基于多任务深度卷积神经网络的显著性对象检测算法
2018-03-20李建平陈雷霆
杨 帆,李建平,李 鑫,陈雷霆
(电子科技大学 计算机科学与工程学院,成都 611731)(*通信作者电子邮箱fanyang_uestc@hotmail.com)
0 引言
视觉显著性可以帮助人类快速地过滤掉不重要的信息,让我们的注意力更加集中在有意义的区域,从而能更好地理解眼前的场景。随着计算机视觉技术的发展,大家希望电脑也能拥有和人类相同的能力,即在分析和理解一个复杂的场景时,电脑可以更加有针对性地处理有用的信息,从而能大幅度降低算法的复杂度,并且排除杂波的干扰。一般来说,视觉显著性算法主要可以被分为两大类:1)眼动估计;2)显著性对象检测。本文的工作主要针对第2)类问题进行研究。显著性对象检测算法的目标是检测图像(输入场景)中最能吸引人注意的整个对象区域。目前,显著性对象检测算法被广泛运用于计算机视觉和多媒体领域的任务中,包括对象追踪[1]、对象发现[2]、对象识别[3]、稠密匹配[4]、图像检索[5]等。
显著性对象检测不受限于对象的类别、尺寸大小、位置、个数,这些不确定因素使得它成为目前计算机视觉和人工智能领域中的一个难题。在传统做法中,研究人员根据观察到的各种先验知识对显著性对象检测算法进行建模,生成显著性图。这些先验知识包括:对比度、中心先验、边缘先验、语义先验等,但在复杂的场景中,传统方法往往不够准确。这是因为这些观察往往限于低级别的特征(例如,颜色和对比度等),而不能准确反映出显著性对象本质的共同点。
近年来,深度卷积神经网络(Convolutional Neural Network, CNN)广泛运用于计算机视觉的各个领域,很多困难的视觉问题都获得了重大的进展。不同于传统方法,深度卷积网络可以从大量的样本中建模并且自动地、端到端地学习到更为本质的特征,从而有效地避免了传统人工建模和设计特征的弊端。在显著性对象检测领域,深度卷积网络也被广泛地使用[6-8],并且大幅度地提高了显著性对象检测的准确性和鲁棒性,但是由于深度网络需要大量运用的池化操作(例如max-pooling和average-pooling)编码上下文信息,这些方法总是不能很好地保存对象边缘的信息,而事实上,对象的边缘信息对于显著性检测非常重要。认知科学的研究也表明:人的视觉注意力在对象中流动并且被对象边缘所阻挡。忽略这些边缘信息或者不能正确编码这些边缘信息,往往只能得到次优的结果。
针对边缘信息被忽略的问题,本文提出一种全新的显著性对象检测模型,该模型基于一个新设计的多任务的卷积神经网络,并且该模型同时训练和学习显著性区域和边缘信息。不同于现存单一任务的深度学习方法,本文检测结果的生成同时依赖于显著性对象边缘和区域的信息。在三个广泛使用的显著性对象检测公共数据库上的实验结果表明,本文所提方法在准确率、召回率以及均方误差上均优于传统算法和单一任务的深度学习算法。
1 相关工作
