CUDA-TP:基于GPU的自顶向下完整蛋白质鉴定并行算法
2018-07-19何增有
段 琼 田 博 陈 征 王 洁,2 何增有,2
1(大连理工大学软件学院 辽宁大连 116620) 2 (辽宁省泛在网络与服务软件重点实验室(大连理工大学) 辽宁大连 116620) (wangjie1003@163.com)
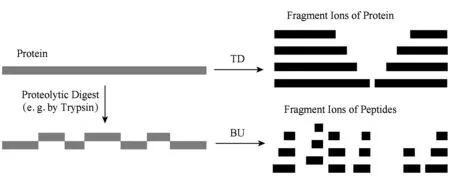
Fig. 1 Comparison between TD and BU for protein identification图1 蛋白质鉴定中的TD与BU方法对比
蛋白质组学(proteomics)是一门新兴学科,主要研究细胞内表达的所有蛋白质及其活动规律[1].由于基因的作用最终是由蛋白质(protein)来体现,所以蛋白质组学的研究有着更为重要的实际意义和价值.蛋白质组学的一个重要目标是能够快速有效地进行蛋白质鉴定,即确定一个样本中表达的所有的蛋白质.蛋白质是由氨基酸分子链接而成的生物大分子,蛋白质的一级结构(氨基酸序列)唯一确定了蛋白质的身份,因此可以通过识别氨基酸序列达到鉴定蛋白质的目的.只有鉴定到生物样品中真实表达的蛋白质,才能准确获得蛋白质相互作用、亚细胞定位等信息,为进一步的疾病标记物发现和新药开发提供强有力的支持[2].因此,蛋白质鉴定是蛋白质组学研究的基础,对整个领域的进一步发展和应用有着十分重要的意义.
为解决蛋白质鉴定问题,目前以生物质谱为基础的蛋白质组学分析方法主要有“自底向上”(bottom-up, BU)和“自顶向下”(top-down, TD)二种方法[3],2种方法比对如图1所示.BU方法通常先将蛋白质的复杂样品进行酶切产生肽段的混合物;然后通过液相色谱等技术将这些肽段的混合物进行分离,进而通过质谱技术将肽段碎裂,并根据碎裂谱图中的离子峰信息进行数据库搜索来鉴定肽段;最后将鉴定到的肽段进行组装、推理获得样品中所含有的蛋白质[4-6].
BU是由肽段推测蛋白质序列,属于“从局部推断整体”.尽管BU已经在当前的蛋白质组学研究中广泛使用,但该类方法同样存在着一系列的局限[7]:
1) 由于并不是所有的肽段都可以有效地被捕捉到并生成二级谱图,导致很多蛋白质没有相应的肽段鉴定结果,进而无法鉴定到该蛋白质的存在;
2) 即使可以通过少数几个鉴定得到的肽段信息来推断蛋白质的存在与否,但是却不能测绘出整个蛋白质序列的全部信息,这主要包括蛋白质各种氨基酸位点上的翻译后修饰(post-translational modification, PTM);
3) 由于是通过肽段的鉴定结果间接地得到蛋白质的鉴定结果,而同一个肽段可以映射到多个不同的蛋白质序列,这就需要解决一个复杂的计算问题:蛋白质推断[8].而蛋白质推断问题目前尚未彻底解决,仍有很多计算上的挑战需要克服.
与BU策略相反,TD方法不需要将蛋白质“切割”成更短的肽段序列,而是直接将完整的蛋白质进行分离和离子化,然后对其进行碎裂并利用串联质谱测量由每个蛋白质生成的二级谱图.在数据分析阶段,通过比对数据库中的蛋白质序列和实验二级谱图进行蛋白质鉴定[9-10].这样,通过完整蛋白质的质量及其碎裂谱的信息可以实现真正意义上的蛋白质鉴定.另外,TD能够保留多种PTM之间的关联信息,逐渐成为蛋白质组学研究中的热点[5].
鉴于TD方法对于蛋白质鉴定具有重要的生物学意义,针对TD策略中完整蛋白质与谱图的匹配问题,已经提出了一些有效的算法.在这些方法中,ProSight[11-12]采用泊松分布概率打分模型计算蛋白质与谱图的匹配概率,用“鸟枪标注”的方法生成所有可能的蛋白质变体数据库.这种方法最大的问题是扩展性差,如果变体增多可能导致“组合爆炸”.Frank等人[13]借鉴谱图比对方法,以动态规划为基础开发了MS-TopDown算法,该算法能有效的鉴定蛋白质及未知的PTM.Liu等人[14]在此基础上通过优化动态规划显著提高了计算速度并提供了匹配的统计显著性评估方法.在此后,TopPIC[15],MASH suit[16],MSpathFinder[17],Ptop[18]等工具都是以动态规划为主体进行蛋白质数据库搜索并在不同的方面做了改进.然而,其面临的最大问题还是匹配时间不尽如人意,这是由动态规划算法所固有的时间复杂度决定的.
高性能计算的发展对计算速度的提升做出了巨大贡献.自2003年开始,图形处理器(graphics proc-essing units, GPU)就在浮点运算性能和存储器带宽上飞速发展.通用并行计算架构(compute unified device architecture, CUDA)[19]是由英伟达公司推出的高性能运算平台,它能够充分发挥GPU并行计算的优势.随着GPU可编程性的增强,GPU突破仅应用于图形处理领域的局限,开始用于一些通用计算领域[20-21],尤其是在生物信息学领域,为研究人员提供了新的思路.例如翟艳堂等人[22]提出的PTM鉴定算法MS-Alignment的并行架构,有效地提高了在肽段上检测PTM的效率;对于肽段鉴定问题,Zhang等人[23]通过CUDA架构将肽段鉴定算法RT-PSM[24]的速度提升了26倍;Baumgardner等人[25]成功对SpectraST[26]算法进行了并行计算加速;Li等人[27]也顺利地将谱图点积算法并行化.近几年来,CUDA并行计算架构更是在基因序列比对方面取得了全新的进展[28-30].
鉴于完整蛋白质与质谱数据匹配存在高耗时的缺点,本文借鉴谱图比对的思想,以MS-TopDown算法为基础,选择CUDA编程模型设计CUDA-TP算法核心步骤,即完整蛋白质与TD质谱匹配分数的计算.同时在计算步骤中引入平衡二叉搜索(adelson-velskii and landis, AVL)树来保存每个路径点上的信息并对MS-Filter[31]进行改进以加速蛋白质过滤.最后,本文选取常用的target-decoy[32-33]方法对结果进行错误发现率(false discovery rate, FDR)控制.实验结果表明:在1%的FDR下CUDA-TP运行速度分别是MS-TopDown和MS-Align+算法的10倍与2倍.
本文的主要贡献有3个方面:
1) 提出了一种新型的基于GPU的完整蛋白质与谱图打分算法,该算法是对MS-TopDown的并行优化,它继承了可以鉴定未知PTM的特点,同时得到的最终分数是谱图网格中的全局分数,并没有使用MS-Align+方法中缩减谱图网格搜索空间的策略.
