多协议下智能家居协议的分类方法
2018-07-03彭大芹李司坤杨彩敏
彭大芹,项 磊,李司坤,杨彩敏 ,邱 雨
(1.“新一代信息网络与终端”重庆市协同创新中心,重庆 400065; 2.重庆邮电大学 电子信息与网络工程研究院,重庆 400065;3.中移物联网有限公司,重庆 400065)
0 引 言
互联网技术的急速发展和城市智慧化进度的不断加快,智能家居[1]作为新型的高科技技术的衍生产品,在智慧城市的建设中发挥着中流砥柱的作用。近年来,智能家居作为家庭信息化的实现方式,已逐渐成为社会信息化发展的重要组成部分,尤其是随着“互联网+”概念的提出,海尔、TCL、美的、格力等互联网与家电企业大佬都想要在智能家居争夺战中占据话语权,从而主导国内智能家居市场,因而,纷纷建立了智能家居生态圈。目前国内已经形成海尔+阿里+魅族、美的+小米与京东等生态圈模式,这虽然反映了智能家居火热的发展势头,但由于智能家居的技术涉及面很广,这样就导致了不同的智能家居品牌开发商有不一样的智能家居接入技术标准和通信协议。比如,就智能家居系统内的无线通信技术来说,就有多种标准和协议,如Zigbee,wifi,蓝牙,红外IR和射频RF等。这种情况下,由于不知道智能家居协议的相关信息和开发文档,相当于零知识情况下未知协议的识别与分类,不仅造成了协议分析的难题,也给网络安全信息管理带来了危害。
传统的协议识别方法难以应对现有的爆炸式新颖流量,因此,一些研究者纷纷结合机器学习[2]算法提出了新的协议识别方法[3]。文献[4-6]在比特流未知的情况下,通过改进的AC(aho-corasick)算法和数据挖掘关联规则算法,提出了未知协议的识别方法;文献[7]提出了未知协议的帧长识别方法;文献[8]提出了基于数据流与机器学习中聚类算法来分析未知的协议;文献[9]根据二进制比特流的特征,提出了一种基字节熵矢量加权指纹的协议识别方法。通过实验表明,该方法对二进制比特流协议的识别高达94%以上的召回率,并可以识别训练数据集中未出现的协议。
本文从同一协议的数据对象之间具有相似度,不同协议的数据对象之间具有差异度出发,利用机器学习算法中的无监督学习的高效、快速的K-Means聚类算法,将多协议聚类成不同的单协议类型的簇集,并使用数理统计和向量空间模型的概念对算法的初始K值、初始聚类中心及数据对象间距离进行了改进,最后提出对未知协议的聚类评价指标。经实验验证,该方法可行性和实用性极高。
1 相关理论
1.1 K-Means算法
在未知的情况下,根据某些特征将数据对象基于某种相似度评判规则聚类划分成若干个类簇的集合的过程,称之为聚类。常用的聚类算法,如K-Means,BIRCH,DBSCAN及STING等,这些聚类算法各有各的优缺点和应用场景的局限性。而本文选择了快速、高效的K-Means聚类算法。
K-Means算法[10]也称为K-均值算法,它是一种基于距离的聚类算法。基本思想是先指定一个数据集将要划分的类簇个数K值及初始中心,然后通过对序列间进行欧式距离计算,将序列划分到距其最近的类簇中心,更新类簇中心,依次迭代计算,直到目标准则函数收敛,输出K个类簇。其K-Means算法的流程如图1所示。
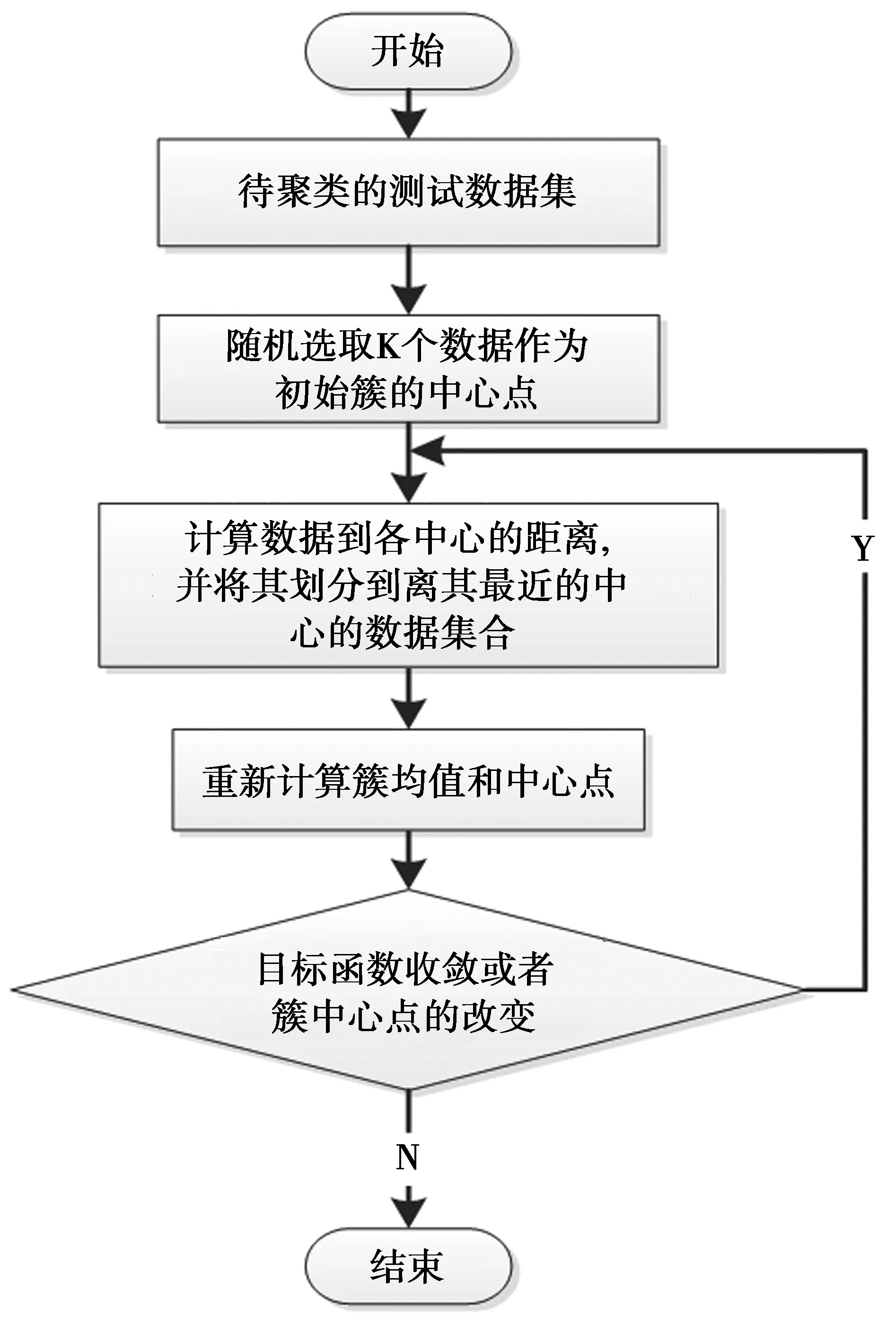
图1 K-Means算法的流程图Fig.1 Flow chart of K-means
K-Means聚类算法的步骤描述如下。
