面向大规模数据接入系统的负载平衡机制
2018-03-20陈庆奎
周 岳,陈庆奎
(上海理工大学 光电信息与计算机工程学院,上海 200093)(*通信作者电子邮箱chenqingkui@usst.edu.cn)
0 引言
随着计算机信息技术与互联网技术的快速发展,网络数据资源呈现爆发式增长。文献[1-2]研究表明,日益增长的数据,会对服务平台的接收、处理和存储数据的能力带来巨大压力。面对快速增长的数据量,有必要进一步提高服务平台的接收能力。分布式系统通过网络组织廉价计算机,来完成单台服务器无法接收、处理和存储的任务。分布式系统中的应用程序可以分成多个任务,分别执行在不同的计算机节点上,各个任务可以并发执行。实践表明,分布式系统能够显著提升服务平台接收、处理和存储数据的能力。
文献[3]指出,由于分布式系统内存在任务的多样性和各节点性能的差异性,导致集群内存在负载不平衡现象。负载的不平衡性导致分布式系统无法充分发挥其并行处理的性能。如果负载差异过大,还会进一步导致系统的处理速度下降、网络延迟增加、任务的响应速度下降等。
当前对于负载平衡的研究有很多,如文献[4-6],分别提出了不同的解决方案,这些研究都取得了不错的成果,但是仍然遗留很多问题有待解决。目前负载平衡系统仍然还存在文献[7]中提及的问题:1)平衡系统各节点角色固定,系统不具有自适应性。当前分布式系统是通过节点冗余来实现系统的鲁棒性,要求在负载平衡系统中对不同功能节点都要进行备份冗余。该方案造成资源开销过大。通过节点角色自适应,能有效减少备份节点数目,降低资源的消耗。2)模型的通用性不高,大部分负载平衡系统的研究都是针对特定的应用场景。负载平衡模型适用场景有限。当一个大型系统中存在多种子系统时,系统往往需要为每个子系统单独设计负载平衡系统。这就导致系统过于复杂,而且影响系统的可扩展性。3)任务整体迁移导致资源大量消耗,而且平衡周期过长等问题。当前任务迁移具有指向性,在负载平衡任务迁移过程中,负载较轻的节点短期内会被大量迁入任务,导致这类节点负载过重再次触发负载平衡;这样周期往复的震荡性,严重影响系统的性能。
针对这些问题,本文提出了混合式负载迁移平衡算法。算法设计以最小化迁移任务为目标,尽量减少任务的迁移,节约系统资源;同时为了减少备份冗余造成节点资源的浪费,该负载平衡方案采取节点自适应策略,各个节点互为备份节点。实验表明,系统具有负载平衡周期短、任务响应时延短等特点。
1 相关工作
一般来说,现行的负载平衡控制模式有3种:集中式控制模式、分布式控制模式和混合式控制模式。
集中式控制模式指定一个节点来负责全系统的任务调度和监督收集各节点的运行状况,如图1(a)所示。集中式控制模式比较简单,系统全局资源利用率最高;但是该模式容易造成控制节点计算量大、内存开销大、易产生瓶颈,且该模式不利于系统扩展。文献[8]研究表明集中式控制模式一般用于小型系统中,不适合使用在大规模分布式系统中。随着系统规模的扩大,集中式控制模式往往不可行。
在分布式控制模式中,每个节点自主完成任务调度,如图1(b)所示。分布式控制模式中,每个节点与周围若干个节点相连,并收集周围节点的运行状况。分布式控制模式容错性较强,且易于扩展,但是分布式负载平衡控制模式比较复杂。目前这种负载平衡策略分为3种:第一类是基于市场学的迁移策略,如Izakian等[9]提出的连续双次竞争(Continuous Double Auction, CDA)分配任务方法。该方法通过计算迁移任务后系统的整体性能收益,来决定是否进行任务迁移。第二类是基于社会学的迁移策略,如Wang等[10]提出的贪婪算法。在该算法中负载节点在其相连的局域网内使用贪婪算法,选择局部最优的方案进行任务迁移。第三类是通过一些其他方式来进行负载分配的方案,如文献[11]提出的自适应负载分配方案、文献[12]提出的资源竞争负载分配方案等。分布式模式的负载平衡面临较高的负载计算成本,且负载通信占用大量网络带宽。
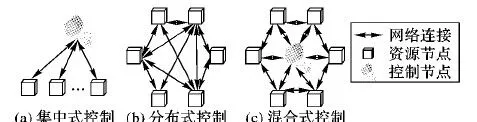
图1 3种控制模式结构
为了克服以上两种控制模式的缺点,混合式控制模式应运而生。如图1(c)所示,资源节点与周围若干个节点相连的同时,又与其所在局部网络内的中心节点相连。在局部网络内使用集中控制模式,实现每个局域网资源利用率最大化,进而实现资源全局利用最大化。在整个集群内使用分布式模式,提高系统的可扩展性。通过这种方式能够有效结合集中控制模式和分布式控制模式的优点,提升系统的整体性能。
虽然以上模型提供了很好的性能,但是仍然存在系统中节点角色固定、模型通用性差和系统负载周期长等问题。为了解决这些问题,本文提出了混合式负载平衡策略。
2 接入系统模型
