高效低复杂度的QC-LDPC码全并行分层结构译码器
2018-07-03邱丽鹏贺玉成
吴 淼,邱丽鹏,周 林,2,贺玉成,2
(1.华侨大学 厦门市移动多媒体通信重点实验室,福建 厦门 361021;2.西安电子科技大学 综合业务网理论及关键技术国家重点实验室,西安 710071)
0 引 言
低密度奇偶校验码是一类可逼近香农限的信道编码技术,由Gallager教授于上世纪60年代首次提出。伪随机低密度奇偶校验(low-density parity-check,LDPC)码由于缺乏结构性编码方法,长期未能在硬件实现上获得突破。一方面,准循环低密度奇偶校验 (quasi-cyclic low-density parity-check,QC-LDPC)码[1]的提出为LDPC码在硬件实现上获得突破提供了可能;另一方面,传统LDPC码译码器大多采用串行结构和全并行结构,但这2种结构都各自存在明显的缺陷。随着QC-LDPC码研究的不断深入,人们提出了部分并行结构,这种结构充分利用码的准循环特性,使译码器在吞吐量与资源消耗之间获得平衡。近几年,一种新的分层译码结构(layered decoding,LD)及其算法[2-3]被提出。分层译码结构与传统部分并行结构相比较,有着收敛速度更快、结构更为简单等优点,从而改善了译码器实现有效性。
LDPC码原始的2种译码算法包括:基于硬判决的比特翻转译码算法(bit flipping,BF)和基于软判决的置信度传播迭代译码算法(belief propagation,BP)。软判决译码是基于后验概率(a posteriori probability,APP)测度,通过反复迭代来提高LDPC码的译码性能,并使其逼近香农限。最小和算法(min-sum algorithm,MSA)是基于BP的简化算法,虽然该算法牺牲了一定的性能,但极大地降低了计算复杂度,便于硬件实现。归一化最小和算法(normalized min-sum algorithm,NMSA)是一种改进的MSA,通过增加一个修正因子在一定程度上补偿因简化计算而导致的性能损失。根据消息传递机制,软判决译码算法又可分为TDMP(turbo decoding message passing)[3]算法和TPMP(two-phase message passing)[4]算法。TPMP算法又称双向迭代消息传递算法,该算法包含2个清晰的迭代过程:水平迭代和垂直迭代。上述提到的BP算法、MSA和NMSA均属于TPMP算法。与双向迭代消息传递机制不同,TDMP算法在迭代过程中,当某个分层完成校验节点的更新后,立即将更新的消息传递给下一分层,完成垂直方向上的消息传递;下一分层在接收到上一分层的后验消息后,结合上次迭代产生的校验消息而完成更新;直到所有分层都完成更新,一轮迭代才结束。这种类似于Turbo码串行迭代的更新方式,消除了水平迭代和垂直迭代的更新等待时间,加快了译码的收敛速度。文献[5]中实现TDMP算法,与传统TPMP算法的LDPC译码器相比,在吞吐率上实现了2倍的提升。
