融合AOBPR和SVD++的排序推荐算法
2018-04-19何灵敏杜民双
何灵敏, 杜民双
(中国计量大学 信息工程学院,浙江 杭州 310018)
推荐系统可在海量数据中为用户推荐对其有用的信息,有效缓解互联网信息过载的问题.在大数据环境下进行推荐是未来推荐系统的大方向[1].传统的推荐算法以用户的历史评分信息为依据,可以将问题转换成为对待推荐的物品进行评分预测,然后基于预测评分进行排序,为用户提供Top-N推荐.将排序学习的思想应用到推荐系统上面是现在比较热门的研究方向.基于排序的推荐算法在没有经过对待推荐物品评分预测过程的情况下,能产生排好序的推荐列表,其核心思想是对每个用户直接产生有序的推荐对象序列,而不是对每个推荐对象预测评分后再排序[2-3].在推荐系统中,常常碰到的一个问题是Top-N推荐,即为用户提供个性化的N个推荐内容.其中,可以挖掘的用户历史信息包括用户对已购买物品的评分,以及用户的浏览记录等.前者是用户显式提供的,而后者是系统日志记录,可能包含用户的隐式偏好,本文分别将其称之为显式反馈和隐式反馈数据.需要注意的是,在排序推荐模型中,一般只考虑隐式反馈数据,将显式反馈数据也作为隐式反馈数据处理.
基于排序的推荐算法在近几年取得了较快的发展.文献[4]提出了一种面向排序的基于贝叶斯概率模型的推荐算法BPR,其关键思想是从用户的隐式反馈数据中推出用户喜好内容的偏序对,然后利用该偏序对来训练一个推荐模型,如协同过滤模型或矩阵分解模型等.文献[5]提出了基于组的贝叶斯个性化排序(Group preference based Bayesian Personal Rankind,GBPR)模型,该模型是在BPR模型基础上考虑了用户的邻居对该用户偏好的影响.文献[6]提出了少即是好协同过滤(Collaborative Less-is-More Filtering,CLiMF)模型,CLiMF模型通过最大化评价指标相关性排序 (Reciprocal Rank,RR) 对推荐对象进行排序.文献[7]提出了xCLiMF模型,xCLiMF模型通过直接优化评价指标ERR来对推荐对象进行排序,是CLiMF模型的扩展版.文献[8]针对BPR收敛速度慢的问题提出了一个改进的AOBPR(Adaptive 0versample Bayesian Personal Ranking)模型,该模型通过对非隐式反馈数据进行非均匀采样来加快收敛速度.
针对AOBPR只能利用隐式反馈数据的问题,本文提出了一种将AOBPR模型与经典的基于矩阵分解的SVD++算法相结合的算法AOBPR_SVD++,该模型既可以利用显式反馈数据又可以利用隐式反馈数据,并可以获得更好的推荐结果.
1 改进
1.1 BPR模型

(1)
式(1)中,集合Ds中每一个元素(u,i,j)都满足i>uj.BPR模型的最优化目标就是:给定任一个推荐模型Θ,对集合Ds中所有的偏序对>u,最大化后验概率p(Θ|>u).
由贝叶斯概率理论可知
p(Θ|>u)∝p(>u|Θ)p(Θ).
(2)
式(2)中有[4]
p(>u|Θ)=∏(u,i,j)∈Dsp(i>uj|Θ). (3)
可定义
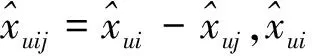
对于推荐模型Θ,可以选择协同过滤模型也可以选择矩阵分解模型,本文是基于矩阵分解[9]模型的.那么有
式(6)中,pu为用户u的特征向量,qi为物品i的特征向量.
1.2 AOBPR模型
BPR模型是一个成对的选出两个物品进行比较的模型,这种选择是一种均匀的采样,模型的训练一般采用的是随机梯度下降法.在实际的数据中,物品通常呈现长尾分布:流行度高的小部分物品经常被选择,而流行度低的大部分物品却少有人问津.这样的分布导致BPR模型在训练过程当中大部分时候都是在做无用功.文献[8]针对BPR收敛速度慢的问题提出了一个改进的AOBPR(Adaptive 0versample Bayesian Personal Ranking)模型,该模型通过对非隐式反馈数据进行非均匀采样来加快收敛速度.AOBPR模型大大改善了BPR模型的收敛速度同时没有降低推荐质量,并且在大量真实数据集上都证明了该模型的有效性.本文在该模型的基础上进行了一些研究,并将传统SVD+ +算法融入该模型以提高推荐质量.
1.3 AOBPR_SVD+ +
SVD+ +算法是一个可以同时利用隐式反馈数据和显式反馈数据的基于矩阵分解的推荐算法[10],在SVD+ +算法中,用户的特征向量表示为
(7)

