云计算环境下影响力优化研究与实现
2018-03-28孙红,左腾
孙 红,左 腾
1(上海理工大学,上海 200093) 2(上海现代光学系统重点实验室,上海 200093)
1 引 言
随着互联网的发展,社交作为互联网应用发展的必备要素,不再局限于信息传递,而是与沟通交流、商务交易类应用融合,借助其他应用的用户基础,形成更强大的关系链,从而实现对信息的广泛、快速传播.作为社交网络的一种重要形式,微博(Weibo)有着即时发布、互动性强、简便易用等特点,微博迅速发展为最为主流的社交平台.据CNNIC发布的第39次《中国互联网络发展状况统计报告》数据显示[1],截至 2016 年 12月,微博的使用率为37.1%,与2016 年6月相比略有上涨.
微博作为一种重要的社会平台,在社会、政治、生活等各个方面都成为一种重要的社会舆论载体.每一个微博用户可以通过微博获取实时的新闻资讯,了解朋友及其他名人,社会媒体等等其它一些我们关心的实时动态.如果一则消息在微博里面迅速传播开,有很多人转播,评论,点赞,那么这则微博相关的话题就会上微博头条,从而会有更多的人知道这个话题,从而影响到社会舆论情况.如果某个微博用户有众多的粉丝和关注度,那么他发布的微博消息就会得到广泛的关注,那么该用户就可以影响信息的传播.所以,现在就会有很多人通过购买水军,来提高自己微博信息传播的影响力,然而这些所谓的粉丝是不能够当作正常微博用户来看的,他们会照成谣言和不良信息的的散布,给社会带来不好的影响和舆论恐慌.
本文主要利用海量的新浪微博用户数量来进行相关研究,面对如此庞大的数据量,就必须利用并行化的方式来处理这些数据.数据并行处理(Data Parallel Processing)是指计算机系统能够同时执行两个或者更多个处理机的一种计算方法.并行处理的主要目的是节省大型和复杂问题的解决时间[2].为使用并行处理,首先需要对程序进行并行化处理,也就是说将工作各个部分分配到不同处理机中[3].当前比较常用的大数据分布式计算应用最具有代表性的有:MapReduce,Spark和GraphX.由于MapReduce模型简单、易于理解、易于使用,极大地简化了程序员的开发工作.而且大量数据处理问题,包括很多机器学习和数据挖掘算法,都可以使用MapReduce实现.为了提高计算效率,同时考虑到企业级大量数据中心正在采用云计算环境,云计算越来越普遍,而且开源云计算平台巳经被广泛应用,因此我们采用基于开源云计算平台Hadoop的MapReduce架构进行并行处理,以缩计算时间,提高计算的效率和实时性[4].
2 研究背景
2.1 相关研究
微博最早起源于国外的,所以相关的研究算法也起源于国外学者的研究.因为Twitter作为微博的鼻祖,国外对微博的研究主要集中在对Twitter 的研究.目前有关微博影响力分析算法主要参考Google 的PageRank[5]算法及其改进后的算法[6,7]和HITS[8]算法及其改进后算法[9,10].PageRank算法模型是为了实现网页排名,该算法也是Google使用的搜索结果排名中的重要组成部分.事实上,PageRank模型本质上是用于有向图的节点级的计算技术,因此应用于用户对微博的影响是自然的.借鉴PageRank算法的思想,在文献[11]中提出了TwitterRank算法,该算法主要是衡量一个用户在某一话题内的影响力,主要思想是给定一个话题,用户的影响力定义为他的所有粉丝的影响力之和.但是该算法仅考虑拥有相似话题的用户间相互的影响力,不具有一般性.文献[12]中,对Twitter的传播特性进行了分析,使用粉丝数量和微博转发数量比对研究用户在话题传播过程中的影响,结果发现拥有众多粉丝数量的微博用户所发的微博不一定会得到很多的转发或者评论,他们在微博中的转发和引并不起绝对的影响,这表明用户的粉丝数量和用户的影响力并没有直接关系,但是那些有影响力的用户能够在各种话题中产生显著的影响.在文献[13]里面,Xun Chen等人提出来Personal Rank算法,该算法也可以用于计算微博用户的影响力,但是在计算时还是需要依赖PageRank算法.在文献[14]里面,Jun Zhou等人使用回归模型来预测每个用户的影响力分数分析个人财产及其内容消息,而且他们的研究揭示了个体大多数用户的影响随时间而变化.在文献[15]里,吴渝等通过对不同时间段的数据进行分析提取出意见领袖.在文献[16]里面,Guo-Jun Mao等人对用户的活跃度进行了分析,但是该文章里面只对用户的评论数进行了分析,并没有深入分析也没有剔除“僵尸粉”的干扰.
