融合深度特征表达与似物性采样的目标跟踪算法
2018-03-28孙佳男
孙佳男,孙 俊
(江南大学 物联网工程学院,江苏 无锡 214122)
1 引 言
视频目标跟踪是计算机视觉领域的重要组成部分,其主要任务是获取视频序列中感兴趣目标的位置信息及运动状态,为进一步提取语义信息建立基础.在视频监控,车辆导航,精确制导,无人机等领域有着重要的研究意义和应用价值.在视频目标跟踪过程中,由于光照,尺度变化,目标形变,遮挡,复杂背景等因素的影响,设计一种鲁棒的跟踪算法是一件具有挑战性的工作[1-3].
目标特征表达是目标跟踪中较为重要的部分.传统特征大多是基于人工设计的特征,如histogram of oriented gradient (HOG),scale-invariant feature transform(SIFT)等,在处理不同的问题时,人工特征有一个较为明显的缺陷是设计者需要较多的专业领域知识.随着深度神经网络理论被逐步引入到目标跟踪框架中[4-10],利用神经网络学习目标特征成为突破人工特征局限性的有效途径,深度神经网络能够挖掘出目标的多层表征,而高层级的表征被认为更能够反映目标的语义信息,这是人工特征所不能实现的.Wang等人[6]最早将深度学习技术引入跟踪中,利用无监督特征学习得到的深度去噪自编码器提取目标特征,以表达目标的本质信息,该方法在一定程度下取得了成功,但是在目标部分重叠场景下,跟踪效果不甚理想.Hong等人[7]利用离线训练好的卷积神经网络,获取若干帧目标显著性图构建目标外观模型,并使用相关匹配算法实现目标定位,一定程度上解决了网络误分类引起的跟踪漂移及目标重叠问题.虽然卷积神经网络的池化操作针对目标尺度变化具有一定的鲁棒性,但是由于跟踪过程中变化较复杂,单纯依靠池化操作并不能有效地估计尺寸信息.
本文的算法是基于文献[8]的,与其不同的是:本文利用深度特征进行跟踪的同时,将似物性采样视为另一条独立的跟踪线索,目的是有效处理尺度变化问题,即利用目标检测方法中的似物性采样Edgeboxes算法[11],设计不确定性度量的目标确认机制及模板更新策略,自适应地调节跟踪目标的尺度值,实现跟踪过程中深度特征表示与似物性采样之间的有效信息互补,从而维持对目标的准确跟踪.在数据集OTB[1]上对文中算法进行测试,并与近些年提出的8种跟踪算法进行比较.定性与定量分析显示,本文提出的算法具有更好的跟踪性能.
2 组成模块
2.1 核相关滤波器
本文提出的算法以KCF[12]跟踪算法为基础,KCF算法通过循环偏移将样本矩阵变化成循环矩阵,避免求解逆矩阵,并将解空间转换至傅里叶域,有效降低算法复杂度.
KCF跟踪算法以目标为中心,选取目标及其周围一定范围内的矩形区域图像块x来训练分类器.假设图像区域大小为M×N,训练样本由图像块x循环移位构成,记为xi,对应的标签数据yi用高斯函数表达.在最小均方条件下,线性分类器f(Xi)的目标表达式为一个岭回归:
(1)
其中,w为分类器参数;λ≥0为正则化系数.

(2)
其中,⊙代表点积;F为离散傅里叶变换;F-1为离散傅里叶反变换.转换后,问题求解从寻找最优w变为寻找最优α,设训练样本组成核矩阵Ki,j=κ(xi,xj),则α的解为:
α=(K+λI)-1y
(3)
借助核矩阵的循环性质,式(3)可进一步写成:
(4)

KCF在下一帧中以M×N的窗口来搜索候选图像块z,计算得到响应值为:
(5)
最终,响应值最大的位置即为目标在当前帧中的位置.由于引入了傅里叶变换,式(1)的求解仅需计算点积和模值,大大节省了计算时间,提高了计算效率.除此之外,文献[3]提出将多通道的图像特征融入KCF中,即式(2)修改为:
κ(x,x′)=
(6)
由于引入多通道信息如颜色,HOG等特征,可以更好地描述目标外观模型,进而提高跟踪性能.
