基于Spark的高效并行自动编码机*
2018-03-21庄福振钱明达申恩兆张大鹏
庄福振 钱明达 申恩兆, 张大鹏 何 清
(1.中国科学院计算技术研究所智能信息处理重点实验室,北京,100190; 2.燕山大学信息科学与工程学院,秦皇岛,066004)
引 言
机器学习作为人工智能的主体与核心,各种机器学习算法已经应用到各个领域,如语音识别、图片分类、推荐系统、手写输入识别和漏洞发现等,极大地提高了计算机智能化程度和各种系统的性能。实际应用中许多数据并不能很好地表示数据规律,甚至对系统的学习产生副作用,这就需要获得好的特征表示来改进算法的性能。然而随着计算机以及互联网的不断发展,信息量不断增大,信息复杂度也不断提升,数据包含的信息日益庞杂、冗余,良好的特征工程成为影响机器学习成败的关键因素。如何取得数据良好的特征表示,进而提升机器学习算法性能已经成为机器学习中一个关键的问题。
特征学习(Feature learning)又称作表示学习(Representation learning),是机器学习领域中的一个重要研究问题,它的目标是自动地学习一个从原始输入到新特征表示的变换,使得新特征表示能够有效应用在各种学习任务中,从而把人从繁琐的特征工程中解放出来。根据训练过程是否需要有标签数据,可以把表示学习算法分为两类:有监督特征学习和无监督特征学习。在有监督特征学习中,通常需要利用有标签数据,比如有监督字典学习。无监督特征学习中,不需要数据具有标签,比如主成分分析、 独立成分分析、 自动编码机、矩阵分解[1]以及众多形式的聚类算法[2-3]。
近几年来神经网络深度结构对特征的多层次抽象吸引了研究人员的广泛关注,深度学习模型在各类学习任务中都取得了不错的性能,且许多深度模型在实际应用场景中都表现良好[4-6]。自动编码机已经被证明在数据降维和特征提取上有着非常好的表现。目前自动编码机已经发展出众多变体,除了自动编码机外,还有稀疏自动编码机、降噪自动编码机、堆叠自动编码机及卷积自动编码机等[7-9]。此外神经元的屏蔽、正则化、边缘化等方法[10]都被运用于自动编码机。在应用上,异常检测中自动编码机取得良好效果,深度自动编码机也被运用到迁移学习中[11]。但以上的自动编码机都是串行实现,不能满足目前大数据环境下模型复杂、计算量大的实际问题。因此,单机串行实现的模型在应用层面具有很大的局限性。
