粗糙集规则匹配算法及其在文本分类中的应用①
2018-05-04朱敏玲吴海艋
朱敏玲, 吴海艋, 石 磊
1(北京信息科技大学 计算机学院,北京 100101)
2(中国科学院 软件研究所,北京 100190)
随着信息技术的飞速发展,万维网的文本信息量急剧增长[1]. 2008年7月26日,谷歌在官方微博中称,其索引的网页数量已经突破1万亿幅,截止至2014年12月底,这一数值更是突破了30万亿幅大关,并以每日50亿的增长速度持续递增[2]. 可见,如何从庞大的网页数据中获得有用信息成为人们的迫切需求,而自动文本分类是获取相关信息的一种方法[3].
目前,文本分类领域常用的方法有支持向量机(SVM),朴素贝叶斯 (Naïve Bayes),K 近邻 (KNN),决策树方法(Decision Tree)等[4],与这些传统的分类方法相比,粗糙集理论用于分类的优点在于其能够通过属性约简在不影响分类精度条件下降低特征向量的维数,从而获得分类所需的最小特征子集,并配合值约简得到最简的显式分类规则[5],最后根据粗糙集的规则匹配方法对待分类文本进行有效的分类.
本文首先对粗糙集理论和中文文本分类的相关知识进行介绍与分析,及如何将中文文本转化为粗糙集所能处理的知识库系统,和如何通过粗糙集的属性约简和值约简来实现规则的提取; 然后,分析本研究中提出的粗糙集规则匹配的改进算法; 再次,对原始方法和改进算法进行对比实验,并对实验数据进行对比和分析; 最后,对本研究工作进行了总结.
1 相关知识
1.1 粗糙集理论
粗糙集 (Rough Set,RS) 理论是由波兰华沙理工大学的Pawlak教授在1982年提出的一种新的数学工具,它能有效地处理和分析不精确、不协调和不完备的信息,并从中发现隐含的知识和潜在的规律[6]. 本文通过粗糙集理论中的知识约简对文本进行分类规则提取,并通过改进的粗糙集匹配方法对新的待分类文本进行规则匹配和文本分类[7].
定义2. 设有信息系统S,是记载x在属性a上的值,表示矩阵中的第i行,第j列元素,被定义为:
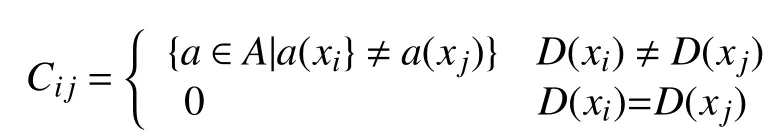
定义3. (区分函数)区分函数是从分辨矩阵中创造的. 约简算法是先求的每个属性的析取,再求其合取[9].
1.2 中文文本分类
相比于英文文本分类,中文文本分类的一个主要差别在于预处理阶段,因为中文文本的词与词之间没有明显的切分标志,不像英文文本的单词那样有空格来区分. 首先,通过现有的分词技术来对中文文本进行分词处理,并在此基础上提取一些重要的文本特征来将文本表示在向量空间. 本文的重点在于如何通过向量空间模型(VSM)和特定的特征选择函数,将文本分出的字、词、词组或概念转化为粗糙集理论所能处理的知识库或信息系统,关键词集即为信息系统中的条件属性集,文本类别集即为决策属性集. 通过Skowron提出的区分矩阵进行属性约简和规则提取[10],生成决策规则表,最后采用改进的规则匹配方法确定每条规则的规则支持度,最终作用于新文本的分类匹配中.
2 规则提取
2.1 文本预处理
文本预处理的过程主要包括:分词处理、停用词过滤、文本特征提取等[11]. 本文采用IKAnalyzer分词工具,它是一款以开源项目Lucene为应用主体,结合词典分词和文法分析算法的中文分词组件,其采用了特有的“正向迭代最细粒度切分算法”,有词性标注、命名实体识别、分词排歧义处理和数量词合并输出等功能,并支持个人词条的优化的词典存储,如“北京奥运会”,“1949 年”,“反装甲狙击车”被纳入用户词典后,可被正确分为一个词条,而不会拆分为“北京”、“奥运会”,“1949”,“年”,“反”,“装甲”,“狙击”,“车”,同时停用词过滤可以将文本使用频率较大但对文本分类没有实际作用的字、词和词组,例如:“的”,“和”,“同时”等,以及网络文本中的格式标签进行去除,例如:“@123456”,“本文来源”,“相关新闻”,“组图”等,该分词工具可在不影响文本原信息表达的情况下进行中文分词,在文本分词预处理中具有比较好的效果[12].
2.2 特征选择
在文本分类中,常用的特征选择函数有信息增益IG (Information Gain),期望交叉熵ECE (Expected Cross Entropy),互信息MI (Mutual Information)等[13].但是它们并不按类别计算统计值,所以选出的特征词往往都是全局意义上的,而实际情况中,往往很多极具类别区分度的词,如“剧组”,“直升机”,“导弹”,“演员”,“电子书”等,根据函数计算出的值不是很大,很可能被除掉,为了避免以上情的发生,本文采用CHI统计方法进行特征词的选择[14],选出的特征词往往更具备类别区分度,其定义如公式(1)所示.

