基于API调用序列的Android恶意代码检测方法研究
2018-03-26,
,
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
近年来,智能手机普及率急速增加,而智能手机极大地方便了人们的生活.智能手机操作系统也层出不穷,其中,Android是目前最流行的智能手机系统.市场研究公司Strategy Analytics公布的最新数据显示:2016年第三季度Android手机的全球市场份额达到了87.5%.在智能手机迅速发展的同时,恶意软件也呈井喷式增长.由于Android系统的开放性和用户安全意识的薄弱,个人隐私窃取、系统破坏和资费恶意消耗等各类安全问题时有发生,Android系统的应用已经成为了攻击者的主要目标.因此,对Android恶意代码检测就成为了一个值得深入研究的课题.
目前,Android恶意检测方法包括基于特征签名匹配的方法以及基于行为的方法,而基于行为的方法又可以进一步分为静态检测方法和动态检测方法[1].对于传统的特征签名匹配方法需要通过已有的恶意应用的签名库进行匹配,从而判断是否为恶意应用,优点是效率高、误报率低,但不能检测未知的恶意应用,并且特征库过大会加大维护难度.基于行为的检测方法可以依靠对已有的恶意行为进行学习,找出其恶意行为的规律,从而可以识别出新的恶意应用.静态检测方法通过对APK进行反编译,对其进行源代码级的解析,无需运行代码,就能作出较为高效的检测.然而,静态检测方法很难处理被混淆的代码,并且也无法应对被加固保护的恶意软件.动态检测方法可以绕过混淆技术的干扰,真实地模拟程序的动态运行,监控程序的实际行为,也可以有较高的检测精度[2].相比于静态检测,动态检测可以通过动态执行代码,利用特有的行为特征来检测恶意软件,但动态检测也有效率比较低,行为特征提取难度大的缺点.因此,笔者提出一种基于动态API调用序列的恶意代码检测方法,并且引入主题模型对其进行建模,有效地提高文本信息处理的性能.
1 相关工作
Android恶意应用已经造成很多用户的困扰,而Android智能手机的普及也使得恶意代码检测技术成为信息安全领域的热门课题,虽然研究时间不长,但国内外已经涌现了许多研究恶意代码检测的科研人员,并且取得了非常多的研究成果.
Schultz等[3]首次将数据挖掘技术应用于恶意代码检测当中.针对不同类型病毒的特性,使用多种分类算法(如Signature methods,RIPPER,Naïve bayes,Multi-Naïve bayes等),检测Win32 dll调用、ASCII码和字节码序列等特征,取得了不错的检测准确率.
2013年,Liu[4]提出了一种基于多分类器集成学习的Android恶意程序检测方法.通过对Android Manifest文件静态分析作为数据源,使用SVM作为基础分类器,通过间谍类程序分类器、短信类程序分类器和控制类程序分类器共同工作得出最后结果.2013年,Rastogi等[5]开发了一个完整的称为Apps playground的检测系统.该系统主要包括敏感API监控、Linux内核监控和TaintDroid的污点跟踪技术等模块,结合了多种检测技术,从多方面分析恶意应用的行为特征
2014年,杨欢等[6]提出一种基于动静态结合的多类行为特征的恶意行为检测方法,并且对不同特征使用不同的机器学习算法,从而解决单一算法无法发挥多类行为特征的问题.最后实现自动化工具Androdect,通过设计三层混合系综算法THEA建立检测模型,对不同特征寻求最优的算法,最终检测准确率达94.12%,并且与其他现有检测工具进行对比,在效率和准确度上更加优异.
2003年,Blei[7]首次提出LDA(Latent Drichlet allocation)模型,并且用于查找文档上的主题及信息.除了可以对文档建模,LDA还运用在其他领域.2013年,张志飞等[8]提出一种短文本分类方法,主要是利用隐含狄利克雷分类模型生成主题,采用KNN算法对网易页面标题数据进行分类.2016年,马钲然等[9]提出了一种新颖的基于主题模型的网络异常行为分类方法,通过主题模型对行为特征进行建模,从而对网络行为进行分类.将数据集对模型进行评估,对比SVM等算法,结果显示准确率达91.69%,分类效果更佳.
2016年,张家旺[10]等利用N-gram算法,对恶意程序语义特征的方法进行分类,并且为了提高精确度,对每个API函数添加权值,结合频次对N-gram序列中每个元素进行特征值重新估计,构建改进的N-gram序列模型.2016年,杨益敏[11]等提出一种静态检测系统,将Android的DEX文件转化为Dalvik指令集,并对其进行抽象,利用N-gram对抽象后的指令序列进行特征提取,分类结果获得了较高的准确率
针对当前国内外研究现状,笔者在原有的Android检测技术的基础上进行创新,将主题模型引入到Android恶意代码检测当中.使用Xposed框架动态劫持运行时的API调用,并且采用主题模型对提取出的API调用序列进行建模.
2 笔者方法
2.1 基本流程
提出了一种基于Xposed框架的恶意代码动态检测系统,并使用Java语言实现整个系统的设计.系统主要通过劫持函数调用,对样本进行特征提取,
从而进行分类.系统整体结构如图1所示.
2.1.1 Apps样本库
Apps样本库由已知的Android恶意应用样本库和正常应用样本库组成.恶意应用主要来自于德国Göttingen大学的Drebin项目恶意样本库,该样本库收集了178 种恶意代码家族,共5 560 份APK样本文件.而正常应用主要来自于Google play上的应用程序.
