基于卷积神经网络的视差图生成技术
2018-03-20朱俊鹏赵洪利杨海涛
朱俊鹏,赵洪利,杨海涛
(1.装备学院 研究生管理大队,北京 101416; 2.装备学院 训练部,北京 101416; 3.装备学院 复杂电子系统仿真实验室,北京 101416)(*通信作者电子邮箱523587076@qq.com)
0 引言
裸眼三维技术,是基于硬件显示技术的发展而兴起的显示方法,即人们在不使用三维辅助眼镜的前提下,通过裸眼观看到立体三维的效果,它有着比二维和普通三维显示更加逼真的便捷体验方式,目前在游戏、电影、广告、医疗、交通、军事等领域有着广泛的应用。从本质上说裸眼三维显示技术和普通的需要借助三维眼镜的三维显示技术最大的不同是前者将三维眼镜“戴”到了屏幕上,人眼在相应的范围里观看屏幕就能产生裸眼三维的效果,而并非两者在三维图像生成算法上的区别,同样的算法借助不同的方式,都能实现三维显示。
卷积神经网络(Convolutional Neural Network, CNN)作为机器学习的一个分支,它是一个含有多隐层的人工神经网络,有着十分强大的特征提取能力,通过建立的训练模型从原始输入端输入的数据中提取更具体、更本质的事物特征,从而有利于解决事物特征的分类和可视化分析。同时通过无监督学习算法实现对输入数据的分级表达,这样就能降低深度神经网络的训练难度和训练规模[1]。
1 研究现状与趋势
1.1 三维图像生成主流技术
结合计算机图像处理技术,目前常见的裸眼三维视频生成方法主要有:基于水平视差的三维显示算法[2]、基于深度图像视点绘制(Depth Image-Based Rendering, DIBR)算法等主要的方法[3-4]。
基于水平视差的三维显示主要利用人眼的特性,在人们裸眼观察的前提下使显示设备呈现出具有空间深度的影像,在转换的过程中,通过平滑置换算法将右视图以全局视差δ移动,通过反向映射得到左视图。水平视差方法在处理过程中存在计算量过大、易出现空洞等现象且图像效果欠佳。
具体的工作流程如图1所示,由原图生成的视差灰度图通过平滑置换方法生成视差序列图,由于视差图会产生空洞所以通过平滑粘连补图方法对视差图进行补图处理,将生成的左、右平滑灰度图再次通过置换生成左、右视差序列图,产生了粘连效果,接着通过消除粘连方法最终生成左眼视差图和右眼视差图,借助特殊的三维硬件显示设备就能实现图片的三维效果。
DIBR技术的主要工作原理是通过参考图像及其相应的深度图合成具有新视点的视图,称之为新视图,新视图后续能够构成立体图像对,通过相关算法产生新视图,参考图像和深度图可分别通过普通摄像机和深度摄像机拍摄获得。在实际操作中,DIBR技术通过三维图像变换生成新视图,但新视图往往出现空洞现象。还需要在后续的操作中对图像进行补图处理。
DIBR算法工作流程如图2所示,将参考图片和相应的深度图作为输入,输入给DIBR,在DIBR算法中根据适当的参数生成多个视点的视图,在生成的视图中通常都包含了左视图、右视图以及在空间位置上对称的图像。再将生成的视图融合成一幅图像,通过硬件裸眼三维显示器,就能够实现裸眼三维的效果。
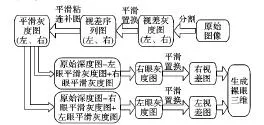
图1 水平视差算法流程
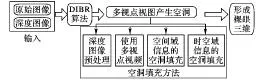
图2 DIBR算法工作流程
1.2 三维图像生成趋势
随着机器学习时代、大数据时代的到来,卷积神经网络(CNN)在图像处理方面的能力得到了广泛的应用,相比传统的方法,卷积神经网络对图像的处理能够避免出现图像空洞的问题,且具备计算速度更快、学习效果良好的优势。卷积神经网络模型提供了一种端到端的学习模型,模型中的参数可以通过传统的梯度下降方法进行训练,经过训练的卷积神经网络能够学习到图像中的特征,并且完成对图像特征的提取、分类以及预测。在图像分类、姿态估计、图像分割等多个计算机视觉领域中有着大量的研究和成果[5]。
