基于多任务全卷积网络的人流监测系统
2018-04-16彭天亮
韦 蕊 彭天亮
(1.西安培华学院 西安 710125)(2.江西省水信息协同感知与智能处理重点实验室南昌工程学院 南昌 330099)
1 引言
在旅游景点和公共集会等场景中,使用计算机视觉技术通过图像或监控视频流,对场景中人群的数量进行准确而稳健的估计,以防止因过高度拥挤可能导致的挤压、踩踏等事件,对公共安全具有重大意义。
现有的人群统计方法一般可以分为两类:基于检测的方法和基于回归的方法。基于检测的方法通常假定可以通过使用给定的对象检测器[1~3]来检测和定位人群图像上的每个人,然后通过累积每个检测到的人来计数,然而,这些方法[4~6]需要巨大的计算资源而且往往受人为遮挡和复杂的限制背景,在实际情况下,产生的相对较低鲁棒性和准确性。基于回归的方法直接从图像中计算人群的数量。Chan等[7]使用手工特征来将人群统计任务转化为回归问题;文献[8~9]提出了更多人群相关的特征,包括基于结构的特征和局部纹理的特征;Lempitsky等[10]提出了一种基于密度的算法,其通过整合估计的密度图来进行计数。
最近,深层卷积神经网络在人群统计场景中显示了出较好的效果。Wan等[11]直接使用基于CNN的模型来建模图像到人数的映射关系;Zhang等[12]提出了多列CNN来提取多尺度特征;Boominathan等[13]提出了一个多网络的CNN来提高对人的分辨率;这些算法在解决尺度变换造成的分辨率问题的同时,使得网络结构较为复杂,这些网络在训练时,需要预先训练单一网络进行全局优化,且引入了更多参数,需要消耗更多的计算资源,使得难以实际应用。本文基于多任务的全卷积神经网络(MTFCN)来进行人流的监测,一方面通过采用不同尺度类似Inception模块[14]中所用的卷积核来提取尺度相关特征,另一方面通过同时学习密度和数量两个任务来提高数据的利用效率,进而提高网络训练速度,所提方法在ShanghaiTech数据集上达到了较好的效果,并迁移到具体场景中,建立了实时人流监测系统。
2 模型
由于透视失真,人群图像通常由不同尺寸的人像组成,因此很难用相同尺寸的卷积核来建模尺度的变化。文献[15]中提出了一个初始模块来处理各种尺度的视觉信息,并汇总到下个阶段。本文采用不同尺度的卷积核和1×1的卷积核相结合使用的方法,来提取多尺度特征,并采用全卷积网络来学习原始图像的密度图,同时采用一个较小的多层网络对人群数量进行回归,通过这种将两个任务一起学习的结构来实现对高密度人流的估计。
2.1 多任务全卷积网络体系结构
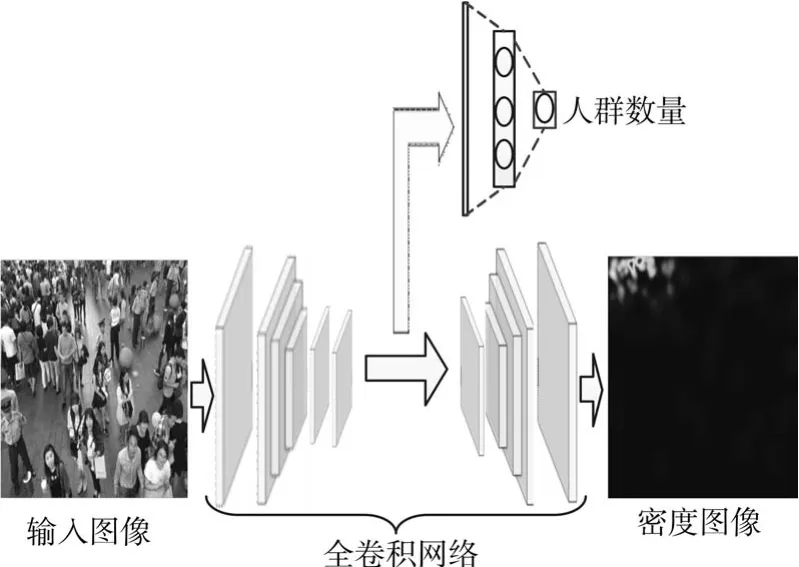
图1 多任务全卷积神经网络结构
多任务全卷积神经网络(MTFCN)的结构如图1所示,包括特征映射、多尺度特征提取、密度估计和人群数量估计。第一个卷积层采用单一尺寸的卷积核来提取底层特征,接着采用一种Inception模块(如图2所示)来提取多尺度融合的特征,其由多个不同尺寸(包括1×1,5×5和3×3)的卷积核组成,至此提取的特征作为后续多任务的共享特征。对于密度估计采用全卷积网络中和卷积操作对偶的反卷积操作实现,并采用多层感知机结构来对人群数量进行回归,由于密度图中的像素取值总为正值,所以非线性激活函数采用ReLU函数[16]实现,以增强对密度图的估计精度。
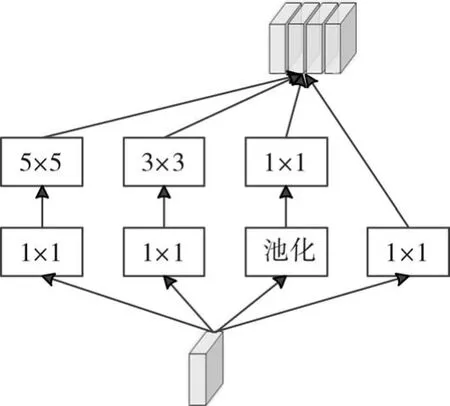
图2 多尺度特征提取
2.2 损失函数
