基于改进长效递归卷积网络的行为识别算法
2018-07-19王学微
王学微,徐 方,贾 凯
(1.中国科学院 沈阳自动化研究所 机器人国家重点实验室,辽宁 沈阳 110016;2.中国科学院大学,北京 100049;3.沈阳新松机器人自动化股份有限公司 中央研究院,辽宁 沈阳 110168)
0 引 言
识别视频序列中人体的行为,不仅要利用每一帧图像上空间信息,还要充分利用帧与帧之间的时序信息。因此,如何有效表达单帧图片的空间信息以及如何获取帧与帧之间的时域信息成为行为识别领域的研究重点。Ji等[1]对卷积神经网络进行扩展,提出3D-CNN(3D-convolution neural networks)网络,通过使用3D卷积核获取帧与帧之间的时域信息与静态信息;Varol等[2]进一步完善3D卷积核,极大地提高了识别准确率;Simonyan等[3]通过引入光流信息来获取帧间时域信息,该方法使用两个卷积神经网络分别处理静态帧和光流数据;Wang等[4]在两个数据流网络结构基础上,使用更复杂的卷积神经网络,从而提高了行为识别的准确率;Jeff Donahue等[5]综合利用CNN网络与LSTM网络,提出长效递归卷积网络(long-term recurrent convolution network,LRCN)模型,然而LRCN算法中使用浅层ZFNet[6]作为CNN网络,很大程度上限制了整个模型对行为的识别能力。算法对LRCN算法进行改进,使用深度卷积神经网络VGG16[7]提取空间特征,提出长效递归深度卷积神经网络(long-term recurrent deep convolution network,LRDCN)算法。在公开数据集UCF101上的实验结果表明,该模型较好提高了人体行为识别准确率。
1 深度学习基本模型介绍
1.1 卷积神经网络
卷积神经网络(convolution neural networks,CNN)是一种深度学习模型,通过卷积以及下采样等操作,可以从图片中逐层提取更高级更抽象的特征。卷积神经网络一般处理二维图像,在数据充足条件下,合理训练的卷积神经网络可以有效提取图像的空间特征,在很多领域其性能明显好于手工设计的特征。
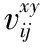
(1)
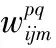
1.2 递归神经网络及其改进模型
与CNN不同,递归神经网络(recurrent neural network,RNN)无需在层面之间构建,能够更好地处理高维度信息的整体逻辑顺序。递归神经网络中,通过一个闭环允许网络将每一步产生的信息传递到下一步中,一个RNN网络可以看作同一网络的多份副本,每一份都将信息传递到下一副本。RNN网络以及其展开的等效网络结构如图1所示。

图1 递归神经网络及其等效模型
