基于属性聚类的离群数据挖掘算法
2018-06-04李俊丽张继福
李俊丽, 张继福
(1. 太原科技大学 计算机科学与技术学院, 山西 太原 030024; 2. 晋中学院 信息技术与工程学院, 山西 晋中 030619)
0 引 言
离群检测是数据挖掘中的一个经典问题, 应用非常广泛, 如犯罪活动[1], 入侵检测[2-3], 工业控制系统异常检测[4], 以及光谱数据挖掘[5]等领域. 随着科学技术的发展, 数据的收集更快也更容易, 从而导致高维海量数据集的产生. 对于处理高维海量数据集, 由于数据量大和维度高, 许多离群挖掘算法效率会降低, 可能很难发现仅出现在多维相关性空间中的一些离群数据. 很多情况下, 许多高维数据集是从不同的角度观察度量数据对象所集成的结果, 因此可以考虑从不同的角度对属性进行分组, 相关性高的属性可以归为一组. 比如在基因表达数据中, 有核血细胞的数据属性被分成密度、 颜色和结构等几个组, 还比如在一个银行客户数据集中, 属性可以分为客户组、 显示客户账户信息的账号组和描述客户消费行为的消费组等, 可疑客户可能只显示和一些金融事务相关的消费活动, 而客户信息和账号信息是正常的. 因此, 一个数据对象可能在一个属性组中为普通数据, 但在另一个属性组中却是离群数据. 不同属性组代表不同的属性信息, 因此在数据挖掘过程中应该考虑不同属性之间的差异性, 将属性分成不同的组以构成不同的属性子空间, 这样有助于在每个属性子空间中挖掘数据模式的不同方面, 以便挖掘更有意义的离群数据.
传统的分类数据离群挖掘方法很多考虑的是在全维空间挖掘离群值, 这些方法忽略了属性之间的关系, 因而很难检测隐藏在属性子集中的离群值. 本文提出一种新的离群挖掘方法来识别高维分类数据集中的离群值. 算法由两个不同的阶段组成. 在第一阶段, 属性子集是通过度量属性之间的相关性而创建的, 相关性高的属性被放置在一个属性子集中. 第二个阶段是专门的离群挖掘, 每个属性子集的数据对象都被分配离群分数. 离群分数高的对象被认为是离群值. 本文将现有的三个分类数据离群检测算法和本文提出的算法进行比较, 并应用人工合成数据集和UCI实际分类数据集来评估四个算法的性能.
1 离群挖掘技术
随着高维数据越来越多, “维灾”影响了许多离群挖掘算法的效率. 针对高维数据集已经提出了很多离群挖掘算法, 子空间离群检测方法就是在相关的子空间中寻找离群点, 关于如何确定子空间的相关性也发展了很多技术.
1.1 子空间离群挖掘
文献[6]提出HOS-Miner动态子空间搜索算法, 该算法使用固定的阈值来识别离群数据, 但不同维度的子空间中离群得分无法比较. 文献[7]引入新的离群得分计算方法, 通过得分函数评估分析子空间确定的数据对象的偏差, 但在此算法中离群数据是基于密度的聚类所产生的副产物. 文献[8]提出一个高维特征空间变化的子空间中挖掘离群数据的原始离群检测模式, 尤其对于数据集中的每个对象, 搜索跨越其最近邻的轴平行子空间以确定这个子空间中对象偏离其最近邻的程度. 文献[9]在几个子空间中同时评估每个数据对象的偏离程度, 通过计算每个数据对象的密度来确定适应于不同维度的子空间, 单个子空间中的得分是比较对象密度和它近邻的平均密度, 一个数据对象总得分是它在所有相关子空间的得分. 文献[10]提出一个性能不受维度影响的高维数据子空间离群挖掘算法. 文献[11]提出一种新的子空间搜索方法, 选择高对比度的子空间基于密度的离群值进行排名, 聚集局部异常因子(Local Outlier Factor, LOF)得分超过所有的“高对比度”子空间的单个数据对象, 但这种方法只适合基于密度的离群挖掘.