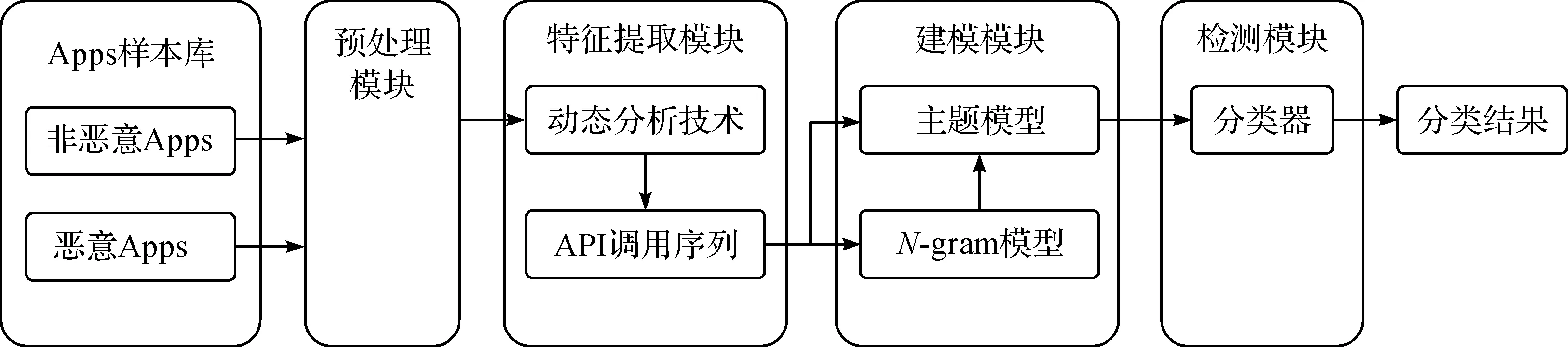
图1 恶意代码检测结构Fig.1 The structure of malicious code detection
2.1.2 预处理模块
由于样本数量较多,恶意代码家族之间数量差距较大,因此根据家族数量比例选取一定数量的恶意应用.正常应用通过现有的杀毒软件,确保所选应用是非恶意应用.并且,为了利于实验,删除过大和过小的应用.
2.1.3 特征提取模块
通过动态分析技术,运用Java语言编写基于Xposed框架的动态特征提取系统.并且编写代码对提取出的特征进行格式化处理,每个应用都有对应的API调用序列.
2.1.4 建模模块
将所提取序列的函数字段提取N-gram特征,运用主题模型对特征向量进行建模并构建分类器.
2.1.5 机器学习检测模块
将所有应用及其特征向量以ARFF(Attribute-relation file format)格式储存,便于之后的分类操作.使用多种算法根据样本特征对应用进行分类,并且使用十折交叉验证来测试算法准确性.对比各个算法的性能,创建最优的检测模型.
2.2 动态函数调用序列的提取
首先设计并编写基于Xposed框架的特征提取模块,该模块主要功能是监控敏感API的运行,并且提取出API运行时的数据,例如包名、类名和参数等.由于需要使用到Xposed框架和Root权限,并且监控过程中产生大量的数据通过日志记录下来,会占用过多资源,还有部分恶意应用会破坏系统文件,因此笔者选择在Android模拟器上安装Xposed框架和模块,进行数据的提取.为了可以自动化地测试待测应用,使用Monkey工具触发事件,尽可能收集完整的数据.
2.2.1 关键技术分析
在Android系统中,大部分的应用程序进程都是由Zygote来创建的,除了Init进程、系统引导进程等一些进程.Zygote进程在启动时会创建一个Dalvik虚拟机实例,当有新的应用程序进程要被启动时,都会从Zygote进程中孵化出新的进程,从而使每个应用程序都有独立的Dalvik虚拟机,如图2所示.

图2 Zygote进程孵化原理Fig.2 The principle of Zygote process forking
Xposed框架可以通过代码注入的方式,在不修改APK的情况下完成对系统应用的劫持.通过替换Android系统/System/Bin/App_process程序从而控制Zygote进程,使得App_process在启动过程中让所有应用程序进程加载XposedBridge.jar包,从而实现劫持的目的,如图3所示.
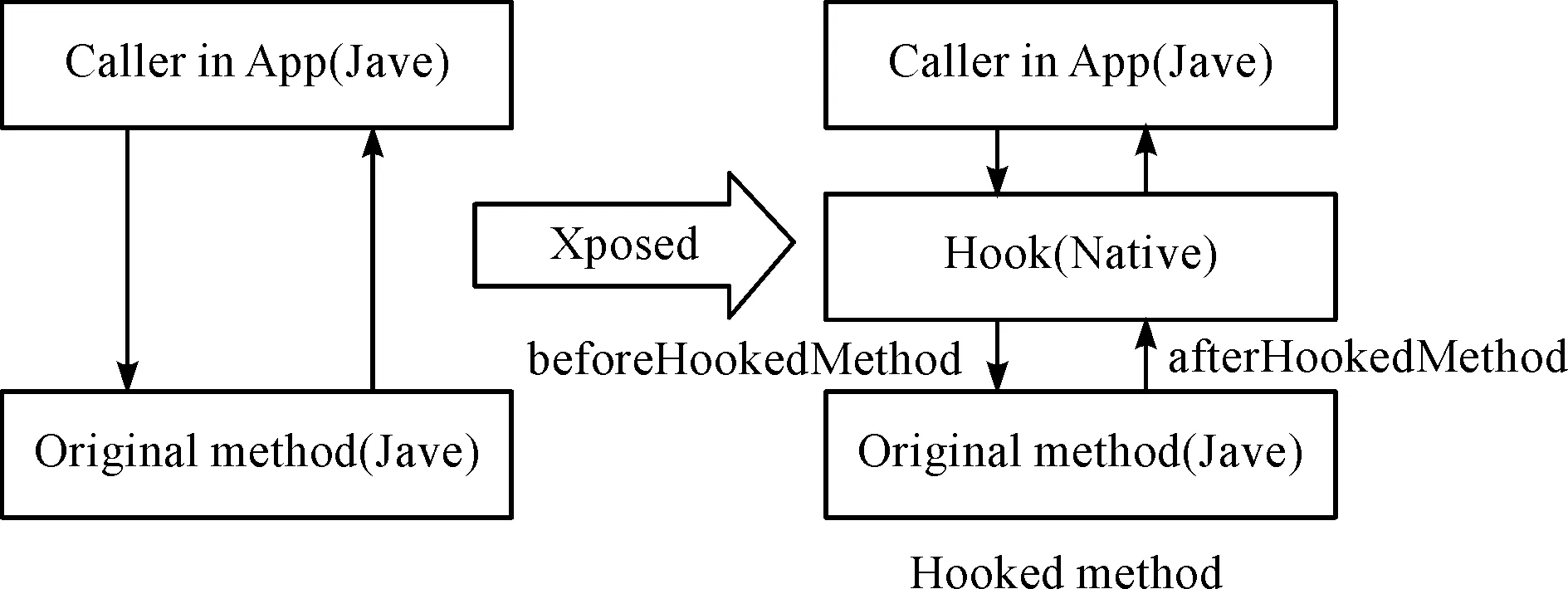
图3 Xposed框架函数劫持原理Fig.3 The principle of Xposed frame hooking function
在Xposed 框架中,XposedHelpers类的findAndHookedMethod方法主要用于寻找需要进行Hook的类及其相应的方法,并在原方法调用前后运行自定义的替换函数.在这个方法的XC_methodHook回调中,重写beforeHookedMethod和afterHookedMethod两种方法,会在需要被劫持方法的之前和之后执行,同时不影响原方法的执行.通过这两个方法的设计可以获取调用参数以及执行结果,并且写入日志中.通过对该日志文件的分析可以获取应用在运行时发生的恶意行为.
