基于字典学习的煤与矸石图像特征识别方法
2018-05-11运杰
, , ,运杰
(山东科技大学 电子通信与物理学院,山东 青岛 266590)
我国矿产资源丰富,煤炭作为最重要的战略资源在经济发展中有着举足轻重的作用。煤炭开采过程中矸石的混入极大地影响了煤的使用效率,煤与矸石的分选是煤炭利用过程中不可或缺的环节[1]。机器视觉技术[2]具有通用性强且易于实施的特点,可以实现非接触式的检测,利于环境保护,适用于煤炭开采这种重复性的工业生产,煤与矸石识别的关键在于如何有效地表达煤与矸石图像特征,特征提取的好坏将会直接影响分类识别的结果。于国防等[3]提出了利用灰度值进行煤和矸石图像识别的方法,但需要一定辅助条件,并且过程比较复杂;王祥瑞[4]提出的煤与矸石图像特征提取方法较为简单,但基于灰度值的特征提取方式单一,在煤矿特定环境下影响识别的准确度,不能满足实际需求;何敏等[5]采用了灰度共生矩阵的特征提取方法,由于提取到的特征参数比较少,容易影响识别的结果;廖阳阳等[6]采用BP网络的识别方法,因受到实验样本差异的影响,其识别精度不高。而且上述特征提取方法难以适应在实际环境情况下的分类识别,准确率也有待提高,因此需要研究可以精确描述煤与矸石图像的特征提取方法。
近年来,字典学习算法[7-8]在图像去噪、面部识别、图像修复、图像超分辨率以及图像分类等领域有着广泛的应用。字典学习算法因其稀疏的表示方式使学习得到的字典原子数量增加、形态丰富,可以与信号或者图像本身的结构进行更好的匹配。本文将采用字典学习中的K-SVD算法提取煤与矸石的图像特征,随机选择煤与矸石的样本图像作为字典原子后,将学习字典按列的顺序随机进行更新,以最大限度地将煤与矸石的图像特征有效表达出来,提高识别的效率。
1 字典学习原理
随着稀疏表示理论的不断成熟,字典学习理论被提出并应用于信号处理和图像信息领域,其中信号的“简单性”是目前研究的热点,尤其是信号的稀疏性表示,即稀疏表示。字典学习方法通过优化相应的字典学习代价函数,获得对信号进行稀疏表示的字典[9]。稀疏表示的模型为:给定字典D=d1,d2,…,dq∈Rp×q,字典D中的每一列dq∈Rp表示为一个原子,信号Y=y1,y2,…,ys∈Rp×s表示为字典D中若干原子的线性组合:Y≈DX,其中X=x1,x2,…,xs∈Rq×s为信号Y在字典D下的表示系数,由于X矩阵内有大量的零元素向量导致每个列向量都是稀疏的,因此X为稀疏矩阵。本文使用的是K-SVD字典学习算法[10-11],与其他字典学习算法相比,该算法时间复杂度较低,计算量小,适用性强,并且已经趋于成熟。
为了将字典学习算法融于煤与矸石的图像特征提取与识别中,把信号Y看作是煤与矸石的图像信号,字典D通过煤与矸石的样本图像学习得到,X为煤与矸石的图像信号Y在学习字典D下的表示系数。求解Y≈DX式中的D和X的过程便为字典学习的过程,所对应字典学习的优化问题可表示为:
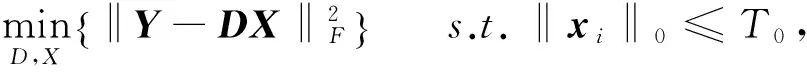
(1)
