基于多因子选股的半监督核聚类算法改进研究
2018-03-20李文星李俊琪
李文星,李俊琪
(暨南大学 经济学院,广东 广州 510000)
一、引 言
伴随着中国经济高速发展和资本市场的不断扩展,广大个人与机构投资者对于股票选取方法的需求呈现出日益增长的趋势。在众多选股的模型中,多因子选股模型被广泛应用,其原理为选取股票的某些因子,当股票因子值满足设定的标准则买入,否则卖出。通常来说,多因子选股模型结果的好坏取决于两个方面,一是因子的选取,二是模型的设定。本文重点阐述多因子选股的模型设定。
多因子选股的模型主要分为有监督选股模型及无监督选股模型两大类。股票样本数据多为无标签数据,在选股过程中处理无标签数据主要有两种方式:一种是人为设定标签,使用有监督模型对股票样本进行分类,其特点为模型分类结果相对准确,但运算量巨大,模型回测过程耗时过长;另一种是通过无监督方法对样本进行分类,其主要通过K-means聚类的方法来实现,该方法选股的特点是运算量相对较小,回测速度快,缺点是准确率相对较低。本文使用半监督K-means核聚类的方法,首先对少量股票的历史数据进行分类,确定部分带标签样本,然后对当前股票数据进行分类预测。
在聚类方法研究的过程中,K-means算法最早是在1967年由Macqueen提出并用数学方法进行证明[1],由于其计算时间短、容易解释、聚类效果较好等优点而被广泛使用。然而,K-means聚类方法的聚类效果严重依赖于初始值的选择情况,当初始值选择不恰当时,模型容易达到局部最优,无法实现预期效果,因此在实际运用中需要改进算法。
在聚类的改进过程中,有学者发现,大量未标签的数据相对容易获取,而标签的数据则难以得到[2]。显然,如果只使用少量的有标识示例,那么利用它们所训练出的学习系统往往很难具有强泛化能力。另一方面,如果仅使用少量“昂贵的”有标识示例而不利用大量“廉价的”未标识示例,则是对数据资源的极大浪费。半监督聚类是指利用少量标识数据或其他先验知识来指导无监督学习,同时监督学习利用无标识数据辅助标识数据进行训练学习,从而达到更好的分类。传统的无监督K-means算法由于没有完全使用有标签数据信息,对信息造成极大的浪费,并且对初始值的选择容易达到局部最优。不少学者对K-means改进时引入半监督,2001年Wagstaff等人在K-means里引入了成对约束[3],Basu等人同时提出半监督聚类框架构想[4]。尹学松等人在2008年提出基于成对约束的判别型半监督聚类来解决成对约束和高维数据问题[5]。袁利永和王基一提出带引力参数的半监督K-means聚类来提高模型处理样本非球状簇的能力,解决非球状簇能力差的问题,从而提高聚类的性能[6]。这些文献各自引入不同的半监督聚类方法提高模型的分类性能。然而,当被分类样本分布为线性不可分时,模型的分类效果依旧差强人意。因此,本文引入基于引力影响因子的半监督K-means聚类方法,并结合核函数理论,对股票样本矩阵进行聚类。
