基于两阶段学习的专家群体评价信息集成方法研究
2018-06-14赵志伟
赵志伟,乔 晗
(1. 天津财经大学 理工学院,天津 300222; 2.河南大学 经济学院,河南 开封 475004)
一、引 言
在统计综合评价中,与个体评价相比,专家群体(群组)评价集成多个评价者的评价信息,用于测度定性指标和分配指标权重。因其力图避免可能出现的个体主观偏差,在评价实践中得到较广泛运用[1-5]。但专家群体评价中,将各专家的主观偏好信息集成起来并不简单。受认知水平、知识结构等方面差异影响,不同专家对于同一问题,可能以不同精度或数据类型表达自己的偏好信息,如何有效集成这些偏好信息的理论方法也成为评价研究的一个热点和前沿问题。近年来很多学者围绕不同类型及精度的专家偏好集成问题展开研究,主要包括两个方面:一是不同类型偏好信息集成研究,如将二元语义、模糊数及语言等级等多类型数据测度得到的专家偏好信息,统一转化为某种特定数据形式后,再利用相应算子集成[6-7];二是同类型数据下的不同精度偏好信息集成研究,如偏好信息以不同精度或语义表达的集成问题,通常做法是首先将其统一转化为基于某个预设标准语言集合的偏好信息,然后进行集成[8-9]。
上述两种集成思路的共同特点是先分别测度,后统一形式。其统一过程通常人为主观设定,缺乏依据,导致集成结果的合理性受到质疑。为此,乔晗基于证据理论提出一种直接以统一数据形式(半可加离散分布),测度不同类型及精度个体偏好的思路,免去了多类型数据转化规则的主观设定环节[4]。但该文献没有给出这种数据类型相适应的群体偏好一致性检验方法。而群体评价者间偏好信息存在分歧往往难以避免[10],当强行集成分歧较大的群体偏好时,可能受极端值影响而导致集成结果缺乏代表性,难以得到专家普遍认可[11]。
本文借鉴国内外相关成果,提出一种基于两阶段学习的专家群体评价方法。首先利用基于子集空间的半可加离散条件分布,测度专家各类型及精度的偏好信息,在此基础上构建规则模拟专家第一阶段学习过程,将偏好信息统一转化为精度一致的确定性分布;然后重新界定专家群体偏好的一致性概念,提出相适应的群体偏好一致性检验方法,并建立第二阶段学习过程,基于贝叶斯迭代机制,调整不满足一致性检验的专家群体偏好至满足集成要求;最后利用马尔科夫链集成专家群体偏好信息。
二、个体偏好信息测度
假设构建一个由独立专家t(t=1,2,…,p)组成的群体E,每位专家能够并愿意利用语言等级Hk(k=1,2,…,q)*元素Hk(k=1,2,…,q)分别为相应的语言评价等级,且有H1H2…Hq,其中“”表示“劣于”。构成的集合H,给出关于评价对象i(i=1,2,…,m)在指标j(j=1,2,…,n)下,关于评价目标表现Xij的偏好信息。显然评价前Xij是一个未知量。根据贝叶斯理论,可将其视为一个遵从某种分布的随机变量,而每位专家对Xij偏好表达则可视为该随机变量下的一次随机试验。基于上述思路,下文首先通过定义集合H有效子集,确定随机变量Xij所有可能的取值。
定义1假设一个由Hk(k=1,2,…,q)构成的集合H,则称其中任意一个存在评价意义的子集Bk⊆H(k=1,2,…,q')为关于H的一个有效子集,而全集H、空集φ,及由下标k不连续元素构成的子集都非有效子集。