1.2 分类数据离群挖掘
分类数据离群挖掘方法一般分为基于规则的和基于熵的算法. 基于规则的算法受到关联规则挖掘领域中频繁项的概念的启发, 提供了对数据集的频繁或不频繁项的分析. 例如, 文献[12]提出一种通过发现频繁项集来检测离群数据的新方法. 在该算法中, 包含频繁模式的数据对象不太可能是离群值. Otey等人设计了一种由频繁项集驱动的算法[13], 该算法为每个数据对象分配一个离群得分, 与对象的非频繁项集成反比. 在对分类数据进行离群挖掘的领域中, 另一类算法是基于熵的概念. 文献[14-15]提出了基于熵的离群检测方法, 并利用熵来测量数据集与离群数据之间的无序程度. 提出了离群点的正式定义和离群点检测的优化模型等.
虽然针对高维分类数据集已经提出了很多离群挖掘算法, 然而这些方法忽略了属性之间的相对依赖性, 因此可能丢失一些仅出现在多维相关性空间的离群数据. 在本文中, 基于属性之间的相对依赖性, 高维数据的属性被分成不同的属性子集. 对于高维分类属性数据集, 本文采用属性聚类的方法将高维属性分成多个属性子集, 然后在多个属性子集上分别进行离群数据挖掘.
2 分类数据集与离群数据
目前, 针对数值型数据的离群挖掘研究已经有了很多优秀成果, 但是现实生活中存在很多分类数据, 由于分类数据缺乏固有的几何特性不能直接进行数值运算, 相应的离群挖掘算法的设计与数值型数据存在较大区别, 且相对来说也比较复杂.
通常, 一个分类属性数据集可以用一个矩阵来表示, 一行代表一个数据对象, 一列代表一个属性. 假设该数据集用矩阵D来表示, 其中数据对象xi表示第i个数据对象, 属性维Aj表示第j个属性维,xij(i=1,2,…,n;j=1,2,…,m)表示第i个数据对象xi在第j个属性上的取值. 那么分类数据集可以表示为D=(X,A), 其中,X是数据对象的集合,X={X1,…,Xn},n代表数据对象个数;A是属性的集合,A={A1,…,Am},m代表维度或属性个数.
离群数据是数据集中出现频率比较低的那些数据对象. 因此, 分类数据集中理想的离群数据对象的每个属性值都具有较低的频率.
数据对象的离群得分定义为
(1)
式中:xi,j是数据对象i在第j个属性上的值;n(xi,j) 是数据对象i的第j个属性值xi,j出现的频率.g(x)=(x-1)log(x-1)-xlogx为本文构造的一个函数, 是为了使低频率的数据对象能得到高的离群得分.
3 基于属性聚类的离群挖掘算法
3.1 属性聚类
对于高维分类属性数据集, 采用属性聚类的方法将高维属性划分成多个属性子集. 属性聚类算法是对数据集中的分类属性采用的一种聚类算法. 不同于传统的数据对象聚类方法, 属性聚类中同一聚类簇中的属性具有较高的相似性.
给定任意两个属性Ai和Aj, 属性之间的相对依赖关系表示为FR(Ai,Aj), 其定义为
(2)
式中:I代表两个属性之间的互信息;H代表两个属性之间的熵值.
对于任意一个属性Ai, 它到其他属性的关系和表示为
(3)
通过对属性进行聚类, 属性被分成不同的簇, 高维属性集被分成多个属性子集, 然后在属性子集上分别进行离群挖掘.