RNN这种链式结构非常擅长处理序列形式的数据,在语音识别、机器翻译、图像标题等领域得到了广泛应用。在普通RNN中,重复模块结构非常简单,只包含一个非线性函数g,此时网络输出RNN前向公式为
(2)
式中:xt代表当t时刻的输入,ht-1代表(t-1)时刻隐层输出,ht是t时刻隐含层的输出,zt为t时刻的网络的输出。
当序列太长时,普通RNN网络存在梯度消失的问题,难以训练。针对此问题,提出很多改进版本的RNN,其中最具代表性的是LSTM(long short term memory)网络,LSTM单元结构如图2所示。
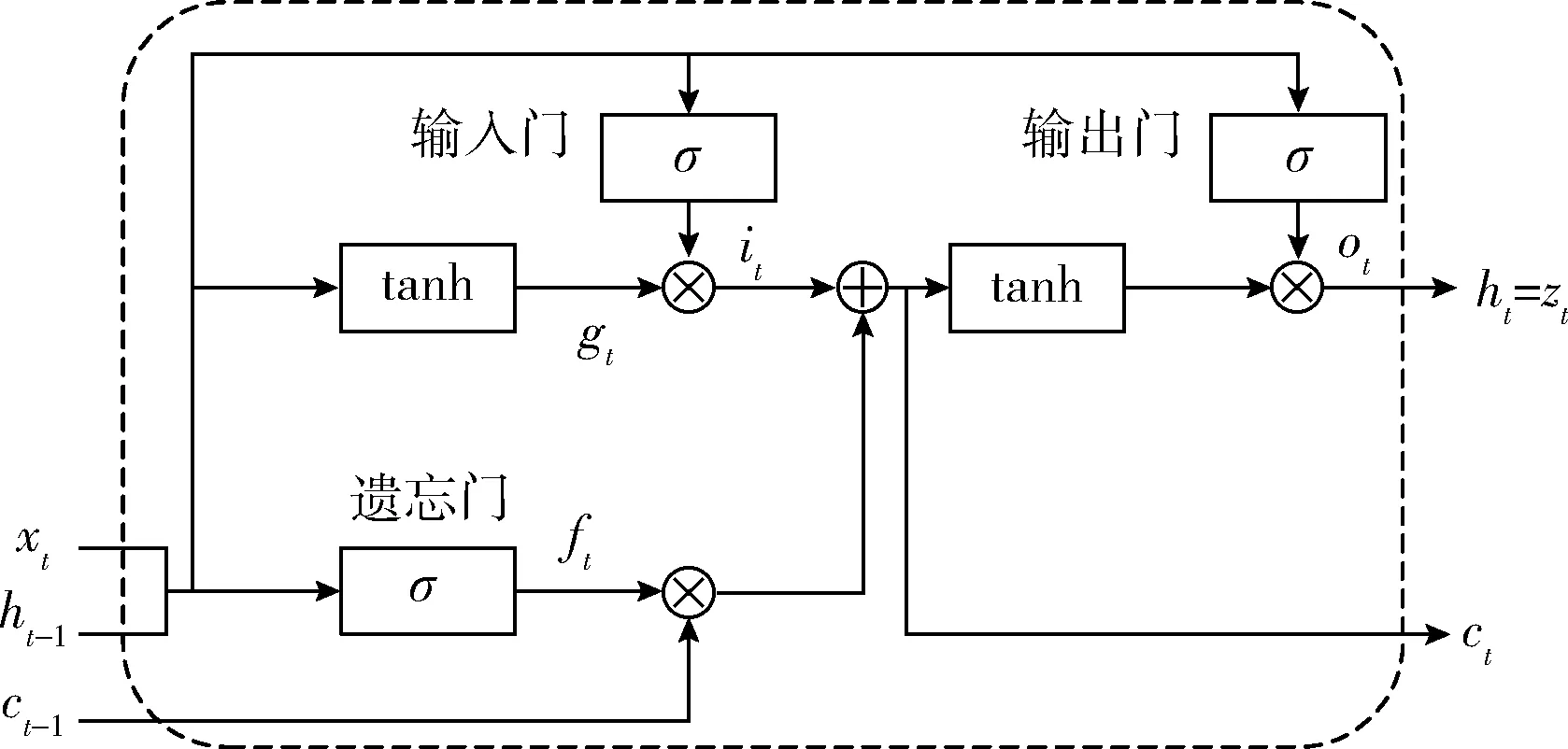
图2 LSTM单元结构
LSTM单元通过输入门、输出门、遗忘门来控制重复模块的输入与输出,其前向递推公式为
(3)
2 LRDCN算法描述
2.1 模型结构
LRDCN由深度卷积神经网络以及LSTM网络组成,网络结构如图3所示。其中深度卷积神经网络为VGG16[7],VGG16有13个卷积层以及3个全链接层,其中前两个全链接层都含有4096个结点,第3个全链接层结点个数与待分类问题相关,由于VGG16网络仅用于从224*224大小的输入图片中提取1*4096维特征,顾只使用前两个全链接层。与一般CNN网络相比,虽然VGG16也是由卷积层以及池化层堆叠而成的,当其使用了更小的卷积核,网络中所有卷积核大小均为3*3,步长为1。池化窗口大小为2*2,步长为2,但并不是所有卷积层后都有池化层,仅部分卷积层后存在池化层。另外,网络中均使用Relu函数作为非线性映射函数。
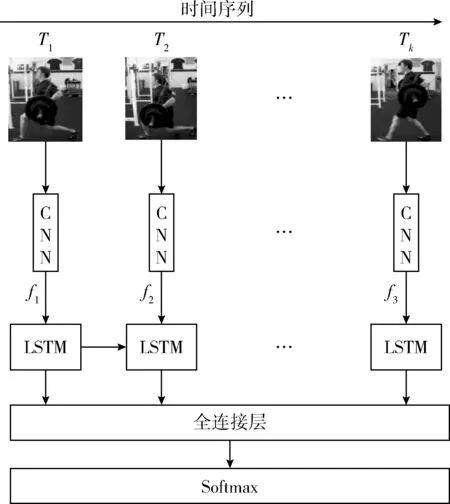
图3 LRDCN网络结构
对于长度为k的视频序列
k表示输入到网络的视频序列长度,理论上k可以取任意非零正整数,且希望k能够涵盖整个行为执行周期,但随着k增大,网络计算复杂度极具增加,使得训练和使用网络都变得十分困难,同时为了与LRCN算法对比,实际训练与测试时k值统一设置为16。
2.2 模型训练
2.2.1 数据预处理
在行为识别领域,RGB图像和光流数据得到广泛应用,在很多算法中,结合光流数据与RGB图像的结果会进一步提升行为识别的准确率,因此分别使用RGB图像以及光流数据分别训练LRDCN网络。其中RGB图像以30 fps的帧率从视频数据中抽取,每张图片大小为320*240,如图4(a)所示。光流通过opencv中实现的TVL1算法得到,并采用文献[5]中的方法构建“光流图”。首先将水平方向光流值和垂直放向光流值放缩到[-128,+128]区间,然后利用调整后的水平方向光流值、垂直方向光流值、光流模值构建三通道的“光流图”,如图4(b)所示。

图4 输入数据
2.2.2 参数设置
孔老一探了探身子,只见一片从来没见过的黄色大雾从鬼子方向飘了过来,他赶紧脱了上衣,浸透水,把嘴和鼻子紧紧捂上。军官培训时教官讲过鬼子的毒气弹,但毒气弹是国际公约明令禁止的化学武器,日本也是签约国,难道他们真的疯狂到使用毒弹的地步?