对于密度估计部分,为了高质量地生成具有尺度相关性的密度图,本文参考Zhang等[12]的由于尺度自适应的核密度估计方法。对于图像中每个人的标注区域,本文采用一个delta函数δ(x-xi)来指示其所在的位置,同时采用一个高斯核Gσ来描述其区域密度分布,因此,最终的概率密度图可以用F(x)=H(x)*Gσ(x)来表示。进一步,考虑到每个人所在的位置只和周围人的位置相关,本文假设可以采用特定对象xi和其周围的7个人之间的平均距离来度量高斯核的方差,进而可用式(1)对密度图进行度量:

其中,M为标记图像中人群个数,通常根据经验可以设置β=0.3。进而可以采用欧式距离作为密度估计的度量函数,如式(2)所示:
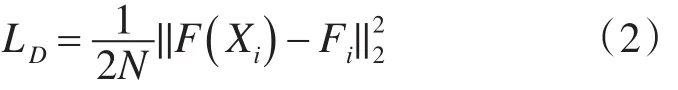
其中,N为训练样本的个数,Xi为第i个样本图像,Fi为和第i个样本对应的真实密度图。
对于人群数量估计,同样采用欧式距离来定义损失函数,具体见式(3):

其中,f(Xi)预测的人群数量,Yi为样本图像中真实的人群数量。
因此,整个网络的损失函数由密度损失函数和人群数量损失函数两部分组成,即:

训练过程采用RMSProp优化算法,其中动量设置为0.9,衰减为0.0005,以加速整个网络的训练。
3 实验
对所提的MTFCN神经网络的评估,本文在标准的ShanghaiTech数据集上进行了测试,实验结果表明,本文所提的方法在精度和鲁棒性方面均有较好的表现,网络的训练采用Caffe框架进行实现[17]。
3.1 评估指标
采用平均绝对误差(MAE)和均方误差(MSE)来评估所提方法的性能,MAE和MSE的计算见式(5)和式(6):
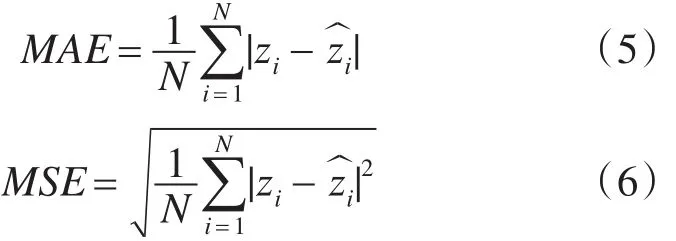
3.2 数据集
ShanghaiTech数据集是一个大规模的人群统计数据集[12],其包含1198幅注释图像,共330,165人。数据集由2部分:A部分包含482幅从互联网上爬取的图像,B部分包含716张街道的图像。在实验时,用800幅图像作为训练集,其余为测试集。
3.3 实验效果
在实验时,本文将所提方法和其他3种方法进行了比较,LBP+RP的方法采用LBP特征来回归人群数量[12],采用多列CNN来估计人群数量(MCNN-CCR)和人群密度(MCNN),表1表明所提方法的有效性,且具有较好的鲁棒性。
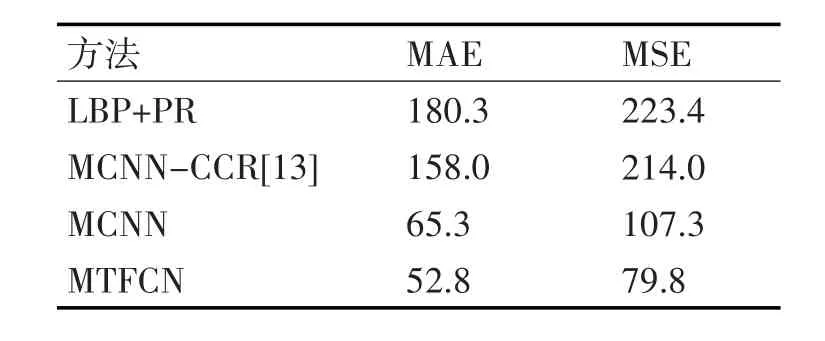
表1
4 基于MTFCN的人流监测系统
基于上述模型及实验效果,本文设计了一种用于实时监测公共场合中人群数量的监测系统,输入为实时视频流,然后对视频中的图像采用MTFCN网络进行人群数量的估计,并进行实时显示,系统效果如图3所示。
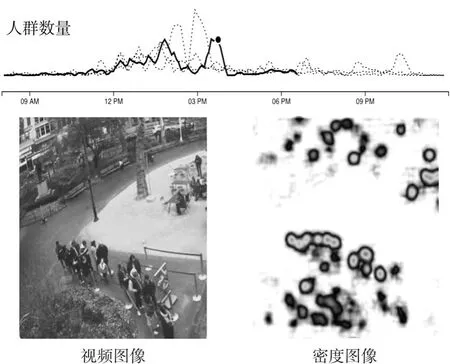
图3 人流监测系统效果
其中,上半部分为实时的人群数量统计情况,下面为视频帧及对应人群密度估计图,监测过程的其他实验效果如图4所示。

图4 监测实验效果
5 结语
本文提出了一个多任务全卷积神经网络(MTFCN)实现对人群数量的统计。和其他基于CNN的方法相比,所提算法采用了多尺度卷积操作以提取多级特征,并结合多任务以提高数据利用率,并可以直接采用端到端的训练的方法。实验表明所提算法可以达到更高的精度和较好的鲁棒性,并通过建立实时的人流监测系统证明了算法的实用性及有效性。
[1]Sheng-Fuu Lin,Jaw-Yeh Chen,Hung-Xin Chao.Estimation of number of people in crowded scenes using perspective transformation[J].IEEETransactions onSystems,Man,and Cybernetics-Part A:Systems and Humans,2001,31(6):645-654.
