大洋调查样品类型自动化匹配的研究与实现❋
2018-04-13刘鸣涛徐建良王小红侯成飞
刘鸣涛, 徐建良, 李 旺, 王小红, 侯成飞
(1.中国海洋大学信息科学与工程学院,山东 青岛 266100; 2.国家海洋局第一海洋研究所,山东 青岛 266061)
位于国家管辖范围以外的国际海域,以其广袤的空间和丰富的资源成为世界各国关注的焦点和争夺的热点。中国自1970年代起就开始了对国际海底区域资源的探索,并与1990年成立了中国大洋矿产资源研究开发协会(简称中国大洋协会)负责组织和管理我国国际海底区域资源的研究开发活动。从1991年中国正式开始了大洋矿产资源研究开发工作(简称“大洋调查”),截止目前共完成了36个航次,调查范围遍及太平洋、大西洋和印度洋,取得了丰富的国际海域水文和海底地形地貌资料,获得了大量生物、微生物和矿产资源样品,完成了矿产资源样品丰度和品级调查等工作[1]。大洋调查属于船基调查方式,利用海洋船舶为平台,搭载各种调查和采样设备,直接或间接的对海洋的物理学、化学、生物学、地质学等海洋状况进行测量、采样分析等处理,并实时或延时对获取的数据进行汇集分析和使用。虽然一些新兴调查手段,如卫星遥感技术,在实时性和同步性上更具优势,但大洋调查仍是我们研究海洋的重要手段,其可获取深海和特定海域详细的现场资料的特点,是其他方法无法取代的[2-4]。
在大洋调查过程中,根据科学家的预先申请样品的情况,一部分采集样品会在现场进行分配。科学家得到样品后,要根据申请时的承诺,对样品进行实验分析以获取相应的数据并提交给相关部门。为了有效的管理样品实验数据,在航次结束后,需要将现场分配的实际情况和样品申请情况进行统计对应,从而为后续的样品数据汇交和分析提供依据。中国大洋样品馆,作为大洋样品及其属性数据的集中保存和管理部门,负责这项重要工作。由于申请样品的用户涉及不同学科,不同领域,不同单位的科学家和相关人员,其在提交样品申请时,对于样品类型的描述存在较大的不确定性,因此大大增加了大洋样品馆工作人员的工作量。如何在不影响样品类型描述的自由度的前提下,通过信息技术手段,实现此项工作的自动化是本文研究的主要目的。
随着信息数据的海量增加,为了实现信息检索、信息集成等需求,基于本体的语义相似度计算方法成为研究的重点方向[5-8],尤其针对生物基因研究领域,取得了很好应用效果[9-10]。本文立足于大洋样品管理领域,经过对样品类型匹配问题的具体分析,提出了一个基于本体的样品类型匹配算法,并成功应用于大洋调查样品现场分配统计过程,实现了现场分配和样品申请数据的自动化对应,提高了中国大洋样品馆管理人员的工作效率。
1 大洋调查样品类型匹配问题分析
1.1 问题分析
在大洋调查的航次结束后,为了后续科学实验数据的汇交和管理,航次现场样品分配的数据需要与样品申请数据进行统计对应,此过程的关键步骤之一是将申请的样品类型和实际分配的样品类型进行匹配。由于在不同航次中负责现场分配的管理员的专业知识水平不同,而申请样品的科学家更是来自不同的单位、不同的学科,拥有不同的学术背景,所以即使针对同一件样品,其在现场分配时的类型描述和申请时的样品类型也可能存在一定的差异,这些差异正是造成目前样品匹配依赖人工鉴别的主要原因。针对此问题,我们对多个航次实际数据进行了分析,发现造成样品类型匹配困难的情形主要存在如下4种:
(1)样品类型命名规范不统一,例如海水样品在不同的申请中可能命名为水体或水样;
