移动端实时人像分割算法研究
2018-04-24王泽荣
王泽荣
(四川大学计算机学院,成都 610065)
0 引言
图像语义分割的目标是给输入图像的每个像素分配一个类别,从而获得逐像素的稠密分类图。从2007年起,图像语义分割或者场景解析已经成为计算机视觉的重要部分,和其他计算机视觉任务一样,图像语义分割的重大突破在2014年,Long[1]等人首次提出利用全卷积来训练一个端到端的网络。
FCN8结构在Pascal VOC2012数据集上达到了62.2%的平均IOU,相对提高了20%。这个网络结构是语义分割的基础,在这个基础上提出了一些更新更好的网络结构。全卷积网络被用于自然图像的语义分割,用于多模医学图像分析和多光谱卫星图像分割。与AlexNet、VGG、ResNet等深度分类网络非常相似,还有大量的深层网络执行语义分割。
针对图像语义分割的网络结构有FCN、SegNet[2]、U-Net[3]、FC-Densenet[4]、E-Net[5]、RefineNet[6]、PSPNet、Mask-RCNN,还有一些半监督的方法有DecoupledNet和GAN-SS。本文考虑了各种网络模型结构,最后在FCN的基础上提出了一种的简洁的网络结构C-seg⁃net,在 320×240图像上单张的分割时间 2ms(Titan-X)。在模型简化方面,采用了Face++提出的Shuf⁃fleNet网络结构模型,对C-segnet中的两个3×3的卷积操作添加了点组卷积和通道打乱操作,一定程度上减少了网络模型的参数和计算的FLOPS,能够在移动端做实时的肖像分割。
本文实验采用的数据集由Camera360提供命名Cdataset。
1 数据预处理
本次实验室的数据集来源于手机照片服务提供商Camera360,图片数据是手机用户自拍照片,主要是上半身图像。本次实验的groudtruth采用俄罗斯抠图软件fabby制作,包含前景和背景信息,一共10万张训练集,300张验证集,100张测试集。
Cdataset数据集合中的数据如图1所示。
1.1 人像语义分割
本次实验采用语义分割,给输入图像的每一个像素点分配一个类别,本次实验室做的是二分类,前景和背景。前景是人像这种语义信息,背景是非人像的语义信息。本次实验的目的是在移动端做到实时,通过网络模型运算量计算想要在移动端做到实时,在Ti⁃tan-X上的分割速度必须大于125fps,也即是单帧分割时间小于8ms。本次实验的数据集都转换到相同的尺度,长宽分别是320和240。为了避免网络复杂带来的过拟合做了一定的数据增强,这些数据增强手段包括图像旋转、图像翻转、图像伽马滤波,最后增强后的数据一共10万张作为训练数据。
本次实验的平台是Ubuntu,GPU是Titan-X,深度学习框架是Pytorch。
1.2 训练网络
第1小节中介绍了训练本文网络所用的数据集。训练集中包含10万张320×240大小的图像,并通过fabby生成所有训练图像的GroundTruth。一个通过的语义分割网络结构可以看成是一个编码器连接一个解码器,编码器部分可以从一个预训练的分类网络上做迁移学习,例如子ImageNet上面训练好的VGG或者ResNet等。编码器的机制与VGG或者ResNet这些体系结构最大的不同在于解码器的任务是将编码器学习到的语义特征映射到像素空间,从而得到一个稠密的分类。分割任务和分类任务最大的不同在于分割最后要得到的是一个稠密的像素级别的分类,网络的输出是一张heatmap而不是一个vector,如下图2所示。与分类网络最大的不同在于,分割网络里面没有全连接层,只有卷积层在解码阶段做的是一个不断上采样的操作,常用的方法有去卷积和插值。

图1
常用的全卷积网络的Pipeline如图3所示。
如何选择上采样的featuremap,在图片分辨率下采样到什么程度才进行上采样?这是全卷积网络遇到的最大难题。如果上采样的feature map分辨率低那么得到的heatmap会比较粗糙,如果过早地进行上采样那么得到的heatmap包含的语义信息将会比较少。FCN[1]的作者采用了一种如图4所示的融合方式。