为了提高服务平台系统的接收能力,本文对接入系统进行了优化设计。如图2所示,接入系统分为三层:数据接收层、业务处理层和数据存取层。为了实现各层之间的解耦合,各个层次不直接交互,数据共享通过数据缓冲区实现。各层可以部署在不同机器上,也可以部署在同一台机器上。不同的是部署在不同机器上时,数据的共享通过网络传输实现。因为现有的分布式处理系统和分布式存储系统相对成熟,所以在这两层,本文直接使用现有技术。下面重点讨论数据接收层。

图2 接入系统结构
2.1 数据接收层
在数据接收层,本文使用用户数据报协议(User Datagram Protocol, UDP)。使用UDP的原因是:1)实时性高,UDP注重的是数据包的吞吐量,这和追求的高数据接收能力吻合。2)与传输控制协议(Transmission Control Protocol, TCP)相比,UDP在数据传输前不需要先建立连接,这意味着便于通信扩展,且节约系统资源。但是UDP通信协议不是一个可靠的通信协议,针对这一问题,本文在UDP通信协议的基础上设计了一个可靠的传输协议。该传输协议通过数据包重传技术确保通信可靠。
为了实现重传,首先使得计算机能够区分每个数据包来源,及数据包到达的先后顺序。协议为每个数据包添加一个标识(Identification, ID)字段,用来标识数据源,并在数据包中添加包序号字段,来区分数据包到达的先后顺序。在接收层为每个向系统传输数据的数据源开辟一个临时缓冲区。缓冲区格式如图3所示。ID标识不同数据源,数字编号表示包的序号。

图3 临时缓冲区结构
Fig. 3 Temporary buffer structure
传输机制为数据源周期向接入系统发送数据包,每个周期内包的序号唯一。当数据包到达接入系统后,系统删除对应缓冲区内数字编号。当一个传输周期过后,数据源向接入系统发送一个传输周期结束标识。然后接入系统检查对应ID的临时缓冲区,如果缓冲区为空,则不需重传;如果缓冲区不空,则将存在的序号发送给数据源,数据源重新发送对应序号的数据包。反复执行以上步骤直到数据包全部到达。
2.2 数据传输分析
假设向系统传输数据的数据源的网络丢包率为1-p,数据源需要传送n个数据包,那么对于成功传送第i个数据包的概率pi为:
pi=(1-p)k×p
(1)
假设数据源一次传送一个数据包耗时为t,那么成功传送第i个数据包耗时的期望值E(ti)为:
E(ti)=t×p+t×p×(1-p)+…+t×p×(1-p)k-1
(2)
即:
E(ti)=t×(1-(1-p)k)
(3)
其中,k为第i个数据包发送次数。由此可得数据源传送n个数据包的总耗时期望值E(T)为:
(4)
从式(4)中,容易看出,系统的接收效率与网络环境有关:网络环境越好,系统的接收能力越强;反之,系统的接收能力下降。
3 负载平衡策略
结合已有的经典负载平衡模型,本文提出了混合式负载平衡策略。如图4所示,算法建立的模型分为三层,分别是任务分配层、负载控制层和资源层。
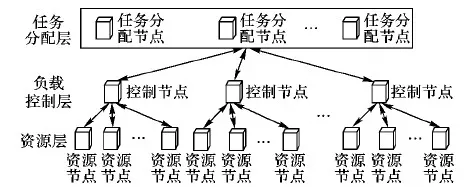
图4 负载平衡模型的结构
3.1 任务分配层
为了确保任务分配层的可靠性,该层中每个任务分配节点对等,同时进行任务接收、分配和控制节点的负载信息的收集,每个节点互为备份。这样设计的好处是既可以增强该层的鲁棒性,又可以防止任务层成为系统的瓶颈,便于任务层的横向扩展。
任务分配节点接收到任务请求时,如果节点过于繁忙则拒绝服务。请求将以退避算法向剩余节点发出请求。当任务分配节点接收任务后,根据控制节点的负载情况,随机地转发给负载较低的控制节点。控制节点接收到任务的概率与其负载程度成反比,即节点负载越重接收到任务的概率越低。
任务分配节点负责分配任务的同时,还需要负载控制节点的负载平衡。如果发生过载,则通知任务负载过重的节点进行负载迁移,一个负载周期内节点只执行一次负载迁移指令。任务迁出的策略是以资源节点为单位进行迁移,迁出任务最重的节点,这样可以快速降低负载率。迁入的对象为负载较轻的控制节点。这类控制节点接收到资源节点的概率与其负载成反比,即负载越轻接收到资源节点的概率越大。
3.2 控制层
负载控制层由m个控制节点组成。节点之间工作相互独立,互不干扰。每个节点连接n个资源节点,形成一个小的局域网,在局域网内使用集中式负载平衡进行管理。控制节点的可靠性由资源节点提供。如果控制节点宕机,那么将从这n个资源节点中,选择一个新的节点作为控制节点,同时该节点的所有任务全部迁出到剩下的n-1个节点。通过这种方式,负载控制层可以不需要对控制节点进行备份,实现节点角色的动态变更,节约系统资源。
控制节点接收到任务后,根据资源节点的负载信息随机分配任务到负载较轻的资源节点。资源节点接收到任务的概率也是与其负载程度成反比,即节点负载越重接收到的任务概率越低。