因为目标的外观是实时变化的,滤波模板α和外观模型x需要动态更新,更新方法为:
(7)
其中,ρ表示学习参数.
2.2 EdgeBoxes
Edgeboxes[11]作为一种似物性检测算法,通过结构化边缘检测算法计算得到每个像素点作为物体边缘的可信度,统计这些边缘信息并设计物体位置预测函数,对生成的目标框打分,分数代表物体框能够框住一个物体的可能性,分数越高,目标框对目标的定位越准确.
通常,我们可以通过改变位置,大小和长宽比来控制物体框的生成.当按照步长分别改变位置,大小,长宽比三个变量时,定义所产生的相邻两个物体框的重合度(Intersection Over Union,IoU)为β1,即参数β1控制步长.根据文献[11],对于宽为bw、高为bh的物体框b,其打分函数定义为:
(8)
其中,i表示b中的每一个像素点,像素点的平均梯度强度为m,bin代表b中大小为bw/2×bh/2的中间区域,wi∈[0,1]是一个权重值,用来衡量像素值是否完全属于b,wi越大,置信度越高,η是惩罚项,其值设为1.5.
在获得物体框集合B后,进行两个重要的后处理操作:框体微调和非极大值抑制(NMS).非极大值抑制是用来过滤掉冗余物体框,由参数β2控制,当物体框bi和bj的重合度大于阈值β2,且框体bi包含物体的可能性大于bj时,框体bj就会被去除.
3 深度特征表达与似物性采样
3.1 深度特征表达
在目标跟踪问题中,确定目标的位置比获取目标语义更为重要,本文利用低层网络提取目标的外观特征,高层网络获取目标语义,在精确地定位目标位置的同时,有效地处理目标外形变化.
由于池化操作会导致特征图尺寸不一,影响目标分辨率,文中首先使用双线性插值算法改变目标特征图大小,使其为定值,减小长宽比对分辨率的影响:
(9)
其中,h代表原始特征图,x是上采样后的特征图,μ是由相邻特征向量计算得到的插值系数.
由2.1节可知,多通道的相关滤波映射结果可通过公式(5)与公式(6)得到:
(10)
利用不同卷基层反映不同的特征映射,特征映射可以作为相关滤波在不同通道上的输入这一特点.式(10)可写作:
(11)
其中,rl表示在卷基层l上的滤波响应值.在得到滤波响应值集合{rl}后,充分利用网络层级特征,层次化地构造滤波响应表达式Φc:
(12)
其中,ω是一个权重常量,由交叉验证选取.目标最优位置坐标可通过式(13)得到:
(13)
在不同卷积层上做相关滤波处理,加权组合不同层的响应值,求解获得跟踪信息估计值Gc=(pc,hc,wc).
3.2 似物性采样
考虑到跟踪过程中较为难处理的尺度变化问题,受到文献[11]的启发,本文将检测方法中的似物性采样融入目标跟踪框架中.在目标特征表达方面,卷积神经网络学习到的特征优于人工提取的特征,因此,文中选择使用卷积层萃取得到的特征作为似物性采样的输入值.
