基于LBP卷积神经网络的面部表情识别
2018-07-19江大鹏
江大鹏,杨 彪,邹 凌+
(1.常州大学 信息科学与工程学院,江苏 常州 213164;2.常州大学 常州市生物医学信息技术重点实验室,江苏 常州 213164)
0 引 言
传统的面部表情识别算法,分为3个主要步骤:检测人脸、提取特征、表情分类。譬如于明等[1]提出基于局部Gabor二值模式(LGBP)特征和稀疏方法,识别面部表情,识别率平均接近于87.5%。Georgoulis S等[2]使用高斯过程隐变量模型,对人脸面部表情进行识别,表情识别率到达90%左右。Ding X等[3]运用级联任务的方法分析人脸面部表情,并在4种CK+、FERA、RU-FACS和GFT数据库上验证,表情识别率达到70%左右。童莹[4]通过提取空间多尺度HOG特征,识别人脸表情。目前,由于深度学习方法具有无监督特征学习能力的突出优点,研究员打破了“先手动提取特征,后模式识别”这一传统观念。深度神经网络的技术将传统的表情识别3个步骤(特征学习、特征选择、表情分类)变成了单一步骤(输入是一张图像而不是一组人工编码的特征)。研究表明,当使用更深层次的架构(即具有许多层)学习具有高级抽象的特征是非常有效的。由于人脸图像千变万化,背景比较复杂,因此人手动提取的特征越来越难以满足实际的需求。深度学习网络可以自动提取任务相关的特征并进行分类,并且具有更好地性能[5,6]。Liu等[7]提出了一种深度置信神经网络(BDBN),BDBN是由一组弱分类器构成,每一个弱分类器作用是对一种特定表通过数据的增益来增加训练的数据量,并在CK+数据集和创建的3个数据集上进行了实验,表情识别率达到93.5%。然而,目前大多数针对面部表情的深度学习模型出现精度不高,并且训练阶段时间比较长[8-10],这部分原因在于数据库中表情图片样本少和图片里面包含了与面部表情的无关信息,比如CK+,JAFFE,Oulu-CASIA数据库中图像包含了许多与表情无关的信息[11-13],如图1所示。

