中国31个省市经济发展水平的动态分析
2018-05-09刘干,陆叶
刘 干,陆 叶
(杭州电子科技大学 经济学院,浙江 杭州 310018)
随着我国经济的快速发展,区域经济发展不平衡问题也变得日益突出,作为解决区域经济发展不平衡问题的关键,首先需要解决的是对我国省域按经济状况做出分类评价。就目前对于该问题的研究成果来看,大多数学者都是通过聚类分析法来实现。然而区域经济发展水平是一个动态的变化过程,不同区域由于各方面条件的差异,其经济发展速度往往会存在较大差异,因而,对于某一经济总体内部不同区域的评价也应是一个动态的过程。从这个层面上来说,对于总体的一次聚类评价显然不能很好地反映内部动态变化过程;而通过不同截面分别进行聚类,再比较聚类结果的差异,一方面,聚类结果受随机波动和事物自身可能存在的周期性波动影响较大;另一方面,不同截面聚类结果之间的可比性无法得到保障。因此,本文从面板数据聚类的角度引入了MA聚类法对该问题进行研究,聚类结果表明该方法具有一定的可靠性。
一、评价指标体系及数据说明
经济发展水平反映的是一个地区在经济总量及增速方面所达到的状态。但从广义上来说,评价一个地区经济发展水平的高低不应仅仅局限于其经济表现,还应考虑其在社会生活及生态环境方面所达到的标准。因此,本文从经济、社会及环境三个层面筛选了14个指标构建了如下经济发展水平的评价指标体系(见表1)。
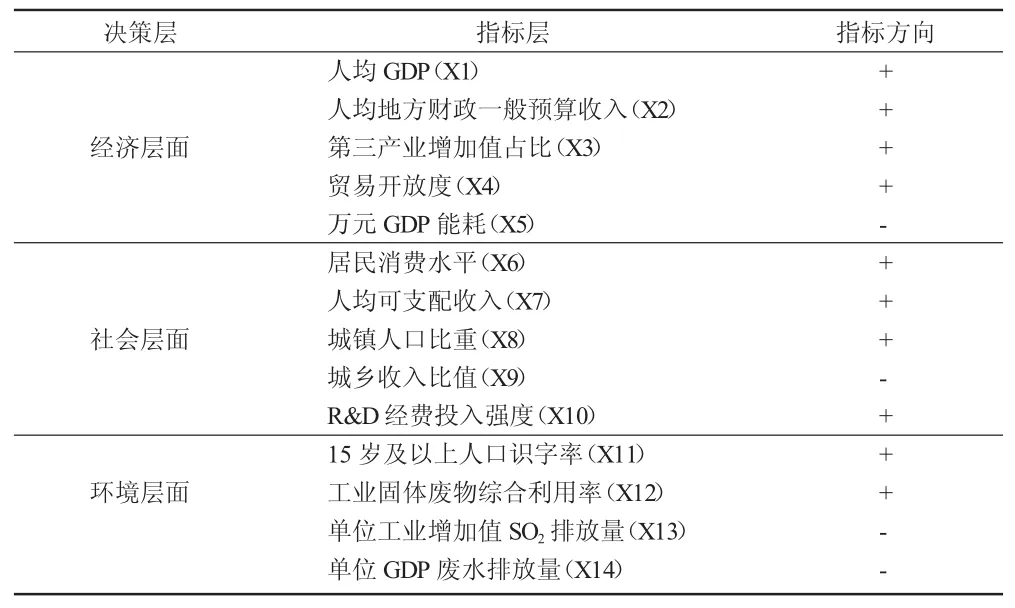
表1 我国经济发展水平评价指标体系
本文的数据选自我国31个省市2005—2015年的经济指标数据。为了剔除人口和价格因素的影响,本文的评价指标均采用相对数来表示,指标中涉及的价格因素均以固定基期(2005)的实际值带入。特别地,由于贸易开放程度指标计算中涉及的货物进出口总额数据采用美元计价,对此,本文采用各年的平均汇率加权处理。对于数据缺失问题,本文采用两种处理方法:一是X11指标2010年的数据缺失,可直接采用线性插值法处理;二是西藏的X5指标数据完全缺失,对此,本文考虑先对其他30个省市进行完全指标数据聚类分析,再根据未缺失的13个指标运用最近邻判别法将西藏归入据其最近的一类。本文所有的指标数据或计算数据均来源于《中国统计年鉴》、《中国能源统计年鉴》、《中国科技统计年鉴》、《国民经济和社会发展统计公报》及各地区年鉴。
二、MA聚类法
从面板数据聚类的角度来考察我国各省市经济发展水平的动态变化过程,首先需要解决的是,在满足可比性的条件下,给出不同时期我国区域经济发展水平的类别划分。为此,本文引入了基于K-means聚类的类别变动分析法,由于其实现过程运用了移动平均法的思想,因此,不妨将其叫做移动平均聚类法,简称MA聚类法。下面给出该方法的操作步骤。
(Ⅰ)给定聚类数K和聚类周期长度TL;
(Ⅱ)从数据的起点开始,选取长度为TL的聚类区间,进行聚类数为K的K-means聚类分析,得到对总体的 K 类划分结果{C1,C2,…,CK};
(Ⅲ)依次将聚类区间向后平移一期,重复(Ⅱ)的过程,直到数据的终点,则可得到T-TL+1组聚类结果;
(Ⅳ)对所有聚类结果进行类的优劣排序,不妨将排序后的第i次的聚类结果仍然记作{C1,C2,…,CK};