(2)采样方式和样品类型混合,例如插管沉积物申请时命名为沉积物(箱式);
(3)多个样品类型混合,例如申请时将氧化物和硫化物合并为氧化物/硫化物;
(4)申请样品类型和分配样品类型粒度不同,例如申请类型为岩石,分配类型为火成岩。
所以,针对含有以上四种情形的样品类型数据,设计一种算法以完成样品类型的自动对应,是本论文需要解决的主要问题。
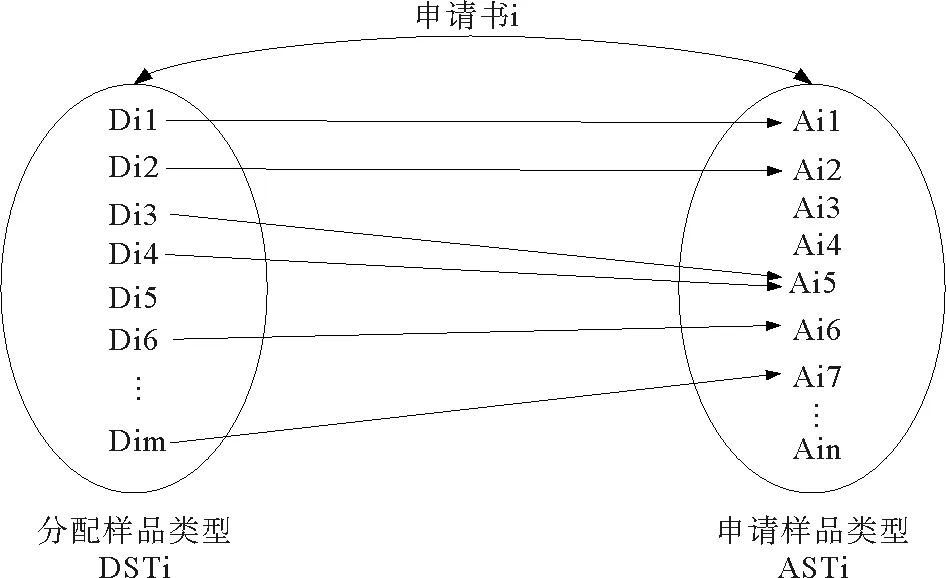
图1 大洋样品类型匹配问题示意图Fig.1 The diagram of marine sample type matching
1.2 问题定义
根据上述分析,我们首先给出大洋调查样品类型匹配问题的定义:
大洋调查样品类型匹配是在两个不同术语集合之间构建语义匹配的过程。如图 1所示,设DSTi(Distributed Sample Type)为申请书对应的分配样品类型的集合,ASTi(Applied Sample Type)为申请书对应的申请样品类型的集合,则我们需要得到满足以下定义的集合Mi。
Mi={(Dij,Aik)|Dij∈DSTi和Aik∈ASTi匹配}
其中:1≤j≤|DSTi|,1≤k≤|ASTi| 。
由于申请样品类型和分配样品类型粒度有所差异,根据领域需求,我们定义Dij和Aik匹配是指Dij和Aik表示相同的样品类型,或者Dij表示的样品类型为Aik的子类型。
2 大洋调查样品类型匹配算法
根据前面的问题分析可知,需要匹配的数据具有以下几个特点,(1)样品类型命名规范不统一;(2)采样方式和样品类型混合;(3)多个样品类型混合;(4)申请样品类型和分配样品类型粒度不同,所以直接在DSTi和ASTi之间,利用术语名称匹配方法的效果并不能满足实际要求。针对于此,我们提出了一个基于本体的样品类型匹配算法,首先将DSTi和ASTi映射到本体中的概念,在此过程中,通过对ASTi中的术语进行分词以解决样品类型和采样方式混合的问题,同时利用本体的同义词关系在一定程度上消解样品类型命名的随意性问题,然后利用本体的Is-a语义关系来计算最终的匹配结果。此方法总体上分为4个步骤,如图 2所示。下面给出此方法的具体设计。

图2 大洋调查样品类型匹配方法步骤示意图
(1)结合领域知识,分析大洋样品类型词汇集合,构建大洋样品类型本体STO(Sample Type Ontology)。
在中国大洋样品馆领域专家的帮助下,对大洋样品类型词汇集合进行了整理,基于Is-a关系构建了大洋样品类型本体。对于本体中的样品类型概念,通过和领域专家沟通和查阅领域资料,尽可能确定出得到公认的名称作为其文本标示。同时,分析了目前已人工完成的多个航次样品分配对应的资料,针对相同的样品类型,提取不同科学家对其的不同描述,并将这些描述以同义词的关系添加在本体中。
(2)将分配样品类型映射到本体相应概念。
由于分配样品类型集合DSTi是由现场样品管理系统维护的标准样品类型,所以DSTi中每个样品类型必然能映射到本体中的一个概念,只需依靠样品类型名称的字符串匹配即可完成,并将映射结果记录在DST_MappedConcept[]数组中。
(3)将申请样品类型映射到与本体相应概念。
由于ASTi中的术语存在多个样品类型混合的情况,例如申请时将沉积物和岩石两类样品写在一起为“沉积物/岩石”,所以,我们首先需要调用Segmentation方法基于本体提供的词汇集合对ASTi中每个成员进行分词。对于分词后结果集合的成员t,再使用FindMappedConcept函数遍历本体来查找其对应的本体概念。这样ASTi中的一条术语就有可能对应本体中的多个概念,故使用AST_MappedConcept[][]二维数组来记录映射结果。算法伪代码如图 3所示。