图1 CK+、JAFFE、Oulu-CASIA数据集样例
1 面部表情识别系统结构
进行面部表情识别任务时主要分为两个阶段:测试和训练阶段。在训练阶段,首先对图像进行人脸检测,选取面部表情兴趣区域,对图像进行裁剪,去除背景干扰,然后对裁剪完的图像使用局部二值模式(LBP)提取纹理特征,输入深度卷积神经网络训练模型。在测试阶段,在测试集进行上述一系列的图像预处理,通过在训练阶段获得的模型,进行表情分类。面部表情系统流程如图2所示。
1.1 图像预处理
1.1.1 人脸检测
采用Viola-Jones框架[14]进行人脸检测,它主要由三功能固件组成:首先使用积分图的思想,用一个较完整的图像来表征人的面部图,并在积分图中得到一个或者多个距离特征。然后根据图像的信息,训练出一系列的弱分类器,同时用AdaBoost方法进行弱分类器的强化,最终得到一个强分类器。为了提高检测效率采用级联的方法组合训练得到的强分类器,极大提高了人脸检测的速度和准确率(降低漏检率和误检率),如图3所示。
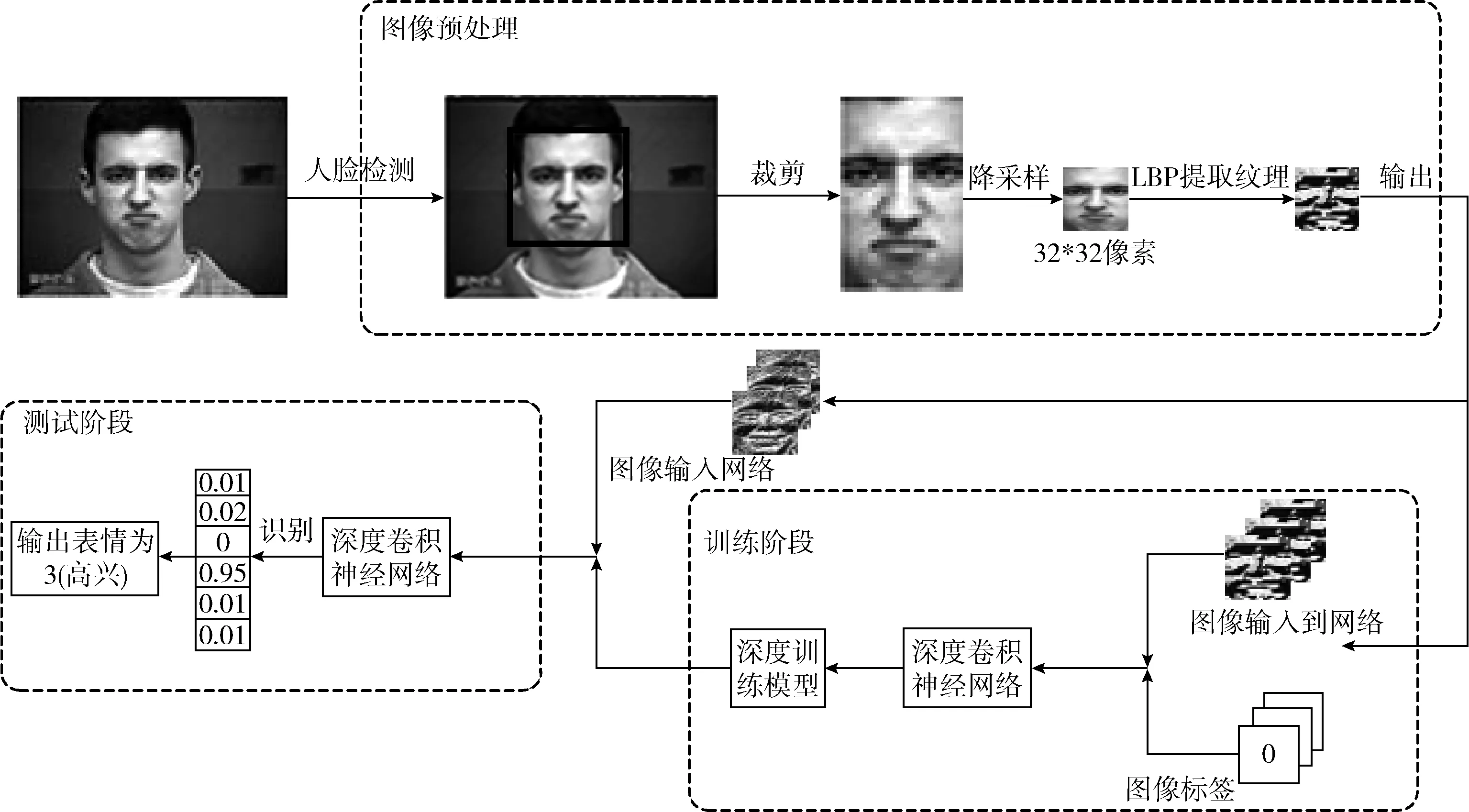
图2 面部表情识别系流程

图3 人脸检测结果
1.1.2 图像裁剪
如图3所示人脸框架中,还有对面部表情分类不重要的信息(例如耳朵,额头等),这些信息可能会降低面部表情的分类率,裁剪过程如图4所示,在图4中对耳朵信息进行去除,使用的系数为0.2,由于人脸是对称的,只保留人脸图像宽度0.6倍。这些因子值是根据人脸结构和经验所确定的。

图4 裁剪流程
1.1.3 降采样
通过降采样的操作确保在深度神经网络中图像的大小并且确保尺度的标准化,即所有图像中面部成分(眼睛、嘴、眉毛等)的位置相同。降采样使用线性内插方法,确保在重新采样之后可以确保图像中面部成分处于相同位置,降采样过程目的在于减少GPU执行卷积过程运行时间,如图2所示。