式中:Y为煤与矸石的图像信号矩阵;xi为稀疏矩阵X中某一列向量;‖·‖F为F范数;‖·‖0为L0范数;T0为设定的初始值,与稀疏度相关。为求解学习过程中的优化问题,K-SVD字典学习利用稀疏编码和字典更新两步的迭代学习算法求解固定字典D和稀疏矩阵X,直到所求变量收敛或者达到设定的迭代次数。在稀疏编码阶段,稀疏矩阵X用OMP追踪算法[12-13]进行求解,具体运算过程如图1所示,其中步骤(3)表示的是求残差r的最相关列标号,步骤(4)是通过最小二乘法获得关于每个样本图像的稀疏系数X,步骤(5)更新残差r,步骤(6)表示达到了设定的迭代次数,迭代终止。第二步是字典更新阶段,利用求解到的稀疏矩阵X对字典D进行逐列更新,若需要更新字典中的第kk=1,2,…,K列dk,目标方程可表示为:
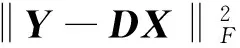
(2)
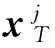
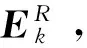
为提高煤与矸石的识别率,本文在字典初始化时从煤与矸石图像的训练样本中随机选择不同的样本作为字典原子,与顺序选择样本相比可以降低运算复杂度,提高算法收敛的速度。然后按照列的顺序随机进行字典原子的更新,最后经过多次迭代来选择最优的字典D。
输入:样本矩阵Y=[y1,y2,…,ys]∈RP×S,字典D=[d1,d2,…,dq]∈Rp×q
输出:稀疏矩阵X=[x1,x2,…,xs]∈Rq×s
(1)i=1;
(2)r0=yi,Ω0=ø,k=1;
(3)jk=arg max|〈rk-1,dj〉|,j=1,2,…,q,Ωk=Ωk-1∪{jk};
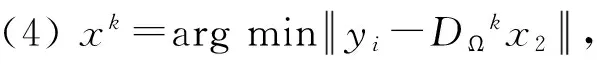
(5)rk=yi-DΩkxk;
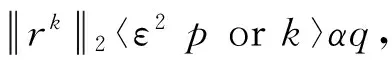
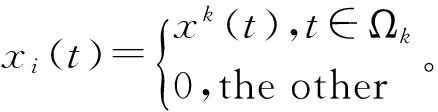

图1稀疏编码的算法流程
Fig.1 Process of sparse coding algorithm
2 煤与矸石图像识别
2.1 实验样本及实验环境
选取来自山西大同煤矿的大小形状各异的煤与矸石样本图像800幅,其中煤与矸石两类各400幅,每幅图像的像素大小均为100×100,灰度级为256,格式为jpg。图像经过预处理后,随机从每类抽取340幅图像放入训练集,剩下的60幅图像作为测试集。由于煤与矸石的开采处在地下,采集到的图像容易受到周围环境的影响,本研究只考虑了在相同光照强度因素下的煤与矸石图像识别,如图2所示。

图2 同一光照强度下的煤与矸石样本图像Fig.2 Coal and gangue sample images under different illumination conditions
本文的实验数据是在Matlab 7.14.0(R2012a)上测试得到。
2.2 图像的预处理