在多因子选股的过程中,股票样本向量矩阵往往存在高维性、集群性、样本线性不可分等问题,传统的统计方法很难将股票样本进行有效分类。当前,解决此类问题的方法通常是引入核函数理论,通过核函数将股票样本向量矩阵投影到高维空间,使用非线性方法来分割样本,得以充分提取股票信息。核函数最早应用在支持向量机,随着核函数在处理样本非线性分布问题上取得巨大优势,张莉等人将Mercer核应用到聚类分析,并证实核聚类方法的可行性和有效性[7]。之后核聚类理论被广泛应用,赵晖等提出基于模糊核聚类的多类分类方法,推广了核聚类在分类上的应用[8]。传统的单个核函数性质通常只具备全局性或局部性,核函数模型无法同时具备较强学习能力和泛化能力[9]。混合核函数通过将不同特性的核函数组合在一起,对不同核函数性质进行综合,一定程度上改善了模型提取信息的能力。由于混合核函数方法并没有解决核函数的选择问题,只是将问题等价转换为权重参数的选择,同时该方法还需要分别对两个核函数确定参数,大大增加了算法的复杂程度,限制了模型的泛化能力。黄啸将修正的高斯核函数与传统核函数性质进行对比,得出该核函数同时具备较强的泛化能力及学习能力[10],修正的高斯核函数在不提高算法复杂程度的基础上,极大改善了单个核函数的性质。
本文引入修正的高斯核函数理论,通过将核函数与基于引力影响因子的半监督K-means聚类方法相结合,模型在处理线性不可分及分布非球状簇的股票样本向量中具有较好的聚类效果。
二、半监督K-means算法的局限
(一)半监督K-means算法
K-means算法具有计算时间短、容易解释、聚类效果较好等优点。然而,K-means聚类方法的聚类效果严重依赖于初始值的选择情况,当初始值选择不恰当时,模型容易达到局部最优,无法实现预期效果。当样本分布为非球状簇时,基于马氏距离计算样本相似度的K-means算法也很难得到较好的聚类效果。半监督K-means算法能充分利用少量的有标识样本信息,将有标识样本作为初始值,避免了K-means算法局部最优的情况,并在一定程度上提高了K-means算法在处理非球状簇分布样本的能力。
