基于词汇语义模式的金融事件信息抽取方法
2018-03-20黄海量
罗 明,黄海量,2
(1.上海财经大学 信息管理与工程学院,上海 200433; 2.上海财经大学 上海市金融信息技术研究重点实验室,上海 200433)(*通信作者电子邮箱hlhuang@shufe.edu.cn)
0 引言
信息抽取是指从自然语言形式的文档中抽取人们所感兴趣的信息,并将其转变为结构化信息的过程。信息抽取研究的范畴包括:命名实体识别(如:人名、地名、机构名等),关系信息抽取,事件信息抽取(与事件有关的事件类别、时间、地点、参与者等)。本文所研究的对象是与金融事件有关的信息抽取。
一直以来,信息抽取工作所面临的主要困难之一是如何解决“自然语言表达的多样性、歧义性和结构性”[1]的问题,多样性是指同一种意思可以有多种表达方式,例如对公司收购事件,既可以用“A公司收购B公司”,也可以用“A公司买下B公司”来表达;歧义性是指同一词语在不同的上下文语境中存在着不同的含义,例如:“苹果公布iOS 9新系统”中的“苹果”指美国苹果公司,而“近日苹果批发价格一路走低”中“苹果”则是指一种水果;结构性是指自然语言所具有的内在结构,例如:“他从北京来到上海”和“他从上海来到北京”两个句子虽然都使用了相同的词语,但由于句子词语成分结构不同导致所表达的语义也不相同。如何采用语义分析的方法来解决这些问题一直以来都是自然语言处理研究领域所关注的核心问题之一。
事件信息抽取是信息抽取研究的一个重要子任务,ACE(Automatic Content Extraction) 2005将事件抽取任务定义成法律制裁(Justice)、冲突(Conflict)、商业(Business)等8个大类32种子类型任务[2],但是ACE 2005所定义的事件类型存在着类型过于宽泛、针对性不强的问题,例如Business中的Start-Org(组织成立)、Movement中的Transport(中转站)在使用中并无实际价值,不能真正满足现实社会对事件抽取的需求,因此还必须针对特定专业领域重新进行事模型和类型的定义。
本文针对以上问题,以中文金融新闻文本为研究对象,首先定义了一个包含5个大类、26种子类事件的金融事件表示模型;其次采用深度学习中的词向量(word vector)方法通过从新闻语料中提取出概念同义词来自动构建概念词典;最后采取基于有限状态机驱动的层次化的词汇-语义规则模式实现了从新闻文本中提取出与金融事件有关的大量关键信息(例如:事件类型、时间、地点、事件施事者、受事者、交易金额、交易数量等)。采用本文方法,在专业领域内能较好地解决以上存在的问题,具有一定的研究价值和实际意义。
1 相关研究
信息抽取的研究,按所采用的基本方法可以分为基于规则模式的方法和基于机器学习的方法两类。基于规则模式的方法的优点是所需要的标注语料较少,甚至可以不需要标注语料,规则可解释性强,易于调整,但这种方法存在着灵活性差、查全率较低、可移植性不好等问题[3]。目前基于规则模式的信息抽取所采用的主要方法有:正则表达式方法[4]、半结构化树(文档对象化模型树(Document Object Model Tree,DOM Tree))方法[5]、词汇-句法模式(Lexical-Syntactical)[6]和词汇-语义模式(Lexical-Semantic Pattern, LSP)[7]。基于机器学习的方法在实施中存在的主要困难是:学习模型效果的好坏在很大程度上依赖于训练语料的规模和标注质量,并且运行时间和效率均会随着语料中符号类别的多少呈线性增长[8]。
本文采用的词汇-语义模式是目前规则模式方法中所采用的主要方法之一。它针对词汇-句法模式所存在的对句法分析结果依赖性过强,不能精确描述同义词、反义词以及上位词之间的联系,不能按专业领域业务需求实现对词汇的概念化抽象等问题[9]进行了进一步的改进和语义增强。近年来的研究成果中,文献[10]通过先对事件动词采取同义词表达,再通过迭代匹配的方法来实现简单语义类型的事件抽取;文献[11]则采用更加复杂的基于本体的词汇-语义模式来实现命名实体和事件的抽取,这种方法的优点在于可以通过在本体中定义更加复杂的概念、类别、实例以及类别间的关系、限制条件等元素,使语义匹配引擎具有更加复杂的逻辑判断推理能力;在此基础上还进一步发展出了基于知识图谱[12]等辅助手段的方法。但以上研究中存在的显著问题是对同义词或本体概念、类别的定义都是通过手工方式完成的,所需要的工作量较大,而且同义词覆盖范围有限。文献[13]提出了一种采用Word2Vec来获得确定维度的词向量,并将其用于短文本分类中的方法,受其启发本文也通过采用Word2Vec的近义词识别功能来自动构建概念同义词典。