基于上述思路,本文利用基于证据理论的半可加离散分布[4],描述不同精度及类型的专家偏好信息。专家t关于评价对象i在指标j下的主观偏好信息可表示为如下定义形式。

(1)
式(1)中P(Xij=k|E=t)表示专家t认为“评价对象i在指标j下被评价为Bk”这一命题为真的信度,由专家根据自身经验主观决定;P(Xij=H|E=t)专家t由于缺乏知识或经验(无知),未能将总量为1的信度完全分配给所有可能偏好选择,并最终赋予集合(识别框架)H。
条件分布V(Xij|t)可描述专家诸如模糊、区间及无知等多种不精确程度及类型的偏好信息*关于条件分布如何描述各种类型偏好信息的具体内容,可参阅乔晗(2017)的论文。,且当其几乎没有证据支撑一个命题时,可通过同时赋予命题及其否命题低信度的方式表达无知。这是因为证据理论的信度函数放松了“完全概率分布”的要求,并能通过信度函数和似然函数表达不确定性(以区间形式)和无知程度(二者差值)。至此,专家间不同类型的偏好信息得以统一测度。
三、专家偏好自学习
经过测度的偏好信息只有通过一致性检验后才能进行集成。但式(2)定义的条件分布V(Xij|t)(t=1,2,…,p)精度差异为一致性检验造成了困难:如果两专家偏好信息的精度不同,其相似程度显然无法判断,群体间偏好的一致性检验就难以开展。因此,本节建立第一阶段学习机制,通过模拟专家交互反馈过程,将含有模糊或未知成分的半可加分布,转化为满足概率三原则的确定性离散分布,为群体偏好信息一致性检验与集成奠定基础。
假设专家在交互学习中表现为如下路径:当自身由于对某个问题了解程度不够,导致偏好中存在模糊或无知成分时,会倾向于参考他所信任专家的意见。基于此,专家t第一阶段学习具体分为两步。
第一步确定需要学习的专家。当专家t初始偏好V(Xij|t)满足以下条件:

(2)
表明该专家需要通过学习消除自身偏好中的模糊或无知成分。
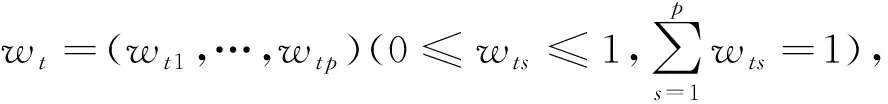
(3)
其中
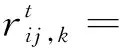
(k=1,2,…,q,l=k+1,k+2,…,q')
(4)
上式中
(5)
(k=1,2,…,q)

采纳度向量wt由专家t主观给出,其中wts表示其认为专家s在该评价领域具有权威性和信任程度。如对自身偏好较为自信,则对wtt赋予较高数值。
四、群体偏好一致性检验
满足一致性检验是群体偏好有效集成的前提条件,因此经过第一阶段学习得到的群体偏好信息R(Xij|t)(t=1,2,…,p)在集成前需要首先进行一致性检验。现有文献对“群体偏好一致性”主要有两种理解:一是将其视为“群体达成一个多数认可的结果,反对者很少且认识到曾有机会影响该结果”[12]89-96;但更多学者将其视为“群体中专家间偏好的相似性较高”,并在方法上通过“任意两专家间偏好相似度的加权平均值”或“所有专家偏好与整体偏好相似度的加权平均值”测度相似性[13-15]。但平均意义一致性,可能存在个别非一致性较高的专家偏好被平均的情况。本节首先界定群体偏好信息的一致性概念,然后给出两个评价者半可加性分布偏好信息的相似度测定方法,在此基础上检验群体偏好分布信息的一致性,并给出非一致性群体偏好的识别方法。
(一)群体偏好一致性概念的重新界定
本文认为群体中所有评价者之间偏好信息的一致性,是指群体中任意两个评价者之间偏好信息的一致性均达到一定水平。基于此,下文重新界定群体评价者偏好信息一致性概念。
定义3假设群体E中任意两专家的偏好信息为Rt和Rs,则当
s(Rt,Rs)≥σ,∀t,s=1,2,…,p且t≠s
(6)
则称群体偏好信息具有一致性,其中σ为预设一致性阈值,s(Rt,Rs)则为专家t和s偏好信息的相似度。
因此,群体偏好信息一致性检验的关键是两专家偏好的相似度测定,下文给出基于确定性离散分布信息的偏好相似度测定思路。
(二)群体内两专家偏好分布相似度测定
首先定义群体中任意两专家间偏好分布信息的分歧度。
定义4假设经过第一轮学习后,两专家t和s的偏好分布信息分别为R(Xij|t)和R(Xij|s),则二者偏好在集合H中相同元素下的分歧分布为:
(k=1,2,…,q)
(7)
同时考虑集合H中元素之间的等级差异,得到最终两偏好信息在两个层次上的分歧度为:
(8)