输入:待聚类的数据集合R={x1,x2,…,xn},要聚类划分的簇的个数K,聚类的初始中心数据集合C={c1,c2,…,ck}。
输出:聚类结果:K个类簇。
①先从数据集R中选取K个数据对象为初始中心点,即C={c1,c2,…,ck};
②按照欧式距离公式计算剩余数据到聚类中心点C的距离,其公式定义为
d(xi,xj)=
(1)
(1)式中:xi=(xi1,xi2,…,xip);xj=(xj1,xj2,…,xjp),分别表示2个p维度的属性的数据对象。
(2)
(2)式中:d(xi,xj)是数据样本点xi和xj的欧式距离。
由(2)式计算距离后,将数据对象划分到距离其最近的簇中心所属的类簇中,更新类簇中心;
③重复迭代上述2个步骤,直到准则目标函数收敛,聚类结束,输出结果。其准则目标函数E公式为
(3)
(3)式中:Ni为第i个类簇集合;ci为第i个类中心。
对于K-Means算法,因为其算法简单、易于实现,在对大规模的数据集聚类划分的时候,有很好的聚类效果而被广泛应用,但是它对于初始的聚类中心的选择甚是敏感,再加上初始中心的随机选择往往会造成聚类的评价函数收敛于局部最优,K值的指定有很大一部分的主观因素,对于无任何经验或者先验知识而言,是极其困难的。针对K-Means算法的2个参数的劣势问题,各研究学者纷纷提出了不同的高效的对策。文献[11]提出了一种新的初始中心选择方法,实验证明,该新提出的方法使目标函数收敛更快,聚类效果更好更稳定;文献[12]研究分析了算法中的不同的目标收敛函数的选择对K均值聚类的影响;文献[13-14]提出对聚类算法K-Means的改进,提高K-Means聚类算法的效率。
1.2 聚类评价
由于本文处理的数据对象是未知协议,事先无法知晓混合协议中各个协议的值分布,所以,对分类出来的单个协议也就无法使用协议识别评价指标F-Measure进行准确度评价。本文由于事先不知道多协议中智能家居协议的多少,无法对正确分类出来的智能家居协议进行准确度计算来评价本文分类方法的好坏,因此,提出采用信息熵作为未知协议分类方法的准确度评价。
信息熵[15]又称为香农熵。它采用数值的形式来表述系统中信息的分布状态,测量系统的纯净程度。熵值越小,则说明该系统中的信息越纯净或者是越单一。假设随机变量X,其取值为{x1,x2,…,xk},xi(1≤i≤k)在X中出现的概率为p(xi),则信息熵H(x)定义为
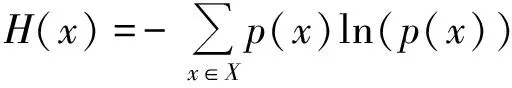
(4)
本文通过对分类出来的智能家居协议类簇系统的信息熵值计算,来表述该类簇系统中信息的纯净或混乱状态,以此评价本文协议分类方法的准确度高或低。以分类出来的智能家居协议类簇中的所有协议数据帧数为行,帧长度为列,构建二维矩阵,计算二维矩阵中每列的信息熵数值,如果计算所得的熵值都接近为0或者普遍较小,则说明本文分类出来的智能家居协议类簇系统的信息很纯净,也即是该分类出来的类簇中只包含智能家居协议一种数据类型,进而说明本文改进的K-Means聚类效果好,协议分类方法准确度高。
2 多协议下智能家居协议的分类方法