控制节点在其局域网内作为中心控制节点。如果发生过载,则其通知任务负载过重的资源节点进行负载迁移。迁移策略是以数据源为单位,迁出执行通信最少的数据源。采用随机方式,将任务迁移到负载相对较轻的一些节点。资源节点接收到任务的概率与其负载成反比,即负载越轻接收到任务的概率越大。迁出通信最少的数据源是防止系统做过多重复性工作,同时减少任务迁移带来的网络通信。
3.3 资源层
资源层是系统的资源真正提供者。这里的资源不包含存储之类的持久化资源。持久化资源被使用频率低,且必须通过冗余备份来保证其可靠性。文献[13-14]中对这方面的介绍相当全面,目前对于这方面的研究已经相当成熟,本文将不再作进一步讨论,因此本文讨论的资源泛指中央处理器(Central Processing Unit, CPU)计算资源、内存资源和通信资源等。资源的可靠性只通过设备的可靠性保证。因为使用这类资源的任务比较多且工作量巨大,通过备份实现可靠性不现实,因此,目前文献[4,6,9]中都是通过设备的可靠性来保证资源的可靠性。如果资源节点失效,那么资源使用方则需要重新发送任务给任务分配节点请求资源。
3.4 负载迁移执行过程
整个系统执行负载平衡步骤如下。
步骤1 任务分配节点接收到来自数据源发送的接入请求。如果任务分配节点负载过重,则放弃服务,数据源使用退避算法再次申请;反之,任务节点根据控制节点负载信息,随机将接入请求转发给控制节点。控制节点接收到接入请求的概率与其负载程度成反比。接着执行步骤2。
步骤2 控制节点接收到接入请求。根据资源节点的负载信息,随机选中一个资源节点负责接收数据源数据,资源节点被选中概率与其负载程度成反比。接着执行步骤3。
步骤3 资源节点与数据源通信。资源节点定期计算自身负载值;如果超过警戒值,则立刻给控制节点发送过载警告,执行步骤4。
步骤4 控制节点接收到资源节点的负载过载信息后,计算自身负载值:如果超过警戒值,则通知任务分配层进行控制层负载平衡;反之则通知局域网内资源节点进行负载迁移。
3.5 负载分析
负载平衡的本质是提高整体系统资源利用率,平衡系统资源使用,使系统整体响应时间最短、数据吞吐量最大。系统整体响应时间和吞吐量一般与节点的网络带宽、CPU计算资源内存大小等相关;此外数据包丢失率能直接体现当前系统接收负载状况,因此本文给出衡量资源节点的负载公式如式(5)所示:

(5)
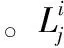
由式(5),可计算出每个控制节点的局域网内的负载总和:
(6)
在式(6)中,n表示控制节点所连接的资源节点个数。Li表示第i个控制节点所在局域网内负载总和。因为每个控制节点连接的资源节点个数不同,所以本文使用总体负载的平均值来衡量控制节点所连接的局域网内负载情况,则有:
(7)
本文使用标准差来衡量每个局域网内负载平衡性,则有:
(8)
当SDi值超过负载平衡阈值φ时,则触发资源节点的负载平衡。
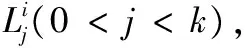
(9)
那么,在这k个节点中第j个节点应该被分配任务的概率为:

(10)

控制节点的负载计算分为两部分:第一部分为节点本身的网络带宽、CPU计算资源和内存资源的消耗;第二部分为节点负责的局域网内资源节点负载的平均水平。
每个控制节点的局域网内的负载水平并不能体现整个系统的负载状况,为了实现全局负载平衡,必须把局域网内的负载水平体现在控制节点的负载信息上。这样可以通过控制节点的负载平衡,来实现全局负载平衡。控制节点的负载为:
CLi=α′×Nru/Nr+β′×Cru/Cr+γ′×Mru/Mr+
θ×averag(Li)
(11)
其中:CLi表示第i个控制节点的负载值;α′+β′+γ′+θ=1且1>α′>0,1>β′>0,1>γ′>0,1>θ>0,α′、β′、γ′分别表示网络带宽、CPU计算资源和内存资源在系统资源中的权重;θ表示局域网内平均负载相对于控制节点负载的比重。
因此,系统中m个控制节点的整体负载为:
(12)
进而,易得控制节点的平均负载值为:
(13)
最终,控制节点负载方差为:
(14)
当SDCL的值负载平衡阈值大于φ′时,控制节点通知任务分配节点其负载过载,然后任务分配节点通知控制节点进行任务迁移。
