基于XGBoost 算法的2型糖尿病精准预测模型研究
2018-03-26张洪侠王金霞徐岩艳胡光瑞李洪军刘天戟李燕林赵志强牛晓强
张洪侠,郭 贺,王金霞,徐岩艳,吕 斌,闫 东,常 佳,胡光瑞,王 雪,李洪军,刘天戟*,李燕林,赵志强,牛晓强
(1.吉林大学中日联谊医院,吉林 长春130033;2. 北京青梧桐健康科技有限公司)
近年来,我国糖尿病患病率逐年增加,研究表明我国成人糖尿病患病率目前为10.9%,其中新诊断糖尿病患病率6.9%,既往已知糖尿病患病率4.0%,40岁以下糖尿病患病率高达5.9%[1],糖尿病发病年轻化趋势严重,由糖尿病引发的心脑血管疾病的发病率也逐年提高,提前进行糖尿病患病风险的评估,对高危人群进行早期干预以降低糖尿病的发病率无疑是当前亟待解决的问题。
XGBoost是极端梯度上升( eXtreme Gradient Boosting)的简称,是一种基于梯度 Boosting 的集成学习算法,其原理是通过弱分类器的迭代计算实现准确的分类效果[2]。它是兼具线性模型和Boosted Tree模型的一种优化模型 。XGBoost模型目前被机器学习、数据挖掘、统计学等专家广泛应用于人工智能、数据分析和统计学习等领域[3]。影响糖尿病发生发展的因素有很多,如年龄、生活方式、肥胖、基因易感性等,本文结合人群体检数据及基因检测数据探讨及评价应用XGBoost模型预测糖尿病患病风险。
1 对象和方法
1.1对象及分组
在我院体检中心进行常规体检的人员当中招募53名2型糖尿病患者和93名非糖尿病患者,年龄区间在18-65岁之间。本研究项目已经获得医院医学伦理委员会批准,所有参与研究的志愿者均签订知情同意书。
1.2方法
1.2.1健康自测问卷 所有志愿者均填写中华医学会健康管理学分会推荐使用的《健康体检自测问卷》[4]。
1.2.2体检项目检查 体检项目包括内科、外科、血常规、尿常规、血糖、糖化血红蛋白、血脂、肝功、肾功、心电、腹部超声、胸片等项检查,体检项目在吉林大学中日联谊医院体检中心、检验科、超声科、放射科等进行。不同的志愿者体检项目不完全相同,但是志愿者的体检项目均有血糖和尿常规两个检测项目。
1.2.3糖尿病易感基因多态性检测 单核苷酸多态性(Single Nucleotide Polymorphism,SNP) 是人类基因组中最常见的基因多态性,是继RFLP,STR之后的第3代遗传学标记。它是指单个碱基的缺失、插入以及单个碱基的置换。也就是一个碱基对的差异。常以二等位基因的形式出现。我们对所有志愿者进行糖尿病易感基因的基因多态性质谱检测,基因质谱检测在北京青梧桐健康科技有限公司进行,所选SNP是根据文献得出(见表1)[5-8]。

表1 糖尿病患病风险检测基因信息表
1.2.3.1基因组DNA提取 EDTA抗凝血0.2 ml,采用康为世纪的全基因组DNA提取试剂盒提取外周血DNA,紫外分光光度计检测OD260/280,比值在1.6-1.8,表明样品纯度较高,可做后续实验。
1.2.3.2PCR扩增及纯化 从Pubmed中检索待测基因序列,利用Assay Designer(Sequenom)软件包对每个待测位点均设计1对引物(由北京青梧桐健康科技有限公司提供)。 PCR反应体系:所有需要检测的DNA样本均稀释到10 ng/μl, 取1 μl DNA样本,将其与1.8 μl ddH2O、0.5 μl PCR缓冲液(含20 mmol/L MgCl2)、0.1 μl 的25 mmol/L dNTP、0.4 μl 25 mmol/L MgCl2、1 μl PCR引物以及0.2 μl Hotstar 酶(Roche)混合在一起。PCR反应条件:95 ℃ 2 min;95 ℃ 30 sec,56 ℃ 20 sec,72 ℃ 60 sec,共45个循环;最终72℃ 5min。PCR扩增后,剩余的dNTP将被去磷酸消化掉,反应体系包括1.53 μl ddH2O、0.17 μl SAP缓冲液、0.3 Unit 碱性磷酸酶SAP(Agena Biosciencr)。该反应在37℃ 进行40 min, 然后85℃ 5 min使酶失活。