随着大数据时代的来临,处理海量数据、建立大规模计算模型成为必然需求。本文提出了一种基于Spark的高效自动编码机,利用Spark分布式内存计算的固有优势高效处理海量数据。现有数据种类繁多,许多数据有非常稀疏的特点,比如推荐系统关系矩阵、文本词袋模型等。而现有基于自动编码机的特征提取算法没有对稀疏数据做针对性优化,计算过程中大量无效运算和存储空间开销使时间复杂度和空间复杂度随数据维度成二次甚至三次增长,与有效数据成指数级增长。本文编码算法是一种对稀疏数据针对性操作的优化方法,使得稀疏数据处理开销与有效数据成正比,极大优化了算法运行的时间效率和空间效率。
1 基于Spark的高效并行自动编码机
1.1 自动编码机的概念
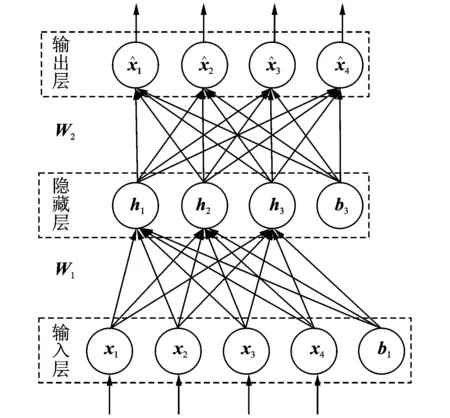
图1 简单的自动编码机结构Fig.1 Structure of a simple auto-encoder
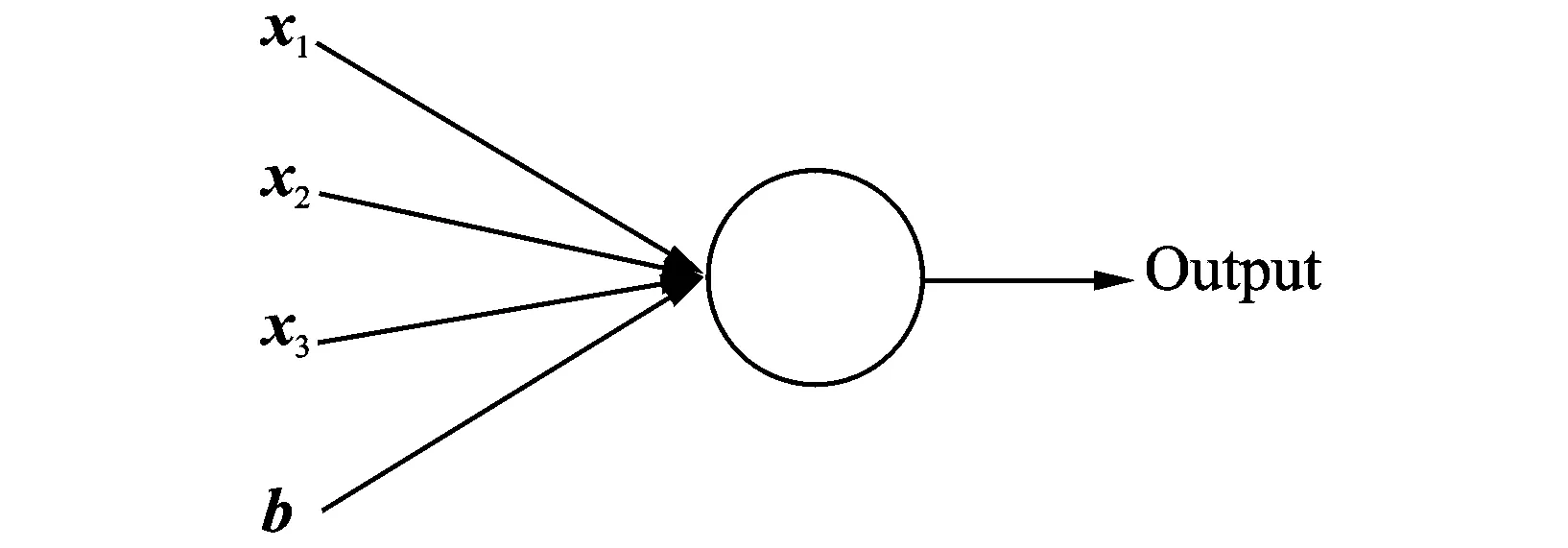
图2 神经元Fig.2 Single neuron
图1中的自动编码机,作为前馈神经网络,分别由输入层、隐含层和输出层组成。其中输入层为数据直接表示,隐含层和输出层中每个节点代表神经网络的一个神经元。神经元由上层网络输出的加权和通过激活函数得到输出,并提供下一层网络使用。神经元可以简单表示为如图2所示,激活函数一般为非线性函数,本文使用Sigmoid函数,其函数表达式为
(1)
一般地,一个自动编码机包括编码部分和解码部分。两部分可以概括为
1.2 Spark分布式计算平台
Apache Spark,2014年成为Apache基金顶级项目,以快速、通用、简单等特点成为当前流行大数据处理模型。Spark提出的分布式内存计算框架,既保留了MapReduce的可扩展性、容错性和兼容性,又弥补了MapReduce在这些应用上的不足。由于采用基于内存的集群计算,所以Spark在这些应用上相对MapReduce有100倍左右的加速[13]。此外Spark可以部署在Hadoop集群环境下,拥有直接访问HDFS文件系统的能力。但不同于MapReduce中间过程和计算结果需要读写HDFS,Spark将计算结果保存在内存中,从而不必频繁读写HDFS,减少了IO操作,提升了算法运行效率,使算法运算时间大幅缩短。
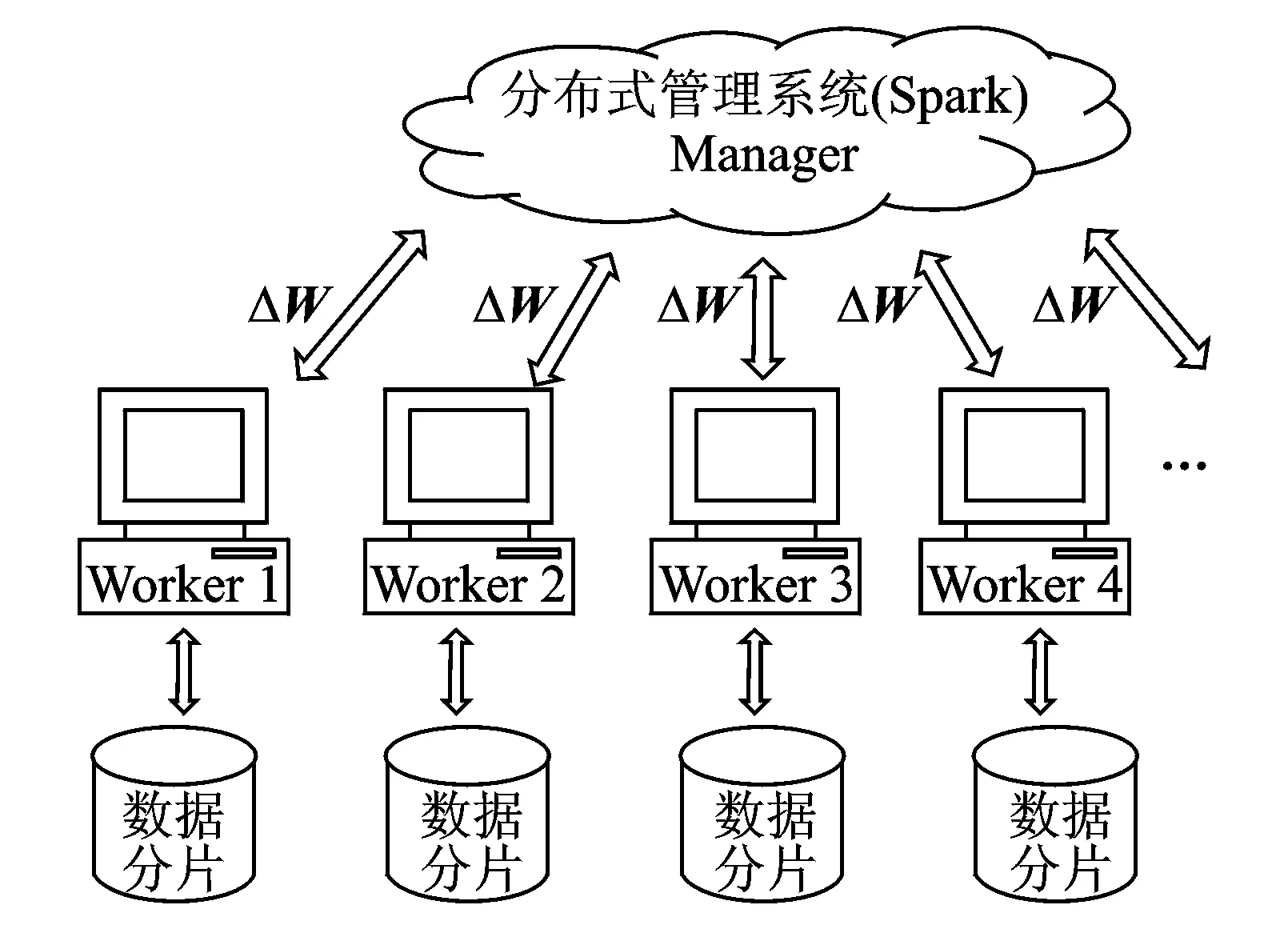
图3 系统结构图Fig.3 Structure of system
值得强调的是,分布式系统需要一个统一调度角色,一般称为管理者(Manager),而其他各运算节点称为工作者(Worker)。一般情况下,并行程序运行过程中由Workers分别计算相对独立的并行步骤,Manager统一调度、管理和统计。
1.3 基于Spark的高效并行自动编码机基本原理