将卷积神经网络引入视差图像的生成是未来图像处理的一个全新方法,对于正在兴起的裸眼三维来说将起到极大的促进作用。卷积神经网络模型通过学习后对输入图像进行视差图片的生成过程,相比现有的方法既不会在转换过程中出现空洞,也不用对特征图进行补图处理,不仅确保精确性也提高了效率,从而降低对内部资源的消耗。
2 卷积神经网络
目前开源的神经网络学习系统有很多,本文使用的MXNet(Mix Net)学习系统包含卷积神经网络,是一种为了满足对二维输入数据的处理而专门设计的一种多层人工神经网络,每层网络都由多个二维平面组成,每个平面也由相对独立的多个神经元组成,两层相邻的神经元互相连接。卷积神经网络有着一个权值共享的网络结构使其更贴近生物神经网络,与此同时通过调整网络的深度和广度可以改变网络的容量,因此,使其能更加有效地降低网络模型的复杂程度,具备更少的权值参数和网络层数,计算更加容易[6]。
典型的卷积神经网络主要由输入层、卷积层、上采样层、全连接层和输出层组成[5]。在本文中,将原始图像W作为卷积神经网络的输入数据,用Si表示卷积神经网络的第i层特征图,那么即有:
Si=W
(1)
假设Si是卷积层,那么Si的产生过程可以如下描述:
Si=f(Si-1⊗Hi+bi)
(2)
其中:Hi表示第i层卷积核的权值向量;“⊗”符号表示卷积核与第i-1层特征图进行卷积运算,由于卷积运算的结果是存在一定偏移的,所以需要与第i层的偏移向量bi相加,最后经过非线性的激励函数f(x)最终得到第i层的特征图Si。
卷积层之后通常是上采样层,上采样层根据相关的上采样规则对卷积完成后的特征图进行采样,这一层的主要任务是对特征图进行相应的降维处理,其次还要保持特征图的尺度不变特点[7]。假设Si是上采样层,即有:
Si=upsampling(Si-1)
(3)
经过多层卷积层和上采样层的交替传递,通过全连接网络对提取出来的特征进行相关的分类,总结出输入的概率分布Y。卷积神经网络实际上就是一个让原始矩阵(H0)进行多层数据变换和降维的过程,最后将得到的结果映射到新的数学特征表达模型中。如下:
Y(i)=P(L=li|S0:(H,b))
(4)
其中li为第i个标签类别,从式(4)中分析可得卷积神经网络对输入数据进行训练的主要目的是最小化损失函数L(H,b)。输入S0经过前向传导后通过损失函数计算出与期望值之间的差异,通常称为“残差”。常见的损失函数有均方误差(Mean Squared Error, MSE)函数以及负对数似然(Negative Log Likelihood, NLL)函数等[8]:
(5)
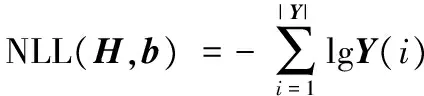
(6)
在计算过程中会出现权值过度拟合的问题,损失函数最后通过增加L范数来控制权值的过拟合,由参数λ控制过拟合作用的强度[9]:
(7)
在训练过程中,通过使用梯度下降方法进行卷积神经网络的优化。残差通过梯度下降进行反向传播,传播过程中更新卷积神经网络每一层的可训练参数(H,b)。学习速率参数η主要控制残差反向传播的强度[9]:
(8)
(9)
卷积神经网络的工作流程分为三步进行,主要是网络模型定义、网络训练和网络预测[6]。网络模型定义,指网络模型主要根据业务需求和数据的特征进行网络深度、功能的设计。网络训练,由于残差的反向传播能够对网络中的参数进行训练,导致训练中出现过拟合和梯度的消逝与爆炸等问题,最终影响了训练的收敛性能;目前针对此问题提出了很多方法,随着网络规模和数据结构的不断扩大,也对相应的网络训练方法有了更高的要求。网络预测就是将输入数据通过前向传输,在每一层输出相应的特征图,最终将这些特征图作为全连接网络的输入,而全连接网络的输出就是基于输入的条件概率分布过程。