本文采用一种自然语言文本处理框架——通用文本处理框架(General Architecture for Text Engineering, GATE)[14]中的Java标注模式引擎(Java Annotation Pattern Engine, JAPE)语言[15]来开发词汇-语义规则模式并实现语义标注工作。这种采用JAPE语言来编写词汇-语义规则模式的方法已经被用于文档检索服务[16]、处理病历中的指代消解[17]、社交网络中的个体语言特征分析[18]和本体自动填充[19]等研究工作中,均取得了较好的效果。
2 事件表示模型
2.1 模型及定义
本文根据金融新闻事件的特点的定义了一个金融事件的表示模型e:
e=Ke∪Ae∪Re
(1)

定义1e由关键事件要素集合Ke、辅助事件要素集合Ae和推理事件要素集合Re构成。
定义2 关键事件要素集合Ke中定义的事件元素有:事件施事者(主体)Arg0,事件受事者(客体)Arg1,事件谓语动词类型Predicate,事件发生时间TMP,事件发布者Pub。关键事件要素是判断一个事件是否成立的充分必要条件,如果一条新闻语句中含有Ke中的元素,则可以判定该条新闻语句具有事件信息价值。
定义3 辅助事件要素集合Ae中定义的事件元素有:事件发生地点LOC,事件类型EventType,事件原因Cause,事件状态EventState。辅助事件要素集合是对事件信息的补充和完善。
定义4 推理事件要素集合Re中定义的事件元素有:标注类型为Lookup的中间过程元素Lookuptaggers,标注类型为Token的中间过程元素Tokentaggers以及其他一些标注类型为Event的过程元素。推理事件要素是本文词汇-语义模式在识别判断及抽取事件关键和辅助要素过程中使用的中间过程的概念语义元素,这类元素不构成最终的事件要素,但它们是规则模板用来推理判断事件类型和其他关键要素的重要依据。
2.2 事件类别及要素定义
本文定义了需要抽取的26种金融事件类别及其他要素如表1所示(鉴于篇幅有限,表1只列出部分内容)。

表1 事件类别及其他要素定义
3 基于词向量的概念词典构建
3.1 概念词典设计
概念词典是词汇-语义模式开展语义抽取工作的基础,它用于语义处理过程中的同义词识别和概念识别处理。本文采取词列表(Word List)的方式来表示概念词典。概念词典由一系列词表文件构成,概念词典文件的层次结构设计如图1所示。
概念词典的索引文件名称为list.def,它是所有概念词典文件的入口,该文件为纯文本文件格式,按每行一条进行内容安排,具体内容如下所示:
event_Verb_Statement.lst:事件动词类型:正式公告
event_Verb_Restruct.lst:事件动词类型:重组
…
每行由“:”分割为三部分:第1部分表示该类别概念所对应的词列表文件名;第2部分表示预定义的主类别(MajorType)如:事件动词类型;第3部分可选,表示预定义的次级类别(MinorType),例如:重组。在二级词列表文件中也是按每行一条的形式来定义具有相同MajorType和MinorType的词组集合,例如:event_Verb_Restruct.lst是与重组事件关键谓词对应的词列表文件,其具体内容为:
重组 方案
重组 预案
资产 重组
…
当文本中存在与以上任何一行相同的一组词条时,例如:“正泰电器(601877)11月9日晚间发布重组预案,…”,系统会采用最大后向匹配算法在“重组 预案”这两个词条节点上标注上类型为Lookup的标注,其属性MajorType=事件动词类型,MinorType=重组。

图1 概念词典的层次结构
3.2 概念词典构建
本文采用Word2Vec[20]中的基于Negative Sampling算法的连续词袋模型(Continuous Bag Of Words, CBOW)来训练词向量,并提取生成概念词典。对于给定的需要预测的正样本词w及其上下文context(w),希望获得的最大似然概率为:
(2)
其中:context(w)表示需要预测的词w的上下文窗口内的词,NEG(w)表示预测不是w的结果,也就是负样本的情况。p(u|context(w))可表示为:
p(u|context(w))=(σ(xwTθu))Lw(u)·
(1-σ(xwTθu))1-Lw(u)
(3)
其中:xw表示context(w)中各词的向量之和;θu表示词u所对应的辅助向量,它是待训练参数;Lw(u)是指示函数,当u=w时为1,否则为0;σ(xwTθu)表示当预测值为u(u∈{w}∪NEG(w))时的概率。
将式(3)代入式(2)可得:
(4)
由式(4)可知,最大化g(w)的过程就是最大化正样本概率σ(xwTθw),同时最小化负样本概率σ(xwTθu)的过程,因此对于给定的语料库C,总体的优化目标为:

(5)
当采用Word2Vec完成词向量训练后,采用以下概念词典的构建算法来完成同义概念词典的构建工作。
构建同义概念词典算法:
Input:同义词种子集合seed_set;已经训练完成的Word2Vec模型word2vec_model。
Output:同义词典文件synonym_dict。
Loadword2Vec_modelandseed_set
//加载Word2Vec模型和种子文件seed_set
dictionary={}
//扩展字典集合dictionary初始化
FOR eachwinseed_set:
//遍历种子集合
sim_words=word2vec.most_similar(w,k)
//word2vec模型中从获取与w近似值最大的前k个词
FOR each item insim_words:
//遍历集合
IF(item.sim>=0.7):
//保留近似值大于0.7的词
dictionary.put(item)
total_words=concatenate(seed_set,dictionary)
//拼接合并种子集合与扩展字典集合
total_words_permu=permutation(total_words)
//对total_words
//集合中的元素,固定种子词组为首词后进行排列组合
FOR eachwinseed_set:
FOR eachpermu_wordsintotal_words_permu:
IF(n_similarity(w,permu_words)>=0.7):
//遍历排列
//组合后的集合,并将与种子词组w之间相似度大于0.7的
//多元词组纳入扩展字典中
dictionary.put(pair_words)
Savedictionarytosynonym_dict
//将扩展字典保存到同义词文件中
4 层次化的词汇-语义模式设计
4.1 层次化标注结构设计
词汇-语义模式的规则表达式由3种元素构成,即:词汇信息(即标点符号、字、词的符号信息,如:“收购”),句法信息(即词性信息,如:动词)和语义信息(即概念信息,如:“收购事件动词”)。本文定义的标注类型如表2所示。
由于各标注类型在词汇-语义规则中存在着逐次提炼升华的内在关系,因此本文设计了一个层次化的标注结构,如图2所示。
其中:Layer0词条层是由完成分词后的词条节点Node集合。Layer1层是由标注类型为Token的节点构成的,它的每个节点与Layer0层中的词条节点构成一一对应的关系,Layer1上的节点主要用来存储词性标注信息。Layer2层是由标注类型为Lookup的节点构成的,它的每个节点与Layer0的节点是1∶n的关系,Layer2上的节点主要用来存储依据概念词典而自动标注的基本语义概念信息。Layer3层由标注类型为Event的节点构成,Event节点由词汇-语义规则在Token节点和Lookup节点的基础上产生,它主要存储更加高级的和面向领域的事件概念信息。

表2 语义标注类型
图2 层次化标注结构
采用这种层次化标注结构的优点在于:使用者可以根据需要在词汇-语义规则文件中灵活地抽出或插入某一标注层,这样在编写词汇-语义规则时不必考虑某种标注类型对规则语法的影响,从而极大地简化了规则编写的工作。
4.2 标注模型设计
本文基于有限状态机理论定义的词汇-语义规则标注模型为:
M=(Σ,Q,q0,F,Δ)
(6)
其中:
1)Σ为模型M的输入Token信息的集合,Σ={a1,a2,…,an},a1,a2,…,an为分词处理后形成的Token序列。
2)Q为模型M中有限的状态集合,在本文中Q指每条规则中的满足匹配语句的状态集合,例如对于以下所示例的词汇-语义规则文件:(括号内的字为对规则含义解释)。
Phase: Event_MiscBusProcess
//规则文件名
Input: Token Lookup Event
//引入规则中需要使用的标注层
Options: control=Appelt debug=true
//匹配优先级控制
Macro:ORG
//定义一个宏名
…
Rule: OrgRule
//定义规则左式
Priority: 100 (定义规则优先级)
(
({Lookup.minorType==~"(country|province|city)"})+
①
({Token.string!=~"[,,。::;;、d]+",
Lookup.majorType!=~"(title)"})[1,6]
②
(ORG_KEY_COMPANY)
③
(
{Token.string==~"[((]"}
({Token.string!=~"[。]"})[1,15]
{Token.string==~"[))]"}
)?