基于Spark的高效并行自动编码机(Parallel auto-encoder,PAE)是对现有自动编码机完成针对稀疏数据的修改后,将其迁移到Spark计算平台上的成果。系统的结构包括一个负责分发Job、收集数据、调度任务的Manager以及若干个负责具体计算的Worker。系统结构如图3所示。图中,系统于分布式系统的各计算节点初始化同样的神经网络。每计算一定量的数据,对模型的参数进行收集归并,不断迭代得到最终权值。
上述过程基于神经网络的性质:相同初始值的神经网络,对同分布下不同数据样本进行拟合,最终所拟合数据分布相同,即得到网络参数分布相近。本文算法以此为基础,在初始化时保证网络完全一致,达到自动编码机并行运算的目的。
此外,本系统针对自动编码机低效处理稀疏数据的缺陷,提出避免计算过程中无效计算和无效存储开销的方案。使用指示器函数对算法进行改进,指示器函数为
通过指示器函数的选择,在计算中系统只关注有效值及其对应神经元,且反向传播时避免无效计算与操作。本文系统成功地将时间复杂度由二次复杂度降为线性复杂度,在保证计算正确性的前提下,大幅度提高了模型训练速度。
2 基于Spark的高效并行自动编码机算法
2.1 编码机算法模型
为实现基于Spark的高效并行自动编码机,本文选择反向传播来进行学习和优化,此外目标函数学习使用了梯度下降思想。另外,为提高算法运行效率,本文采用随机梯度下降算法,即计算每一条样本,实时更新学习模型。
当模型训练开始,Manager首先进行Map操作,将初始化参数分发至各Worker节点,包括数据规模、隐藏层配置、输入数据路径、正则化参数及随机数种子等。此后每个Worker独立读取数据,利用随机数种子分别初始化自动编码机的各项参数,其中由相同的随机种子保证各Worker上神经网络初始状态一致。
随后Worker分别利用各自数据分片训练自动编码机,Worker每次处理一条数据样本,将读入样本进行正向传播,即利用输入数据计算隐藏层和输出层的结果。完成后进行反向传播,利用得到的输出数据误差计算出神经网络的参数梯度。利用所得梯度,完成网络参数更新,至此完成模型的一次迭代。整个训练过程需要重复迭代,保证所分得数据分片中的每一例样本至少计算一遍。
各Worker利用一部分数据完成模型训练后,进行Reduce操作,将各节点计算结果进行约减。其中约减操作定义为Worker将计算所得模型参数上传至 Manager,由Manager对各参数取平均。至此完成系统的一次迭代。
对系统进行迭代,保证所有Worker均完全训练,至少保证训练集中所有数据均参与到系统模型的训练中。最终在Manager上得到一个训练完毕的模型。值得指出的是,实际操作中可以根据集群实际情况,对数据进行多种划分模式,包括但不限于差异化节点数目、节点间不同数据条数、各次迭代处理的数据条数以及系统整体对数据比例划分。