在低层卷积层上,选取以pt-1为中心点的特征图像块ze.利用EdgeBoxes检测机制在特征图像块ze进行似物性采样,在非极大值抑制处理后,得到一系列按scoreb排序的物体框.根据文献[11]中的结论,当采样数目较小时,EdgeBoxes有着不错的实验效果,所以本文挑选scoreb靠前的200个采样结果,定义为B′.为了进一步筛选集合B′中的采样结果,进行拒绝采样,计算集合B′中元素与Gc检测框之间的IoU值,保留IoU在[θ1,θ2]范围内的采样结果,剔除此范围外的结果,文中θ1=0.55,θ2=0.85.筛选后得到最优目标集合B″,为了计算似物性采样下的跟踪信息Ge,设计一个指标函数Φ去评价集合B″中的元素,将Ge与3.1节得到的跟踪信息Gc进行对比,确定最终的目标中心位置,长与宽.针对集合B″中的物体框,首先将检测框be的大小调整为与KCF中目标搜索框相同,指标函数Φ定义为:
Φ(be)=sum(kxbe·α)
(14)
其中,sum(·)表示矩阵中所有元素的和;核函数kxbe反映目标外观x与物体框be之间的相似度;α通过式(3)得到;此处不需要做傅里叶变换处理.选取Φ(be)中最大值Φmax,它所对应的中心位置为pe,长he和宽we.如果Φmax小于Φc,即似物性采样得到的物体框不能准确反映目标的位置尺度信息,目标信息仍由Gc=(pc,hc,wc)表示.如果Φmax>Φc,则利用下式计算并更新目标信息Gfinal=(p,h,w):
p=pc+γ(pe-pc),(w,h)=(wc,hc)+γ((we,he)-(wc,hc))
(15)
其中,γ作为一个阻尼系数防止位置与尺寸变化过于突然.
4 实验结果
4.1 参数设置
本文实验中的测试视频和实验参数的设置均保持不变,所有的实验基于Matlab2015平台,在CPU为Intel Core I7,显卡Nvidia Titan X,内存容量32GB的PC机上运行.
样本区域设置为初始目标框区域的1.8倍,EdgeBoxes框体微调尺寸为目标区域1.4倍.正则化系数λ为0.001,高斯核的标准差σ取0.1,式(7)中学习参数ρ为0.075.EdgeBoxes窗口重叠率β1为0.65,非极大值抑制系数β2取0.75.采用VGG-19深度卷积网络提取目标特征映射,选取卷基层conv3(4),conv4(4)和conv5(4)计算响应值集合{rl},权重常量ω={1,0.5,0.01},且EdgeBoxes在conv3(4)上计算检测框.式(15)中阻尼系数γ取0.7.
4.2 数据集与评价指标
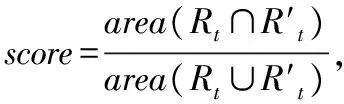
4.3 模块分析
为了评估引入深度特征及似物性采样对跟踪性能的影响,本文选取OTB中28个具有尺度变换特征的跟踪序列,进行分模块的实验.DPCT为融合深度特征提取与似物性采样的跟踪算法,即本文算法;在核相关滤波算法框架下,比较实验按组成模块分为三组:
a)CT为利用深度特征信息但未引入似物性采样的算法;
b)DPT为引入似物性采样但未利用深度特征信息的算法;
c)KCF为原始基准算法.
表1 分模块与DPCT比较
Table 1 Comparisons between DPCT and building blocks

评价指标DPCTCTDPTKCFCLE(像素)16.819.625.939.1DP(%)89.488.074.467.9OP(%)65.260.463.847.9
分析表1,文中的三种算法相对于KCF算法,在CLE,DP,OP等指标值上都有明显的性能提升.以DPT及KCF为例,在KCF基础上,引入以深度特征为基础的似物性采样后,DP提高6.5%,OP增幅达15.9%,CLE从39.1像素减少到25.9像素.同样,比较DPCT与CT,似物性采样的引入同样使DP与OP指标得到提升,CLE值降低,这些都证明了文中引入的似物性检测可以有效地处理尺度变化问题.此外,对比DPCT、DPT发现,利用卷积神经网络得到的深度特征表达,大大地提升了跟踪性能,尤其是DP增加了14.4%,CLE降低了9.1个像素.分模块化的实验结果较好地验证了文中算法的有效性与鲁棒性.
4.4 算法对比
为了评估本文算法的性能,本文在KCF[12]的基础上又选取了近年来出现的7种跟踪算法:CSK[13]、DSST[14]、samf[15]、SCM[16]、Struck[17]、ASLA[18]、MEEM[19],使用文献作者公布的原始代码在相同的实验条件下和本文算法做对比,分别记录平均CLE、DP、OP和每秒处理帧数FPS.表2列出了每种算法的整体跟踪性能,跟踪结果用51段视频跟踪结果的平均值来表示,每个指标最好和次好的结果进行了加粗和下划线处理.