同CPU计算资源节点在局域网络获得任务的概率计算方式一样,假设系统中有m个节点,选定k′个节点作为任务分配节点,每个节点的负载为CLi,0 (15) (16) 本文在3个计算机集群上进行模拟实验,分别是:1)发送集群。由8台计算机组成,用来模拟数据源向服务平台发送数据。2)接收集群。由4台计算机组成,用来模拟服务平台,负责接收、处理和转发存储数据。3)存储集群。由10台计算组成,用来作数据的存储。为了简化实验,本文按照如表1参数进行实验。 表1 系统参数 实验分析如下所示。 实验数据包大小分为3种:125 B、175 B与200 B。本文接收系统在不同接收速度下,采用多次仿真取平均值的方法,通过丢包率,重传包数量、接收与处理延时、处理与存储延迟和负载耗时来衡量接入系统和负载平衡算法的性能。 图5~6为丢包率和重传包数量随接收速度变化趋势。 图5 不同接收速度下的丢包率 从图5~6中可以看出,系统在接收速度小于50万packet/s时,系统丢包率和重传数量为0。随着接收速度的增加,系统的丢包率开始增加。为了保证通信可靠,重传包数迅速增加。这是因为接收速度受数据源发送速度影响,当数据源发送数据包速度过快时,网络出现拥塞。从图5~6中可看出,网络状况很好的情况下,系统有很好的接收能力。从图中还可以看出,不同大小的数据包对接收系统也有一定影响,这是因为接收速度一定时,数据包越大,网络带宽被占用越多。从这一方面,也可以证明系统接收能力受网络状况影响。 图6 不同接收速度下的重传数据包数 图7与图8描述的是系统各个处理层之间的处理延时情况。从图7中,可以看出随着接收速度的增加,接收到的数据包和处理之间的延时增加。这是由于处理速度最大值小于接收速度最大值,当接收速度高于处理速度时,数据包会累积在缓冲区内,导致处理延时的增加。从图8中,可以看出随着接收速度增加,处理延时和存储延时反而减小。这是因为本文为了提高存储效率,对存储进行了优化。为了减少存取层访问数据库的次数,只有数据在缓冲区内过期或者待存储的数据过多时,存取层才访问数据库,因此,当接收速度增加时,处理速度也被迫增加,数据缓冲区内待存储的数据快速累积,导致触发存储次数增加,因此处理与存储延时变小。从两幅图中可以看出,数据包越大,处理和存储延时相对越大。这是因为数据包大导致处理速度变慢,所以触发存储次数相对较少。 图7 接收与处理延时 图8 处理与存储延时 为了触发负载平衡,实验开始时,先向分布式并发系统中单台机器发送数据,这样可以快速触发系统的负载平衡,以此来观测系统负载平衡速度。实验分别模拟26万、34万、42万、50万、58万、66万、74万和82万个数据源分别向系统发送数据包时系统的负载平衡耗时情况。 从图9中可以看出,系统的负载耗时随负载压力的增大而增大;负载压力越大,负载平衡耗时增加越快。这是因为负载压力越大,网络资源消耗越大,那么负载的耗时也就会越长。从图9中还可以看出,不同大小的通信数据包导致的负载耗时也不相同。这是因为发送数据包的速度一定,那么数据包越大,占用的网络带宽越大,导致系统通信延迟增加,进而导致系统负载耗时的增加。 图9 负载平衡耗时 随着网络数据的快速增长,分布式系统应用越来越广。为了提高分布式系统的数据接入能力,有必要对负载平衡遗留问题作进一步研究。本文在已有的负载平衡模型的基础上,提出了混合式负载迁移平衡算法。实验表明,基于该负载平衡策略的系统能在很短时间内完成负载平衡任务,任务响应迅速,且节点具有自适应性。 本文算法也存在局限性和不足,还需在真实环境进行检验。本文算法考虑的资源问题只关注节点自身,没有考虑多个节点协同工作情况下负载平衡的实现方式。这是目前负载平衡研究的一个难题,日后也将该问题作为主要的研究方向。 References) [1] 廖锋,成静静.大数据环境下Hadoop分布式系统的研究与设计[J].广东通信技术,2013(10):22-27.(LIAO F, CHENG J J. Research and design of Hadoop distributed system under big data environment [J]. Guangdong Communication Technology, 2013(10): 22-27.) [2] HASHEM I A T, YAQOOB I, ANUAR N B, et al. The rise of “big data” on cloud computing: review and open research issues [J]. Information Systems, 2015, 47: 98-115. [3] 房俊华,王晓桐,张蓉,等.分布式数据流上的高性能分发策略[J].软件学报,2017,28(3):563-578.(FANG J H, WANG X T, ZHANG R, et al. A high performance distribution policy on distributed data streams [J]. Journal of Software, 2017, 28(3): 563-578.) [4] JIANG Y, ZHOU Y, WANG W. Task allocation for undependable multiagent systems in social networks [J]. IEEE Transactions on Parallel and Distributed Systems, 2013, 24(8): 