2.2.2 工作流程
利用Xposed框架提供的Jar包编写一个监听Android应用运行的监控模块,可以在应用程序被创建后,根据所要监控的API编写回调函数,在其执行前后插入相应的操作,如图4所示.具体模块工作流程如下:
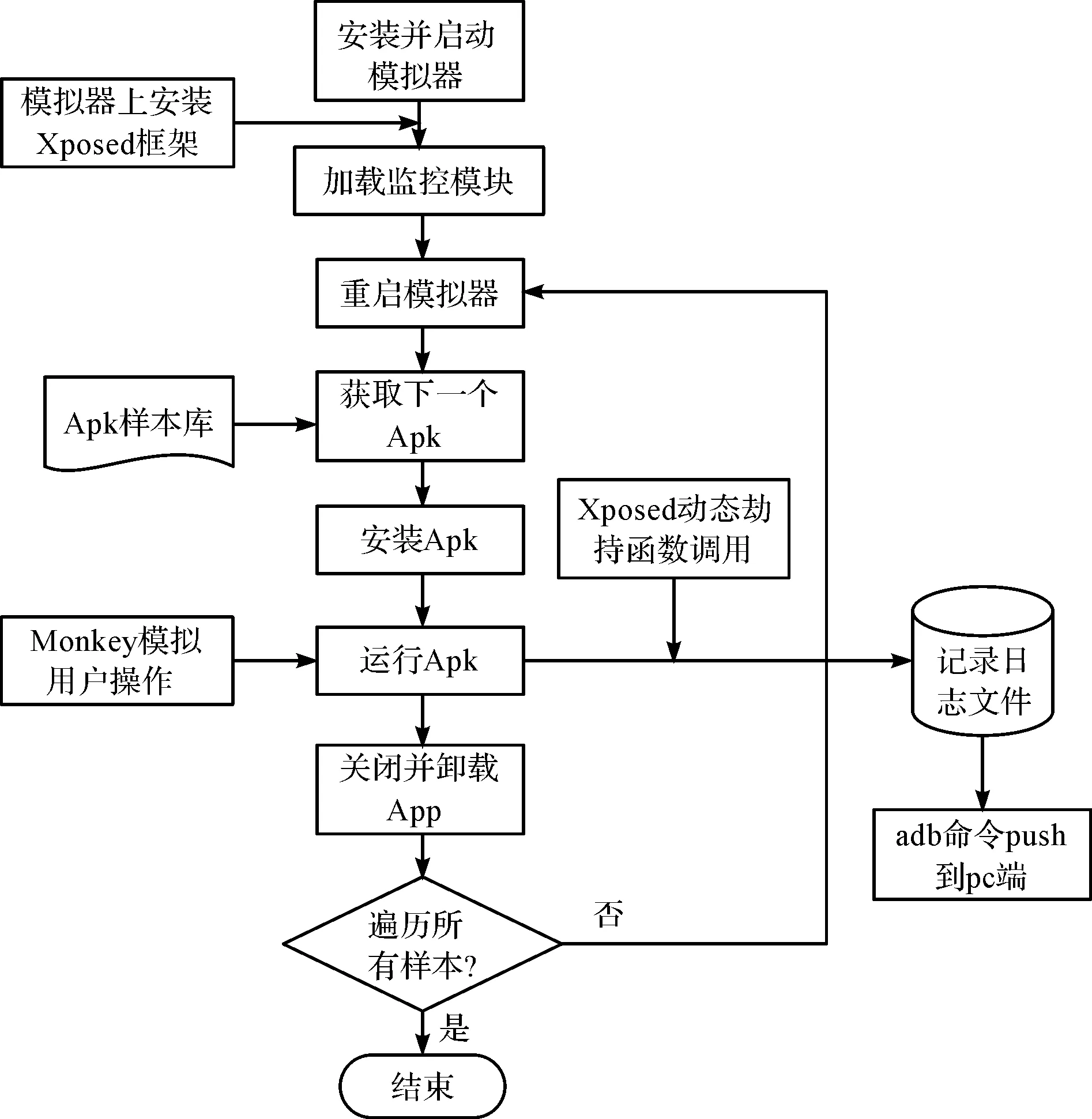
图4 动态劫持API调用序列流程Fig.4 The process of dynamic hooking API sequence
1) 安装并使用Genymotion模拟器,主要代替真机作为待测应用的运行环境;获取系统的root权限,在模拟器上安装Xposed框架.