显著性对象检测算法可以被归纳为两个类别:传统方法和基于深度学习的方法。传统方法主要基于各种不同的先验知识,然后利用这些先验知识进行数学建模,从而计算出每个像素的显著性值。Cheng等[9]利用全局对比度计算对象的显著性图,该方法认为人的注意力总是倾向于那些对比度(全局对比度或者局部对比度)比较强烈的区域,从而可以通过颜色直方图的计算,快速找出图像中那些对比度强烈的区域。除此之外,边缘先验也广泛地运用在显著性对象检测算法中,并衍生出各种类型的算法。这类算法假设图像边缘的区域往往不是显著性对象的区域,因为人们在日常拍照的过程中,总是将显著性的对象置于相对中间的位置。其中基于流形排序的散射算法[10]、基于二值图的显著性检测算法[11]、基于边缘接触的显著性对象检测算法[12]等都取得了不错的效果。除此之外,监督学习的方法也运用在显著性对象检测的任务中[13]。另外,Li等[14]提出构建显著性的特征,并且建立与已有样本的稠密对应关系,从而引导显著性对象的检测。传统方法运用各种观察和先验知识进行数学建模,从而检测出图像或者场景中的显著性对象。因为这些方法总是缺少了足够的语义信息,所以它们不可避免地会在应对复杂场景和先验矛盾的情况下失效。
由于深度卷积网络强大的建模能力和自动的端到端的学习方式,很多近期的工作基于深度卷积网络学习有效的特征,从而进行显著性对象检测。例如:文献[6]利用更加丰富的上下文信息学习显著性对象区域等;文献[7]基于一个多尺度编码上下文的深度卷积网络进行显著性对象检测;文献[8]同时编码传统特征向量和深度特征向量,利用它们的互补优势进行显著性对象检测;文献[15]基于一个多流卷积网络学习显著性对象的特征;文献[16]通过两个独立的深度神经网络分别计算区域和边界信息,并且利用条件随机场进行优化。这些方法相对传统显著性对象检测方法大幅度提高了检测的准确率,但是由于深度网络的池化操作不能更好地保存对象的边缘信息(也称边缘信息损失),因而导致整个对象区域的边缘模糊。为了解决上述问题,稠密条件随机场(Dense Conditional Random Field)被广泛地运用来优化深度网络检测的结果,进而得到完整的区域和清晰的边缘;但是稠密条件随机场的计算比较耗时,而且由于稠密条件随机场基于低级别的图像特征(比如颜色),因而它在应对复杂场景时,也并不是特别有效。综上所述,基于深度卷积网络的显著性对象检测算法仍然有较大的提升空间。
2 基于多任务深度CNN的显著性对象检测
本文提出的显著性对象检测算法主要基于一个多任务卷积神经网络。不同于现有基于卷积神经网络进行显著性对象检测的框架,本文提出的多任务深度卷积网络同时进行显著性对象区域和边缘两种特征的学习,并且它们共享同一个底层表达。该网络的输入为任意一张图像,输出为一个显著性对象区域的检测结果以及一个显著性边缘的检测结果。根据边缘的检测结果,生成一系列候选区域,这些区域结合显著性区域的检测结果重新进行排序并且加权求和,从而最后生成最终的显著性图。
2.1 多任务深度卷积神经网络结构
多任务深度卷积神经网络的目标是同时对图像的边缘和区域信息进行编码。如图1所示,在编码过程中(encode process),该网络共享一个VGG- 16网络,在解码过程(decode process)中,该网络包括一个显著性区域检测分支以及一个显著性边缘检测分支。其中显著性对象区域检测子网络是一个整体嵌套网络(holistically-nested network)[17],显著性对象边缘检测是一个反卷积网络(deconvnet)。在训练的过程中,采取交互的方式训练这个网络:先固定显著性对象边缘检测子网络,训练显著性对象区域子网络;然后固定显著性对象区域检测子网络,调整(fine-tune)显著性对象边缘检测子网络。上述过程交替执行,直到损失函数(loss function)不再下降为止。在执行的过程中,输入一张图像,深度卷积网络自动同时生成显著性对象区域图和显著性对象边缘图。值得注意的是,两个子网络共享同一个底层VGG- 16网络,因而它们可以保持一定的相关性,从而更加准确。

