基于上下文感知和个性化度量嵌入的下一个兴趣点推荐*
2018-05-08鲜学丰陈晓杰赵朋朋杨元峰VictorSheng
鲜学丰,陈晓杰,赵朋朋,杨元峰 ,Victor S.Sheng
(1.江苏省现代企业信息化应用支撑软件工程技术研发中心,江苏 苏州 215104; 2.苏州大学智能信息处理及应用研究所,江苏 苏州 215006; 3.阿肯色中央大学计算机科学系,康威 72035)
1 引言
随着全球定位系统和无线通信网络等基础设施的飞速发展以及手持、车载无线通信定位设备的广泛应用,特别是众多移动社交网络的位置签到、位置共享及位置标识等功能的应用普及,位置服务与社交网络逐渐融合,形成了基于位置的社交网络LBSN(Location-Based Social Networks)。例如,Foursquare、Gowalla和Yelp 等社交应用通过移动用户的地理位置推行的签到功能,把线上虚拟社会与线下真实世界联结在一起,实现了用户位置定位的同时,还实现了位置信息在虚拟网络世界的共享与传播,从而衍生出多种多样的位置服务。
目前个性化推荐技术得到工业界和学术界的广泛关注,在多个领域得到广泛应用,比如电子商务网站为用户推荐商品,视频网站为用户推荐电影。日益成熟的推荐技术较好地解决了互联网信息过载的问题。在基于位置的社交网络中,兴趣点推荐作为热门的研究课题,旨在为用户推荐兴趣点,方便用户出行生活,并且提升平台的用户体验[1 - 6]。
在兴趣点推荐的研究工作中,用户个人偏好对推荐的结果起了主导作用。在个性化推荐领域,用户个人偏好成为了必不可少的因素[7]。一些研究工作表明,用户的时序性签到行为可以反映出人类活动的时序性模式[8]。在研究工作中得出的个性化的马尔科夫链分解FPMC(Factorizing Personalized Markov Chains)方法[9],主要使用矩阵分解的方法。然而,这并没有挖掘出兴趣点之间的潜在联系。在下一个兴趣点推荐的研究中,如何在一阶马尔科夫链模型中获取用户签到记录之间的转移概率成为全新的挑战。由于数据的稀疏性,马尔科夫链模型难以评估未被观察到的数据间的转移概率。为了有效解决这个问题,进一步的研究提出了个性化排名度量嵌入法PRME(Personalized Ranking Metric Embedding)[10],通过将每一个兴趣点映射到低维空间计算兴趣点之间的转移概率。PRME模型结合考虑了用户偏好和时序性转移两个影响因素。和FPMC模型相比,PRME模型更好地解决了数据稀疏性带来的问题。然而,PRME模型没有深度挖掘签到行为的上下文情境信息来进行推荐。
然而,在大多数兴趣点推荐的研究工作中,用户访问的周期性习惯和伴随着用户偏好的上下文情境信息还没有被深度挖掘出来。上下文情境信息包括每天的时间段、每周的星期、当前签到兴趣点的分类等。例如,在工作日,人们通常习惯于在上班途中光顾一家咖啡店,我们可以把这个看作是一种周期性的行为习惯。据分析,下一个兴趣点和当前兴趣点息息相关。例如,通常在健身结束后,人们倾向于选择去餐厅补充高蛋白食物,而不是去酒吧。本文统计并分析了Foursquare中来自日本东京的用户签到记录,图1描述了4种热门签到地点类别在一天各个时间点的签到几率,图2描述了4种热门签到地点类别在一周各天的签到几率。可以发现,按类别划分用户的活动具有周期性。图1中属于Nightlife Spot类别的签到通常发生在晚上十点到凌晨四点之间,而在白天则很少。图2中属于School类别的签到通常发生在工作日,周末的几率则很小。根据以上分析可以得出,用户的周期性行为模式对下一个兴趣点推荐有很大影响。