[2]Navneet Dalal and Bill Triggs.Histograms of oriented gra-dients for human detection[C]//Computer Vision and Pattern Recognition,2005.CVPR 2005.IEEEComputer Society Conference on.IEEE,2005,1:886-893.
[3]Meng Wang,Xiaogang Wang.Automatic adaptation of a generic pedestrian detector to a specific traffic scene[C]//in Computer Vision and Pattern Recognition(CVPR),2011 IEEEConference on.IEEE,2011:3401-3408.
[4]Weina Ge and Robert T Collins.Marked point processes for crowd counting[C]//in Computer Vision andPattern Recognition,2009.CVPR 2009.IEEE Conference on.IEEE,2009:2913-2920.
[5]Haroon Idrees,Khurram Soomro,Mubarak Shah.Detecting humans in dense crowds using locallyconsistent scale prior and global occlusion reasoning[J].IEEE transactions on pattern analysis andmachine intelligence,2015,37(10):1986-1998.
[6]Zhe Lin,Larry SDavis.Shape-based human detection and segmentation via hierarchical part-templatematching[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(4):604-618.
[7]Antoni B Chan,Zhang-Sheng John Liang,Nuno Vasconcelos.Privacy preserving crowd monitoring:Counting people without people models or tracking[C]//in Computer Vision and Pattern Recognition,2008.CVPR 2008.IEEE Conference on.IEEE,2008:1-7.
[8]Antoni B Chan,Nuno Vasconcelos.Bayesian poisson regression for crowd counting[C]//in Computer Vision,009 IEEE 12th International Conference on.IEEE,2009:545-551.
[9]Ke Chen,Chen Change Loy,Shaogang Gong,Tony Xiang.Feature mining for localised crowd counting[J].in BMVC,2012,1:3.
[10]Victor Lempitsky,Andrew Zisserman.Learning to count objects in images[J].in Advances in Neural Information Processing Systems,2010:1324-1332.
[11]Chuan Wang,Hua Zhang,Liang Yang,Si Liu,Xiaochun Cao.Deep people counting in extremely dense crowds[C]//in Proceedings of the 23rd ACM internationalconference on Multimedia.ACM,2015:1299-1302.
[12]Yingying Zhang,Desen Zhou,Siqin Chen,Shenghua Gao,YiMa.Single-image crowd counting viamulti-column convolutionalneural network[C]//in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:589-597.
[13]Lokesh Boominathan,Srinivas SS Kruthiventi,R Venkatesh Babu.Crowdnet:A deep convolutional network for dense crowd counting[C]//in Proceedings of the 2016 ACM on Multimedia Conference.ACM,2016:640-644.
[14]Christian Szegedy,Wei Liu,Yangqing Jia,Pierre Sermanet,Scott Reed,Dragomir Anguelov,Dumitru Erhan,Vincent Vanhoucke,Andrew Rabinovich.Going deeper with convolutions[C]//in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:1-9.
[15]Min Lin,Qiang Chen,Shuicheng Yan.Network in network[C]//arXiv preprintarXiv:1312.4400,2013.
[16]Vinod Nair,Geoffrey EHinton.Rectified linear units improve restricted boltzmann machines[C]//in Proceedings of the 27th international conference on machine learning(ICML-10),2010:807-814.
[17]Yangqing Jia,Evan Shelhamer,Jeff Donahue,Sergey Karayev,Jonathan Long,Ross Girshick,Sergio Guadarrama,Trevor Darrell.Caffe:Convolutional architecture for fast feature embedding[C]//in Proceedings of the 22ndACMinternational conference on Multimedia.ACM,2014:675-678.