为了更好地对煤与矸石的图像进行特征提取,将拍摄到的含有大量干扰信息的彩色图像转换为灰度图像,利用PCA算法降维[14-15]。PCA算法是一种常用的数据降维方法,是在尽可能代表原始数据的前提下,通过线性变换将高维空间中的样本数据投影到低维空间,以去掉图像中大量的冗余信息,从而提高K-SVD算法的特征提取效率。首先将放入训练集的每一幅样本图像随机相连形成训练样本矩阵,经PCA算法进行降维处理后,对降维后的样本图像进行归一化处理,使训练样本矩阵中每一个列向量的模都为1。降维处理的投影公式为
B=ETA-M,M=m,m,……,m。
(3)
式中,A为所需要处理的样本矩阵,E为特征空间,m为样本图像的均值向量,将矩阵B进行归一化处理得到的矩阵Y便是所求的煤与矸石的图像信号矩阵。
2.3 煤与矸石图像的特征提取
预处理后,利用K-SVD字典学习算法将归一化后的信号矩阵Y进行学习,经过两步的迭代学习算法求解出字典D与稀疏矩阵X。字典D实质为经过不断的学习与优化找到合适的变换空间,而稀疏矩阵X则是信号矩阵Y在变换空间D下的投影。于是信号矩阵Y的每一列向量对应着稀疏矩阵X的每一列向量,稀疏矩阵X便作为样本图像的特征向量对应着训练集的每一幅样本图像,故求解稀疏矩阵X的过程即为煤与矸石的图像特征提取过程。
2.4 分类识别
支持向量机(SVM)[16]兼顾训练误差与测试误差的最小化,具有良好的适应性和泛化能力,是识别率最好的二分类器,所以本研究选用SVM对煤与矸石的图像进行二分类。
3 影响识别率因素研究
经测试,影响煤与矸石识别率的因素主要有两个:字典D和分类器的选择。将着重研究字典D对识别率的影响,通过调整参数选择最优的字典D来提高煤与矸石的识别率。
在字典D的列数为45,稀疏误差ε=0.045,稀疏度α=0.45情况下,首先进行不同字典初始化,在更新方法下经过连续10次测试得到煤与矸石的识别率(图3)。可看出,第6次的识别率最高,选择这次的识别率作为该参数条件下煤与矸石图像的识别率,同时图中表现出的识别率波动差距较大,表明字典的初始化与更新对识别效率有较大影响。
图4则表示在ε=0.039,α=0.27情况下,不同字典列数对煤与矸石的识别率影响曲线。从图中可以看出,在字典列数大于50以后,煤与矸石的识别率随着字典列数的不断增加逐渐下降,而在小于50时识别率是不断提高的。同时随着字典列数的增加,程序运行时间也会越长,相应地也增大了识别时间,空间代价也越大。
图5给出了字典列数为40,稀疏度为0.33的条件下,不同稀疏误差对煤与矸石识别率的影响曲线。可看出,煤与矸石的识别率在稀疏误差为0.035之前一直呈上升趋势,之后不断下降,表明稀疏误差在0.035时识别效率最高。
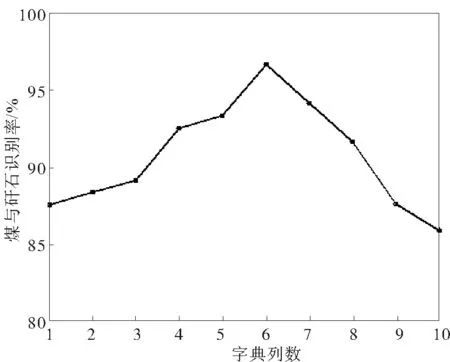
图3 不同字典初始化与更新下的识别率Fig.3 Recognition rate under different dictionary initialization and update
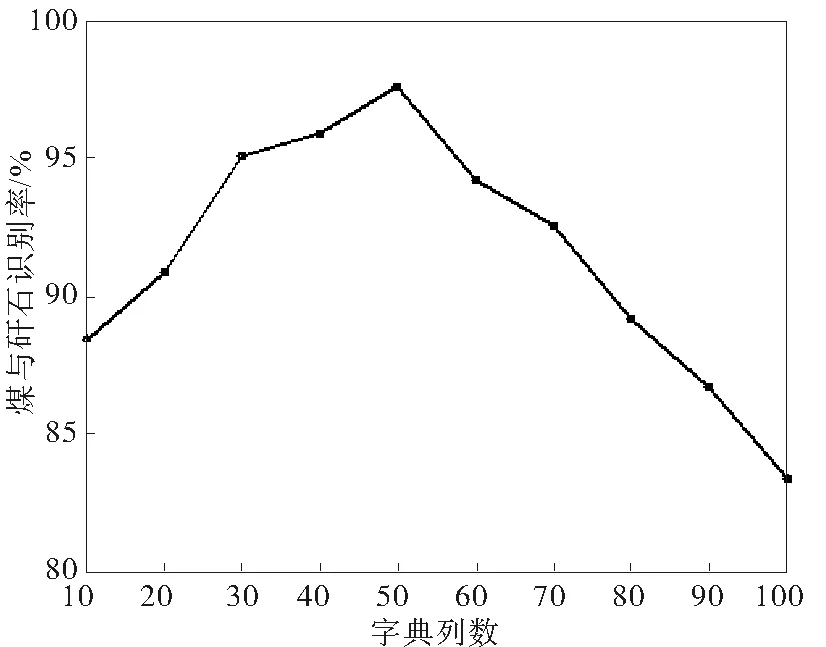
图4 不同字典列数下的识别率Fig.4 Recognition rate under different number of dictionaries