随着大规模集成电路的快速发展,实现高效的LDPC码编译码器成为一项重要研究内容。2005年,L. Yang[6]完成了工作频率112 MHz、吞吐率为127 Mbit/s的(3,6)规则LDPC码译码器的现场可编程门阵列(field programmable gate array,FPGA)实现;2012年,袁瑞佳[7]设计出一种基于FPGA的LDPC码编译码器联合设计方法,所设计的编码器和译码器可并行工作,有效提升了硬件工作效率;2013年,姚远[8]实现了基于IEEE 802.16e标准的并行分层译码算法的LDPC译码器硬件设计;同年,周健等[9]实现了面向磁记录信道的原模图LDPC码译码器的FPGA设计;2015年,张顺根等[10]提出了一种基于FPGA的随机构造QC-LDPC分层译码器设计方法。上述LDPC译码器设计普遍存在不同程度的实现复杂度问题,为此,本文充分利用QC-LDPC码的准循环结构特点,提出一种改进的可降低实现复杂度的全并行分层译码器结构。
1 QC-LDPC码及其分层译码算法
1.1 QC-LDPC码简介
QC-LDPC码是一种有准循环结构的LDPC码,其实质上是将LDPC码的校验矩阵划分成多个子块,每个子块由全零矩阵或非零的具有循环特性的置换矩阵构成。QC-LDPC码实现复杂度低,便于硬件实现。
1.2 分层译码算法
本文使用的国际空间数据系统咨询委员会(consultative committee for space data system,CCSDS)标准下的(8 192,4 096)码,它由通过循环移位单位矩阵产生的子矩阵,这样的结构非常适合水平分层译码算法,因为每个子矩阵的列重为1。在水平分层译码中,可以将基矩阵的每一行作为一个层,共分为12层,来自当前层的变量节点消息将垂直传递给属于同一个变量节点的所有其他未处理的层。在每次迭代中,从顶层到底层按顺序处理。
在非分层算法中,双向互相传递的信息,称作变量节点信息与校验节点信息,由单独的处理单元更新并迭代地相互传递,变量节点会等待校验节点全部更新完毕才会进行更新,反之亦然。而在分层译码算法中,各个层逐层参与译码操作,某个层完成了校验节点更新之后,立刻将更新的信息传递给下一层进行处理,当所有层都完成一次循环之后,即为完成一次迭代。分层译码算法相比于非分层译码算法,显著减少译码迭代计算的等待时间,加快译码迭代速率。硬件实现方面,在非分层算法中,校验节点和变量节点之间频繁的消息传递需要一个复杂的布线网络,而分层译码算法将变量节点部分退化成一个存储器,简化了非分层译码算法中过于复杂的内部连接网络,降低了控制模块的设计复杂度。同时,在实现分层译码算法时,相比于非分层译码算法,迭代次数明显降低,迭代速度显著提高。
目前,用于FPGA实现的LDPC码主流译码算法是MSA及其改进算法。本文采用分层最小和译码算法(layered min-sum decoding algorithm,LMSDA),也是基于MSA的一种改进算法,其算法主要描述为
qj,nj=Λnj-rj,nj
(1)
(2)
(3)

LMSDA的具体工作流程如下。
步骤1对后验概率信息Λnj和校验节点信息进行初始化。
Λnj=2y2/σ2,rj,nj=0
(4)