1.1.4 局部二值模式(LBP)
使用LBP算法对输入图像的流形面从高维降到低维,由于LBP算法具有灰度不变性,并且由图5可以明显区分人脸兴趣区域特征,同时淡化了研究价值不大的平滑区域,同时降低了特征的维数,减少深度卷积神经网络对大量数据的运行时间。

图5 LBP提取纹理特征
1.1.5 样本增益
深度卷积神经网络需要大量的样本,针对目前现有数据库,样本量少,不利于使用卷积神经网络,因此需要对样本进行增益。AT Lopes等[15]对单张图片进行旋转、翻转采样的扩展训练样本方法,生成了大量的训练样本,本文借鉴了此方法来增益样本如图6所示。
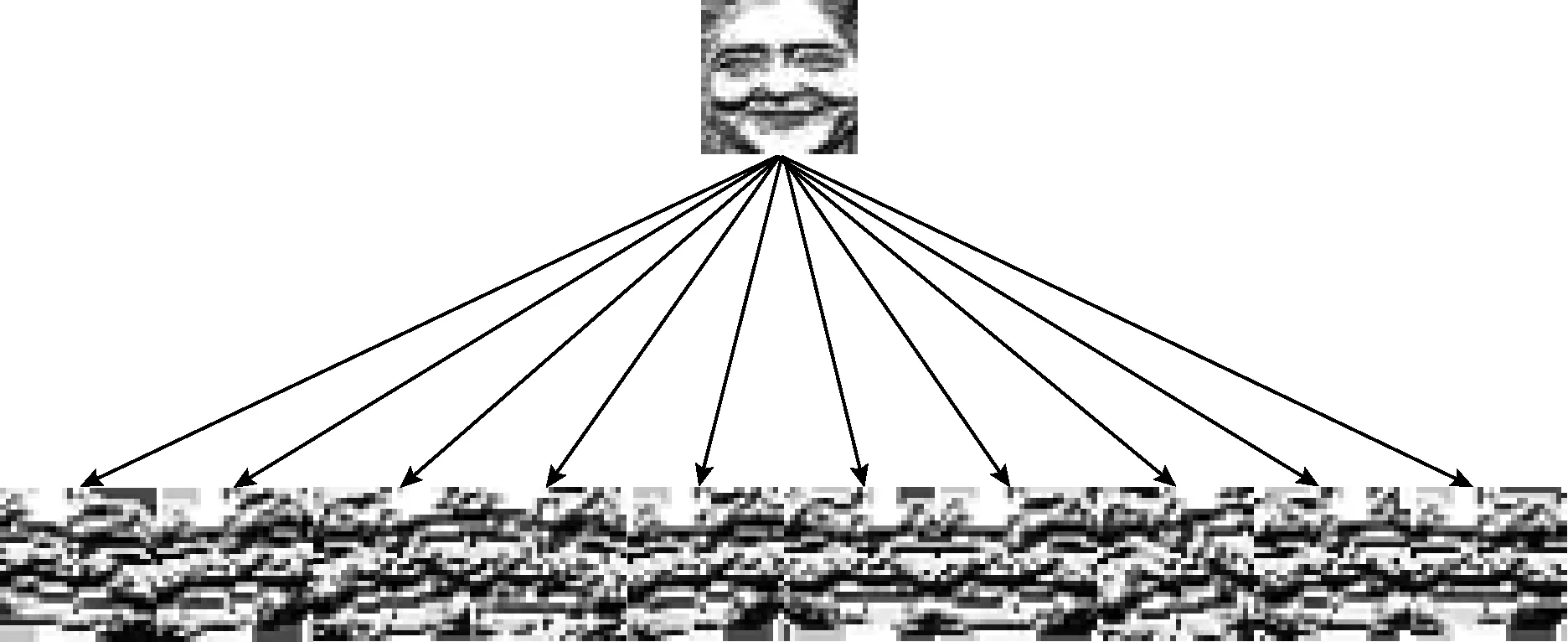
图6 增益样本
1.2 卷积神经网络
基于经典LeNet-5的网络框架进行改进,本文使用的卷积神经网络架构如图7所示。除了输入平面,它包含6层,输入一张32*32人脸图,输出每种表情概率,确定最终面部表情。卷积神经网络(CNN)架构包括两个卷积层、两个降采样层和一个全连接层一个Sotfmax层。CNN的第一层是卷积层,其采用5*5的卷积核并输出28*28像素的16张图像。CNN的第二层使用Max-pooling(内核大小为2*2)的降采样层将图像缩小到其图像大小的一半,输出16张14*14像素的图像。CNN的第三层是卷积层,采用5*5的卷积核并输出32张10*10像素的图像。CNN的第四层是降采样层,采用2*2内核,输出32张4*4像素的图像。通过一系列卷积和降采样操作获得平面,这些平面称之为特征图。CNN的第五层是全连接层,全连接层包含了128个神经元。最后一层为Softmax输出6个网络节点(每个节点表示该面部表情下概率大小)。