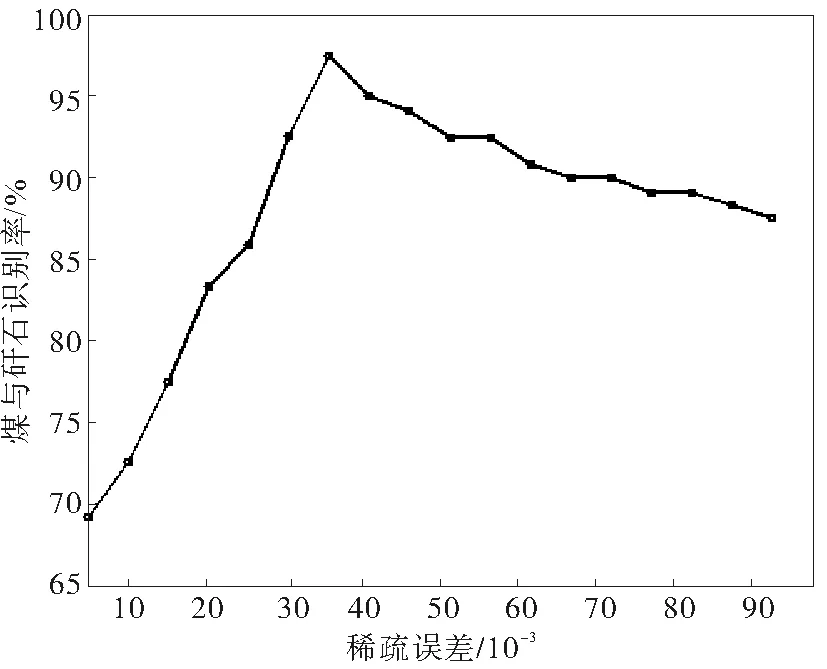
图5 不同稀疏误差下的识别率Fig.5 Recognition rate under different sparse error
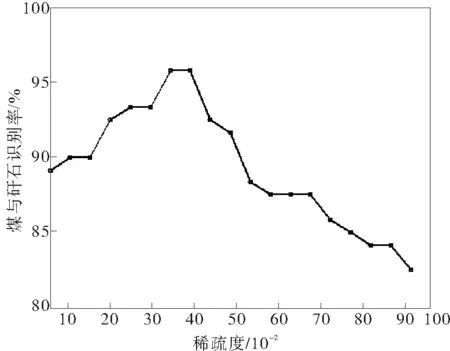
图6 不同稀疏度下的识别率Fig.6 Recognition rate under different sparsity
图6给出了在字典列数为41和稀疏误差为0.035的情况下,稀疏度对煤与矸石识别率的影响曲线。从图中可知在稀疏范围内,识别率在0.2~0.4间保持平稳状态,在0.35左右达到峰值,在0.4以后不断下降。
为了判断字典参数的优劣对煤与矸石识别率的影响,本文通过调节字典参数测得煤与矸石的样本识别率以及识别时间(表1)可以看出,实验测试的样本识别率最高可达97.5%,错误样本仅为3,其中识别时间为2.9 s,字典的初始化与更新、字典列、稀疏误差和稀疏度对识别率都有较大的影响。表2给出使用字典学习和不使用字典学习对煤与矸石识别率的影响情况对比,可知使用字典学习将煤与矸石的识别率从81.6%提高到97.5%,有效地提取出煤与矸石的图像特征,达到更佳的分类识别效果。
为了验证本论文所提方法的效果,在相同样本情况下与已有几种方法的最高识别率进行了对比测试,基于灰度值的特征提取方式、基于小波变换的特征提取方式和基于灰度共生矩阵的特征提取方式的最高识别率分别为92.5%、94.1%和95.8%,而本文识别方法的最高识别率为97.5%。此外,煤矿中采煤机平均切割线速度一般约为7 cm/s,2.6 s的识别反应时间满足实际煤与矸石的自动分选要求。

表1 不同字典参数影响下的识别率Tab.1 Recognition rate under different dictionary parameters
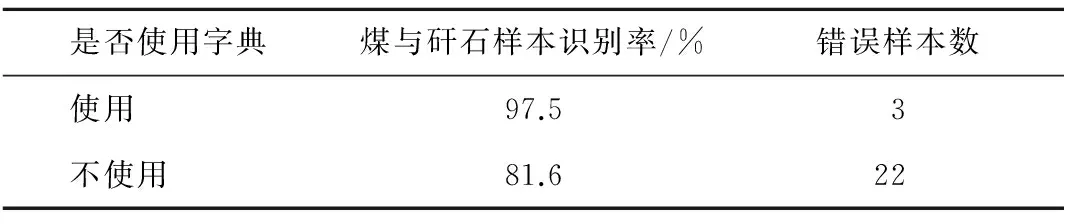
表2 是否使用字典学习对识别率的影响Tab.2 The effect of dictionary learning on recognition rate
4 结 论
研究了基于字典学习的煤与矸石图像特征识别方法,得到结论如下:
1) 基于K-SVD字典学习算法可以有效地表达煤与矸石的图像特征,具有较好的稀疏性,可适用于规模较大的图像信息采集;
2) 字典学习算法中的字典初始化与更新、字典的列数、稀疏误差和稀疏度均会影响煤与矸石的识别率,调节好字典中的最优参数可有效提高煤与矸石的识别率;
3) 与其他煤与矸石的图像特征提取方法相比,基于字典学习的纹理特征提取方法有着特征维数较少,计算量小的优势,时间和空间代价较小,为煤与矸石的自动识别分选提供了一种新的思路和方式,为后续的分类识别打下良好基础。
由于条件有限,本文只考虑了同一光照强度对识别效果的影响,下一步将着重研究在实际开采过程中,受到更多噪声影响下的煤与矸石识别率提高的问题。
参考文献:
[1]石焕,程宏志,刘万超.我国选煤技术现状及发展趋势[J].煤炭科学技术, 2016,44(6):169-174.