本文方法的大致系统框图如图2所示。将捕获的多协议数据帧,使用数理统计进行数据预处理,计算出近似的K、和初始中心,然后基于向量空间模型的概念(vector space model,VSM),使用数据对象之间的相似度计算代替K-Means聚类算法中原有欧式距离计算,最后用信息熵对聚类结果进行评价。其创新点如下:①用数理统计方法改进了算法K-Means聚类中K值和初始聚类中心的选择的随机性;②提出了基于向量空间模型的概念,以数据对象相似度代替数据对象间的聚类;③提出了未知协议的识别与分类评价的方法,基于信息熵的评估方法。
2.1 数据预处理
因为本文的输入数据是按帧已划分好的数据帧作为数据对象,以字节为数据处理单元。所以数据预处理基本思想是假设有n条数据帧,截取每帧数据的前m个字节,以字节为元素,构建一个n行m列的矩阵a[n][m]。
2.2 VSM_K-Means算法
此部分的目标是通过对输入的多协议数据帧分类出智能家居协议的单类型数据帧。其关键技术有:①K-Means聚类初始输入个数K值及初始聚类中心的选择;②类簇聚类划分的距离计算。本文针对这2个关键技术,分别给出了以下对应的改进思想。
1)利用数理统计知识,通过对数据预处理得到的数据集二维矩阵a[n][m]中每列字节频率进行统计,设置阈值,筛选出每列的高频字节,包含该高频字节的行的个数即为算法初始聚类个数K值,包含该高频字节的行即为该算法初始聚类中心。
2)利用VSM相似度计算代替K-Means聚类算法中类簇聚类划分的欧式距离计算,原有的以欧式距离计算的聚类类簇划分,虽然方法简单、直观,但在处理未知协议帧之间的相似问题上并不适用,本文选用VSM的概念对协议帧向量化计算以相似度代替欧式计算。

图2 零知识多协议下智能家居协议分类系统框图Fig 2 Smart home protocol classification system block diagram of Zero-knowledge multi-protocol
VSM是通过将文本划分成多个相互独立的N个词的集合,然后再由每个词对文本所做的贡献程度赋上不同的权重值,这样一个文本就可以由{词、权重}2个N维的向量表示,从而使得文本之间的相似度具有了简化的计算,被广泛应用到信息检索领域。
本文由于是对未知的协议数据帧聚类,简单的欧式距离作为算法聚类的评判尺度,并不能实质性地反映出各个数据对象之间的关系,会造成将相同或者相似对象聚为一类的时间较长的结果。而以相似度计算,选取未知协议数据每帧中的高频字节及高频字节偏移位置作为协议数据帧向量空间化的2个特征属性,以未知协议帧自身每个字节的特性来反映各个数据对象之间的相似性,这不仅从本质上反映了数据对象之间的相似性,还可以加快相同或者相似数据对象聚为一类的速度,减少算法运行时间。
其具体步骤如下。
①将数据预处理的结果n行m列的矩阵记作矩阵a[n][m];
②按列统计每一个字符出现的次数N,然后按照公式(5)计算字节在每列中的频率,将每一列中频率最大的那个字节加入字节候选集合Sbyte_list,并将每列中包含此候选字节的行号加入行候选集合Rhang_list,直到循环遍历完矩阵a[n][m];
(5)
③设置频率阈值为[0.2,1],将字节候选集合Sbyte_list满足该阈值范围的字节筛选出来,即为高频字节集Slist;
④依据筛选出来的高频字节,将候选字节对应的行候选集合Rhang_list更新为高频字节对应的行集合Rh_list;