图1 多任务深度卷积网络整体框架结构
2.2 显著性对象区域检测子网络
显著性对象检测是一个相对复杂的任务,它不仅需要高层次的语义信息,还需要低层次的局部信息,因而本文提出的显著性对象区域检测子网络同时融合VGG- 16的浅层信息和深层信息。类似于整体嵌套网络,将VGG- 16每个组的最后一层作为边缘特征输出(side-output),另外在每个边缘输出中加入一个卷积层,从而更好地编码上下文信息。
显著性对象区域检测子网路的输入为一张任意图像I,输出为显著性区域概率图ψ(I;θR),其中θR为显著性对象区域检测子网络的网络参数。该网络学习多尺度显著性对象区域特征,然后利用一个融合网络整合各个尺度计算的显著性对象的预测结果,并且得出最终的显著性区域概率图。VGG- 16有6个不同的尺度,其中最后一个尺度更多地整合全局信息,而显著性对象检测是一个像素级的分类问题,因而只利用VGG- 16的前5个尺度进行显著性对象区域的检测,并且每个尺度对应分类器的权重为ki,其中i=1,2,…,5。本文运用标准交叉熵代价函数(cross-entropy loss)去训练整个网络,计算每个像素和标注的差值。显著性对象区域子网络每个尺度的代价函数被定义为:
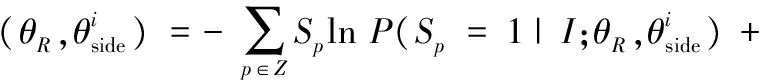
(1)
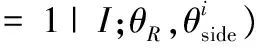

(2)

通过上述代价函数训练,显著性对象区域检测子网络可以有效地对图像的显著性区域进行预测。然而正如前文讨论,由于深度卷积网络固有的信息损失的缺陷(如图2所示),该网络并不能完整地保存对象的边缘信息,因此在该网络基础上,设计了另一个重要分支,对显著性对象边缘的特征进行有效的学习和提取。
2.3 显著性对象边缘检测子网络
如图1所示,显著性对象边缘检测网络分支是一个反卷积网络。理论上,反卷积网络可以看成是卷积网络的逆过程,即将上层的卷积图作为输入,然后进行反卷积操作,得到新的卷积图。如表1所示,在本文的多任务深度卷积神经网络中设计了6个反卷积层,分别对应了VGG- 16的6个尺度。显著性对象边缘子网络的设计参考文献[18],但是这里的任务是显著性对象的检测,而不是给定类别的对象边缘检测,因此,在训练的过程中,运用大量显著性图的人工标注,提取出边缘,并且进行自动的端到端的学习,从而学习到每个反卷积网络的参数。代价函数仍然为交叉熵代价函数计算显著性对象边缘:
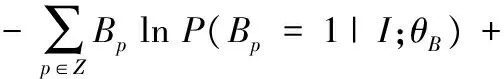
(1-Bp) lnP(Bp=0|I;θB)
(3)
其中:Bp表示坐标p对应的边缘标注,θB表示反卷积网络的所有参数。因而,整个多任务深度卷积网络的代价函数可以定义为:
Lall(θ)=Lfuse(θ)+Lb(θ)
(4)
其中Lall(θ)为整个多任务深度卷积网络的代价函数。基于深度学习的框架,本文用随机梯度下降的方式求解上述代价函数和训练模型,从而训练好整个模型。
在测试时,多任务深度卷积网络的输入为任意一张图像,输出为一个显著性对象区域概率图和一个显著性对象边缘概率图。显著性对象图需要融合上述两种输出结果,从而得到一个更好的显著性检测结果。

表1 显著性对象边缘检测子网络参数设置
2.4 显著性对象图生成