3.2 算法描述
算法1 属性聚类算法(Attribute Clustering)
输入:c个任选属性
输出:c个属性子集
1) for (r= 1;r≤c;r+ +) ∥c是属性子集的个数∥
2) for(i=1;i≤m;i+ +) ∥m是数据集中属性的个数∥
3) ComputeFR(yi∶ηr) betweenyiandηrby Eq.(2) ∥ηr是属性子集Cr的中心属性, 通过式(2)计算属性yi和ηr之间的相对依赖关系∥
4) ifFR(yi∶ηr)≥FR(yi∶ηs) (s∈{1,…,c}-{r})
5) assignyitoCr
6) end if
7) end for
8) ifMR(yi)≥MR(yj) (yj∈Cr,j≠i) (Eq.(3))
9) setηr=yi
10) end if
11) end for
12) Repeatedly perform step1-11 until all the numbercof features for the groups remain unchanged ∥重复算法直到c个中心属性不变∥
13) Outputcattribute subsets
算法2 Outlier Mining Algorithm Using Attribute Clustering (OMAC)
输入: 数据集DS, 属性子集个数c
输出:k个离群数据
1) Obtaincattribute subsets by algorithm 1;∥通过属性聚类得到c个属性子集∥
2) For (r=1;r≤c;r+ +) ∥c是属性子集的数量∥
3) For (i=1;i≤n;i+ +) ∥n是数据对象的数量∥
4) Compute the score of objectxiby Eq.(1);∥通过式(1)计算数据对象的离群得分∥
5) End for
6) End for
7) Searching thekobjects with greatest scores ∥查找k个得分最高的离群数据∥
8) Outputkoutliers
4 实验分析
本文选用UCI数据集和人工数据集对OMAC算法的性能进行实验分析. 实验环境为: CPU Intel(R) Core(TM) i7-4713MQ, RAM 4 GB, Windows 7操作系统, 采用 Java 语言实现了OMAC以及其他三个比较算法GA[15], AVF[16]和ITB[17].
4.1 UCI数据集
使用来自UCI的四个真实的分类数据集. 由于预先知道测试数据集中的每个对象所属于的真正类, 所以将数据集中小类中的对象定义为异常对象. 参考文献[15]的实验技术, 删除了一些小类的数据对象, 使数据集中有大约2%的数据是离群数据. 实验中使用的UCI数据集如表 1 所示.
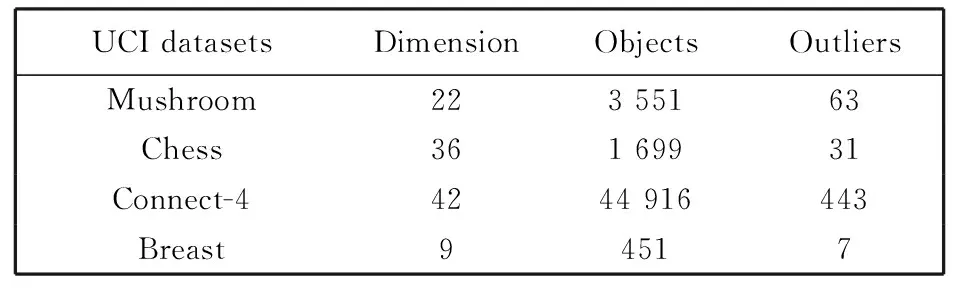
表 1 UCI数据集描述Tab.1 Description of UCI datasets
为了对离群检测算法的准确率进行评估, 在UCI数据集上采用不同算法进行了实验, 算法对真实数据集的准确率描述如表 2 所示.
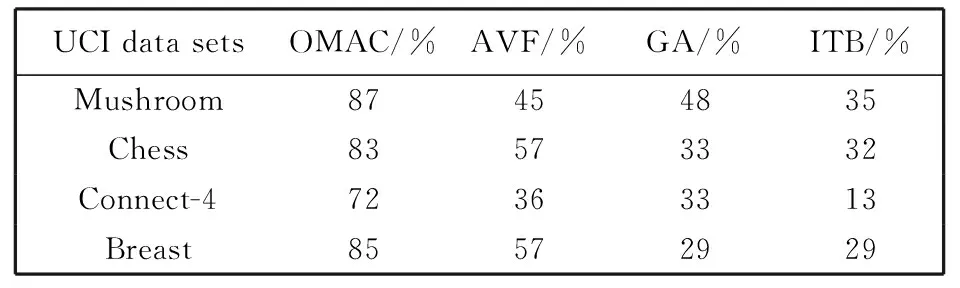
表 2 UCI数据集准确率比较Tab.2 Comparison of the accuracy in the UCI datasets
由表 2 可以看出, 与其他算法相比, OMAC算法在真实数据集上的准确率较高. 主要原因是OMAC算法是基于属性子集的离群挖掘算法, 而其他算法从所有属性维度挖掘离群数据, 准确性受到“维灾”的影响.
