面向中文社交媒体语料的无监督新词识别研究
2018-05-04黄锴宇黄德根
张 婧,黄锴宇,梁 晨,黄德根
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
社交媒体数据承载着大量舆情信息及商业信息。近年来,面向微博等社交媒体语料的自然语言处理任务受到广泛关注,例如,微博情感分析[1]、命名实体识别[2-4]、热点事件抽取[5]等。此外,还有很多面向微博语料的评测任务,例如,COAE2014评测任务中新增加了面向微博的情感新词发现任务,NLPCC2015也开展了面向微博的中文分词及词性标注任务[6]。目前,很多优秀的中文分词系统应用在传统语料(例如新闻、专利)上,已经达到了令人满意的效果[7-10]。然而,由于用户在社交媒体中发表言论时通常使用极其随意的表达方式,因此,社交媒体语料中包含很多缩略词、转义词、谐音词等新词,使得现有的很多自然语言处理技术和工具无法正常用于社交媒体语料的词法分析任务[11]。研究显示,在中文分词评测中,系统间性能差别最大的是未登录词的召回情况[12]。为了提高面向社交媒体语料的中文分词效果,本文利用大规模未标注的微博语料进行新词识别研究。
1 相关工作
新词识别方法一般分为有监督方法和无监督方法。有监督方法需要利用大规模熟语料作为训练语料,但面向社交媒体的熟语料极其匮乏,故无监督方法更适用于面向微博语料的新词识别任务。文献[13]提出采用信息熵(Information Entropy,IE)与词法规则相结合的无监督方法,识别微博语料中的新词,该文献首先采用词关联性信息的迭代上下文熵算法获取候选新词,再使用词法信息进行过滤,取得较好的效果。文献[14]提出Overlap Variety(OV)方法来解决微博语料中低频新词的召回问题,OV方法在衡量候选新词可信度的时候不单纯考虑候选新词的频率,而是比较该候选新词的前后邻接词(Accessor Variety,AV)和该候选新词的覆盖串的AV值。该篇文献的实验表明,OV方法是目前新词识别效果最先进的方法之一。
现有的无监督新词识别方法大都采用传统统计量IE、AV、PMI(Point-wise Mutual Information)等提取大规模未标注语料中的词碎片的分布信息。为了更加有效地使用已有的统计量,本文利用发展语料,分析了传统统计量对有意义的二元词串和无意义的二元词串的区分效果,并选择最具有区分力度的统计量对语料中的词碎片进行考量,获得候选新词。
除了以上传统统计量之外,词向量的提出为无监督新词识别方法提供了有利的参考信息。文献[15]首先提出了分布式词表示方法,又称词向量(word embedding)。通过大规模语料训练得到的词向量既包含词语的语义信息,又包含词语的句法信息。文献[16]提出了两种训练词向量的神经网络模型CBOW和Skip-gram,该方法采用低维空间表示法,不但解决了维数灾难问题,而且挖掘了词语之间的关联属性,从而提高了词语表示在语义上的准确度。CBOW模型是在已知上下文的基础上预测当前词,而Skip-gram模型恰好相反,是在已知当前词的基础上预测其上下文。
目前,关于词向量的研究备受关注。文献[17]提出了一种新的神经网络结构来训练词向量,该文献的实验证明,在训练词向量的过程中,该方法能结合局部信息和全局信息更好地获取词的语义信息。文献[18]提出了基于字向量和词向量相结合的方式获得词向量,该文献表明,字词结合的词向量比传统词向量涵盖了更有效的语义及句法信息。
本文结合上述的词向量技术和传统统计量,提出了一种新的无监督新词识别方法。首先,使用PMI方法获取候选新词;其次,采用多种策略在大规模未标注的微博语料上训练得到字向量和词向量;再根据训练得到的字向量和词向量构建成词概率较低的弱成词词串集合,利用该集合对候选新词从内部构成和外部环境两个方面进行过滤,以提高新词识别效果。此外,本文还重现了目前新词识别效果较好的Overlap Variety方法作为本文的对比实验。
2 新词定义及其分析
2.1 新词定义