如图2,为了融合显著性对象区域和边缘的所有信息,首先利用显著性对象边缘的概率图,并且通过多尺度联合分组算法[19],生成大量的候选区域,再结合多任务深度卷积网络输出的显著性对象区域检测的结果,并通过以下方式重新计算这些候选区域为显著性对象区域的概率:
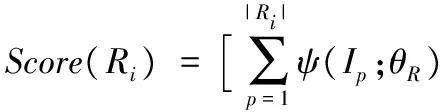
(5)


(6)
其中:Scorep(Ri)表示像素p由第i个候选区域决定的显著性分数;Norm{·}表示归一化操作,即最后需要将相加的值重新归化到[0,1]。
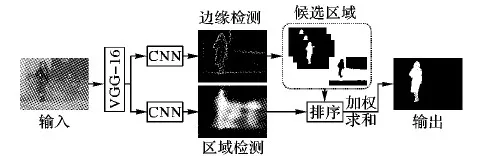
图2 显著性对象图生成框架
2.5 训练和测试细节
本文运用MSRA- 10000[9]作为训练数据。对于每个训练的样本,首先将它们的尺度调整为224×224。边缘标注是通过对显著性图进行梯度计算提取出来。本文运用“poly”学习率衰减方式训练整个网络,并且学习衰减率被定义为(1-iter/maxiter)power;同时将初始的学习率设置为10-7,并且power=0.9,最大循环次数为60 000,运用随机梯度下降法,去优化整个网络。因为本文的网络为一个多任务网络,因此在训练的过程中,需要先固定显著性对象区域检测子网络,学习显著性对象边缘检测子网络的参数;之后再固定显著性对象边缘检测子网络,学习显著性对象区域检测子网络的参数。上述训练交替进行直到代价函数收敛,整个训练过程耗时24 h左右。
测试过程中,仅仅只需要输入任意一张图像,网络会自动生成它对应的显著性区域图和显著性对象边缘图作为输出。之后本文利用网络输出结果,根据2.4节描述,生成最终的显著性对象图。
3 实验结果与分析
3.1 数据库和对比方法
运用3个广泛使用的显著性对象检测数据库,包括扩展的复杂场景显著性数据集(Extended Complex Scene Saliency Dataset, ECSSD)[20]、大连理工-欧姆龙显著性数据集(DUT-OMRON)[10]以及帕斯卡数据集(PASCAL-S)[21],作为测试数据,验证本文所提方法的有效性。其中ECSSD中有1 000幅图像,这些图像包含一个或者多个显著性对象,并且具有非常复杂的场景;DUT-OMRON是另外一个最具有挑战的显著性对象检测数据库,含有5 168幅特别具有挑战的图像,这些图像包含非常复杂的场景;PASCAL-S被认为是目前最难的数据库之一,它包含850幅图像,这些图像含有一个或者多个对象,并且这些对象具有不同的显著值。上述三个数据库被广泛运用于验证显著性对象检测算法的有效性。
为了进一步验证本文方法的优越性,将本文提出的方法与目前常见的显著性对象检测算法进行比较。这些方法分为两类:第一类是公认准确度排名较高的传统方法,包括显著性区域融合(Discriminative Regional Feature Integration, DRFI)[13]算法、基于最小障碍(Minimum Barrier, MB+)[22]显著性检测算法、基于流排序(Manifold Ranking, MR)[10]显著性检测算法、基于鲁棒背景检测(Robust Background Detection, RBD)[12]显著性优化、基于高维颜色变换(High-Dimensional Color Transform, HDCT)[23]显著性检测、基于二值图包围方式(Boolean Map Saliency, BMS)[11]显著性检测。第二类为目前基于深度学习的显著性对象检测算法,包括:基于多信息深度学习(Multi-Context, MC)[6]显著性检测、基于多尺度深度纹理(Multi-scale Deep Feature, MDF)[24]显著性检测、基于距离图深度(Encoded Low-level Distance, ELD)[8]显著性检测。