(4)式中:y为接收信息;σ2为噪声方差。
步骤2第k次迭代,第j层。
更新变量节点信息
(5)
更新校验节点信息
(6)
步骤3更新后验概率信息,表达式为
(7)
步骤4译码判决:当Λnj>0时,输出判决Znj=0;否则Znj=1。若译码结果Z满足ZHT=0或达到最大迭代次数lmax,则停止迭代,输出Z;否则,k=k+1,并跳转至步骤2继续下一次迭代。
在LMSDA中,将变量节点更新模块简化成一个存储单元,变量节点与校验节点之间信息的传递,由一个校验节点更新(check node update,CNU)模块来完成。由于省去了变量节点,垂直方向上的消息传递则根据校验矩阵H中循环子矩阵偏移值的差值通过校验节点与校验节点之间来互相传递。但校验矩阵H中,同一列位置上可能有多个相同的偏移值或其差值小于12(假设一个CNU计算延迟为12个时钟周期)。偏移值的差值过小会造成严重不利影响:比如某时刻t,当前校验节点Cj未计算完更新值,另一个与Cj在同一列上有非零元素的校验节点Ck将开始读取Cj的更新值,会导致译码失败。因此,本文根据文献[11]的方法对校验矩阵H中循环子矩阵的偏移值进行了修正,如图1所示。
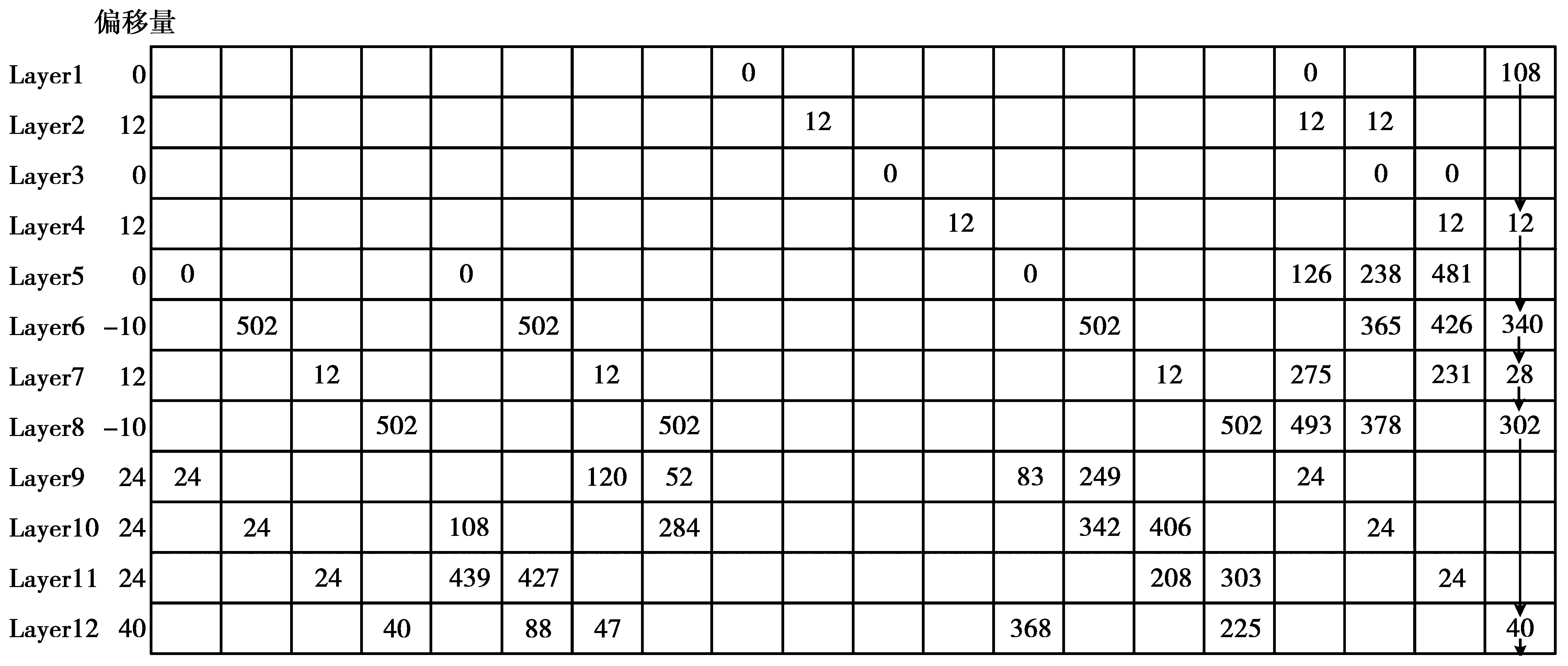
图1 修正偏移值的(8 192,4 096) LDPC码的校验矩阵Fig.1 Offset correction value check matrix of the (8 192,4 096) LDPC code
本文修正后的校验矩阵满足同一超列上的非零偏移值之间的差值大于等于12,这个数值是CNU模块所保留的计算空间,即一个CNU单元最大延迟为12个时钟周期。垂直方向上消息传递的规则可总结为:每一超行数据处理完毕后,传递给偏移值较小的超行,最后,偏移值最小的超行传给最大偏移值的超行。以第20超列中的6个超行为例,其传递规则为:340→302→108→40→28→12→340。本文修正后的校验矩阵与原校验矩阵的性能比较如图2所示,由图2可知,修正后的校验矩阵在误码率性能上有微小损失,几乎可以忽略不计。而修正后的校验矩阵使得分层的并行度得到了较大幅度的提升,可以进一步提升译码器的吞吐量。为验证LMSDA的性能,本文采用CCSDS标准下的(8 192,4 096)LDPC码,经仿真实验和优化,量化位数设定为6 bit,最大迭代次数设定为10次,并与其他几种译码算法进行性能比较,结果如图3所示。10次迭代的LMSDA的性能与20次迭代的最小和算法相近,即在相同误码率的条件下,LMSDA的收敛速度明显优于最小和算法,可有效降低译码器迭代次数。
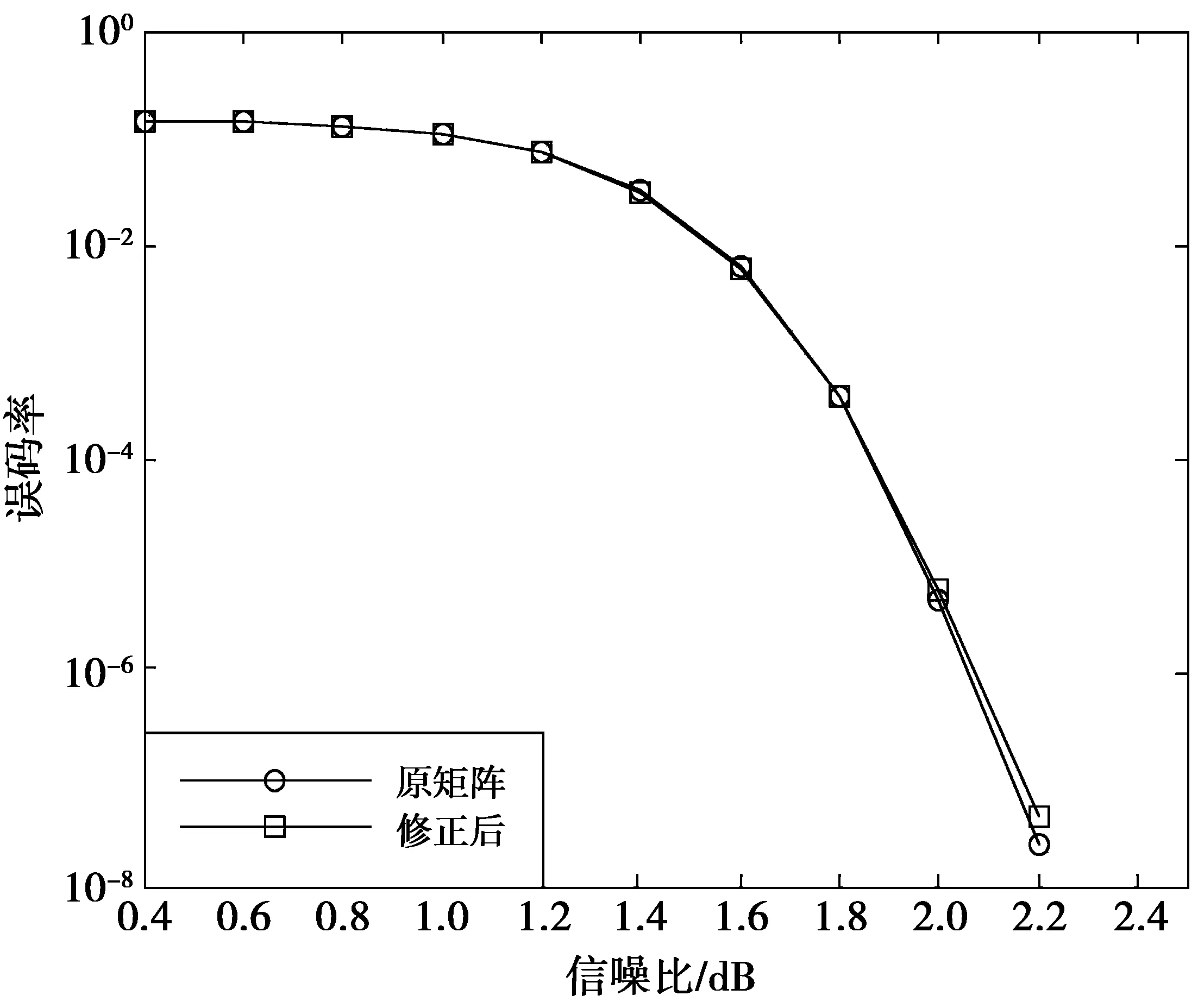
图2 校验矩阵修正前后的性能比较Fig.2 Comparison of performance before and after check matrix correction
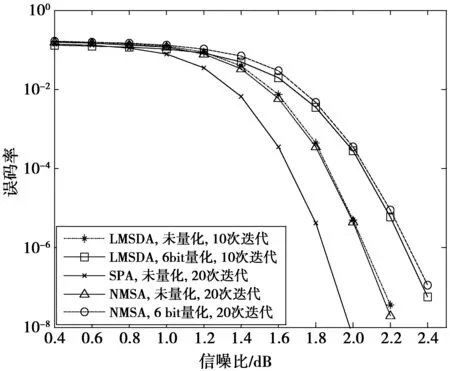
图3 不同算法的误码率性能比较Fig.3 Comparison of Bit-Error-Rate performance of different algorithm