新词,又称未登录词,目前没有统一的界定。文献[19]将新词定义为没有在词典中出现的词;文献[20]则认为,新词是指随时代发展新出现的词或旧词新用的词。本文所识别的新词与传统定义的新词不同,不是单纯指分词系统词典中不存在的词,而是指分词语料标准集中存在的,但分词系统标注结果中不存在的词。具体定义如下:
GSS(gold standard set): 表示人工标注的标准分词集合。
SRS(segmented results set): 表示使用分词工具进行分词后得到的分词集合。
本文对新词的定义: New word={w,w∈GSS 且 w∉SRS}。
这样定义的原因有两点: 第一,该定义所指的新词一部分属于分词系统所使用的词典中不包含的词,记为NWset1;另一部分属于系统词典中包括,但分词系统未正确切分的词,记为NWset2。这两类新词对于提高分词系统的性能都具有重要的作用,NWset1可以丰富现有词典的词汇,而NWset2可以完善词典中已有的词语的成词代价。第二,这样定义新词不局限于特定的某个词典,因而即使对于词典差异很大的分词系统,我们的定义也同样适用。
2.2 新词分析
我们根据《北京大学现代汉语语料库基本加工规范》[21]人工标注了一万条微博语料作为发展语料,实验数据部分对发展语料的标注过程进行了详细介绍。经过统计,发展语料标准集中的总词条数(不同词个数)为46 112,其中新词个数为22 957,新词比例为49.79%,可见微博语料中包含大量新词。此外,我们对发展语料中新词的词长分布进行了分析,分析结果如图1所示。
图1表明,发展语料中的新词主要由二元新词和三元新词构成,二者之和占新词总数的92%,远远超过其他新词的比例。因此,本文重点识别微博语料中词长不大于3的新词。
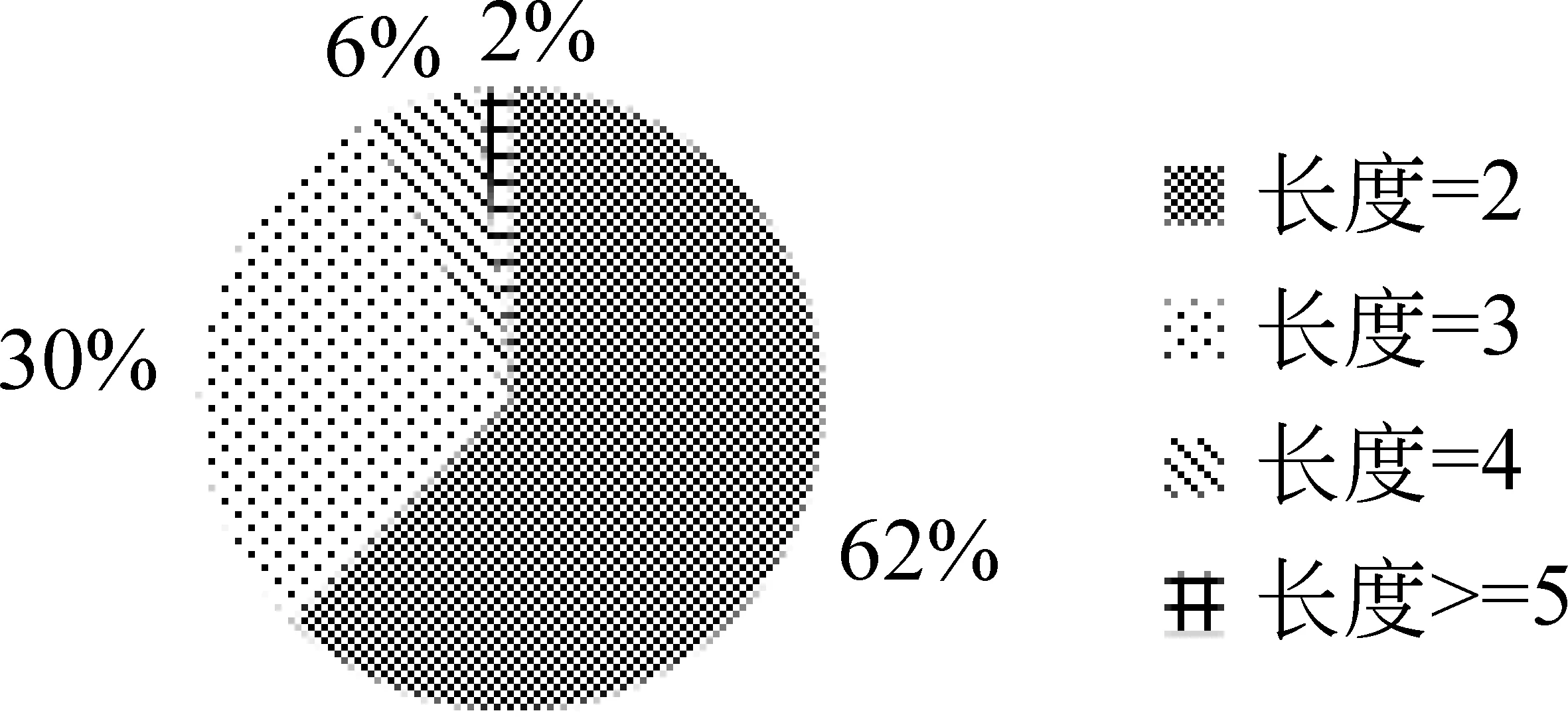
图1 发展语料中新词的词长分布
3 理论基础
3.1 词向量
词向量的提出使得在无监督的条件下获得语料中词语的语义信息成为可能。由于词向量模型中基于softmax方法的Skip-gram模型更适用于低频词,而微博语料中新词的频率普遍偏低(经统计,规模为一万条微博的发展语料中,频率为1的新词占总词条的69%)。因此本文使用基于softmax方法的Skip-gram模型训练得到词向量,训练参数为: 维度=200,窗口=9,最低词频=1。实验中我们收集了35万条未标注的微博语料用来训练词向量。通过采用不同的策略,训练得到以下三种不同的词向量,用于构建候选新词过滤集合。三种词向量分别为: 词向量WE,字向量CE和含位置信息的字向量LCE,为了叙述方便,后文统称为词向量。
词向量: 使用Nihao分词工具[8]对未标注的微博语料进行预分词,将预分词语料中的词及词碎片作为神经网络模型的训练单位,训练得到词向量,记为WE(word embedding)。
字向量: 将未标注的微博语料按字切分,将字作为神经网络模型的训练单位,训练得到字向量,记为CE(character embedding)。
含位置信息的字向量: 由于中文中字的歧义现象比较严重,为了获得更加有效的字向量,我们使用分词工具对大规模未标注的微博语料进行预分词后,根据字在词语中的位置对字进行细分类。本文根据字在词中的位置,将字分为四个类别: B表示该字出现在所在词语的开始位置;E表示该字出现在所在词语的结束位置;M表示该字出现在所在词语的中间位置,即非开始位置和结束位置;S表示该字独立成词或表示该字为词碎片。将含有分类信息的字作为神经网络模型的训练单位,训练得到包含位置信息的字向量,记为LCE(location information based character embedding)。
3.2 传统统计量
在很多自然语言处理任务中,都会使用前后邻接词、信息熵、点互信息等统计量提取重要参考信息,本节将对这三种统计量在新词识别任务中的使用方法进行详细介绍。
3.2.1 前后邻接词(Accessor Variety,AV)
文献[22]首次提出Accessor Variety的概念,其核心思想是若某个词串w是有意义的,那么它可以适用于多种不同的语言环境,即,如果一个词串出现在不同的语言环境下,那它可能是有意义的。在新词识别任务中,令Lav(w)表示与词串w直接相邻的不同的前一个字的个数,Rav(w)表示与词串w直接相邻的不同的后一个字的个数。Lav(w)和Rav(w)这两个值可以用来衡量词串w对不同语境的适应能力。词串w的AV值定义如式(1)所示。