3 关键技术
将卷积神经网络引入裸眼三维图像的生成研究中,通过此网络训练生成特征图,将其叠加得到深度图,具有保真度高的特征。
当前对于裸眼三维图像生成的工作主要包含两步,从左视图估计一个准确的深度图,并使用DIBR算法渲染正确的右视图。接着直接对右视图进行回归处理,由于深度图采用了水平视差法故存在背景空洞,导致在DIBR计算过程中出现了像素空洞。
本文中建立卷积神经网络模型来预测概率视差序列图,并将视差序列图叠加得到深度图,并将其作为中间媒介输入,接着与输入图像进行卷积再叠加,通过使用各层的选择层来模拟DIBR方法的过程。在训练过程中,视差序列图由模型生成,且不存在背景空洞的现象,在生成后不用跟实际的视差图进行比较分析,整个训练过程以水平视差的表达和绘图展现的双重目的而结束。此模型通过各层的选择层能够进行端到端的训练。
3.1 模型构建
最近的研究证明,把全连接输入层的特征图结合起来,将有利于进行图片像素的预测,这在人脸识别、姿态估计、物体检测等应用的特征提取上有着较高的准确率[10-11]。鉴于本文研究内容中对无背景空洞、无背景粘连深度图的需求,为了保证生成裸眼三维的高效性和准确性,因此把卷积神经网络引入到本文中,通过将卷积神经网络与DIBR法进行结合,构建一种新的模型。
模型设计如图3所示,将左视图作为输入,分别通过多个卷积层。由于在卷积训练中得到的是分辨率远小于原始图片的特征碎片,这些特征碎片在对新的图像进行特征预测时会产生大量不同的卷积特征映射图,对这些图要经过相应的处理。
在每个卷积层后有一个分支,通过解卷积对上一层输出的图像进行上采样,上采样层的操作即为池化层,将每一卷积计算过后的特征映射图进行聚合统计计算,不仅能对特征图进行降维处理,还保证了每一层图片尺寸的稳定。
在全连接层中,首先将每一层的特征映射图进行叠加得到最终的特征图,再将每一层得到的每个特征图进行叠加,得到与输入图像尺寸要求一致的深度图,并将其作为选择层的输入。再将此深度图在每一个空间位置的通道上分别进行运算得到多个概率视差图,将概率视差图和左视图输入选择层,每一个概率视差图都与左视图进行一次卷积运算,再将所有的运算结果进行叠加,最终得到右视图。
本文建立了12层的卷积计算层,在对样本数据训练期间,每一卷积层的图像训练都存在区别,从图片的近景到远景进行特征学习。故每一卷积层掌握的特征是不一样的。
训练结束后,每一层都对新输入图像特征进行提取,结合训练所得特征,对输入图像依次从近景到远景进行特征的提取,在实际操作中,卷积层的层数较少,卷积网络对输入图像特征提取的不完全,卷积层数较多会产生过拟合现象,降低卷积神经网络的泛化能力。4.2节对本文模型中每一层的计算效果经过上采样处理后进行了展示,从中可以看出每一层的变化情况以及本文12层卷积网络的合理性。
初始化的解卷积层相当于能够促进训练的双线性插值,具体而言,通过因子S进行上采样,核心的ω值[12]定义为:
(10)

(11)
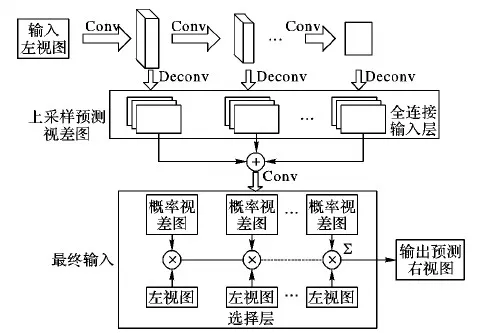
图3 模型结构
3.2 选择层重构原理
选择层是传统裸眼三维生成的DIBR算法,用传统的算法对选择层进行重新构造,一方面能保证右视图生成的便捷性,一方面保证了卷积神经网络结构的完整性。在传统的裸眼三维图像生成过程中,通过左视图I和深度图Z,能够计算出视差图D,具体计算公式如下所示:
D=B(Z-f)/Z
(12)
其中:B为两眼之间的间距,Z为输入深度,f为两眼到交点平面的距离,如图4所示。右视图O则表示为:
Oij=Iij+Dij
(13)
