基于神经网络的川崎病并发冠状动脉病变预测模型
2018-07-19谭续海贺向前
张 胜 田 杰 樊 楚 谭续海 李 哲 贺向前*
1(重庆医科大学医学信息学院,重庆 400016)2(重庆医科大学儿科学院,重庆 400016)
引言
川崎病(Kawasaki disease,KD)是一种以全身小血管炎为主要病理改变的小儿急性发热性疾病,最主要的并发症是冠状动脉病变(coronary artery lesions,CAL),易发展为缺血性心脏病,但目前川崎病引发冠状动脉病变的致病机制尚未明确[1-2]。因此,研究KD并发CAL的危险指标用于预测KD患者患CAL的风险性,对KD的预后具有重要的意义。
近年来,许多研究者用统计分析方法对KD并发CAL的危险因素进行了探讨。如Kim等对KD患者的数据进行多因素回归分析后得出,显著增高的C反应蛋白及发热超过8 d与冠状动脉瘤的形成相关[3]。Maric等对KD患者进行统计分析后得出,显著增高的血小板计数、年龄小于6个月及发热7 d以上,是形成冠状动脉瘤的独立危险因素[4]。段泓宇等人发现,KD并发CAL的高危因素是丙种球蛋白使用时间晚、发热10 d以上及高水平CRP[5]。但此类研究的样本量较少,选取的指标大多为以往文献报道过的因素,缺乏一定的创新性,并在疾病分类识别方面具有一定的局限性。因此,利用数据挖掘技术,研究计算机从临床病例中自动提取KD并发CAL的危险指标并预测患CAL的风险性,可为KD的预后提供一定的建议和决策支持。
数据挖掘主要研究从大量数据中发现知识的技术[6]。关联规则和神经网络都是数据挖掘的常用技术,关联规则常用于发现患者的临床数据与疾病发生可能性之间的关联关系,神经网络常用于疾病分类识别,它们在医学领域已得到广泛应用[7-8]。本研究利用关联规则对川崎病患者的病例数据进行分析,自动筛选KD并发CAL的危险指标,建立神经网络模型和Logistic回归模型预测KD并发CAL的风险性。
1 方法
本研究收集了重庆医科大学附属儿童医院2010年1月—2016年1月间就诊的1 000例川崎病患者的电子病历数据,包括人口学资料、实验室检查数据、超声心动图数据,患者均按照相应诊断标准确诊为患川崎病[1]。首先对数据进行预处理,其次用关联规则筛选川崎病并发冠状动脉病变的危险指标,将样本集随机划分为训练集(700例)和测试集(300例),分别用于建立神经网络模型和Logistic回归模型,并用灵敏度及特异性等指标对模型的预测效果予以评估。
1.1 数据预处理