gav(w)=logAV(w)
(1)
其中,AV(w)=min{Lav(w),Rav(w)}。
3.2.2 信息熵(Information Entropy,IE)
信息熵是信息论的基本概念,又称熵,可以衡量一个随机变量的不确定性。一个随机变量的信息熵越大,它的不确定性就越大,那么,正确估计其值的可能性就越小。在新词识别任务中,我们利用信息熵衡量语料中某一词串的所有前邻接词(或后邻接词)分布的不确定性。信息熵越小说明词串的前邻接词(或后邻接词)分布越集中,这样的词串越有可能与其前邻接词(或后邻接词)合并形成候选新词;反之,说明词串的前邻接词(或后邻接词)分布的越分散,该词串独立成词的可能性越大。我们用左信息熵LIE计算词串与其前邻接词的信息熵,用右信息熵RIE计算词串与其后邻接词的信息熵,计算如式(2)所示。
(2)
(3)
其中,w为当前考察的词串,m为w的前邻接词的总数,n为w的后邻接词的总数,lwi为w的第i个前邻接词,rwi为w的第i个后邻接词。
3.2.3 点互信息(Point-wiseMutualInformation,PMI)
点互信息源于信息论中的互信息,是一种用来度量关联性的统计量。在新词识别任务中,通常使用PMI来衡量词碎片之间的共现程度,其具体的计算如式(4)所示。
(4)
其中,x、y表示语料中的词或词碎片,P(x,y)表示x和y作为相邻词串同时出现的频率,P(x)、P(y)分别表示x和y在整个语料中出现的频率。
4 新词识别算法
在新词识别过程中,由于二元新词的构成形式(单字+单字)相对于三元新词的构成形式(单字+二字、二字+单字、单字+单字+单字)较为简单,因此,我们优先识别二元新词,根据过滤后的二元新词对语料进行自动修正,然后进行二次迭代,识别三元新词。每次迭代过程中,将新词识别任务分为候选新词识别和候选新词过滤两个子任务,下面分别详细介绍这两个子任务的处理方法。
4.1 候选新词识别
本文首先利用发展语料分析现有统计量(AV,IE,PMI)对预分词结果中的单字词碎片的区分效果,根据分析结果选择区分效果最为明显的统计量进行候选新词识别。由于二元新词的识别结果将直接影响到三元新词的识别,所以,在此分析过程中,我们主要针对连续的两个单字组成的二元词串进行分析。分析方法及结果如下:
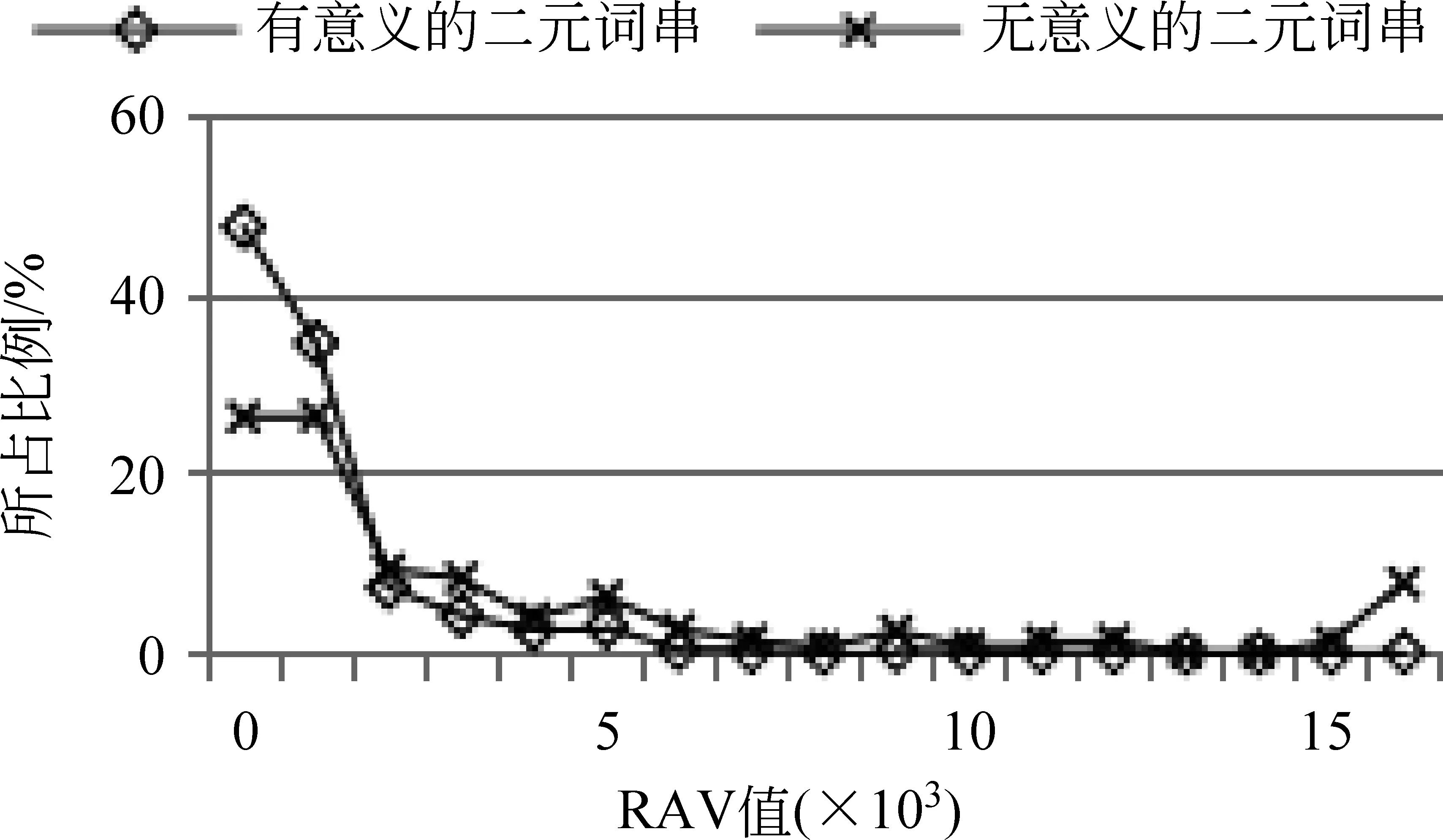
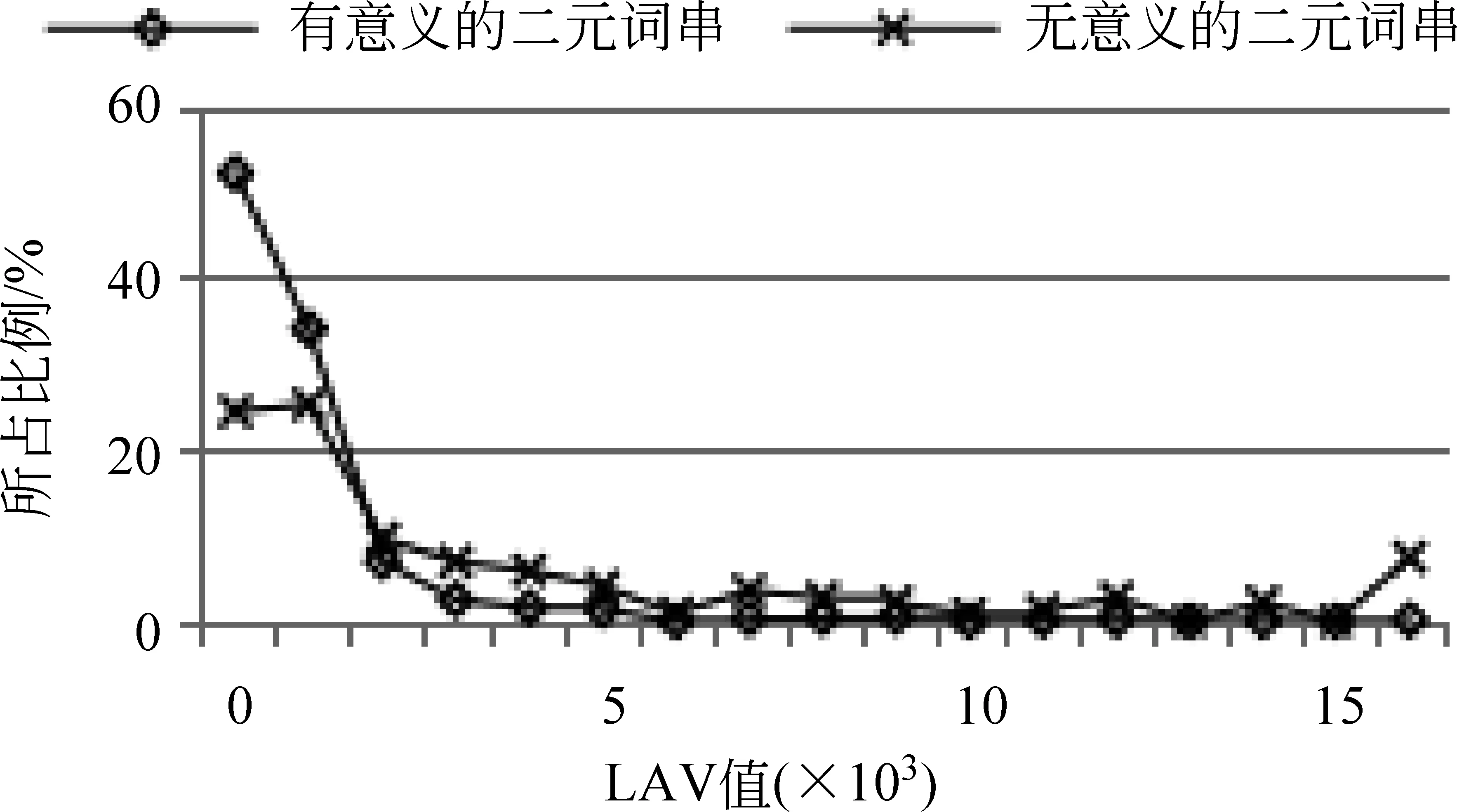
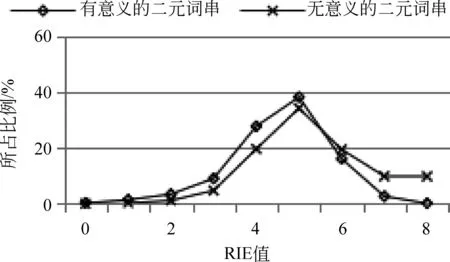
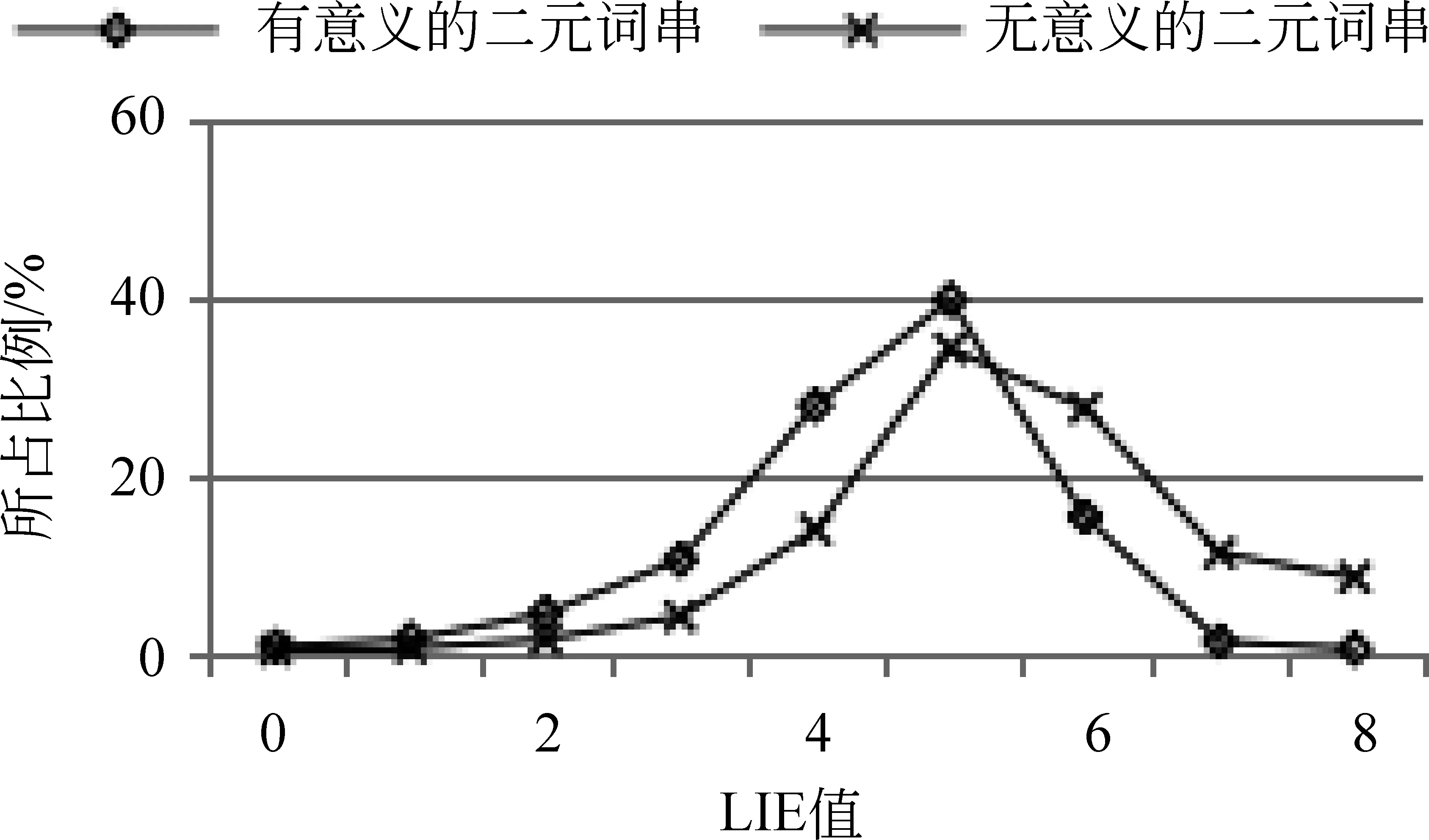
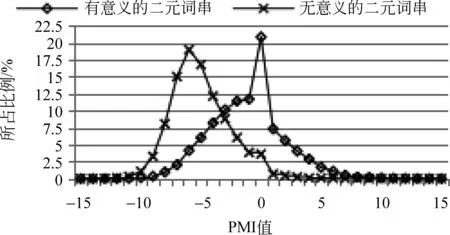
图2 传统统计量对二元词串的区分效果
分析方法: 根据发展语料的预分词结果(SRS集合)和标准集(GSS集合)获取有意义的二元词串和无意义的二元词串,分别计算每个二元词串的PMI值和二元词串中第一个字的RIE值、RAV值,以及第二个字的LIE值、LAV值。每个统计量取不同值时所包含的二元词串的比例如图2所示。
词串的获取: 抽取发展语料的SRS集合中所有连续的两个长度为1的词串组成的二元词串,记作SetAll。
有意义的词串: 对于SetAll中的词串bigramToken,如果发展语料的GSS集合中存在该词串bigramToken,则bigramToken为有意义的词串。
无意义的词串: 对于SetAll中的词串bigramToken,如果不在发展语料的GSS集合中,则bigramToken为无意义的词串。
图2的数据表明,IE(包括LIE和RIE)和AV(包括LAV和RAV)对有意义和无意义的二字词串的区分度不大。即,无论IE和AV的阈值定为多少,识别结果中的有意义的词串和无意义的词串的比例都差不多;而PMI对有意义和无意义的词串具有明显的区分效果,PMI值大于-4的二字词串中,有意义的词串的比重明显大于无意义的词串。因此,本文选择PMI对候选新词进行识别。在第一次迭代进行二元候选新词识别过程中,PMI阈值设为-4,即选择PMI值大于-4的二元词串作为候选新词。