3.2 准确率-召回率曲线
准确率-召回率曲线被广泛用来验证显著性对象检测算法。通过设置不同的阈值,从而计算各个方法检测结果准确率和召回率。如图3所示,本文提出的方法在三个广泛使用的数据集上都获得最高的准确率-召回率。总的来说,基于深度卷积网络的方法具有更高的准确率。这是因为深度卷积网络在学习的过程中能更好地捕获高级的语义信息,因而能更好地应对复杂的场景。传统方法(包括DRFI、MB+、MR、RBD、HDCT、BMS)在处理复杂场景时(例如DUT-OMRON和PASCAL-S数据库中的图像),由于它们基于观察所得的线索进行数学建模,而这些线索并不能完全覆盖所有情形,因而不能很好地应对复杂的场景。除此之外,本文方法由于克服了深度卷积神经网络边缘信息损失缺陷,因而取得更准确的显著性图。
3.3 F-measure
为了进一步验证本文所提方法,除了准确率-召回率曲线,本文还运用F-measure(Fβ)对提出的方法进行验证和比较。F-measure也一种验证显著性对象检测算法的方法,通过如下公式计算:
(7)
其中β为权重,参照文献[11,13,22],本文设置β=0.3,强调precision的重要性。F-measure值越高表明算法检测显著性对象检测的准确度越高。表2总结了本文所提方法与常见的显著性对象检测算法在三个广泛使用的标准数据库上的检测结果。
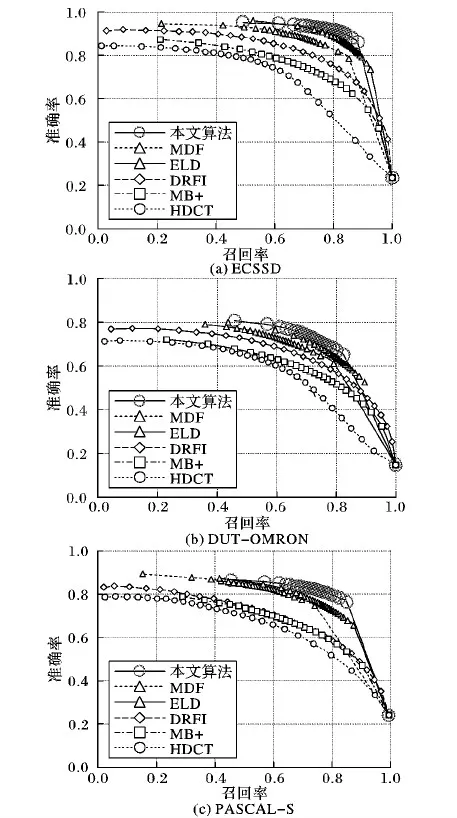
图3 不同方法的准确率-召回率曲线
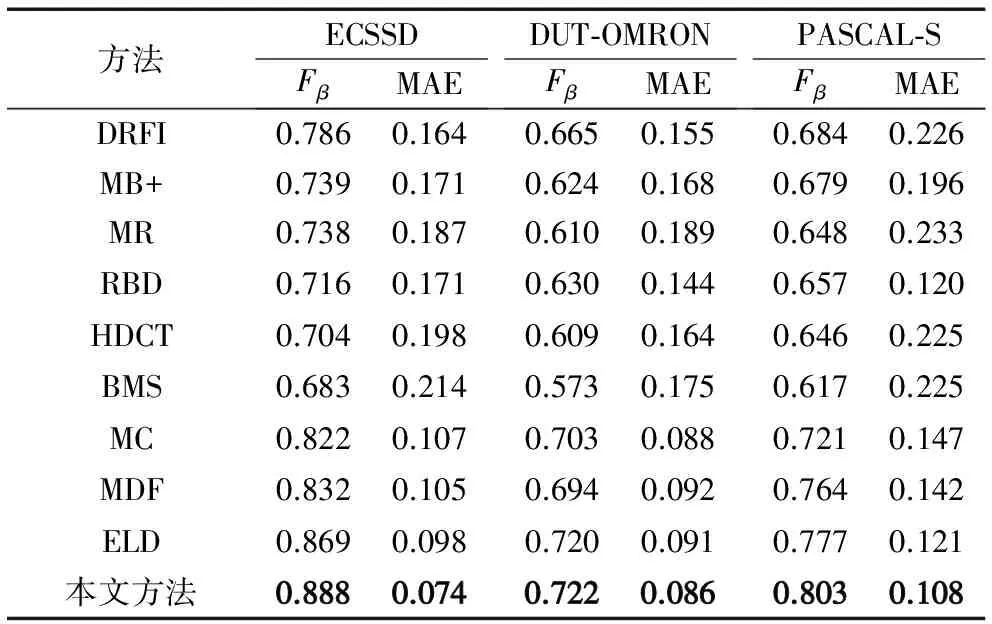
Tab. 2 Detection results comparison of different methods on three widely-used benchmarks
从表2可以得出:1)相比传统显著性对象检测算法,基于深度学习的显著性对象检测算法能够计算出准确度高的结果;2)本文所提方法在三个具有挑战性的数据库上都获得最高准确率;3)本文所提方法鲁棒性相对较高,在不同难度数据库上都获得较高的准确率。
3.4 平均绝对误差
平均绝对误差(Mean Absolute Error, MAE)是指显著性图和人工标注的均方误差,常常作为验证显著性对象检测的重要指标。MAE是计算检测出的显著性图的每个像素和人工标注显著性图的每个像素的平均绝对误差:
(8)
其中:W和H分别表示显著性图的宽度和高度;S(x,y)和G(x,y)分别代表在坐标为(x,y)处方法预测的显著性值和人工标注的显著性值。
如表2所示,本文提出的方法在三个广泛使用的公共数据集上获取了最低的方差错误。这是因为本文提出方法能够生成更加准确的结果,并且更好地保存了边缘信息。同样的,相比传统方法,基于深度卷积网络的方法取得更低的错误率,而本文方法比现有基于深度学习的方法更能有效保存边缘信息,防止边缘信息丢失,因而取得准确度高的结果。
3.5 视觉比较