其中,w代表特定词汇,Dj代表文本类别,N为文本总篇数;A为词汇w与类别Dj共现的文本篇数;B为词汇w出现类别Dj不出现的文本篇数C为类别Dj出现而词而汇w不出现的文本篇数;D为词汇w和类别Dj均不出现的文本篇数.
一般特征项的CHI值选取为对所有类别的CHI平均值或最大值,但是CHI统计方法由于考虑了特征项与类别的负相关性. 所以,在实际情况中,选词结果往往偏向于类别区分度更高的那一类或那几类文本,而对于文本内容比较相似、区分度较低的文本,选出的词函数值普遍偏低,从而只有较少的类别区分词被选中,对后续的粗糙集知识库的知识约简造成影响.故本文对CHI特征选择算法进行了改进,规定选取时特征项的CHI值为其对所有类别的CHI最大值,并加入新的选择公式对每类文本的特征词数量进行重新分配,使选择出的特征词更偏向于类别区分度较低的几类文本. 假设从K类文本中选取出N个特征项,改进后的公式(2).

即在原方法中,每类文本平均分到的特征词数量为N/k,由于原CHI方法在特征选择上对类别区分度较高的文本的偏袒,因此类别区分度较低的那几类文本实际分到的特征词数量将小于N/k,改进后的公式在N/k的基础上乘以类别因子AVG(N)/AVGN,Dj消除后者在特征词数量上的劣势,其中为全部文本的前N个特征项的CHI平均值,AVGN,Dj为类别Dj中前N个特征项的CHI值平均值. 从式(2)可以看出,类别区分度较小的类别,其AVG(N)/AVGN,Dj更大,故实际分到的特征词数也更多. 这也更有利于接下来的粗糙集属性约简,因为在类别区分度较大的类别中,过多的特征词必定造成条件属性的冗余,加大属性约简的负担,甚至影响属性约简的结果.
2.3 生成文本决策表
根据改进后的CHI特征选择方法选出前N个特征词组成了决策表的条件属性集,文本类别集合组成了决策属性集. 特征词的权重根据TF-IDF公式计算,如公式(3).

其中,tfik为特征项tk在文本di中出现的频率,idfik为特征项tk的逆向文档频率.
考虑到TF-IDF公式计算出的权值为连续值,因此还需要对连续值进行离散化,如公式(4).

其中,Weightik表示该特征词i在文本k中的权值,Wmin和Wmax分别表示特征词i在所有决策表中的最小值和最大值.a和b表示缩放范围[a,b].本文中对为0的项,取0,其余项根据缩放范围取[1,3]进行权值离散化.并对最终结果取整(如1.123取值为1)作为离散化后的权值. 经过离散化后的决策表1所示.