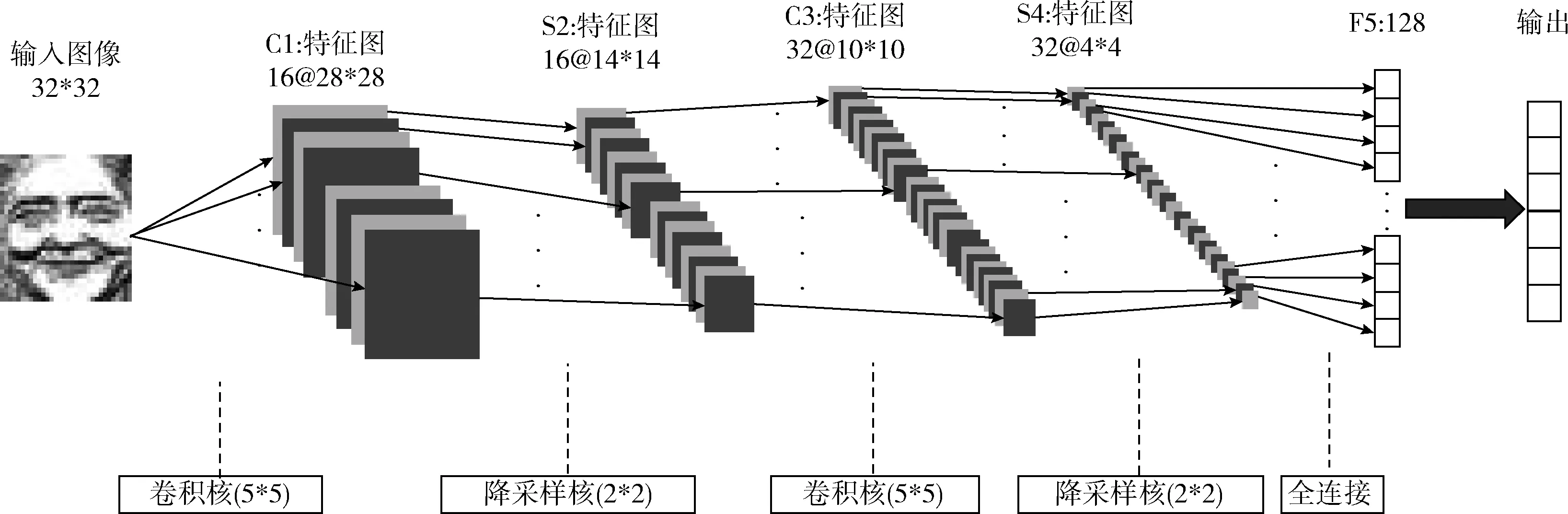
图7 深度卷积神经网络架构
1.2.1 卷积层
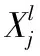
(1)
输入特征图的卷积核都是相同的,对于一个特定特征图都有一个偏置系数,通过选取的组合作为输入的特征图。卷积层是从图像的很小领域块接受输入,当神经元的输入块维度大于特征图维度时,神经元快会在不同领域块重复加权计算,构成权值共享。CNN使用随机梯度下降法计算神经元之间的突触权重,这种方法由Buttou等[16]提出。卷积层和全连接层的突触的初始值,是由Gulcehre C等[17]提出的,如式(2)所示
(2)
其中,Fin为输入的维度,Fout为输出的维度,W为突触的初始化值。式(3)所示神经元网络中的权值由t时刻到t+1时刻的更新过程
W(t+1)=W(t)+ηδ(t)x(t)
(3)
其中,η是学习速率,x(t)为神经元的输入,δ(t)为其误差项。为了使得模型获得图像的平移不变性和增强模型的泛化能力,采用Lecun等神经视觉感受野的概念。局部感受野使得神经元可以提取基本的视觉特征,主要是眼睛,眉毛和嘴唇的形状,棱角和边缘。当特征被检测到,由于在不同的人脸图像绝对位置可能是不同的,因此它的绝对位置信息被淡化,只要此特征相对其它特征位置的特征是相关的。比如惊讶表情,由于个体差异性不同,眉毛的精确位置不同,但是眉毛和眼睛之间相对距离可以区别面部是否呈现一个惊讶表情的趋势。每个卷积层之后通常有一个降采样层,是因为在映射条件下,造成不同特征的编码位置不同,减少位置精度的一个简单的方式时减少映射图像的控件分辨率。
1.2.2 降采样层
降采样层的目的是减少特征图的空间分辨率[18],在图像进行平移、扭曲、比例变化和旋转的操作时,减少了输出的敏感性。降采样的计算过程如式(4)所示
(4)