1671-1681. [5] PENMATSA S, CHRONOPOULOS A T. Game-theoretic static load balancing for distributed systems [J]. Journal of Parallel and Distributed Computing, 2011, 71(4): 537-555. [6] TONG Z, XIAO Z, LI K, et al. Proactive scheduling in distributed computing—A reinforcement learning approach [J]. Journal of Parallel and Distributed Computing, 2014, 74(7): 2662-2672. [7] JIANG Y. A survey of task allocation and load balancing in distributed systems [J]. IEEE Transactions on Parallel & Distributed Systems, 2016, 27(2): 585-599. [8] VAN DER HORST J, NOBLE J. Distributed and centralized task allocation: when and where to use them [C]// SASOW 2010: Proceedings of the 2010 Fourth IEEE International Conference on Self-Adaptive and Self-Organizing Systems Workshop. Piscataway, NJ: IEEE, 2010: 1-8. [9] IZAKIAN H, ABRAHAM A, LADANI B T. An auction method for resource allocation in computational grids [J]. Future Generation Computer Systems, 2010, 26(2): 228-235. [10] WANG W, JIANG Y. Community-aware task allocation for social networked multiagent systems [J]. IEEE Transactions on Cybernetics, 2014, 44(9): 1529-1543. [11] DI S, WANG C L. Decentralized proactive resource allocation for maximizing throughput of P2P grid [J]. Journal of Parallel and Distributed Computing, 2012, 72(2): 308-321. [12] GARG S K, VENUGOPAL S, BROBERG J, et al. Double auction-inspired meta-scheduling of parallel applications on global grids [J]. Journal of Parallel and Distributed Computing, 2013, 73(4): 450-464. [13] DUONG-BA T, NGUYEN T, BOSE B, et al. Distributed client-server assignment for online social network applications [J]. IEEE Transactions on Emerging Topics in Computing, 2014, 2(4): 422-435. [14] FARAGARDI H R, SHOJAEE R, KESHTKAR M A, et al. Optimal task allocation for maximizing reliability in distributed real-time systems [C]// ICIS 2013: Proceedings of the 2013 IEEE/ACIS 12th International Conference on Computer and Information Science. Piscataway, NJ: IEEE, 2013: 513-519. [15] DUSSO P M, SAUER C, HRDER T. Optimizing sort in Hadoop