在此基础上给出群体中两专家偏好信息相似度的定义。
定义5假设群体中两专家t和s的偏好分布信息分别为R(Xij|t)和R(Xij|s),则称:
(9)
为两专家间偏好分布信息的相似度。
根据式(6)~式(9)即可检验群体偏好信息是否满足集成要求。
五、群体偏好一致性自调整
当专家群体偏好信息不满足一致性检验时,需要在集成前进行一致性调整。现有群体偏好信息一致性调整方法主要有三种思路:一是专家间通过多轮交互与反馈实现群体偏好一致性收敛[2],还有文献加入引导模型,通过给出偏好调整建议、删除分歧度较大偏好*Zhang 等(2015)认为两个专家偏好分歧度较大说明至少有一个专家偏好值得怀疑,删除这与整体偏好一致性相对较差的专家偏好,实现群体偏好信息一致性收敛。以及减少偏好调整人数与轮次等方式,加速评价群体偏好收敛[7]。二是利用迭代模型模拟专家交互反馈机制,实现一致性自收敛[13-15]。三是通过降低偏好一致性较差专家对整体偏好的贡献度(权重),实现一致性自收敛[16]。上述思路中的自收敛机制没有考虑不同专家偏好调整的差异性,交互反馈机制往往未考虑专家能够且愿意调整自身偏好的次数限制,且暗含强迫专家为迎合一致性而妥协的要求,导致最终专家偏好与其初始意见差距过大。基于此,本节建立第二阶段学习,通过模拟群体专家间信息交互反馈的偏好调整机制,收敛群体偏好至满足一致性要求。
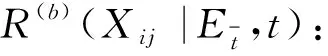
(10)
(k=1,2,…,q)
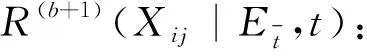
(k=1,2,…,q)
(11)
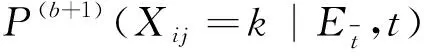
(12)
专家群体偏好信息按式(10)~式(12)进行迭代至满足一致性检验。
六、群体偏好信息集成与比较
本文利用马尔科夫链标准极限定理,通过模拟收敛基于信任矩阵n次迭代的专家偏好信息,集成满足一致性检验的群体偏好,得到整个专家群体对指标Xij的测度。
假设专家t根据对其他专家的信任程度wt=(wt1,wt2,…,wtp)调整自身偏好为如下形式:
(13)
(t=1,2,…,p)

(14)

(Xij|t=p)]
(15)
则可得:
Vij,(1)=Bij·Vij
(16)
即通过式(16)将群体专家偏好向量Vij转化为Vij,(1)。如此迭代n次后得到的群体偏好向量为:
Vij,(n)=[R(n)(Xij|t=1),…,
R(n)(Xij|t=p)]
(17)
其中
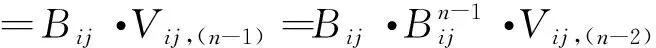
(18)
根据式(18),如果最终出现一个n,使得
Vij,(n)=Vij
(19)

(20)
(t=1,2,…,p)
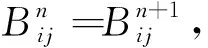
(21)
有式(20)成立。显然hij中元素满足

(22)
因此,最终收敛结果为:
(23)
下文给出收敛性证明。假设将每位专家的偏好信息R(Xij|t)(t=1,2,…,p)视为一个有限马尔科夫链的状态空间T′,由于矩阵Bij中的元素wts满足条件:
① 在表1中该偏好信息简写为“(H4,0.8)”,下同。
(1)0≤wts≤1,t,s∈T′