2) 对MS-Filter算法进行改进加速了蛋白质过滤过程.
3) 使用真实数据集进行实验,验证了本文所提出的CUDA-TP算法的高效性.
1 问题定义
1.1 符号表示
通常情况下,可以把一个谱图转换为其相应的前缀残基质量(prefix residue mass, PRM)谱图来表示完整蛋白质的前缀肽段.例如二级串联谱图中一个质量为ma的y离子单同位素谱峰在PRM谱图中对应的质量为M-ma(M表示完整蛋白质质量).本文中,谱图中所有谱峰都为单同位素谱峰,每个谱峰的单同位素质量包含2个值:ma和其对应的M-ma.同时,谱图还包含1个空质量0与代表完整蛋白质PRM值的M-18(18表示1个水分子质量).具体而言,可以把谱图S表示为一个有序序列:
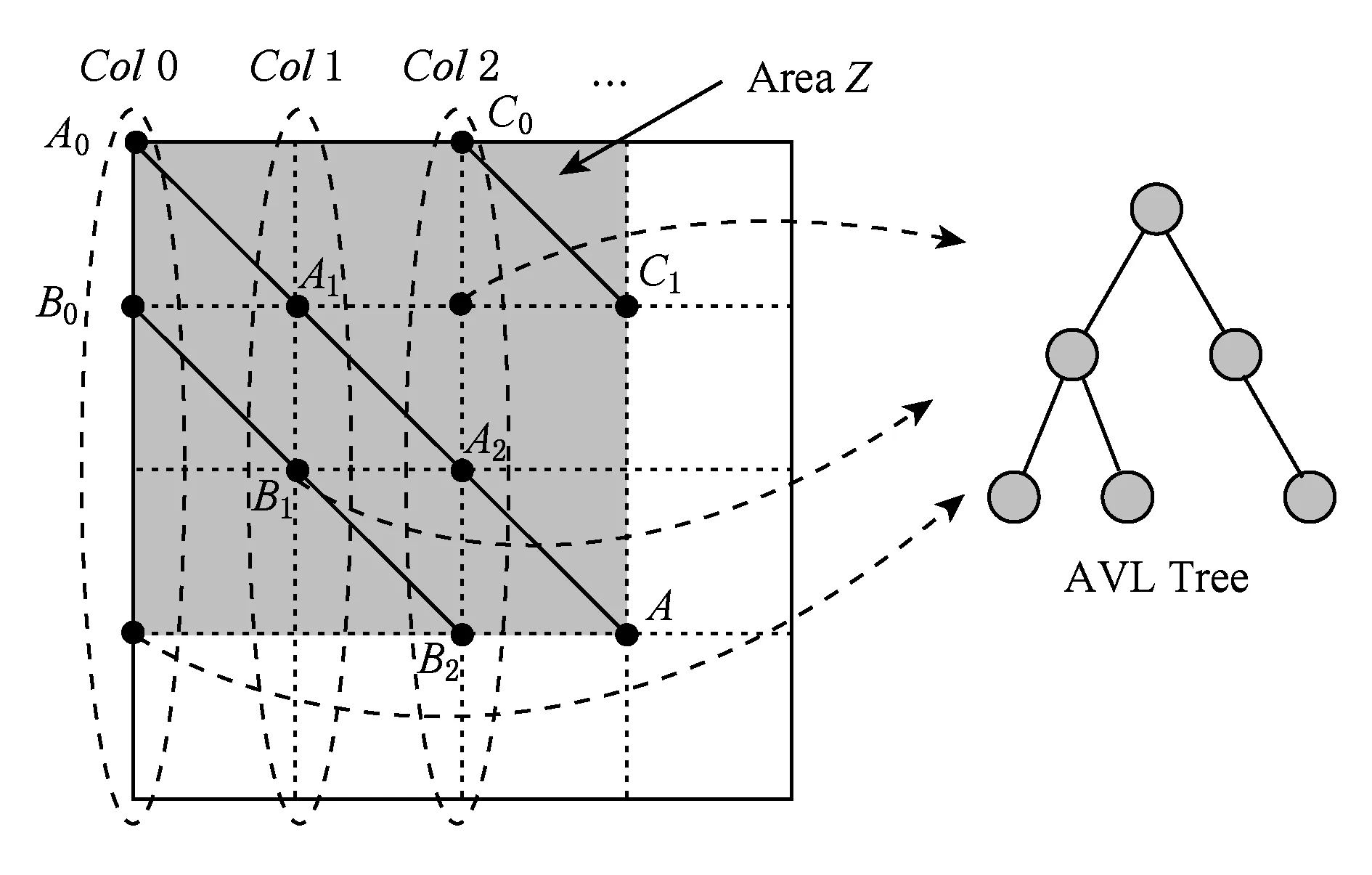
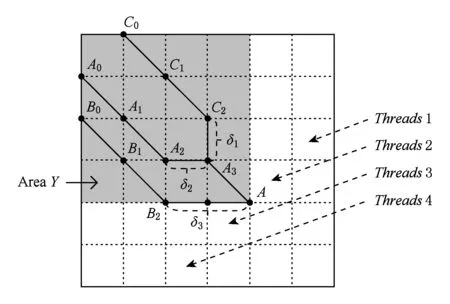
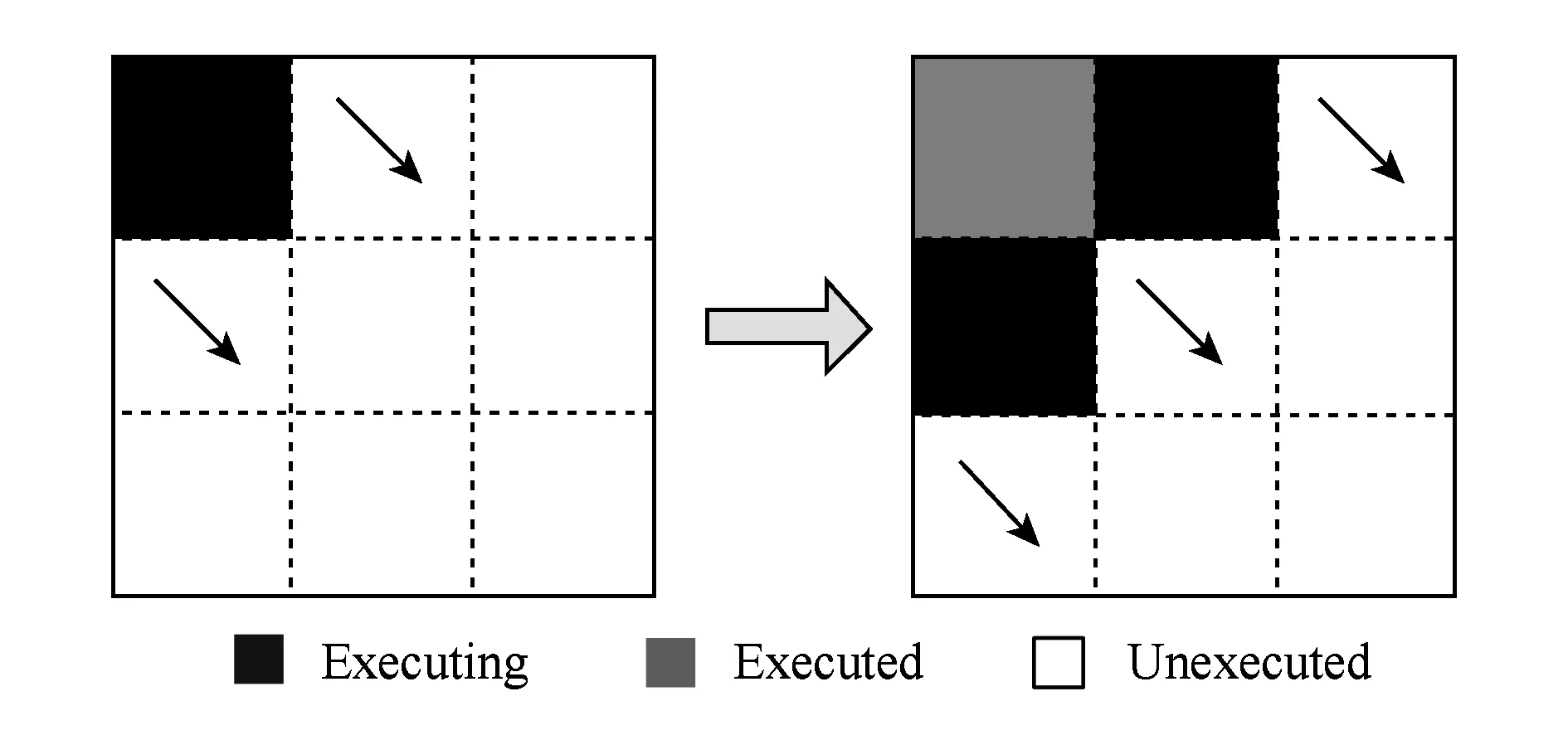
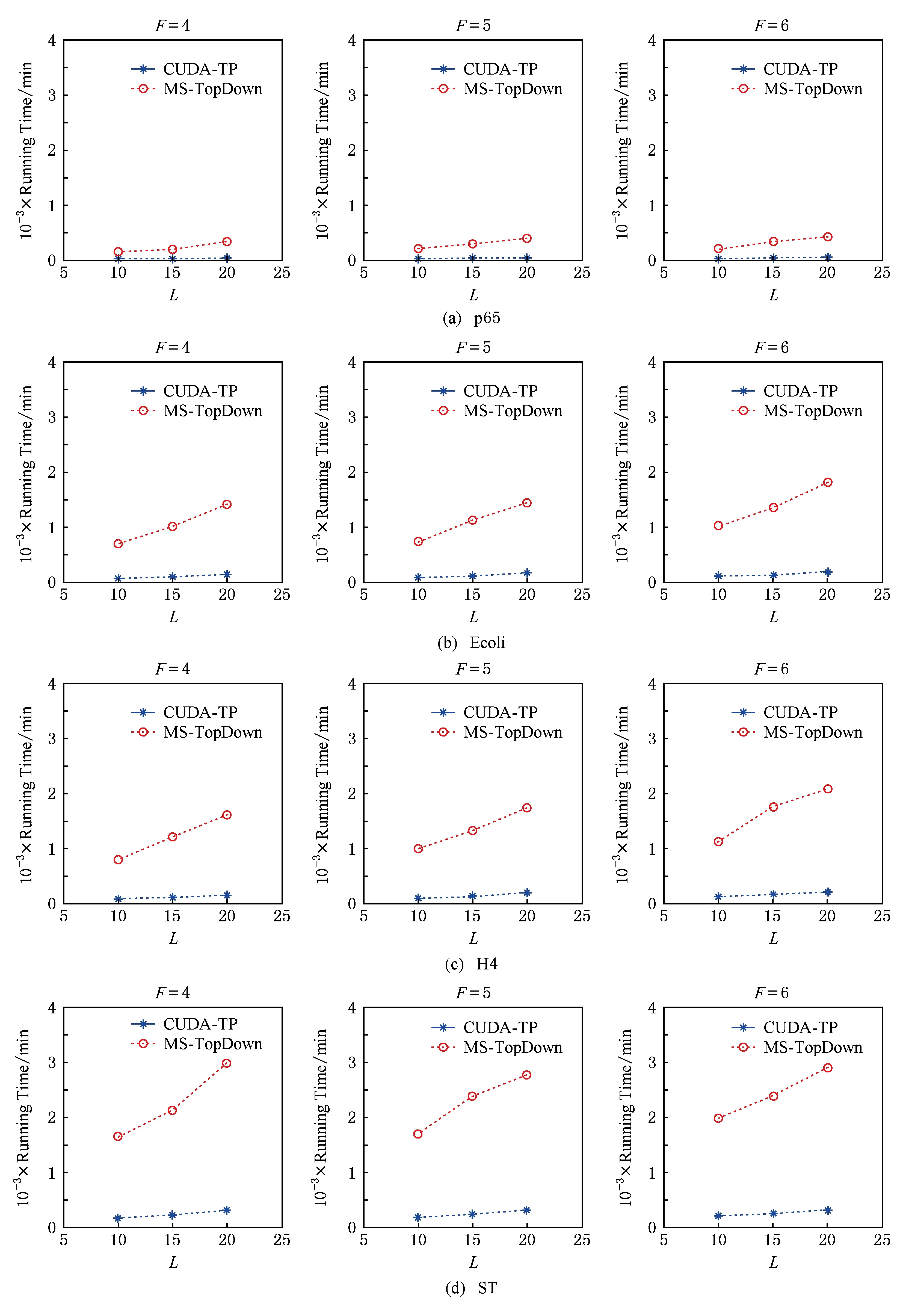
a0 其中,a0=0,an=M-18.相应地,长度为m的蛋白质序列P表示为 b0 其中,bi表示蛋白质序列P中从第1个氨基酸到第i个氨基酸的质量之和(假设b0=0,bm=M′-18,M′为蛋白质P未加任何修饰物的质量).给定一个蛋白质序列P和一个谱图S,定义它们所组成的谱图网格(spectra grid)为(a0,b0),(a0,bm),(an,b0),(an,bm)四个点所组成的2维矩形方格,其共包含(n+1)(m+1)个点.为了降低复杂性和方便计算,大部分的TD方法不包含谱峰强度,本文也将不考虑谱图中谱峰强度. 蛋白质序列P和谱图S之间的匹配可以看作谱图网格中的一条如图2所示的路径.路径中一个点与其相邻点的连接包含3种情况: 1) 如果从(ai,bj)到(ai′,bj′)满足ai=ai′,bj=bj′,则呈斜对角线; 2) 如果从(ai,bj)到(ai′,bj′)满足ai′>ai,则为垂直线,垂直线表示蛋白质质量增大,例如氨基酸位点上产生一个质量大于0的PTM; 3) 如果从(ai,bj)到(ai′,bj′)满足bi′>bi,则为水平线,水平线表示蛋白质质量减少,例如氨基酸位点上产生1个质量小于0的PTM.匹配路径上所经过的点即为共享谱峰数量[34](shared peak count),也称为匹配分数.图2(a)表示完美匹配,没有发生任何PTM;图2(b)表示第5和第6个氨基酸位点上分别产生-80Da和+90Da的PTM. Fig. 2 Illustration of protein-spectra matching图2 蛋白质与谱图之间的匹配 通过观察可知,每条从(a0,b0)到(an,bm)的路径都可能是蛋白质序列P和谱图S的一个有效匹配,而且匹配的路径数目随着质量变化个数F(质量变化对应路径中垂直与水平线)的增加而呈现指数增长.为了避免这种情况的发生,通常采用动态规划算法寻找谱图网格中的最优路径[14-18],这样,算法的运行时间只会随着F的增加呈线性增长. 动态规划算法在寻找最优路径的过程中需要迭代地填充大小为n×m×F的数组D,D中的元素Di j(f)表示在最多允许发生f个质量变化的前提下从(a0,b0)到(ai,bj)的最高匹配分数.数组D填充完成后,Dnm(F)的值即为蛋白质序列P和谱图S的匹配分数.在最优路径中,Di′j′(f′)的前驱点标记为Di j(f),如果2个数值对(ai,bj)和(ai′,bj′)满足条件: |ai-ai′-bj′+bj|<β, (1) 则称它们是余对角的(codiagonal),其中β为误差值. 