2 译码器设计与实现
本文选择CCSDS标准的(8 192,4 096)LDPC码来设计全并行分层最小和(parallel layered min-sum,PLMS)译码器。本文设计主要特点有:①采用状态切割技术,使译码器的整体延时缩短,并提升了同步性能;②采用共用存储器结构,大大降低了硬件资源的消耗;③优化设计五级流水线结构,能够有效提高译码器工作频率。本文设计的QC-LDPC码译码器系统框图如图4所示。
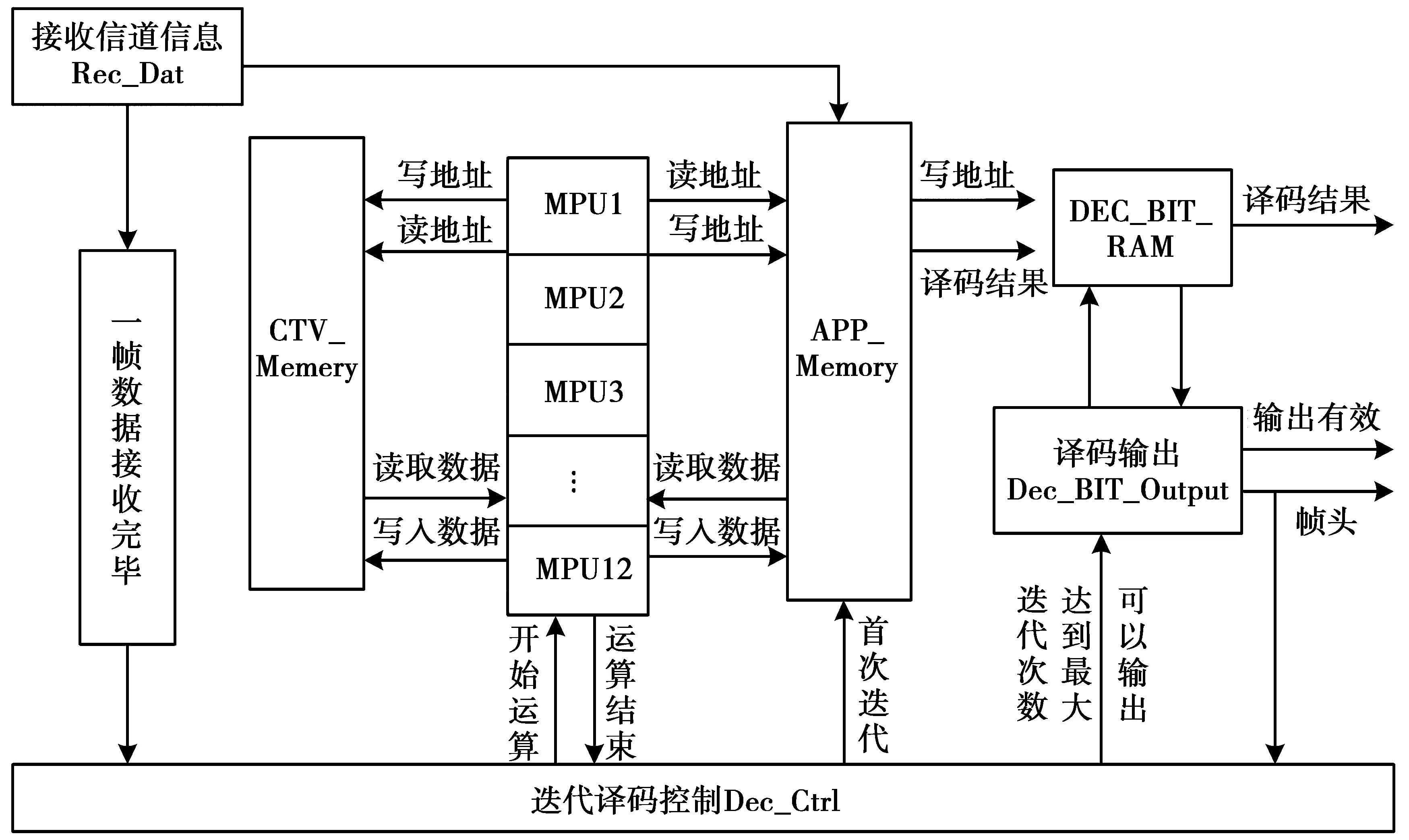
图4 全并行分层LDPC码译码器结构框图Fig.4 Structure diagram of Full-Parallel-Layered decoder of QC-LDPC codes
本译码器采用一种基于TDMP算法和NMSA相结合的译码算法,该算法具备TDMP算法的快收敛性,同时又拥有NMSA的低复杂度。通过对校验矩阵偏移值的修正,译码器支持全并行分层译码,克服了TDMP算法吞吐量低的缺点。本设计译码器由接收信道信息(Rec_Dat)、信息存储器(APP_Memory,CTV_Memory和DEC_BIT_RAM)、消息处理单元(message processing unit,MPU)、译码输出(Dec_BIT_Output)以及迭代译码控制(Dec_Ctrl)等几个主要模块组成。下面主要介绍译码器几个具有特色部分的设计。
2.1 状态切割技术
传统的译码器设计方法将所有的控制信号、地址信号集成在一个控制模块和一个地址生成器之中,容易导致延时较长,同步的能差的缺陷。本设计采用了状态切割技术,将控制状态机分成3个相对独立的小状态机,分别是接收状态机、MPU状态机和输出状态机。接收状态机与输出状态机用于控制信息的输入与输出,MPU状态机负责控制迭代过程。与传统的方法相比,本设计优点在于延时较低且能提高工作频率。本文状态切割如图5所示。
2.2 信息存储模块及共用存储器结构
信息存储模块包括APP_Memory模块、CTV_Memory模块和译码判决模块(DEC_BIT_RAM)。其中,APP_Memory模块储存初始化信息和每次迭代产生的后验信息(垂直信息),CTV_Memory模块储存上一次迭代过程中的校验节点更新的信息(水平信息),RAM_DEC_BIT模块用于存储每次迭代结束后的译码结果。
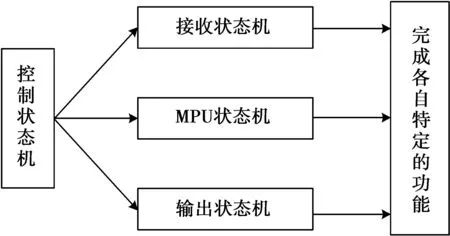
图5 状态切割技术示意图Fig.5 State segmentation diagram
2.2.1 APP_Memory模块
本文选用修正后的(8 192,4 096)QC-LDPC码,利用其校验矩阵的准循环特性,只需有非零元素的子矩阵位置上配置一个memory单元,储存该位置变量节点更新的值,最大限度地节省空间。信道信息的初始化过程与迭代过程不是同时进行,因此,信道初始化信息与变量节点更新信息可以共用一个存储器。存储器由二选一选择器选择存储的信息,初始化阶段Ln被选通,而迭代更新阶段则CTV被选通,本设计可以降低资源消耗,提升硬件资源利用率。本文设计共用存储器的结构如图6所示。