其中,将采样函数为down(),采样窗口是将图像分割成若干个均匀分布的小块,其目的是为了降低分辨率来得到缩放不变性,每个输出特征图都有自己的乘性偏置参数β和加性偏置参数b。
1.2.3 全连接层和Softmax层
全连接层与一般神经网络相类似,它的神经元与之前的网络层相连接,目的在于增加神经网络深度,保持结构中深度和广度的平衡。全连接层接收所学习的特征集合,最后输出每个面部表情的置信水平。使用soft-max的逻辑函数(SoftmaxWithLoss)计算损耗。神经元的激活函数是ReLu,如式(5)所示。ReLu函数通常在深层架构中激活速率快[19]
ReLu(x)=max(0,x)
(5)
2 实验与分析
本节使用构建深度神经网络框架对3个公开可用的数据库进行实验,其中3个数据分别为:Cohn-Kanada(CK+)、The Japanese Female Facial Expression(JAFFE)、NIR&VIS数据库。评估环节的目标包括:原图像与预处理图像评估、数据集间的验证、与其它方法比较。在硬件平台上:本实验使用的GPU为NVIDA GeForce GTX 1080,其显存容量为8 G,CPU为Intel Core i7 3.7 GHz。软件平台:操作系统配置的是Linux Ubuntu 12.04,安装了Python 3.0、NVIDIA CUDA Framework 6.5和cuDNN库。
2.1 数据集
提出的系统使用CK+、JAFFE和Oulu-CASIA数据库进行了训练和测试。表1是3个数据库基本信息。

表1 3个数据库的基本信息
由于CK+、JAFFE、Oulu-CASIA数据集下样本数量少,需要进行数据提升,本文采用Keras框架下图像生成器(ImageDataGenerator),对图像生产器设置的训练参数见表2。
