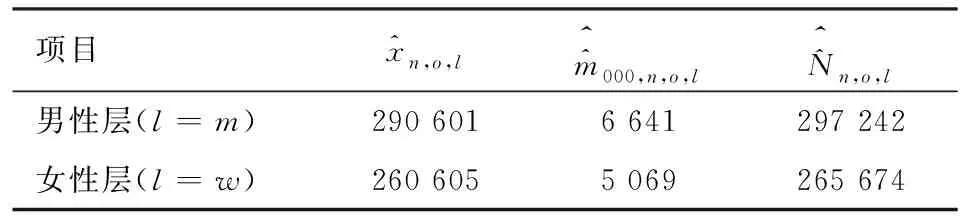
表6 等概率人口层的人数估计值表 单位:人
从表6可以看出,重庆市南岸区部分街道的男性层的人口数估计值为297 242人,而女性层的人口数估计值为265 674人。
(四)等概率人口层(男性层及女性层)人数估计值的抽样方差及协方差计算
使用式(20)计算在轮流刀切第一重样本(共13个样本普查小区,共刀切13次)情况下,进入第二重样本(共8个样本普查小区)的每一个样本普查小区的复制权数,计算结果见表7。
表7 样本普查小区复制权数表
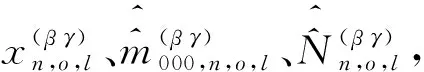
利用表8和表9数据,使用式(15)和式(23)计算重庆市南岸区部分街道的男性层及女性层人数估计值的抽样方差,以及它们之间的协方差。具体计算过程及其结果见表10、表11和表12。
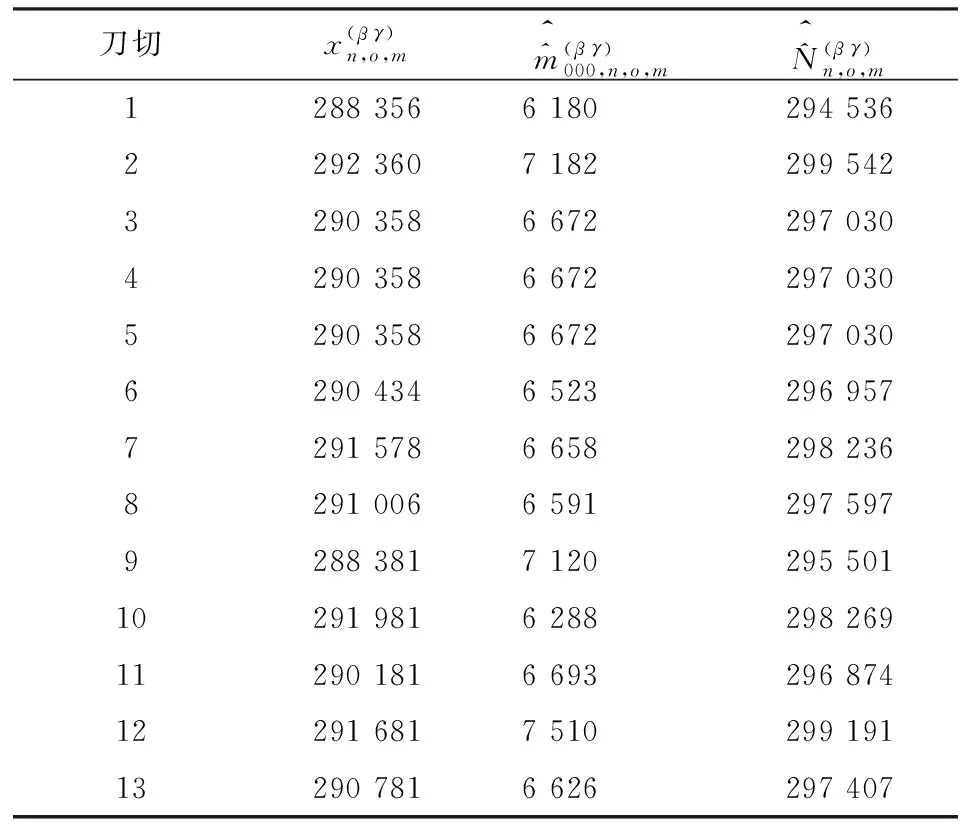
表8 男性层(l=m)人口数复制值表
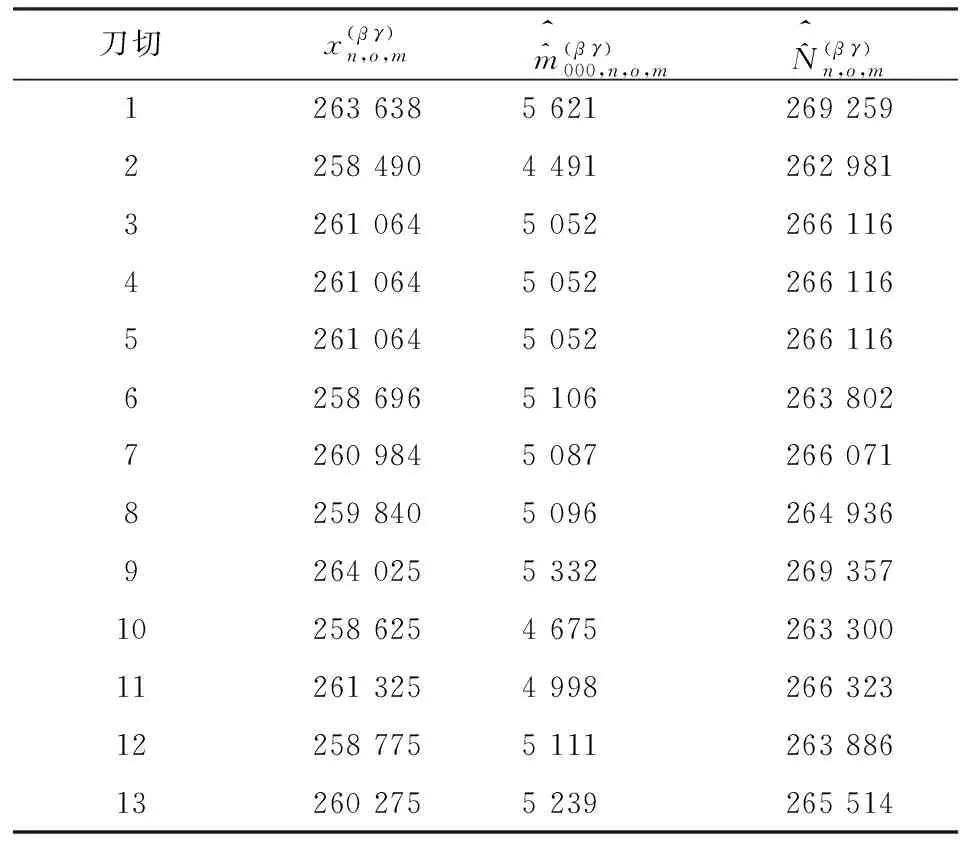
表9 女性层(l=w)人口数复制值表
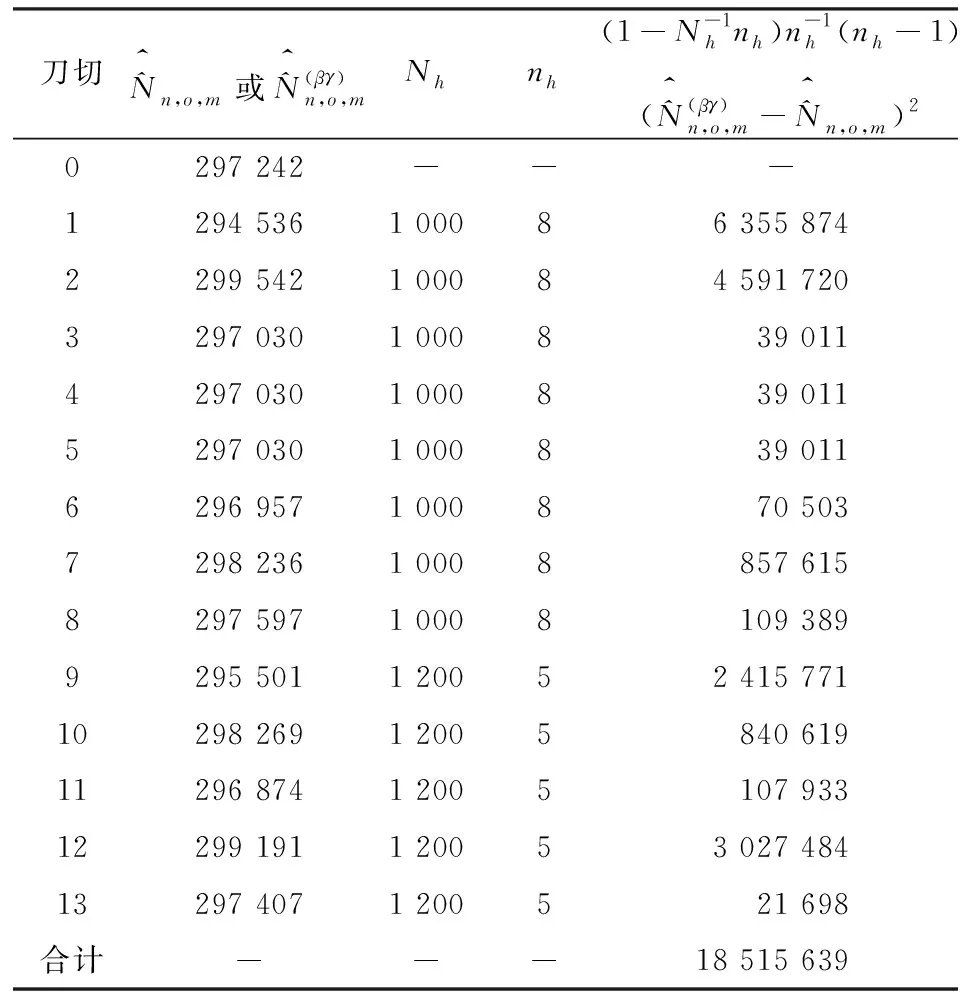
表10 男性层(l=m)抽样方差计算表