图3 ASTMapping算法
其中,在查找分词后的ASTi术语所对应的本体概念的过程中,使用了本体中的同义词关系来协助概念名称的字符串匹配,即如果某术语与本体中某概念的同义词匹配成功,则认为此术语与此概念成功对应。例如“沉积物/矿物样”在分词后成为两条术语“沉积物”和“矿物样”,在本体中并不存在“矿物样”样品类型,但是“矿物样”可以匹配到岩石样品类型的同义词,那么“矿物样”也将对应于本体中的岩石类型。
(4)计算匹配结果并输出。
经过前面3个步骤,将分别得到DSTi及ASTi术语所对应的本体中的概念,这样,只需根据本体中概念之间的语义距离即可计算出DSTi和ASTi的匹配结果Mi。本文主要利用Is-a关系来计算本体概念间的语义距离,将Is-a关系看作为有向边,概念看作为节点,则本体等效为一个有向无环图,将两个概念间的语义距离定义为其对应节点在图中的最短路径上所有边的权值总和。设C1,C2为本体中的两个概念,则其之间的语义距离定义为:
其中:n为概念C1,C2对应图中节点之间最短路径的边的个数;weighti为此最短路径上第i条边的权值。针对本文的特殊情形,样品类型间的cIs-a关系表示相同的语义,可以认为它们权值相同,即weighti=1。
下面给出一个简单的例子,如图 4所示。在分配样品类型集合中存在术语“火成岩”,申请样品类型集合中存在“矿物样”和“中性岩”,根据名称和同义词关系它们分别和本体中的“火成岩”“岩石”和“中性岩”得到对应,此时需要根据本体结构来计算得到最终匹配结果。虽然概念“火成岩”到“岩石”和“中性岩”的边的个数都为1,但是在计算语义距离时,Is-a关系是被看作有向边的。计算可得,Dist(火成岩,岩石)=1,而Dist(火成岩,中性岩)=∞,所以分配样品类型“火成岩”和申请样品类型的“矿物样”匹配成功。
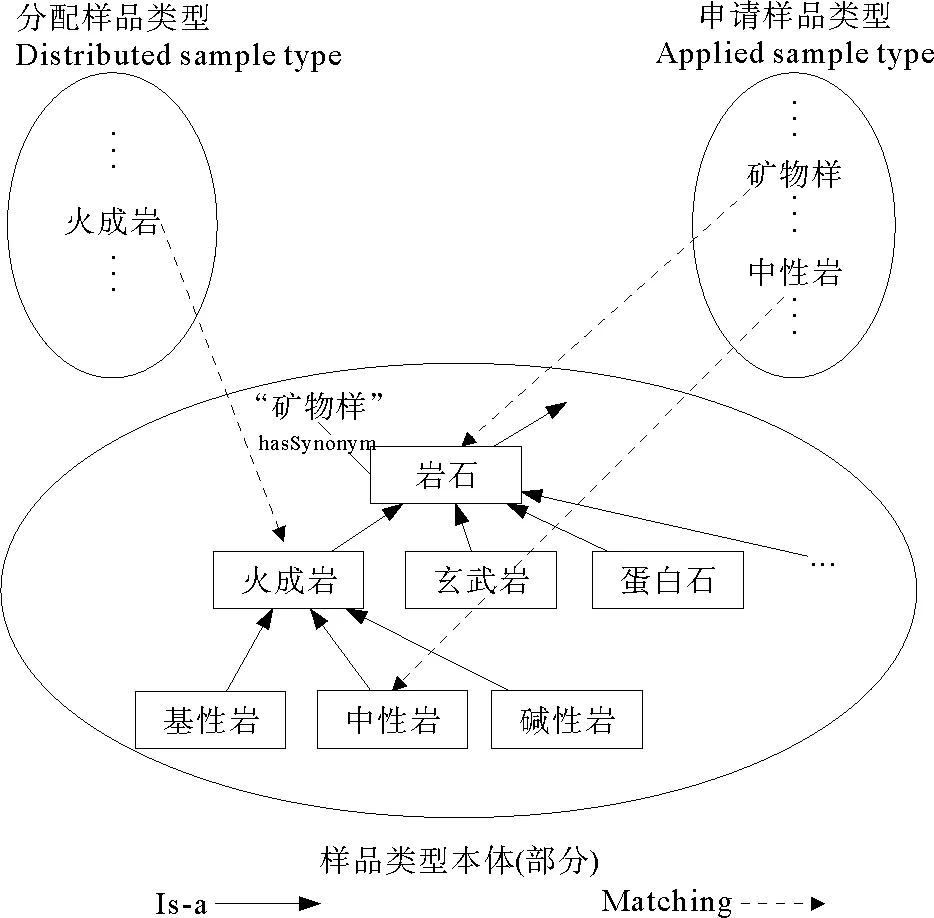
图4 样品类型匹配示例
3 实验测试
为了验证本文方法的有效性,使用C#编程实现了本文算法,并针对大洋4个航次的数据进行了实验测试。实验的硬件和软件环境为,Inter Xeon E5440 2.82GHz处理器、32G内存和Window Server 2008R2 64 bit操作系统。采用准确率P、召回率R和F1-measure值来对实验结果进行评价[11]。准确率P为匹配结果中正确的数量和发现匹配的总数的比值,召回率R定义为匹配结果中正确的数量与实际正确匹配数量的比值,F1-measure值为匹配结果的综合评价,其定义如下:
针对实验数据,使用完全依靠术语名称匹配的算法以及未对术语进行分词的情况作为对比,以验证本文算法的有效性。3种方法在实验数据上得到的结果见表1。
从实验结果可以看出,基于术语名称的匹配由于没有考虑到术语间的Is-a关系和同义词关系,所以获取的正确匹配数量较少,而本文基于本体的匹配算法有效的提高了样品类型匹配的效果。在对申请样品类型未分词的情况下,其准确率达到了0.782 8,召回率为0.694 4。利用本体提供的领域专业术语进行分词后,大大消除了无效文本的影响,其准确率达到了0.936 9,

表1 大洋样品类型数据匹配实验结果