2.2 计算框架
本文主要用到的是基于Hadoop的MapReduce计算框架,该框架主要是通过简单有力的接口来实现自动化的并行化和大规模分布式计算,结合这个接口的实现在大量普通的PC机上实现高性能计算[17].在Hadoop里面,数据存储的核心是HDFS文件存储系统,HDFS使用Block(存储快)对文件的存储进行操作.在Hadoop中,数据处理核心为MapReduce程序设计模型.MapReduce把数据处理分为两个主要的阶段,即Map阶段和Reduce阶段.MapReduce作业的输入是一系列存储在Hadoop分布式文件系统HDFS上的文件,在Map阶段之前,首先要对数据进行分块处理成split,之后将数据信息交给Map任务去进行读取,然后进行分类写入.一个Map任务的执行过程和数据输入输出的形式如下所示:
Map:data→
Map阶段主要是对输入进行整合,通过用户自己定义Map函数,定义输入格式获取文件信息和类型,并且确定读取方式,最终将读取的Split内容,解析成以键值对
一个Reduce任务的执行过程和数据输入输出的形式如下所示:
Reduce:
Reduce是用来对结果进行后续处理.系统框架自动对Map输出结果进行Shuffle和Sort处理,根据相同的键将其对应的值组合成一个集合

图1 MapReduce流程图Fig.1 MapReduce flow chart
通过接收到的键值对数据对Map获取内容的值进行二次整理和归并排序,最后以
3 MR-UIRank微博用户影响力模型
3.1 PageRank模型
最初的PageRank模型,是Google在搜索引擎结果中对网站排名的核心算法.PageRank通过计算页面链接的数量和质量来确定网站的重要性的粗略估计,PageRank 是基于从许多优质的网页链接过来的网页,必定还是优质网页的回归关系,来判定所有网页的重要性.
为了方便研究,现给出与本文相关的公式定义.
定义1.(PageRank算法)对所有研究的网页给定一个有向图G=

(1)
其中Mpi是所有对Pi网页有出链的网页集合,L(Pi)是网页Pi的出链数目,N是研究网页总数,α代表的是阻尼因子,取值范围是0-1.根据上面的公式,我们可以计算每个网页的PR(下文的所有的PR代表PageRank)值,在不断迭代趋于平稳的时候,即为最终结果.图2显示了运用PageRank算法时,网页Pi与网页Pj之间的关系.

图2 网页Pi和网页Pj的关系Fig.2 Page pi and page pj relationship
在表现网页之间链接关系时,Google使用了矩阵,即下面的定义2.
定义2.(Google初始矩阵)我们可以用一个矩阵来表示这张图的出链入链关系,初始矩阵S=(si,j),其中si,j代表网页j跳转到页面i的概率.也就是说,对于i,j∈G,与有向图G相关的Google矩阵可以被设置如下:

(2)
其中L(j)是网页j的出站链接总数.
现在给出N为4的一个例子(共有A、B、C、D、E、F、G七张网页)帮助说明这个矩阵.对于图3所示的有向图,其Google初始矩阵可以通过公式(2)获得,图4给出了Google初始矩阵S计算结果.