图2

图3

图4
将下采样到原图长宽分别是原来的1/32feature map上采样到原图size一样的图用FCN-32表示,同理有FCN-16、FCN-8,将各层的heatmap进行融合得到最后的结果,假设最后的网络输出用h表示h=FCN-32+FCN-16+FCN-8,这样的融合方式一定程度上解决了最后的结果过于粗糙。本文的融合方式不同于FCN,本文的融合方式是每次上采样2倍,然后与上一层的Score-Map融合,从而形成一个金字塔的融合方式。本文最后没有采用ImageNet上预训练好的VGG网络进行Fine-tuning,主要因为(1)VGG网络太深,没法做到实时,虽然一定程度上可以提升IOU。(2)本次实验数据集全是人像,并且主要是上半身,ImageNet提取的语义信息对本次实验的帮助并不大。因此需要设计自己的网络结构,并且把图像都resize到320×240,这样的处理一定程度上减小了数据的方差,使得网络更容易训练,也减少了一次卷积计算所用时间,本文在FCN的基础上设计的精简网络模型参数如表1所示。
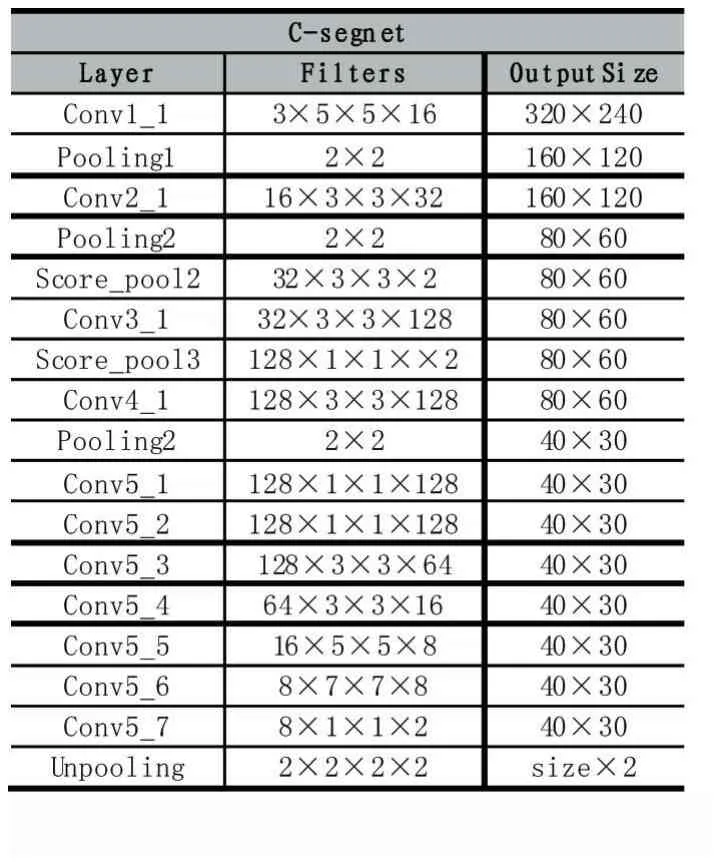
表1
在训练阶段,在conv5_3和conv5_7之后分别添加了dropout操作,一定程度上可以防止过拟合,本次实验的 batchsize是 1,学习率 lr=0.0001。添加了一个shufflenet对比实验,将两个3×3的conv都换成shuf⁃flenet的 bottleneck。
2 结果分析
首先在验证集上选择训练好的网络模型,旋转IOU最好的模型在测试集上测试网络模型的泛化能力,本次实验用到的数据集包括训练集、验证集、和测试集,其中训练集10万张照片,验证集300张,测试集100张。网络性能的好坏通过IOU衡量,其定义如下:IOU=(predict&&target)/(predict||target)。
本次实验的学习曲线如图5所示。

图5
从图5中我们可以看到添加shufflenet之后的网络有了一定的IOU下降,原因在于点组卷积之后网络可训练参数有所减少,网络的表达能力不如之前,在不添加chanel shuffle和点组卷积之前网络的大小为1.2MB,添加之后训练的网络大小为864KB,并且网络计算机的FLOPS比之前少了一些,单帧分割速度有所提升但并不明显。
3 结语
本次实验在FCN的基础上提出了一个精简的网络模型,可以在移动端做到实时的人像分割。并对比实验验证了shufflenet在模型复杂度降低方面的有效性。本次实验依然存在很多的不足:(1)当用户的手移动过快,有fast motion存在的时候分割比较模糊;(2)当背景和前景模式差别不大的时候分割效果不好,并且在头发丝附近的分割还是比较粗糙。针对以上两个问题,是未来研究工作的重点内容。本次实验将移动端的视频分割,当成了单帧的静态图像分割,一定程度上丢失了时间维度上的信息,未来的工作考虑在时间序列上做相关的工作。
参考文献:
[1]Jonathan Long,Evan Shelhamer,Trevor Darrell.The IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2015:3431-3440.
[2]Kendall,Alex;Cipolla,Roberto.SegNet:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.Badrinarayanan,Vijay,2015.
[3]Olaf Ronneberger,Philipp Fischer,Thomas Brox.U-Net:Convolutional Networks for Biomedical Image Segmentation,2015.
[4]Simon Jégou,Michal Drozdzal,David Vazquez,Adriana Romero,Yoshua Bengio.The One Hundred Layers Tiramisu:Fully Convolutional DenseNets for Semantic Segmentation(CVPR),2016.
[5]Adam Paszke,Abhishek Chaurasia,Sangpil Kim,Eugenio Culurciello.ENet:A Deep Neural Network Architecture for Real-Time Semantic Segmentation,2016.
[6]LIN Guo-sheng,Anton Milan,SHEN Chun-hua,Ian Reid.RefineNet:Multi-Path Refinement Networks for High-Resolution Semantic Segmentation,2016.