使用UCF101数据集对LRDCN网络进行训练、测试。该数据集共13 320段视频样本,训练样本只有10 000个左右,用如此有限的数据集训练大规模深度学习神经网络非常容易发生过拟合问题。实验采取以下几种策略训练网络,以降低网络过拟合的风险:
数据增广:随机裁剪是常用的数据增广手段,传统的随机裁剪方法是在输入图片中随机截取一块固定大小的图片,从而增加样本数量。与传统的随机裁剪策略不同,使用文献[4]中的方法,不仅随机选择裁剪区域,裁剪区域的宽和高也是从{256,224,192,168}这4个数中随机选则的。最后将裁剪得到的图片调整至224*224,作为VGG16网络的输入。
预训练:通过预训练,可以提高收敛速度、降低网络过拟合风险。首先使用UCF101数据集优调在ImageNet上训练好的VGG16模型,然后用优调过的VGG16初始化LRDCN网络的CNN部分。由于光流数据经过调整,可以将光流当作RGB图像处理,所以在用光流数据训练网络时,用光流数据优调通过RGB图像训练得到的LRDCN模型。
学习率以及迭代次数:由于网络已经预训练过,使用更小的学习率可以减弱过拟合现象。当输入RGB图像时,基础学习率设置为0.001,每迭代8000次,学习率缩小10倍,迭代20 000次时停止训练。当输入光流数据时,基础学习率设置为0.001,每迭代20 000次,学习率缩小10倍,迭代70 000次时停止训练。
Dropout值设置:Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的节点可以暂时认为不是网络的一部分,训练过程中通过一定的概率随机抽选不工作的节点,从而增加网络的泛化能力。当使用RGB图像训练网络时,将VGG16网络的全链接层和LSTM层的dropout值设分别设置为0.9和0.5;当使用光流数据训练网络时,将VGG16全连接层和LSTM层的dropout值分别设置为0.7和0.5。
2.3 模型测试
定义同一视频中连续的16帧作为一个测试单元,以8帧为步长,则长度为T的视频序列中共含有(T-16)/8+1个测试单元。将每个测试单元分别输入到LRDCN网络中,最后取(T-16)/8+1个测试结果的平均值作为该段视频的最终标签。
3 实验结果及分析
3.1 数据集介绍
UCF101[8]数据集包含101类行为,行为涵盖体育运动、乐器演奏、人与人的日常交互等方面,每类行为至少有100段视频,一共包含13 320段视频。UCF101数据集官方将这13 320段视频采用3种不同的划分方式,从而获得3组不同的训练、测试集合。每组训练数据集和测试数据集分别含有10 000段和3000段左右视频,在使用时,训练数据集与测试数据集必须成对使用,不得交叉使用。最终取在3组测试数据集合上的平均准确率作为最终结果,为与其它文献对比,准确率以均值方式给出。
3.2 实验结果
(1)特尔至强处理器E5-2603 v4;