Note:①Algorithm;②No of correct matching(algorithm);③No of matching(algorithm);④No of correct matching(manual);⑤Precision ratio;⑥Recall ratio;⑦String-based matching algorithm;⑧Ontology-based matching(before segmentation);⑨Ontology-based matching algorthm(after sgementation)
召回率为0.770 3。为了适应实际使用的要求,获取的匹配应该首先保证准确率,所以在术语和本体概念匹配时算法要求匹配成功的条件必须为字符串完全匹配。而对于不确定的匹配,程序给出提示,由用户人工确定。开发程序的匹配结果界面见图 5,由于大洋数据有一定保密性要求,对申请书编号进行了模糊处理。
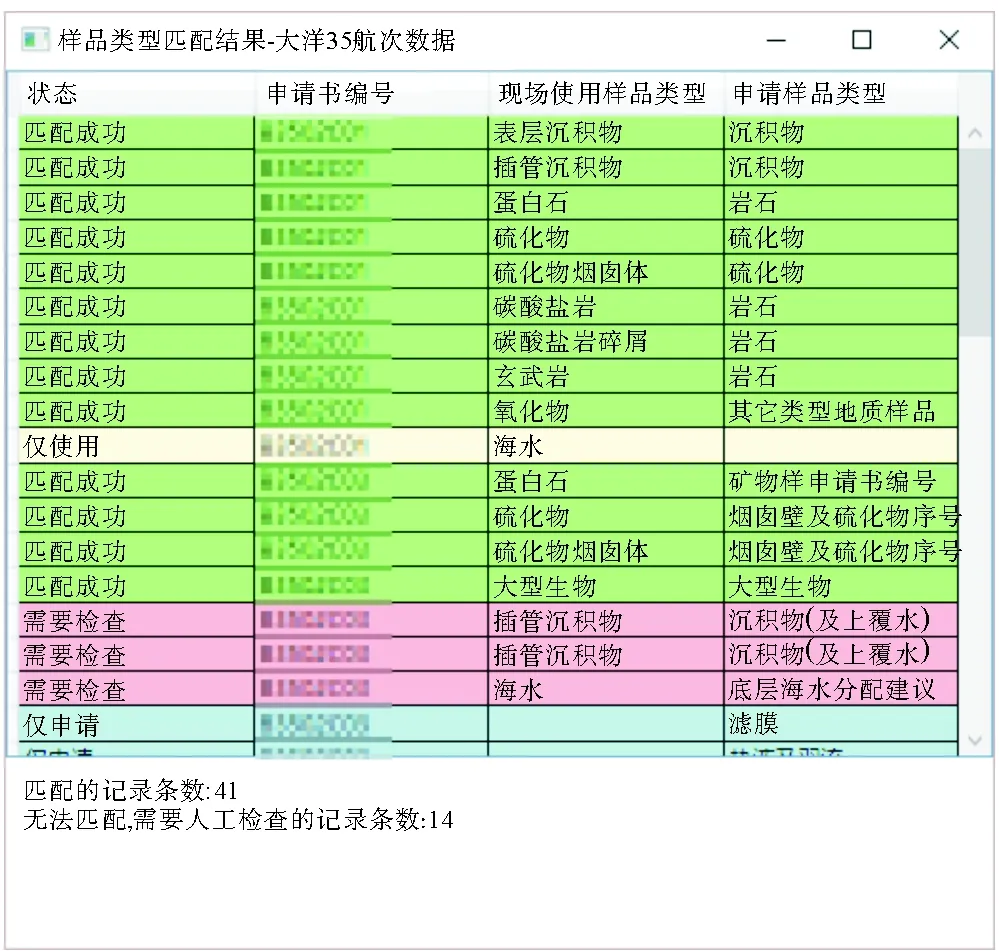
图5 样品类型自动匹配结果输出界面Fig.5 User interface of marine sample type matching results
4 结语
针对大洋调查过程中,现场使用样品类型与申请样品类型的数据匹配问题,本文提出了基于本体的样品类型匹配算法。实验结果表明,本文方法针对目的问题的情境取得了较好的准确率和F1-measure综合指标。在大洋样品管理过程中,涉及多个科研单位和主体,如何实现彼此之间的数据互操作是实现大洋样品管理信息化的关键问题,而样品类型匹配问题必然会在各种不同的数据交互情况中碰到,故本文工作具有较大的现实意义。
本文算法取得较高F1-measure值在较大程度上是依靠领域本体的支持,其为算法提供了精确的专业分词词典和同义词词典,但本文算法的召回率相对较低。研究如何利用聚类算法和相似度计算方法进行样品类型匹配从而进一步提高匹配效果将是我们下一步的工作。
参考文献:
[1] 石绥祥, 雷波. 中国数字海洋: 理论与实践[M]. 北京: 海洋出版社, 2011: 27-30.
Shi S, Lei B. China Digital Ocean: Theory and Practice[M]. Beijing: Ocean Press, 2011: 27-30.
[2] 刘志杰, 殷汝广, 程永寿, 等. 大洋矿产资源信息管理现状与发展设想[J]. 海洋开发与管理, 2013(3): 18-22.
Liu Z, Yin R, Cheng Y, et al. Current status and prospect of information management ofoceanic minerial resource [J]. Ocean Development and Management, 2013(3): 18-22.
[3] 屈新岳. 海洋调查工作的发展与现实问题分析及对策[J]. 气象水文海洋仪器, 2011(3): 100-102.
Qu X. Development of marine investigation and countermeasures for realistic problem [J]. Meteorological, Hydrologicaland Marine Instruments, 2011(3): 100-102.