(24)
(25)
满足条件(1)和(2)的唯一解。
至此,可通过集成专家群体偏好信息得到最终的指标测度结果V(Xij)。利用同样方法可测度评价指标体系中的其余指标。
七、两阶段学习的具体步骤
综上所述,本文基于两阶段学习的专家群体评价方法可归纳为如下5个步骤:
Step1:利用式(1)和定义1和2,将群体中专家不同类型及精度的主观偏好信息,统一测度为半可加离散分布形式。
Step2:执行第一阶段专家学习,利用定义2~5,通过模拟专家间交互学习过程,将群体专家的半可加离散分布转化为确定性分布。
Step3:利用定义3~5及式(6)~式(9),对基于不同专家间的确定性分布信息进行一致性检验,判断是否满足偏好信息集成要求。若通过检验则执行Step5,否则执行Step4。
Step4:执行第二阶段群体专家自学习,利用式(10)~式(12)调整Step3中未通过一致性检验的群体偏好至满足集成要求。
Step5:利用式(13)~式(25)集成满足一致性检验的群体偏好,得到各评价对象在不同指标下的表现。
八、实例分析
高成长的中小企业能够显著促进就业与经济增长,但中国中小企业成长的衰减速度显著高于其他国家,增加了经济的不稳定性与资本投资的风险。因此,如何有效评价及识别高成长性的中小企业,成为政府决策部门、学术界及资本市场一直以来力图解决的问题。本节通过建立含有8位专家的群体(et,t=1,2,…,8),从企业家素质y1、创新能力y2、运营水平y3、产品竞争力y4及环境因素y5等5个方面对4家中小企业的成长性展开评价,以验证本文方法的可行性和有效性。
首先测度群体专家的偏好表达。每位专家根据自身经验及知识,利用评价等级集合H={Hn|n=1,2,3,4,5},自由、充分表达关于每个评价对象在所有指标下的偏好信息,其中Hn(n=1,2,3,4,5)依次表示“差,较差,一般,较好,好”。
Step1:群体专家偏好信息测度首先利用式(1)测度群体专家的偏好信息。如在企业a1的企业家素质(y1)中:专家e1给出的偏好信息是“有80%的把握应该被评价为H4”,并未给出剩余20%的信度如何分配;e2认为“只有50%的把握可被评价为H5,并愿意把另外30%的信心放在H3至H4之间”,同样有20%的信度未分配;e3是“分别有80%和20%的把握被评价为H4和H3”;e4“确定(100%)应该被评价为H4”;e5是“确定应该被评价为H4与H5之间”,但未给出更为详细的信度分配。利用式(1)可统一测度上述不同类型及精度的偏好信息,其中专家e1的偏好信息V(X11|t=1)可描述为①:
V(X11=4|t=1)=0.8
V(X11=0|t=1)=0.2
表示其仅给出有效子集H4的信度,而对于剩余20%信度分配表现为无知。同理,专家e2将信度分别分配给了有效子集H3H4与H5,由于无知将剩余20%信度分配给识别框架H。而专家e3偏好中不存在无知,并将总量为1的信度完全分配给有效子集H4和H3,表示一种确定性分布息。而专家e5虽然完全分配了所有信度(不存在无知),但难以给出更为详尽的分配方案,表现出一种模糊偏好信息。表1为所有专家对企业a1在5个定性指标下经过测度的偏好信息。受篇幅所限,本文没有列出其余3个企业的相应数据。