袁利永等人在K-means聚类算法的基础上,提出了基于引力影响因子的半监督聚类算法,该算法引入由少量带标签样本形成的seed集,并假设seed集中包含有K个类,形成K个初始聚类中心,同时考虑到已分类样本对未分类样本的引力影响,构造出引力影响矩阵[6]。
(二)带引力参数的半监督K-means聚类算法优劣点
带引力参数的半监督K-means聚类算法充分使用了已标签样本信息,具有较高的聚类效果。在样本初始值选择过程中使用已标签的K类样本数据的中心点作为K个初始中心进行聚类,很大程度上避免了无监督K-means聚类方法中出现的局部最优的情况,并且该方法在目标函数中引入引力参数因子,在聚类过程中不仅考虑到待分类样本与已知类中心的距离,而且还利用已分类样本对于待分类样本的引力作用。模型在处理非球状簇分布样本具有一定的效果,同时适用于空间分布为椭球形簇或凹凸面球形簇的样本。然而在多因子选股的过程中,股票样本向量矩阵通常具有高维、线性不可分等特点,该方法对线性不可分样本的聚类效果较差,引力参数的引入只能对样本分布为类球状簇样本具有较好效果,其目标函数的本质仍然是基于马氏距离计算的样本相似度,对于非线性可分的样本聚类效果不明显,对股票因子信息难以做到充分提取。当前,解决此类问题的方法通常是引入核函数理论,通过核函数将样本向量矩阵投影到高维空间,在高维空间中对样本进行聚类,使用非线性方法来分割原始空间样本,得以充分提取文本信息。然而,传统的单个核函数性质通常无法同时具备全局性或局部性,核函数模型无法同时具备较强学习能力和泛化能力。近年来很多学者通过研究混合核函数来优化单一核函数的缺陷,通过将不同特性的核函数组合在一起,对不同核函数性质进行综合,一定程度上改善了模型提取信息的能力。但由于混合核函数方法并没有解决核函数的选择问题,只是将问题等价转换为权重参数的选择。同时该方法还需要分别对两个核函数确定参数,大大增加了算法的复杂程度,限制了模型的泛化能力。本文引入修正的高斯核函数理论,在不增加算法复杂程度的前提下,可以极大改善单个核函数的性质。
三、半监督K-means算法的改进
半监督K-means的改进主要通过引入核函数理论并在此基础上对核函数进行修正,使得原始模型在处理样本线性不可分、样本分布非球状簇等问题中具有较高效率,同时,使得模型具有较强的泛化能力与学习能力。
(一)核函数
核函数理论出现已久,Mercer定理可追溯到1909年再生核理论[11],Hilbert理论是20世纪40年代发展起来的[12],但是,直到Boser等人将之用于支持向量机之前[13],其重要性没有受到充分重视。所谓核函数就是存在一种非线性变换φ(·),使得K(xi,xj)=φ(xi)·φ(xj)成立,核函数的引入使得统计模型在处理非线性问题上具有较大的优势。核函数通过将线性不可分样本投影到高维空间,使样本在高维空间中线性可分,即核函数将原始空间样本隐含地表示到高维Hilber空间,并在高维特征空间中训练一个线性分类器,并且在训练过程中不需要知道具体的非线性映射,这个过程称为核映射过程。
