基于云计算数据查询的安全索引构建方法*
2018-04-02邢文凯
邢文凯
(1. 郑州大学 西亚斯国际学院, 河南 新郑 451150; 2. 商丘职业技术学院 计算机系,河南 商丘 476100)
云计算具有超强的数据处理能力,并且能够实现大容量数据的有效存储,逐渐受到企业和个人数据管理的青睐.通过云端处理平台,用户能够有效降低本地资源投入,节约日常维护时间成本,并且能够在大数据统计和计算后为决策支持提供帮助[1].与保存于本地相比,用户数据保存于云端更容易出现数据泄露或被破坏的可能[2],所以云计算服务器数据资源的管理和隐私保护显得尤为重要.当前数据拥有者外包数据给云端管理的模式仍处于初级阶段,大部分数据仍由数据拥有者运行维护.
云计算数据量大且内容丰富,用户访频率高,在用户查询读取数据过程中,如何保证用户既能通过云端获取需求信息,又能隐藏其他数据,防止关联数据隐私泄露,是当前云计算数据管理需要亟待解决的问题.文献[3]从云计算数据安全架构方面对云计算与大数据时代下的隐私保护提出了策略;文献[4]从用户属性着手,进行多项授权的安全云端登陆.当前云计算加密方法主要有内容感知加密和格式加密,前者是对关键信息设置加密策略,后者是对整段数据进行加密.两者共同点是均需要采用加密算法完成数据加密,比如椭圆加密,DES密钥生成等,两者差异主要表现在数据加密的范围,前者针对关键数据,后者针对整个数据文本.这些加密手段都将重点放在数据传输及通信过程中,或者在云计算服务器端对数据采取加密保护.本文以数据查询的索引构建作为切入点,将相似子图查询与哈希多关键字索引相结合,旨在提高用户数据检索过程中的数据安全性,在安全索引策略制定过程中,还需考虑云计算数据的查询效率及数据管理的存储成本.
1 云计算数据图状部署
云计算数据类型丰富,数据量大,对应的数据操作方法也呈多样化特点.考虑到图状数据在结构化复杂数据方面的独特优点[5],本文采用图状数据对云计算数据进行部署,对图状数据进行操作和处理来挖掘云计算数据的关联性,提高数据使用价值,具体查询系统模型如图1所示.
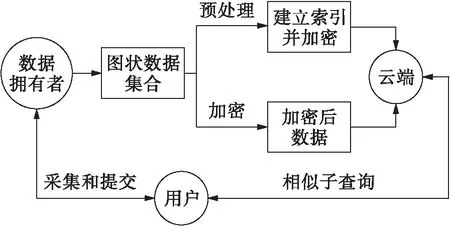
图1 云计算数据查询系统模型Fig.1 Model for data query system in cloud computing
在数据查询过程中,不论是图状数据本身还是查询关键字及索引,都是云平台需要保护的数据.在用户访问图状数据时,如何保证用户数据不被窃取和替换是研究人员需要重点关注的问题,本文从索引构建方面提高数据的安全性.
图状数据对结构化复杂数据进行部署,在用户访问云平台进行数据查询过程中,提高了用户获取有效数据的效率.云平台需要对庞大的图状数据建立合适的索引结构,利用索引关键字进行相似性计算.图状数据查询过程中,节点之间的关联性与约束节点的可达性是云台数据保护的另一关键点.
本文从相似子查询过程中分析可能出现的数据泄露问题,并在数据建立索引过程中采取策略对这些问题进行规避.
2 安全索引构建
2.1 相似子图查询构造
相似子图查询的定义如下:给定查询图Q和图状数据集合G=(G1,G2,…,Gm),然后在G中找出所有近似包含Q的图状数据[5],具体算法步骤如下:
1) 抽取需要查询数据样本的图状数据特征子结构,对结构进行归一化聚合处理得到FG=(f1,f2,…,fn),然后将图状数据的特征向量表示为gi=(gi,1,gi,2,…,gi,n).特征子结构主要分为两类,频繁子结构和一般子结构,划分标准参考文献[6-7],则图状数据的索引向量可表示为I=(g1,g2,…,gm).