未经预处理的数据通常是不规范的,有噪声和缺失值的,数据预处理是数据挖掘的首要步骤。本研究通过SQL Server2008数据库管理工具对数据进行预处理,主要包括数据清理、数据集成、数据变换[9]。在本研究中数据清理主要是处理空缺值,对缺失数据的比例较多的指标直接删除缺失值,对缺失数据比例较少的指标使用均值插补法填补空缺值;数据集成是将数据库中多个数据表中的数据进行合并;数据变换主要是将连续型的变量转换成离散型变量,根据不同变量的特点对各离散后的变量值进行规范化处理并编码。例如,根据超声心动图数据中Z-score取值将分类变量划分为未患CAL(Z-score<2.5)和患CAL(Z-score≥2.5),分别用NCAL和CAL表示;根据变量CRP的正常值范围是<8 mg/L,则划分为<8 mg/L和≥8 mg/L两个区间,分别用N、H表示。
原数据中共5 020例川崎病患者,其中患冠状动脉病变的患者仅343例,考虑到原数据中样本分布不平衡的问题,最终取1 000例(包括343例患CAL)KD患者的数据进行分析。取患者的基本信息、首次入院时的检验指标以及超声心动图冠状动脉内径Z值,清洗后共计53个变量,其中自变量52个,包括性别、年龄、C反应蛋白(C-reactive protein,CRP)、白细胞(white blood cell,WBC)、单核细胞(mono nuclear,MONO)、淋巴细胞(lymphocyte,LYM)、中性粒细胞(neutrophil,NEU)、血沉(erythrocyte sedimentation rate,ESR)、红细胞(red blood cell,RBC)、血红蛋白(hemoglobin,HGB)、红细胞压积(hematocrit,HCT)、平均红细胞体积(mean corpuscular volume,MCV)、平均红细胞血红蛋白(mean corpuscular hemoglobin,MCH)、红细胞分布宽度(red blood cell distribution width,RDW)、血小板计数(platelet count,PLT)、平均血小板体积(mean platelet volum,MPV)、大血小板细胞比(platelet-large cell ratio,PLCR)、血小板分布宽度(platelet distribution width,PDW)、血小板压积(thrombocytocrit,TCT)、嗜酸性粒细胞(eosnophils,EOS)、结合胆红素(conjugated bilirubin,CB)、总胆汁酸(total bile acid,TBA)、白蛋白(albumin,ALB)、血清补体(serum