任何满足Mercer定理的函数都可以作为核函数[11],目前研究最多的核函数主要有三类:
第一,多项式核函数
K(xi,xj)=[(xi·xj)+η]q
(1)
第二,高斯核函数
(2)
第三,Sigmoid核函数
K(xi,xj)=tanh(υ(xi·xj)+c)
(3)
其中q、σ、c、η皆为常数,在实际运用过程中,根据具体问题确定各个参数的取值。
多项式核函数及Sigmoid核函数具有全局性的特点,具体表现为测试样本离训练样本的距离较远的点对核函数的值产生影响较大,具有较强的泛化能力。高斯核函数具有局部性的特点,相互之间距离较近的数据点对核函数值影响较大,距离较远的点对核函数值影响较小,具有较强的学习能力。
图1为高斯核函数图,通过调整σ取值可以使得核函数宽度发生变化,σ值越小,核函数越宽。当样本点靠近输入测试点时,核函数值较大且接近于1,随着样本点离输入测试点越来越远,核函数值趋于无穷小,在进行内积运算时这部分所对应的数据相当于被截断了,造成了信息的丢失。因此,高斯核函数学习能力较强,泛化能力较弱。
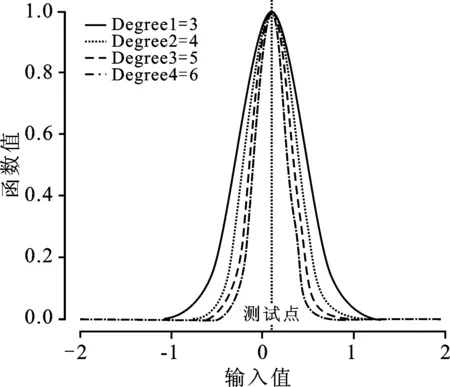
图1 高斯核函数
图2为多项式核函数曲线,输入的测试点不同,核函数平缓程度会发生变化,随着测试样本取值增加,核函数变量越来越陡峭。并且,样本点与输入测试点距离较大时,多项式核函数值逐渐增大,并将趋于无穷。因此,多项式核函数具有较强的泛化能力,但学习能力较弱。
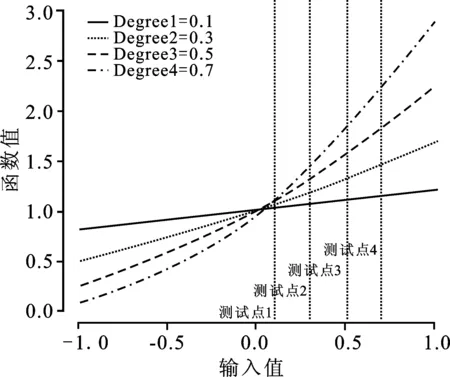
图2 多项式核函数
高斯核函数将样本向量映射到高维特征空间中,会使得样本点变得非常稀疏,要改变这一特性必须满足两个条件,第一是在测试点附近有较快衰减,第二是在无限远处仍保持适度衰减。本文基于核函数理论,引入了一种修正的高斯核函数[10],其表达式为:
(4)
其中,σ是核函数的带宽变量,γ为位移参数,λ为微调参数变量,该核函数兼具全局性核函数与局部性核函数的性质。通过修正后的高斯核函数可知,当样本点接近于测试点时,函数取值较大;离测试点越远,则函数取值越小。σ值为函数带宽变量,通过控制σ值可以灵活地控制函数的带宽,且σ取值越大函数图像带宽越小。γ的取值主要影响的是核函数的“胖瘦”程度;γ取值越大,核函数图形越“胖”。λ为微调参数,该参数能够确保随着输入值与测试值的距离增加,核函数值不会趋于无穷小。相较于原始的高斯核函数,在方差σ相同的情况下,修正的高斯核函数具有较大的峰度,距离较近的点对核函数影响较大,随着距离增加,该核函数值会迅速衰减,但不会趋于无穷小,该核函数兼顾较强的泛化能力和学习能力。