表10表明,重庆市南岸区部分街道男性层的人口数的抽样方差为18 515 639,标准误差为4 302人。
表11表明,重庆市南岸区部分街道女性层的人口数的抽样方差为39 817 523,标准误差为6 310人。
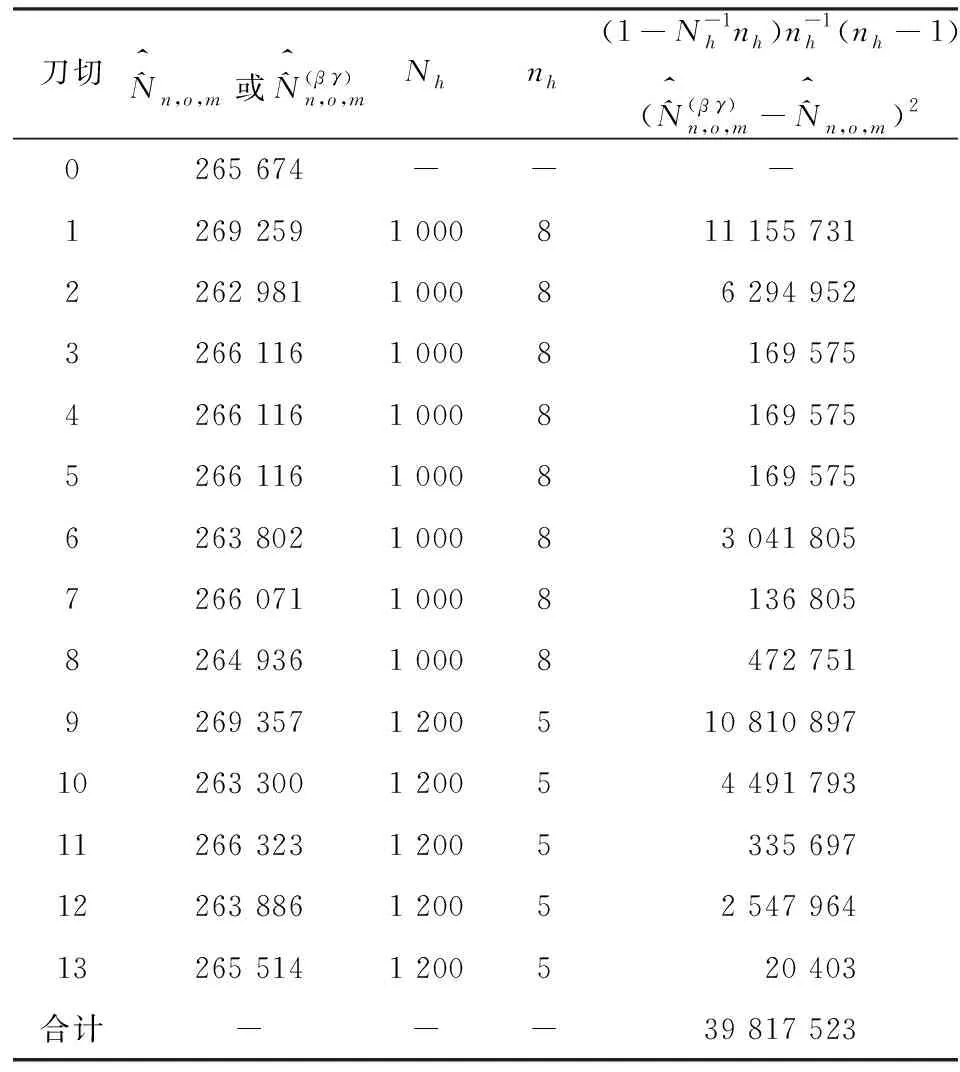
表11 女性层(l=w)抽样方差计算表
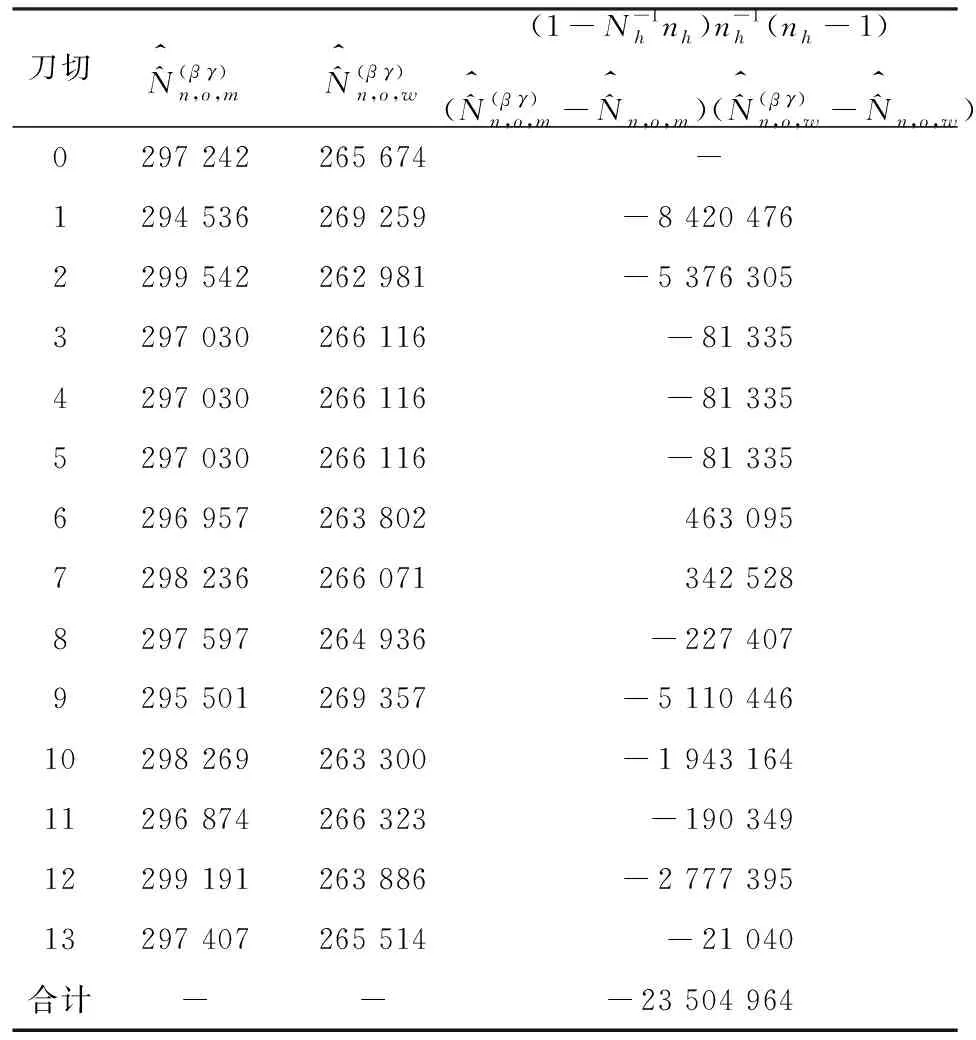
表12 男性层(l=m)与女性层(l=w)协方差计算表
从表12可以看出,重庆市南岸区部分街道的男性层与女性层之间的协方差为-23 504 964,表明这两个等概率人口层负相关。
(五)总体人口数估计及抽样方差估计
使用式(21)~式(23),利用表6、表10~表12数据,得到重庆市南岸区部分街道的人口数及抽样误差分别为:
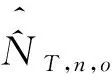
=562 916(人)
39 817 523-2×23 504 964=11 323 234
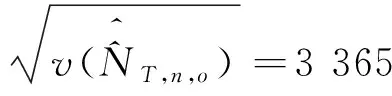
(六)总体户籍登记系统净误差率估计
重庆市南岸区部分街道的户籍人口数为556 161人。根据式(24)和式(25)得到其户籍登记系统的净误差率及其抽样标准误差分别为:
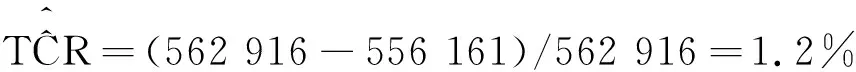
(七)小结
从以上计算结果可以看出,2017年6月1日,重庆市南岸区部分街道的总人数为562 916人(抽样标准误差为3 365人),其中男性297 242人(抽样标准误差为4 302人)、女性265 674人(抽样标准误差为6 310人),户籍登记系统净误差率为1.2%(抽样标准误差为0.0 059 778)。
四、结论与建议
本文从理论层面和实际操作层面详细讨论了用于户籍登记系统覆盖评估的三系统估计量及其基于分层刀切方差估计量的抽样方差估计量。通过实际案例演示了样本抽取、样本数据采集与处理、样本普查小区抽样权数、复制权数、男女人口层、总体实际人口数计算等工作步骤,为中国未来户籍登记系统评估提供了具体的估计方法。在此基础上得到如下结论,并提出相应对策建议。
(一)结论
户籍登记系统作为中国最重要人口行政记录,本身用于行政管理目的而不是用于统计目的。这决定了它的人口登记方法、登记时间和登记范围与统计的要求不一致。这种不一致必然导致户籍人口数偏离实际人口数。改变这一状况的根本方法是事后对其完整性进行评估。根据评估的结果将户籍人口数调整为实际人口数。如果建立户籍登记系统的公安部门引入三系统估计量评估方法,就能够为国家统计局提供高精度的人口行政记录数据。这么做的前提是,国家统计局与公安部门建立密切的数据共享合作关系。
