基于时态密度特征的改进数据流聚类算法
2018-03-28陈羽中郭松荣李国辉林魏超
陈羽中,郭松荣,郭 昆,李国辉,林魏超
1(福州大学 数学与计算机科学学院,福州 350116) 2(福建省网络计算与智能信息处理重点实验室,福州 350116) 3(海西政务大数据应用协同创新中心,福州 350003) 4(空间数据挖掘与信息共享教育部重点实验室,福州 350002)
1 引 言
近年来,随着云计算、物联网的快速发展,以智能传输系统、用电实时采集系统、网络流量监测等为代表的实时数据流应用日益增多.海量数据的实时产生,使面向海量数据流的数据分析与挖掘成为数据挖掘研究的重要内容.随着电网技术的发展,用电信息采集系统智能化电表的出现,用户用电信息采集的频率更加频繁,智能终端接入量不断增加.面对如此巨大的用户量和数据,如何快速有效地进行分析挖掘已经成为建设智能电网的一项重要研究课题[1].
数据流是一种由数据项构成的序列,其具有以下特征:①动态性,数据项随着时间的变化而不断变化;②时效性,数据项的信息表达的是当前时间的状态;③瞬时性,数据流的无限性和连续性使得当前的处理机没办法处理完整的数据流信息,无限的数据流没法全部被物理机保存起来;④无限性,数据项随着时间的推移不断到达,数据量的增长没有限制[2].传统的聚类算法已经无法适应这种新型的海量的数据流环境,海量的数据流对聚类算法提出了新的挑战[3,4]:数据只能访问一次;数据具有时效性,需要能够在有限的时间内对数据进行聚类;数据可能会随着时间的推移而发生变化,需要考虑数据概念漂移的问题;要求具有处理离群点的能力等.因此对于数据流聚类算法的研究已经在学术界和工业界得到了广泛的关注.
目前,数据流聚类算法研究已经取得不少成果, Aggarwal等提出了一个优秀的解决数据流聚类的CluStream算法[5],该算法首次提出了数据流处理的两个阶段,分别是在线微簇聚类和离线的宏簇聚类过程.朱蔚恒等提出了一种基于密度与空间的ACluStream算法,能够进行任意形状的聚类[6],但其在处理不属于已有聚类块的新数据点误差较大.张建朋等利用改进的WAP将新检测到的类的模式合并到聚类模型中,提出一种具有时态特征与近邻传播思想的数据流聚类算法TCAPStream[7],但难以适应海量大数据.邢长征等基于近邻传播思想提出了一种基于近邻传播与密度相融合的进化数据流聚类算法[8].陈晋音等提出了一种面向混合属性数据流的基于密度的聚类算法研究方法[9].孙力娟等提出了一种基于权值衰减的数据流模糊微簇聚类算法[10].Zhang等提出了一种采用模糊聚类算法的数据流聚类算法,其聚类的结果克服硬聚类的缺点,能反应对象与类之间的实际关系[11].
本文提出一种新的数据流聚类算法DACluStream(Dynamic Adjustment CluStream),改进了CluStream聚类框架的在线微簇删除、合并机制,同时对于CluStream不能够增加在线微簇的个数的限制进行修改,可以根据在线微簇的情况进行动态的增加微簇个数.此外,还借助并行实时计算框架Spark Streaming实现DACluStream算法,使其可以适应于海量大数据的实时处理.本文后续章节安排如下:第2节介绍了CluStream算法基本思想、CluStream存在的缺陷以及主流的并行实时计算框架;第3节介绍了本文所提的算法的具体内容;第4节介绍了本文所做的相关实验与结果;最后部分对本文所做的内容进行总结并提出未来的研究方向.
2 基本概念介绍
2.1 CluStream算法基本思想
CluStream算法有两个主要的处理阶段程,分别为在线的微簇聚类和离线宏簇聚类两个部分.其算法的主要包含以下几个内容:
1)初始聚类:当数据量达到一定规模的时候进行初始的在线微簇聚类;
2)在线微簇更新:对于新到达的数据,判断其是否属于已有的微簇.若属于则更新原有的微簇模型,否则作为一个新的微簇点替换掉原有比较早的微簇或合并两个比较近的微簇,进而更新在线的微簇信息,并利用金字塔时间的存储结构存储在线微簇信息.
3)离线宏簇聚类:离线部分主要是使用一个宏簇的聚类过程,对在线聚类得到的微簇进行再次的聚类得到宏簇的聚类,同时根据用户的要求进行聚类结果的分析.