通过两眼之间的距离B以及焦平面与两眼之间的距离f,结合式(12)能计算视差图。当人眼的焦点离人眼越近时,生成的视差图效果较差,反之较好。
然而,由于视差图D并非可区分层次的,所以还不能直接通过选择层计算。本文所采用的网络在计算每个像素位置Dij时,可能存在差异值d的概率分布,对所有的i,j来说满足:
(14)
同时将左视图的移动产生的堆栈定义为:
(15)
那么通过下式由选择层构造右视图:
(16)
目前Dij是能够区分层次的,因此能够计算输出和真实右视图Y之间的损耗M,并将此作为训练的目标。计算公式如下:
M=|O-Y|
(17)
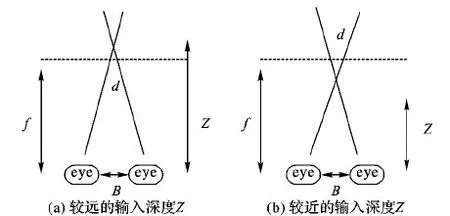
图4 视差图生成物理模型
3.3 模型设置
在实验过程中,采用不带有时序信息的单个图片作为输入,这样可以确保与传统算法的进行比较的公平性。
训练数据集主要来自KITTI[13],KITTI数据集是目前最大的计算机视觉算法评测数据集。在训练期间,每个输入左帧被调整为432×180像素,生成200个8×8大小的特征碎片,由此特征碎片对输入的图像做计算,最终由上采样层进行降维处理,生成384×160的预测图像。
生成的右视图为384×160的分辨率,这对于一般图片的使用来说是无法接受的分辨率。为了解决这个问题,首先通过卷积网络的视差图通常有很多比原始彩色图像要少的高频内容,因此能够将预测得到的视差图进行扩展,并将其与原始的高分辨率左视图相结合呈现出高分辨率的右视图。以这种方式呈现右视图与4倍上采样频率相比,具有更好的图像质量。
对于定量分析,本文主要采用384×160分辨率的图像作为输入和输出;对于定性分析,本文采用卷积神经网络对图片进行卷积和上采样,通过利用卷积网络的权值初始化主分支上的卷积层(图3立体方块部分),并以标准偏差为0.01的正态分布初始化所有其他权值。
为了使全连接输入层的图像特征信息、尺寸信息更加完整,在合并各层后,创建一个侧面分支,将多层(本文创建了12层)卷积层进行批量的归一化处理。接着通过解卷积层进行初始化处理,如式(10)~(11)所示,此解卷积的输出尺寸也匹配最终的输出尺寸。通过批量归一化处理的卷积网络层与随机的初始化层进行连接,这样就能够解决由于卷积网络的庞大和不均匀的激活量所造成的像素尺寸重构数值不稳定的问题[14-15]。
在硬件方面,需要通过Nvidia的独立显卡进行显示,通过Nvidia GTX Titan GPU计算,卷积神经网络可以以每秒100帧的速度重建新的右视图。而本文使用的主要是MXNet架构的卷积神经网络,MXNet为开源的网络架构模型,支持C++、Python、R、Matlab、Javascript等语言,可运行在CPU、GPU或移动设备上[16]。
4 实验对比分析
为了验证算法的可靠性,提高实验的可信度以及对视差图效果进行优劣判断,本文通过基于水平视差的三维显示、DIBR算法与卷积神经网络进行比较,验证本文方法与传统方法的优缺点,采用定量分析和定性分析两种方法进行综合评价。定量分析主要比较生成右视图像素尺寸重构的平均绝对误差,误差越小,效果越好。定性分析通过直观比较DIBR方法生成的视差图和卷积神经网络生成的视差图来判断,由1.1节可知DIBR生成的视差图是目前主流方法中应用最广、空洞效果改善最好的,将本文的方法与其进行比较将更好说明本文方法的优劣。通过这两种评估方法最终验证卷积神经网络进行裸眼三维图像生成的可行性。
4.1 定量分析
本文取像素尺寸重构误差值的平均绝对误差进行定量分析,由于在生成右视图时,都会对图片的每一个像素进行重新排列,故与原图会出现一定的尺寸误差,尺寸误差越小就说明生成的右视图与原图匹配效果更好。分析平均绝对误差(Mean Absolute Error, MAE)通过计算进行,如式(18):
(18)