为获得真实可靠的户籍登记系统净误差率估计值,总体人口数与户籍登记系统人口数在口径上必须一致。户籍登记系统提供的是具有本地户籍的人口数,所估计的总体实际人口数也应该是具有本地户籍的总体人口数。为了做到这一点,对每一个样本普查小区的三份人口登记名单,要仔细审查其中的每份名单中的人口是否具有本地户籍。对有本地户籍者予以保留,对不具有本地户籍者予以剔除。对没有本地户籍,在其他地区有户籍的人口,作为其他地区人口数估计的范围。
三系统估计量是估计户籍登记系统净误差率或覆盖率的前沿方法。与作为目前民事登记系统覆盖评估主流方法的独立双系统估计量相比,一方面,三系统估计量除了利用户籍登记系统这一辅助信息外,还利用了与总体实际人口数密切相关的本次人口普查辅助信息,而且对这种辅助信息的使用是建立在具有科学依据的捕获-再捕获-再捕获模型的基础上,因此在估计精度上自然会有所提高。另一方面,小规模实证研究表明,即使不考虑同时未在三个系统登记的人口数,三系统估计量比独立双系统估计量的估计结果还是要更加接近于实际一些。
不能把用来估计动物总体规模的三次捕获模型等同于用来估计人口总体规模的三系统估计量。在应用三次捕获模型构造三系统估计量时,需要解决总体人口分层问题、人口移动问题、有限总体概率抽样及估计问题。只有解决了这些问题,才能构造出适合于户籍登记系统覆盖评估的三个系统对总体抽样登记的、人口移动的三系统估计量。在构造三系统估计量时,还有一个特别需要注意的问题,那就是每个系统只允许遗漏人口,而不能错误登记人口(即把不属于总体的人口纳入系统中)。
(二)建议
国家统计局应尽快着手建立对中国户籍登记系统覆盖状况的定期评估工作。一是以此为线索,查找户籍登记工作中存在的漏洞,尤其是一人多户和死亡者未注销户口问题;二是在使用户籍登记系统提供的人口数字时要做适当调整,不能直接使用,否则影响依据户籍人口数所做决策或计划的科学性。
上述评估工作宜每年进行一次。在人口普查年,随同人口普查质量评估工作一起进行。把人口普查的标准时点定为户籍登记系统覆盖评估的标准时点;用人口普查质量评估样本作为户籍登记系统覆盖评估的样本。在非人口普查年,随同人口抽样调查质量评估工作一起进行。把人口抽样调查的标准时点定为户籍登记系统覆盖评估的标准时点;用人口抽样调查质量评估样本作为户籍登记系统覆盖评估的样本。
国家统计局在制订户籍登记系统覆盖评估方案时,可尝试使用三系统估计量这一前沿理论研究成果。如果等到前沿理论被完全掌握再使用它,那将总是落后于美国等其他国家。为了尽快掌握前沿理论,国家统计局可以组织培训,聘请专家讲授三系统估计量及其抽样方差估计量。