(2)NVIDIA Tesla K80 GPU;
(3)Ubuntu 14.04;
(4)CUDA7.5。
3.2.1 VGG16网络fc6与fc7层特征对精度的影响
VGG16网络的fc6层与fc7层均提取得到1*4096维的特征,但实验发现,无论使用RGB图像或者使用光流数据,fc6层特征要好于fc7层特征。如表1所示,当使用RGB图像时,fc6特征比fc7特征高0.7%;当使用光流数据时,与fc7特征相比,使用fc6特征准确率会提高1.6%,因此,后续实验中均使用fc6层特征。

表1 卷积特征对结果影响
3.2.2 LSTM单元隐含层维度对精度的影响
LSTM单元隐含层维度对识别精度影响较大,实验分析隐含层维度从128提高到1024对精度的影响,实验结果见表2。当输入RGB图像时,LSTM隐含层维度从128增加到1024,其识别准确率提高4.94%。对于光流数据,当LSTM隐含层维度从128增加到512时,识别率提高4.7%,但当从512增加到1024时,准确率并没有明显区别。由于随着隐含层维度的提高会导致训练时间的增加,并且存在过拟合风险,因此在输入RGB图像时,LSTM单元隐含层维度设为1024,当输入光流数据时,设置为512。
3.2.3 综合RGB与光流图
RGB图像与光流图像在信息上存在很好的互补性,结合RGB图像与光流图像的预测结果会进一步提高识别精度,见表3。将RGB图像与光流图像预测结果进行1∶1融合后,准确率提高到83.43%;进一步将预测结果进行1∶2 融合后,准确率提高到84.68%。结果均好于改进前的LRCN算法。
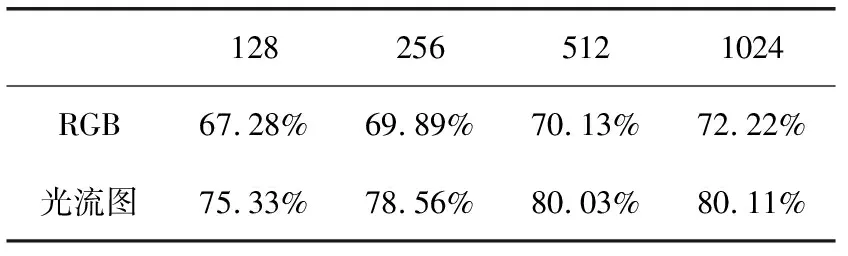
表2 不同LSTM隐层维度对精度影响
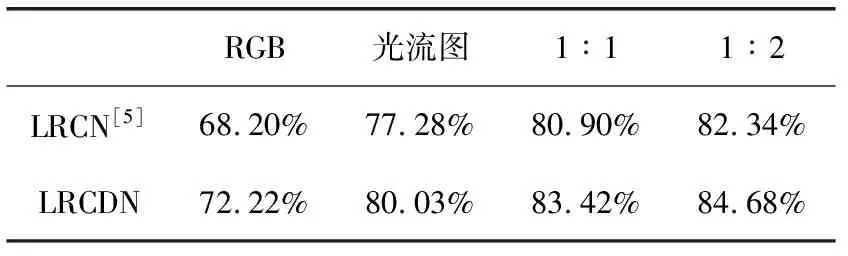
表3 不同LSTM隐层单元数对精度影响
3.3 UCF101数据集中不同算法的平均识别率
为了验证算法的性能,表4给出与其它算法在UCF101数据集上的识别精度对比结果,从表中可以看出,改进算法在UCF101数据集上取得了84.68%的平均识别率,高于其它算法。
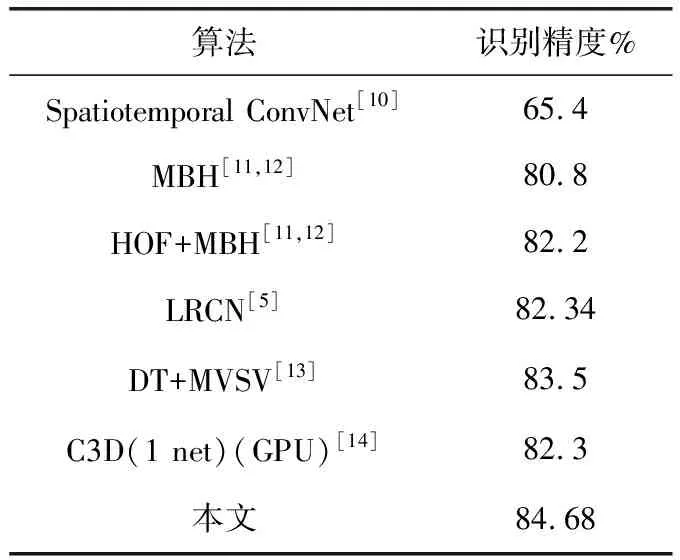
表4 不同算法综合对比
4 结束语
对长效递归卷积神经网络进行改进,提出LRDCN算法。使用预训练、数据增广等手段克服训练深度神经网络模型带来的过拟合问题。并通过实验分析了VGG16的fc6层与fc7层特征对识别精度的影响,以及LSTM单元隐含层维度对识别精度的影响。当结合RGB与光流信息时,在UCF101数据集上取得了84.68%的准确率,明显高于LRCN,验证了本算法的有效性。
算法中仅使用单层的LSTM网络,对获取视频序列的时域特征存在一定局限性,通过叠加LSTM层可以增强网络对时域信息的表达能力,未来会研究使用多层LSTM网络对行为识别精度的影响。