(8)
本文用SVD++算法来作为AOBPR模型的推荐模型Θ,这样改进后的算法可以同时利用隐式反馈数据和显式反馈数据.在真实的数据集当中通常都是杂糅着隐式反馈数据和显式反馈数据.例如我们在淘宝购物的时候,有的商品我们会明确给予评分(例如五星好评),但是有的商品我们虽然购买但是没有给出明确的评分,有的商品我们有过点击行为.评分是用户对商品喜爱程度的一种显式表达,点击行为则是一种隐式表达.对于融合了以上两种数据类型的数据集可以用本文提出的算法进行处理.这样可以更加全面地利用用户的历史行为信息.显然,隐式反馈数据要比显式反馈数据难处理得多.而AOBPR模型在处理数据的时候一般会将所有的数据都看成是隐式反馈数据,忽略用户的显式评分信息,这显然没有充分利用用户的历史行为信息.
在上文中式(5)的求解过程一般是使用随机梯度下降法.由于本文的改进其中的梯度求解会发生一些变化,下面给出具体的求导公式.我们的最优化目标是
模型Θ参数的梯度如下:
(10)
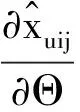

(11)
式(11)中的k为所在向量的分量,θ为模型参数Θ的一个具体值,通过以上的公式可以迭代求出全部的模型参数Θ,由于我们改进的算法可以更多的利用用户的历史行为信息,所以可以得出更加精确的推荐结果.而且本文的算法是在最新提出的AOBPR模型上做的改进因此在模型的训练过程当中也有更好的收敛速度.
2 实 验
2.1 实验环境及数据集
本文所有算法都是在ubuntu系统下基于java代码实现的.反复运行各个算法10次后取平均结果作为该算法的最终运行结果.
本文分别使用用两个数据集对改进后的算法进行试验.
1)Filmtrust数据集:其中包括1 508个用户对2 071部电影进行25 497条评分记录.
2)MovieLens 1M数据集:其中包括6 040个用户对3 900部电影进行了1 000 209条评分记录.
选取不同的数据集进行实验的原因是可以在不同的数据上验证改进的算法的有效性.目前没有公开可以获取的数据集同时包含隐式反馈数据和显式反馈数据,因此,从显式反馈数据中创建隐式反馈数据来进行实验.具体的方法是:从训练数据中,随机选取一定比例(本文取隐式与显式反馈比为2∶1)的评分数据,不关心其具体的评分,将其转换为二值隐式反馈数据.对于训练集和测试集的划分,将候选数据按4∶1划分成两个部分,分别作为训练集和测试集.
2.2 测量指标
基于排序的算法我们需要评估的是一个序列的好坏,是各个个体的相互关系,而不是大部分机器学习算法那样评估的是每个个体的处理好坏.本实验采用在排名问题上非常广泛的评价指标AUC(Area Under the receiver operating characteristic Curve)、标准化折算累加值(Normalized Discounted Cumulative Gain,NDCG)对改进后的算法的准确度进行验证.
AUC是一个概率值,如果AUC的值越大代表当前分类算法越有可能将用户更喜欢的物品排在前面,从而能够更好地分类.NDCG(Normalized Discounted Cumulative Gain)是标准化折算累加值,整体质量越高的列表NDCG值越大.
2.3 实验结果与讨论
本文设计了两组实验,即分别在Filmtrust和MovieLens 1M数据集上将BPR、AOBPR、CLiMF算法和本文提出的改进算法AOBPR_SVD++进行比较.
实验结果如图1~4.