图3 页面有向图Fig.3 A directed graph for page

图4 Google 初始矩阵Fig.4 Google initial matrix
定义3.(Google矩阵)得到初始矩阵后,我们就可以计算PR值了,当只有α概率的用户会点击网页链接,剩下(1-α)概率的用户会跳到无关的页面上去,而访问的页面恰好是这7个页面中A的概率只有(1-α)/7(α是阻尼系数,Google在计算网页排名的时候取α等于0.85,所以本文在这里也取0.85),所以真正的Google矩阵由公式(3)计算.
(3)
定义4.(PR值计算)在有向图G及其Google矩阵GM里面,其中n是G中的节点数然后.于是得到Pn=GM×Pn-1,可以通过以下公式(3)逐级地迭代更新秩向量,直到得到Pn=Pn-1时,才算迭代完成,这时的Pn就是PR的值.于是计算PR值的过程就变成了一个 Markov 过程.
Pn=GM×Pn-1
(4)
3.2 MR-UIRank模型
传统的PageRank模型可以帮助评估微博用户的影响力,但其有效性并不被大多数人认可.传统的PageRank模型仅考虑链接关系,即用户与用户之间的关注与被关注关系.把微博用户的粉丝看作网站的入站链接,微博用户关注的人看作网站的出站链接,这样就可以把PageRank模型应用到计算微博用户影响力里面来[18].但是,在计算影响力的时候,那些拥有众多“僵死粉”的微博用户的影响力就会被虚假提高,从而计算出来的影响力并不准确,其实那些拥有众多“水军”的用户影响力并没有那么高.所以,首先要剔除微博用户的僵尸粉,在进行粉丝筛选的时候,需要选取高质量的粉丝.需要选取长期关注博主的粉丝,而不是近期突然增加的粉丝.
定义5.(粉丝选取)认定选取的粉丝集合为F,其中选取的粉丝是关注博主三个月以上的用户.而且这些用户在三个礼拜以内有和别人互动,且评论或者转发过该博主的微博等这样的交互行为.
F(i)={j|(j,i)∈A∪FT>3m∪AT>3w}
(5)
F(i)代表用户i的粉丝集合,j代表其中一个粉丝,FT代表的是粉丝j关注博主的时间,大于三个月,AT代表粉丝j活跃的天数是三周.这一步只是对粉丝进行了筛选,剔除了一些僵死粉的干扰.选取完粉丝后就需要计算用户的活跃度了,下面的定义6代表粉丝活跃度计算公式.
定义6.(用户活跃度计算)用户的活跃度包括很多条件,如用户发布的微博数,转发微博数,点赞微博数,评论微博数,@别人的微博数,收藏微博数量以及在微博中的活跃的天数.本文设定的时间段是最近三个月内微博用户的活动情况,综合这些条件,下面给定微博用户i其活跃度的计算公式:
(6)
其中nbi是微博用户i三个月内发布的微博数量,NB是整个微博里面所有微博用户三个月内发布的微博数量;nri是微博用户i三个月内转发的微博数量,NRi是三个月内整个微博里面所有微博用户转发微博数量;nci是微博用户i三个月内评论微博数量,NCi是三个月内整个微博里面所有微博用户评论微博数量;nli是微博用户i三个月内点赞微博数量,NLi是三个月内整个微博里面所有微博用户点赞微博数量;nai是微博用户i三个月内“@”其他用户微博数量,NAi是三个月内整个微博里面所有微博用户“@”其他用户微博数量;di是微博用户i三个月内的活跃天数,Di是三个月内整个微博里面所有微博用户平均活跃天数.