Figure 1 Periodic analysis of one day sign in behavior图1 一天签到行为周期性分析

Figure 2 Periodic analysis of one week sign in behavior图2 一周签到行为周期性分析
基于以上考虑,针对用户签到的数据稀疏性问题,本文将用户周期性行为模式归结为上下文情境信息,提出了一种个性化度量嵌入的推荐算法,同时将用户签到的上下文情境信息考虑进来,从而丰富有效数据,缓解数据稀疏性问题,提高推荐的准确率,并且进一步优化算法,降低时间复杂度。本文考虑的上下文情境信息包括每天的时间段、每周的星期、当前签到兴趣点的分类等。通过将每一个兴趣点映射到低维隐式空间,进一步使用度量嵌入算法来计算兴趣点之间的转移概率。然后,使用度量排序嵌入的算法将隐式空间的候选推荐兴趣点进行排序。本文提出了基于上下文感知的个性化度量嵌入模型CPME(Context-aware Personalized Metric Embedding),结合考虑了时序性影响、用户个人偏好和上下文情境信息。最后,基于用户更偏向于访问离自己更近的兴趣点的事实,将地理影响因素考虑在内,进而提出了CPME-G(Context-aware Personalized Metric Embedding-Geo)模型。
本文第2节介绍兴趣点研究的相关工作;在第3节中,将对下一个兴趣点推荐进行问题定义;第4节详细解释所提出的模型;第5节深入剖析所提出模型的参数训练;在第6节中,本文将展示实验结果;最后,将在第7节中总结本文的工作。
2 相关工作
兴趣点推荐所采用的数据集可以分为基于GPS的轨迹数据和LSBN中的签到数据。利用基于GPS轨迹数据进行推荐,其首要工作就是从轨迹数据中挖掘出兴趣点并进行推荐研究[11]。LSBN中的用户签到数据不仅包含兴趣点语义描述信息,还包含兴趣点地理位置信息,同时还具有丰富的用户社交网络信息,因此基于位置的兴趣点推荐研究受到研究者的广泛关注。兴趣点推荐至今已取得不少成果,可以分为以下四类:
(1)基于地理位置影响因素的推荐,文献[12]发掘了签到记录中的“地理聚类现象”,用来提高兴趣点推荐的准确率。(2)基于时序影响因素的推荐,文献[13]充分利用了时序影响因素来提高兴趣点推荐的性能。(3)基于社交关系因素的推荐,文献[14]提出了一种新的推荐框架SoDimRec,它结合了社交关系的非均匀性和弱关系依赖来进行推荐。(4)基于内容的推荐,文献[15]提出了一种考虑内容的贝叶斯协同过滤框架,同时给出了一种可扩展的优化算法来学习潜在参数和超参数,特别是针对隐式反馈的挖掘。
随着兴趣点推荐的热度上升,基于序列的下一个兴趣点推荐已成为兴趣点推荐的热点研究问题。文献[16]提出了一个统一的基于张量的隐式模型,为了更好地进行下一个兴趣点的个性化推荐,它将潜在可被观察的连续签到行为融合到一种用户的隐式倾向中。词嵌入和成分嵌入模型在自然语言处理领域已经取得了很好的效果。有研究者将度量嵌入的算法应用在下一个兴趣点推荐领域。为了解决数据稀疏性问题,文献[10]使用了度量嵌入算法并提出了个性化排名度量嵌入模型。文献[17]提出了基于图的度量嵌入模型来表示低维隐式空间的兴趣点,并且他们提出了一种事件衰减的方法来挖掘表示动态的用户偏好。为了提取关系特征,文献[18]提出了多特征成分嵌入模型。在上述相关工作的基础上,本文进一步挖掘了用户行为的周期性和伴随着用户偏好的上下文情境信息,并采用度量嵌入的方法来进行下一个兴趣点推荐。
3 问题定义
下一个兴趣点推荐的目的是根据用户的当前地点推荐下一个兴趣点。当两个连续的签到点发生在一个很短的时间段内时,他们之间就存在马尔科夫链的性质[7]。马尔科夫链描述了从一个状态转换到另一个状态的随机过程。这个过程具有无记忆性的特点,也就是说,下一个状态的概率分布只能由当前状态决定,在时间序列中它前面的时间均与之无关。可以得出当需要考虑一个短时间段内的兴趣点转移关系时,意味着下一个兴趣点受当前兴趣点的影响。本文研究的下一个兴趣点推荐是在过滤掉用户访问过的兴趣点的前提下给用户推荐新的兴趣点,问题定义如下:
给定一个LBSN的用户集合U={u1,u2,…,ui,…,uX},以及地理位置点的集合L={l1,l2,…,lj,…,lY},即兴趣点集合。其中X和Y分别是用户的个数和兴趣点的个数。每个地理位置点可以用〈longitude,latitude〉来描述具体定位。给定一个用户的当前兴趣点lc以及历史访问记录Lu,下一个兴趣点推荐问题就是基于用户的当前兴趣点lc给用户u推荐一系列将要访问的下一个兴趣点集合Recu,lc,Recu,lc={l∈LLu}。文中涉及符号的定义如表1所示。

