特征聚类的混合协同过滤算法研究
2018-04-19杜民双何灵敏
杜民双,何灵敏
(中国计量大学 信息工程学院,浙江 杭州 310018)
推荐算法是目前个性化推荐系统的研究热点问题,在电子商务领域有着广泛应用,其核心思想就是利用数据挖掘技术与人工智能技术来改进传统的协同过滤算法在实际中的应用[1-2].随着信息技术和互联网的发展,人们逐渐从信息匮乏的时代进入到了信息过载的时代.在这样的情况下无论是信息消费者还是信息生产者都遇到了极大的挑战:作为消费者如何从大量的信息中找到自己感兴趣的部分;而作为信息生产者如何使自己的信息脱颖而出,让消费者对自己的信息感兴趣,同样是一件不容易的事情.推荐系统正是为了解决这种问题而产生的.
推荐系统作为一种高效的解决方法,为用户推荐可能感兴趣的项目.协同过滤作为一种应用最广泛的推荐算法之一,它的主要思想是:利用已有用户群过去的行为或意见来预测当前目标用户最可能喜欢哪些东西或对哪些东西感兴趣.Breese等人[2]将协同过滤推荐算法主要分为基于内存和基于模型两大类,这两类协同过滤推荐技术各有特点.基于内存的协同过滤根据相似性对象不同又可以分为基于用户的协同过滤和基于项目的协同过滤.它是协同过滤技术中最成功的算法,它利用整个用户评分数据集来计算用户之间的相似度,寻找与目标用户偏好最相近的N个邻居即Top-N推荐.它的特点是思想简单,有较高的精确度,但是为了得到目标用户的推荐结果,必须扫描整个数据集,这样就会带来数据的可扩展性问题.随着用户和项目都在大量增加,基于内存的协同过滤很不适合在线推荐系统[3-4].而与基于内存的协同过滤不同的是基于模型的协同过滤是利用用户的评分数据集训练出一个模型,利用模型给目标用户进行推荐.基于模型的协同过滤推荐主要有:朴素贝叶斯模型[5]、聚类分析模型[6-8]、图模型[9]、以及基于矩阵分解模型的奇异值分解[10]等.模型推荐算法可以在很短的时间内作出响应,同时缓解了传统的协同过滤数据稀疏性和可扩展性等问题.但是它的缺点是:模型训练时间比较长,且对于数据变动过于敏感,推荐的结果准确性也缺乏很好的解释性等.
为了使推荐系统同时具有更好的扩展性和更好的推荐准确性,本论文提出对首先利用用户的特征运用K-Means算法给用户聚类,然后在聚类的基础上对每个聚类后的聚簇中利用混合协同过滤框架为每个聚簇训练一个模型.从而达到对推荐扩展性和准确性的提高.
1 改进优化
为了解决基于内存的协同过滤面临的可扩展性问题,于是根据用户的特征运用K-Means算法给用户聚类.为了减小用户经过聚类之后带来的推荐精度下降的问题,本论文提出对混合协同过滤框架进行改进.即在聚类之后在每个聚簇中利用基于用户的协同过滤和基于项目的协同过滤进行混合模型的建立.从而提高算法的推荐准确性.本文的算法流程图如图1.

图1 算法流程示意图Figure 1 Algorithm flow diagram
1.1 基于用户特征的K-Means聚类
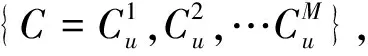
输入:目标用户Ua,最终的聚类个数M
输出:目标用户Ua所在的聚类.
1)从用户的特征数据集中随机地选择M个用户特征向量来作为聚类的质心.
2)计算其余的用户向量距离M个质心的距离,然后把用户加入到距离质心最近的那个簇中.
3)每个用户都已经属于其中的一个簇,根据每个质心所包含的数据向量的集合,重新计算从而得到新的质心.
4)如果新计算得到的质心与原来的质心之间的距离达到每个事先设置好的阈值,算法中止;否则需要迭代步骤2)~4).