SHI Huan,CHENG Hongzhi,LIU Wanchao.Present status and development trend of China’s coal preparation technology[J].Coal Science and Technology,2016,44(6):169-174.
[2]田原.浅谈机器视觉技术在煤矿中的应用前景[J].工矿自动化,2010,36(5):30-33.
TIAN Yuan.Brief discussion of application prospect of technology of machine vision in coal mine[J].Industry and Mine Automation,2010,36(5):30-33.
[3]于国防,邹士威,秦聪.图像灰度信息在煤矸石自动分选中的应用研究[J].工矿自动化,2012,38(2):36-39.
YU Guofang,ZOU Shiwei,QIN Cong.Application research of image gray information in automatic separation of coal and tangue[J].Industry and Mine Automation,2012,38(2):36-39.
[4]王祥瑞.煤矿矸石自动分选中图像处理与识别技术的应用[J].煤炭技术,2012,31(8):120-121.
WANG Xiangrui.Application of image processing and recognition technology in waste automatic separation of coal mine[J].Coal Technology,2012,31(8):120-121.
[5]何敏,王培培,蒋慧慧.基于SVM和纹理的煤和煤矸石自动识别[J].计算机工程与设计,2012,33(3):1117-1121.
HE Min,WANG Peipei,JIANG Huihui.Recognition of coal and stone based on SVM and texture[J].Computer Engineering and Design,2012,33(3):1117-1121.
[6]廖阳阳.基于BP网络和图像处理的煤矸石的动态识别[J].工业控制计算机,2015(7):119-122.
LIAO Yangyang.Recognition of coal and stone based on BP[J].Industrial Control Computer,2015(7):119-122.
[7]WEI C,MIGUEL R D R.Dictionary learning with optimized projection design for compressive sensing applications[J].IEEE Signal Processing Letters,2013,20(10):992-995.
[8]SHI J,WANG X H.Image super-resolution reconstruction based on improved K-SVD dictionary-learning[J]. Acta Electronica Sinica,2013,41(5):997-1000.
[9]练秋生,石保顺,陈书贞.字典学习模型、算法及其应用研究进展[J].自动化学报,2015,41(2):240-260.
LIAN Qiusheng,SHI Baoshun,CHEN Shunzhen.Research advances on dictionary learning models,algorithms and applications[J]. Acta Auto matica Sinica,2015,41(2):240-260.
[10]JIANG Z L,LIN Z,DAVIS L S.Label consistent K-SVD:Learning a discriminative dictionary for recognition[J].IEEE Transaction on Pattern Analysis and Machine Intelligence,2013,35(11):2651-2664.
[11]刘雅莉,马杰,王晓云,等.一种改进的K-SVD字典学习算法[J].河北工业大学学报,2016,45(2):1-8.
LIU Yali,MA Jie,WANG Xiaoyun,et al.An improved K-SVD dictionary learning algorithm[J].Journal of Hebei University of Technology,2016,45(2):1-8.
[12]LI J,WANG Q,SHEN Y.Near optimal condition of OMP algorithm in recovering sparse signal from noisy measurement[J].Journal of Systems Engineering and Electronics,2014,25(4):547-553.
[13]李少东,裴文炯,杨军,等.贝叶斯模型下的OMP重构算法及应用[J].系统工程与电子技术,2015,37(2):246-252.
LI Shaodong,PEI Wenjiong,YANG Jun,et al.OMP reconstruction algorithm via Bayesian model and its application[J].Systems Engineering and Electronics,2015,37(2):246-252.
[14]FOUZI H,MOHAMED N N,HAZEM N N. Enhanced monitoring using PCA-based GLR fault detection and multiscale filtering[C]//IEEE Symposium on Computational Intelligence in Control and Automation.2013:1-8.
[15]胡嘉良,高玉超,余继峰, 等.基于PCA-BP神经网络的非常规储层岩性识别研究[J].山东科技大学学报(自然科学版),2016,35(5):9-16.
HU Jialiang,GAO Yuchao,YU Jifeng,et al.Lithology identification of unconventional reservoirs based on PCA-BP neural network[J].Journal of Shandong University of Science and Technology(Natural Science),2016,35(5):9-16.
[16]丁世飞,齐丙娟,谭红艳.支持向量机理论与算法研究综述[J].电子科技大学学报,2011,40(1):2-10.
DING Shifei,QI Bingjuan,TAN Hongyan.An overview on theory and algorithm of support vector machines[J].Journal of University of Electronic Science and Technology of China,2011,40(1):2-10.