(Ⅴ)比较相邻聚类结果之间的差异,并做出分析。
关于MA聚类法的具体实现过程仍需做如下几点说明:
(1)面板数据的K-means聚类法。与截面K-means聚类不同的是,面板数据K-means聚类的距离函数度量的是两个矩阵之间的距离,样本点i与聚类中心j之间的欧式距离为:
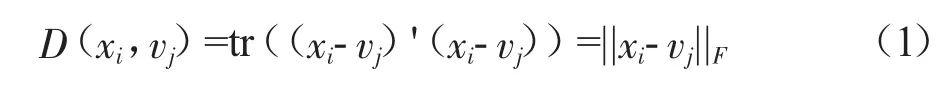
其中,xi表示第i个样本点矩阵,其维度为Q×T(Q表示聚类指标个数,本文表示主因子个数;T表示聚类周期的长度),vj表示第j个聚类中心矩阵,其维度与xi相同。||A||F表示矩阵A的Frobenius范数,即矩阵A内部所有元素平方和的平方根。
(2)聚类数K的确定。在K-means聚类之前,一般都需要指定聚类数,而聚类数K实际上就是最佳聚类数,关于最佳聚类数的确定方法有很多,但据研究[1]表明:在采用K-means聚类法的条件下,CH指标法的性能最优。另外,考虑到聚类结果的统一性要求,即所有T-TL+1组聚类结果的聚类数应相同。因此,本文通过对整个数据区间运用CH指标法确定最佳聚类数K*,并以其作为聚类数K的值,其计算公式如下:

(3)聚类周期长度TL的确定。当聚类总体在目标变量上的变化呈现周期性波动时,聚类周期TL应选择该周期长度的整数倍;当聚类总体在目标变量上的变化并无明显的周期性波动时,TL的长度可选择3,以消除随机波动。
(4)类的优劣判别法。本质上,类的优劣判别可以归结为对聚类结果的综合评价问题,关于多指标综合评价问题的方法可参考[2],本文由于在聚类之前首先运用因子分析对数据进行了降维处理,因此,可直接以类平均因子综合得分作为各类优劣程度的测度值,从而其数值大小即代表了各自类别的优劣。
(5)类预测法。当分析问题除了需要考察总体内部各区域在历史一段时间内目标变量的动态变化过程,还需对未来变动趋势做出预测时,可以在上述方法之前,通过ARIMA模型对各指标数据进行相同期数的时间序列预测,并将预测后的指标数据叠加到原有数据基础上进行分析。从而,类预测的期数与指标数据外推预测的期数相同。
三、实证分析
(一)指标预测
由于统计年鉴中公布的数据截止到2015年,为了将最新的数据纳入分析过程,本文运用ARIMA模型对各省市的14个指标分别进行2期的预测,截取了部分预测结果如下:
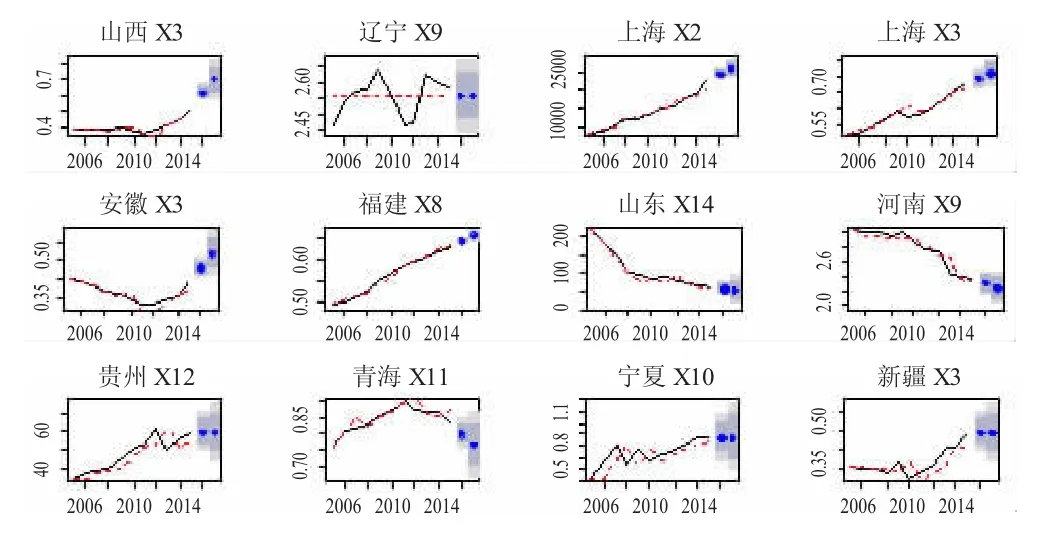
图1 指标预测结果
从图1中可以看出,除部分指标波动较大,指标做短期时间序列预测基本能捕捉到序列的趋势,因此,后文基于指标预测结果进行的类预测具有良好的可信度。
(二)聚类数K和聚类周期长度TL的确定
由于样本量的限制,即本文只对我国31个省市的经济发展水平进行聚类,所以,最佳聚类数的取值不宜太大。为此,根据式(2)计算出CH指标在2~8区间内的值如表2所示。

表2 不同聚类数下的CH统计值
从表2可得,随着聚类数K的增加,CH指标值先递增,在K=5处取得最大值,之后又逐渐递减。因此,从总体来看,将我国省域划分为5类最为合适。