4.2 候选新词过滤
现有的候选新词的过滤方法一般是基于规则或词典的方法,例如,词性规则和停用词词典。这些方法的过滤效果较为明显,但通用性较差。本文先利用词向量构建弱成词词串集合,然后再利用该集合对候选新词从内部构成和外部环境两个方面进行过滤。由于词向量可以根据不同的目标语料训练得到,因此,该方法不局限于特定的语料,通用性较好。
本文所选的弱成词词串的功能与停用词的功能类似(即与其他词串合并成为词语的能力较差),但弱成词词串不同于停用词,二者主要有两点不同: 第一,停用词中包含词长大于1的词语,而我们构建的弱成词词串只包含长度为1的字符;第二,停用词不包含位置信息,而弱成词词串包含位置信息。
构建弱成词词串集合时,我们选择成词能力较差的高频单字词及标点作为种子集合。该种子集合共包含11个字符: {“我”,“是”,“的”,“了”,“在”,“。”,“,”,“、”,“;”,“!”,“?”}。然后利用词向量计算当前词与种子集合中词的相似度,以此为依据扩展种子集合,经过T次迭代进而得到弱成词词串集合,本文实验中,T=3。词与集合的相似度计算公式如式(5)所示。利用词向量和种子集合构建弱成词词串集合的算法如算法1所示。
(5)
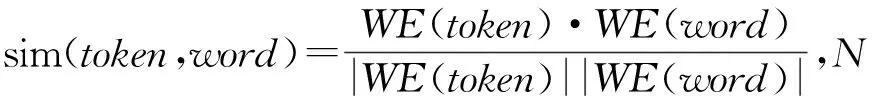

算法1:弱成词词串集合的构建算法输入:词向量字典WEDictionary、种子集合SeedSet、预分词语料segCorpus输出:弱成词词串集合L1.foriterator=1toTdoL2. tokenSim=[] //用于存放词和集合的相似度L3. fortokeninsegCorpusdoL4. iftoken的长度等于1thenL5. 获取包含该token的词向量L6. forwordinSeedSetdoL7. 获取word的词向量L8. endforL9. 根据式(5)计算token和SeedSet的相似度,将结果保存到tokenSim中L10 endifL11. endforL12. 将tokenSim中的token按照其相似度值从大到小排序,取TopM的token加入SeedSet中L13.endfor
构建好弱成词词串集合后,从候选新词的内部构成和外部环境两个方面对候选新词进行过滤。从候选新词的内部构成上对其进行过滤时,利用弱成词词串集合判断构成候选新词的词碎片的成词能力,如果构成候选新词的任一词碎片的成词能力较弱,则该候选新词会被过滤掉;从候选新词的外部环境上对其进行过滤时,如果该候选新词的前邻接词或后邻接词中包含成词能力较弱的词串,说明该候选新词的外部环境较为稳定,则该候选新词不会被过滤掉,反之,该候选新词会被过滤掉。具体如算法2所示。

算法2:候选新词过滤算法输入:词向量词典WEDictionary、弱成词词串集合AntiWordSet、候选新词NWCandidateSet、预分词语料segCorpus输出:过滤后的候选新词FilteredNW//从候选新词的内部构成上对其进行过滤:L1. forcandidate=wiwi+1inNWCandidateSetdoL2. 计算AS1=AvgSim(wi,AntiWordSetM)和AS2=AvgSim(wi+1,AntiWordSetM)L3. ifAS1大于阈值SIMorAS2大于阈值SIMthen将candidate过滤掉L4. endfor//从候选新词的外部环境上对其进行过滤:L5. forcandidate=wiwi+1inNWCandidateSetdoL6. 获取candidate在segCorpus中的上下文contextStr=wi-cwi-c+1...wi-1wiwi+1...wi+1+cL7. 将所有contextStr加入到candidate的上下文集合contextStrSet中L8. environmentFlag=0L9. forcontextStr=wi-cwi-c+1...wi-1wiwi+1...wi+1+cincontextStrSetdoL10. 