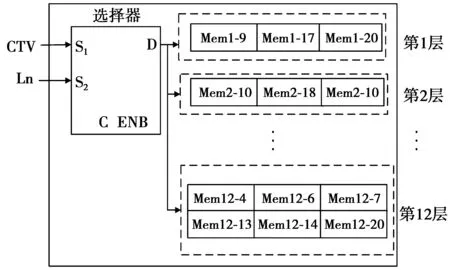
图6 APP_Memory模块结构Fig.6 APP_Memory module structure
图6中,Mem1-9表示该单元储存第1层第9个子矩阵所在的变量节点的迭代信息,Mem2-18指向第2层第18个子矩阵,以此类推。每一层的memory个数与H矩阵的列重相等,例如Layer1的列重为3,memory也为3个;Layer12的列重为6,memory也为6个。图1所示校验矩阵共60个非零子矩阵,因此,APP_Memory模块共有60个memory单元。每个memory单元采用乒乓存储结构,即当前帧参与本次迭代译码的同时,可对下一帧的信道初始化信息进行接收。memory单元采用简单双端口RAM设计,存储深度设置为2倍循环阵的大小,即512×2=1 024。前512个RAM划分为高位存储区,储存当前帧的迭代更新信息,后512个低位存储区用于储存下一帧数据的初始化信息,高低位存储区由Rec_Dat模块Ln数据地址高位信号“wraddr_ln_high”控制。当wraddr_ln_high=‘0’时,Ln数据被写入高位存储区,反之,Ln数据写入低位存储区。
2.2.2 CTV_Memory模块
CTV_Memory模块完成校验节点信息的存储,本文修正的(8 192,4 096)LDPC码校验矩阵最大可分为12层,每层配置一个校验节点,共需要12个RAM单元。由于每次水平更新时MPU只读取一次校验信息,也就是说,CTV_Memory模块只需要存储上一次迭代的校验信息,不需要乒乓存储结构。所以,CTV_Memory直接采用简单双端口RAM实现即可,存储深度为512。
2.2.3 译码结果存储模块
每一次迭代结束后得到的译码结果,将被输入到译码结果存储器(DEC_BIT_RAM)中暂存。暂存的数据可用作输出校验,若译码正确则停止迭代,并输出最终的译码结果,否则继续进行下一次迭代。本文选取的LDPC码码长为8 192,码率为0.5,信息长度为4 096。因此,译码结果存储器仅需要一个深度为8 192的RAM单元。同样地,DEC_BIT_RAM存储器也是乒乓缓存结构,支持连续输出。综上,译码器共消耗60×6+12×3+8=404 kbit,节省了存储信道初始化信息所需8 192×6 bit=48 kbit的空间。
2.3 消息处理单元MPU模块及五级流水线结构
在LMSDA中,变量节点更新模块退化成一个存储单元,变量节点与校验节点之间信息的传递,由一个消息处理单元MPU模块来完成。因此,MPU模块成为算法中的核心处理单元,其整体电路结构如图7所示。

图7 MPU模块整体电路结构Fig.7 MPU module integrated circuit structure
模块内部配置了2个状态机和1个地址生成器,用于简化顶层控制模块的设计复杂度。读状态机与写状态机分别产生CTV_Memory和APP_Memory存储器的读地址和写地址及相应的控制信号。地址生成器根据2个状态机的控制信号,完成地址的初始化,之后的每一拍令地址自加1并输出即可。整个MPU模块的启动、终止信号由控制模块(Dec_Ctrl)产生。