从下页表2可以得到,本文提出的算法(DPCT)在平均CLE、平均DP,平均OP三个指标值上都位列第一.在平均DP及CLE上,本文算法比第二名MEEM分别提升6.9%的准确率和减少6.6像素值.在平均OP上,比第二名samf增加3.4%的准确率.由于文中算法使用了深度卷积网络,该过程需要将卷积核与图像的每个像素进行卷积运算,复杂度为O(n2),该前向特征提取步骤导致算法的平均FPS值并不理想,同时根据统计,针对每一帧进行的似物性采样操作,平均时间花费0.2s.
除此之外,跟踪性能比较还可以通过成功率曲线和距离精度曲线体现,具体结果如图1.图1左侧子图为成功率曲线,数值通过计算每种算法成功率曲线与坐标轴围成的区域面积(Area-under-the-curve,AUC)获得,本文算法成功率为0.622,相比于第二名samf提高了7.4%,同KCF算法相比提高了21%;右侧子图为距离精度曲线,记录了算法对目标中心的定位精度,本文算法排名第一,精确度为0.898,相比于第二名MEEM和基础算法KCF分别提高了8.3%和21.3%.从图1可以看出,本文跟踪算法优于其它算法.
表2 本文算法与其它跟踪算法性能对比图
Table 2 Comparisons between DPCT and other trackers

评价指标本文算法CSKDSSTsamfSCMStruckASLAKCFMEEM平均CLE(像素)14.340.388.834.454.150.659.335.520.9平均DP(%)89.854.574.078.564.965.653.274.082.9平均OP(%)76.644.367.073.261.655.951.162.369.3平均FPS10.226941.757656149.624520.8

图1 不同算法的成功率曲线与距离精度曲线Fig.1 Success plots and distance precision plots of different trackers
4.5 定性分析
图2列出了表2中取得最好效果的5个算法在10段视频序列上的跟踪结果(a)~(j),分别对应 CarScale、David、Shaking、Car4、Trellis、Jogging-1、Jogging-2、Tiger-2、MotorRolling和Soccer,每个视频选取3帧.这些视频序列中包含有尺度变化(a~e,i,j),遮挡(a,b,j,f~h)、光照变化(b~e,h~j)、目标变形(b,f~h)和运动模糊(b,i,j)等影响因素.观察跟踪序列,本文的算法均取得了较好的跟踪效果.依靠深度卷积神经网络和似物性采样后,文中算法不仅能有效地处理尺度变化问题,同时在运动模糊、目标变形等方面均有较强的鲁棒性.

图2 5个跟踪算法在10个视频中的跟踪效果Fig.2 Tracking results of 5 trackers on different challenging image sequences
然而,文中的算法仍存在一些不足,图3中列出了两个跟踪失败的视频序列singer2和Lemming,其中目标真实位置由黑色框体标出,文中算法跟踪位置由框体标出.对于singer2,由于存在较快的平面内外旋转,目标模板更新速度无法满足其外观的快速改变,导致在第15帧就丢失目标.Lemming视频序列属于长时跟踪且存在较大面积的目标遮挡,依旧按照公式(7)得到的目标模板x和滤波系数α会导致目标逐渐被背景替代,当目标再次出现时将无法正确定位.面对这类问题,需要动态的调整公式(7)的学习率或重新设计更新策略来改善跟踪性能.
5 结束语
本文提出一种在核相关滤波跟踪框架下,融合深度卷积神经网络与似物性估计的混合跟踪算法,该算法利用离线训练好的卷积神经网络提取目标特征映射,层次化地构造目标外观模型;同时在提取好的深度特征图上,结合似物性采样Edgeboxes算法,设计了一种不确定度量的目标确认与模板更新策略,实现了对目标中心位置、尺寸信息的进一步精确.在目标跟踪公开数据集上,通过定量与定性的分析本文算法与多种跟踪算法比较的结果表明:本文在处理尺度变化、运动模糊等问题上具有较强的鲁棒性和更好的性能;但是它在处理长时跟踪、面积较大的遮挡问题上效果一般,下一步的研究目标是在有效处理尺度问题的同时,可以兼顾其它跟踪难点.