以上模型可具体表示为:
正向传播
h=sigmoid(W1x+b1)
(4)
(5)
反向传播
(6)
(7)
(8)
(9)
权值更新
W=W+φ(xinΔW-αW)
(10)
式(4~10)中符号表示含义如表1所示。

表1 公式符号含义
表中:N为输入数据样本数量;M为输入数据维度;K表示隐藏层节点目。
2.2 自动编码机的实现
根据2.1节描述可以实现基于Spark的高效并行自动编码机。Worker上随机梯度下降(Stochastic gradient descent,SGD)伪代码如算法1所示,基于Spark的高效并行自动编码机伪代码如算法2所示。
算法1随机梯度下降算法
输出:自动编码机学习到的参数W1,b1,W2,b2
For:对输入数据集中的每一个样本:
(1)根据式(4,5),进行正向传播。并计算网络中每个单元的输出;
(2)根据式(6,7),利用已求有输出分别求得网络各节点的残差;
(3)由式(8,9),利用已有残差分别计算网络模型各参数的梯度;
(4)按照式(10),更新自编码机权值。
算法2基于Spark的高效并行自动编码机
输出:自动编码机学习到的参数W1,b1,W2,b2
(1)初始化,由Manager根据Nworker将网络参数size,τ进行分发,并根据实际情况,将xin随机划分为若干部分,分别派发给Worker。Worker根据Manager下发的size来构建网络,τ来初始化矩阵;
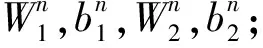
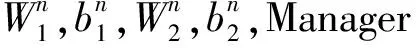
算法2流程如图4所示。由算法2得到的所有Worker上的参数,可以得到最终的模型参数。
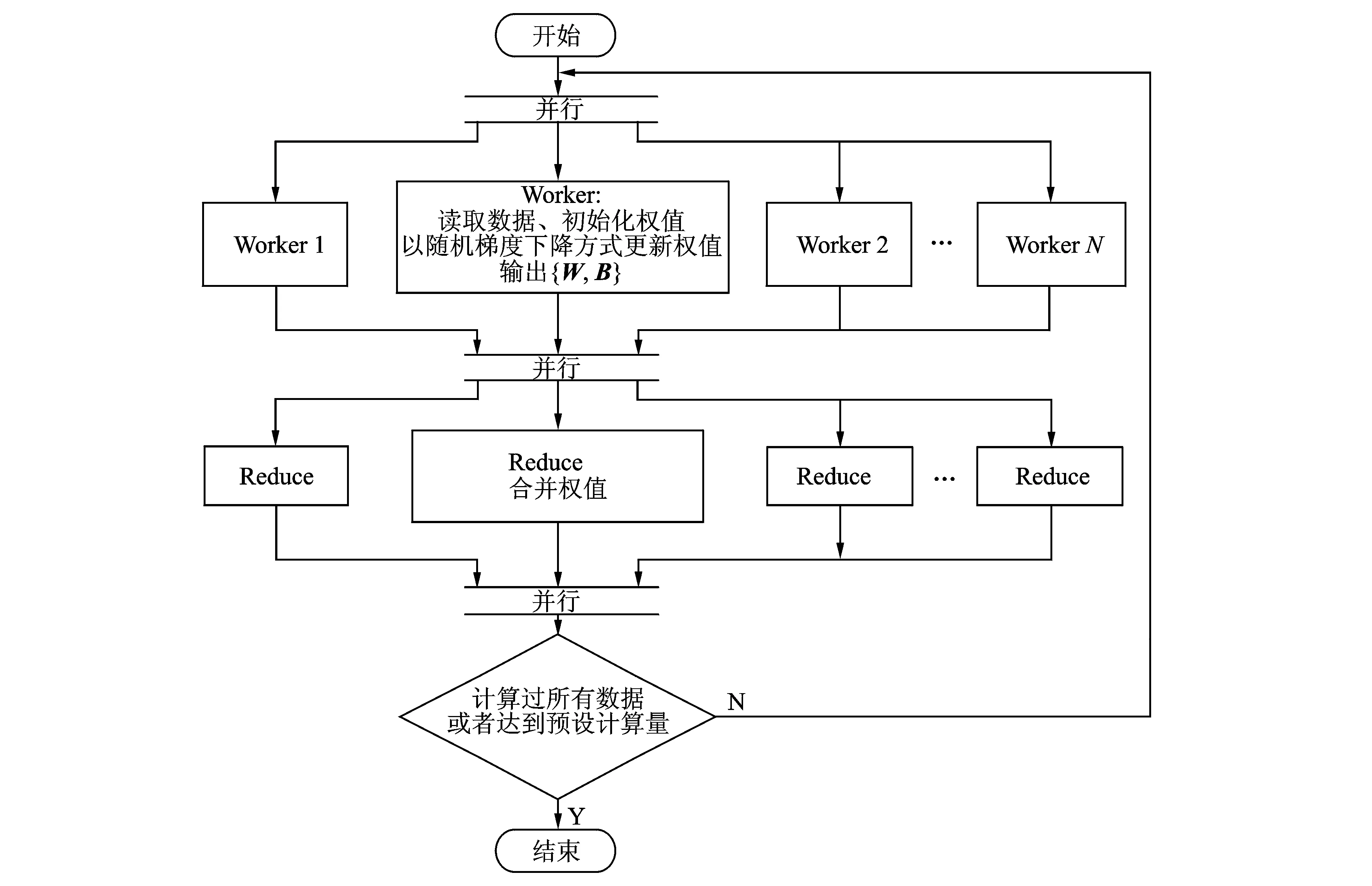
图4 基于Spark高效并行自动编码机Fig.4 Efficient parallel auto-encoder based on Spark
3 实验与结果分析
本节在两个学习任务上验证算法的有效性以及高效性,即分类任务和协同过滤。本文实验包括:(1)直接对源数据利用支持向量机(SVM)得到分类结果与PAE分类结果进行比较。(2)利用Matlab Deeplearning Tool(http://www.mathworks.com/matlabcentral/fileexchange/38310-deep-learning-toolbox)中SAE单机压缩数据后,再利用SVM分类结果与PAE得到的压缩数据分类结果进行比较,分别验证算法不同方面的能力和表现。其中SAE串行算法的有效性已经被众多事实所验证,公认其获得的特征可以有效提升机器学习算法性能,故而在此不再重复讨论。(3)将PAE应用到推荐系统中,得到推荐结果分别与基准算法进行比较,进而验证PAE在推荐系统中的有效性。