计算prefixContext=AvgSim(wj,AntiWordSetM),i-c≤j≤i-1L11. 计算suffixContext=AvgSim(wj,AntiWordSetM),i+2≤j≤i+1+cL12. ifprefixContext大于阈值SIMorsuffixContext大于阈值SIMthenenvironmentFlag=1L13. endforL14. ifenvironmentFlag==0then过滤该候选新词candidateL15.endfor
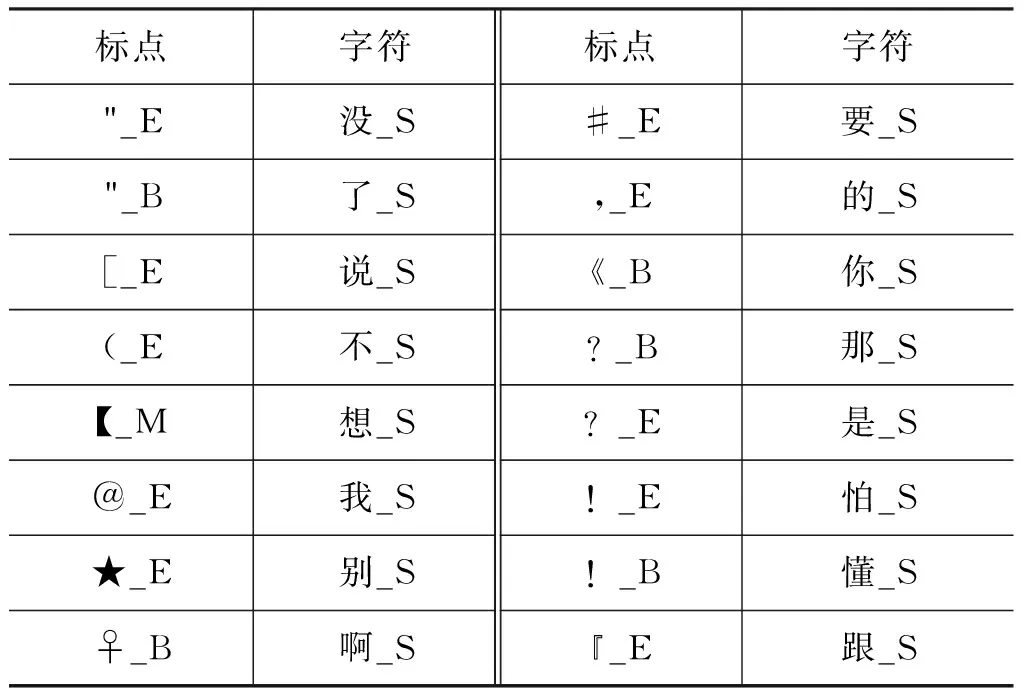
表1 弱成词词串示例
在构建弱成词词串集合的过程中,本文经过T=3次迭代,经过多次实验,当弱成词词串集合包含170个词串时,实验结果达到最优。最终,获得的弱成词词串集合包括120个标点和50个字符。表1是弱成词词串集合中包含的部分标点和字符。表中的标点和字符后面的B、M、E、S表示该字符的位置。
5 实验及实验结果
5.1 实验语料
未标注语料: 为了获得尽可能丰富的词串信息,我们收集了2011~2015年近35万条未标注的微博语料,预分词后,用于训练词向量以及计算词串的IE、AV、PMI等信息。
测试语料: 使用NLPCC2015年的面向微博语料的中文分词评测任务的训练语料作为本实验的测试语料,语料规模为一万条微博[6]。
发展语料: 为了在完全不参考测试语料的情况下对本文的方法进行调参,我们根据《北京大学现代汉语语料库基本加工规范》[21]人工标注了一万条微博作为发展语料。为了确保人工标注的一致性,我们随机选取500条微博让两名标注人员(标注人员A和标注人员B)对其进行标注,然后对比两人的标注结果,针对不一致的标注结果进行讨论和修改,直到标注的一致性达到一定的Kappa值[23]。因Kappa值考量了标注人员随机标注的可能性,故它比一般的百分比计算方法更具有说服性,其计算如式(6)所示。
标注人员的标注任务是在预分词的基础上进行的,假设预分词结果为:W1W2...Wi...Wn,标注人员是在原有词串的间隔处进行操作。如果选择将Wi与Wi+1合并,标注者在Wi与Wi+1之间的标记为yes(记为下标y),反之,如果不合并,则此处的标记为no(记为下标n)。根据两名标注人员的标记结果,最后计算得到的kappa值为93.55%,这说明标注结果已经达到了较高的一致性,因此,标注人员标注的发展语料是可靠的。
其中,P(A)表示两名标注人员实际标注一致的概率;P(e)表示两名标注人员随机标注一致的概率;C(AyBy)表示两名标注人员在对应相同的地方都选择合并的操作数;C(AnBn)表示两名标注人员在对应相同的地方都选择不合并的操作数,因预分词结果中很多地方都不需要合并,且我们更关注两名标注人员同时选择合并的情况。因此,在计算Kappa时,两名标注人员都未修改的地方不予考虑,即C(AnBn)=0;Count表示被任意一名标注人员修改过的地方的总数;P(Ay)表示标注人员A标注成yes的概率,即标注人员A标成yes的操作数除以标注人员A总的操作数,式(8)中的其他P(*)表示的意思类似于P(Ay)。
5.2 实验设计及结果分析
5.2.1 新词识别结果
实验过程中,我们首先识别由两个单字词碎片组成的词串,然后进行二次迭代,获得三元新词。为了检验本文的方法,我们进行了如下对比实验,二元新词的识别结果如表2所示。

表2 二元新词识别结果
Baseline: 利用PMI识别预分词语料中的二元新词,其中PMI的阈值设定为-4;
Baseline+WE: 采用Baseline的方法获得候选新词,使用基于词向量WE构建的弱成词词串集合对候选新词从内部结构方面进行过滤;
Baseline+CE: 采用Baseline的方法获得候选新词,使用基于字向量CE构建的弱成词词串集合对候选新词从内部结构方面进行过滤;
Baseline+LCE: 采用Baseline的方法获得候选新词,使用基于含有位置信息的字向量LCE构建的弱成词词串集合对候选新词从内部结构方面进行过滤;