表1 文本分类决策表
2.4 决策表的规则提取
在规则提取上分两步走,首先进行特征词的属性约简,随后再进行属性值约简.
2.4.1 属性约简
为删除对文本分类决策没有影响的特征词,利用粗糙集的属性约简能力在保证决策表分类能力不变的前提之下,删除其中不相关、对决策结果不会造成影响的条件属性,即文本特征词,从而达到属性约简和降低特征维数的目的[15].
Skowron教授提出的区分矩阵和区分函数可以通过区分函数中的极小析取范式进行合取,获得知识系统中的所有属性约简的集合,但是对于最优约简子集的选择一直都是一个NP问题[16],因此不在本文的讨论范围之内. 本文直接选取所有属性约简集合中条件属性最少的约简子集生成新的约简决策表,并通过从约简决策表中减少条件属性的方法,依次计算每个条件属性的重要程度,作为后续规则匹配中的一个重要参数,如公式(5).
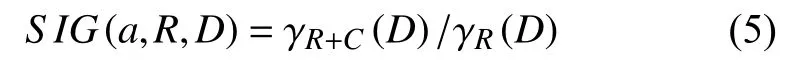
2.4.2 值约简
与粗糙集理论的属性约简相比,值约简再次用到了区分矩阵获取每一项中的极小析取范式,但两者的不同之处在于,在对结果进行合取转化时,属性约简是从全局出发,对所有的极小析取范式进行统一的合取化,其结果为所有属性约简结果的集合[17]. 而值约简中是对区分矩阵的每一行进行合取化,每一条完整的规则最终被约简为了多个能区分其他不同类别的最小规则集合.


表2 决策表
根据表2构造的区分矩阵如表3所示.
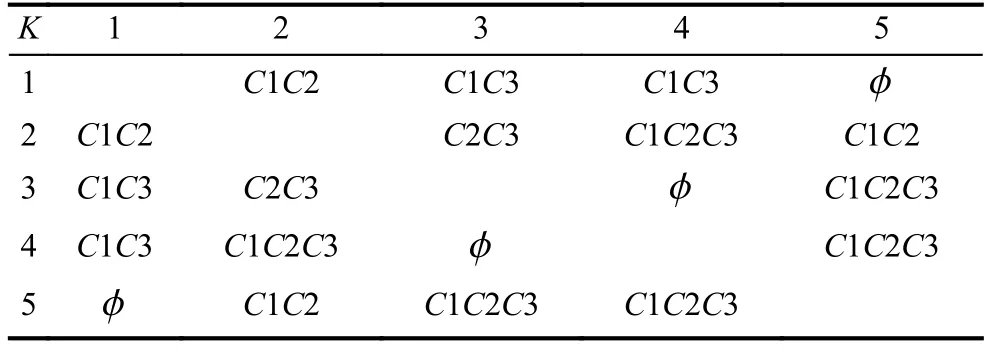
表3 区分矩阵
以表3的第2行为例,根据区分矩阵获取第i行完全规则的约简规则的步骤如下.
步骤1. 把每一行的空项和重复项去除,获得互不重复的最小析取范式集.处理后的第2行,第2项和第
步骤2. 把每一行的最小析取范式进行合取化,获得约简规则集的条件属性下标集合. 第2行提取出的规则集合表示为:

步骤3. 根据离散定律中的吸收律和幂等律删除冗余和包含关系,获得每一行的最简规则集合. 第2行的最简规则集合表示为:
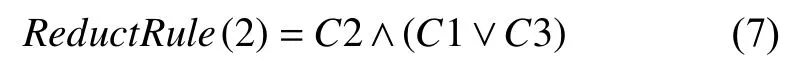
经过值约简后导出的约简规则如表4所示,*代表约简掉的属性权值.

表4 决策规则表
然后,对约简后的决策表中的重复规则和冗余规则进行合并,可得出表5的决策规则表.