Table 1 Symbol definition表1 符号定义
4 基于上下文感知的个性化度量嵌入推荐方法
4.1 度量排序嵌入
本文采用兴趣点之间的转移概率来描述当前兴趣点对下一个兴趣点的影响,由于数据稀疏性对计算兴趣点之间的转移概率带来了巨大的困扰,基于度量嵌入的方法很好地缓解了该问题。该方法将每一个兴趣点映射到一个低维空间,通过计算兴趣点之间的欧氏距离来描述转移概率,本文采用的欧氏距离是业界最常用的度量方式。两个兴趣点之间的距离越近,说明它们之间的转移概率越高。当所有的兴趣点都嵌入到低维空间中后,可以挖掘出未被观察到的兴趣点之间的转移概率。在度量嵌入模型中,每一个兴趣点在一个K维空间都存在一个位置E(l)。一对候选兴趣点〈li,lj〉之间的转移概率的定义如下:
(1)

度量嵌入的方法可以很好地挖掘兴趣点间的关系,并且将这些关系通过距离展现出来。因此,基于度量嵌入的方法在模拟时序关系的转移上有很大的优势。所谓兴趣点间的联系,即:假设有三个连续的签到点li,lj和lk。依据马尔科夫链描述的过程,可以得到两组可观察到的序列li→lj和lj→lk。不可避免地,li对lk也会产生影响,即:li→lk是一个隐式的转移关系。如果这个转移关系更紧密,那么在低维空间上E(li)和E(lk)之间的距离会更加接近它们和E(lj)之间的距离。
对于单独一个用户,他所有的个人签到记录所涉及的签到点总是有限的,即他不可能对所有的兴趣点进行过访问,换句话说,从任意一个用户获得的可观察到的数据是稀疏的。需要更充分地利用这些已被观察到的数据来进行参数学习。相比于未观察到的兴趣点,已观察到的下一个兴趣点和当前兴趣点更接近。例如,存在一个已被观察到的转移关系lc→li和一个未被观察到的转移关系lc→lj,从当前兴趣点lc转移到兴趣点li比转移到兴趣点lj概率更大。我们可以得出以下排序:

(2)
本文将两个兴趣点之间的欧氏距离表示为‖E(li)-E(lj)‖2,并缩写为Dli,lj。对兴趣点的排序方法如下:
⟹
e-‖E(li)-E(lc)‖2>e-‖E(lj)-E(lc)‖2⟹
‖E(li)-E(lc)‖2<‖E(lj)-E(lc)‖2⟹
Dlc,lj-Dlc,li>0
(3)
4.2 上下文感知度量排序嵌入
4.2.1 用户偏好空间
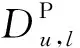
4.2.2 时序关系空间

4.2.3 上下文感知空间
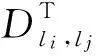


Table 2 Spatial time segment classificationdescription to Time-of-Day space表2 Time-of-Day空间时间段分类描述

Figure 3 Points of interest map to Time-of-Day space图3 兴趣点映射到Time-of-Day空间

Figure 4 Points of interest map to Day-of-Week space图4 兴趣点映射到Day-of-Week空间


Figure 5 Points of interest map to Category space图5 兴趣点映射到Category空间
根据以上分析,本文将用户个人偏好、时序转移关系和上下文感知信息综合考虑来衡量一个候选兴趣点的转移概率。给定一个用户u以及他的当前位置lc,我们使用线性插值函数来衡量这三个度量。最后,综合距离的定义由以下公式给出:

(4)
其中a,b,c,d,e分别代表不同隐式空间上对应的欧氏距离的权重,且满足a,b,c,d,e∈[0,1]以及a+b+c+d+e=1。
通过把每一个兴趣点映射到创建的三个空间:Time-of-Day空间、Day-of-Week空间和Category空间,我们将每一个兴趣点按组分配到对应的具体空间。根据第3节的论述,如果两个连续兴趣点之间的时间差小于τ,时序性所带来的影响就应当被考虑。如果两个连续签到点的时间差很大,就认为他们在时序性上相互之间不受影响,因此就仅仅考虑用户偏好带来的影响。根据以上分析,本文给出以下函数:
对于l,lc∈LT,W,且a,b,c,d,e∈[0,1],a+b+c+d+e=1,
(5)
4.2.4 结合地理影响因素
据分析,当给定当前的位置时,用户偏向于访问更近的兴趣点而不是离他们更远的兴趣点。因此,地理位置的远近对用户的访问行为有很大的影响。根据这些分析,本文考虑了地理影响因素,提出了CPME-G模型,该模型是在CPME的基础上加入了地理影响因素。本文引入一个变量来描述地理影响因素的权重并通过地理位置的经纬度来描述地理距离。对于给定一对兴趣点之间的地理距离dlc,l和权重函数g(lc,l)={(1+dlc,l)0.25},它们之间的混合度量距离就可以表示为Du,lc,l·wlc,l。当兴趣点之间的距离很小时,它们之间的混合度量距离也会很小,这意味着这个兴趣点很有可能被推荐。最后,结合地理影响因素的度量可以被定义为:
对于l,lc∈LT,W,且a,b,c,d,e∈[0,1],a+b+c+d+e=1,
(6)
5 参数学习
本文使用一种近似于贝叶斯个性化排名的方法BPR(Baysian Personalized Ranking)[19],假设用户和他们的签到历史记录是独立的,我们可以用极大后验假设来评估本文提出的基于上下文感知个性化度量嵌入模型:
(7)
其中Θ={ES(L),EP(L),EP(U),EC(L)}是参数的集合。
类似于文献[12],本文使用逻辑回归函数σ(z)=1/(1+e-z)进行归一化操作,得到的排名概率可表示为:
P(>u,lc|Θ)=
P((Du,lc,lj-Du,lc,li)>0|Θ)=σ(Du,lc,lj-Du,lc,li)
(8)
假设模型参数服从高斯分布,那么可以得到最后的目标函数,λ是一个正则项的参数:
Du,lc,li))-λ‖Θ‖2
(9)
紧接着BPR方法,本文使用随机梯度下降的方法来更新参数。根据历史签到记录,我们可以获得一组可被观察到的数据〈u,lc,li〉,其中lc是指用户u的当前位置,li是下一个兴趣点。对于每一组观察到的数据,本文通过随机生成一个兴趣点lj,并且它满足不在用户的历史记录中。给定一组训练数据〈u,lc,li,lj〉,那么这个更新的过程可以被描述为:
(10)
其中z=Du,lc,lj-Du,lc,li,γ是学习速率因子。
