基于Apriori算法的时序关联关系数据挖掘装置的实现∗
2018-03-20国悦婷
国悦婷 刘 磊 张 星
(华中科技大学自动化学院 武汉 430074)
1 引言
随着互联网公司业务规模的快速增长,运维正面临着更为频繁的故障告警[1]。在大规模网络的运维工作中,每周海量的接警信息对运维工作人员而言工作量过大且难以及时查看,也会给短信网关带来较大压力,进一步影响故障的根因定位[2],致使核心告警延迟甚至遗漏,造成重大损失[3]。因此,需要对海量告警信息进行告警收敛,以获取真正有价值的告警信息[4]。
目前,国内工业界针对以上问题,多采用的是告警合并策略[5]。首先,对告警进行分类,通常分为对业务有直接影响的告警[6](如在线下降、服务器ping不通、业务进程崩溃、业务进程日志中出现致命字符串等)和预警(如在线波动、CPU和内存异常等)[7],其次,完成告警的去重、合并和聚合,最后,通过规则库过滤进行告警收敛[8],对于误报、连锁告警、大量告警等现象,会进行根因定位分析等,并做可视化数据呈现[9]。然而,采用简单的时间窗口合并、服务组织合并等方式的告警合并策略无法实现大量告警精准归类的目标,且合并效率较低[10]。
从历史告警数据中看,一个故障往往会引发很多相关策略的告警,这些告警在时序上存在一定的关联,所以我们可以从历史数据中挖掘不同策略间的时序关联关系,从而确定哪些规则是可以合并的,在告警的时候将关联策略合并展示,可以有效的减少告警条数、更清晰的接收故障信息[11]。本文从实际运维场景的需求出发,对Apriori算法作出相应改进,并在运维告警的时序信息场景中进行了实际应用,结果表明在告警合并的结果和效率上均获得了显著的改善效果。
2 问题定义
传统的关联关系挖掘方法使用支持度挖掘频繁项集,然后从频繁项集中产生规则,根据各规则置信度,给出关联规则。
定义1 告警序列
告警序列S是由告警类型集合E上的多个有序的告警组成,表示为S=(s,Ts,Te),s为序列,Ts为序列起始时间,Te为序列终止时间。例如在图1中,Ts=0,Te=600,告警序列s由多个有序的告警向量(A,t)组成(其中A为告警监控项,t为告警发生的时间,A∈E)。告警序列实例如图1所示。
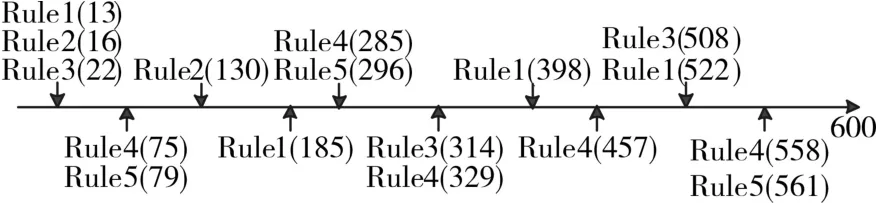
图1 告警序列实例
定义2 时间窗口
告警序列S=(s,Ts,Te)上的一个告警子项,可以表示成W=(w,ts,te),ts<t< te,其中 w=te-ts称为时间窗口。
定义3 告警串行关系