④
):MyOrg
-->//规则左式到右式转换符
{
//定义规则右式逻辑处理语句
gate.AnnotationSet org=
(gate.AnnotationSet) bindings.get("MyOrg");
gate.FeatureMap features=Factory.newFeatureMap();
…
outputAS.add(org.firstNode(),org.lastNode(),"Event",
features);
outputAS.removeAll(org);
}
Rule:BusIncomeRule2(开始一条新的规则)
Priority: 100
…
在这条规则中,Q共有6个状态即:初始状态q0和接受终止状态qf、规则中的①~④四条语句判断为真时所对应的状态分别为q1~q4,因此Q={q0,q1,q2,q3,q4,qf}。
3)q0代表模型M的初始状态,q0=∅。
4)F代表模型M的最终可接受状态集,F⊆Q,F={qf}。
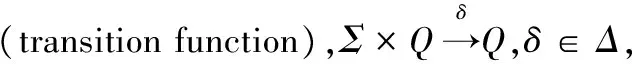
qi=δi(qi-1,ai)
(7)
其中ai为当前的输入Token。
6)对一个特定的输入Token序列,例如:Σ*={中南建设,6月,8日,晚间,公告,,,公司,拟,出资, 10亿,元,…},在状态机M上的匹配执行结果是一个状态序列:q0,q1,…,qn,qn表示终止状态,如果qn∈F则表示该Token序列被状态机接受(即匹配成功);否则被拒绝。
7)为了简化模型表示,M中不记录拒绝状态和转向拒绝状态的转移函数。
4.3 标注算法设计
词汇-语义规则标注算法如下。
Input:D,表示采用GATE ANNIE插件预处理后,已经标注有Token 和Lookup标注类型的输入文档;P,表示满足JAPE语法规则的词汇-语义规则文件集合。
Output:MLAnnotateSet,表示输出的标注类型为Event的语义标注集合。
FOR eachphaseiinP
//phasei为P中的某一规则文件
Getting all annotations fromoutASList of Last (i-1) phase and put them ininASlist
//将上一个规则文件的处理
//结果取出放入当前处理序列inAS中
FOR eachrulejinphasei.Rules:
//对phasei中的规则进行遍历
FOR eachD.NodeskinD:
//D.Nodesk为文档
//D中的Token节点
L.put(D.Nodesk)
//将D.Nodesk放入列表L中
Initialization Finite State MachineMjrespect torulej,LetQ={q0,qf},Δ={δ1,δ2,…,δn},q0=∅
//初始化状态机Mj
IF( {L1,L2,…,Ln} are accepted byMj):
//当满足规则子句匹配条件时
①Feed annotation set ininASwhich cover {L1,L2,…,Ln} to RHS for creating new semantic annotation and put computing results intooutASlist
//将匹配的标注集合
//送入词汇-语义规则右式(RHS)进行程序逻辑处理,
//并产生新的语义标注信息
②L=L-{L1,L2,…,Ln}
//继续执行下一段Token的
//规则匹配操作
ELSE:
Search nextMj+1
//查找规则文件中的下一条
//规则再重新开始匹配操作
Getting all semantic annotation which type is "MLTag" fromoutASlist, and put them inMLAnnotateSet
//获得类型为MLTag的
//语义标注集合
4.4 标注算法的空间复杂度和时间复杂度分析
算法的空间复杂度是指一个算法在运行过程中临时占用存储空间大小的度量,一般用:S(n)=O(f(n))来表示,其中n表示问题规模的大小,在本文中指需要进行语义标注的新闻文本语料的大小。标注算法在计算机存储器上存储的空间S由算法本身的空间S1,输入输出数据所占据的存储空间S2和算法在运行过程中临时占用的存储空间S3组成,即:
S=S1+S2+S3
(8)
在本文中标注算法本身由固定数目的程序行组成,而不受问题规模n的大小影响,因此:S1=O(1);S2与输入输出语料的规模n一阶线性相关,因此可表示为:S2=O(n);在标注算法中由于不存在递归调用和二分法查找的情况,S3的大小只与问题规模n一阶线性相关,因此:S3=O(n)。综合以上分析标注算法的空间复杂度为:
S=S1+S2+S3=O(1)+2O(n)
(9)
算法的时间复杂度是指当问题规模为n时,算法所需要的最长运行时间,一般用T(n)=O(f(n))来表示,在本文标注算法中问题规模n指需要进行标注的新闻语料大小。由4.3节所示,标注算法主要由:对所有输入语料文档的遍历循环T1(假设输入文档的个数为n1),对所有规则文件的遍历循环T2(假设规则文件的个数为n2),对单个规则文件内的子规则遍历循环T3(假设每个规则文件内平均子规则个数为n3),对单个输入文档内Token层节点的遍历循环T4(假设每个输入文档内的平均Token节点个数为n4)组成,则本文标注算法的时间复杂度可用式(10)表示:
T=T1×T2×T3×T4=O(n1×n2×n3×n4)
(10)
5 实验与分析
5.1 实验数据设置
采用网络爬虫技术从东方财富网的公司新闻频道和新浪财经上市公司新闻频道爬取了2015年全年共计122 366条金融类新闻报道,并从中随机抽取了5 000条不重复的新闻报道作为测试样本进行了事件类别手工标注处理,选取文本中的首段前2句作为语料来验证事件信息抽取效果。本文3.2节中Word2Vec所采用的模型训练语料则是来自东方财富网公司新闻频道2015—2017年共计194 466篇新闻报道全文,累计1.59亿汉字的训练规模。
5.2 信息抽取结果
实验中共计生成5 000篇信息标注XML文档,本文选用一个例子来说明事件信息抽取的实际效果。
1)原始语料:27日晚间,临时停牌一天的暴风科技在晚间揭晓了停牌原因。公司正在筹划重大资产重组事项,拟以发行股份及支付现金方式收购专业从事文学作品版权运营的公司,交易金额预计不低于6亿元。
2)经过词汇-语义规则处理后事件信息的最终标注的结果部分内容是:
a)AnnotationImpl:id=79;type=FinalTag;features={rule=Event_BuyRule,time=2015年10月27日20时,transaction_method=拟以发行股份及支付现金方式,event_type=PlanBuy,agents=[{string=暴风科技,label=已识别机构名}],patients=[{string=事项,label=非机构名,type=直接标的物},{string=专业从事文学作品版权运营的公司,label=非机构名,type=直接标的物}]};start=NodeImpl:id=64;offset=88;end=NodeImpl:id=65;offset=90。
b)AnnotationImpl:id=80;type=FinalTag;features={rule=Event_WantCapitalRule,time=2015年10月27日20时,wantCapital_type=非公开发行,event_type=PlanWantCapital,agents=(略)。
c)AnnotationImpl:id=81;type=FinalTag;features={rule=Event_RestructRule,time=2015年10月27日20时,event_type=PlanRestr,agents=(略)。
结果分析:
1)所有抽取的事件要素都实现了以属性的形式存储于features集合中。本例中,共从实例文本中共抽取出了三类事件及其属性信息(拟收购、拟募资、拟重组),分别处理为三条类型为FinalTag的标注。
2)本例中抽取的所有事件要素汇总如表3所示。

表3 事件要素抽取结果汇总
5.3 事件类型的识别效果