每个MPU通过读取与之相连的变量节点所对应APP_Memory上的值,在模块内部首先完成垂直信息的更新,再经过CNU模块进行分离、比较运算得出水平信息的更新值。最后将垂直信息和水平信息叠加得到后验信息,才完成一次迭代。本设计中,减法器组模块为流水线结构的第1级,CNU模块包含了3个级,分别是符号幅值分离模块、求最小值模块、合成模块,最后由加法器组模块作为流水线结构的第5级。五级流水线的优点在于可以有效地提高工作频率。下面以行重为8的校验节点为例,MPU模块的五级流水线结构如图8所示。
图8中,CTV为上一次迭代校验节点传给变量节点的信息,APP为上一次迭代的后验信息。减法器组模块为流水线结构的第1级,完成LMSDA的第1步,即垂直信息的更新。MPU模块每一拍分别向APP_Memory和CTV_Memory模块读取上一次迭代的水平信息和后验概率信息,并完成8次并行的减法运算。为了避免溢出,将减法器经过一个限幅器(Limit)进行限幅,然后将数据传入第2级进行CNU更新。为了方便计算,译码器内部信息均采用二进制补码表示。第2—4级流水线为CNU模块,这部分实现了垂直信息的分离、比选以及合并工作,完成水平信息的更新。图8中的第2—4级是以校验矩阵第1列为例,行重为3的CNU电路结构。其中,“Abs_sign”模块实现符号位与幅值分离的功能;“<”模块实现输入数据的比较并输出最小值;“D”代表D触发器;“x≪2-x”模块实现最小值归一化因子α的乘积;第2级进行符号与幅值分离的工作,第3级将符号位延时并比较求出最大值与最小值,第4级将符号与幅值合并。对比文献[11],本文设计省去了比较与选择部分,节约了硬件资源开销,有效减少了关键路径延时,提高了工作频率。此外,还融入了归一化最小和因子的计算,可以进一步节省硬件资源,且不需要额外增加控制信号。第5级流水线为加法器组模块,将第1级减法器组输出的垂直信息和第2—4级输出的水平信息进行累加,完成(3)式的计算,即后验概率信息的更新。整个流水线第1级需要1拍,第2—4级需要8拍,第5级需要1拍,又由于加入了2个Limit模块来限幅,而一个Limit占用一拍,所以整个流水线需要12拍。本文选用的校验矩阵共有12层,即12个MPU模块并行更新一次完整的迭代过程需要12个时钟周期。这也是前面提到的修正后校验矩阵时,同一列位置上偏移值的差必须满足不小于12的原因。文献[10]中所提到的校验节点更新结构中,一次校验节点的更新迭代就需要16个时钟周期,对比文献[10]的结构,本文将修正因子运算过程嵌入至第2—4级之中,由于本文五级流水线结构上的优势,一次消息更新迭代仅需要12个时钟周期,加快了收敛速度。
3 译码器性能及实现复杂度
本文设计译码器的实现方案以Xilinx公司Virtex系列开发板XC7VX485T芯片为硬件实现平台,ISE 14.2为开发环境,使用Verilog HDL语言编程实现了 (8 192,4 096) 全并行分层QC-LDPC码译码器的设计。译码器整体的时序仿真图如图9所示。