通常,如果i (2) Di j(f)的计算为 Di j(f)=max(Ddiag(i,j)(f)+1, (3) Hi j(f)的状态转移方程为 Hi j(f)=max(Di j(f),Hi-1,j(f),Hi,j-1(f)). (4) 路径起始点D0,0(f)=0.可以看出,质量变化数F仅会让数组D中的元素个数线性增加,算法的时间复杂度为O(nmF),n和m分别表示谱图S中谱峰数量与蛋白质序列P的长度. 为了减小匹配误差,算法中的质量变化可以选取已知的PTM(如双氧化、磷酸化、甲基化)集合ΔPTM中的数值δ.因此,质量变化分为了2部分:已知的PTM与未知的PTM.用Fs和Fg分别表示二者在匹配中所允许的最大个数.至此,可以将diag(i,j)扩展为diag(δ)(i,j)并使之满足条件: -β<|ai-ai′-bj′+bj|-δ<β, (5) 则之前的数组D和H大小变为n×m×Fg×Fs,Di j(g,s)中的值仍然表示从(0,0)到(i,j)的最大分数.把式(3)转化成: Di j(g,s)=max(Ddiag(i,j)(g,s)+1, (6) 状态转移方程式(4)更新成 Hi j(g,s)=max(Di j(g,s), (7) 通过式(6),可以利用动态规划算法,最终求得全局谱图网格中完整蛋白质序列P与谱图S的匹配分数. Fig. 3 The flowchart of CUDA-TP algorithm图3 CUDA-TP算法流程图 如第1节所述的算法虽然能在线性时间内计算出匹配分数,但当蛋白质数据库变大或者谱图数量增多时,其时间开销依然不容乐观.为了加速计算过程,本文提出了基于GPU的CUDA-TP算法,该算法首先在CPU端使用AVL树优化前驱节点的求取,然后设计并行模型加速式(6)的计算.同时,为了加快蛋白质过滤,CUDA-TP还对蛋白质过滤算法MS-Filter[31]做了改进.算法的整体流程如图3所示. 在谱图网格中寻找最优路径时,首先要计算网格中每个点的前驱坐标diag(i,j).由定义可知diag(i,j)必是(i,j)左上部余对角线上的点.如图4所示,为求A的前驱点,首先需要找到其左上部区域Z中与A在同一条余对角线上的点的集合{A0,A1,A2},然后再在该集合内选取diag(i,j)的坐标.在选取坐标时,由式(6)可知,由于A1的diag值为A0的坐标,所以匹配路径中A1的匹配分数(对应D中元素)至少比A0大1,依次类推,得到点A的diag取值是离A最近点A2的坐标值.因此,求谱图网格中每个点的diag即为求距离该点最近且和它呈余对角的点的坐标.最简单的方法是遍历满足要求区域中的所有点,如图4所示,A的遍历区域为Z,但时间开销巨大. Fig. 4 Calculate diag of all nodes in the spectra grid图4 计算谱图网格中所有点的diag 由式(1)易知,如果2个点是余对角的,那么它们所在坐标对应的数值对(ai,bj)的差值d在误差范围内是相等的.也就是说,集合{A0,A1,A2}对应相同的d.利用这条性质,可以通过AVL树只遍历一遍谱图网格求取所有点的diag,如图4所示.计算分步骤: 1) 将谱图网格从左到右按列进行划分,每列元素的顺序从上到下; 2) 建立一棵空的AVL树,树的节点包含1个坐标和1个d值; 3) 从第1列的第1个元素开始,依次计算坐标元素的d值.如果AVL树中没有这个元素的d值,则把此值和它的坐标作为新节点插入AVL树.如果查找到已经有节点的d值与它相等,则把该元素的diag置为此节点所存储的坐标,同时更新节点的坐标为该元素的坐标. 当步骤3运行至最后1列的最后1个元素时,所有点的diag求取完毕.由于AVL树节点个数等于谱图网格中所有节点的不同的d值数量,所以AVL树的查找速度≪O(lbnm),能极大加快diag的计算.伪代码如下: 算法1. 在CPU端计算diag. 