为了考察本文方法对事件类型识别的能力,对属于26类金融事件的2 414条测试样本进行了事件类别识别测试,测试样本数排名前10位的事件类别识别结果如表4所示。其中:P(Precision)为准确率,R(Recall)为召回率,F1(F1 Measure)为F1测量值。
26种事件类型总的识别结果如图3所示,分类指标的微平均值为:Micro_F1=0.903,Micro_Precision=0.939,Micro_Recall=0.869。
重大合同事件虽然样本数较多(105个)但召回率指标表现较低(R=0.563,P=0.952,F1=0.708),其原因是针对重大合同事件的词汇-语义规则语句的覆盖程度不够,还有待进一步拓展提升。而“重组通过”这类事件指标表现较低的原因一方面同样是因为针对该类事件的词汇-语义规则语句的覆盖程度不够,另一方面也与样本数过少(仅16个)有关,因此需要增加更多的该类事件的测试样本。
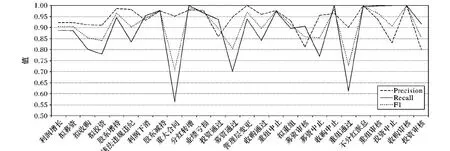
图3 26类金融事件类别识别结果

Tab. 4 Event identification results of top 10 samples
5.4 与机器学习方法的比较
为了进一步分析本文所提出的基于规则模式方法与机器学习方法在事件分类方面的效果差异,在使用相同测试样本数据集的基础上,分别采用本文方法(Lexical-Semantic Pattern, LSP)与基于支持向量机(Support Vector Machine, SVM)[21]、朴素贝叶斯(Naïve Bayes, NB)[22]、K近邻(K-Nearest Neighbor,KNN)[23]3种机器学习分类算法(输入特征分别采取:文本分词并去除停用词后的词条作为输入特征集合(Segmentation, SEG)和通过本文方法获取的事件要素(语义标注)作为输入特征集合(Semantic, SEM)两种方式),进行综合比较,所有事件类型的微平均结果如表5所示。
从表5可知采用本文所述方法(LSP)比所有的机器学习方法所获得的分类指标结果都有较大幅度的提升,例如:本文方法的微平均F1(Micro_F1)值(0.903)比3种机器学习方法中最高的F1值(0.814)(NB+SEM方法)提高了8.9个百分点)。这说明基于词汇-语义规则模式的事件分类方法虽然相比机器学习方法存在灵活性和通用性差,而且规则编制的手工工作量大等缺点;但当其应用于特定行业领域时,与机器学习方法相比往往能够获得更好的事件分类效果,并且随着规则的不断完善和优化,指标提升的空间也很大。
从与其他文献的研究结果比较来看,在各自使用不同数据和所处场景的条件下,本文方法获得的3种指标的微平均值都超过了0.85,其效果要略好于文献[24]的结果,该文献采用统计学习方式(基于Labed_LDA(Latent Dirichlet Allocation)模型)在最大10个主题类别上获得的事件分类指标Micor_F1值为0.908;而普通的SVM方法在10类时Micro_F1的值只有0.85左右,而本文方法获得的Micor_F1指标为0.903,且本文涉及的事件分类数目是26种,分类的难度高于10种类别。
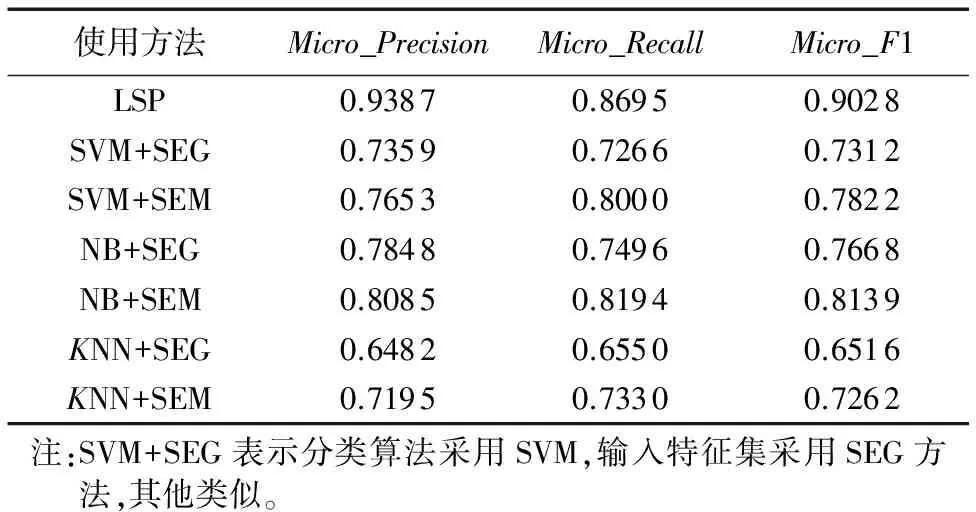
表5 多种方法的微平均指标汇总
6 结语
本文采用基于层次化词汇-语义规则模式的方法从金融新闻文本中提取出事件类别、参与人、时间、地点、交易金额等大量与金融事件相关的语义要素信息。本文的创新之处在于:1)定义了一个面向实际行业应用的金融事件表示模型;2)采用一种新的基于深度学习方法(Word2Vector)来自动生成概念同义词典的方法,解决了传统手工方式编制概念同义词典费时费力的问题;3)设计了一种基于有限状态机驱动的层次化的词汇-语义规则标注模式方法,从而实现了对事件语义标注信息的层次化提取和抽象。
采用本文方法可以有效地解决传统的基于词汇或词汇-句法规则方法中所存着的:对句法分析结果依赖性过强,不能精确描述同义词、反义词以及上位词之间的联系,不能按专业领域业务需求实现对词汇的概念化抽象等问题。本文存在的不足是由于这种层次化词汇-语义模式方法是面向专业领域的,因此针对其他专业领域的文本信息抽取任务还需要设计不同的信息表示模型,编制不同的规则语句来实现。