(1)CK+:选取该数据库6种原始表情图片一共572张,使用ImageDataGenerator进行数据提升,一共生成了12 834张图像,其中训练数据为12 054张图像,测试数据为780张图像。
(2)JAFFE:选取该数据库6种原始表情图片一共184张,使用ImageDataGenerator进行数据提升,一共生成了12 720张图像,其中训练数据为12 000张图像,测试数据为720张图像。
(3)Oulu-CASIA:选取该数据库6种原始表情图片一共2864张图像,使用ImageDataGenerator进行数据提升,一共生成了18 440张图像,其中训练数据为17 460张图像,测试数据为980张图像。
2.2 实验评估
2.2.1 原图像与预处理图像对比评估
为了比较原图像与预处理图像在卷积网络识别效果,在公开CK+数据集上设计了两组实验,在训练阶段使用相同训练参数,ImageDataGenerator图像生产器的训练参数见表3。
原图像识别结果如图8所示(表情编号0-生气,1-厌恶,2-害怕,3-高兴,4-伤心,5-惊讶),6类表情的识别率为89.89%。通过使用第1节中设计图像预处理与神经网络组合方案,在公开CK+数据集上进行实验,结果如图8所示,6类表情的识别率为94.56%。通过在CK+数据集上使用原图像和预处理对比的结果,见表4,在生气表情上识别率提高10.60%,在害怕表情上提高10.19%,在伤心表情上提高14.12%,平均识别率也得到了提高,在原始图像上每个Epochs大约为10 s,在预处理图像上每个Epochs为5 s,训练阶段总体时间也减少了一倍,从以上数据说明了本文在预处理和深度模型框架组合方案对面部微表情识别率比使用原图像使用卷积神经网络的方法更加高效。为了进一步体现本文提出的方案,在下一小节设计了对3个标准数据进行验证。
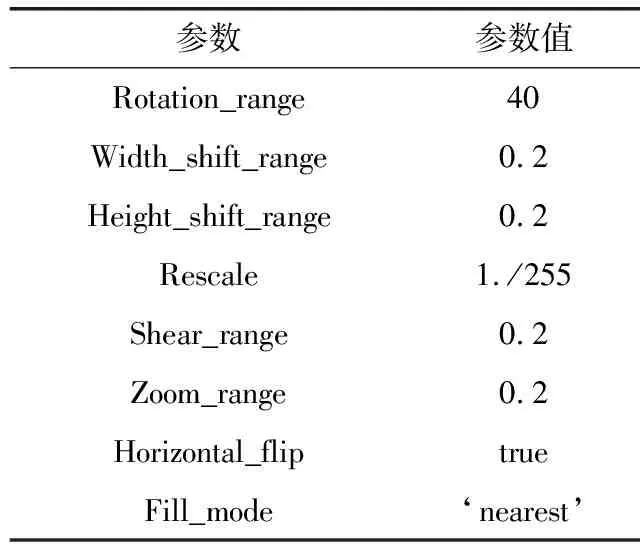