ExperimentX+External: 表示在实验ExperimentX的基础上,从外部环境方面对候选新词进一步进行过滤,其中上下文窗口c的取值为1的实验效果最佳;
OverlapVariety: 为了将本文提出的方法和现有优秀的方法进行对比,我们重现了文献[14]提出的OverlapVariety方法。
数据显示,单纯从内部构成方面对候选新词过滤的实验中,LCE的过滤效果最为明显,比基线系统的F值提高了3.28%,比Overlap Variety方法提高了1.43%;从外部环境对候选新词过滤后,F值得到进一步提高,最佳结果比基线系统提高了6.75%。实验表明,本文利用含有位置信息的字向量构建的弱成词词串集合能有效过滤二元候选新词中的噪音词串。
根据二元新词的识别结果,将预分词语料中的二元新词进行合并,然后进行二次迭代,进一步识别语料中的三元新词。二次迭代过程中,获取三元候选新词时,同样采用PMI方法。利用发展语料调整PMI阈值时,PMI阈值对新词识别结果的影响如图3所示。
由图3可见,二次迭代的PMI阈值为2时,发展语料中新词识别结果的F值达到峰值。因此,本文二次迭代时设定PMI阈值为2。最终发展语料中二元新词和三元新词的识别结果如表3的第一行数据所示;测试语料的识别结果如表3的第二行数据所示。
实验结果表明,测试语料和发展语料的识别结果比较接近,说明本文提出的方法能够有效识别二元和三元新词,并对候选新词中的噪音进行有效过滤;同时,该结果也进一步证明了我们标注的发展语料的可信度。
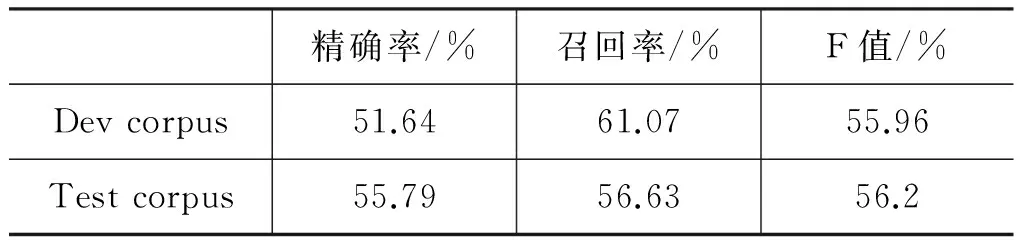
表3 二元新词和三元新词的识别结果
此外,我们通过改变未标注语料的大小,比较了语料规模对新词识别结果的影响,实验结果如图4所示。实验表明语料规模从1万条微博(只包含发展语料)到35万条微博逐渐扩大时,召回率逐渐降低,精确率和F值不断提高。当语料规模达到15万条微博后,实验结果趋于平稳。
5.2.2 新词识别结果分析
我们最终识别到的新词包括医学、科技、金融、生物、影视娱乐等多种领域的术语;还有人名、地名、品牌名等命名实体;此外,还有包括字母、数字与汉字组合成的新词,以及包含错字的新词。表4是我们识别到的新词的举例。
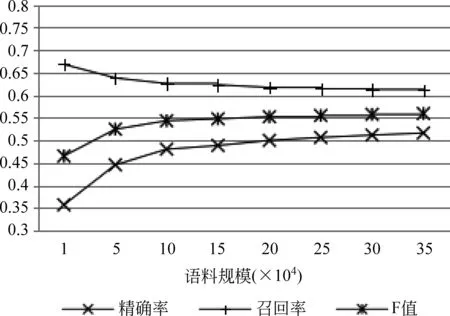
图4 语料规模对新词识别结果的影响
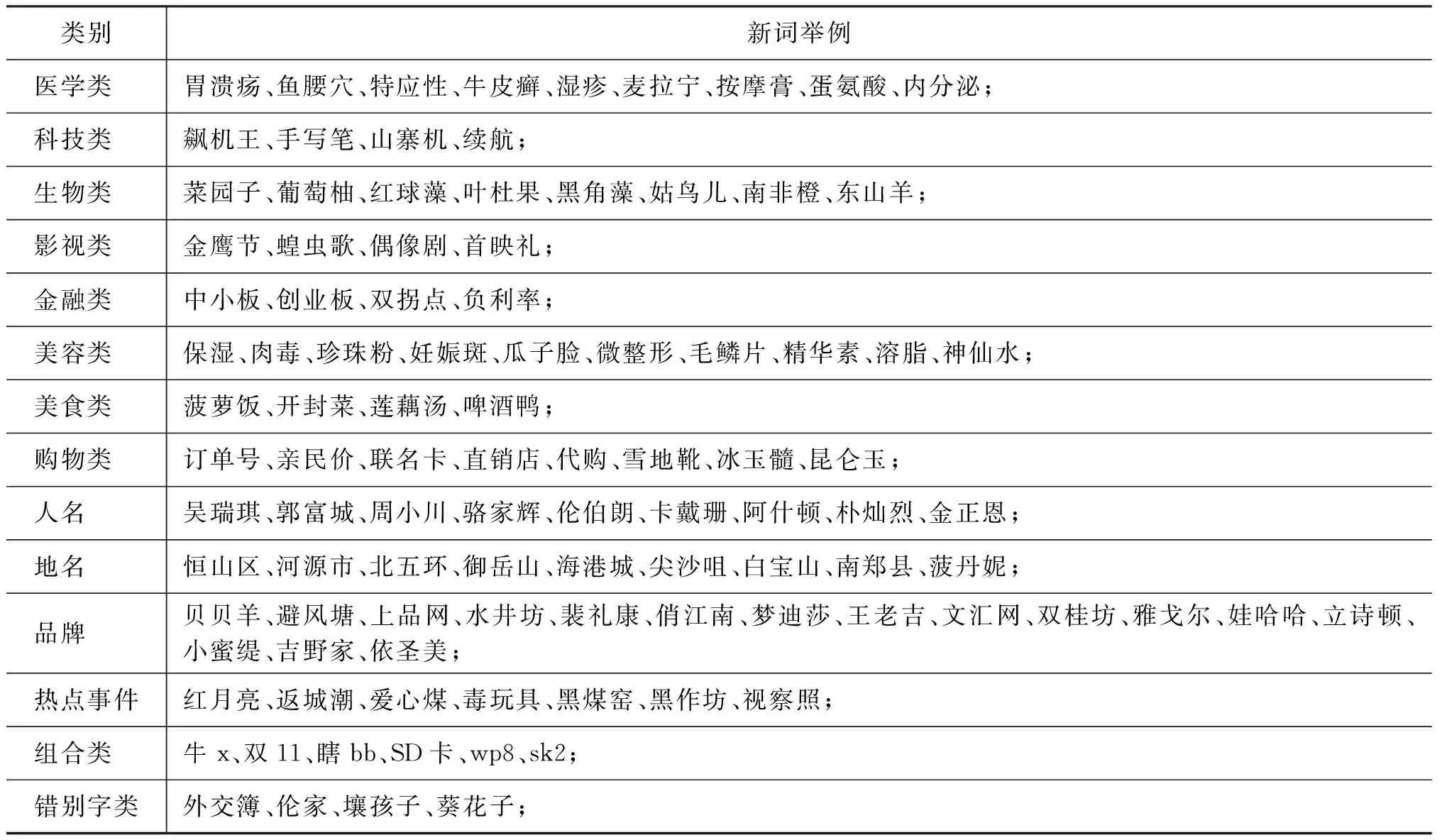
表4 新词示例
虽然本文提出的方法能够识别很多领域的新词,但该方法仍存在缺点。该方法对四字词的识别效果不佳,例如我们识别出的新词中还包括“心如止”(正确为: 心如止水)、“语道破”(正确为: 一语道破);此外,新词识别结果中除了上述识别不完整的四字词外,还有类似于“负全责”、“请接力”、“取决于”、“隐藏着”等包含多余成分的错误词语。因此,要获得更加高质量的新词,还需要很多工作和努力。
6 总结和展望
本文是面向中文社交媒体语料的新词识别研究。这一研究任务的难点在于,社交媒体语料中没有成熟的训练语料,无法通过有监督的方法训练得到可靠的新词识别模型。因此,本文采用基于PMI和多种策略的词向量的无监督方法进行新词识别和过滤。实验结果表明,本文利用词向量构建的弱成词词串集合对候选新词进行了有效过滤,新词识别效果明显优于基线系统和现有的最佳的无监督新词识别方法之一Overlap Variety方法。此外,为了分析传统统计量PMI、AV、IE等方法的识别效果,本文根据《北大分词语料标注规则》标注了面向社交媒体语料的分词语料,作为实验的发展语料,发展语料的实验结果与最终测试语料的实验结果较为接近,证明本文标注的发展语料具有较高的可靠性。
尽管本文所提出方法的识别结果得到了明显提高,但最终的F值还没有达到60%,因此还存在很大的提升空间。下一步,我们将在此基础上,进一步提高新词识别的精确度,利用自学习方法逐渐扩大面向社交媒体的成熟语料,为有监督方法提供可靠的训练语料。