在研究了用户的活跃度之后,但还需要对用户的微博质量进行研究.微博的质量体现在微博的内容是否健康,真实,是否对我们整个社会有一定的影响.例如那些在微博里面散布广告,发布虚假消息的微博用户,那么他们的这些行为对于整个微博环境,对于整个社会带来了负面的影响,应当予以否定.所以,在选取微博内容时,就需要剔除那些质量较差的微博,选取能够对于社会产生正面影响的微博.因此,在筛选微博数据的时候,本文就选取了和社会话题相关的微博作为研究对象.同时对用户微博被评论的数量,被转发的数量,被点赞的数量,和被收藏数量进行研究.如果微博被众多人评论,转发,点赞和收藏自然说明该用户的影响力要高.根据上面提出的思想,下面的定义7给出了在用户微博质量的简单评估计算方法.
定义7.(用户微博质量计算)对由于用户发布微博,有着不确定性,且微博的内容和每天发生的事情有关,所以,在选取微博内容的时候,本文选取了最近三个月的微博内容作为实验的对象.于微博用户i,选取的研究话题为社会话题为SI(Social Issues),用户微博质量计算公式如下:
(7)
(8)
(9)
(10)
(11)
Quality(i)=QSI(i)+QR(i)+QC(i)+QL(i)+QF(i)
(12)
其中nsii是用户i发布与主题SI相关的微博数量,Ni是用户i在微博中发布的所有微博数量;rsii是用户i发布与主题SI相关的微博被转发的数量,Ri是在微博里面所有被转发的微博数量;csii是用户i发布与主题SI相关的微博被评论的数量,Ci是在微博里面所有被评论的微博数量;lsii是用户i发布与主题SI相关的微博被点赞的数量,Li是在微博里面所有被点赞的微博数量.fsii是用户i发布与主题SI相关的微博被收藏的数量,Fi是在微博里面所有被收藏的微博数量.研究的时间段是最近的三个月.
此外,还有另一个因素也可以在很大程度上反映用户的影响力,就是微博用户的可信度.比如微博里面的那些大V,一些经过官方认证博主,那么他们的发言就会很有影响力,人们愿意相信这些人所发布的微博.目前在新浪微博平台上已经提供认证机制,共有四种认证方式.第一种是兴趣认证,第二种是自媒体认证,第三种是身份认证,最后一种是官方认证.在此,本文利用微博上不同的认证,给出不同的用户信誉度.定义8给出了在微博上用户可信度的简单计算方法.
定义8.(微博用户可信度)对于微博用户i,其可信度可以计算公式如下:

(13)
在进行运算PageRank算法之前还需要修改微博用户的权重,由定义9给出.
定义9.(微博用户权重)对于微博用户i,它的权重w(weiht)计算公式如下:
w(i)=Activity(i)+Quality(i)+Credibility(i)
(14)
然后将用户权重加入进原始PageRank模型计算.
定义10.(加权Google矩阵)对于有向图G=

(15)
公式(15)中的zi,j是公式(3)中的值gmi,j与用户权重w(i)的乘积,所以加权的Google矩阵考虑的用户的链接结构包括用户活跃度,用户微博质量和用户可信度等因素.假设已经获得图1中每个节点的评估参数,如令w(A)=w1,w(B)= w2,w(C)= w3,w(D)=w4,w(E)=w5,w(F)=w6,w(G)=w7那么通过计算,就可以获得加权后的的Google矩阵Z.
4 实验与分析
4.1 实验数据
在获取新浪微博数据时,首先要先注册新浪微博账号,然后利用该账号在新浪微博开放平台完成开发者的注册,注册身份为学生,然后在开放平台上创建一个应用,创建完应用后,开发者会得到获取两个非常重要的参数App Key和Secret Key.在创建应用过程中需要填写一个授权回调页.应用创建完成后,就可以利用新浪官方API进行开发了.首先进入开放平台,在文档里面资源下载和API选项,首先需要在资源下载下面下载相关的SDK,本文用到的是JAVA SDK.下载完了JAVA SDK后就需要导入到eclipse里面,然后是配置下载下来的JAVA SDK.主要改一个文件,src文件夹下面的config.properties,配置如下参数.