References)
[1] 中国中文信息学会.中文信息处理发展报告[EB/OL].(2016- 12- 23) [2017- 01- 15].http://cips-upload.bj.bcebos.com/cips2016.pdf.(Chinese Information Processing Society of China. Chinese information processing development report[EB/OL].(2016- 12- 23) [2017- 01- 15]. http://cips-upload.bj.bcebos.com/cips2016.pdf.)
[2] LI P, ZHU Q, DIAO H, et al. Joint modeling of trigger identification and event type determination in Chinese event extraction [C]// COLING 2012: Proceedings of the 24th International Conference on Computational Linguistics. Mumbai: [s.n.], 2012: 1635-1652.
[3] HOGENBOOM F, FRASINCAR F, KAYMAK U, et al. A survey of event extraction methods from text for decision support systems [J]. Decision Support Systems, 2016, 85: 12-22.
[4] 罗明,黄海量.一种基于有限状态机的中文地址标准化方法[J].计算机应用研究,2016,33(12):3691-3695.(LUO M, HUANG H L. New method of Chinese address standardization based on finite state machine theory [J]. Application Research of Computers, 2016, 33(12): 3691-3695.)
[5] CHANG C H, CHUANG H M, HUANG C Y, et al. Enhancing POI search on maps via online address extraction and associated information segmentation [J]. Applied Intelligence, 2016, 44(3): 539-556.
[6] AL ZAMIL M G H, CAN A B, et al. ROLEX-SP: rules of lexical syntactic patterns for free text categorization [J]. Knowledge-Based Systems, 2011, 24(1): 58-65.
[7] 刘丹丹,彭成,钱龙华,等.词汇语义信息对中文实体关系抽取影响的比较[J].计算机应用,2012,32(8):2238-2244.(LIU D D, PENG C, QIAN L H, et al. Comparative analysis of impact of lexical semantic information on Chinese entity relation extraction [J].Journal of Computer Applications, 2012, 32(8): 2238-2244.)
[8] 宗成庆.统计自然语言处理[M].2版.北京:清华大学出版社,2013:110-128.(ZONG C Q. Statistical Natural Language Processing [M]. 2nd ed. Beijing: Tsinghua University Press, 2013: 110-128.)