输入:谱图a[n]、蛋白质序列b[m]、误差值β、AVL树avl_tree; 输出:所有点的diag. ①InitializeAVLtree(avl_tree)*将输入的avl_tree初始化为null* ② fori=0 tomdo ③ forj=0 tondo ④d←b[i]-a[j]; ⑤ ifavl_treeincluded ⑥diag(i,j)←avl_tree[d](i,j); ⑦avl_tree[d](i,j)←(i,j); ⑧ else ⑨Insert(avl_tree,d,i,j); ⑩ end if 需要注意的是,伪代码中行⑤AVL树在查找d值时,如果AVL树节点中的值与该值的差的绝对值小于β,就认为它们是相等的.avl_tree[d](i,j)表示AVL树中查找到的等于d值的节点所包含的坐标. Fig. 5 Calculate diag(δ) of all nodes in the spectra grid图5 计算谱图网格中所有点的diag(δ) 不同于diag的计算,求解diag(δ)需要知道PTM集合ΔPTM中的所有数值δ.如果ΔPTM中有k个值,那么,求某个点的diag(δ)之前必须找出该点谱图网格左上部与该点满足式(5)的k个点集合,然后在这k个点集合中选取使匹配分值最大,即距离所求点最近的k个点的坐标作为最终结果.如图5所示,假设k=3,集合ΔPTM={δ1,δ2,δ3},在求A点的diag(δ)时,首先在区域Y中寻找满足条件的点集合{A0,A1,A2},{B0,B1,B2},{C0,C1,C2},然后选取集合中距离A最近的3个点A2,B2,C2的坐标作为返回值.显然,算法1无法满足这样的计算要求. 由diag(δ)的计算过程可知,网格中的每个元素在求解时,其结果互不影响,即所有元素可以同时计算.这种性质很好地符合了CUDA并行架构要求.在CUDA架构中,CPU作为主机(host),GPU作为主机的协处理器(co-processor),它被看作执行高度线程化并行处理任务的计算设备(device).运行在GPU上的CUDA并行计算函数称为内核(kernel),以线程栅格(grid)形式组织,线程栅格由若干个线程块(block)组成,每个线程块又包含若干个线程(threads).实际运行时,线程块被分割成更小的线程束(wrap)来执行运算任务,1个线程束由连续的32个线程组成. diag(δ)并行算法如图5所示,网格中每个点的计算分配1个线程,线程之间并行执行,线程块与线程块之间不需要同步,将所有的元素存入GPU的全局存储器.对一个点左上部的搜索区域,仍然按照算法1进行划分.算法执行过程中,始终维护1个包含k个点坐标的数组g,该数组的元素为坐标值且映射ΔPTM中的某个δ值.遍历搜索区域时,如果2个点在同一个集合中,那么它们所对应的δ必是相等的,则把后遍历到的节点坐标更新到数组g.如图5中的点集合{A0,A1,A2},它们都对应δ2,当遍历至A1时,更新g[δ2]为A1的坐标,依次类推,遍历完成时,数组g即为A的最终结果.算法2描述了计算diag(δ)的具体过程. 算法2. 在GPU端计算diag(δ). 输入:谱图a[n]、蛋白质序列b[m]、误差值β、PTM的集合ΔPTM; 输出:存储所有点的diag(δ)数组g. ① (n_left,m_left)←GetCoord(blockDim.x,blockIdx.x,blockIdx.y);*根据线程块,线程信息获取要处理的元素* ②d←fbs(b[m_left]-a[n_left]); ③ fori=0 tom_leftdo ④ forj=0 ton_leftdo ⑤delta←fbs(b[i]-a[j]-d); ⑥ ifΔPTMincludedelta ⑦g[delta]←(i,j); ⑧ end if ⑨ end for ⑩ end for 算法2中的行①表示从当前的线程获取所要计算的点坐标;行②保存该坐标对应的d值;行③④开始遍历坐标左上部区域的所有点;行⑤~求当前遍历点的delta值,如果PTM集合ΔPTM包含此值,则将其更新到数组g,最后返回的数组g即为最终结果;代码的行⑥检测ΔPTM中是否存在δ与delta之差的绝对值小于β,如果存在,则判断集合ΔPTM包含delta. 