1.client_ID:appkey 创建应用获取到的appkey (App Key)
2.client_SERCRET:app_secret 创建应用获取到的appsecret(Secret Key)
3.redirect_URI:回调地址 OAuth2的回调地址(就是在高级信息里面填写的授权回调页).
在配置好配置文件后就需要进行Oath2.0认证,这是在调用所有API之前都需要进行的操作.
调用example下面weibo4j.examples.oauth2包里面的 OAuth4Code.java.如果这个步骤完成了就可以任意调用微博API了.然后再微博API选项下面查阅相关的API文档,就可以在eclipse里面下载到需要用到的数据.然后利用微博API获取了64678个微博用户,其中包含用户的基本信息和用户关系网络和发布的微博信息等一些数据,然后从64678个用户里面选择3958个微博用户作为实验对象.虽然3958个用户只是新浪微博用户总数的一小部分,但这些用户的关系是相对完整的,所以我们可以使用它们来测试我们的算法在本文中的有效性.
4.2 实验环境
本次实验采用4台PC机搭建云计算Hadoop平台,其中每台机器的配置均为:Intel 酷睿i7 6700HQ 3.5GHz,内存DDR4 2133MHz 16GB,硬盘2TB.在每台PC机操作系统为64位Centos7 linux,而且配置安装Hadoop 的版本为2.7.3、JDK为jdk-8u111-linux-x64版本以及其他环境配置.
搭建的云计算hadoop平台集群设置信息如图5所示.
图5 Hadoop集群设置Fig.5 Hadoop cluster settings
4.3 实验结果
本文对实验结果进行比较分析选取社会问题作为PageRank和MR-UIRank算法计算时的主题,分别对传统的PageRank算法和本文提出的MR-UIRank算法计算出的用户影响力进行排序,列出PageRank算法和MR-UIRank算法影响力排名前10的用户.计算结果如表1和表2所示.表中的微博数是用户最近三个月所发布的微博数量.
表1 PageRank算法计算结果
Table 1 Calculation by Pagerank

排名微博用户名粉丝数微博数认证1新手指南172567565125官方2微博管理员15672263666官方3谢娜88124987159身份4陈坤8075713074身份5姚晨80321437172身份6赵薇7898828640身份7何炅82099269122身份8angelababy7802469630身份9人民日报509764113060官方10央视新闻485761653335官方
通过对表1的分析,可看传统的PageRank算法在计算时的最注重的是粉丝数量,而忽略了用户的自身行为活动,而且他们近期发布的微博数量也比较少.我们可以看出:排名靠前的都是影视大咖等这一些知名度较高的微博用户,他们的歌迷,影迷,粉丝众多从而导致他们的影响力很高.由此本文发现排名第一和第二微博用户是新手指南和微博管理员,但是他们实际的影响力并没有计算结果那么高.他们的排名之所以这么高是应为他们拥有众多粉丝,他们拥有粉丝数量是排名第三微博用户(谢娜)的将近两倍,因为他们拥有这么多的粉丝数量,在传统的PageRank算法计算影响力的时候就把他粉丝的影响力加权起来了,这样影响力就比其他用户的高了许多.拥有这么多粉丝数量的原因是在用户最开始注册微博的时候就系统就帮微博用户就自动关注了他们,而且用户也没有去取消关注,还有就是当微博用户不去用他们的微博账号后,之前的微博账号不能注销,所以这样在无形之中就产生了“僵尸用户”,而且这些“僵尸用户”也不会被系统清除,所以他们的粉丝才会这么多,但其活跃度相对而言不是很高.所以在目前微博里面就会有明星花钱去买粉丝,来提高自己的想象力,提高自己的知名度.在表1里面,我们还可以看到,人民日报和央视新闻也挤入了前十,虽然他们得粉丝数量和前面的微博用户相差很大,但是发布的微博数量多.