由于社会经济指标的变化具有一定的周期性,根据施发启[3]的研究表明:我国的经济周期具有一定的特殊性,即经济周期长短不一,但自第9个经济周期后已基本接近尤格拉循环,因此,本文取TL=9进行后续分析。
(三)MA聚类分析及类的优劣判别
考虑到西藏的万元GDP能耗数据完全缺失,因此,聚类过程只针对其余30个省市进行。为了对指标数据降维,本文首先进行因子分析,由平行分析法[4]保留了3个主因子;然后,基于30个省市的主因子数据进行K=5,TL=9的MA聚类分析,并根据类平均因子综合得分法对聚类结果进行排序,所得结果如表3和图2所示。

表3 MA聚类分析结果
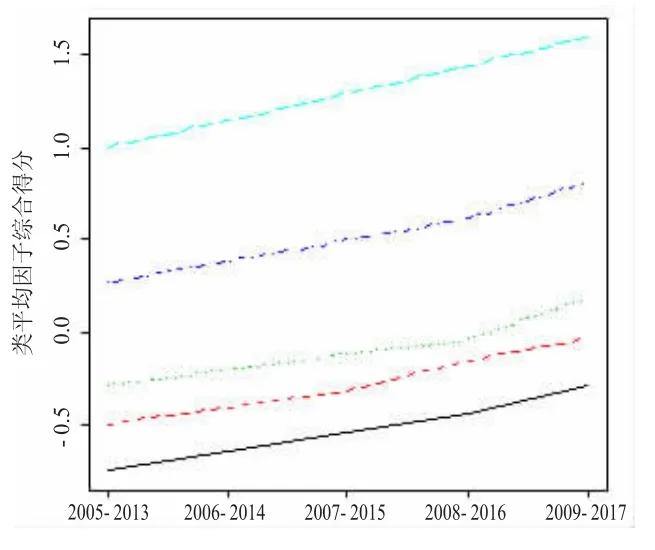
图2 类平均因子综合得分
根据表3,从整体来看,我国30个省市中有超过75%的区域经济发展水平落入了中等及以下的类别,区域经济发展水平的分布呈现出明显的右偏性,区域经济发展不平衡状况仍十分严重,这点从图2的类平均因子综合得分折线图中也可明显看出。从局部来看,区间2005—2013年、2006—2014年和2007—2015年的聚类结果没有发生变动,说明我国各地区经济发展水平在2005—2015年间发展相对平稳,各类中区域经济发展水平的平均增速没有太大差异。
根据指标预测数据,区间2008—2016年的聚类结果相对于上期仅在经济水平较低的两类间发生了变动,即甘肃和青海的经济增速相对于C4类其他地区出现了下滑趋势,因而被划分到了经济水平更低的类中。区间2009—2017年的区域经济发展水平聚类结果波动较大,变动主要表现在C3和C4类元素的交换,其中只有内蒙古、重庆和陕西的变动方向为正,其余包括辽宁、河北、吉林、黑龙江、安徽、江西、河南、湖南、四川、山西、云南和新疆的变动方向均为负向。出现如此大面积省市经济波动的原因主要有两方面:一方面,2008—2016年聚类区间内C3和C4类的经济发展水平差距并不明显(这点从图2可看出),而C4中经济水平较高的内蒙古、重庆和陕西的经济增速比C3中的经济水平较低的河北、吉林和黑龙江等的经济增速高,因而实现了反超;另一方面,在原有类别中,经济水平相对较低的辽宁、山西、云南等地区经济增速低于其余省份,因而,导致与经济水平较低类的距离更近。
从图2中曲线的走势来看,我国区域经济总体均呈现稳步上升趋势,且在2005—2017年间,区域间的差距没有被明显拉大的现象,区域间经济发展不平衡问题也没有得到明显改善。从图2中折线的疏密情况来看,我国区域间经济发展水平“贫富悬殊”,区域经济发展不平衡现象主要表现在经济发达地区、中高经济发展水平地区和中等及以下经济发展水平地区之间,而经济发展水平较低的3类间的差距并不明显,这也导致聚类变动主要发生在这3类间。
(四)经济发展水平的空间分布
为了研究我国31个省市经济发展水平的空间分布情况,首先需要对西藏的分类情况做出判别,为了简化分析过程,本文基于除缺失指标(万元GDP能耗)外的13个指标数据,通过以熵权法进行指标加权的最近邻判别法将西藏划分到距其最近的类别。计算结果如表4所示。

表4 西藏到各类中心的距离
由表4可知,西藏与2005—2013年、2006—2014年及 2007—2015年的 C4类最近,与 2008—2016年和2009—2017年的C5类最近,因此,根据最近判别法的原理,分别将西藏归入相应的类别。