表2 ImageDataGenerator训练参数
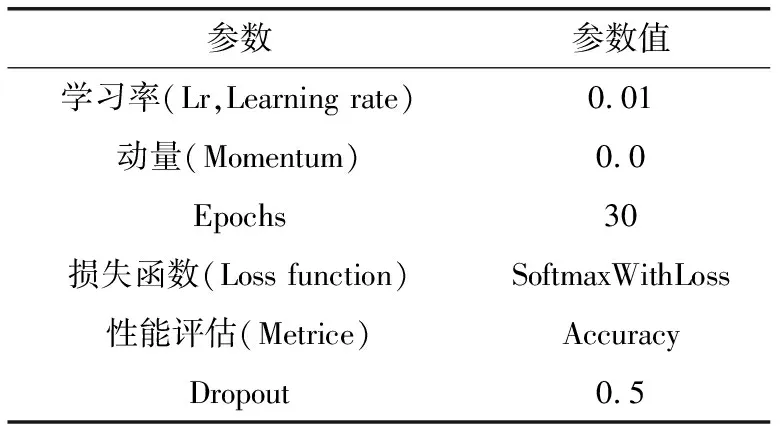
表3 训练参数
2.2.2 数据集间评估
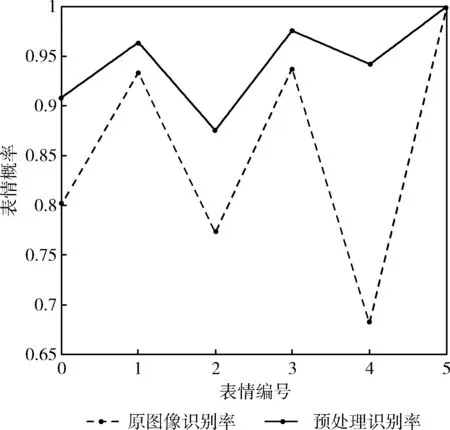
图8 预处理与原图像在面部微表情上的识别率

图像生气厌恶害怕高兴伤心惊讶时间/s识别率/%原图像80.10%93.25%77.31%93.75%68.25%99.89%30088.76LBP图像90.70%96.275/%87.50%97.58%94.12%100%15094.58

图9 3个数据集对6种面部微表情识别的混合矩阵(confusion matrix)
本节分别在CK+、JAFFE和Oulu-CASIA NIR&VIS数据集上使用预处理与深度框架组合方案得到混合矩阵(normalized confusion matrix),图9(a)是在CK+数据集上使用本文框架所得混合矩阵,图9(b)是在JAFFE数据集上所得的混合矩阵图,图9(c)是在Oulu-CASIA数据集上所得混合矩阵。表5是3个数据库的面部识别率。训练阶段30个Epochs(大约3000次迭代)对应的损失(Loss)和预测值(Accurcay)分别在CK+、JAFFE和Oulu-CASIA数据集如图10(a)、图10(b)和图10(c)所示,3个数据库都在第25个Epochs之后收敛,根据混合矩阵和面部微表情的识别率和损失率和识别曲线表明,提出的方法能够有效的用于识别面部微表情。
从整体实验结果来看,3种数据集的6种表情识别率都在80%以上,尤其在生气、高兴、惊讶3个表情识别率都在90%以上,这表明使用预处理与深度卷积神经网络组合方案,对3个数据集训练出的各个模型有很好的表现,而且在训练阶段的运行时间都在160 s左右,结果表明,提出的预处理与深度卷积神经网络方案能够很好融入3个数据集,体现了该方案具有较强稳定性和训练速度快的能力。