⑤计算高频字节对应的行集合Rh_list中数据对象之间的相似度值,设置数据帧之间的相似度阈值,如果数据帧之间的相似度值大于设置的相似度阈值,则将其合并,否则,不合并,直到数据集中无可合并的数据帧。本文通过对高频字节对应的行集合Rh_list中任意2个高频字节对应的行集合进行相似度计算,设置相似度阈值,如果这2个高频字节所对应的行集合相似度大于设置的阈值,则将该2个行集合合并组成一个新的行集合,直到集合Rh_list中无可合并的数据对象,然后更新高频字节对应的行集合Rh_list为初始聚类中心集合Rlist,即是算法的输入初始聚类中心,其个数即为初始聚类个数K值;
相似度距离计算方法为假设集合Rh_list中的2个数据对象为集合Si(设集合Si为筛选出来的高频字节X所在的行号集合)、集合Sj(设集合Sj为筛选出来的高频字节Y所在的行号集合),其相似度距离为
(6)
相似度的阈值limsimilar设定方法:因为经过阈值筛选合并后的集合Rh_list中的数据对象就是K-Means聚类算法的初始聚类中心,其个数就是K值,所以此若limsimilar的值设置越大,小于此阈值的集合不合并,最后得到的K值越大;若limsimilar的值设置越小,大于此阈值的集合合并,最后得到的K值越小。本文根据数学中的中值定理,将limsimilar的值从0.1~1,绘制limsimilar-k函数曲线,计算曲线的平均K值作为聚类算法的初始输入K值。
(7)
(7)式中:X1=(x11,x22,…,x1n),X2=(x21,x22,…,x2n)为n维向量。当余弦相似度取值为1时,说明数据对象X1,X2完全一样,其每一维度的分量都是完全一样的,当余弦度取值为0时,刚好相反。
⑦输入K值、初始聚类中心、向量化后的n条数据帧;
⑧按照公式(7)计算数据帧x到每个聚类中心的相似度值,并将其划分到相似度值最高的类簇中;
⑨按照公式(3)计算目标准则收敛函数E;
⑩更新聚类中心,重新计算收敛函数E。若函数E不收敛,则转到步骤⑦继续运算,若其收敛,则结束,输出K个类簇。
2.3 聚类评估方法
由于未知协议的识别与分类无法使用F-Measure进行识别的准确度评价。本文选用对聚类输出的每一个类簇,将每个类簇中的帧数据按照预处理方法构建成二维矩阵。按公式(5)统计每一列中每个字节出现的概率,再按照公式(4)计算每一列的熵值,直至循环遍历完矩阵中所有元素。计算所得的熵值代表了聚类簇中数据集的纯净程度,如果分类出来的类簇只包含一种协议,则该类簇计算所得熵值较小及中存在信息熵值为0;如果分类出来的类簇中不是单一协议而是夹杂了其他协议,则该类簇计算所得熵值较大且几乎不存在信息熵值为0的情况。所以,可选定信息熵来评价未知协议分类识别的准确度。
3 实验与结果分析
3.1 数据准备
本文在真实的实验室环境下,采用抓包工具wireshark对连接有智能家居设备(该智能家居设备采用的协议类型为MQTT协议)以及其他终端设备的目标路由器进行协议流量数据采集,分别选取2组数据作为本文的实验测试数据,其所选的实验测试数据如表1所示。

表1 测试数据表Tab.1 Test data table
3.2 结果分析
1)2组数据作为输入,先根据limsimilar-k函数曲线计算出算法初始输入聚类个数K值和及初始聚类中心。不同的limsimilar-k取值,对应不同的K值,其第1组数据的limsimilar-k取值统计如表2所示,第1组数据的limsimilar-k函数曲线关系如图3所示。
其第2组数据的limsimilar-k取值统计如表3所示,第2组数据的limsimilar-k函数曲线关系如图4所示。