2) 采用图状数据的边向量和被查询量Q进行模拟对比,找出两者差异,然后对图状数据的边向量进行一系列边操作,得到与被查询量Q最接近的图状结构.在模拟对比过程中,由于对图状数据向量进行了放松边操作才能模拟得到与Q最相似的图状结构.放松边操作是在距离计算过程中对Q的边进行添加、删除、修改权值等操作[8],在放松边的操作过程中,必然造成图状数据与被查询向量存在特征结构差.在此将结构差记为dmax,将dmax作为判断查询门限值标准,其值可通过递归函数求解.
3) 计算被查询量Q与图状数据集合G中的结构差异,具体计算为
(1)
式中,i和j取值范围为1≤i≤m,1≤j≤n.当qj≤gi,j时,表示图状数据集合G是包含被查询数据对象Q的,则将两者差异性记为0;当qj>gi,j时,需要计算两者特征子结构的差异,还需要计算整体差异,计算规则为
(2)
当d(Q,Gi)≤dmax时,则表示图像数据集合G包含查询数据对象集合Q,需要通过索引找到用户查询结果.如果用户发现此次查询结果并不全面,可以继续重复上述操作,对图状数据进行边操作,但这种操作必然导致dmax的增大,造成相似误差增大.
以上方法可以满足云计算数据的相似查询,但是对于安全性和隐私保护未采取任何方法规避,下文将对数据查询的隐私保护制定策略.
为了方便描述查询过程的隐私问题,需要对计算机陷门这个概念进行说明.陷门是指在登陆系统时绕过口令检查的登陆操作[9],也可以理解为非授权访问.这种非授权访问对于云端数据泄露有很大影响,而且在数据查询过程中,一旦攻击者对图状数据的特征子结构种类和数量进行破解,那整个图状数据集合就很有可能会被解密,云端数据对于攻击者变得透明.
对于图状数据集合G中的一个图状数据Gi,将其特征向量和随机向量分别用gi和λi表示,然后运用ASM-PH加密得到加密向量EK(gi)和EK(λi),接着计算安全向量,即
EK(ψi)=EK(gi)EK(λi)
(3)
EK(ψi)是特征向量和随机向量的乘积,形成密文数据,则有图状数据加密后的集合为
EK(ψ)={EK(ψ1),EK(ψ2),…,EK(ψm)}
(4)
在陷门处理方面,当云平台检测到登录信息后,将安全和查询向量进行对比,即
EK(α(qj,gi,j))=EK(qj)EK(λi)-EK(ψi)
(5)
然后根据EK(α(qj,gi,j))计算两个图的差异性,防止无授权访问,最后对EK(d(Q,Gi))进行判断计算,其计算表达式为
EK(d(Q,Gi))=EK(dmax)EK(λi)-EK(gi)
(6)
若d(Q,Gi)≥0,表示图状数据集合G包含被查询对象Q;若d(Q,Gi)<0,表示查询对象Q不在图状数据集合G中.
2.2 哈希索引策略
哈希函数作为一种压缩映射,广泛用于数据加密算法中[10-11],本文利用哈希函数将图状数据单个数据集的可达节点进行哈希运算,作为数据索引的第一级.设数据集合K={η,M1,M2,ξ,β},M1、M2和β={β1,β2,…,βt}分别为(n+1)×(n+1)维可逆矩阵和随机数.
将查询的路径标签进行向量转换,向量转换过程中引入随机数[12-13],然后计算查询指示向量,其表达式为
(7)
式中:ξk为k维随机向量;γi,j,k为图状数据向量γi,j的路径标签值.

(8)
将得到的标签集合作为图状数据单集安全检索的第二级检索,即
Hi=(T1,T2,…,TK)
(9)
最后,结合哈希函数构造的一级检索和标签集合的二级检索[14],得到本文所构建的安全索引为
I=(I1,I2,…,Im)
(10)
式中,Ii=(Ki,Hi).
3 实例仿真
本文采用8 GBit内存,64位处理器作为云端服务器,采用Matlab进行实例仿真.为了验证算法的通用性,实例仿真的5组图状数据集合均来自于随机数发生器,为了保证样本的差异性,5组数据集合的数量分别为2 000,4 000,6 000,8 000,10 000.被查询对象数据选择边分别为8,16,20,24,32,频繁子结构(Struct A)和一般子结构(Struct B)作为特征子结构的两个类型[6-7],将不同子结构规模、不同数据样本及不同查询对象情况的性能进行实例仿真.首先,考虑到云计算数据量大的特点,分析了本文安全索引构建方法的存储成本,对5组图状数据集合仿真,其特征数量规模和所占内存情况分别如图2、3所示.