1.2.3.3待测位点的PEX反应 反应体系:0.94 μl 延伸引物(由北京青梧桐健康科技有限公司提供)、0.2 μl 10 X Gold缓冲液、0.2 μl 终止反应液、0.041 μl iPLEX酶(Sequenom)以及0.619 μl ddH2O。反应条件:94 ℃ 30 sec;94 ℃ 5 sec,52 ℃ 5 sec,80 ℃ 5 sec 5个循环,共40个循环;最终72℃ 3 min。在终止反应物中加入6 mg 阳离子交换树脂(Sequenom)脱盐,混合后加入16 μl ddH2O悬浮。
1.2.3.4样本分析 使用MassARRAY Nanodispenser(Sequenom)将最终的分型产物点样到一块384孔的spectroCHIP (Sequenom)上,并用基质辅助激光解吸电离飞行时间质谱进行分析。最终结果由 MassARRAY RT软件系统(版本号4.0)实时读取,并由MassARRAY Typer软件系统(版本号4.0)完成基因分型分析。
1.2.3.5等位基因判别 通过MALDI-TOF-MS检测,各个引物及其PEX产物可形成2个(纯合子)或3个(杂合子)信号峰,计算各个产物峰与相应的引物峰之间的m/z之差,得知所延伸的碱基的类型,可推断该SNP位点的基因型。
1.2.4运用XGBoost模型建立糖尿病风险预测模型
1.2.4.1数据预处理 原始数据有699维的特征,部分特征列缺失数据严重,将数据缺失超过20%的特征列删除,剩余92列。包含所有的SNP数据,年龄性别等个人信息,以及部分生化检验信息。数据中的缺失值全部填充为0。
1.2.4.2特征提取 我们对特征列做进一步处理,首先剔除姓名、登记号、体检日期三个与体检指标无关的特征列。剩余的特征中,我们只保留特征内容为数值型,而非字符型的特征列,总共得到61列。此外,我们还对SNP位点进行编码,每个SNP位点有三种类型,因而对于每个SNP特征列,编码后形成三个新的特征列。
1.2.4.3样本划分 我们随机将数据划分为训练集和测试集,其中80%的样本为训练集,其余为测试集。
1.2.4.4机器学习建模 我们使用XGBoost模型来进行建模与预测。传统GBDT在优化时只用到一阶导数信息,XGBoost则同时用到了一阶和二阶导数的信息。XGBoost在代价函数里加入了正则项,用于控制模型的复杂度。正则项降低了模型的方差,使学习出来的模型更加简单,防止过拟合。XGBoost还借鉴了随机森林列抽样的做法,能降低过拟合。随机森林的原理是随机建立大量的分类树,每棵树单独对样本进行分类,最终分类结果由每棵树各自的分类结果通过投票确定。随机森林算法提高了分类的准确性,且结果稳健,易于调整参数,但运行速度较慢。
1.3分析
1.3.1模型正确率的计算 我们采用准确率为指标来评价模型的预测效果,定义公式如下:正确率=预测正确的样本数/总样本数*100%。XGBoost模型预测得到的值为0-1之间的小数,将其二值化,0.5以上的定为1,0.5以下的设为0。二值化后预测值与实际值进行比较,计算正确率。