4.2 人工数据集
使用人工合成数据的优点是能够生成各种大小和维度的数据集. 本文使用GAClust软件生成了 50维的5 000条, 10 000条, 15 000条和 20 000条的人工数据集共4个, 分别为数据集1, 2, 3和4. 每个数据集中有1%的数据是离群数据.
4.2.1K值对不同算法准确率和效率的影响
在数据集1中, 离群数据数目k为50, 为了测试不同算法不同k值所对应的准确率, 将数据集1的离群数据数目进行了增减, 随着k值的变化, 不同算法的准确率如图 1 所示.
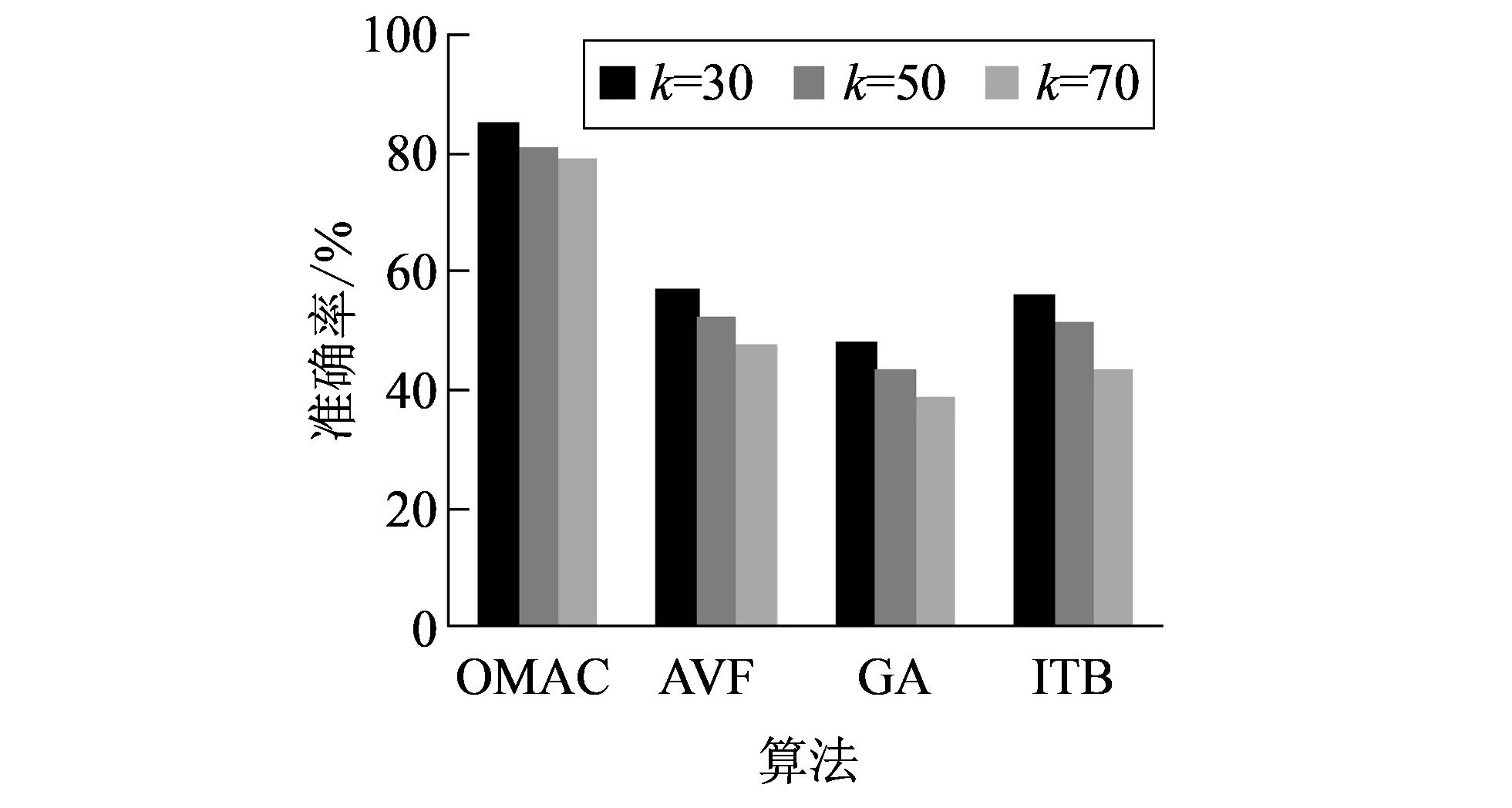
图 1 不同k值对应的准确率Fig.1 Accuracy of different k values
由图 1 可以看出, 随着k值的增加, 挖掘准确率有所降低. 主要原因是随着要挖掘的离群数据数量的增加, 挖掘难度越来越大. 但OMAC算法的准确性明显高于其他算法. 这是因为OMAC算法能够在不同的属性子集中挖掘不同的特征模式, 因此可以检测到更多的离群数据.