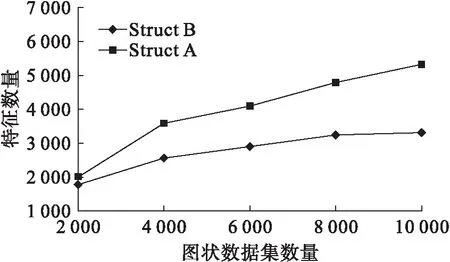
图2 特征对象规模图Fig.2 Scale of query objects
图2是不同数量的图状数据集合进行安全索引带来的特征子结构种类数量的变化情况.从图2中可以看出,Struct A相对于Struct B在相同数量集合的条件下,种类数量更丰富,因此更耗存储成本.随着图状数据集合数量的增加,Struct A的种类缓慢增加,而Struct B的种类数量基本保持稳定,这表明该索引构建方法在大数据量情况下,存储成本开销并不大,而且增长比较慢.
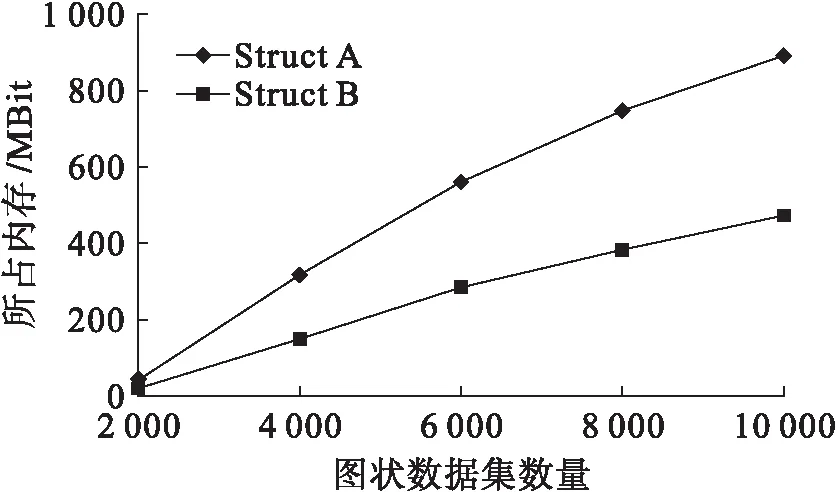
图3 不同规模图状数据集合索引所占内存Fig.3 Memory occupied by index of graphdata set with different scales
由图3可以看出,随着图状数据量的增加,安全索引所占内存呈线性增加,Struct A相比于Struct B增加速度较快.当图状数据量达到10 000个时,Struct A约占用900 MBit的存储空间,Struct B大约需要400 MBit,图状数据量越大,安全索引所占空间也越大,增大趋势明显.
在相似子图查询过程中,对图状数据进行边操作,然后对图状数据与被查询对象进行相似子图比较,判断该图状数据集合中是否包含被查询对象.图4为不同放松边数的相似查询结果,在放松1条边的情况下,不论被查询对象的结构大小,几乎可以得到确切的相似比较匹配答案,表明经过加密和哈希等操作的安全索引并未增加相似匹配的难度和误差.随着放松边数增加,相似误差变大,图状数据集合中与被查询对象匹配的子图呈线性增加.在放松同样边数的情况下,特征子结构结构规模越大,相似匹配得到的结果越多,从这点来看,此方法更适合于模糊查询.