表2 MR-UIRank算法计算结果
Table 2 Calculation byMR-UIRan

排名微博用户名粉丝数微博数认证1中国新闻网310891102803官方2人民日报509764113060官方3央视新闻485761653335官方4新浪新闻106879172855官方5人民网371373675422官方6法制晚报161633113929官方7环球时报71063714877官方8中国经营报23364983075官方9成都商报274330323535官方10Vista看天下514359421898官方
分析表2可以发现MR-UIRank算法得到的结果和粉丝数量没有呈现出正相关的关系.而微博用户的自身的活动,他的微博数量,所发布微博的内容等一些他的动态行为成了评论影响力强有力的标准.排名靠前的是中国最具权威的报刊和新闻媒体人民日报和央视新闻,可以看到,他们的粉丝数量和微博数量都是非常高的.MR-UIRank算法的前10个用户他们都是官方认证用户,而且发布了足够的微博,粉丝.此外,为了评估文章的质量,我们把主题放在社会问题上,所以MR-UIRank算法得到的前10个用户,大多是官方认证的新闻媒体,他们具有更大的权威性,而且这10个用户里面没有一个娱乐明星,这也说明这些娱乐明星发布的微博很少与社会话题有关,通过查看他们的微博,他们发布的微博话题大多数都是他们的日常生活或者一些宣传,因此在MR-UIRank算法里面他们都排不上名.PageRank算法在评估用户影响力时没有考虑到用户自身的动态行为,而是依赖于粉丝数量,过于简单片面,所以在一定程度上受到“僵尸粉的”干扰.
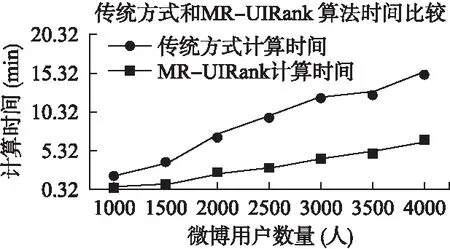
图6 时间比较Fig.6 Time comparison
为了比较效率,本文用不同数量的用户测试了传统方式计算的时间和MR-UIRank算法执行时间的变化与比较.本文分了七个,分别包括1000,1500,2000,2500,3000,3500和4000个微博用户数量.计算结果如图6所示.
从图6可以看出,MR-UIRank算法的执行时间明显低于在相同数据容量下执行的传统方式计算时间.这是因为与传统计算方式算法相比,MR-UIRank算法利用了MapReduce计算框架,这样就明显提高了计算的效率,缩短了计算时间.而且,随着计算数量的不断增加,MR-UIRank算法的效率会明显提高,优势会越来越大.所以在进行大规模的计算时,运用MapReduce计算框架能够明显提高时效性,使得算法运行得到优化.
5 结束语
本文分析了微博社交网络的用户的关系网络和自身的行为,结合传统Pagerank算法,运用云计算平台进行计算,结果表明本文的算充分法考虑用户的实际活动行为以及用户的粉丝,使得挖掘结果更客观和准确,可以获得更加全面,真实的结果,更好的反应微博用户影响力.而且运用云计算后的计算效率比传统的计算更加高效,节省时间.
在下一步的研究中,将会研究算法的高效性和准确性,在提高准确度的情况下提升效率,缩短计算时间,以便于应对更加规模庞大的数据量计算.
[1] The 39thstatistical report on Internet development in China[R].Beijing:China Internet Network Information Center,http://www.cnnic.net.cn/,2016.
[2] Fu Cheng-long.Study of parallel production technology of remote sensing product and its application[D].Zhengzhou: Henan University,2014.
[3] Sun H,Chen S P,Jin C,et al.Research and simulation of task scheduling algorithm in cloud computing[J].Telkomnika Indonesian Journal of Electrical Engineering,2013,11(11):6664-6672.