2.2 CluStream算法存在的问题
CluStream提供一个解决数据聚类的框架,但是也存在一些问题.
在线微簇的聚类的结果的好坏会影响到用户离线部分的宏簇聚类.CluStream在线聚类部分设定的微簇的个数q是固定不变的,当有新的微簇形成的时候,如果没有可以删除的微簇,会合并两个最近的微簇,但随着时间的推移,这样会把原来两个最近的不相关的微簇合并在一次,造成较大的误差.如图1所示,微簇1到微簇5的微簇中类别区分度比较明显,如果为了合并而将两个比较近的簇2和4合并的话,将会使合并之后的微簇变得稀疏.
2.3 并行实时计算框架
面对海量的数据,单台处理机已经难以适应,需要将数据分发到更多的处理机进行分布式并行计算.主流的并行数据处理框架有Hadoop[12]和Spark[13]等.而主流的并行实时计算框架有Storm、Spark Streaming等.
Storm通过设计一个用于实时计算的拓扑(topology),整个拓扑由stream,spout和bolt组成[14].Spark Streaming是Spark核心API的一个扩展,其接收实时流的数据,并将输入数据流以时间片(秒级)为单位进行拆分,然后通过Spark Engine处理,每一批的数据都转成Spark中的RDD(Resilient Distributed Datasets,RDD)进行处理[15].
3 改进的数据流聚类算法
针对2.2节所述CluStream算法存在的问题,可以在以下几个方面进行改进:
1)根据在线微簇情况设计一种动态添加微簇个数的方法;
2)为了保持微簇的数量对CluStream的微簇删除机制进行调整,定义时态特征,使用衰减系数对微簇里的数量进行随着时间的推移而衰减.
3)将算法应用到并行实时计算框架中,使其能够处理海量大规模实时数据.
为了更好的描述数据点对在线微簇的贡献程度,提出微簇时态密度特征的概念,基于微簇的时态密度特征提出了新的在线微簇删除、合并和增加机制.
3.1 微簇时态密度特征
数据点对于微簇的聚类的贡献程度随着时间的变化而变化,越早的数据对微簇的贡献程度越低,相反越近的数据对微簇的贡献程度越大[16].
微簇时态密度特征描述的是数据点对微簇的贡献程度,新的数据点到达时,时态权重为1,之后随着时间的推移而进行指数的衰减.若一个微簇一直有新的数据到达,则其时态密度(权重之和)会越来越大,反之其时态密度会逐渐减少.因此时态密度特征能够直观的反映一个微簇随着时间的推移对整体的微簇产生的重要性,如果其一直未能有新的数据到达以更新该微簇信息则可以将该微簇安全的删除掉.
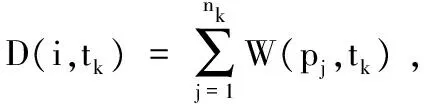
W(pj,tk+1)=2-λ(tk+1-tpj)=2-λ(tk+1-tk+tk-tpj)
2-λ(tk+1-tk)2-λ(tk-tpj)=2-λ(tk+1-tk)W(pj,tk)
(1)
又假设t1时刻新到达的数据量为Δn则有:
(2)
由公式(2)可知,对于任意的微簇i其时态密度由两部分组成,一部分为之前存在的原有的数据的衰减后得到的密度,另一部分为刚到达的该微簇i的新的数据的密度.同时这种增量的计算方式,能够有效的避免每次重新计算所有点的密度,进而有效提高了计算的速度.
3.2 微簇删除、合并与增加
3.2.1 微簇删除
根据定义1可知,微簇时态密度特征,可以表示数据点对微簇的贡献情况.当一个微簇一直未能有新的数据点到达,可见其是一个比较早的微簇,可以将该微簇安全的删除,以防止无限的增加微簇的数量.
定义2.设tk时刻新到达的数据量为Δn,在线微簇的数量为q,删除的阈值为δ,微簇i的时态密度之和为D(i,tk),则D(i,tk)<(Δn*δ/q)时,则可以安全的将微簇删除.
3.2.2 微簇的合并
定义3.设当前在线微簇中,微簇i和微簇u的簇中心的距离最近为dmini,u,微簇i的最大覆盖范围为dic,微簇的u的最大覆盖范围为duc,则当(dic+duc)>dmini,u时可以将微簇i和微簇u进行合并为一个新的微簇e,否则增加一个新的微簇.