表5 决策规则表
则,化简后的规则如下:

对表2和表5分析可知,经过值约简后的决策规则表,每条规则的条件前件长度得到了进一步的缩减,同时每两条规则之间互不冲突,并且与原决策表的完整规则一一对应. 约简后的规则集更加清晰明了,也具可解释性.
3 规则匹配
决策规则生成之后,就可以运用规则对新数据项或文本进行预测和分类. 基于粗糙集的规则匹配分为完全匹配和部分匹配两个阶段.
3.1 完全匹配
1)完全匹配的基本步骤
步骤1. 在分类器中对新数据项进行规则化处理,抽取出与完全规则条件属性一一对应的表达式.
步骤2. 在决策规则集中进行规则查找,如果有且只有一条规则与之完全对应,则新数据项的类别归至该决策规则所属的类别; 如果遍历完所有规则后,没有任何规则与之相匹配,则把该数据项归入待定项进入部分匹配阶段.
步骤3. 如果出现多个规则的前件与该数据项相匹配,则根据规则支持度的排序,把支持度最高的规则的决策类别定义为新对象的类别,如公式(7).
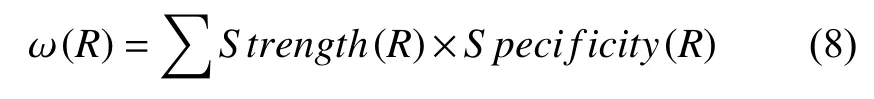
其中,Strength(R)是规则强度(Strength),即训练集中与之匹配的训练项个数;Specificity(R)是规则专指度(Specificity),即规则中条件属性前件的个数; ω (R)是规则支持度[19].
但是,由于规则专指度会对规则中属性条件较长的规则有所偏袒,导致完全匹配的规则结果往往选出条件属性数较多的规则作为分类的依据,这与粗糙集理论的本意有所矛盾. 故本文对完全匹配的算法进行了改进,在完全匹配阶段之前,对约简规则进行规则预检验.
2)规则预检验
规则预检验的过程分为如下几个步骤.
步骤1. 选取一份新的验证集,并进行规则化.
步骤2. 将约简规则与验证集进行比较,依次求出规则强度和规则置信度(Confidence).
此时的规则支持度可表示为公式(8).

其中,Confidence(R)是规则置信度,即约简规则与验证集的规则条件匹配且类别标签相同的比率. ω (R)值越大,表示根据该规则推导出的类别标签的可信赖程度越大,在多个规则同时满足匹配条件的情况下选择ω(R)值最高的规则的类别进行匹配,其结果的准确率往往更高. 同时,如果某一新数据项完全匹配出的规则的 ω (R)=0或没有任何规则与之相匹配,则把该数据项归入待定项进入部分匹配阶段.
从以上步骤得知,规则预检验的方法是基于规则支持度 ω (R)而展开的,其也存在一些缺憾. 若选取的支持度过高,则某些有价值的规则模式不能被获取; 反之,过低时会产生很多无实际意义的规则模式,分类系统性能下降. 本文通过实际训练来选取合适的特征词数来弥补其缺憾.
3.2 部分匹配
部分匹配的基本过程是逐一减少新数据项的条件属性个数,直到出现一条或多条规则能与之匹配为止.其匹配思路与完全匹配基本相同. 因此,部分匹配的规则支持度 ω (R)可以表示为公式(9).