图3 跟踪丢失情况Fig.3 Losses of the tracking
[1] Wu Yi,Lim J,Yang M.-H.Online object tracking:a benchmark [C].In IEEE Conference on Computer Vision and Pattern Recognition,2013:2411-2418.
[2] Guan Hao,Xue Xiang-yang,An Zhi-yong.Advances on application of deep learning for video object tracking [J].Journal of Automa tica Sinica,2016,42(6):834-847.
[3] Guan Hao,Xue Xiang-yang,An Zhi-yong.Video object tracking via visual prior and context information [J].Journal of Chinese Computer Systems,2016,37(9):2074-2078.
[4] Li Han-xi,Li Yi,Porikli F.DeepTrack:learning discriminative feature representations online for robust visual tracking [J].IEEE Transactions on Image Processing,2016,25(4):1834-1848.
[5] Li Han-xi,Li Yi,Porikli F.Robust online visual tracking with a single convolutional neural network [C].In the Asian Conference on Computer Vision,2015:194-209.
[6] Wang Nai-yan,D-Y.Yeung.Online robust nonnegative dictionary learning for visual tracking [C].In the International Conference on Computer Vision,2013:657-664.
[7] Hong S,You T,Kwak S,et al.Online tracking by learning discriminative saliency map with convolutional neural network [C].In the International Conference on Machine Learning,2015:597-606.
[8] Ma Chao,Huang Jia-bin,Yang Xiao-kang,et al.Hierarchical convolutional features for visual tracking [C].In IEEE Conference on Computer Vision and Pattern Recognition,2015:3074-3082.
[9] Szegedy C,Liu Wei,Jia Yang-qing,et al.Going deeper with convolutions[C].In IEEE Conference on Computer Vision and Pattern Recognition,2015:1-9.
[10] Li Han-xi,Li Yi,Porikli F.Robust online visual tracking with a single convolutional neural network[C].In the Asian Conference on Computer Vision,2015:194-209.
[11] Lawrence Zitnick C.,Piotr Dollár.Edgeboxes:locating object proposals from edges[C].In the European Conference on Computer Vision,2014:391-405.
[12] Henriques J F,Caseiro R,Martins P,et al.High-speed tracking with kernelized correlation filters [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(3):583-596.
[13] Henriques J F,Caseiro R,Martins P,et al.Exploiting the circulant structure of tracking-by-detection with kernels [C].In the European Conference on Computer Vision,2012:702-715.
[14] Danelljan M,Häger G,Khan F S,et al.Accurate scale estimation for robust visual tracking [C].In the British Machine Vision Conference,2014:1-5.
[15] Li Yang,Zhu Jian-kang.A scale adaptive kernel correlation filter tracker with feature integration [C].In the European Conference on Computer Vision,2014:254-265.
[16] Zhong Wei,Lu Hu-chuan,Yang M.-H.Robust object tracking via sparsity-based collaborative model [C].In IEEE Conference on Computer Vision and Pattern Recognition,2012:1838-1845.
[17] Hare S,Saffari A,Torr P.Struck:structured output tracking with kernels[C].In IEEE International Conference on Computer Vision and Pattern Recognition,2013:2411-2418.
[18] Xu Jia,Lu Hu-chuan,Yang M.-H.Visual tracking via adaptive structural local sparse appearance model [C].In IEEE Conference on Computer Vision and Pattern Recognition,2012:1822-1829.
[19] Zhang Jian-ming,Ma Shu-gao,Sclaroff S.MEEM:robust tracking via multiple experts using entropy minimization [C].In the European Conference on Computer Vision,2014:266-278.
附中文参考文献:
[2] 管 皓,薛向阳,安志勇.深度学习在视频目标跟踪中的应用进展与展望[J].自动化学报,2016,42(6):834-847.
[3] 管 皓,薛向阳,安志勇.融合视觉先验与背景信息的视频目标跟踪算法[J].小型微型计算机系统,2016,37(9):2074-2078.