[1] Nguyen T H, Shirai K. Topic modeling based sentiment analysis on social media for stock market prediction[C]//Proceedings of the 53rd Annural Meeting of the Association for Computational Linguistics. 2015: 1354-1364.
[2] Liu X, Zhou M, Wei F, et al. Joint inference of named entity recognition and normalization for tweets[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers. 2012: 526-535.
[3] Peng N, Dredze M. Named Entity Recognition for Chinese Social Media with Jointly Trained Embeddings[C]//Proceedings of the 2015 Conference on EMNLP of the Association for Computational Linguistics. Lisbon, Portugal, 2015: 548-554.
[4] Li C, Liu Y. Improving Named Entity Recognition in Tweets via Detecting Non-Standard Words[C]//Proceedings of the 53rd Annural Meeting of the Association for Computational Linguistics. 2015: 929-938.
[5] Dong G, Li R, Yang W, et al. Microblog burst keywords detection based on social trust and dynamics model[J]. Chinese Journal of Electronics, 2014, 23(4): 695-700.
[6] Qiu X, Qian P, Yin L, et al. Overview of the NLPCC 2015 Shared Task: Chinese Word Segmentation and POS Tagging for Micro-blog Texts[M].Natural Language Processing and Chinese Computing. Springer International Publishing, 2015: 541-549.
[7] Liu Y, Zhang Y, Che W, et al. Domain Adaptation for CRF-based Chinese Word Segmentation using Free Annotations[C]//Proceedings of EMNLP. 2014: 864-874.
[8] Degen H, Deqin T. Context information and fragments based cross-domain word segmentation[J]. China Communications, 2012, 9(3): 49-57.
[9] Li Z, Sun M. Punctuation as implicit annotations for Chinese word segmentation[J]. Computational Linguistics, 2009, 35(4): 505-512.
[10] Tseng H, Chang P, Andrew G, et al. A conditional random field word segmenter for sighan bakeoff 2005[C]//Proceedings of the 4th SIGHAN workshop on Chinese language Processing. 2005: 168-171.