表2 第一组数据limsimilar-k取值统计Tab.2 limsimilar-k value statistics of the first data

图3 第1组数据的limsimilar-k曲线图Fig.3 limsimilar-k graph of the first data

表3 第二组数据limsimilar-k取值统计Tab.3 limsimilar-k value statistics of the second data
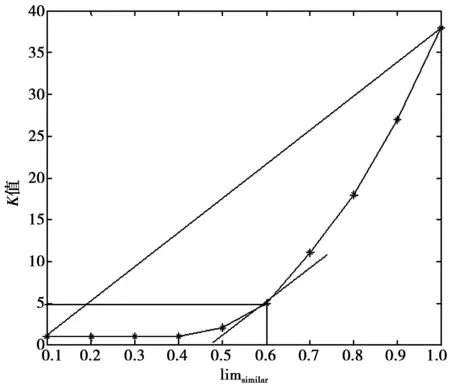
图4 第2组数据的limsimilar-k曲线图Fig.4 limsimilar-k graph of the second data
根据中值定理,将曲线的首尾相连,然后作其平行线,以最后离开曲线的那一切点,即为对应的K值。第1组数据得到的K=6;第2组数据得到的K=5。也即是指定第1组、第2组数据的初始K值分别为6和5,然后作为本文改进的K-Means的聚类算法的初始输入。因为本文是将已知的数据作为未知的数据来算,所以仍然可以使用F-Measure进行聚类准确率的评估。
经本文方法分类识别后,第1组数据总数据帧共500,被正确分类出了419条数据帧,其中智能家居协议MQTT为100帧被正确识别分类出了93帧,由此得到本文改进算法的准确率为
其智能家居协议MQTT协议识别的精度为
经本文方法分类识别后,第2组数据总数据帧共500,被正确分类出了469条数据帧,其中智能家居协议MQTT为100帧被正确识别分类出了97帧,由此得到本文改进算法的准确率为
其智能家居协议MQTT协议识别的精度为
2)聚类算法效果评估分析。本文选取了100帧智能家居协议MQTT作为单协议类簇、50帧MQTT协议与50帧DNS混合协议作为另一类簇,取每一个类簇的协议帧前40字节,也即二维矩阵的前40列。计算其每列信息熵值,计算结果绘图如图5所示。
从图5可以看出,对于只有一种智能家居协议MQTT类簇来说,其每列的熵值都偏低于混合的MQTT和DNS协议类簇,且存在多列信息熵值为0的列,这也说明只有一种智能家居协议MQTT类簇纯净度很高,证明了使用信息熵作为未知协议聚类效果评价指标的正确性和可行性。
3)算法准确率仿真。以本文改进的方法和原有的K-Means聚类算法对这2组数据进行分类的准确率对比如图6所示。

图6 本文改进的方法与原有K-Means算法准确率对比Fig.6 Contrastive of accuracy rate between improvement method and
由图6可以看出,本文改进的K-Means算法在准确率上比原有的K-Means算法平均高出约25%。
4 总 结
本文提出了多协议下智能家居协议的分类方法,使用数理统计计算K值和初始聚类中心,解决了K值和初始中心选择的随机性问题;基于向量空间模型的概念,使用数据对象之间的相似度代替数据对象之间的距离,加快了聚类算法中目标函数的收敛速度;最后提供了一种未知协议分类的评价指标:用信息熵作为评价聚类效果。本文只是将智能家居协议分类出来,下一步将研究在无任何先验知识的情况,研究分析智能家居协议的具体格式、语义、参数等。
参考文献:
[1] 朱敏玲,李宁.智能家居发展现状及未来浅析[J].电视技术,2015(4):82-85+96.