1.2 混合协同过滤框架
由于基于模型的推荐算法在一定程度上解决了传统的协同过滤算法面临的可扩展性问题,但随之而来的是推荐精度的下降[5].为了使推荐算法具有两者的优点,于是提出了一种混合协同过滤框架,从而可以有效地提高用户经过K-Means算法聚类之后的推荐精度.这个框架包括两步:第一步中论文的训练集采用5折交叉验证的方式来产生,并分别在训练集上运用基于用户的协同过滤和基于项目的协同过滤算法对训练集进行预测,分别产生基于用户的协同过滤的预测结果和基于项目的协同过滤的预测结果.第二步中训练集是第一步基于用户的协同过滤产生的预测结果与基于项目的协同过滤产生的预测结果,并将分别产生的预测结果进行建模使其与真实值之间的误差越来越小.其中基于用户的协同过滤相似度的计算采用的是改进的Pearson相似度[11],相似度计算公式如下:
(1)
基于项目的协同过滤相似度的计算采用的是修正的余弦相似性的计算公式如下:
sim(u,v)=
(2)
1.2.1第一步
第一步的作用是产生第二步的建模训练数据.定义R表示用户的原始评分矩阵,将整个原始的评分矩阵随机的平均分成五等分,其中第j份用Rj表示,Rj表示除了Rj以外的其他数据.如果Rj被用作训练数据那么相应的Rj就被用作测试数据.FU表示基于用户的协同过滤,FI表示基于项目的协同过滤.用式(1)产生第二步的训练数据.

(3)
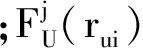
1.2.2第二步
第二步的作用是将第一步产生的训练数据对基于项目的协同过滤和基于用户的协同过滤进行线性融合.融合后的建模模型如下:
F(rui)=θ(1)FU(rui)+θ(2)FI(rui).
(4)
其中F(rui)表示经过线性融合后的预测函数,θ(1)和θ(2)表示基于项目的协同过滤和基于用户的协同过滤所占的预测值的权重.
最终的目标是要求预测值与真实值之间的误差最小,即表示成如式(5)所示的最小值:
f=|F(rui)-rui|.
(5)
因为论文的问题是具有实际意义的,利用线性回归模型融合后,将所有的权重参数约束为非负,所以最终表示成了带有约束条件的二次规划问题.通过拉格朗日乘子和KT条件解答.
2 实验和分析
2.1 数据集
实验数据采用的是MovieLens公开数据集,本文数据集采用MovieLens公开数据集,分别在100 K和1 M两个数量级的数据集上进行实验.其中100 K数据集包含了943个用户对1 682部电影的10万条评分记录.1M数据集包含了6 040个用户对3 900部电影的100万条评分记录.本文用到了历史评分信息和用户特征信息两个数据集.其中用户的特征信息如表1.本论文选取了其中的三个属性并根据专家意见给每个属性表示成数值的形式:age(1~3)、gender(0~1)、occupation(1~8),首先运用基于用户特征的K-Means算法进行聚类,然后随机的把在一个簇中的评分数据分成两份,一份占总评分数据的80%用作训练集,另一份占总评分数据的20%用作测试集.

表1 用户特征信息表
2.2 评价指标
推荐系统多采用准确度来对算法的好坏进行评价[3].准确度是衡量推荐算法预测用户对项目的评分与用户实际对项目的评分的相似程度,通常采用平均绝对误差(MAE)来衡量推荐算法的准确度.MAE是一个简单却鲁棒的用于评估的推荐精度技术,计算的是预测评分与实际评分差的绝对值.MAE越小,则推荐精度也会越高.用户U的平均绝对误差计算如下:
(6)
其中F(rui)代表用户u对项目i的预测得分,rui表示用户u对项目i的实际得分N表示测试集的大小.
2.3 结果仿真分析
为了验证本文所提出算法的有效性,设计了三组对比实验:第一组先用用户特征聚类再用基于用户的协同过滤,第二组先用用户的特征进行聚类再用基于项目的协同过滤,第三组也就是本文提出的先用基于用户特征进行聚类再用混合协同过滤框架的算法进行推荐作对比.Cacheda等人[4]经过实验后得出在MovieLens数据集上聚成8个簇时算法在精确度和扩展性上得到了很好的折中,本文的实验聚簇也是设定为8个.
本文数据集采用MovieLens公开数据集,分别在100 K和1 M两个数量级的数据集上进行实验.仿真结果如图2和图3.