从图3可知,相比于原始高斯核函数,修正的高斯核函数样本点在离测试点较近的区域,函数值衰减较快,在离测试点较远的区域,修正的高斯核函数的函数值衰减速度相比于原始的高斯核函数要慢很多。通过调整修正后的高斯核函数的参数γ,可以灵活控制函数值的衰减速度。修正后的高斯核函数能够在一定程度上弥补原始高斯核函数值在无限远处趋于无穷小的不足。因此,修正后的高斯核函数同时具备了较强的泛化能力和学习能力。
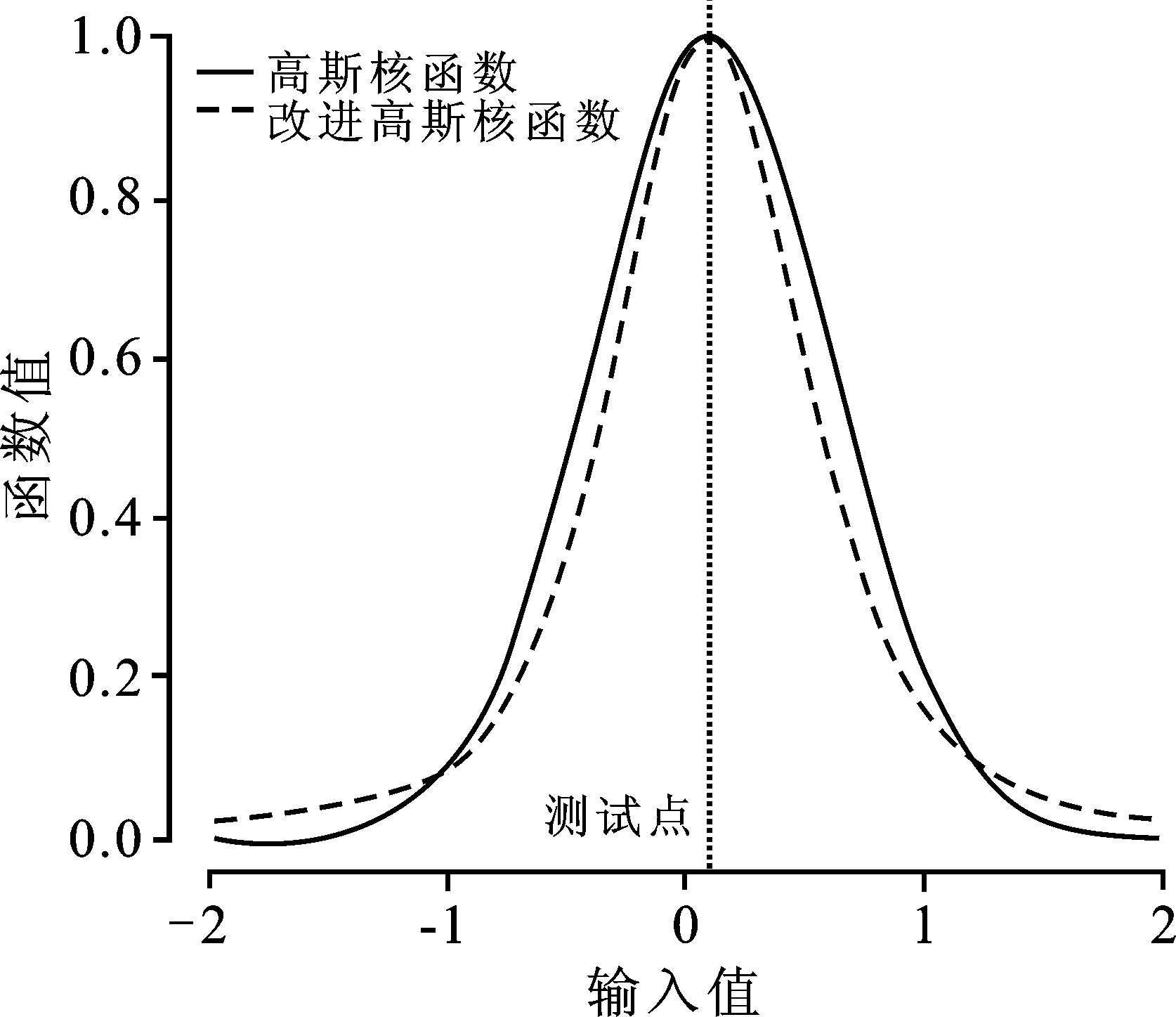
图3 修正后的高斯核函数
(二)改进的半监督K-means核聚类
改进的半监督K-means核聚类将修正后的高斯核函数用于样本之间相似度的测量,使得半监督K-means聚类方法在处理线性不可分样本时具有较好的效果。
本文基于带引力参数的半监督K-means聚类算法,通过引入修正后的高斯核函数算法,使得新的模型在处理模型局部最优、样本分布为非球状簇及样本线性不可分等问题上具有较好的效果。改进半监督K-means核聚类算法主要基于以下两个方面考虑:第一,在引力影响因子计算过程中引入核函数。引力影响因子算法通过引入核函数,使得已标签样本能以一种非线性的方式计算其与待分类样本之间的相似度。第二,在计算待分类样本与类中心相似度过程中引入修正后的高斯核函数算法。使用核函数将待分类样本点与类中心映射到高维特征空间,在高维特征空间中使用线性判别的方法计算样本点与类中心相似度,从而使得样本点能够在源空间中进行非线性分割。改进的半监督K-means核聚类引力影响因子计算公式为:
GF(xi,Cj)=
(5)
其中GF(xi,Cj)表示给定类别Cj对样本点xi的引力影响大小;L表示已标签数据,将其分成K类C1,C2,…,Ck;Lj为Cj内带标签的样本集合;xk为Lj内的一个向量元素;k(xi,xk)为样本xi,xk投影到高维特征空间的向量积,即样本xi、xk之间的核函数值;k(xi,xk)通过将样本xi、xk投影到高维特征空间并计算其内积来得出样本间的相似性度量。若xi亦为带标签样本且属于Lj类,则给定类别的Cj对样本点xi的引力影响大小为1,反之为0。引力影响度计算公式为:
(6)