为求蛋白质序列P与谱图S的匹配分数,需要对式(6)和式(7)进行计算,即求解数组D和数组H.在CUDA-TP算法中,D和H在逻辑上被聚集为数组E,E中每个元素包含2个值:Di,j,Hi,j.在计算Ei,j之前,需要得到Ei-1,j,Ei,j-1,Ei-1,j-1这3个值.如图6所示,每次计算一个对角线上的元素,依次向下进行,直至最后1个元素.不难发现,对角线上的元素计算时互相之间是并行的,某个对角线上的元素全部计算完成后,再进行下一个对角线的计算.由此,可以设计并行架构求解数组E. Fig. 6 Execution of CUDA-TP algorithm图6 CUDA-TP算法的执行顺序 若蛋白质序列P的长度为m,谱图S的谱峰数量为n,则数组E的元素个数为nm.当n或者m变得很大时,E的元素就会相应的增多,导致要求解的空间很“庞大”,而GPU中同时并行执行的线程数量是受限的,给每个元素指定1个线程显然是不科学的.为了合理地利用GPU性能,可以把r×c个元素分为1个计算单元,每个单元分别分配1个线程,r和c根据GPU计算能力来指定大小(本文r和c均设置为2).线程按照标号顺序计算单元格中的元素,以保证在计算当前元素时其左上部的所有元素是已知的.同时,并行的线程运行在同一个线程块内,这样能够将数组E放到GPU的共享存储器中.如图7所示,计算单元A,B,C中的元素互不影响,它们是并行的,3个线程同时对其进行计算且每个线程按顺序计算4个元素. Fig. 7 Parallel processing architecture图7 并行计算架构 算法3. 在GPU端计算数组E. 输入:谱图a[n]、蛋白质序列b[m]、计算单元大小r和c,diag,diag(δ); 输出:所求数组E. ①idx←GetIdx(blockDim.x,blockIdx.x,blockIdx.y); ②p←min(nr,mc); ③ fori=0 tordo ④ forj=0 tocdo ⑤ (ei,ej)←GetEIndex(E,p,idx,i,j); ⑥ if (ei,ej)≠∅ ⑦E[ei,ej]←GetMax(E,ei,ej,diag,diag(δ));*获取结果并填充进数组E* ⑧ end if ⑨ end for ⑩ end for 算法3的行①首先获取当前的线程标号;行②求得最大并行数p;行③④表示线程按顺序计算r×c个元素;行⑤得到要处理的元素坐标,如果该坐标代表的元素不为空元素,则将数组E中此元素的数值更新;最后的行返回数组E.需要注意的是,更新数组元素值的函数GetMax中的参数diag为算法1的结果,diag_delta即为3.2节所述的diag(δ),E包含的数组D和H值严格按照式(6)和式(7)求解. 数组填充时,串行程序依次计算数组E中的元素,完成F个E数组的计算需要O(NF).由2.3节可知,CUDA-TP算法将E划分为F(r×c)个单元格,每次有p个线程同时运行且每个线程在单元格中串行执行,但由于空元素的存在,平均同时运行线程的数量约为p2, GPU执行完毕后最多剩余(r-1)n+(c-1)m个元素,于是CUDA-TP计算E的时间复杂度为 (8) 因此,质谱匹配的总时间复杂度由O(N2+FN)变为 (9) 对谱图S来说,要从蛋白质数据库中寻找1个蛋白质P,使得它与这个蛋白质的匹配分数最高.蛋白质数据库通常包含很多个蛋白质,让所有蛋白质与谱图S进行匹配分值计算,时间开销是巨大的.