2) 在模拟器上加载已经编写好的监控模块,并在Xposed框架中启用,重新启动模拟器,使监控模块正式运行.
3) 通过待测应用的Apk文件安装并运行该应用.使用Monkey工具模拟用户触摸屏幕、滑动和按键等操作来对其进行压力测试.当运行过程中触发敏感API调用时,记录下应用的包名、API函数名、参数以及返回值等信息.
4) 将提取出来的敏感API信息通过adb命令从模拟器中Push到PC端,通过对日志文件的分析提取出需要的特征.
5) 日志输出结束后,清除模拟器中的日志目录,并且利用adb命令关闭并卸载该App.重启模拟器,安装下一个Apk,直到遍历所有的样本.
2.3 序列的主题模型
主题模型是一种文本挖掘中的概率模型,主要用于对文本的分类,区别于传统的空间向量模型[12],不再只是考虑文档在词典空间的维度,而是实现在主题空间上的表示.它既可以提取文档中隐含语义的挖掘,即主题;又可以对文档特征降维.在主题模型中,主题可以表现为一系列相关的单词以及其条件概率,说明这些单词与对应主题具有一定的相关性.
2.3.1 序列文本的主题模型
LDA是一个“文本—主题—词汇”的三层贝叶斯模型,每个文本都是由多个主题组合而成(利用文档在所有主题上的概率分布来表示),而每个主题都是词汇上的概率分布(即每个词对主题的贡献度)[8].
将主题模型引入到恶意代码分类当中,对每一条所提出的API调用序列进行建模,所有的API函数组成一个词汇库.对于每一个应用的API调用序列,LDA定义了如下的生成过程:首先,对于每条序列,从主题分布中抽取一个主题,然后从上述选中的主题所对应的单词分布中抽取一个API函数,不断重复上述过程直至遍历到序列中每一个API函数[13],如图5所示.图5中:只有w表示可观测变量,其他都是潜在变量或者参数;箭头表示两个变量间的依赖关系;方框表示重复抽样,重复次数在方框的右下角.

图5 LDA模型结构Fig.5 The structure of LDA model
假设有M个应用的序列隐含着K个主题,所提取的模型中,一个序列是由一个N维向量组成,而N维的向量代表着API调用序列一系列的基本特征,也可称为应用的行为[14].
LDA模型生成文档过程如下:
ɑ→θ→z表示生成API调用序列的所有API函数对应的主题.θ是文本—主题的概率分布,每一条API调用序列与K个主题的一个多项分布相对应.ɑ→θ过程,就是从狄利克雷分布ɑ中取样生成序列m的主题分布θm.θ→z过程,就是从主题的多项式分布θm中取样生成序列m第n个词的主题.
β→Φ→w表示序列中的API函数是如何产生的.Φ是主题—词汇的概率分布,每个主题与V个API函数的一个多项分布相对应.β→Φ过程,就是从狄利克雷分布β中取样生成主题zm,n对应的词语分布Φzm,n.β是一个V维向量,V是特征库中特征的总数.Φ→w过程,就是从词语的多项式分布Φzm,n中采样最终生成词语wm,n.
根据LDA的图模型,w表示可观测变量,ɑ和β是根据经验所得的先验参数,其他变量z,θ,Φ都是隐含变量,需要根据观察到的变量来学习估计的.因此,可以写出所有变量的联合分布为
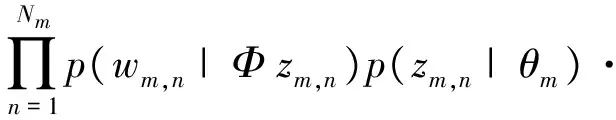
将所提取的样本特征应用于LDA模型,从而得到应用行为的主题分布.图6(a)展示了样本中应用对应的主题分布概率.图6(b)分别展示了8,13 号主题中前3 个单词分布,即API调用.
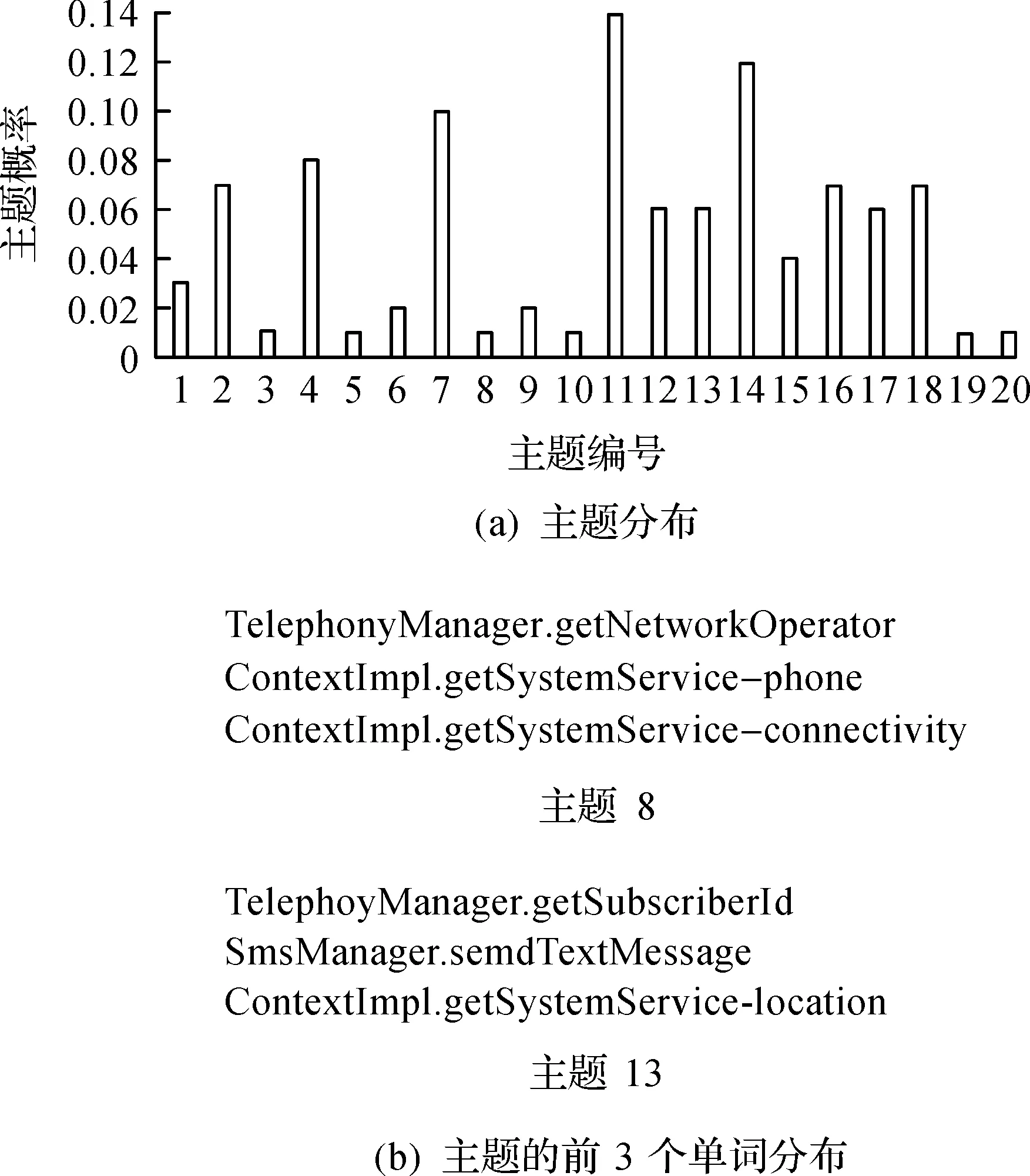
图6 主题分布及其单词分布Fig.6 The distribution of topic and word
2.3.2 序列N-gram的主题模型
N-gram是自然语言处理领域的概念,是大词汇连续语音识别中常用的一种语言模型[10].它的基本理念是将待提取的内容按照字节以长度为N的滑动窗口进行切分.N-gram常用于文档的分类、信息检索等.该算法的优点:1) 语种无关性,该算法可以同时处理中文、英文和繁体中文等;2) 不需要对文档内容进行语言学方面的处理;3) 对拼写错误的容错能力很强;4) 不需要任何词典和规则.