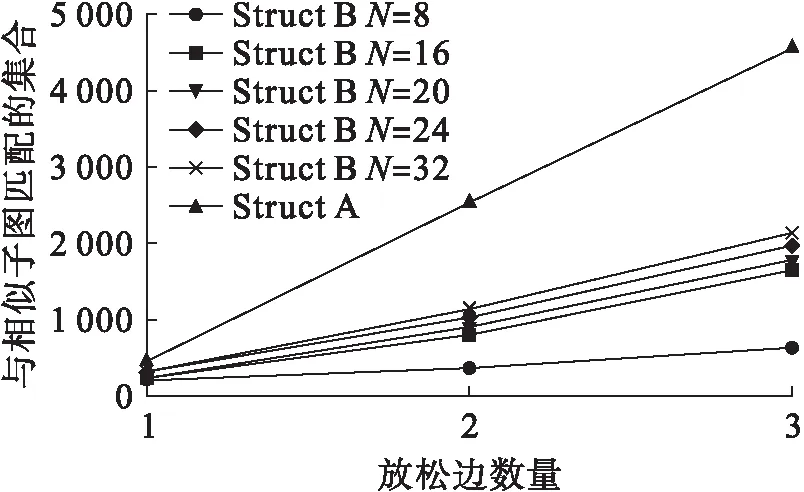
图4 不同放松边数的相似查询结果Fig.4 Similar query results of different relaxation edges
考虑了存储成本和查询效果之后,对时间成本进行仿真.云计算数据量大且访问用户众多,查询效率也是索引构建必须考虑的重要因素,图5的横坐标表示查询对象图结构规模大小,图的规模大小按边数个数来衡量,边分别为8,16,20,24,32,即Q8、Q16、Q20、Q24、Q32.从图5可以看出,Struct B并不随着查询对象规模的扩大增加查询时间,时间成本一直保持在3.2 s左右,而Struct A也保持在6~7 s之间,这表明查询的时间成本并不随着查询对象规模的扩大而增加.
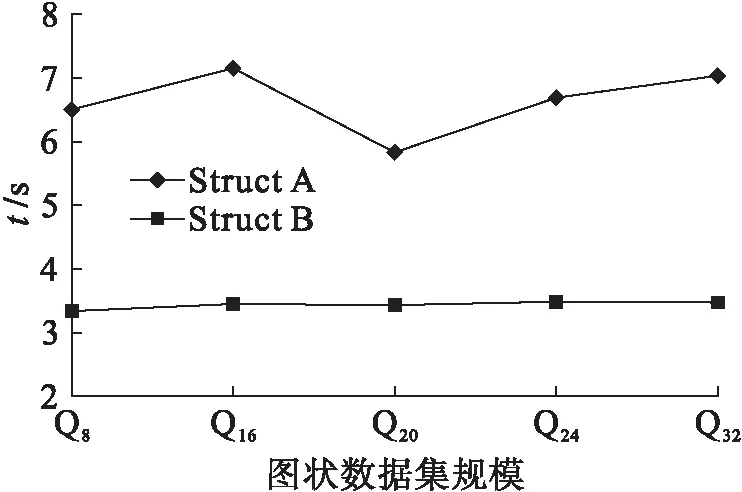
图5 不同规模查询对象的查询时间Fig.5 Query time for query objects with different scales
虽然被查询对象的规模并不影响查询时间,但随着图状数据集合个数的增加,查询时间逐渐增大.图6为不同图状数据集数量下的查询时间,从图6可以看出,不同种类、不同规模的查询对象在不同数量图状数据集合下查询所消耗的时间差别较大.Struct A所耗时间比Struct B高,对于Struct B类查询对象来说,结构规模越大,时间成本越高,但时间成本的增加非常慢,即使图状样本数据加倍,时间也增加非常少.
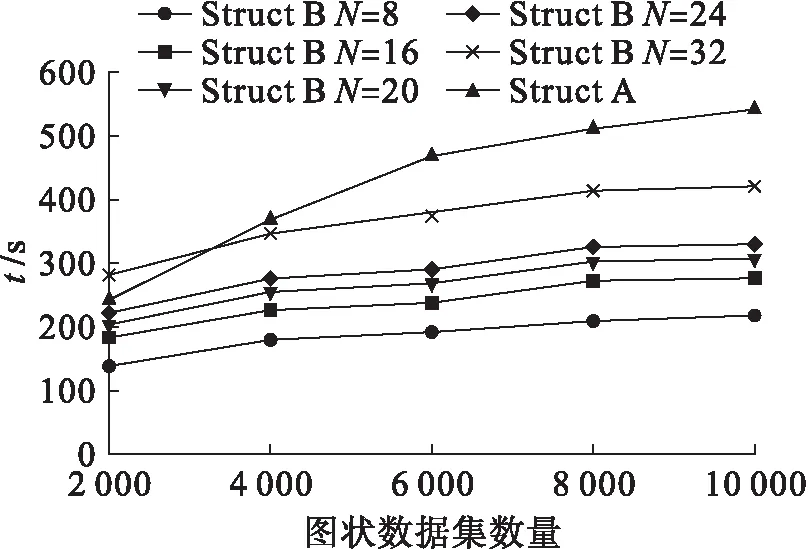
图6 不同图状数据集数量下的查询时间Fig.6 Time-consuming of query objects undergraph data set with different scales
4 结 论
本文利用相似子图查询和哈希函数构建云计算数据安全索引,在构建过程中,通过相似误差判断被查询对象是否在图状数据集合中;在索引构造中,引入ASM-PH加密算法对索引图状数据进行加密.对图状集合数据可达节点进行哈希散列作为一级检索目录,而标签集合作为二级检索目录,以该方法作为云计算数据的索引构建,不论是在时间成本、存储成本及查询准确度方面均有一定的优势,可广泛用于大数据的云端寄存和管理.