常用的方法是为每个谱图挑选出L个候选蛋白质,然后谱图与这L个候选蛋白质计算匹配分数并以最高分值的蛋白质作为鉴定结果.MS-Filter[31]是目前进行蛋白质过滤很有效的方法(蛋白质过滤问题定义及相关算法参见文献[31]),它为每个蛋白质与谱图S计算过滤分数,以分数高低作为是否过滤蛋白质的条件.CUDA-TP通过优化MS-Filter算法3个计算步骤中的步骤2来加速蛋白质过滤,优化后的计算过程: 1) 在低精度下计算谱图与蛋白质的卷积数组; 2) 查找对角线分值大于阈值的候选区域,如果相邻候选区域的最大边界与最小边界值之差小于所有氨基酸中甘氨酸的最小质量75.05,则将这2个区域合并; 3) 在高精度下依次对合并后的候选区域计算卷积数组,如果卷积数组中对角线分值大于设定的阈值,则将阈值更新为此分值,最后的阈值即为蛋白质的过滤分数. 蛋白质的过滤加速体现在步骤2的候选区域合并,通过合并分散的小区域来减少步骤3高精度卷积数组的个数. CUDA-TP创建L个流(stream)对过滤出的候选蛋白质与谱图的匹配分数并行计算,CUDA架构的流并行是粗粒度的并行,它能够使GPU运算的同时与CPU进行数据交换.如图8所示,为每个候选蛋白质分配1个流,流与流之间并行执行. Fig. 8 Stream parallelism for calculating the matching score between the spectrum and candidate proteins图8 谱图与候选蛋白质匹配分数计算的流并行 本文采用人类细胞蛋白p65[35]、大肠杆菌蛋白[36](escherichia coli, Ecoli)、人类核心组蛋白(human core histones)H4[37]和鼠伤寒沙门氏菌[38](salmonella typhimurium, ST)质谱数据来进行实验,所有的蛋白质数据库均来自美国国立生物信息中心NCBI①.原始质谱数据文件使用ReAdw②和MS-Deconv[39]转化为只包含单同位素谱峰的谱图. 由于TD方法是对完整蛋白质的鉴定,谱峰数量太少会导致匹配分数过低,所以只保留前体质量(precursor mass)大于2500Da且至少包含10个谱峰的谱图[14].最终的实验数据集及其分布如表1和图9所示. Table1TheNumberofSpectrafromFourDatasetsandtheNumberofProteinsintheCorrespondingDatabases 表1 数据集中的谱图数量及数据库中蛋白质个数 Fig. 9 Distribution of the number of peaks and the length of proteins图9 谱峰数量和蛋白质长度分布 p65数据集包含240个谱图,Ecoli数据集包含921个谱图,H4和ST分别包含1 245,4 339个谱图,谱图中的谱峰数量分布如图9(a)所示.p65与Ecoli数据集的谱峰较为均匀地分布在20~190之间;ST数据集的谱峰数量大多在20~80之间,占比57.2%,为2 482个;而H4数据集的谱峰数量多数分布在160~200之间,占比57.8%,为720个. 4个实验数据集的蛋白质数据库分别含有349,2 206,2 433,4 606个蛋白质,蛋白质序列长度分布如图9(b)所示.p65蛋白质数据库中的蛋白质长度大多分布在240~480之间,占比60.2%,共211个;ST蛋白质数据库中的蛋白质长度在40~240之间的有2 947个,占整个数据库的64.1%;H4和Ecoli蛋白质数据库中的蛋白质长度多集中在80~340,H4包含1 989个,Ecoli包含1 883个,各自占比为81.4%,83.3%. CUDA-TP基于谱图比对思想,与MS -Align+③通过减少搜索谱图网格空间以达到运行时间降低的策略不同,它是串行算法MS-TopDown的并行加速算法.