将数据集1的离群数据数目k分别设置为30, 60, 90, 120和150以测试离群数据数量对不同算法的效率的影响. 随着离群数目的增加, 不同算法的效率如图 2 所示.
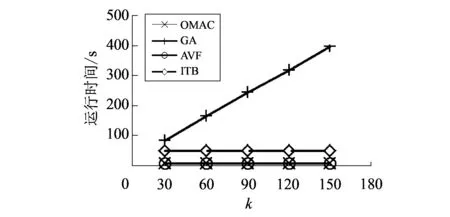
图 2 离群数据量大小对算法效率的影响Fig.2 Effect of outlier size on efficiency of algorithm
由图 2 可以看出, 随着离群数据目标数k值的增加, 其他算法运行时间都基本不变, 只有GA算法的运行时间线性增加. 这是因为GA挖掘一个离群数据需要对数据集进行一次扫描, 所以挖掘k个离群数据需要扫描数据集k次, 因此随着离群数据目标数的增加, 时间消耗会增加, 而其他的算法则不会.
4.2.2 数据对象大小和维度大小对算法效率的影响
首先, 使用数据集1, 2, 3和4来进行算法效率的测试. 随着数据集数据对象的变化, 不同算法的效率表现如图 3 所示.

图 3 数据集大小对算法的效率影响Fig.3 Effect of data set size on efficiency of algorithm
其次, 将数据集1的维度增加到100维, 150维和200维以测试维度增加对不同算法效率的影响. 随着属性维数的增加, 不同算法的效率如图 4 所示.
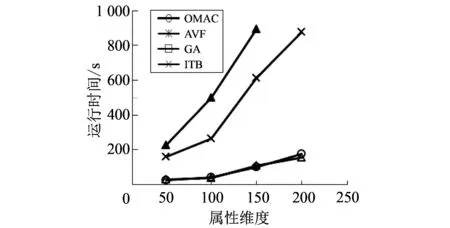
图 4 数据集维度大小对算法的效率影响Fig.4 Effect of data set dimensionality on the efficiency of the algorithm
由图 3 和图 4 可以看出, 随着数据对象的增加, OMAC的时间消耗有所增加, 但与其他算法相比, 增加的时间并不明显. 与其他三种算法相比, OMAC的运行时间增长速度比较缓慢. 这是因为GA算法的时间复杂度比其他三种算法都要高. 对于ITB算法, 由于算法需要计算出离群值的上限, 因此, ITB算法的总体复杂度略高于OMAC和AVF.
5 结 论
本文提出了一种基于属性聚类的离群挖掘算法, 称为OMAC, 用于高维分类数据集. 与大多数现有的算法不同, 该算法可以将属性进行分组, 这样可以在不同的属性子集中挖掘数据对象的不同方面, 并从高维的分类数据中挖掘出相应的离群数据. 此外, 除了需要检测的离群数据的目标数, OMAC算法不需要对任何用户给定的参数进行设置. 为了进行性能评价, 通过UCI数据集和人工合成数据集对OMAC算法进行了实验验证. 结果表明, 其在高维分类属性数据集上, OMAC与AVF, GA, ITB算法相比, 其离群数据的能力和效率都有所提高.