其中,N为表示新对象的总条件属性个数,Nc表示部分匹配过程中去掉的条件属性个数.
同时,关于对新数据项条件属性的去除次序的确定方法,本文规定,条件属性去除的先后次序与文章之前的属性约简过程中计算的SIG(a,R,D)的升序次序保持一致,即属性重要程度低的属性会在部分匹配的过程中优先被去除.
经过完全匹配和部分匹配之后,如果出现没有与现有规则相匹配的数据项,则将验证集中规则支持度最高的结果赋给该项. 到此为止,规则匹配完全结束.
4 实验结果及分析
为验证该分类器的效果,进行了如下的实验验证.首先,选取合理的训练集是非常必要的. 因为训练集的文本数、类别数及特征项数对于分类器的执行效果都有重大影响[20]. 在此,选取了UCI(University of California Irvine)数据库中的iris和diabetes数据集和Statlog中的australian和heart数据集作为训练样本,在每个数据集中任意选择了3类数据. 同时,考虑到分类器默认情况下假设的样本数是大致均匀分布的,如果一类比其他类数据量大得过分,分类器会把其他类的数据判为大的类别上,从而换取平均误差最小. 为了避免该情况的发生,采取不同的样本比例进行训练的方法.
然后,采用第2节中提到的方法对原始数据进行处理,并把数据样本分别按 1:1:1 和 5:2:3 的比例随机打乱,各生成10份不同的训练集,并记录平均的分类准确率情况,实验结果如表6所示. 改进后的匹配方法在4组数据集上的准确率相比于原方法,分类效果均有不同程度的提升. 同时,改进后的匹配方法在训练集数据较少的情况下仍获得不错的分类效果.
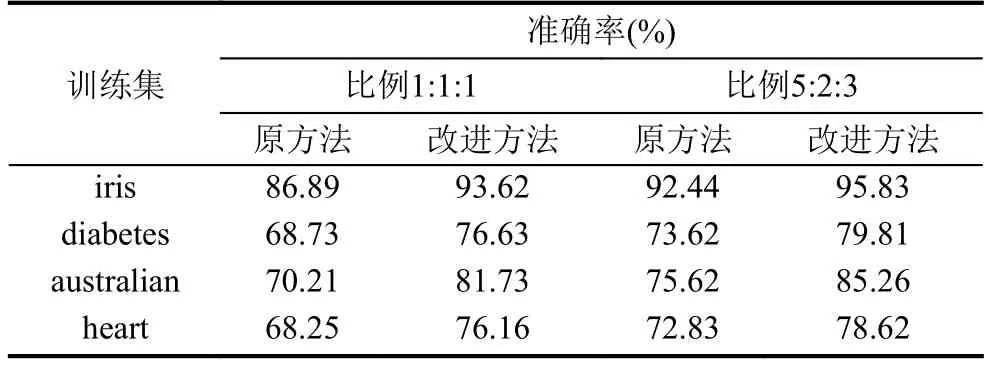
表6 4种训练集的训练结果
表7为特征词数相同而取不同训练样本数量时,2种匹配方法的训练结果,数据集采用UCI的iris数据集. 对表7进行对比分析,可以看出改进后的匹配方法在训练数据取不同数量的情况下,均获得不错的分类效果; 同时,在训练数据小于测试数据的情况下分类效果的提升更加明显. 因此,在对训练数据量有限的数据进行分类的时候,改进后的匹配方法更加实用.

表7 iris训练集的训练结果(特征词数=125)
表8为训练样本数相同,而特征词数不同的情况下,原方法与本文改进后方法的执行结果. 可以看出,并不是特征词数量越多准确率越高. 当训练文本数都取360时,特征词数量较少的情况下,改进方法的分类效果更佳; 特征词数大于125后,两种匹配方法的分类效果相差不大.

表8 特征词数对分类效果的影响(训练文本数=360)
经过训练集的训练后,不仅验证了粗糙集约简的效率,也验证了本文规则提取方法的合理性,同时得到比较好的特征词参数范围.
最后,运用一般数据进行测试,验证其泛化能力等.从网上下载和收集了来自腾讯新闻、凤凰新闻、新浪新闻及网易新闻的新闻报道组成的语料库,从中选用了军事、娱乐、阅读和法制四个类别共600篇文章作为实验语料. 从特征词数量和训练文本数量两个方面对改进前后的匹配方法进行分析,实验结果如表9所示. 由表9可知,当特征词数都取125时,测试文本取不同数量的情况下,改进方法的分类效果均有不同程度的提高; 同时,在测试文本数较少时,改进方法对分类效果的提升更加明显.