[1] 刘艳秋,王浩,张颖,等.大数据背景下物流服务订单分配 [J].沈阳工业大学学报,2016,38(2):190-195.
(LIU Yan-qiu,WANG Hao,ZHANG Ying,et al.Order allocation of logistics service under background of big data [J].Journal of Shenyang University of Technology,2016,38(2):190-195.)
[2] Boru D,Kliazovich D,Granelli F,et al.Energy-efficient data replication in cloud computing datacenters [J].Cluster Computing,2015,18(1):385-402.
[3] 欧萍.数据库索引技术应用[J].电子科技,2011,24(9):146-148.
(OU Ping.Database index technology application[J].Electronic Science and Technology,2011,24(9):146-148.)
[4] Chen Y,Song L,Yang G.Attribute-based access control for multi-authority systems with constant size ciphertext in cloud computing [J].Communications China,2016,13(2):146-162.
[5] 马静,王浩成.基于路径映射的相似子图匹配算法 [J].计算机科学,2012,39(11):137-141.
(MA Jing,WANG Hao-cheng.Similarity subgraph matching algorithm based on path mapping [J].Computer Science,2012,39(11):137-141.)
[7] 张焕生,崔炳德,王政峰,等.基于图的频繁子结构挖掘算法综述 [J].微型机与应用,2009,28(10):5-9.
(ZHANG Huan-sheng,CUI Bing-de,WANG Zheng-feng,et al.A survey of algorithms for mining frequent subgraph structures based on graphs [J].Microcomputer and Applications,2009,28(10):5-9.)
[8] 马茜,谷峪,李芳芳,等.顺序敏感的多源感知数据填补技术 [J].软件学报,2016,27(9):2332-2347.
(MA Qian,GU Yu,LI Fang-fang,et al.Order-sensitive missing value imputation technology for multi-source sensory data [J].Journal of Software,2016,27(9):2332-2347.)
[9] 彭天强,栗芳.基于深度卷积神经网络和二进制哈希学习的图像检索方法 [J].电子与信息学报,2016,38(8):2068-2075.
(PENG Tian-qiang,LI Fang.Image retrieval based on deep convolutional neural networks and binary hashing learning [J].Journal of Electronics and Information Technology,2016,38(8):2068-2075.)
[10]闫建华.格基签密关键技术研究 [D].北京:北京邮电大学,2015.
(YAN Jian-hua.Lattice signcryption key technology research [D].Beijing:Beijing University of Posts and Telecommunications,2015.)
[11]倪剑兵.关键字搜索公钥加密方案的分析与设计 [D].成都:电子科技大学,2014.
(NI Jian-bing.Analysis and design of keyword search public key encryption scheme [D].Chengdu:University of Electronic Science and Technology of China,2014.)
[12]阮林林.基于局部线性嵌入和局部保持投影的图像哈希算法 [D].桂林:广西师范大学,2015.
(RUAN Lin-lin.Image hashing algorithm based on locally linear embedding and locality preserving projections [D].Guilin:Guangxi Normal University,2015.)
[13]余纯武,郭飞,张健.轻量哈希函数HBL [J].计算机工程与应用,2016,52(20):1-4.
(YU Chun-wu,GUO Fei,ZHANG Jian.Lightweight hash function HBL [J].Computer Engineering and Applications,2016,52(20):1-4.)
[14]孙德才,王晓霞.一种基于Bigram二级哈希的中文索引结构[J].电子设计工程,2014(12):1-4.
(SUN De-cai,WANG Xiao-xia.A chinese index structure based on Bigram two level Hash[J].Electronic Design Engineering,2014(12):1-4.)