3.1 数据集和预处理
为了验证PAE算法的有效性和并行效率,本文采用文本数据集20Newsgroups(http://qwone.com/~jason/20Newsgroups/),该数据集包含20个主题,每个主题有大约1 000个样本文件,数据维度为61 188,数据以稀疏数据的方式存储。20个主题按照题材简单分类后如表2所示。为了构造分类问题,本文以文档主题作为分类预期结果,总共20类。
表2 20Newsgroups数据集主题
在PAE应用于推荐系统的实验中,本文基于两个个性推荐系统公共数据集MovieLens(http://grouplens.org/datasets/movielens/)和NetFlix(http://www.prea.gatech.edu/download.html)进行实验。
MovieLens是一套公共推荐系统数据集,数据为用户对自己看过的电影进行的评分,分值为1~5。显然,数据集中用户和电影构成的评分矩阵极度稀疏。数据集中包括3个不同大小的库,100 K数据集中包括1 000位用户对1 700部电影进行评分的100 000个评分记录;1 M数据集中包括6 000位用户对4 000部电影打分的100万条记录;10 M数据集中包括了72 000位用户对10 000部电影进行评分的1 000万条记录和10万标签记录。
NetFlix和MovieLens一样也是用户电影评分数据集,同样分值分布为1~5,但前者数据量远远高于后者。该数据集反映了自1998年10月到2005年12月期间的评分记录分布。NetFlix中包括了从48万名用户对17 000部电影的评分中随机选取的1亿条评分记录。此外还包括了电影的发行时间和发行标题。
3.2 特征表示学习
特征表示学习实验中主要分为两部分,分别验证PAE的有效性和高效性。
(1)在验证PAE有效性实验中,本文首先训练SVM分类器,得到源数据分类准确率基准值;随后由PAE在不同数目的Worker下对数据进行压缩降维,利用压缩后的降维特征训练分类器得到分类准确率。其中SVM作为基准分类器使用LibSVM[14]库。实验从所有数据中分别随机选取60%,70%,80%,90%作为训练集,剩下的作为测试集。为了保证分布式算法在不同节点情况下充分测试,本文分别测试了2,3,4个Worker的情况。