complement,SC)、胆红素(bilirubin,BIL)、尿蛋白(urine protein,PRO)、γ-谷氨酰转肽酶(gamma-glutamyl transpeptidase,GGT)、谷丙转氨酶(alanine aminotransferase,ALT)、谷草转氨酶(glutamic-oxalacetic transaminase,AST)、谷草与谷丙比值(AST/ALT,ASAL)、红细胞形态(red blood cell state,RS)、总蛋白(total protein,TP)、前白蛋白(pre-albumin,PA)、碱性磷酸酶(alkaline phosphatase,ALP)、酮体(ketone bodies,KET)、磷(phosphorus,PHOS)、氯(chlorine,CL)、尿素氮(usea nitrogen,BUN)、肌酐(creatinine,CTN)、肌酸激酶(creatine Kinase)、肌酸激酶同工酶(creatine Kinase Isoenzyme,CKM)、间接胆红素(indirect bilirubin,IBIL)、总胆红素(total bilirubin,TBIL)、镁(magnesium,MG)、钠(sodium,NA)、尿酸(uric acid,UA)、尿葡萄糖(urine glucose,GLU)、球蛋白(globulin,GLB)、乳酸脱氢酶(lactic dehydrogenase,LDH)、尿维生素C(urine vitamin C,UVC)、亚硝酸盐(nitrite,NIT)、总钙(total calcium,TCA)。应变量1个,包括患冠状动脉病变(CAL)343例和未患冠状动脉病变(NCAL)657例。其中,男684例(68.4%),女316例(31.6%);年龄小于2岁的566例(56.6%),2~5岁的311例(31.1%),5~7岁的74例(7.4%),7岁以上的49例(4.9%)。最后导出为Excel的.csv格式,得到可用于数据挖掘工具R[10]处理的初始数据集。
1.2 关联规则
关联规则是挖掘发现数据属性间的有趣关系的方法,关联规则可表示为X⟹Y,X为规则左边,代表预测指标;Y为规则右边,代表是否患CAL。X⟹Y反映X出现时,Y也出现的规律;支持度反映了X和Y同时出现的概率;置信度反映了X出现的条件下Y出现的概率;最小支持度描述了规则的最低重要程度;最小置信度描述了规则的最低可靠性,满足最小支持度和最小置信度的规则为强关联规则。