3.2.3 微簇的增加
定义3表明两个相对较近的微簇的距离在可控的覆盖范围内是较近的,将两者进行合并并不会使其覆盖范围扩大得比较大,可以解决CluStream中存在的问题.同时为限制在线微簇个数q的无限增长设定一个阈值θ,当在线微簇的数量达到θq时停止微簇的增长.
3.3 算法实现
基于前面的讨论,给出改进的DACluStream算法的主要步骤如下:
3.3.1 初始化微簇聚类(initKmeans)
当数据量达到minInitPoints初始聚类的最小数据量的时候开始进行在线微簇的初始化.
3.3.2 在线微簇更新(updateMicroClusters)
根据已有的在线微簇模型,对新到达的数据流信息进行在线微簇的更新,根据3.2的微簇删除、合并与增加机制对微簇信息进行更新.
3.3.3 离线宏簇聚类(offlineMacroClusters)
在线得到的numQ个微簇,根据用户的需求进行k个宏簇的聚类,并对结果进行分析.
函数1.initKmeans
输入:currentN当前ti时刻到达的数据量,q初始的微簇的数量,minInitPoints初始聚类最小的数据量,minInitPoints为初始聚类最小的数据量
输出:初始聚类得到的模型
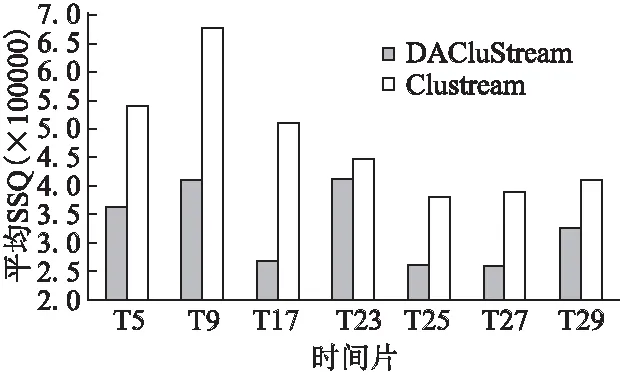
1.IF(sumOfN 2.Wait for data;//等待新的数据的到达 3.sumOfN=sumOfN+currentN;//累加新到达的数据 4.ELSE 5.使用sumOfN所有的数据进行Kmeans模型iter的迭代构建; 6.END IF 函数2.updateMicroClusters 输入:聚类模型,currentRdd当前到达的数据 输出:新的聚类模型 1.计算Rmsd作为微簇的覆盖范围; 2.初始化离群点集合OutList; 3.初始化可以归并的集合AddList; 4.sumOfN+=currentRdd.count; 5.currentRdd.Map( 6.FOR(微簇i <-所有微簇)DO 7.计算数据点Pj到微簇i的簇中心的距离; 8.找到距离最近的微簇d,最近的距离为Distj,d; 9.END FOR 10.IF(Distj,d>=Rmsdd) THEN 11.OutList.add(Pj);//数据点Pj不能归入已有的微簇中; 12.ELSE 13.AddList.add((d,Pj));//数据点Pj可以归入已有的微簇d中; 14.END IF) 15.遍历AddList更新已有的微簇的簇中心; 16.初始化可以安全删除的微簇DeleteList; 17.初始化待合并的微簇MergeList; 18.IF(OutList不为空) THEN 19.FOR(微簇i<- 所有微簇) DO 20. 根据定义2计算微簇i是否可以删除; 21. IF(微簇i可以删除) THEN 22.DeleteList.add(i); 23. ELSEMergeList.add(i); 24. END IF 25.END FOR 26.初始化新的簇的集合newMCList;// 用于存储新的不可归并的数据 27.OutList.map(//将离群点q和新的微簇newMC进行比较,看能否归入到新的微簇中 28.IF(新的微簇为null)THEN 29. IF(DeleteList!= null)THEN 30.将离群点p作为一个新的微簇,并计算其Rmsd; 31.DeleteList.remove(0); 32. ELSE//合并最近的两个微簇 33.将离群点p作为一个新的微簇,并计算其Rmsd; 34.根据定义3判断是否两个微簇可以合并或者增加新的微簇; 35.END IF 36.ELSE 37.FOR(微簇i<- 所有新建的微簇) DO 38. 计算数据离群点p到微簇i的簇中心的距离; 39. 找到距离最近的微簇d,最近的距离为Distp,d;} 40. IF(Distp,d<=Rmsdd) THEN 41. 更新微簇d的微簇信息; 42. ELSE 43. IF(新的微簇为null)THEN 44. IF(DeleteList!= null)THEN 45.将离群点p作为一个新的微簇,并计算其Rmsd; 46.DeleteList.remove(0); 47.ELSE{//合并最近的两个微簇 48. 将离群点p作为一个新的微簇,并计算其Rmsd; 49.