将西藏的分类结果添加到表3,并通过ArcGIS 10.5绘出聚类分布图(见图3)(由于前3期聚类结果与第4期的差别仅表现在C4和C5类之间,为了呈现的美观,这里只给出第4、5期的聚类结果)。
从图3的聚类结果来看,我国经济发展水平较高的地区均位于东部地区的沿海经济带,西部地区经济发展水平相对落后,出现经济发展水平波动的地区主要分布在中西部交界地区。从聚类变动情况来看,重庆、陕西和内蒙古的经济发展较快,开始步入中等经济水平,而辽宁、山西等地的经济增速较为缓慢,甚至出现衰落迹象。结合指标数据来看,近年来,重庆的对外开放程度不断加深,内蒙古的人均GDP增幅明显,陕西在科技及教育方面成果显著,而辽宁在三废处理能力上相对薄弱;山西由于经济类型较为粗放,且主要以煤炭资源带动经济发展,随着近年煤炭市场的低迷,经济出现了严重下滑。从图(a)到(b)的大幅变动也主要是由于这些地区经济发展速度的变化造成了聚类结果的重组。

图3 聚类结果分布图
四、结论与建议
本文从经济、社会和环境三个角度构建了一套区域经济发展水平评价指标体系,相比于只从经济和社会角度去刻画经济发展状况更准确、更全面。另外,采用MA聚类法对区域经济发展水平进行动态聚类和聚类预测,克服了一次聚类无法给出区域经济动态发展特征和各年度分别聚类带来的可比性不足的问题。
运用MA聚类法对我国 31个省市 2005—2015年的经济发展水平数据进行动态聚类,结果显示,我国区域经济发展水平的分布呈现出明显的右偏性,区域间“贫富悬殊”差异显著;区域经济发展不平衡问题主要表现在经济发展水平高、中高和中等及以下地区之间差异显著;虽然区域经济发展水平总体呈上升趋势,但区域间经济发展不平衡的状况并没有得到明显的改善。从区域经济发展水平变动情况来看,重庆、陕西和内蒙古的经济发展较快,开始步入中等经济水平,而辽宁、山西等地的经济增速较为缓慢,甚至出现衰落迹象。结合指标数据分析,重庆、陕西和内蒙古经济发展水平的提升分别得益于在对外开放、科技教育和人均GDP等方面发展迅速;而山西受近年煤炭市场低迷的影响,经济下滑严重;辽宁在环保方面的表现欠佳也对其整体经济水平造成了一定的影响。整体来看,解决区域经济发展不平衡问题首先需各地区发挥自身优势,着力解决阻碍地区经济发展的问题,并寻求适合地区特点的新经济增长点;其次,各地区应加强同周边区域的交流互通,实现经济的互补。
【参考文献】
[1]Arbelaitz O,Gurrutxaga I,Muguerza J,et al.An extensive comparative study of cluster validity indices[J].Pattern Recognition,2013,46(1):243-256.
[2]虞晓芬,傅玳,2014.多指标综合评价方法综述[J].统计与决策(11):119-121.
[3]施发启,2000.中国经济周期实证分析[J].统计研究(7):59-62.
[4]孔明,卞冉.平行分析在探索性因素分析中的应用[J].心理科学,2007,30(4):924-925.