提升度描述了X和Y的独立性,该值等于1说明X和Y没有任何关联,该值大于1时,强关联规则才有价值[11]。本研究约束条件设定最小支持度和最小置信度分别为0.01和0.9,提升度大于1,规则右边Y为CAL。调用R软件中arules关联规则函数包中的Apriori算法命令,读取数据集,找出满足约束条件的强关联规则,筛选KD并发CAL的危险指标。
1.3 预测模型
人工神经网络(artificial neural network,ANN)是利用生物学中神经网络的基本原理而模拟人脑的神经系统对复杂信息的处理机制的一种数学模型。BP神经网络是典型的多层前馈型神经网络,可分为若干“层”,各层按信号传输先后顺序依次排列[12]。BP神经网络常用于数据挖掘的分类问题,KD并发CAL的预测模型是个典型的医学分类问题。本研究中的BP神经网络结构见图1,其中输入层有27个离散型输入变量,输出层有一个分类变量,包括患冠状动脉病变和未患冠状动脉病变两种状态。
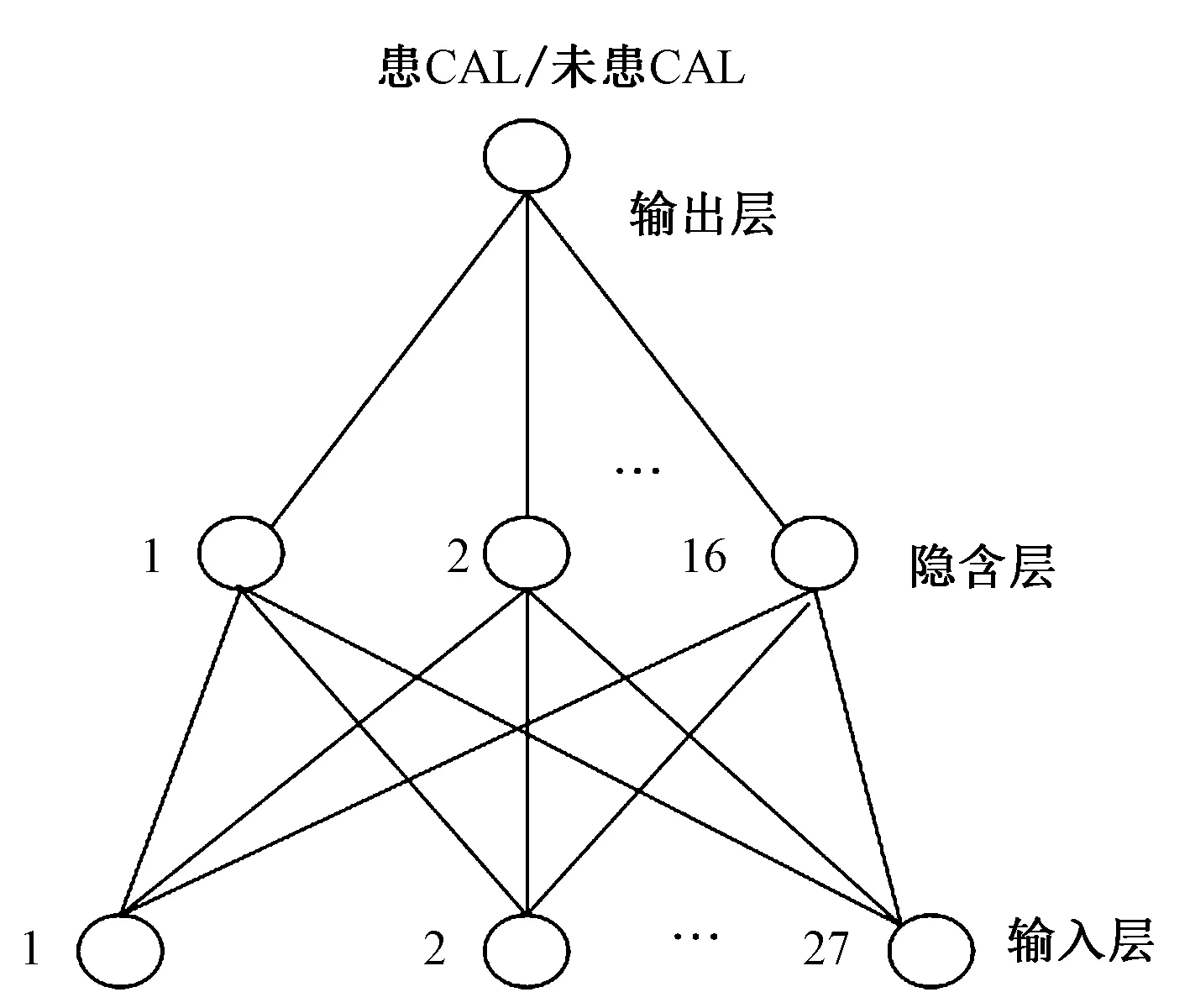
图1 BP神经网络结构Fig.1 The architecture of BP neural network
由于隐含层的节点数是未知的,而隐含层的节点数对模型的性能是有影响的,所以需要调节隐含层的节点数来调整神经网络模型的性能。确定隐含层节点数目的公式为
(1)
式中,h为隐含层节点数目,m为输入层节点数目,n为输出层节点数目,a为1~10之间的调节常数。
本研究的m为27,n为1,根据式(1),使h在7~16范围调节,分别建立模型并予以评估,确定最佳模型。
1.4 模型评估
将采用灵敏度、特异性、准确率及AUC(ROC曲线下面积)指标来评估模型的性能。混淆矩阵(confusion matrix)通常是评估分类器可信度的一个基本工具,是一种用来呈现算法性能的可视化效果的特定矩阵,见表1。

表1 混淆矩阵
通过混淆矩阵可计算:
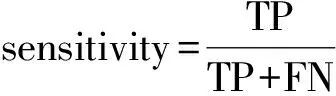
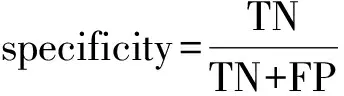
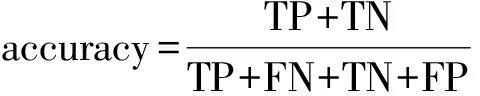
以及ROC曲线下的面积(area under the ROC curve,AUC)。在模型评估阶段,AUC常被用作重要的评估指标来衡量模型的准确性。通常,AUC的值介于0.5~1.0之间,AUC的值越接近1模型的效果越好[13]。
2 结果
2.1 关联分析结果