表1 群体专家关于评价对象a1在所有评价指标下的偏好信息测度

表2 群体专家采纳度矩阵
Step2:群体专家第一阶段学习。利用式(2)~式(5)执行第一阶段专家学习,将表1中群体专家间不同精度的半可加离散分布,统一转化为式(3)中的确定性分布(保留两位小数),其中采纳度矩阵如表2所示,其中wts表示专家t认为专家s在该评价领域权威性和信任程度。
Step3:群体专家偏好信息一致性检验。假设预设一致性阈值σ=0.70,利用式(6)~式(9)检验每个指标下各位专家偏好信息的一致性后发现,群体偏好在y13和y14两指标下不满足集成条件,剩余指标均满足基于阈值下的一致性要求。
Step4:群体专家第二阶段学习。当专家群体偏好信息不满足一致性检验时,需要在集成前进行一致性调整。利用式(10)~式(12),调整上述两个指标下的群体偏好至满足集成要求。
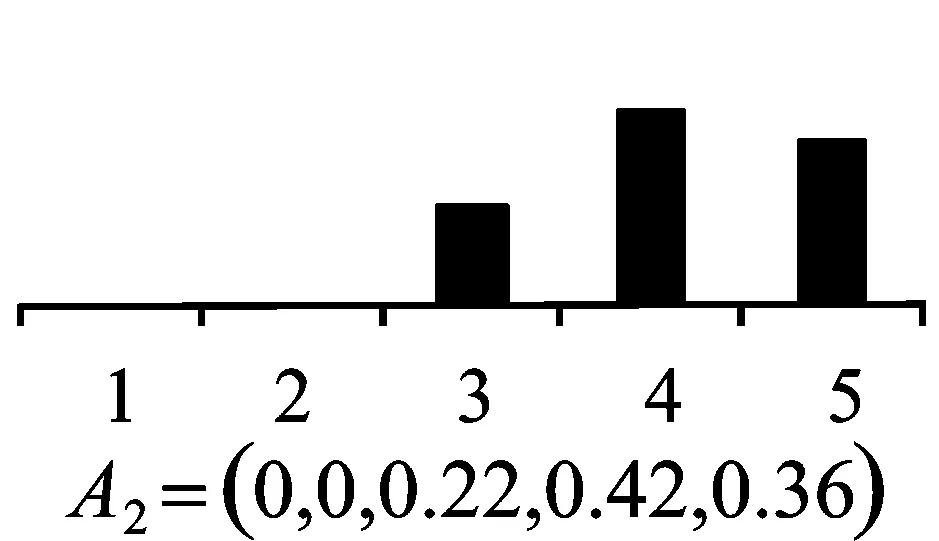
Step5:群体偏好信息集成。最后利用式(13)~式(23)集成满足一致性要求的群体偏好信息及指标信息,得到企业a1成长性最终评价结果。通过相同方法得到如图1所示的其余3家企业成长性的评价结果。
九、结 论
本文围绕专家群体评价中可能出现的不同类型及精度个体偏好信息的集成问题,提出一种基于两阶段学习的专家群体评价方法,主要贡献如下。
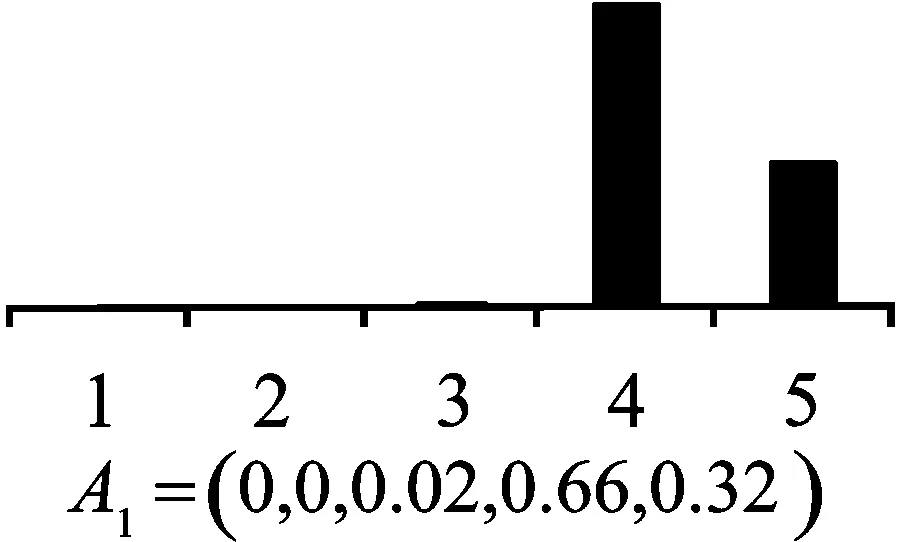
(a1)