N-gram算法采用固定长度为N的滑动窗口进行切分,将文本按字节流从第一个字符开始从左向右移动,形成了与之前N-1个词相关的字节片段序列.目前常用N-gram模型是二元的Bi-gram和三元的Tri-gram模型.对2 种模型的切分方法进行比较,比如对“我是中华人民共和国公民”进行切分,Bi-gram的切分结果就是“我是,是中,中华,华人,人民,民共,共和,和国,国公,公民”;而Tri-gram的切分结果则是“我是中,是中华,中华人,华人民,人民共,民共和,共和国,和国公,国公民”.
纵观前人的研究,大部分的电动汽车动力系统参数匹配设计采用高电压电池以满足汽车的动力性能要求,但高电压对汽车电路元器件的要求更高,且对人们的用电安全有影响。本文设计采用辅能源单变换器并联的复合电源结构的低电压电池作为电动车的动力源,对其动力系统的相关参数进行匹配计算。通过在ADVISOR软件环境下建模仿真,验证该匹配方案符合设计要求。
N-gram也经常用于对恶意代码的分析,因此可以将所劫持的API序列进行N-gram特征提取.由于用N-gram提取特征时,特征维度会呈现指数型的增长,当N>3时,会产生10 000多个特征向量,而且大部分的特征向量出现的频率较低,N取值太高,反而降低了系统检测的准确度.
LDA模型由于只考虑词汇的频率而不考虑词汇出现的顺序,简化了算法的复杂程度.为了加强词汇前后顺序的相关性,将API序列进行N-gram特征提取后的输出作为LDA模型的输入,并且LDA模型可以对N-gram特征向量进行降维,解决特征维度过高的问题.
如图7所示,经过2-gram特征提取的LDA模型的主题分布及其单词分布.

图7 2-gram的主题分布及其单词分布Fig.7 The distribution of topic and word
3 性能分析
从德国Göttingen大学的Drebin项目恶意样本库中选取了473 个恶意应用,并且从googleplay商店下载了340 个应用,默认这些应用是非恶意的,与恶意样本组成样本库.样本库中的样本经过预处理选取,均适合进行实验研究.每个样本提取动态特征都需要花几分钟的时间.
3.1 评价指标
为了准确地评估实验结果,采用混淆矩阵对实验结果进行分析.由于笔者主要是为了检测恶意应用,因此将恶意应用定义为正元组,而非恶意应用定义为负元祖,如表1所示.

表1 混淆矩阵Table 1 Confusion matrix
表1中:TP(True positive)表示实际恶意应用正确预测为恶意应用的个数;FP(False positive)表示实际正常应用错误预测为恶意应用的个数;FN(False negative)表示实际恶意应用错误预测为正常应用的个数;TN(True negative)表示正常恶意应用正确预测为正常应用的个数.
根据混淆矩阵计算出的分类器评估结果,主要选用的检测指标为
2) 命中率TPR(True positive rate):TPR=TP/(TP+FN).
3) 误报率FPR(False positive rate):FPR=FP/(FP+TN).
4) 精确度Precision:Precision=TP/(TP+FP).
5) 召回率Recall:Recall=TP/(TP+FN).
6)F-Measure:F-Measure=2·Recall·Precision/(Recall+Precision).
3.2 实验分析
3.2.1 序列文本的主题模型的实验结果与分析
笔者选用Naïve bayes算法、KNN算法、PART算法、J48算法和Random forest算法,对序列文本分别进行主题模型建模以及未建模实验,并且利用通用的十折交叉验证法测试算法准确性.表2展示了直接对序列文本进行实验的分类结果.