本文将提出的CPME模型的学习算法总结在算法1 中。该算法的描述如下:首先,初始化模型参数,使其服从高斯分布(Line 1)。然后从训练集中读取并存储〈u,lc,li〉,其中l,lc∈LT,W(Line 3)。对于每一个访问过的元组〈u,lc,li〉,本文从兴趣点集中随机产生一个兴趣点lj,且满足用户u没有访问过这个兴趣点(Line 4)。接着,算法将Δ(lc,li)的时间差和设定的时间阈值τ进行比较。如果Δ(lc,li)<τ,那么就更新这些参数(Line 6~Line 10)。本算法综合考虑了用户个人偏好、时序转移关系和上下文感知。当我们要训练CPME-G模型时,需加上地理影响权重g(lc,l)={(1+dlc,l)0.25},并使用相似的算法进行参数学习。总结发现,本算法的时间复杂度为O(KI|H|),其中,K是空间维数,I是迭代训练的次数,并且H是观察到的数据的集合。
算法1基于上下文感知个性化度量嵌入算法
输入:签到数据集H,学习速率因子γ,权重a,b,c,d和e,时间阈值τ。
输出:模型参数Θ=ES(L),EP(L),EP(U),ET(L),EW(L),EC(L)。
1. 初始化Θ使其服从高斯分布N(0,0.01);
2. repeat
3. for Each Observation 〈u,lc,li〉,l,lc∈LT,Wdo
4. Randomly generate an unobserved POIlj
5. ifΔ(lc,li)<τthen
6. UpdateEP(u),EP(li),EP(lj);
7. UpdateES(lc),ES(li),ES(lj);
8. UpdateET(lc),ET(li),ET(lj);
9. UpdateEW(lc),EW(li),EW(lj);
10. UpdateEC(lc),EC(li),EC(lj);
11. end if
12. ifΔ(lc,li) then
13. UpdateEP(u),EP(li),EP(lj);
14. end if
15. end for
16. until convergence;
17. returnΘ=ES(L),EP(L),EP(U),ET(L),EW(L),EC(L).
6 实验设计
6.1 数据集
本实验使用的数据集是来源于Foursquare的用户真实签到记录,分别为纽约和东京两个城市。该数据集记录了从2012年4月到2013年2月的10个月间的用户签到记录,该数据集被使用于文献[16]的实验验证。本实验通过以下步骤对数据集进行预处理。首先过滤掉无效的签到数据,并且选取了在纽约和东京两个城市间总签到个数不少于90次的用户签到记录。经预处理后统计如表3所示,纽约的数据集中共有1 083个用户和38 471个兴趣点,总签到记录有227 482条。东京的数据集中有2 293个用户和61 886个兴趣点,总签到记录有573 703条。纽约和东京的数据集密度分别为0.545 861%和0.404 288%。Foursquare上的数据集类别可以分为9个根类别和417个子类别,9个根类别主要包括餐厅、车站、办公、户外运动等等。根据这10个月的签到数据,实验将前7个月的签到记录作为训练集,第8个月作为验证集来调整参数,并且将最后2个月作为测试集。根据验证集,实验得出空间维数K为60,标准化因子λ为0.03,以及权重a,b,c,d和e的取值分别为0.2,0.4,0.05,0.05和0.3。