[11] Eisenstein J. What to do about bad language on the internet[C]//Proceedings of HLT-NAACL. 2013: 359-369.
[12] Sproat R, Emerson T. The first international Chinese word segmentation bakeoff[C]//Proceedings of the 2nd SIGHAN workshop on Chinese language processing. Association for Computational Linguistics, 2003: 133-143.
[13] 霍帅, 张敏, 刘奕群, 等. 基于微博内容的新词发现方法[J]. 模式识别与人工智能, 2014, 27(2): 141-145.
[14] Ye Y, Wu Q, Li Y, et al. Unknown Chinese word extraction based on variety of overlapping strings[J]. Information Processing & Management, 2013, 49(2): 497-512.
[15] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors[J]. Cognitive modeling, 1988, 5(3): 1.
[16] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the 27th NIPS. 2013: 3111-3119.
[17] Huang E H, Socher R, Manning C D, et al. Improving word representations via global context and multiple word prototypes[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers. Association for Computational Linguistics, 2012: 873-882.
[18] Chen X, Xu L, Liu Z, et al. Joint learning of character and word embeddings[C]//Proceedings of IJCAI. 2015: 1236-1242.
[19] Chen K J, Ma W Y. Unknown word extraction for Chinese documents[C]//Proceedings of the 19th international conference on Computational linguistics. Association for Computational Linguistics, 2002: 1-7.
[20] 邹纲, 刘洋, 刘群, 等. 面向 Internet 的中文新词语检测[J]. 中文信息学报, 2004, 18(6): 2-10.
[21] 俞士汶, 段慧明, 朱学锋, 等. 北京大学现代汉语语料库基本加工规范[J]. 中文信息学报, 2002, 16(5): 51-66.
[22] Feng H, Chen K, Deng X, et al. Accessor variety criteria for Chinese word extraction[J]. Computational Linguistics, 2004, 30(1): 75-93.
[23] Carletta J. Assessing agreement on classification tasks: the kappa statistic[J]. Computational linguistics, 1996, 22(2): 249-254.