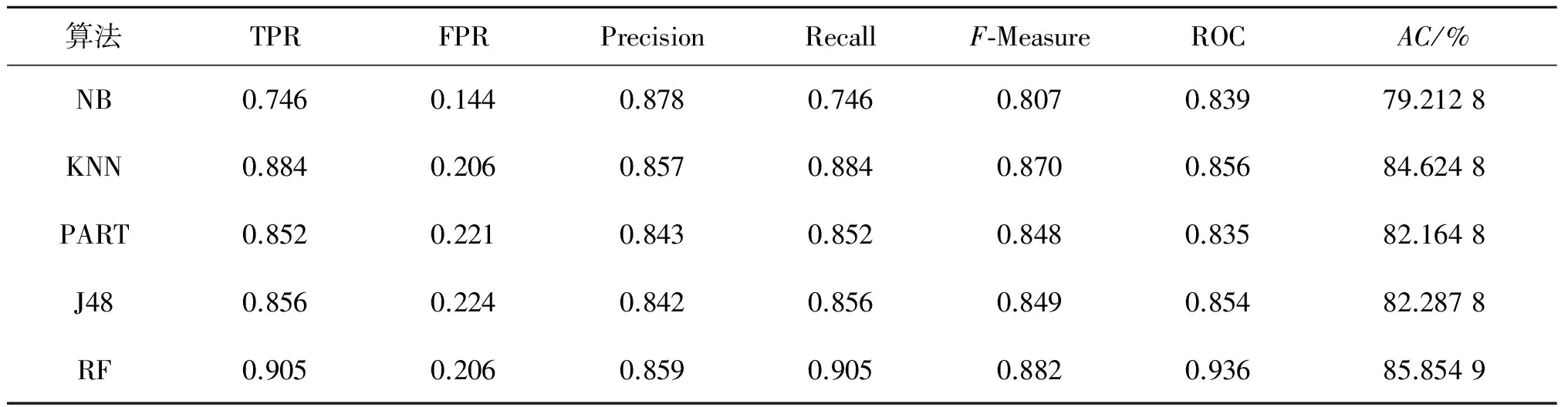
表2 序列文本的分类结果Table 2 The classification results of sequence
对于主题模型的建模,设定参数ɑ=1,β=1,主题数=50.表3显示经过主题模型建模的特征的分类结果.
从表2,3的实验对比结果可知:序列文本进行主题模型建模后的分类效果基本上好于直接对序列文本作分类的效果,除了Naïve bayes算法.在两种分类结果中,Random forest算法在各个指标上都要优于其他算法,并且在对主题模型的分类中有所提升,准确度达到90.28%,而Naïve bayes算法的准确度都不太理想.综上所述,笔者将在后面的实验中选用Random forest算法作为主要的分类算法.
为了更好地研究3个模型参数ɑ,β和主题数对实验结果的影响,将对3个参数做3组实验.每一组实验都需要固定一个参数,对其他两个参数进行评估,如表4所示.

表4 三组实验的参数Table 4 The parameter of three experiments
图8显示不同的参数设置对实验结果的影响.