本文通过设置不同的参数F(常用策略是固定Fg,改变Fs)和L来对CUDA-TP与MS-TopDown的运行时间进行比对,实验环境如表2所示: Table 2 The Running Environment表2 实验环境 Fig. 10 Running time of CUDA-TP and MS-TopDown on four datasets with different parameters 图10 4个数据集上CUDA-TP与MS-TopDown在不同参数下的运行时间 MS-TopDown没有蛋白质过滤步骤,选用2.5节改进的MS-Filter算法进行蛋白质过滤.MS-Align+从官方网站下载,MS-Align+只提供参数F的设置,运行时L为软件中的默认参数,因此只对比不同F参数下的运行时间.同时,实验采用常用的target-decoy[32-33]进行FDR控制,所得实验结果FDR值均小于1%.本文首先设定不同的允许最多发生的PTM个数F和蛋白质过滤数量L,从多角度对比CUDA-TP与MS-TopDown的运行时间,4个数据集的实验结果如图10所示: 在p65数据集上,CUDA-TP平均运行时间为22 min,MS-TopDown平均运行时间为212 min,CUDA-TP速度是MS-TopDown的9.6倍;在Ecoli数据集上,CUDA-TP平均运行时间为110 min,MS-TopDown平均运行时间为1 212 min,CUDA-TP速度是MS-TopDown的11倍;在ST数据集上,CUDA-TP平均运行时间为243 min,MS-TopDown平均运行时间为2 315 min,CUDA-TP速度是MS-TopDown的9.5倍;在H4数据集上,CUDA-TP平均用时139 min,MS-TopDown用时1 405 min,CUDA-TP速度是MS-TopDown的10.1倍.可以看出,虽然质谱数据集ST是H4的将近4倍,但是用时却只是H4的2倍,这是由于H4谱图中谱峰数量与其数据库蛋白质长度普遍比ST的高,导致要求解的谱图网格元素增多,增加了运行时间. MS-Align+只可以调整F的大小,L默认固定为20,因此本文对比分析了3种方法在不同F参数下的运行时间,实验结果如图11所示: Fig. 11 Running time of three methods on four datasets with different parameters图11 4个数据集上3种方法在不同参数下的运行时间 3种方法的平均运行时间在表3中给出,从表3中可以看到CUDA-TP的运行速度约是MS-Align+的2倍,这证明基于谱图比对思想的并行计算方法明显优于通过减少谱图网格搜索空间来加速计算过程的策略. Table 3 Average Running Time of Three Methods表3 3种方法平均运行时间 min 并行算法除了运行时间,有时更加关心其运行时的吞吐率.MS-TopDown与MS-Align+是单核CPU 程序,并没有进行多线程优化,这是由于2种方法采用以空间换取时间的策略,单核运行时就几乎达到了电脑资源的占用极限,实验中二者平均内存使用率在90%以上,多核CPU的运行几乎是不可完成的.文献[18]也指出单核MS-Align+运行大规模人类蛋白质质谱数据时,内存需求甚至高达40 GB.而CUDA-TP并行算法可以在显存1 GB的电脑上流畅运行,其内存占用不超过4 GB,因此具有更广的适用性. CUDA-TP的时间复杂度已经在2.4节详细给出,3种方法在不同数据集上的吞吐率如表4所示,吞吐率指单位时间内算法执行的计算单元数量.