参考文献:
[1] 凌晨添. 进化神经网络在信用卡欺诈检测中的应用[J]. 微电子学与计算机, 2011, 28(10): 14-17.
Ling Chentian. Evolutionary neural network for credit card frand detection[J]. Microelectronics and Computer, 2011, 28(10): 14-17. (in Chinese)
[2] 梅孝辉. 基于聚类的离群点挖掘在入侵检测中的应用研究[D]. 重庆: 重庆大学, 2015.
[3] 欧阳根平. Hadoop云平台下基于离群点挖掘的入侵检测技术研究[D]. 成都: 电子科技大学, 2015.
[4] 陈庄, 黄勇, 邹航. 基于离群点挖掘的工业控制系统异常检测[J]. 计算机科学, 2014, 41(5): 178-181.
Chen Zhuang, Huang Yong, Zou Hang. Anomaly detection of industrial control system based on outlier mining[J]. Computer Science, 2014, 41(5): 178-181. (in Chinese)
[5] 张继福, 李永红, 秦啸, 等. 基于MapReduce 与相关子空间的局部离群数据挖掘算法[J]. 软件学报, 2015 26(5): 1079-1095.
Zhang Jifu, Li Yonghong, Qin Xiao, et al. Related-subspace-based local outlier detection algorithm using map reduce[J]. Journal of Software, 2015, 26(5): 1079-1095. (in Chinese)
[6] Zhang J, Lou M, Ling T W, et al. HOS-miner: a system for detecting outlying subspaces of high-dimensional data[C]. Thirtieth International Conference on Very Large Data Bases. VLDB Endowment, 2004: 1265-1268.
[7] Müller E, Assent I, Steinhausen U, et al. OutRank: ranking outliers in high dimensional data[C]. Proceedings of the 24th International Conference on Data Engineering (ICDE) Workshop on Ranking in Databases (DBRank), Cancun, Mexico, 2008: 600-603.
[8] Fayyad U M, Piatetsky-Shapiro G, Smyth P. Advances in Knowledge Discovery and Data Mining[M]. Massachusetts: MIT Press, 1996.
[9] Müller E, Schiffer M, Seidl T. Adaptive outlierness for subspace outlier ranking[C]. International Conference on Information and Knowledge Management, 2010: 1629-1632.
[10] Nguyen H V, Gopalkrishnan V, Assent I. An unbiased distance-based outlier detection approach for high-dimensional data[C]. International Coference on Database Systems for Advanced Application, 2011(6587): 138-152.
[11] Keller F, Muller E, Bohm K. HiCS: high contrast subspaces for density-based outlier ranking[J]. IEEE, 2012, 41(4): 1037-1048.
[12] He Z, Xu X, Huang Z J, et al. FP-outlier: frequent pattern based outlier detection[J]. Computer Science and Information Systems, 2005(2): 103-118.
[13] Otey M E, Ghoting A, Parthasarathy S. Fast distributed outlier detection in mixed-attribute data sets[J]. Data Mining and Knowledge Discovery, 2006(12): 203-228.
[14] He Z, Deng S, Xu X. An optimization model for outlier detection in categorical data[J]. Lecture Notes in Computer Science, 2005, 3644(1): 400-409.
[15] He Z, Xu X, Deng S, et al. A fast greedy algorithm for outlier mining[C]. Proceedings of 10th Pacific-Asia Conference on Knowledge and Data Discovery, 2006: 567-576.
[16] Koufakou A. Scalable and efficient outlier detection in large distributed data sets with mixed-type attributes[D]. Orlando: University of Central Florida, 2009.
[17] Wu S, Wang S. Information-theoretic outlier detection for large-scale categorical data[J]. IEEE Transactions on Knowledge and Data Engineering, 2013, 25(3): 589-602.