由图8(a)的实验结果可知:ɑ的取值对实验结果影响不大,但主题数=5时准确度有所下降,其他结果准确度基本维持在90%上下.由图8(b)的实验结果可知:β取值越高,结果的准确度越低,尤其β=100,ɑ=0.01时,准确度很低.由图8(c)的实验结果可知:曲线整体呈下降趋势,与图8(b)的结果相同,β越高准确度越低,同时主题数过低时,准确度也不甚理想,这与实验图8(a)的结果相同.总结以上实验,将设置参数为ɑ=1,β=0.01,主题数=50,用于接下来的N-gram实验,这与经验所得的β=0.01,ɑ=50主题数的结果基本一致[8].
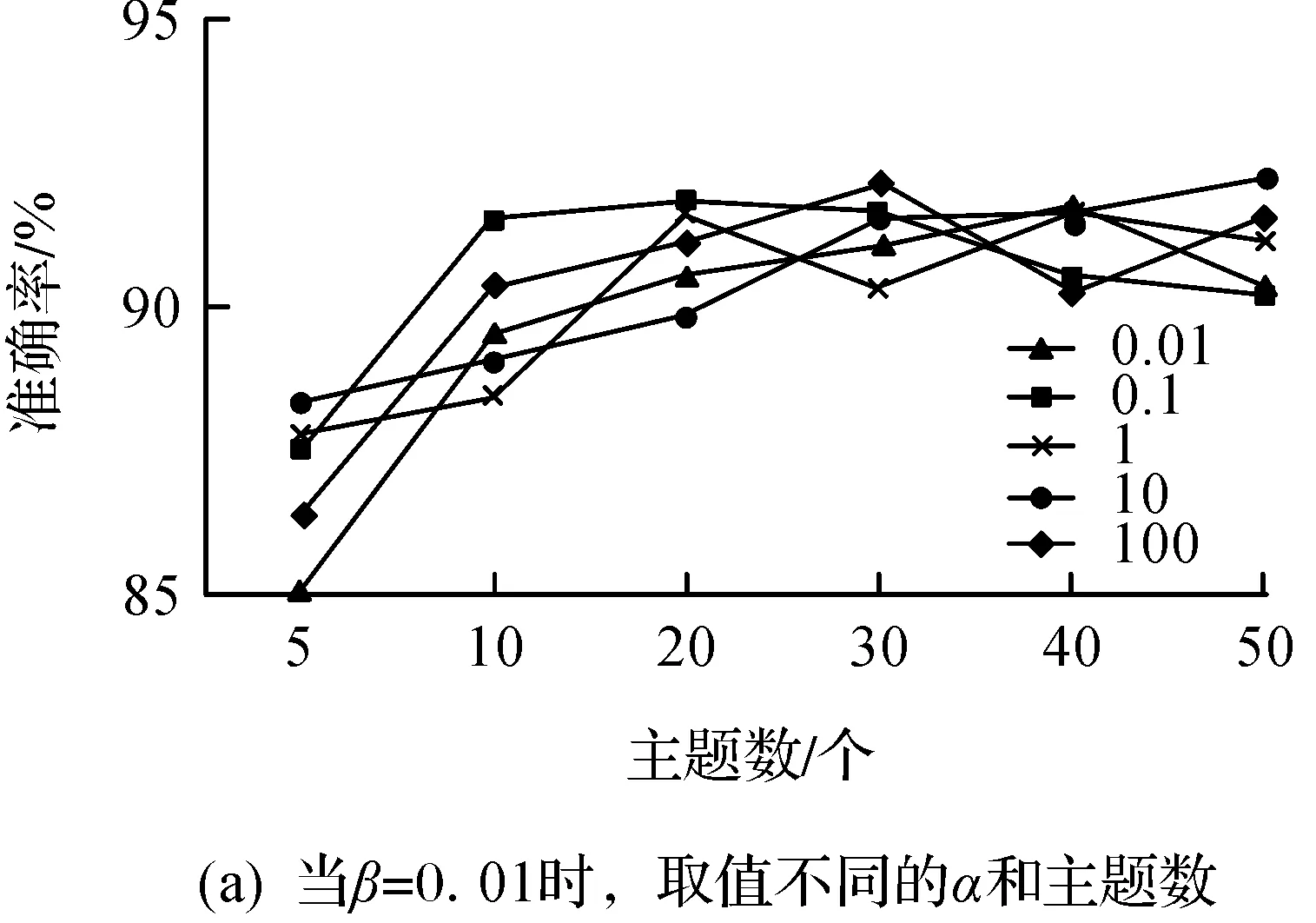
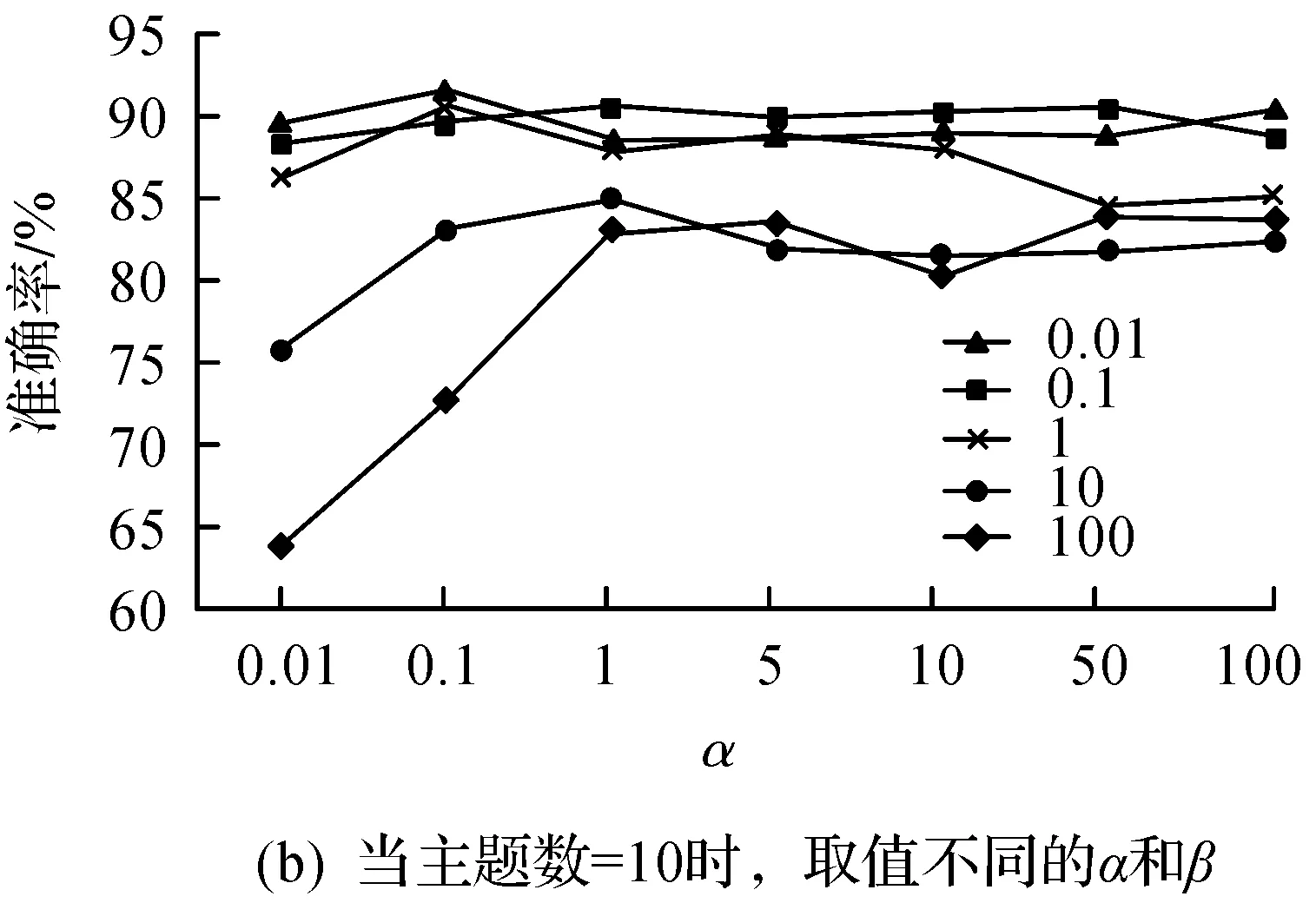
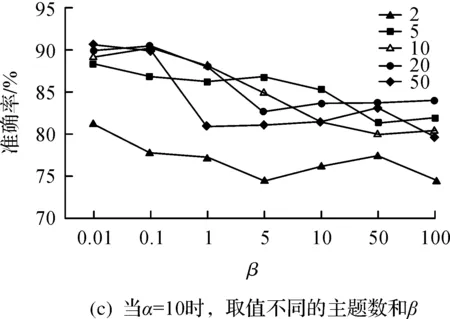
图8 模型参数对准确率的影响Fig.8 Influence of model parameters on accuracy
3.2.2 序列N-gram的主题模型的实验结果与分析
将样本集的API调用序列根据2-gram,3-gram,4-gram提取特征,并且使用主题模型进行建模,然后使用Random forest算法进行分类,采用十折交叉验证进行测试.如表5所示.