表9 训练文本数对分类效果的影响(特征词数=125)
5 结束语
本文把粗糙集理论应用于中文文本分类的规则提取和规则匹配中,并对基于CHI方法的类别特征词选取方法进行了相应的改进,使其更加适用于粗糙集的知识约简. 在训练阶段使用区分矩阵对完整决策规则进行属性约简和规则提取,并通过规则预验证的方法对规则支持度进行优化; 同时,通过调整特征词的数量来弥补规则预检验方法所带来的信息损失而影响有效规则提取的问题. 实验结果表明,改进后的规则匹配方法在实际的文本分类中分类准确率更高,同时在一定程度上克服了原匹配方法容易选出条件前件数较多的规则的缺点,也使得匹配出的规则更加简单明了,更具可解释性.
1 Fan W,Bifet A. Mining big data:Current status,and forecast to the future. ACM SIGKDD Explorations Newsletter,2012,14(2):1-5.
2 朱基钗,高亢,刘硕. 互联网络发展状况统计. 党政论坛·干部文摘,2016,(9):19. [doi:10.3969/j.issn.1006-1754.2017.01.016]
3 Shen YD,Eiter T. Evaluating epistemic negation in answerset programming. Artificial Intelligence,2016,237:115-135. [doi:10.1016/j.artint.2016.04.004]
4 吴德,刘三阳,梁锦锦. 多类文本分类算法GS-SVDD. 计算机 科 学,2016,43(8):190-193. [doi:10.11896/j.issn.1002-137X.2016.08.038]
5 程学旗,兰艳艳. 网络大数据的文本内容分析. 大数据,2015,(3):62-71.
6 朱敏玲. 属性序下的粗糙集与KNN相结合的英文文本分类研究. 黑龙江大学自然科学学报,2015,32(3):404-408.
7 Mitra S,Pal SK,Mitra P. Data mining in soft computing framework:A survey. IEEE Transactions on Neural Networks,2002,13(1):3-14. [doi:10.1109/72.977258]
8 Miao DQ,Duan QG,Zhang HY,et al. Rough set based hybrid algorithm for text classification. Expert Systems with Applications,2009,36(5):9168-9174. [doi:10.1016/j.eswa.2008.12.026]
9 Grzymala-Busse WJ. Rough set theory with applications to data mining. In:Negoita M,Reusch B,eds. Real World Applications of Computational Intelligence. Berlin,Heidelberg,Germany:Springer,2005.
10 Pawlak Z,Skowron A. Rudiments of rough sets. Information Sciences,2007,177(1):3-27. [doi:10.1016/j.ins.2006.06.003]
11 朱敏玲. 基于粗糙集与向量机的文本分类算法研究. 北京信息科技大学学报,2015,30(4):31-34.
12 马晓玲,金碧漪,范并思. 中文文本情感倾向分析研究. 情报资料工作,2013,34(1):52-56.
13 李扬,潘泉,杨涛. 基于短文本情感分析的敏感信息识别.西 安 交 通 大 学 学 报,2016,50(9):80-84. [doi:10.7652/xjtuxb201609013]
14 黄章树,叶志龙. 基于改进的CHI统计方法在文本分类中的应用. 计算机系统应用,2016,25(11):136-140.
15 梁海龙. 基于邻域粗糙集的属性约简和样本约减算法研究及在文本分类中的应用[硕士学位论文]. 太原:太原理工大学,2015.
16 杨传健,葛浩,汪志圣. 基于粗糙集的属性约简方法研究综述. 计算机应用研究,2012,29(1):16-20.
17 胡清华,于达仁,谢宗霞. 基于邻域粒化和粗糙逼近的数值属性约简. 软件学报,2008,19(3):640-649.
18 段洁,胡清华,张灵均,等. 基于邻域粗糙集的多标记分类特征选择算法. 计算机研究与发展,2015,52(1):56-65.[doi:10.7544/issn1000-1239.2015.20140544]
19 时希杰,沈睿芳,吴育华. 基于粗糙集的两阶段规则提取算法与有效性度量. 计算机工程,2006,32(3):60-62.
20 李湘东,曹环,黄莉. 文本分类中训练集相关数量指标的影响研究. 计算机应用研究,2014,31(11):3324-3327. [doi:10.3969/j.issn.1001-3695.2014.11.028]