(2)本文也比较了Matlab Deeplearning Tool中SAE作为特征的提取方法。由SAE对数据进行降维压缩,得到的特征表示由SVM进行学习并构造分类器,通过测试集得出分类准确率。实验中利用自动编码机将原有61 188维稀疏数据提取特征降维到100维。为了验证PAE对海量数据处理性能,本文将18 774个样本的数据集进行扩展、复制,进而得到海量数据。通过海量数据测试将PAE与SAE进行对比,验证算法运行效率。
3.3 特征表示学习实验结果
3.3.1 PAE正确性分析
表3给出了PAE有效性实验的实验结果,所列数据均为5次实验平均值。表中还记录了不同数目的Worker下本文并行算法执行结果。由表3中结果可以看到,SVM分类准确率随着训练比的不断提高而提高,经过PAE降维后的数据在SVM分类器的表现普遍优于同训练比例的原始数据。这是由于原始数据维度非常高,通过降维可以得到更好的特征表示。实验结果证明了PAE提取特征的正确性和有效性。
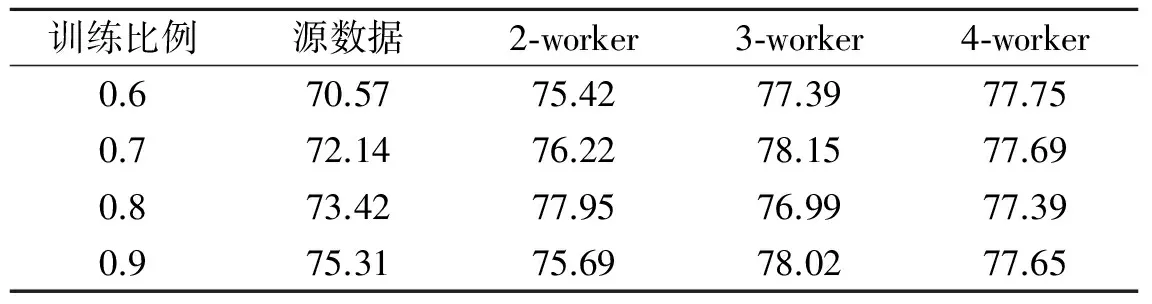
表3 SVM分类准确率
3.3.2 PAE效率分析
在保证正确性的情况下,与Matlab Deeplearning Tool中SAE做效率对比,同样地将源数据集由61 188维度压缩为100维度。SAE及PAE算法运行时间统计结果如图5所示。值得指出的是,SAE在数据量达到8 000条时,报出了内存不足的异常,亦即单机Matlab Deeplearning Tool中SAE处理数据的极限不足8 000条。并且由图5显示,SAE时间开销是随数据量的变化成二次变化。运行环境为:Intel CoreTMi7-4790 3.6 GHz CPU,8 GB 内存,500 GB 硬盘,操作系统为 Windows 7,64位专业版。
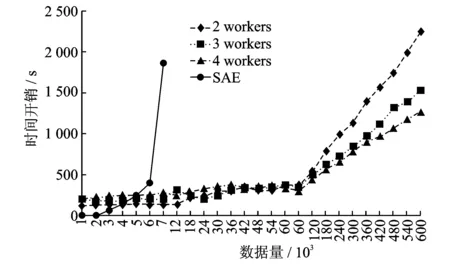
图5 SAE和PAE运算时间开销对比Fig.5 Time cost comparison between SAE and PAE
同样的数据,在PAE实验过程中设置不同的Worker数。由图5看到在数据量较小时,PAE时间开销相对较大,变化趋势与数据量并无明显联系,这是因为数据量较小时,分布式计算中平台通讯开销所占系统时间开销比例较大。随着数据量的不断增大,可以看出当数据量达到60 000条时,系统时间开销开始有明显的增长,此时系统的计算时间占比逐渐变大,计算时间的变化对系统总时间开销的影响开始显现出来。与单机运行SAE对比,首先PAE能够处理的数据量远远大于SAE;其次由图线对比得出,在数据量逐渐增大的过程中,系统时间开销随数据量增大而线性增长,相比SAE二次增长的时间曲线,具有明显优势。
3.4 PAE在推荐系统中的应用