(a2)
(a3)
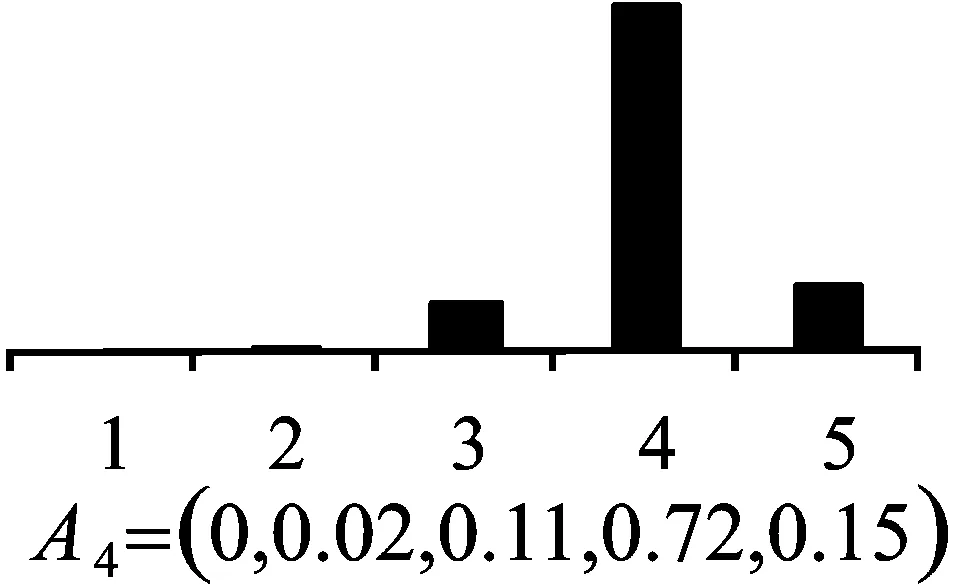
(a4)图1 4家中小企业成长性评价结果
第一,建立第一阶段专家学习机制,通过模拟专家偏好信息调整,实现半可加离散分布向确定性分布的精度统一化目标,为群体偏好的一致性检验奠定基础。该过程并通过构建可采纳度向量区分不同专家间偏好调整的异质性。
第二,重新界定专家群体偏好信息一致性的概念,以避免存在非一致专家偏好被平均的伪一致性情况出现,尽可能提高群体偏好集成的有效性。
第三,建立第二阶段专家学习机制,模拟群体专家间的交互反馈机制,尽可能贴近偏好调整实际情况同时无需专家参与,并通过构建信任向量的方式区分不同专家偏好调整与集成过程的异质性,提高集成方法的可操作性及效率。
参考文献:
[1] 陈骥, 苏为华. 关于群组评价技术若干问题的探讨[J].统计研究, 2008,25(8).
[2] Mata F,Martinez L,Herrera-Viedma E. An Adaptive Consensus Support Model for Group Decision-Making Problems in a Multigranular Fuzzy Linguistic Context[J]. IEEE Transactions on Fuzzy Systems,2009,17(2).
[3] 张崇辉,苏为华,曾守桢. 存在领导者的自组织群组评价技术及应用[J].统计研究,2017,34(8).
[4] 乔晗. 基于证据理论的综合评价定性指标测度优化研究[J].统计与信息论坛,2017,32(6).
[5] 乔晗. 主成分综合评价方法评述及适用性问题研究[J].天津商业大学学报,2015,35(3).
[6] Herrera F,Martinez L. A Model Based on Linguistic 2-tuples for Dealing with Multigranular Hierarchical Linguistic Contexts in Multi-Expert Decision-Making[J].IEEE Transactions on Systems Man & Cybernetics Part B Cybernetics A Publication of the IEEE Systems Man & Cybernetics Society,2001,31(2).
[7] Zhang F,Ignatius J,Zhao Y,et al. An Improved Consensus-Based Group Decision Making Model with Heterogeneous Information[J].Applied Soft Computing,2015(35).
[8] Morente-Molinera J A,Pérez I J,Urea M R,et al. On Multi-Granular Fuzzy Linguistic Modeling in Group Decision Making Problems:A Systematic Review and Future Trends[J].Knowledge-Based Systems,2015,74(1).
[9] Herrera-Viedma E,Martinez L,Mata F,Chiclana F. A Consensus Support System Model for Group Decision-Making Problems With Multigranular Linguistic Preference Relations[J].IEEE Transactions on Fuzzy Systems,2005,13(5).
[10] Zhang W,Xu Y,Wang H. A Consensus Reaching Model for 2-tuple Linguistic Multiple Attribute Group Decision Making with Incomplete Weight Information[J].International Journal of Systems Science,2016,47(2).
[11] 杜娟,霍佳震. 交互式多属性群决策评价方法研究[J].中国管理科学,2016,24(11).
[12] Ben-Arieh D,Chen Z. Linguistic-Labels Aggregation and Consensus Measure for Autocratic Decision Making Using Group Recommendations[M].Piscataway:IEEE Press,2006.
[13] Xu Z,Cai X. Group Consensus Algorithms Based on Preference Relations[J].Information Sciences,2011,181(1).
[14] Xu Y,Sun H,Wang H. Optimal Consensus Models for Group Decision Making under Linguistic Preference Relations[J].International Transactions in Operational Research,2015(3).
[15] Xu Z. An Automatic Approach to Reaching Consensus in Multiple Attribute Group Decision Making[J].Computers & Industrial Engineering,2009,56(4).
[16] Lee H S. Optimal Consensus of Fuzzy Opinions under Group Decision Making Environment[J].Fuzzy Sets & Systems,2002,132(3).