其中:x为右视图,y为左视图,g(·)表示生成相应的模型,H和W分别为图像的高度和宽度。考虑到卷积神经网络预测的不稳定性,为保证实验的准确性,本文对3种方法进行11次的定量分析,结果如图5所示。
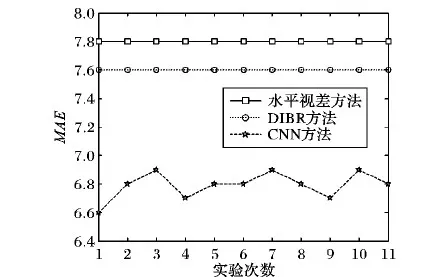
图5 MAE值比较
由于卷积神经网络存在不稳定性,故MAE并非一个定值,本文在3.2节中对其存在的不稳定性结果进行了解卷积处理,由实验结果来看其MAE值在一个合理的区域内变动,卷积神经网络相对于水平视差和DIBR方法来说,其误差值分别平均降低了12.82%和10.52%。由于考虑到修正误差会降低模型计算速度,由图分析可知误差的范围是在合理范围中,故不需要对误差进行修正。
4.2 定性分析
为了更好地理解本文所提的方法,文中展示了定性分析的结果,通过卷积神经网络对特征进行提取,展现出较强的立体感,并通过12个卷积层从近到远的分配视差图,如图6所示。
从图6中可以观察到卷积神经网络方法能够通过输入图片中对隐含的信息的特征提取得到特征图,主要包括图片的尺寸、遮挡物以及图片中物体的几何构架。由卷积网络计算出来的这12幅图像都是384×160大小的尺寸,这得益于上采样层的处理。随着卷积计算的进行,在卷积计算的后几层,无论是近景的人物还是任务背后远景的湖、山、天空、云彩都得到了很好的体现,这说明卷积神经网络很好地提取到原始图像中的各个特征元素,并能很好地表现出来。
从图6中分析可见对图片的预测由近到远进行分析,每一个层面的视差图都不一样,随着卷积层数的深入,得到的视差图存在过拟合的趋势,使得后期视差图会出现失真的现象,然而,这并不影响最后整体生成图像的质量。这是因为每一排的像素的值相同且固定,任何视差图的分配都将按照固定的像素大小进行排列,所以视差的计算只需要精确的垂直边缘,在实验中也能够看出深度学习框架的学习的主体主要也集中在这个区域当中。

图6 CNN方法定性分析结果(各层视差图)
同时通过卷积神经网络生成的右视图和DIBR方法生成右视图的灰度图进行对比分析,如图7所示。

图7 原图、DIBR和CNN方法效果比较
图7展示了不同样本图片经过DIBR和卷积网络的效果,从左至右依次为原图、DIBR深度图、卷积神经网络预测视差图。从图中分析可以得出,卷积神经网络的预测视差图方法能够更好地勾勒图片中物体的轮廓,能够勾勒出图中的远景的山、湖泊、楼房、天空的轮廓,近景的字迹、人物形态;而由传统方法DIBR的深度图其背景之间产生了粘连,远景分不清景物的轮廓,也看不清石碑上的刻字,图像特征不能直接区分。因此由图7可以清楚地对比出由卷积神经网络生成的视差图更加清晰,特征提取更加明显,很好地克服了传统方法的缺点。
5 结语
本文使用卷积神经网络对裸眼三维图像生成进行了研究,通过输入相应的左视图图像进行多层的训练得到特征图,通过模拟DIBR得到相应的右视图。此方法相比传统的三维生成方法,特征图没有背景空洞现象,准确率高。在实验中使用的图像都来自于静止图像,未考虑带有时态信息的视频,在普通二维视频生成裸眼三维视频的过程中,可通过时间信息来提高特征提取的性能,并结合该网络对视频进行了研究,发现几乎没有定量性能的增益,且视频的连贯性受到了影响,此问题也是下一步需要对本文的设计需要进行提高的一个研究方向。
References)
[1] 刘建伟,刘媛,罗雄麟.深度学习研究进展[J].计算机应用研究,2014,31(7):1921-1930.(LIU J W, LIU Y, LUO X L. Research and development on deep learning [J]. Application Research of Computers, 2014, 31(7): 1921-1930.)