满足最小支持度0.01、最小置信度0.9、提升度大于1且规则右边Y为CAL的关联规则共83个,前30个规则中共有27个指标,包含性别、年龄及25个偏离正常范围的实验室指标,如表2所示,这些指标为:HCT、PLCR、CRP、PLT、AST、ASAL、ESR、MPV、MONO、ALB、KET、PHOS、CL、ALP、RBC、MCH、EOS、BUN、NEU、MCV、RDW、RS、PRO、TP、PA。由第1、2条规则可得,HCT、PLCR、CRP、PLT、ASAL及ESR是KD并发CAL的主要危险指标。其中,第2条规则可解释为CRP ≥8 mg/L, PLT ≥300×109/L, ASAL < 0.23, ESR ≥15 mm/h出现的条件下KD患者并发CAL的概率是0.91。
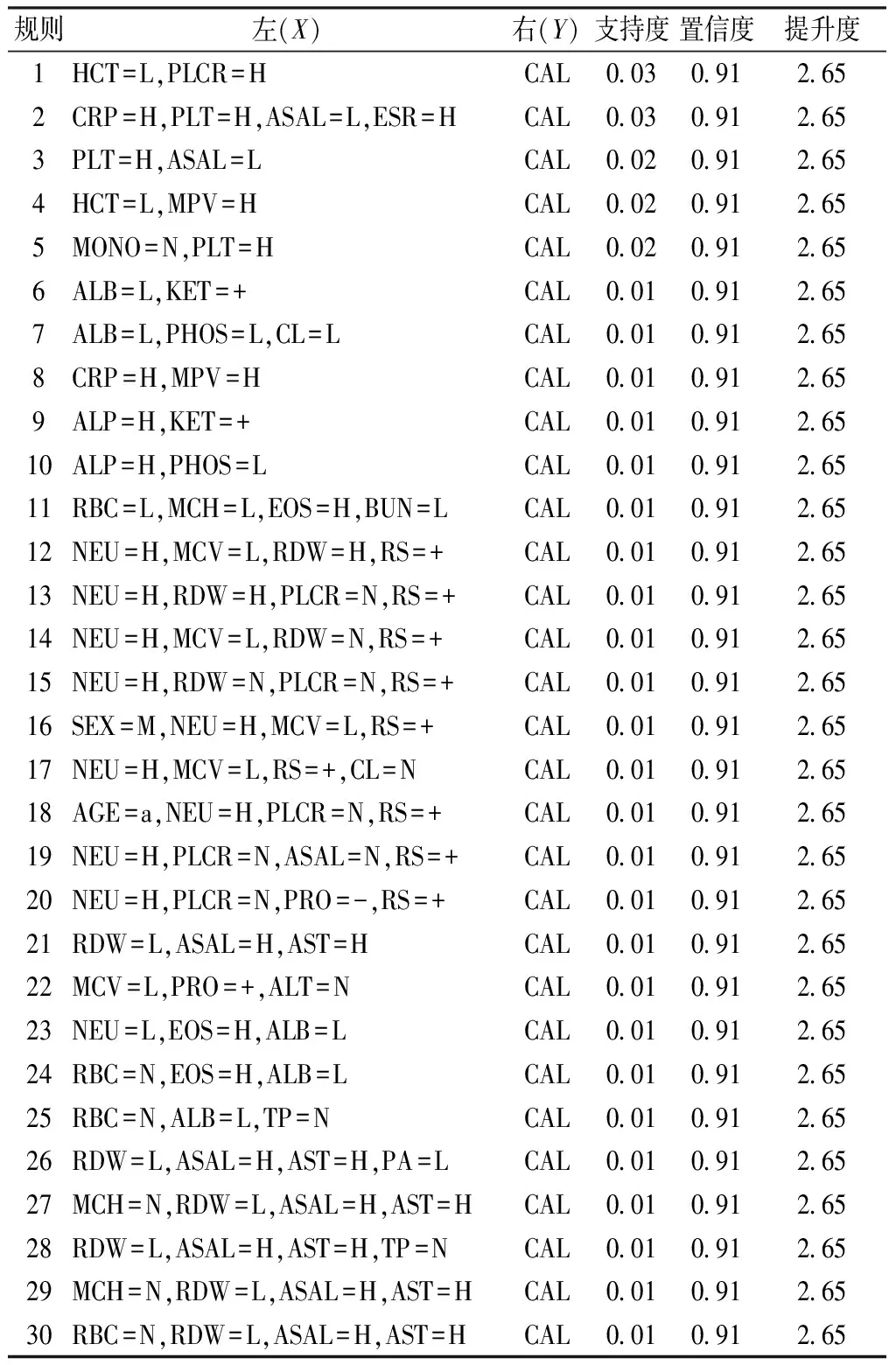
表2 强关联规则
2.2 预测模型
上述27个变量作为预测模型的输入变量,建立神经网络模型来预测KD患者并发CAL的风险。为了使模型得到充分训练,本研究采用随机抽样的方法,将样本集划分为训练集(460例未患CAL,240例患CAL)和测试集(197例未患CAL,103例患CAL)。
其中,训练集用于模型学习,测试集用于模型测试。在训练集上训练神经网络模型,通过设置不同的隐含层节点数,用灵敏度等指标来评估神经网络模型的学习效果,见表3。由表3可得,隐含层节点数为12时,模型的灵敏度达到最大。为了将更多患CAL的KD患者预测出,所以将隐含层节点数为12以下的模型确定为最佳模型。
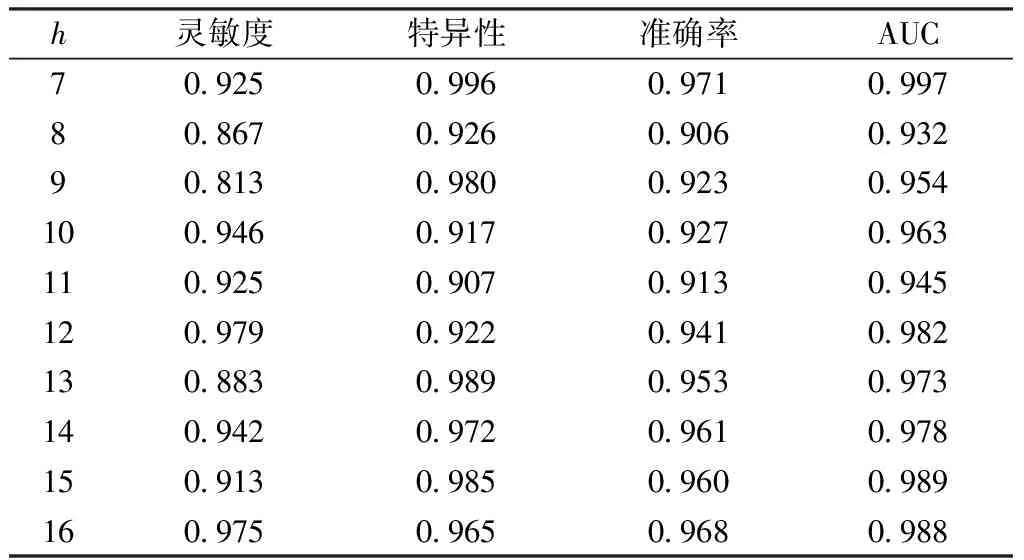
表3 不同隐含层节点数下的模型学习效果
用最佳神经网络模型在测试集上进行预测,检验模型的预测性能,得到混淆矩阵为真阳性74例,真阴性147例,假阳性50例,假阴性29例。用Logistic回归方法进行预测,得到混淆矩阵为真阳性18例,真阴性176例,假阳性21例,假阴性85例。
根据神经网络模型和Logistic回归模型各自的混淆矩阵,分别计算其评价指标,见表4。可以看出,神经网络模型的灵敏度、准确率及AUC指标优于Logistic回归模型的指标。因此,神经网络模型对川崎病并发冠状动脉病变的预测效果优于Logistic回归模型的预测效果。

表4 神经网络模型与Logistic回归预测效果的对比
3 讨论