视觉比较的结果如图4中所示。和最后一列人工标注(GroundTruth, GT)作对比,本文所提方法生成的最后结果更接近于人工标注,本文所提方法即使在特别具有挑战的场景中,仍然可以生成准确的显著性图。相比传统方法,基于深度卷积网络的方法的检测结果更加集中在正确的区域,这是因为这些方法能有效学习到高级的语义信息。本文所提方法由于整合了边缘和区域的信息,因而能更有效地保存边缘信息,在背景复杂的场景中,本文提出方法仍然具有较高的鲁棒性。

图4 不同方法的视觉比较
3.6 运行效率比较
各种方法的运行效率比较如表3所示。

表3 运行效率比较 s
由于基于深度学习的方法需要运用GPU加速,因而本文用两种不同的实验环境分别测试传统方法和基于深度学习方法的运行效率。具体来说,对于传统显著性对象检测方法,本文的实验环境为Windows操作系统,CPU为i7 2.50 GHz,内存为8 GB;对于基于深度学习的方法,用GPU进行加速,实验环境为Linux系统,GPU为NVIDIA GTX 1080ti,显存为11 GB。本文所提算法平均1.1 s完成一张图像的检测,运行速率上低于一些高效率算法(比如MB+),但是本文所提算法却获得了最高的准确度。另外,本文提出算法的运行效率仍然大幅度高于现有的部分算法。
4 结语
本文提出一种基于深度卷积网络的显著性对象检测算法。该算法能有效地整合边缘信息和区域信息,从而获得更高的准确性。为了实现对象边缘信息和区域信息的提取,本文提出了一个多任务的深度卷积网络,该网络共享相同的底层结构,从而大幅度缩减了训练和运行时间。在获取显著性对象边缘和区域信息后,本文进一步提出一个简单、有效的整合算法,精确地过滤了错误信息并且准确地保存了对象边缘信息。实验结果表明,本文所提的多任务深度学习框架能更好地整合显著性对象边缘信息和区域信息,从而能达到更好的效果。
当然,由于本文算法依赖于对象边缘先验知识提取对象候选区域,因此对于非常复杂的场景或者对象与图像边缘过度接触的情况,本文算法仍然存在不足。这些问题将在后续的研究中被逐步改善,进一步提高算法效果。
References)
[1] BORJI A, FRINTROP S, SIHITE D et al. Adaptive object tracking by learning background context [C]// CVPR 2012: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2012: 23-30.
[2] ZHU J, WU J, XU Y, et al. Unsupervised object class discovery via saliency-guided multiple class learning [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(4): 826-875.
[3] RUTISHAUSER U, WALTHER D, KOCH C, et al. Is bottom-up attention useful for object recognition? [C]// CVPR 2004: Proceedings of the 2004 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2004: 37-44.