Table 3 Foursquare datasets description表3 Foursquare数据集描述
6.2 评估指标
根据每一个用户的签到行为分析,给出一个按兴趣点转移概率从高到低进行排序的推荐列表Recu,N,N表示推荐列表中所推荐的兴趣点个数。为了评价本文提出的下一个兴趣点推荐算法的效果,我们选用推荐问题通用的指标:准确率、召回率和F1-score。准确率指推荐结果中用户将来真正访问的数量占推荐总数的比例,反映了推荐的准确性。召回率指推荐结果中用户将来真正访问数量占用户将来访问兴趣点总量的比例,反映了推荐的全面性。F1-score是准确率和召回率的综合,F1-score越高,说明推荐模型越稳健。对用户进行下一个兴趣点推荐的准确率和召回率定义如下:
(11)
(12)
(13)
其中,Lvisited表示用户u访问过的兴趣点集合,|Lvisited|表示用户u访问过的兴趣点的总数,|U|表示用户的总数,N表示下一个兴趣点推荐列表中所推荐的兴趣点个数。准确率和召回率相互制约,F1-score总体评估,综合利用三者可以对预测结果做出客观的评价。
6.3 性能与实验对比
本文主要将提出的模型CPME和PRME进行比较。CPME和PRME的性能比较结果如图7~图9所示。从图中可以看出,我们提出的模型比PRME性能更优,性能提高了12.35%左右。
图6描述了不同时间阈值对纽约和东京数据集TOP10准确率的影响,其中τ分别为3 h,6 h,12 h和24 h。CPME和CPME-G的准确率高于PRME和PRME-G。
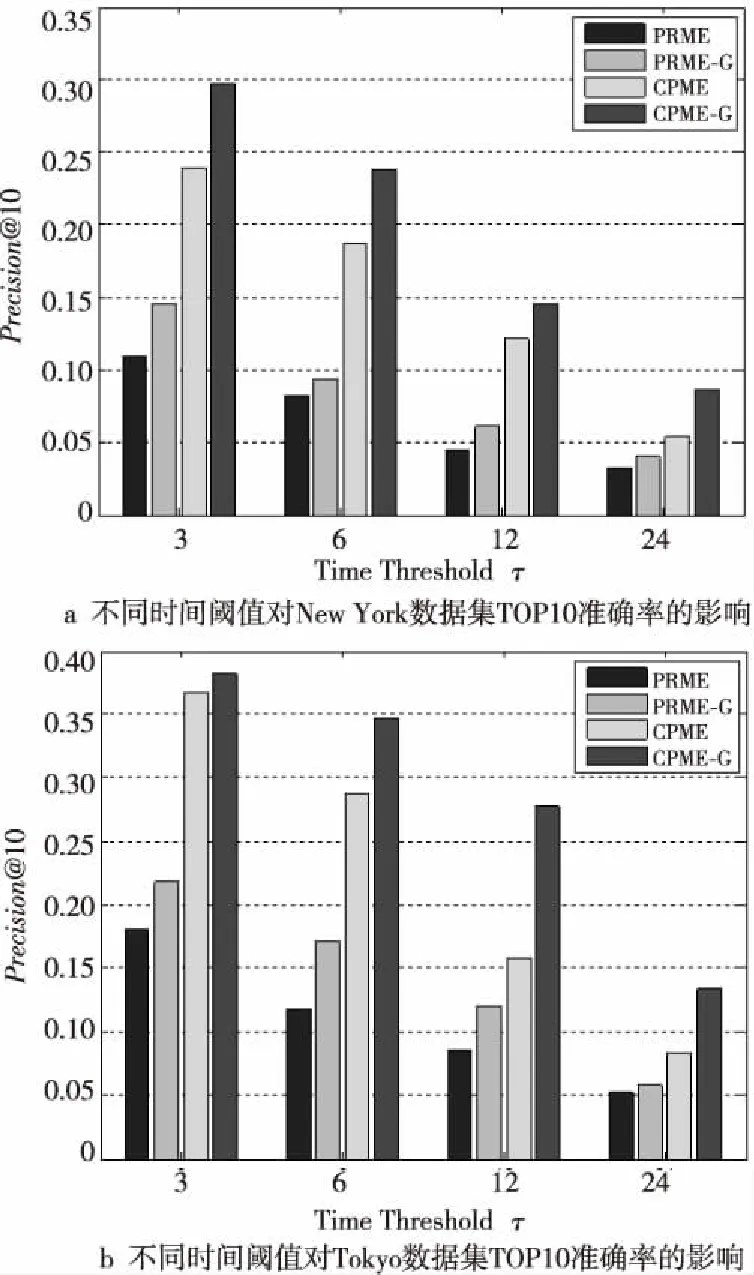
Figure 6 Precision of the two city datasets varies with time threshold图6 两个城市数据集的准确率随时间阈值变化的结果
同时,这些方法的准确率都随着τ的增大而降低,分析得出:时间阈值越大,兴趣点之间的时序转移关系就越小。统筹权衡用户个人偏好、时序转移关系、上下文感知和地理位置四个因素的影响,实验将时间阈值设定为6 h。由图7和图8可知,无论N取何值,本文所提出的CPME在2个数据集上的准确率和召回率普遍优于PRME的。同时,CPME和PRME模型性能都远高于PMF(Probabilistic Matrix Factorization)。由图7~图9可知,当在同一个N下进行比较时,考虑的上下文信息种类越多,推荐精度越高。同时我们发现,不同上下文信息种类之间的组合不同,实验的结果也不同,图例中的W(Day-of-Week)、T(Time-of-Day)、C(Catagory)、W+T、C+W、T+C、T+W+C是指CPME考虑的上下文信息的种类及组合。由于Time-of-Day对一天中的签到点的分类更为精细,而Day-of-Week把一周七天分为工作日和周末两大类导致数据整体稀疏性缓解,可以发现单独考虑Time-of-Day比单独考虑Day-of-Week的效果更好。实验通过考虑Time-of-Day和Day-of-Week,同时加入兴趣点类别的考虑,实验的推荐精度得到了显著提升。