[2] 赵天奇.裸眼3D内容生成和显示若干关键技术研究[D].北京:北京邮电大学,2015:22-43.(ZHAO T Q. Research on key technologies of naked eye there-dimensional display and its content generation [D]. Beijing: Beijing University of Posts and Telecommunications, 2015: 22-43.)
[3] 李博乐.基于DIBR的裸眼3D显示系统研究与实现[D].重庆:重庆大学,2015:7-40.(LI B L. Research and implementation of glasses-free 3D display system based on DIBR [D]. Chongqing: Chongqing University, 2015: 7-40.)
[4] 谭伟敏.裸眼3D显示关键技术研究[D].重庆:重庆大学,2014:32-43.(TAN W M. Research on key technologies of glasses-free 3D display [D]. Chongqing: Chongqing University, 2014: 32-42.)
[5] 李彦冬,郝宗波,雷航.卷积神经网络研究综述[J].计算机应用,2016,36(9):2508-2515.(LI Y D, HAO Z B, LEI H. Survey of convolutional neural network [J]. Journal of Computer Applications, 2016, 36(9): 2508-2515.)
[6] 卢宏涛,张秦川.深度卷积神经网络在计算机视觉中的应用研究综述[J].数据采集与处理,2016,31(1):1-17(LU H T, ZHANG Q C. Application of deep convolutional neural network in computer vision [J]. Journal of Data Acquisition and Processing, 2016, 31(1): 1-17)
[7] SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of go with deep neural networks and tree search [J]. Nature, 2016, 529(7587): 484-489.
[8] ZEILER M D, FERGUS R. Stochastic pooling for regularization of deep convolutional neural networks [EB/OL]. [2017- 01- 11]. http://www.matthrwzeiler.com/pubs/iclr2013/iclr2013.pdf.
[9] MURPHY K P. Machine Learning: A Probabilistic Perspective [M]. Cambridge, MA: MIT Press, 2012: 82-92.
[10] TATARCHENKO M, DOSOVITSKIY A, BROX T. Single-view to multi-view: reconstructing unseen views with a convolutional network [J]. Knowledge & Information Systems, 2015, 38(1): 231-257.
[11] DOSOVITSKIY A, FISCHER P, ILG E, et al. FlowNet: learning optical flow with convolutional networks [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 2758-2766.
[12] RICHTER S R, VINEET V, ROTH S, et al. Playing for data: ground truth from computer games [C]// Proceedings of the 2016 European Conference on Computer Vision. Berlin: Springer, 2016: 102-118.
[13] GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: the KITTI dataset [J]. International Journal of Robotics Research, 2013, 32(11): 1231-1237.
[14] WANG C, YAN X, SMITH M, et al. A unified framework for automatic wound segmentation and analysis with deep convolutional neural networks [C]// EMBC 2015: Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. Piscataway, NJ: IEEE, 2015: 2415-2418.
[15] HE K, ZHANG X, REN S, et al. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification [C]// Proceedings of the 2016 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2016: 1026-1034.
[16] ATHEY S, IMBENS G. Machine learning methods for estimating heterogeneous causal effects [J]. Statistics, 2015, 113(27): 7353-7360.
This work is partially supported by the Academy of Equipment School Level Basic Research Project (DXZT-JC-ZZ- 2013- 009).
ZHUJunpeng, born in 1993, M. S. candidate. His research interests include information network security.
ZHAOHongli, born in 1964, Ph. D., professor. His research interests include information network security.
YANGHaitao, born in 1979, Ph. D., associate research fellow. His research interests include information network security.