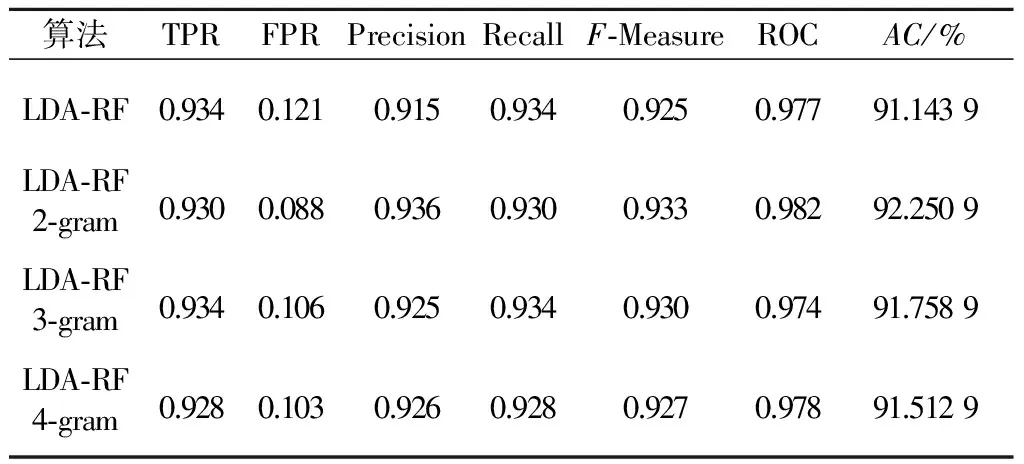
表5 基于N-gram序列的分类结果Table 5 The classification results of N-gram sequence
对比实验结果:2-gram的序列各个指标基本都要好于unigram序列;3-gram序列的TPR值与unigram序列持平,但FPR更优,即误报率更低,并且精确率和准确率较高;而4-gram序列的TPR值低于unigram序列,但误报率更低.总体上,基于2-gram序列的主题模型使用Random forest算法的效果最优.
为了研究样本数量对实验的影响,增加1 组1 771 个样本的数据集,其中838 个是正常应用,933 个恶意应用.基于2-gram序列并且用相同的参数对大样本集进行分类.结果如表6所示.不难看出:大样本集的综合评估指标要优于小样本集,样本数量越大综合表现越好.

表6 样本数量的对比结果Table 6 The comparison of sample size
4 结 论
提出了一个基于动态API调用序列的Android恶意代码检测方法,使用Xposed框架设计监控应用动态行为的模块,劫持得到API调用序列,并且对序列进行N-gram特征提取,引入主题模型对特征序列进行建模,最后用机器学习的分类算法进行分类.在实验中,通过对比实验,找到最优的参数设置以及模型算法,实验结果基本符合预期,并具有一定的检测能力.笔者方法依然有很多可以改进的方面:首先可以扩大样本集,研究更多的样本对实验结果的影响;然后可以进一步改进模型算法,去除噪声并更加准确地提取特征,从而提高检测准确率.
[1] 李挺,董航,袁春阳,等.基于Dalvik指令的Android恶意代码特征描述及验证[J].计算机研究与发展,2014,51(7):1458-1466.
[2] 卿斯汉.Android安全研究进展[J].软件学报,2016,27(1):45-71.
[3] SCHULTZ M G, ESKIN E, ZADOK E, et al. Data mining methods for detection of new malicious executables[C]//IEEE Symposium on Security & Privacy. Oakland: IEEE, 2001: 38-49.
[4] LIU W. Mutiple classifier system based Android malware det-ection[C]//Machine Learning and Cybernetics(ICMLC).Washington: IEEE, 2013:57-62.
[5] RASTOGI V, CHEN Y, ENCK W. AppsPlayground: automatic security analysis of smartphone applications[C]//ACM Conference on Data and Application Security and Privacy. San Antonio: ACM, 2013: 209-220.
[6] 杨欢,张玉清.基于多类特征的Android应用恶意行为检测系统[J].计算机学报,2014,37(1):16-27.
[7] BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. Journal of machine learning research, 2003(3): 993-1022.
[8] 张志飞,苗夺谦,高灿.基于LDA主题模型的短文本分类方法[J].计算机应用,2013,33(6):1587-1590.
[9] 马钲然,张博锋,王勇军.基于主题模型的网络异常行为分类学习方法研究[J].计算机科学,2016,43(9):57-60.
[10] 张家旺,李燕伟.基于N-gram算法的恶意程序检测系统研究与设计[J].理论研究,2016(8):74-80.
[11] 陈铁明,杨益敏,陈波.Maldetect:基于Dalvik指令抽象的Android恶意代码检测系统[J].计算机研究与发展,2016,53(10):2299-2306.
[12] 王万良,潘蒙.基于多特征的视频关联文本关键词提取方法[J].浙江工业大学学报,2017,45(1):14-18.
[13] 李锋刚,梁钰,GAO Xiaozhi,等.基于LDA-wSVM模型的文本分类研究[J].计算机应用研究,2015,32(1):21-25.
[14] 高雪,谢仪,侯红卫.基于多指标面板数据的改进的聚类方法及应用[J].浙江工业大学学报,2014,42(4):468-472.