1.3.2特征重要性评估法 通过 XGBoost 建模可以判断每个特征变量对模型的贡献程度,从而判断哪些特征变量对于糖尿病的发病风险的影响更为显著。以数字代号对应的体检指标如表2所示。
2 结果
2.1模型正确率
根据公式运用测试集检测,最后的正确率约为86.6%。
2.2特征重要性评估结果
图1为XGBoost模型的特征重要性评估。其中,排在前16位的重要特征有15位都是体检特征,如血糖、甘油三酯、红细胞计数等。之后的重要特征以SNP为主。

表2 特征代号对应的体检特征名称
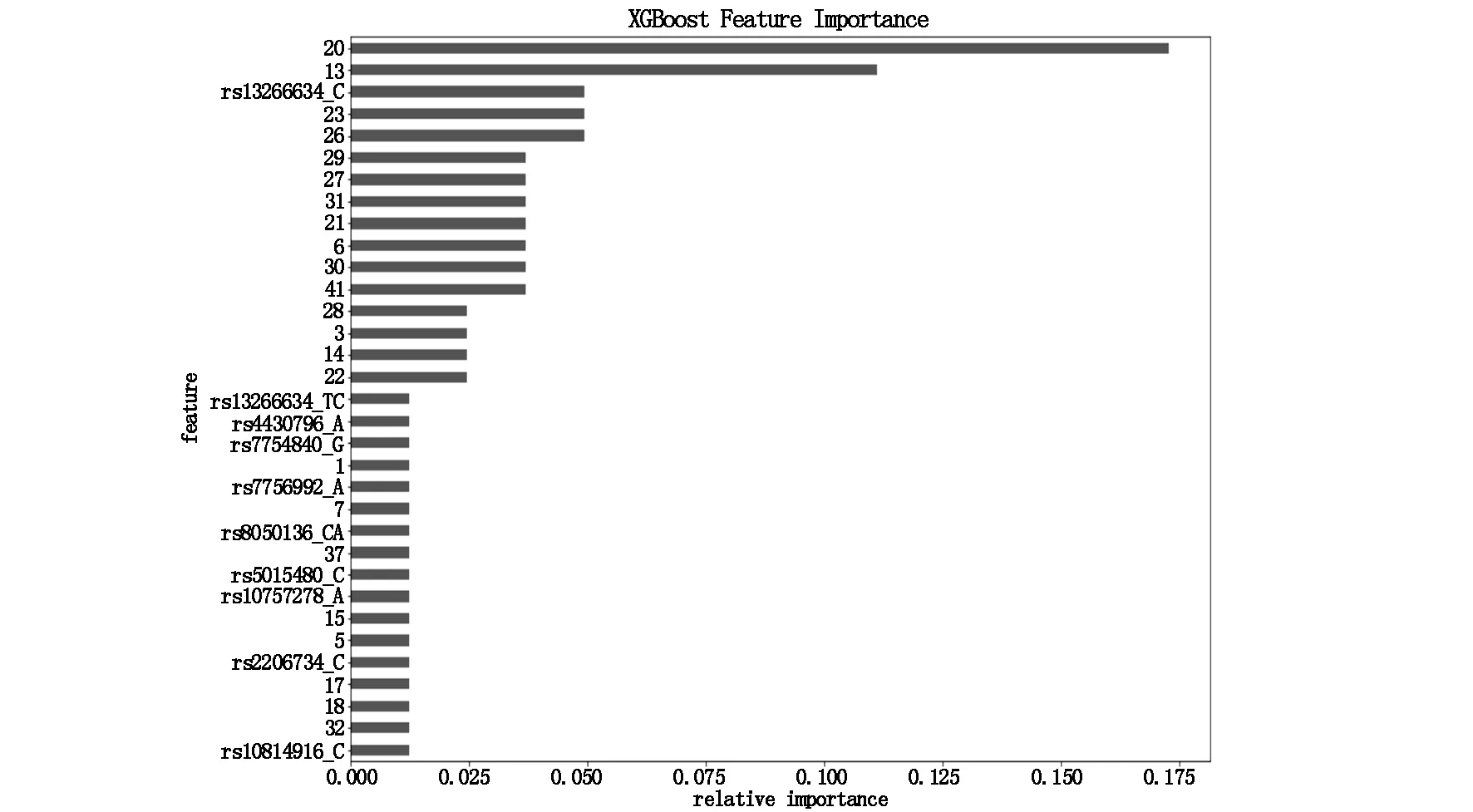
图1 xgboost模型的特征重要性评估
3 讨论
国内外糖尿病的发病风险模型很多,有建模方法为Logistic回归模型的墨西哥后裔美国人和非西班牙白种人糖尿病发病预测模型、日籍美国人个体糖尿病发病风险预测模型、芬兰人群DM个体危险评分模型;有建模方法为Cox回归模型的适用于中国台湾人的糖尿病风险评估模型;有建模方法为人工神经网络的糖尿病和糖耐量受损的个体发病预测模型[9],上述建模方法各有利弊。本文采用的XGBoost是一种 Gradient Boosting 算法的快速实现,它能够充分利用多核 CPU 进行并行计算,同时在算法上进行改进以提高精度。
特征重要性评估结果显示,对模型贡献前三名的变量依次是空腹血糖、甘油三酯和SLC30A8基因rs13266634-C位点的等位基因。高血糖是糖尿病风险的最明显的特征,众多研究表明高甘油三酯血症也与糖尿病发病密切相关[10]。SLC30A8基因,位于8号染色体(8q24),是锌转运体蛋白8(ZnT-8)的编码基因,能够特异性地在胰岛β细胞中表达。ZnT-8能促进锌从胰岛β细胞的胞浆进入含有胰岛素的分泌颗粒,参与胰岛素的分泌。如果SLC30A8基因变异致ZnT-8的结构和功能异常,就会使胰岛素分泌减少、胰高糖素分泌增加,导致血糖增高。研究证实SLC30A8增加2型糖尿病易感性可能是通过影响胰岛β细胞功能使其紊乱、影响ZnT-8蛋白的功能从而导致锌离子浓度发生变化和致胰岛β细胞对前胰岛素加工障碍所介导的。近期国内多项研究表明SLC30A8基因CC基因型及等位基因C是2型糖尿病的风险因素[11,12],与我们的XGBoost糖尿病风险预测模型一致。同时,应用测试集进行测试发现XGBoost糖尿病风险预测模型的准确度是86.6%,说明XGBoost糖尿病风险预测模型不但运算速度快,同时准确度也较高,对今后进一步临床推广具有现实意义。
另外,本研究的XGBoost糖尿病风险预测模型的特征重要性评估显示:糖化血红蛋白、年龄、总胆固醇分别排在第9位、第12位和第15位,说明高糖化血红蛋白、高龄和高胆固醇血症这三个变量对该模型的贡献量较大,白细胞计数对模型的贡献量排在第16位,考虑可能与糖尿病容易并发各种感染而引起的白细胞数增多有关。但对模型贡献量排名前14的变量中还有红细胞计数、红细胞平均体积、红细胞体积分布宽度、红细胞平均血红蛋白量、血小板平均体积、白蛋白、血小板计数、红细胞平均血红蛋白浓度、碱性磷酸酶,由于本研究样本量不大,模型还需不断优化,因而这些变量对模型贡献的机制还有待于进一步深入研究。
综上所述,从模型的分类预测准确度方面来看,本研究搭建 XGBoost糖尿病风险预测模型是成功的,具有良好的稳定性、较高的预测精度及运行的高效性,可以提前预警糖尿病风险,根据风险指标可给予精准健康干预,模型具有很强的可操作性和推广性。本研究数据样本量有限,后续研究中将逐渐扩大样本量以建立预测效果更为准确的XGBoost模型。