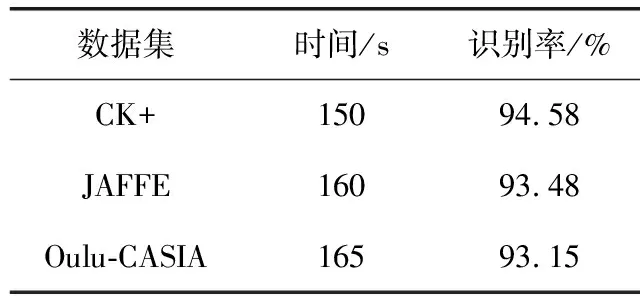
表5 使用本文方法在3个数据集上识别率
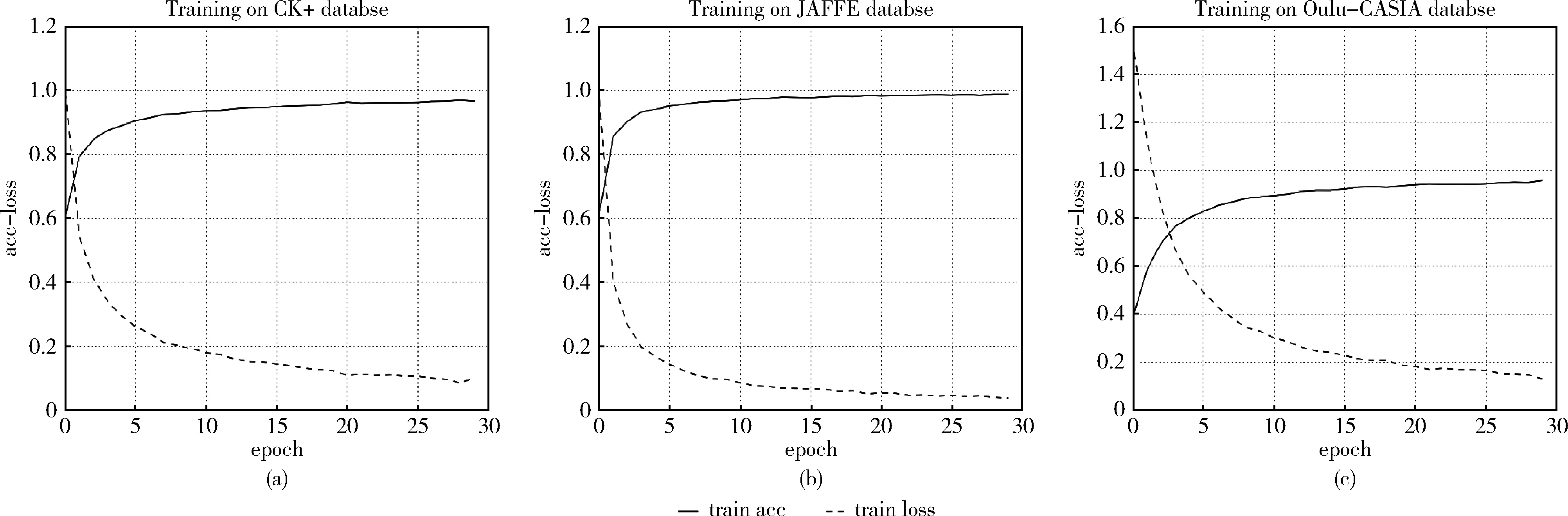
图10 3个数据集上训练阶段的损失率和准确率
2.2.3 与其它方法比较
为了比较本文方法与其它方法在面部表情的性能,设计了另一组实验(SVM+CNLF),在公开CK+数据集上,与SVM、PCA、ASM等方法进行了比较,本文列出了人工提取特征方法和基于深度学习方法进行对比,其中本文图像预处理和深度卷积网络组合方案体现了在传统的数据集上有非常优异的表现。见表6。
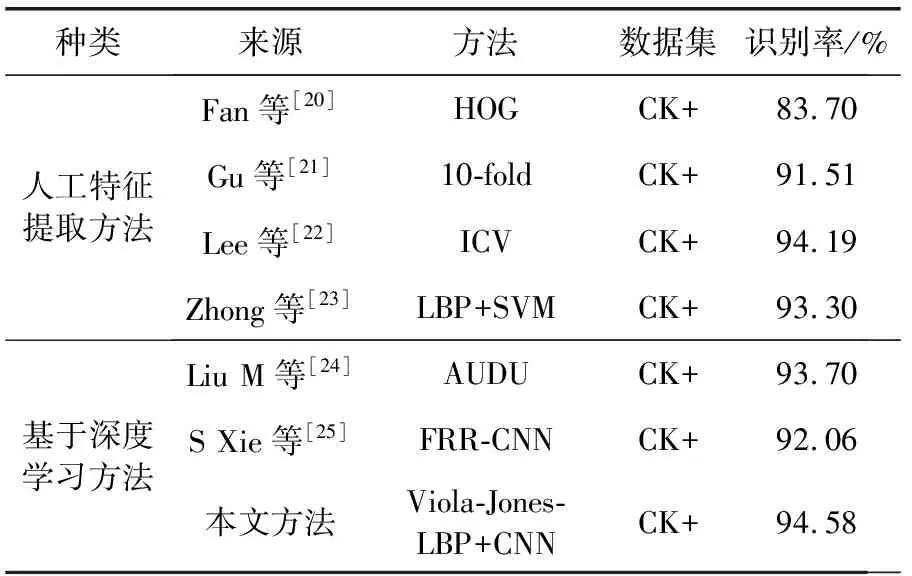
表6 在CK+数据集的模型对比
3 结束语
由于面部表情数据量小且如何利用少量原始数据提高表情识别率是一个难题,本文对此进行了研究。深度神经网络的目的无需人工干预,直接将原始数据输入进网络,自动进行特征选择,由于一张图像背景比较复杂,包含的噪声(背景)比较多,影响面部表情识别率和神经网络的运行时间。因此,本文使用Viola-Jones框架提取面部表情的感兴趣区域,提取感兴趣区域的LBP图像,使得在图像预处理阶段具有鲁棒性,以减少图像之间的变化并选择要学习的特征,以简易快捷的方式,间接地观测了模型地情况,对于深度卷积神经网络这样的模型,有很好的提升效果。
本文使用图像预处理与深度卷积神经网络的组合方案,在3个数据集(CK+,JAFFE,Oulu-CASIA)上进行了评估,实验结果表明使用该方案降低了在训练阶段所用的时间,在3个数据库上的识别率分别为94.58%,93.48%,93.15%,体现了本文提出的预处理和深度卷积神经网络组合方案对面部表情识别有很大的优势。