在推荐系统的应用实验中,本文使用了非负矩阵分解(Non-negative matrix factorization,NMF)与概率矩阵分解(Probabilistic matrix factorization, PMF)作为与PAE比较的参考算法,其中NMF与PMF均来自于PREA[15]工具包。
个性化推荐算法工具包(Personalized recommendation algorithms toolkit,PREA)是一个个性化推荐算法的工具包,其中包括了大量推荐算法的实现,提供了便捷的接口可供调用。学术界提出的各种推荐算法常与它进行对比,验证准确率及效率。
在实验过程中,本文利用均值绝对误差(Mean absolute error,MAE)和均值平方根误差(Root mean squared error, RSME)作为衡量算法效果的度量值。实验中利用PAE分别以user和item作为维度坐标进行压缩降维。为表述方便本文将两种方法表示为PAEu和PAEi。不同算法5次实验结果的平均值如表4所示。
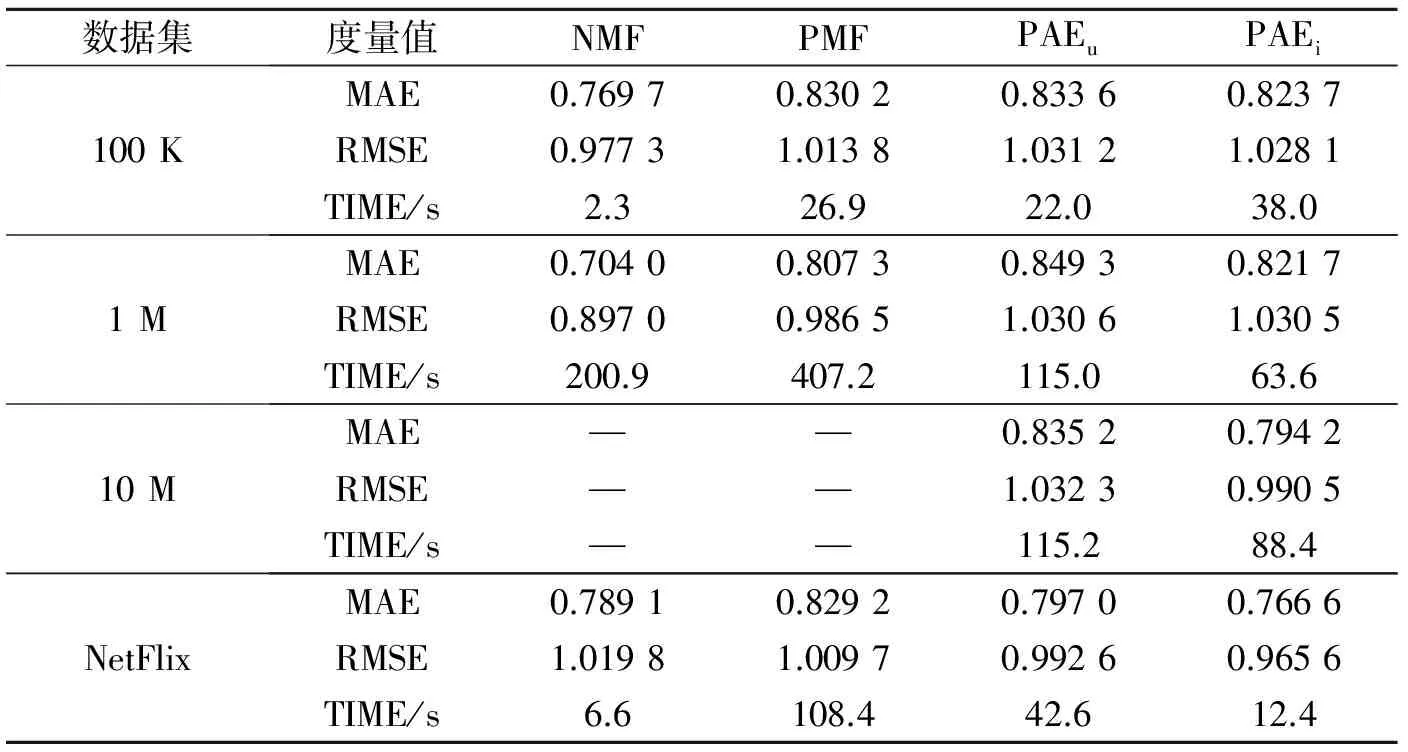
表4 推荐系统实验数据
由表4可以看出,当数据量较小时,在推荐结果的准确性和推荐效果的稳定性方面NMF表现相对较好,而且在算法运行时间上也有一定优势。但随着实验数据量的增大,NMF与PMF均出现了内存不足的情况,在基于海量数据推荐任务中,两种算法并不能很好地给出结果。而PAE的两种算法,尽管在准确性和稳定性方面稍弱于NMF和PMF,但可以应对海量数据的推荐任务。结果充分表明PAE可以应用于推荐系统中,特别是在海量数据下的应用场景。
4 结束语
本文提出了一种基于Spark的高效并行自动编码机。通过对自动编码机进行并行化,使之能够高效处理稀疏大数据,同时具备正常处理非稀疏数据能力。此外,将其迁移到Spark分布式平台,面向稀疏数据进行针对性优化,使其大幅减少IO操作,提升算法运行效率,算法运算时间明显缩短。本文做了大量实验来验证PAE的可行性与有效性,实验建立在两个实际应用任务上,其中分类任务验证了PAE的高效性和PAE对特征提取的有效性。在保证特征提取有效性的前提下本文将PAE应用在推荐系统中,利用自动编码机提取到的数据特征对原有数据进行填充预测,进而得出推荐结果,通过与对比算法的比较进一步验证本算法的有效性和高效性。
[1] Srebro N, Rennie J D M, Jaakkola T. Maximum-margin matrix factorization[J]. Advances in Neural Information Processing Systems, 2004,37(2):1329-1336.