[4] Xu Ya-bin,Li Zhuo,Dong Yuan.The quick spam filtering method based on social computing and machine learning[J].Systems Engineering-Theory & Practice,2014(S1):179-186.
[5] Page L,Brin S,Motwani R,et al.The pagerank citation ranking:bringing order to the web[R].Stanford InfoLab,1999.
[6] Lamberti F,Sanna A,Demartini C.A relation-based page rank algorithm for semantic web search engines[J].IEEE Transactions on Knowledge & Data Engineering,2009,21(1):123-136.
[7] Jing Y,Baluja S.Pagerank for product image search[C].International Conference on World Wide Web,ACM,2008:307-316.
[8] Kleinberg J M.Authoritative sources in a hyperlinked environment[C].Acm-Siam Symposium on Discrete Algorithms,Society for Industrial and Applied Mathematics,1998.
[9] Liu Y,Lin Y.Supervised HITS algorithm for medline citation ranking[C].IEEE International Conference on Bioinformatics and Bioengineering,Bibe 2007,Harvard Medical School,Boston,Ma,Usa,2007:1323-1327.
[10] Asano Y,Tezuka Y,Nishizeki T.Improvements of HITS algorithms for spam links[C].Joint,Asia-Pacific Web and,International Conference on Web-Age Information Management Conference on Advances in Data and Web Management,Springer-Verlag,2007:200-208.
[11] Jianshu Weng,Ee-Peng Lim,Jing Jiang,et al.TwitterRank:finding topic-sensitive influential twitterers[C].ACM International Conference on Web Search and Data Mining (WSDM),2010.
[12] Cha M,Haddadi H,Benevenuto F,et al.Measuring user influence in twitter:the million follower fallacy[C].International Conference on Weblogs and Social Media (ICWSM),2010.
[13] Chen Xu,Wang Peng-fei,Qin Zheng,et al.HLBPR:a hybrid local Bayesian personal ranking method[C].International Conference Companion on World Wide Web,International World Wide Web Conferences Steering Committee,2016:21-22.
[14] Zhou Jun,Zhang Yan,Wang Bing,et al.Predicting user influence in microblogs[C].Computer Communication and the Internet (ICCCI),2016 IEEE International Conference on IEEE,2016:292-295.
[15] Wu Yu,Ma Lu-lu,Lin Mao,et al.Discovery algorithm of opinion leaders based on user influence[J].Journal of Chinese Computer Systems,2015,36(3):561-565.
[16] Mao G J,Zhang J.A pagerank-based mining algorithm for user influnces on micro-bloges [C].Pacific Asia Conference on Information Systems(PACIS),2016.
[17] Pan Quan,Guo Ming,Lin Peng.An algorithm for the maximum clique based on MapReduce[J].Systems Engineering-Theory & Practice,2011,(S2):150-153.
[18] Xu Wen-tao,Liu Feng,Zhu Er-zhou.Research on novel ranking algorithm of microblog user′s influence based on MapReduce [J].Computer Science,2016,43(9):66-70.
附中文参考文献:
[1] 第39次中国互联网络发展状况统计报告[R].北京:中国互联网络信息中心,http://www.cnnic.net.cn/,2016.
[2] 付成龙.遥感产品并行生产技术的研究及其应用[D].郑州:河南大学,2014.
[4] 徐雅斌,李 卓,董 源.基于社会计算和机器学习的垃圾邮件快速过滤[J].系统工程理论与实践,2014,(S1):179-186.
[15] 吴 渝,马璐璐,林 茂,等.基于用户影响力的意见领袖发现算法[J].小型微型计算机系统,2015,36(3):561-565.
[17] 潘 全,郭 鸣,林 鹏.基于MapReduce的最大团算法[J].系统工程理论与实践,2011,(S2):150-153.
[18] 徐文涛,刘 锋,朱二周.基于MapReduce的新型微博用户影响力排名算法研究[J].计算机科学,2016,43(9):66-70.