[4] YANG F, LI X, CHENG H, et al. Object-aware dense semantic correspondence [C]// CVPR 2017: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 2777-2785.
[5] HE J, FENG J, LIU X, et al. Mobile product search with bag of Hash bits and boundary re-ranking [C]// CVPR 2012: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2012: 3005-3012.
[6] ZHAO R, OUYANG W, LI H, et al. Saliency detection by multi-context deep learning [C]// CVPR 2015: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1265-1274.
[7] LI G B, YU Y Z. Visual saliency based on multi-scale deep features [C]// CVPR 2015: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 5455-5463.
[8] LEE G, TAI Y W, KIM J. Deep saliency with encoded low level distance map and high level features [C]// CVPR 2016: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 660-668.
[9] CHENG M, NILOY J, HUANG X, et al. Global contrast based salient region detection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3): 569-582.
[10] YANG C, ZHANG L, LU H, et al. Saliency detection via graph-based manifold ranking [C]// CVPR 2013: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2013: 3166-3173.
[11] ZHANG J, SCLAROFF S. Exploiting surroundedness for saliency detection: a Boolean map approach [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 38(5): 889-902.
[12] ZHU W, LIANG S, WEI Y, et al. Saliency optimization from robust background detection [C]// CVPR 2014: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 2814-2821.
[13] JIANG H, WANG J, YUAN Z, et al. Salient object detection: a discriminative regional feature integration approach [C]// CVPR 2013: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2013: 2083-2090.
[14] LI X, YANG F, CHEN L, et al. Saliency transfer: an example-based method for salient object detection [C]// IJCAI 2016: Proceedings of the 2016 International Joint Conference on Artificial Intelligence. Menlo Park: AAAI Press, 2016: 3411-3417.
[15] LI X, ZHAO L, WEI L, et al. DeepSaliency: multi-task deep neural network model for salient object detection [J]. IEEE Transactions on Image Processing, 2016, 25(8): 3919-3930.
[16] 李岳云,许悦雷,马时平,等.深度卷积神经网络的显著性检测[J].中国图象图形学报,2016,21(1):53-59.(LI Y Y, XU Y L, MA S P, et al. Saliency detection based on deep convolutional neural network [J]. Journal of Image and Graphics, 2016, 21(1): 53-59.)
[17] XIE S, TU Z. Holistically-nested edge detection [C]// CVPR 2016: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 1395-1403.
[18] YANG J, PRICE B, COHEN S, et al. Object contour detection with a fully convolutional encoder-decoder network [C]// CVPR 2016: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 193-202.
[19] ARBELAEZ P, PONTTUSET J, BSRRO J, et al. Multiscale combinatorial grouping [C]// ICCV 2014: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 328-335.
[20] XIE Y, LU H, YANG M. Bayesian saliency via low and mid level cues [J]. IEEE Transactions on Image Processing, 2013, 22(5): 1689-1698.
[21] LI Y, HOU X, KOCH C, et al. The secrets of salient object segmentation [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 280-287.
[22] ZHANG J, SCLAROFF S, LIN Z, et al. Minimum barrier salient object detection at 80 FPS [C]// ICCV 2015: Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 1404-1412.
[23] KIM J, HAN D, TAI Y W, et al. Salient region detection via high-dimensional color transform [C]// CVPR 2014: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 883-890.
[24] LI G, YU Y. Visual saliency based on multiscale deep features [C]// CVPR 2015: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 5455-5463.
This work is partially supported by the National Natural Science Foundation (6157021026), the National High Technology Research and Development Program (863 Program) of China (2015AA016010).
YANGFan, born in 1987, Ph. D. candidate. His research interests include computer vision, deep learning, dense semantic correspondence.
LIJianping, born in 1964, Ph. D., professor. His research interests include wavelet signal processing, pattern recognition, image processing.
LIXin, born in 1986, Ph. D. candidate. His research interests include computer vision, deep learning, artificial intelligence.
CHENLeiting, born in 1966, Ph. D., professor. His research interests include computer graphics, multimedia technology, image processing.