[9] 李培峰,周国栋,朱巧明.基于语义的中文事件触发词抽取联合模型[J].软件学报,2016,27(2): 280-294.(LI P F, ZHOU G D, ZHU Q M. Semantics-based joint model of Chinese event trigger extraction [J]. Journal of Software, 2016, 27(2): 280-294.)
[10] ATKINSON M, DU M, PISKORSKI J, et al. Techniques for multilingual security-related event extraction from online news [M]// Computational Linguistics. Berlin: Springer, 2013: 163-186.
[11] 孙明.语义Web使用挖掘若干关键技术研究[D].成都:电子科技大学,2009:37-49.(SUN M. Research on some key issues for semantic Web usage mining [D]. Chengdu: University of Electronic Science and Technology of China, 2009: 37-49.)
[12] WANG W, ZHAO D, et al. Ontology-based event modeling for semantic understanding of Chinese news story [M]// Natural Language Processing and Chinese Computing. Berlin: Springer, 2012: 58-68.
[13] ZHANG Y, LIU J. Microblogging short text classification based on Word2Vec [C]// Proceedings of the 2016 International Conference on Electronic, Mechanical, Information and Management. [S.l.]: Atlantis Press, 2016: 395-401.
[14] CUNNINGHAM H, MAYNARD D, BONTCHEVA K, et al. GATE: a framework and graphical development environment for robust NLP tools and applications [C]// Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Oxford: Oxford University Press, 2002: 47-51.
[15] CUNNINGHAM H, MAYNARD D, TABLAN V, et al. JAPE: a Java Annotation Patterns Engine [EB/OL]. (2000- 10- 12)[2016- 06- 12]. http://www.dcs.shef.ac.uk/intranet/research/public/resmes/CS0010.pdf.
[16] FUENTES-LORENZO D, NDEZ N, FISTEUS J, et al. Improving large-scale search engines with semantic annotations [J]. Expert Systems with Applications, 2013, 40(6): 2287-2296.
[17] GOOCH P, ROUDSARI A. Lexical patterns, features and knowledge resources for conference resolution in clinical notes [J]. Journal of Biomedical Informatics, 2012, 45(5): 901-912.
[18] FERNANDEZ M, PICCOLO L S G, MAYNARD D, et al. Talking climate change via social media: communication, engagement and behavior [C]// Proceedings of the 2016 ACM Conference on Web Science. New York: ACM, 2016: 85-94.
[19] 王俊华,左万利,彭涛.面向文本的本体学习方法[J].吉林大学学报(工学版),2015,45(1): 236-244.(WANG J H, ZUO W L, PENG T. Test-oriented ontology learning methods [J]. Journal of Jilin University (Engineering and Technology Edition), 2015, 45(1): 236-244.)
[20] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [C]// Proceedings of the 2013 International Conference on Neural Information Processing Systems. West Chester, OH: Curran Associates Inc., 2013: 3111-3119.
[21] ALTINEL B, DIRI B, GANIZ M C. A novel semantic smoothing kernel for text classification with class-based weighting [J]. Knowledge-Based Systems, 2015, 89: 265-277.
[22] ZHANG L, JIANG L, LI C, et al. Two feature weighting approaches for naive Bayes text classifiers [J]. Knowledge-Based Systems, 2016, 100:137-144.
[23] ZHANG X, LI Y, KOTAGIRI R, et al.KRNN:K, Rare-class nearest neighbour classification [J]. Pattern Recognition, 2016, 62:33-44.
[24] 李文波,孙乐,张大鲲.基于Labeled-LDA模型的文本分类新算法[J].计算机学报,2008,31(4): 620-627.(LI W B, SUN L, ZHANG D K. Text classification based on labeled-LDA model [J]. Chinese Journal of Computers, 2008, 31(4): 620-627.)
This work is partially supported by the Shanghai Science and Technology Talents Project (14XD1421000), the Shanghai Science and Technology Innovation Action Plan Project (16511102900).
LUOMing, born in 1974, Ph. D., senior engineer. His research interests include data mining, natural language processing, artificial intelligence.
HUANGHailiang, born in 1975, Ph. D., professor. His research interests include big data technology, AI method and their applications in field of finance and economics.