图1 MovieLens 1M数据集AUC实验图Figure 1 AUC achieved from MovieLens 1M data set

图2 MovieLens 1M数据集NDCG实验图Figure 2 NDCG achieved from MovieLens 1M data set
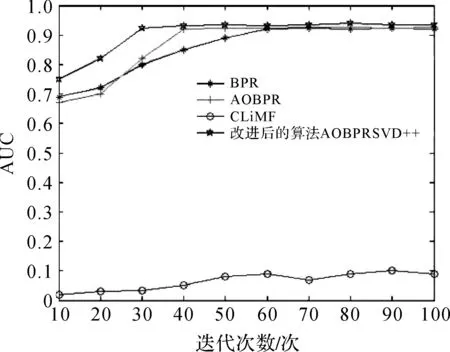
图3 Filmtrust数据集AUC实验图Figure 3 AUC achieved from Filmtrust data set

图4 Filmtrust数据集NDCG实验图Figure 4 NDCG achieved from Filmtrust data set
通过在两个数据集上的实验可以看出:改进后的算法AOBPR_SVD++在两个排序指标AUC、NDCG上相比其他算法都有一定的改进.收敛速度上要比BPR和CLiMF算法更快.
3 结 语
本文提出的AOBPR_SVD++算法能同时利用用户的显式反馈数据和隐式反馈数据,实验结果表明此算法推荐质量与其他算法相比有所提高.在实际的数据中,用户的隐式反馈数据可能要更加复杂,如用户的点击行为、收藏行为、购买行为在评价用户的喜好程度的时候是占有不同权重的,如何利用用户的历史行为信息更好的挖掘用户的兴趣是今后的工作重点.
【参考文献】
[1]朱扬勇, 孙婧. 推荐系统研究进展[J].计算机科学与探索, 2015, 9(5): 513-525.
ZHU Y Y, SUN J .Recommender system:Up to now[J] .JournalofFrontiersofComputerScienceandTechnology,2015, 9(5): 513-525.
[2]黄震华,张佳雯,田春岐,等.基于排序学习的推荐算法研究综述 [J].软件学报,2016, 27 (3):691-713.
HUANG Z H , ZHANG J W , TIAN C Q .Survey on learning-to-rank based recommendation algorithms [J].JournalofSoftware,2016, 27 (3):691-713.
[3]李改.融合显/隐式反馈的协同排序算法[J].计算计应用,2015,35(5):1328-1332,1341.
LI G. Collaborative ranking algorithm by explicit and implicit feedback fusion[J].JournalofComputer, 2015,35(5):1328- 1332,1341.
[4]RENDLE S, FREUDENTHALER C, GANTNER Z, et al. BPR: Bayesian personalized ranking from implicit feedback [C] //Proceedingsofthe25thConferenceonUncertaintyinArtificialIntelligence(UAI09). Arlington, Virginia, USA: AUAI Press, 2009: 452-461.
[5]PAN W, LI C. GBPR: group preference based Bayesian per- sonalized ranking for one-class collaborative filtering[C]//Proceedingsofthe26thInternationalConferenceonKnowledgeDiscoveryandDataMining. New York: ACM,2009: 667-676.
[6]SHI Y,KARATZOGLOU A,BALTRUNAS L,et al.CLiMF:Collaborative Less-is-More Filtering[C]//Proceedingsofthe23rdInternationalConferenceonArtificialIntelligence. New York: ACM,2013: 3077-3081.
[7]SHI Y, KARATZOGLOU A, BALTRUNAS L, et al. xCLiMF: Optimizing expected reciprocal rank for data with multiple levels of rele vance[C]//Proceedingsofthe6thACMConferenceonRecommenderSystems. New York: ACM,2013: 431-434.
[8]RENDLE S,FREUDENTHALER C. Improving pairwise learning for item recommendation from implicit feedback[C]//WebSearchandDataMining.WSDM: ACM,2014: 273-282.
[9]KOREN Y,BEL R,VOLINSKY C.Matrix factorization techniques for recommender systems[J].Computer,2009,42(8): 30-37.
[10]KOREN Y.Factorization meets the neighborhood: a multifaceted collaborative filtering model[C]//Proceedingsofthe14thACMSIGKDDInternationalConferenceonknowledgeDiscoveryandDataMining. New York: ACM,2008: 426-434.