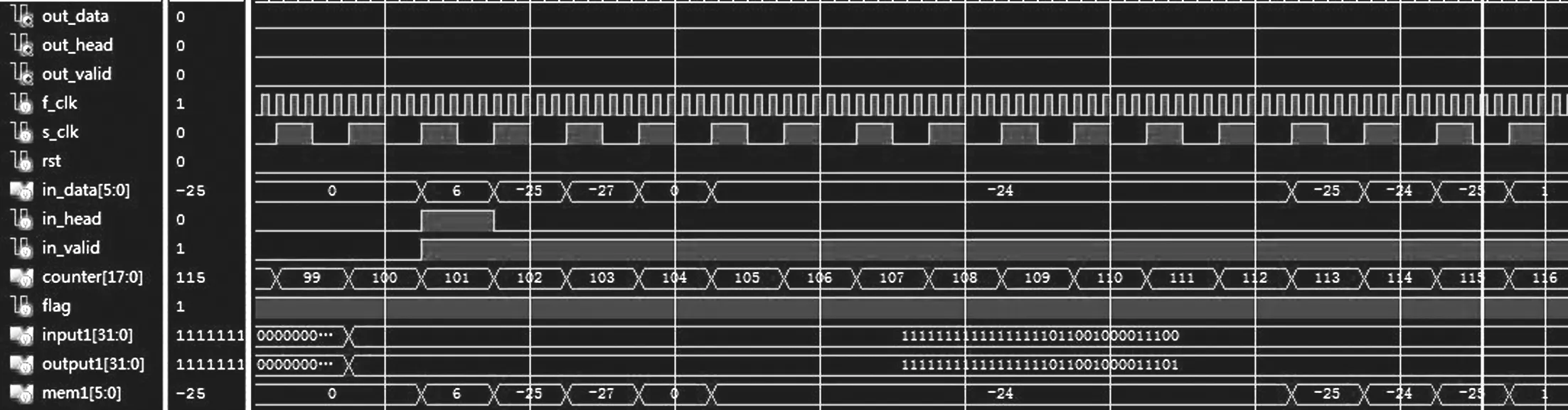
图9 译码器整体时序仿真图Fig.9 Decoder overall timing simulation
对译码器进行综合优化及静态时序分析,验证了译码器的正确性和高效性。表1为本文所设计译码器的实现复杂度。
模块的关键路径的延时为3.304 ns,则系统的工作频率为302.7 MHz。译码速度,即吞吐量,计算式为
(8)
(8)式中:f为工作频率;N为码长;m为循环子矩阵大小;t为一次迭代消耗的时钟周期数;iter为最大迭代次数。经计算,最大迭代次数为10时,译码器的吞吐量可达473.2 Mbit/s。其他译码器的性能比较如表2所示。
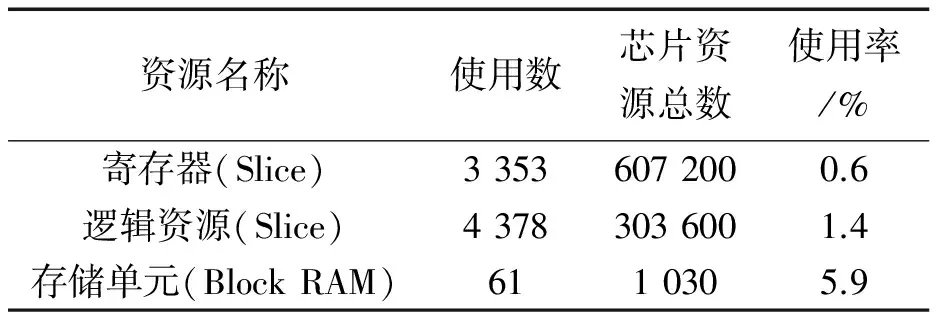
表1 译码器实现复杂度Tab.1 Decoder implementation complexity
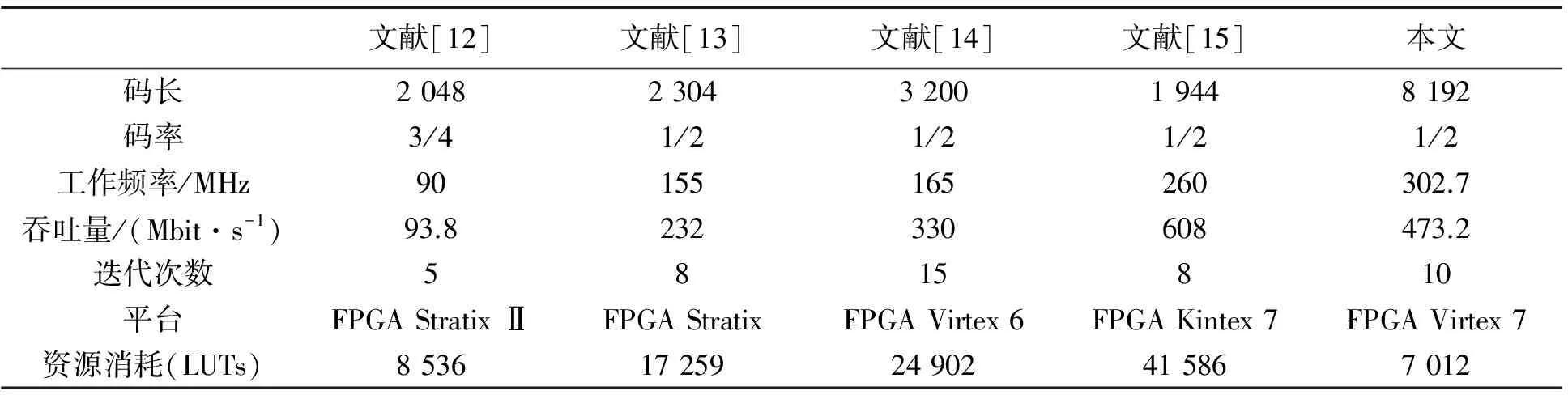
表2 译码器性能比较Tab.2 Decoder performance comparison
表2的性能对比证明了本文设计译码器的优越性。与同类译码器[12-14]相比,资源消耗可以降低50%以上,吞吐量提升了2~3倍,无论是译码吞吐量、工作频率还是资源消耗方面,本设计译码器都更为突出。相比于文献[15],在工作频率以及资源消耗上占据明显优势。
4 结 论
本文采用全并行分层最小和算法,提出了一种具有较高吞吐量、较低复杂度的分层译码器结构,并在FPGA平台上实现了基于CCSDS标准的 (8 192,4 096) LDPC码译码器。本译码器主要具有以下优点:①关键模块MPU采用五级流水线结构化设计,内部的CNU单元同样是一个流水线的更新过程,提高了系统工作频率;②控制模块状态机被划分为3个具有特定功能的小状态机,嵌入到接收信道信息模块、译码输出模块以及MPU模块中,降低了控制模块的设计复杂度,同时,每个模块的路径延迟得到了缩短,提高了整个系统的工作频率;③优化了模块和存储单元,使得译码器硬件资源有较高的利用率;④全并行的分层译码结构,加快了译码器收敛速度,提高了译码吞吐量。表2的性能对比证明了本文设计译码器的优越性。本文实现了码长为8 192,码率为1/2的QC-LDPC码译码器,在Virtex7开发板上验证表明,吞吐量可达473.2 Mbit/s,存储资源消耗仅为传统部分并行结构译码器的1/4。因此,本文提出的分层全并行结构的QC-LDPC码译码器同时具备高效、低复杂度、吞吐量大、收敛快等性能,一定程度解决了译码器吞吐量与资源消耗的矛盾。
参考文献:
[1] KOU Yu, LIN Shu, FOSSORIER M P C. Low-density parity-check codes based on finite geometries: a rediscovery and new results[J].IEEE Transactions on Information Theory, 2001, 47(7): 2711-2736.