[4] 韩春花, 殷汝广, 石绥祥. 我国大洋资料管理体系建设与运行[J]. 海洋信息, 2012(2): 1-16.
Han C, Yin R, Shi S. Construction and operation of ocean information management system in China[J]. Marine Information, 2012(2): 1-16.
[5] Rodríguez M A, Egenhofer M J. Determining Semantic Similarity among Entity Classes from Different Ontologies[J]. IEEE Transactions on Knowledge and Data Engineering, 2003, 15(2): 442-456.
[6] Pesquita C, Faria D, Falcão A O, et al. Semantic similarity in biomedical ontologies[J]. Plos Computational Biology, 2009, 5(7): e1000443.
[7] 孙铁利, 邢元元, 关煜, 等. 一种新的本体的概念语义相似度计算方法[J]. 中国科技论文, 2015(14): 1700-1703.
Sun T, XingY, GuanY, et al. Novel ontology-based concept semantic similarity measure [J]. China Sciencepaper, 2015(14): 1700-1703.
[8] 翟东海, 崔静静, 聂洪玉, 等. 基于语义相似度的话题关联检测方法[J]. 西南交通大学学报, 2015(3): 517-522.
Zhai D, Cui J, Nie H, et al. Topic Link Detection Method Based on Semantic Similarity[J]. Journal of Southwest Jiaotong University, 2015(3): 517-522.
[9] Taha K. Determining the Semantic Similarities Among Gene Ontology Terms[J]. Biomedical & Health Informatics IEEE Journal of, 2013, 17(3): 512-25.
[10] Peng J, Uygun S, Kim T, et al. Measuring semantic similarities by combining gene ontology annotations and gene co-function networks[J]. Bmc Bioinformatics, 2015, 16(1): 1-14.
[11] John Makhoul, Francis Kubala, Richard Schwartz, et al. Performance Measures For Information Extraction[C]. California: Proceedings of Darpa Broadcast News Workshop, 1999: 249-252.