[1]Wang L,Gao P,Zhang M,et al. Prevalence and ethnic pattern of diabetes and prediabetes in China in 2013 [J].JAMA,2017,317(24):2515.
[2]Chen T Q ,Guestrin C.XGBoost:A scalable tree boosting system[C]//ACM.Proceedings of the 22nd ACM SIGKDD.International Conference on Knowledge Discovery and Data Mining.New York:ACM,2016:785-794.
[3]贾文慧,孙林子,景英川.基于XGBoost模型的股骨颈骨折手术预后质量评分预测[J].太原理工大学学报,2018,49(1):174.
[4]中华医学会健康管理学分会,中华健康管理学杂志编委会.健康体检基本项目专家共识[J].中华健康管理学杂志,2014,8(2):81.
[5]Wu Y,Li H,Loos RJ,et al.Common variants in CDKAL1,CDKN2A/B,IGF2BP2,SLC30A8,and HHEX/IDE genes are associated with type 2 diabetes and impaired fasting glucose in a Chinese Han population[J].Diabetes,2008,57(10):2834.
[6]Ruchat SM,Vohl MC,Weisnagel SJ,et al.Combining genetic markers and clinical risk factors improves the risk assessment of impaired glucose metabolism[J].Ann Med,2010,42(3):196.
[7]Li H,Gan W,Lu L,et al.A genome-wide association study identifies GRK5 and RASGRP1 as type 2 diabetes loci in Chinese Hans[J].Diabetes,2013,62(1):291.
[8]Fuchsberger C,Flannick J,Teslovich TM,et al.The genetic architecture of type 2 diabetes[J].Nature,2016,536(7614):41.
[9]钱 玲,施侣元,程茂金.人工神经网络应用于糖尿病并发症的影响因素研究[J].现代预防医学,2005,32(12):1625.
[10]Weijers RN.Lipid composition of cell membranes and its relevance in type 2 diabetes mellitus[J].Curr DiabeteS Rev,2015,8(5):390.
[11]刘 阳,王占友,池志宏,等.SLC30A8基因rs13266634 C/T单核有酸多态性与2型糖尿病易感性的相关性研究[J].中国医科大学学报,2015,44(6):494.
[12]张淑兰,刘 静,郭陆晋,等.SLC30A8基因rs13266634多态性与甘肃汉族、回族2型糖尿病的相关性[J].中国老年学杂志,2015,35(4):898.