[2] ZHANG Kai, HUANG Xinming, WANG Zhongfeng. An area-efficient LDPC decoder architecture and implementation for CMMB systems[C]∥2009 20th IEEE International Conference on Application-specific Systems, Architectures and Processors.Boston:IEEE Press,2009:235-238.
[3] MANSOUR M M. A turbo-decoding message-passing algorithm for sparse parity-check matrix codes[J].IEEE Transactions on Signal Processing,2006,54(11):4376-4392.
[4] MANSOUR M M, SHANBHAG N R. High-Thoughput LDPC Decoders[J]. IEEE Transactions on Very Large Scale Integration Systems, 2003, 11(6): 976-996.
[5] LIAO Ruochen, FU Yuzhuo, LIU Ting. FPGA-Based High Throughput TDMP LDPC Decoder[J]. Computer Engineering and Technology, 2016(666): 94-101.
[6] YANG Lei, SHEN Manyuan, LIU Hui, et al. An FPGA implementation of low-density parity-check code decoder with multi-rate capability[C]∥Proceedings of the ASP-DAC 2005. Asia and South Pacific Design Automation Conference, 2005.Shanghai:IEEE Press, 2005: 760-763.
[7] 袁瑞佳, 白宝明. 基于FPGA的LDPC码编译码器联合设计[J]. 电子与信息学报, 2012, 34(1): 38-44.
YUAN Ruijia, BAI Baoming. FPGA-based Joint Design of LDPC Encoder and Decoder[J]. Journal of Electrics & Information Technology, 2012, 34(1):38-44.
[8] 姚远. 基于并行分层译码算法的LDPC译码器设计[D]. 上海:复旦大学, 2013.
YAO Yuan. Design of LDPC Decoder Based on Parallel Layered Decoding Algorithm[D].Shanghai: Fudan University, 2013.
[9] 周健, 吕毅博, 洪少华,等.面向磁记录信道的原模图LDPC码译码器的FPGA设计[J].重庆邮电大学学报:自然科学版, 2013, 25(6): 788-794.
ZHOU Jian, LV Yibo, HONG Shaohua,et al. Protograph-based LDPC Decoder Applied to Magnetic Recording Channel [J]. Journal of Chongqing University of Posts and Telecommunications: Natural Science Edition, 2013, 25(6): 788-794.
[10] 张顺根, 仰枫帆. 基于FPGA的随机构造QC-LDPC分层译码器设计[J].无线电通信技术, 2015, 41(1): 41-45.
ZHANG Shungen,YANG Fengfan.Design on Randomly Constructed QC-LDPC Layered Decoder Based on FPGA[J].Radio Communications Technology,2015, 41(1):41-45.
[11] ZHANG Kai, HUANG Xinming, WANG Zhongfeng. High-throughput layered decoder implementation for quasi-cyclic LDPC codes[J]. IEEE Journal on Selected Areas in Communications, 2009, 27(6):985-994.
[12] 彭阳阳, 仰枫帆. 基于FPGA的QC-LDPC码分层译码器设计[J]. 无线电工程, 2014, 44(1): 17-20.
PENG Yangyang, YANG Fengfan. Design on QC-LDPC Layered Decoder Based on FPGA[J]. Radio Engineering, 2014, 44(1):17-20.
[13] DING Hong, YANG Shuai, LUO Wu, et al. Design and implementation for high speed LDPC decoder with layered decoding[C]∥International Conference on Communications and Mobile Computing. Kunming: IEEE Press, 2009: 156-160.
[14] 云飞龙, 杜锋, 朱宏鹏,等. 一种高吞吐量QC-LDPC码译码器的FPGA实现[C]∥第七届中国卫星导航学术年会论文集.长沙:中国卫星导航学术年会, 2016.
YUN Feilong, DU Feng, ZHU Hongpeng, et al. FPGA Implementation of a High-throughput QC-LDPC[C]∥The Seventh China Satellite Navigation Academic Annual Proceedings.Changsha, China: The Seventh Annual Meeting of China Satellite Navigation, 2016.
[15] SWAPNIL M, DAVID U, HOJEE K,et al. High-Throughput FPGA-based QC-LDPC Decoder Architecture[C]∥Vehicular Technology Conference. Boston, MA, USA :IEEE Press,2015:1-5.