根据定义3判断是否两个微簇可以合并或者增加新的微簇; END IF 50. END IF 51. END IF 52. END FOR 53. END IF ) 54.END IF 函数3.offlineMacroClusters 输入:在线得到的numQ个微簇,numPoints用于聚类的数据,k聚类类别的个数 输出:离线聚类得到的模型 1.FOR(微簇i<-numQ个微簇)DO 2.Weighti=Ni/sumOfN;//微簇i的权重,Ni表示微簇i里的数据量的个数 3.END FOR 4.从numQ个微簇中根据其权重有放回的抽取numPoints的数据点作为points,权重越大选中的概率越大; 5.从numQ个微簇中根据其权重无放回的抽取k个数据作为初始种子点seeds,权重越大选中的概率越大; 6.使用points和seeds构建Kmeans的offIters迭代聚类; 7.输出聚类的模型. 函数initKmeans的时间复杂度主要是在微簇的在线Kmeans聚类上,聚类的个数q、数据量的大小minInitPoints和迭代次数iter,其时间复杂度为O(q×minInitPoints×iter). 函数updateMicroClusters因为每个时间片到达的数据量n远大于已有的微簇的个数numQ,所以易知其时间复杂度O(numQ×n). 函数offlineMacroClusters3的时间复杂度在于宏簇的Kmeans聚类上,聚类个数k,数据量大小numPoints,迭代次数offIters,易知其时间复杂度为O(numPoints×k×offIters). 根据前面所述DACluStream算法主要分为在线微簇更新和离线宏簇聚类两个部分,两个部分可以独立分开的.在在线微簇更新部分算法时间复杂度为O(numQ×n),而在离线宏簇部分算法复杂度为O(numPoints×k×offIters). 实验数据主要分为两个部分分别为人工数据集和真实数据集.其中人工数据集为51673条记录规模,具有5个维度的30个类别的服从高斯分布的数据集且生成的数据大小介于[0,1]之间.真实数据集来自于某电力公司提供的某省的部分电力负荷数据达到528628条记录规模,其中包含用户每天24个小时的电力负荷值.实验的硬件环境为9台Ubuntu系统的虚拟机组成的集群,每台虚拟机的配置为:2个核心,16G内存和100G的硬盘大小.软件环境为Ubuntu 版本号,JDK 7.0,Spark 版本号为1.5.2.实验发现minInitPoints取不同值对聚类精度影响很小,因此在实验中统一取minInitPoints=3000,实验的数据流速度设置为3000条/时间片,衰减速度 ,为了保障在线微簇数据的完整性设置删除阈值 ,同时因在线微簇的初始聚类数量(人工数据集q=150,真实数据集q=100)比较大,为限制其变化太多影响聚类效果,设置自动增长的. 对于聚类质量的评估主要使用的是SSQ(sum of square distance),数据点Pj到聚类i的类中心Ci的距离记作 ,计算当前时间批次内到达的所有数据点到其最近的簇中心的距离 的平方和为该时间片的SSQ如公式(3)所示. (3) 其中n为聚类的个数,ni为属于聚类i的数据点个数,SSQ是一种常用的评价K-划分聚类质量的方法,该值越小说明聚类的质量越好[6]. 为了防止实验误差,本文通过多次实验取平均值作为实验结果.实验中都是取20次的实验结果的平均值作为实验结果,人工数据集平均SSQ如表1、图2所示,电力数据集实验结果如下页表2、图3所示. 表1 人工数据集平均SSQTable 1 Average SSQ of artificial data sets 4.3.1 人工数据集上的实验结果 从图2可以发现,在人工数据集上,本文所提的DACluS-tream算法聚类得到的质量相对于CluStream算法聚类得到的质量有显著性的提高,DACluStream的SSQ相对于CluStream的SSQ降低了4倍左右,说明DACluStream聚类得到的结果的各个簇内数据比较紧密,聚类质量高.这是因为算法在在线微簇更新部分,对微簇的删除、合并做了修改,且算法可以动态添加微簇的个数,使各个微簇之间的数据更加紧密,聚类效果更好.且DACluStream算法聚类得到的SSQ的波动性比较小,说明DACluStream算法具有较好的稳定性,当在线微簇数达到一定程度时,所有新到达的数据能够归入到已有的微簇,使其微簇内整体微簇个数达到稳定的时候,稳定性变高. 图2 人工数据集平均SSQFig.2 Average SSQ of artificial data sets 4.3.2 真实数据集上的实验结果 从图3中可以发现,在真实用电数据集上,本文所提的DACluStream算法聚类得到的质量比CluStream算法聚类得到的质量高,随着时间片的推移DACluStream聚类得到的结果都比CluStream聚类得到结果质量高.DACluStream算法能够根据在线微簇的情况动态添加微簇的个数,提出了新的微簇的删除、合并机制,使各个微簇里的数据更加紧密,提高聚类质量. 