其中GD(xi,Cj)为给定类别的Cj对数据点xi的引力影响与所有类别对xi引力影响之和的比值。
(7)
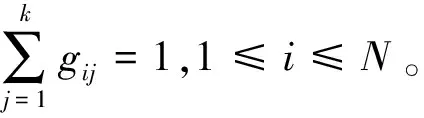
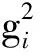
(8)
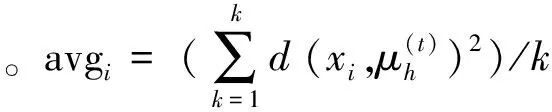
四、实验结果与对比
(一)实验数据说明
为了验证本文改进后的算法,参考《再论多因子选股策略》中因子选取方法[14],从A股市场所有上市公司2004年1月30日至2017年3月31日的规模因子、估值因子、成长因子、盈利因子、动量反转因子、交投因子、波动因子、股东因子、分析师因子中选取了总市值、资产收益率、月换手率、月波动率、营业收入同比增长率、市盈率、预测因子、前一个月涨跌幅、机构持股比例、户均持股比例变化的月度数据,以及股票收益率的月度数据。历史数据月度股票收益率前5%标志为1,后5%标志为-1,中间部分标志为0,构造出带标签的样本数据见表1。
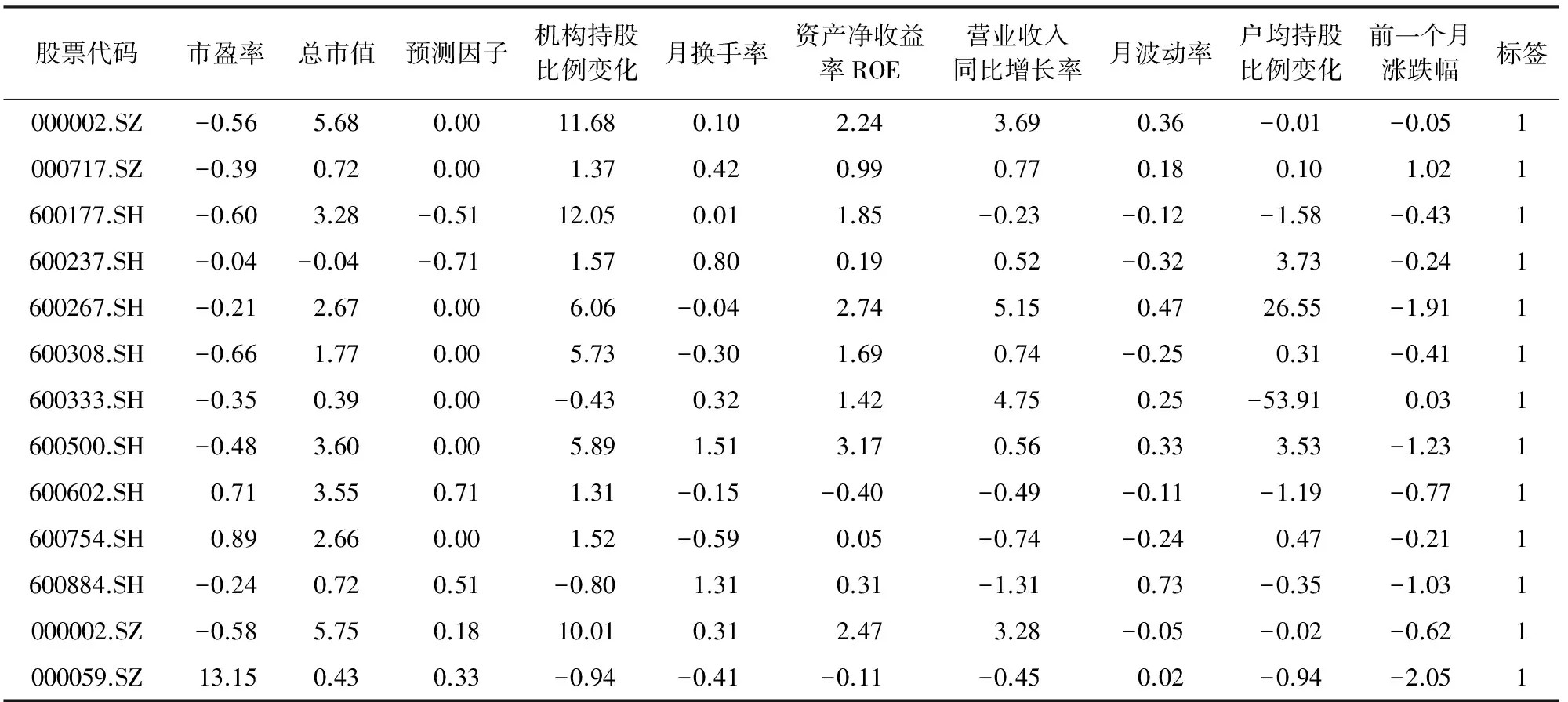
表1 部分股票样本实例
注:数据来源于万德数据库。
(二)实验数据预处理及模型参数优化
股票样本数据预处理包括行业中性化处理及剔除缺失值。当样本中存在缺失值时,对样本进行剔除处理。行业中性化处理是指根据A股市场每家公司所属行业类别,将同行业企业选出来,求出因子的中位数取值,然后用因子值减去中位数再除以中位数。因子行业中性化处理使得不同行业之间因子值具有相同的量纲,因子之间具有可比性。
在多因子选股回测过程中以过去12个月的股票样本数据作为带标签数据,当前月份数据为无标签数据,带入模型以便对当前月份股票样本进行分类。在回测过程中,模型参数的取值极大程度上影响模型选股的优劣,模型参数的取值是模型选股的关键。本文运用10折交叉验证法选出最佳模型参数,在每次模型运算过程中将过去12个份股票样本随机分为10等分,每次验证中以其中一份为训练集,其他为测试集,依次循环进行10次,使得每一等份都作为测试集,然后计算10次结果的平均准确率,以最大平均准确率对应的参数为最优参数带入模型。
(三)实验数据模型对比
本文根据实验数据进行3个方面的聚类对比,为了验证传统半监督聚类模型选股的优劣,本文首先将多因子选股模型设定为传统的半监督聚类模型,对股票样本数据进行聚类,然后依次将模型设定为半监督核聚类算法及改进的半监督核聚类算法,其模型回测部分结果如表2所示。
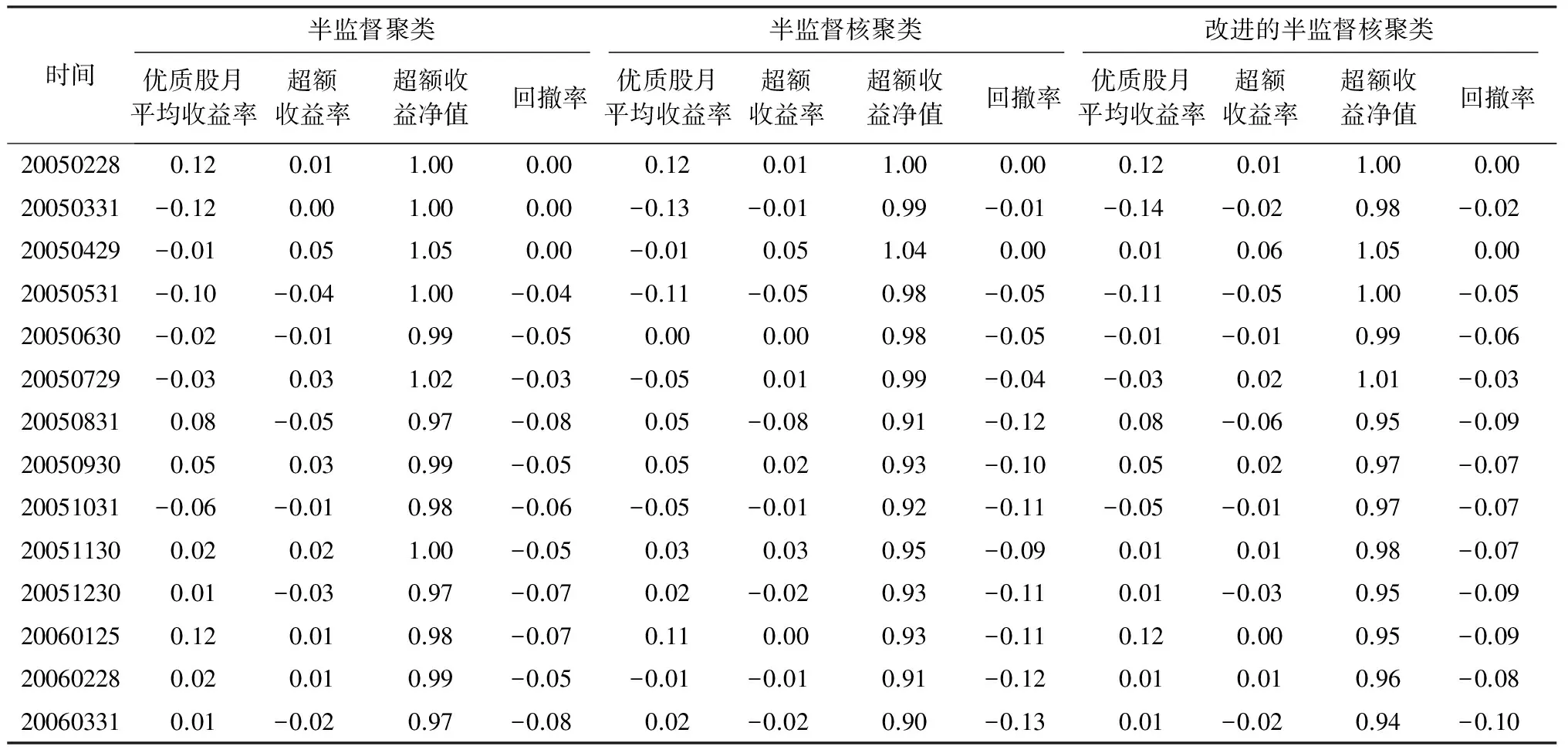
表2 模型回测部分结果