ZHU Minling ,LI Ning. The present situation and future analysis of the smart home[J].Video Engineering,2015(4):82-85+96.
[2] SINGH A, THAKUR N, SHARMA A. A review of supervised machine learning algorithms[C]// 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom). India: IEEE, 2016:1310-1315.
[3] 林荣强.网络协议识别关键技术研究[D].郑州:解放军信息工程大学,2015.
LIN Rongqiang. Research on key technologies of network protocol recognition[D]. Zhengzhou: Information Engineering University,2015.
[4] 王庆亮.未知协议逆向分析关键技术研究[D].北京:北方工业大学,2015.
WANG Qingliang. Research on key techniques of inverse protocol analysis for unknown protocol[D].Beijing: North China University of Technology,2015.
[5] 宋疆.无线网络环境下未知协议发现探索研究[D].成都:电子科技大学,2013.
SONG Jiang. Research on unknown protocol discovery in wireless network environment[D].Chengdu:University of Electronic Science and Technology of China,2013.
[6] 王和洲. 面向比特流的链路协议识别与分析技术[D].合肥:中国科学技术大学,2014.
WANG Hezhou. Link protocol recognition and analysis technology facing the bitstream[D]. Hefei:University of Science and Technology of China,2014.
[7] FEN L, TONG L, CHUN-RUI Z, et al. Length Identification of Unknown Data Frame[C]//2012 Eighth International Conference on Computational Intelligence and Security. Guangzhou, China:IEEE,2012,674-677.
[8] 戴理,舒辉,黄荷洁. 基于数据流分析的网络协议逆向解析技术[J]. 计算机应用,2013(5):1217-1221.
DAI Li ,SHU Hui ,HUANG Hejie. The reverse analysis technology of network protocol based on data flow analysis[J]. Journal of Computer Applications,2013(5):1217-1221.
[9] 黄笑言,陈性元,祝宁,等. 基于字节熵矢量加权指纹的二进制协议识别[J]. 计算机应用研究,2015(2):493-497.
HUANG Xiaoyan, CHENG Xingyuan, ZHU Ning, et al. Binary protocol recognition based on vector entropy of vector entropy[J]. Application Research of Computers, 2015(2):493-497.
[10] 宋建林. K-means聚类算法的改进研究[D].合肥:安徽大学,2016.
SONG Jianlin. Research on the improvement of K-means clustering algorithm[D]. Hefei:Anhui University, 2016.
[11] 赵京胜,孙梦丹,张丽. 一种有效的K-means初始中心优化算法[J]. 信息技术与信息化,2016(5):77-79.
ZHAO Jingsheng ,SUN Mengdan ,ZHANG Li. An effective initial center optimization algorithm of K-means[J]. Information Technology & Information, 2016(5):77-79.
[12] KAPIL S, CHAWLA M. Performance evaluation of K-means clustering algorithm with various distance metrics[C]//2016 IEEE 1st International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES), Delhi, India: IEEE,2016, pp. 1-4.
[13] LING S, YUNFENG Q. Optimization of the distributed K-means clustering algorithm based on set pair analysis[C]//2015 8th International Congress on Image and Signal Processing (CISP). Shenyang, China: IEEE,2015,1593-1598.
[14] KAPIL S, CHAWLA M. Performance evaluation of K-means clustering algorithm with various distance metrics[C]//2016 IEEE 1st International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES). Delhi, India:IEEE,2016,1-4.
[15] 郭庆琳,李艳梅,唐琦. 基于VSM的文本相似度计算的研究[J]. 计算机应用研究,2008(11):3256-3258.
GUO Qinglin, LI Yanmei, TANG Qi.Research on text similarity calculation based on VSM[J]. Application Research of Computers, 2008(11):3256-3258.