本研究通过关联规则分析电子病历数据,自动高效地寻找变量与患病之间的关系,发现了CRP和NEU是KD并发CAL的主要危险因素。据以往文献报道,C反应蛋白反映了炎症的程度,所以推测炎症程度越高,发生CAL的风险越高[14-16]。中性粒细胞通过内皮细胞受损的部位渗透血管壁,释放出酶和炎性因子,导致血管壁损伤。急性期KD患者的免疫组化研究显示,冠状动脉内皮细胞中存在大量的中性粒细胞黏附[17]。因此,CRP水平偏高、中性粒细胞数量增多的KD患者有显著较高的CAL发生率。特别地,在强关联规则中发现:CRP ≥8 mg/L, PLT ≥300×109/L, ASAL < 0.23, ESR≥15 mm/h出现的条件下KD患者并发CAL的概率是0.91。关联规则可发现多个因素共同与疾病相关联,在一定程度上弥补了单因素统计分析方法的不足。
本研究使用关联规则的目的是筛选指标,结合临床医生综合分析,寻找对预测作用较大的特征,且摒弃对预测作用较小甚至毫无作用的特征,进而进行预测建模,达到数据降维的功能。但是与传统降维的方法又有所区别,比如主成分分析方法通过正交变换,起到降维的作用,不过部分参数旋转或平移,参数变量与实际问题的关系缺乏直观感,解释理解较为困难,不利于问题的分析。通过实验发现,关联规则筛选参数虽不是最有效的方法,且仍然有可能存在相关性的参数,但实验中可以不用剔除太多的参数,运算速度尚可。采用关联规则剔除的相关参数,尽管与多位医生探讨确认过,确实没有多大用处的才考虑剔除。但是,不能排除这些参数完全与CAL无关,后续研究将尽可能多地分析参数,利用大数据的思维,尽可能去发现之前文献报道之外或者医生忽略的一些参数与川崎病并发冠状动脉病变的关系,确实没有用处的参数才考虑剔除。本研究仅纳入了实验室检验指标用于预测KD并发CAL的风险性。事实上,患者发热天数以及丙种球蛋白使用时间也是KD并发CAL的重要危险因素[3-5]。下一步计划将临床体征及用药情况等数据一并纳入分析。
本研究通过评估和对比人工神经网络模型和logistic回归模型的预测性能,发现神经网络模型对KD并发CAL的预测效果优于Logistic回归模型,与以往多项研究结果类似,均显示神经网络较Logistic回归具有更准确的疾病预测能力[18-20]。因此,神经网络在疾病的分类识别应用上相比统计方法更具有优势。目前,广泛用于分类识别的数据挖掘算法还有决策树、贝叶斯网络、支持向量机等。后续研究将这几种数据挖掘算法纳入研究分别进行建模,评估和对比模型的预测性能,以期找到最优的KD并发CAL的预测模型。
4 结论
结合关联规则及神经网络数据挖掘方法对KD患者的电子病历数据进行分析,相对于统计分析方法更具有优势,不仅能自动高效地寻找变量与患病之间的关系,且建立了KD并发CAL的风险预测模型,可为川崎病的预后治疗提供一定的建议和决策支持。