如表2所示,模型输出的结果包括回测过程中模型选取优质股票的月度平均收益率,对冲中证500后的超额收益率,根据超额收益率求取的超额收益净值以及体现模型风险水平的回撤率。
图4为不同模型选出股票的超额收益净值,横坐标表示时间,纵坐标表示收益率。前期各个模型选出股票组合收益率相差较小,各个模型超额收益净值曲线几乎重合,随着时间的推移,改进模型的超额收益净值逐渐显现优势,最终明显高于其他水平。半监督聚类模型的收益率水平为9.78,半监督核聚类模型的收益率水平为9.98,改进的半监督核聚类模型的收益率水平为11.94。单从模型的收益率水平而言,改进的半监督核聚类模型的效果明显要好于其他两个模型。
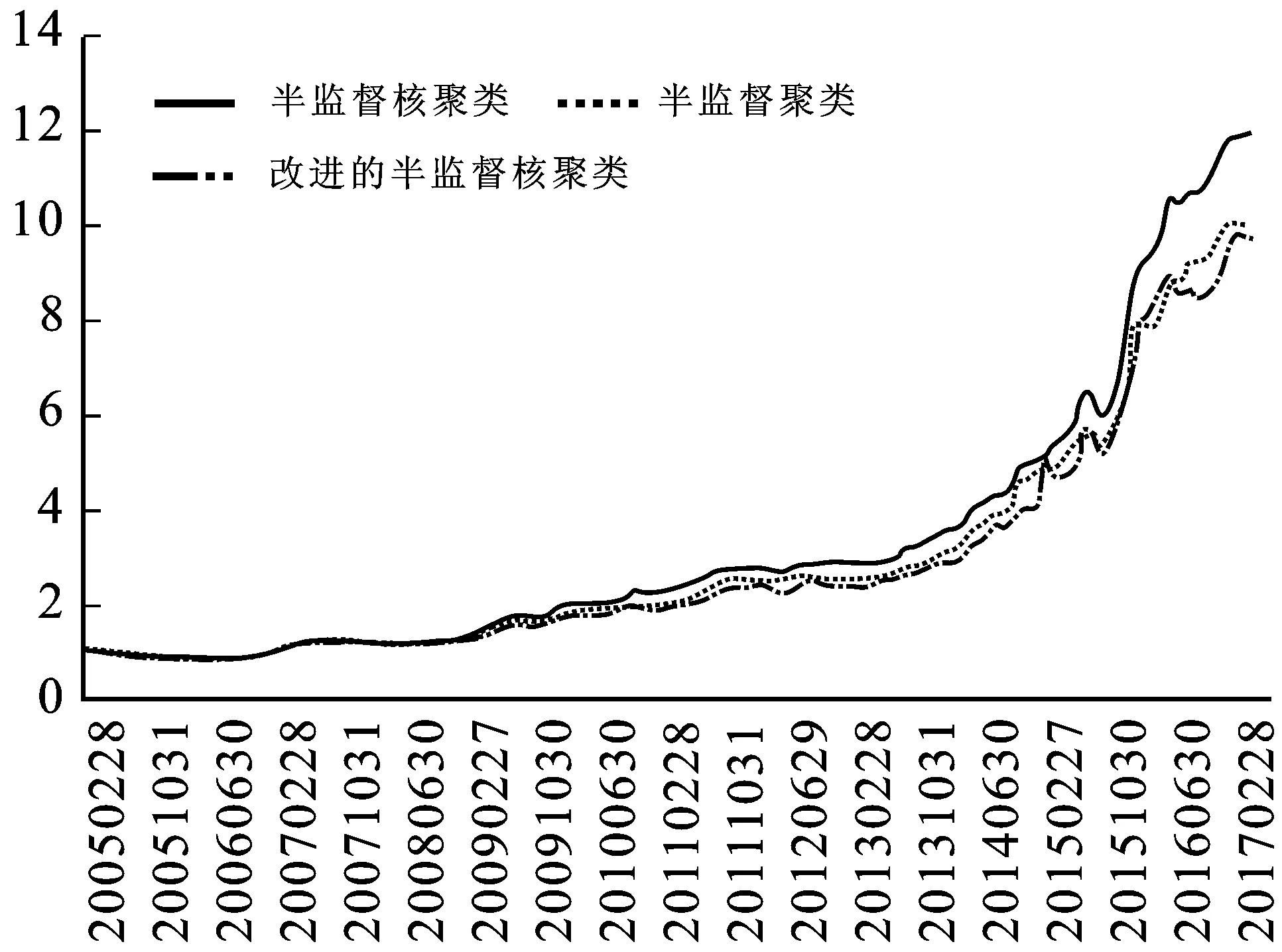
图4 不同模型选出股票的超额收益净值
五、结束语
半监督聚类是聚类的一个重要领域。本文针对多因子选股模型进行半监督K-means算法的改进,在引入已标识数据对未标识数据的引力影响的基础上加入修正高斯核函数,构建改进的高斯核函数与基于引力影响因子的半监督K-means聚类方法,在不提高算法复杂程度的基础上,极大改善K-means模型在处理高维、线性不可分问题的能力。通过理论分析可知,改进算法极大提高聚类的质量,在处理高维、线性不可分的问题上具有良好的性能。实证结果表明,该模型能选出较优的股票组合,改进模型选取股票的超额收益净值明显高于传统模型。它不仅适用于多因子选股,还能用于解决其他数据非线性可分等问题。本文还存在一些不足,首先,样本标签的设定是人为的,以月收益率前5%股票为优质股,后5%为劣质股,具有一定的主观性,这样导致模型的敏感程度较高,已标识的错误信息会影响到模型判别的准确率;其次,参数的选取对聚类效果有明显的影响,如何更好确定参数的选取或者实现参数的自适应调整,需要进一步研究。
[1] Macqueen J.Some Methods for Classification and Analysis of Multivariate Observations[C]//Proceeding of the 5th Berkeley Symposium on Mathematical Statistics and Probability,Berkeley:University of California Press,1967.
[2] 余养强.半监督学习若干问题的研究[D].福州:福建师范大学,2010.