Figure 7 Precision of the two city datasets varies with N图7 两个城市数据集的准确率随N变化的结果

Figure 8 Recall of the two city datasets varies with N图8 两个城市数据集的召回率随N变化的结果
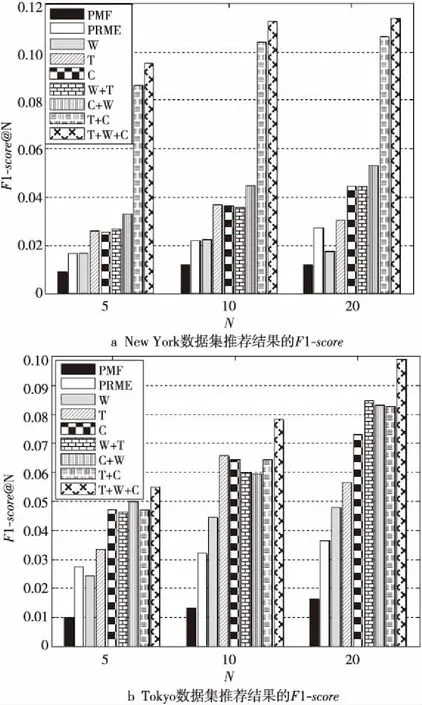
Figure 9 F1-score of the two city datasets varies with N图9 两个城市数据集的F1-score随N变化的结果
本文分析了上下文信息的类型对推荐的影响,我们选取了Time-of-Day、Day-of-Week以及Category三个空间。从图中可以得出考虑上下文信息比不考虑的性能更优。总体来看,随着上下文信息的加入,性能越来越好。更精细地分析可以得出不同的上下文信息对性能的提高也不同。
7 结束语
本文提出一种基于个性化上下文感知度量嵌入的方法来推荐下一个兴趣点,并且使用了排名度量嵌入算法计算隐式空间的兴趣点转移概率。在此基础上进一步提出了CPME-G模型,该模型融合四种影响因素:用户个人偏好、时序转移关系、上下文感知和地理位置影响。最后,在Foursquare的两个数据集上验证了本文算法的可行性。为了提高本模型下一个兴趣点推荐的性能,未来的工作中将考虑更多的上下文信息。
参考文献:
[1] Chen S,Moore J L,Turnbull D,et al.Playlist prediction via metric embedding[C]∥Proc of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2012:714-722.
[2] Cho E,Myers S A,Leskovec J.Friendship and mobility:User movement in location-based social networks[C]∥Proc of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2011:1082-1090.
[3] Li X,Cong G,Li X L,et al.Rank-geofm:A ranking based geographical factorization method for point of interest recommendation[C]∥Proc of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval,2015:433-442.
[4] Lian D,Zhao C,Xie X,et al.GeoMF:Joint geographical modeling and matrix factorization for point-of-interest recommendation[C]∥Proc of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2014:831-840.
[5] Ye M,Yin P,Lee W C,et al.Exploiting geographical influence for collaborative point-of-interest recommendation[C]∥Proc of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval,2011:325-334.
[6] Yuan Q, Cong G, Ma Z,et al.Time-aware point-of-interest recommendation[C]∥Proc of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval,2013:363-372.
[7] Cheng C,Yang H,Lyu M R,et al.Where you like to go next:Successive point-of-interest recommendation[C]∥Proc of the 22th International Joint Conference on Artificial Intelligence,2013:2605-2611.
[8] Ye J,Zhu Z,Cheng H.What's your next move:User activity prediction in location-based social networks[C]∥Proc of the 2013 SIAM International Conference on Data Mining,2013:171-179.
[9] Rendle S, Freudenthaler C,Schmidt-Thieme L.Factorizing personalized Markov chains for next-basket recommendation[C]∥Proc of the 19th International Conference on World Wide Web,2010:811-820.
[10] Feng S,Li X,Zeng Y,et al.Personalized ranking metric embedding for next new POI recommendation[C]∥Proc of the 24th International Joint Conference on Artificial Intelligence,2015:2069-2075.
[11] Zheng Y,Zhang L,Xie X,et al.Mining interesting locations and travel sequences from GPS trajectories[C]∥Proc of the 18th International Conference on World Wide Web,2009:791-800.
[12] Liu B,Fu Y,Yao Z,et al.Learning geographical preferences for point-of-interest recommendation[C]∥Proc of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2013:1043-1051.
[13] Yang D,Zhang D,Zheng V W,et al.Modeling user activity preference by leveraging user spatial temporal characteristics in LBSNs[J].IEEE Transactions on Systems,Man,and Cybernetics:Systems,2015,45(1):129-142.
[14] Tang J,Aggarwal C,Liu H.Recommendations in signed social networks[C]∥Proc of the 25th International Conference on World Wide Web,2016:31-40.
[15] Lian D,Ge Y,Zhang F,et al.Content-aware collaborative filtering for location recommendation based on human mobility data[C]∥Proc of the 15th IEEE International Conference on Data Mining,2015:261-270.
[16] He J,Li X,Liao L,et al.Inferring a personalized next point-of-interest recommendation model with latent behavior patterns[C]∥Proc of the 30th AAAI Conference on Artificial Intelligence,2016:137-143.
[17] Xie M,Yin H,Xu F,et al.Graph-based metric embedding for next POI recommendation[C]∥Proc of the 17th International Conference on Web Information Systems Engineering,2016:207-222.
[18] Gormley M R,Yu M,Dredze M.Improved relation extraction with feature-rich compositional embedding models[C]∥Proc of 2015 Conference on Empirical Methods on Natural Language Processing,2015:1-12.
[19] Rendle S,Freudenthaler C,Gantner Z,et al.BPR:Bayesian
personalized ranking from implicit feedback[C]∥Proc of the 25th Conference on Uncertainty in Artificial Intelligence,2009:452-461.