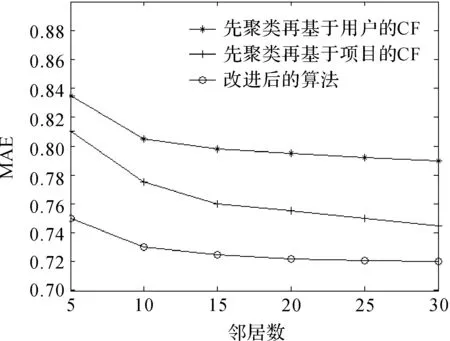
图2 MovieLens 100 K数据集实验图Figure 2 Experiment diagram ofMovieLens 100K data set
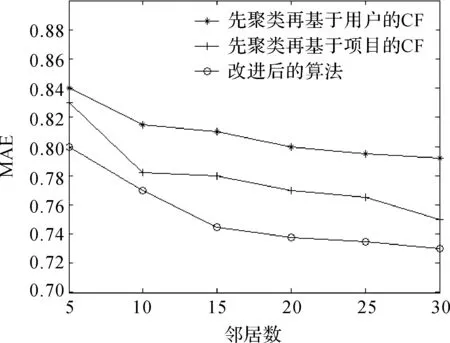
图3 MovieLens 1M数据集实验图Figure 3 Experiment diagram ofMovieLens 1M data set
由图可以看出本论文提出的算法能够提高推荐系统的准确度.同时也验证了在聚类之后基于项目的协同过滤要优于基于用户的协同过滤.
3 结 语
本文所提出的基于用户特征聚类的混合协同过滤推荐算法在一定程度上解决了传统算法面临的可扩展性问题和准确性问题.然而在进行K-Means算法进行聚类时,初始点的选择和聚簇个数的选择对推荐系统效果的好坏也有很大的影响.另一方面,是否对其他更多的数据集具有普适性等问题,将会作为后期工作中继续研究的内容.
【参考文献】
[1]UNGAR L H, FOSTER D P. Clustering methods for colla-borative filtering[C]//ProcofWorkshoponRecommendationSystemsatthe15thNationalConference.onArtificialIntelligence. Menlo Park:AAA I Press, 1998:11-15.
[2]BREESE J S, HECKERMAN D, KADIE C. Empirical analysis of predictive algorithms for collaborative filtering[C]//Procofthe14thConferenceonUncertaintyinArt-ificialIntelligence. Madison:Morgan-Kaufmann, 1998:43-52.
[3]CACHEDA F, CARNEIRO V, FERNANDEZ D, et al. Comparison of collaborative filtering algorithms:limitations of current techniques and proposals for scalable, high-per-formance recommender systems[J].ACMTransactionsontheWeb, 2011, 5(1) :161-171.
[4]SEHGAL M S B, GONDAL I, DOOLEY L. Stacked regression ensemble for cancer class prediction[C]//Procof
IEEEInternationalConferenceonIndustrialInformatics. Perth, WA, Australia:IEEE, 2005:831-835.
[5]LIU H. A new user similarity modelto improve the accuracy of collaborative filtering[J].Knowledge-basedSystem, 2014, 15(2):156-166.
[6]KANIMOZHI M, LOGESHWARI K, SARANYA K, et al. Clustering for collaborative filtering application in Web recommenda-tions[J].InternationalJournalofComputerScience&MobileComputing, 2013,2(4):217-222.
[7]HUANG G Y, LI Y C, GAO J P, et al. Collaborative filtering recommendation algorithm based on user clustering of item attributes[J].ComputerEngineering&Design, 2010,31(5):1038-1041.
[8]XUE G R, LIN C X, YANG Q, et al. Scalable collaborative filtering using cluster-based smoothing[C]//Procofthe28thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval. New York:ACM Press, 2005:114-121.
[9]GAO H J, TANG J L, HU X, et al. Exploring temporal effects for location recommendation on location-based social networks[C]//Procofthe7thACMConferenceonRecommenderSystems. New York:ACM Press, 2013:93-100.
[10]GE S, GE X Y. An SVD-based collaborative filtering approach to alleviate cold-start problems[C]//Procofthe9thInternationalConferenceonFuzzySystemsandKnowledgeDiscovery. Sichuan,China:IEEE, 2012:1474-1477.
[11]卫泽, 周登文. 基于用户的优化协同过滤推荐算法[J]. 计算机与数学工程, 2017,45(4):613-615.
WEI Z, ZHOU D W. Colaborative filtering recommend-ation optimization based on user[J].Computer&DigitalEngineering, 2017,45(4):613-615.