表2 真实数据集平均SSQTable 2 Average SSQ of real data sets 图3 真实数据集平均SSQFig.3 Average SSQ of real data sets 通过实验可以发现,本文所提的DACluStream聚类算法,能够在在线微簇更新过程中,得到一个更好的微簇,使其在离线宏簇聚类的时候得到一个更好的聚类结果. 面对数据流实时到达的特性,如何有效的对数据进行聚类分析具有重要的意义.CluStream是一个优秀的处理实时聚类框架,但其存在一定的缺陷.本文提出一种改进CluStream的DACluStream聚类算法,使用微簇时态密度之和对微簇的有效性进行描述,算法根据在线微簇的聚类情况进行动态的微簇添加操作,通过实验分析对比,可以发现本文所提的DACluStream能够得到更好的聚类质量.同时通过应用Spark Streaming实现算法的并行化扩展,能够适应于如今海量大数据挖掘的需求.接下来,将进一步在使算法能够处理更多类型的数据流,如非数值型的数据流,同时引入更多的优化策略,进一步提升算法的精度等方面展开研究. [1] Jing Jie-feng,Li Shan-shan.Research and development of real-time data mining system in power network[J].Hebei Electric Power,2007,(S1):33-35. [2] Xu Fei.The research of real-time processing based on big data stream[D].Wuxi:Jiangnan University,2015 . [3] Hassani M,Spaus P,Gaber M M,et al.Density-based projected clustering of data streams[C].International Conference on Scalable Uncertainty Management,Springer Berlin Heidelberg,2012:311-324. [4] Brief A,Holmes G,Pfahringer B.MOA:massive online analysis,a framework for stream classification and clustering[C].JMLR:Workshop and Conference Proceedings,2010,11:44-50. [5] Aggarwal C C,Han J,Wang J,et al.A framework for clustering evolving data streams[C].Proceedings of the 29th International Conference on Very Large Data Bases-Volume 29,VLDB Endowment,2003:81-92. [6] Zhu Wei-heng,Yin Jian,Xie Yi-huang.Arbitrary shape cluster algorithm for clustering data stream[J].Journal of Software,2006,17(3):379-386. [7] Zhang Jian-peng,Chen Fu-cai,Li Shao-mei,et al.Online clustering of evolution data stream based on affinity propagation clustering[J].Pattern Recognition & Artificial Intelligence,2014,27(5):443-451. [8] Xin Chang-zheng,Liu Jian.Evolutionary data stream clustering algorithm based on integration of affinity propagation and density[J].Journal of Computer Applications,2015,35(7):1927-1932. [9] Chen