using replacement selection [C]// Proceedings of the 2015 East European Conference on Advances in Databases and Information Systems. Berlin: Springer, 2015: 365-379. [16] KOTA R, GIBBINS N, JENNINGS N R. Decentralized approaches for self-adaptation in Agent organizations [J]. ACM Transactions on Autonomous and Adaptive Systems, 2012, 7(1): 1-28. [17] AN B, LESSER V, SIM K M. Strategic Agents for multi-resource negotiation [J]. Autonomous Agents and Multi-Agent Systems, 2011, 23(1): 114-153. [18] CARPIO F, ENGELMANN A, JUKAN A. DiffFlow: differentiating short and long flows for load balancing in data center networks [C]// GLOBECOM 2016: Proceedings of the 2016 IEEE Global Communications Conference. Piscataway, NJ: IEEE, 2016: 1-6. [19] JIANG Y, HUANG Z. The rich get richer: Preferential attachment in the task allocation of cooperative networked multiagent systems with resource caching [J]. IEEE Transactions on Systems, Man, and Cybernetics—Part A: Systems and Humans, 2012, 42(5): 1040-1052. [20] EUGSTER P, KOGAN K, NIKOLENKO S I, et al. Heterogeneous packet processing in shared memory buffers [J]. Journal of Parallel & Distributed Computing, 2016, 99(8): 1-13. [21] WANG T, SU Z, XIA Y, et al. Rethinking the data center networking: architecture, network protocols, and resource sharing [J]. IEEE Access, 2014, 2(7): 1481-1496. This work is partially supported by the National Natural Science Foundation of China (60970012, 61572325), Shanghai Key Science and Technology Project (14511107902, 16DZ1203603), Shanghai Engineering Research Center Construction Project (GCZX14014), Shanghai Leading Academic Discipline Project (XTKX2012). ZHOUYue, born in 1991, M. S. candidate. His research interests include distributed computing, Internet of things. CHENQingkui, born in 1966, Ph. D., professor. His research interests include network computing, parallel computing, Internet of things.
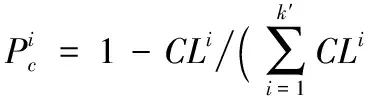
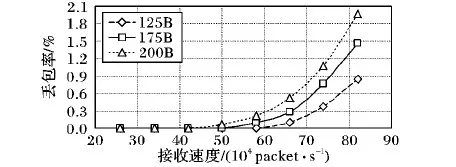
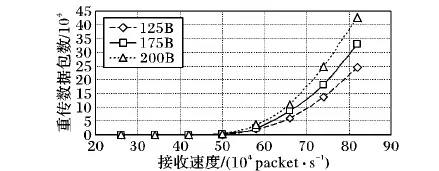
4 实验结果及分析




5 结语