[3] Wagstaff K,Cardie C,Rogers S,et al.Constrained K-means Clustering with Background Knowledge[C]∥Proceedings of the Eighteenth International Conference on Machine Learning,Morgan Kaufman Publishers Inc,2001.
[4] Basu S,Bilenko M,Mooney R J.A Probabilistic Framework for Semi-supervised Clustering[C]// Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM,2004.
[5] 尹学松,胡思良,陈松灿.基于成对约束的判别型半监督聚类分析[J].软件学报,2008,19(11).
[6] 袁利永,王基一.一种改进的半监督K-means聚类算法[J].计算机工程与科学,2011,33(6).
[7] 张莉,周伟达,焦李成.核聚类算法[J].计算机学报,2002,25(6).
[8] 赵晖,荣莉莉.基于模糊核聚类的SVM多类分类方法[J].系统工程与电子技术,2006,28(5).
[9] 瞿娜娜.基于组合核函数支持向量机研究及应用[D].广州:华南理工大学,2011.
[10] 黄啸.支持向量机核函数的研究[D].苏州:苏州大学,2008.
[11] Mercer J.Functions of Positive and Negative Type,and Their Connection with the Theory of Integral Equations[J].Philosophical Transactions of the Royal Society of London,1909(209).
[12] Halmos P R.A Hilbert Space Problem Book[J].Mathematical Gazette,1989,73(465).
[13] Boser B E,Guyon I M,Vapnik V N.A Training Algorithm for Optimal Margin Classifiers[C]// The Workshop on Computational Learning Theory,ACM,1992.
[14] 魏刚.再论多因子选股[EB/OL].[2012-09-06].https://wenku.baidu.com/view/db4d95bcfd0a79563c1e7290.