Jin-yin,He Hui-hao,Yang Dong-yong.Density-based heterogeneous data stream clustering algorithm[J].Journal of Chinese Computer Systems,2016,37(1):43-47. [10] Sun Li-juan,Chen Xiao-dong,Han Chong,et al.New fuzzy-clustering algorithm for data stream[J].Journal of Electronics & Information Technology,2015,37(7):1620-1625. [11] Zhang B,Qin S,Wang W,et al.Data stream clustering based on fuzzy c-mean algorithm and entropy theory[J].Signal Processing,2016,126(2):111-116. [12] Xie Gui-lan,Luo Sheng-xian.Study on application of MapReduce model based on Hadoop[J].Microcomputer & Its Applications,2010,29(8):4-7. [13] Karau H,Konwinski A,Wendell P,et al.Learning spark:lightning-fast big data analysis[M]." O′Reilly Media,Inc.",2015. [14] Toshniwal A,Taneja S,Shukla A,et al.Storm@ twitter[C].Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data,ACM,2014:147-156. [15] Liu X,Iftikhar N,Xie X.Survey of real-time processing systems for big data[C].Proceedings of the 18th International Database Engineering & Applications Symposium,ACM,2014:356-361. [16] Yang Ning,Tang Chang-jie,Wang Yue,et al.Clustering algorithm on data stream with skew distribution based on temporal Density[J].Journal of Software,2010,21(5):1031-1041. 附中文参考文献: [1] 景杰峰,李姗姗.电网实时数据挖掘系统的研究与开发[J].河北电力技术,2007,(S1):33-35. [2] 徐 飞.大数据流的实时处理研究[D].无锡:江南大学,2015. [6] 朱蔚恒,印 鉴,谢益煌.基于数据流的任意形状聚类算法[J].软件学报,2006,17(3):379-386. [7] 张建朋,陈福才,李邵梅,等.基于仿射传播的进化数据流在线聚类算法[J].模式识别与人工智能,2014,27(5):443-451. [8] 邢长征,刘 剑.基于近邻传播与密度相融合的进化数据流聚类算法[J].计算机应用,2015,35(7):1927-1932. [9] 陈晋音,何辉豪,杨东勇.一种面向混合属性数据流的基于密度的聚类算法研究[J].小型微型计算机系统,2016,37(1):43-47. [10] 孙力娟,陈小东,韩 崇,等.一种新的数据流模糊聚类方法[J].电子与信息学报,2015,37(7):1620-1625. [12] 谢桂兰,罗省贤.基于Hadoop MapReduce模型的应用研究[J].微型机与应用,2010,29(8):4-7. [16] 杨 宁,唐常杰,王 悦,等.一种基于时态密度的倾斜分布数据流聚类算法[J].软件学报,2010,21(5):1031-1041.3.4 复杂性分析
4 实 验
4.1 实验数据及环境配置
4.2 评价指标
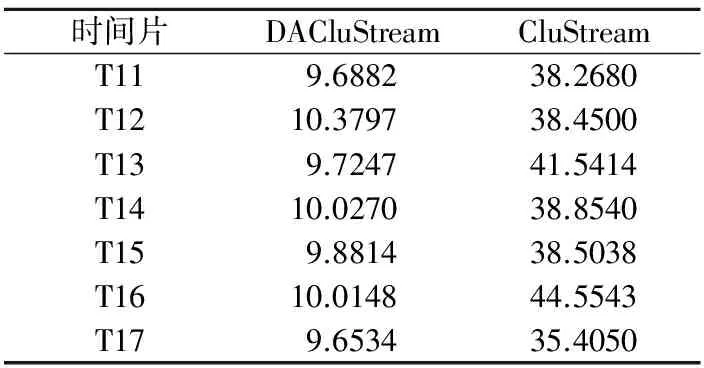
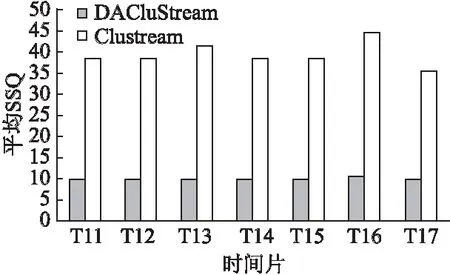
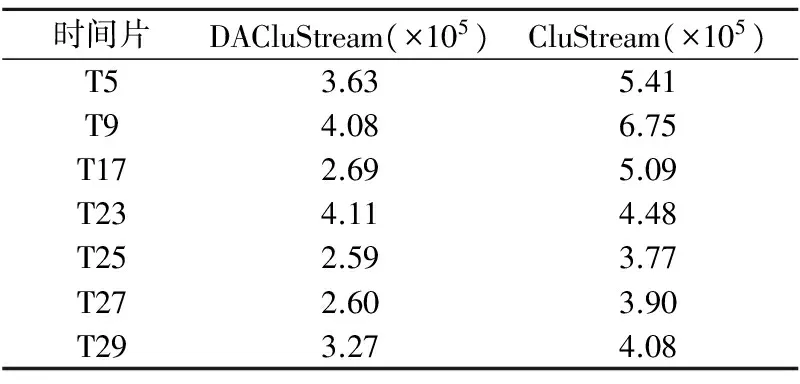
4.3 实验结果与分析
5 结 论