从表4中可以看出CUDA-TP吞吐率约为MS-TopDown和MS-Align+的11倍,这在Ecoli和H4数据上表现尤为明显,说明谱图网格元素的增多虽然增加了运行时间,但吞吐率并没有随着降低.MS-Align+通过减少求取网格的数量来减少计算时间,但吞吐率并没有实质提升.因此,CUDA-TP在运行时间和算法的吞吐率上要明显优于目前的MS-TopDown和MS-Align+方法. Table 4 Throughput of Three Methods 表4 3种方法的吞吐率 10-6cells Table 4 Throughput of Three Methods 表4 3种方法的吞吐率 10-6cells DatasetCUDA-TPMS-TopDownMS-Align+p65108.59.89.7Ecoli120.410.511.3H4115.111.211.7ST106.78.99.2 MS-TopDown在数据集上的执行时间通常要花费大量时间(本文中MS-TopDown在最大数据集上的运行时间在2 d左右),这大大降低了其在蛋白质鉴定中的实用性,而本文提出的基于GPU的蛋白质鉴定并行算法运行速度是其10倍,有效地解决了谱图比对思想应用于大规模数据的弊端,与现有的MS-Align+算法相比具有明显优势,通过上述多种不同的实验测试,验证了CUDA-TP的优秀性能.CUDA-TP源代码托管在github公共服务网站①. 当前,“自顶向下”的蛋白质组学飞速发展,已经成为大规模鉴定蛋白质及定位PTM的关键技术,但这些技术的应用算法在运行时间上还存在瓶颈.本文研究了TD策略下的蛋白质鉴定问题,提出了一种新型的基于GPU的完整蛋白质鉴定并行算法CUDA-TP.1)该算法通过流并行和优化MS-Filter来加速蛋白质过滤;2)引入AVL树降低谱图网格中每个元素前驱节点的求取时间;3)在GPU端设计了计算迭代公式的CUDA并行架构.实验结果表明CUDA-TP可以有效地加速完整蛋白质鉴定,与通过减少谱图搜索空间来换取效率的MS-Align+相比具有明显优势. 在TD策略下对完整蛋白质进行鉴定,除了计算蛋白质与谱图的匹配分数,还需要进一步评估匹配结果的统计显著性.因此如何计算匹配分数的同时得到蛋白质与谱图匹配的统计显著性评估结果,并且不降低时间运行效率,这将是我们下一步的研究工作.1.2 质谱匹配
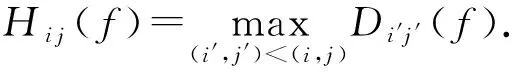
Hi-1,j-1(f-1)+1).
Hi-1,j-1(g-1,s),Ddiag(δ)(i,j)(g,s-1)+1).
Hi-1,j(g,s),Hi,j-1(g,s)).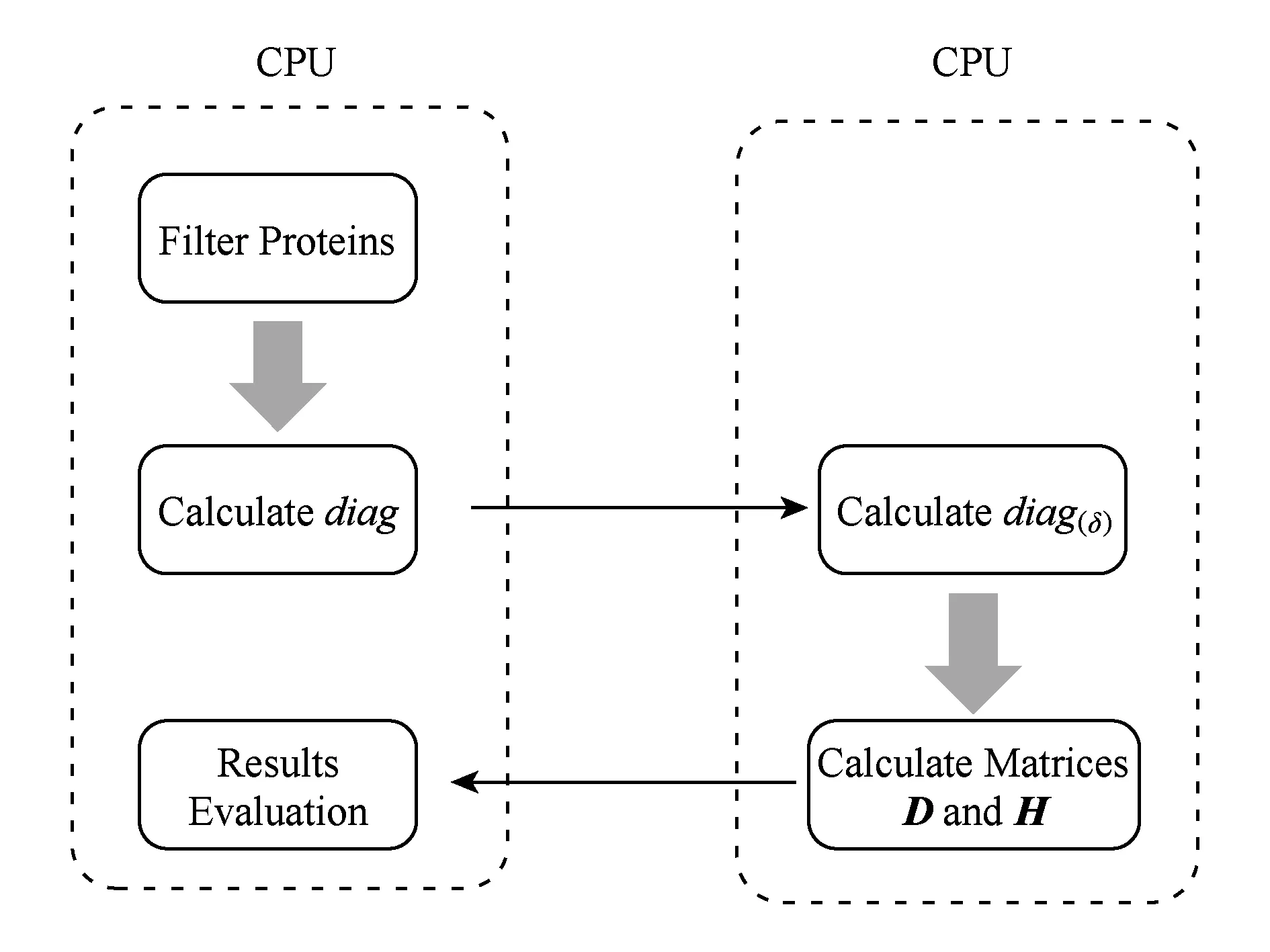
2 CUDA-TP算法
2.1 计算diag
2.2 计算diag(δ)
2.3 数组计算并行架构

2.4 时间复杂度分析
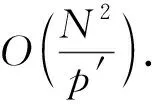
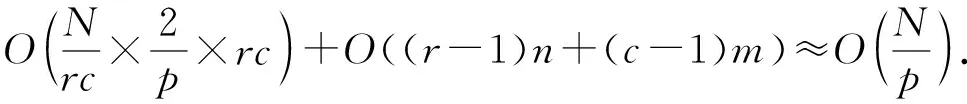
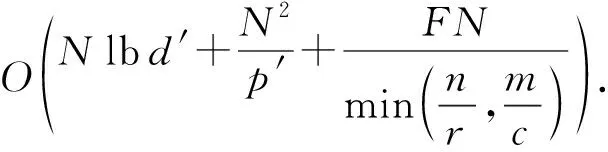
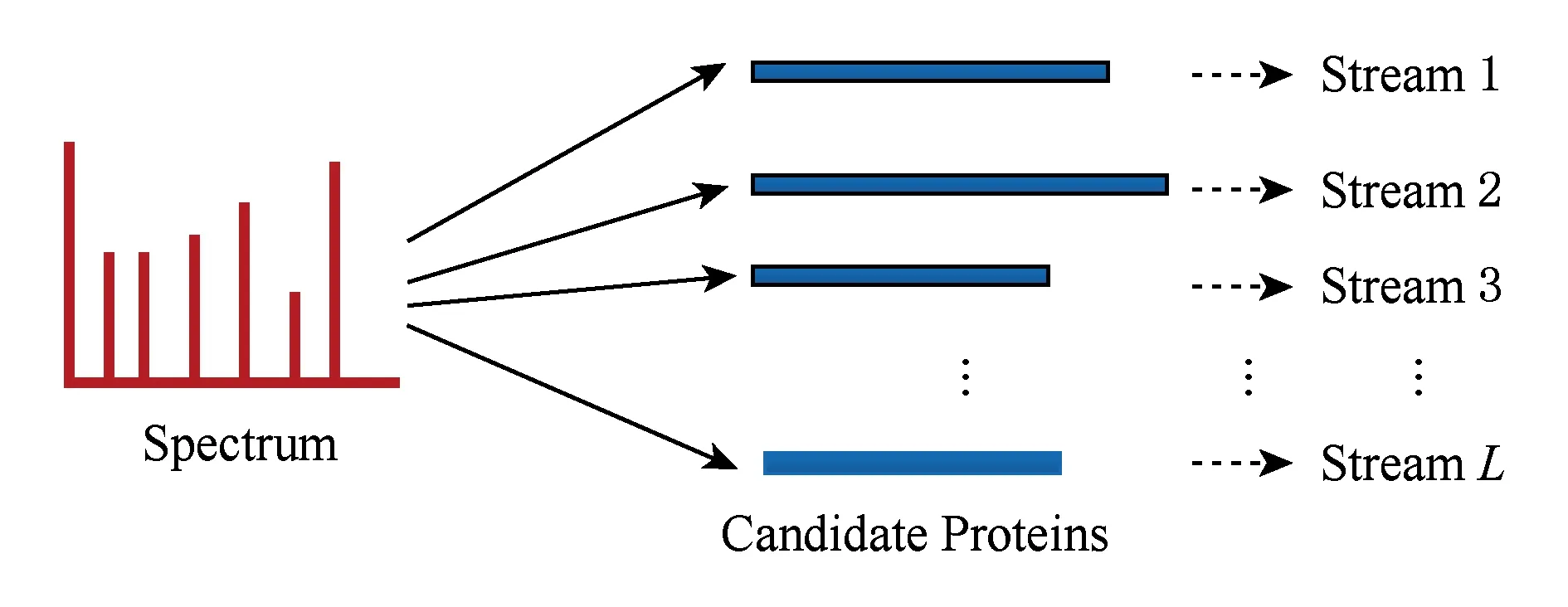
2.5 蛋白质过滤
3 实验与结果
3.1 数据集合
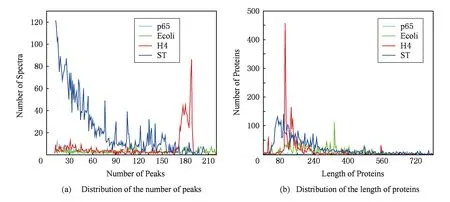
3.2 CUDA-TP运行时间

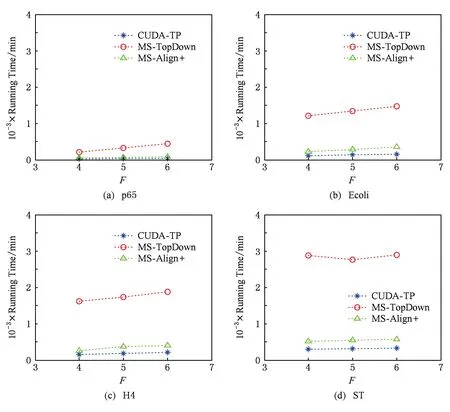
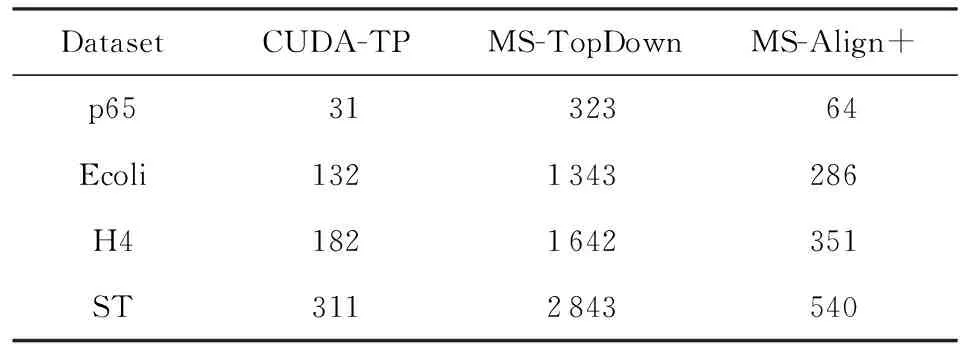
3.3 CUDA-TP算法吞吐率
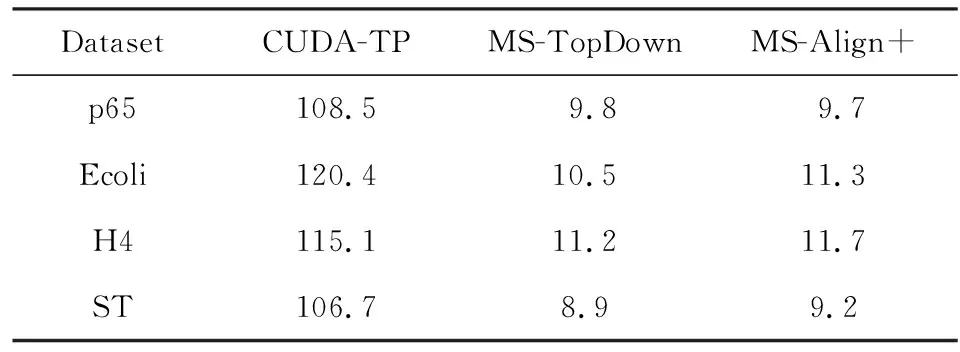
4 总结及展望