[2] Coates A, Ng A Y, Lee H. An analysis of single-layer networks in unsupervised feature learning[J]. Journal of Machine Learning Research, 2011,15:215-223.
[3] Dance C, Willamowski J, Fan L, et al. Visual categorization with bags of key points[C]// ECCV International Workshop on Statistical Learning in Computer Vision. Prague:[s.n.], 2004:1-22.
[4] 卢宏涛,张秦川.深度卷积神经网络在计算机视觉中的应用研究综述[J].数据采集与处理,2016,31(1):1-17.
Lu Hongtao, Zhang Qinchuan. Applications of deep convolutional neural network in computer vision[J]. Journal of Data Acquisition and Processing, 2016,31(1):1-17.
[5] 李思雯,吕建成,倪胜巧.集成的卷积神经网络在智能冰箱果蔬识别中的应用[J].数据采集与处理,2016,31(1):205-212.
Li Siwen, Lü Jiancheng, Ni Shengqiao. Integrated convolutional neural network and its application in fruits and vegetables recognition of intelligent refrigerator[J]. Journal of Data Acquisition and Processing, 2016,31(1):205-212.
[6] 杨阳,张文生.基于深度学习的图像自动标注算法[J]. 数据采集与处理,2015,30(1):88-98.
Yang Yang, Zhang Wensheng. Image auto-annotation based on deep learning[J]. Journal of Data Acquisition and Processing, 2015,30(1):88-98.
[7] Le Q V, Ranzato M A, Monga R, et al. Building high-level Ieatures using large scale unsupervised learning[C]//Proceedings of the International Conference on Machine Learning (ICML). Edinburgh, UK:[s.n.],2012:107-114.
[8] Vincent P, Larochelle H, Bengio Y, et al. Extracting and composing robust features with denoising autoencoders[C]//Proceedings of the 25th International Conference on Machine Learning. Canada:[s.n.], 2008:1096-1103.
[9] Gupta A, Maida A S, Ayhan M. Natural image bases to represent neuroimaging data[C]//30th International Conference on Machine Learning. Atlanta, Georgia, USA: International Machine Learning Society, 2013:987-994.
[10] Chen M, Xu Z, Weinberger K, et al. Marginalized denoising autoencoders for domain adaptation[J]. Computer Science, 2012: 2012arXiv1206.4683C.
[11] Zhuang F, Cheng X, Luo P, et al. Supervised representation learning: Transfer learning with deep autoencoders[C]//Proc of the 24th International Joint Conference on Artificial Intelligence. Buenos Aires, Argentina: AAAI Press, 2015:4119-4125.
[12] Bengio Y. Learning deep architectures for AI[J]. Foundations & TrendsR in Machine Learning, 2009,2(1):1-127.
[13] 黎文阳.大数据处理模型Apache Spark研究[J].现代计算机:普及版,2015(8):55-60.
Li Wenyang. Research on apache spark for big data processing[J]. Modern Computer, 2015(8):55-60.
[14] Chang C C, Lin C J. LIBSVM: A library for support vector machines[J]. ACM Transactions on Intelligent Systems & Technology, 2011,2(3):389-396.
[15] Lee J, Sun M, Lebanon G. PREA: Personalized recommendation algorithms toolkit[J]. Journal of Machine Learning Research, 2012,13(3):2699-2703.