∀Ai(Ai∈E) ,∀Aj(Aj∈E) ,如 果 Ai≠Aj,f∶Ai→ Aj或者f∶Aj→ Ai,则 Ai,Aj之 间 是 串 行 关系。告警情景a由告警事件A和B组成,且告警A会导致告警B出现,则A与B为串行关系。
3 Apriori算法及改进
Apriori算法是最有影响的挖掘布尔关联规则频繁项集的经典算法。
Apriori算法中,使用的是一种称为逐层搜索的迭代方法,通过遍历数据库累计每个项的计数,并收集满足最小支持度的项,找出频繁项集的集合L1[12]。然后不断迭代直至不能找到频繁项集。其中,候选集产生的过程分为连接和剪枝两个部分。采用这种方式,使得所有的频繁项集既不会遗漏又不会重复。为提高频繁项集逐层产生的效率,Apriori算法利用了一种称为先验性质的重要性质用于压缩搜索空间[13]。Apriori算法流程如图2所示。
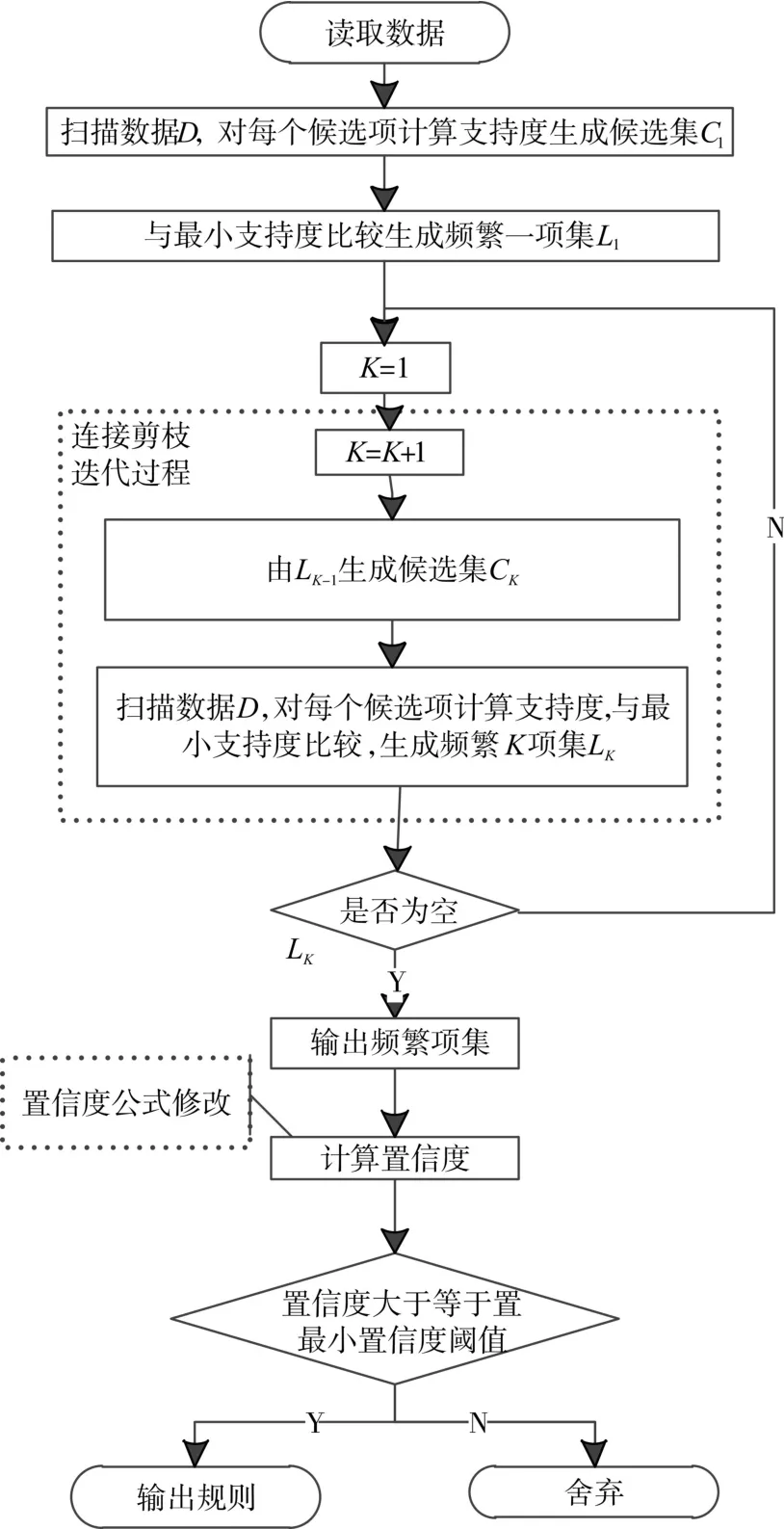
图2 Apriori算法流程图
先验性质 频繁项集的所有非空子集也一定是频繁的。

在运维场景中,告警在时序上存在一定的关联,如Rule1→Rule2,呈现一对一串行的特点。因此可对Apriori算法进行简化,去掉迭代过程以提升运行效率,其过程是先建立带时间窗口的支持度表,然后计算得出计数表,最后在得到置信度表的时候,对置信度的计算做调整,避免频繁报警项作为分母时引起置信度值失真。因此将置信度的公式调整为式(3)。
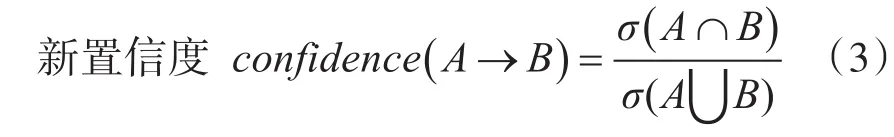
由 Card( A∪B )=Card(A)+Card(B)-Card(A∩B),置信度公式在矩阵计算中可记为式(4):
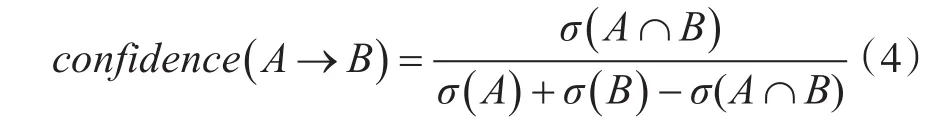
如果项集S的置信度满足预定义的最小置信度阈值min_conf,如满足式(5):
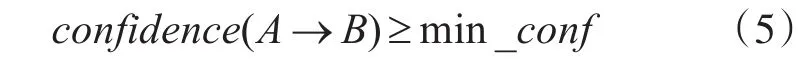
又因为规则由频繁项集产生,因此每个规则都自动地满足最小支持度。同时满足最小支持度阈值和最小置信度阈值的规则称为强规则,则S是频繁项集,规则A→B为强规则。
4 实验内容
为达到对告警信息合并收敛的效果,设计并实现了数据挖掘装置,其整体框架分为三部分:抓取模块、模型训练模块和测试评估模块。该框架支持历史数据的爬取存储、挖掘训练和测试,并将三个模块的代码解耦,并具有高内聚、低耦合的特点。
数据抓取部分从各个存储系统中抓取告警数据,经过数据清洗存入本地磁盘,模型训练部分使用相应的策略训练数据模型,得到挖掘规则,模型测试部分根据本地磁盘的数据和挖掘规则,得到测试结果。系统结构如图3所示。
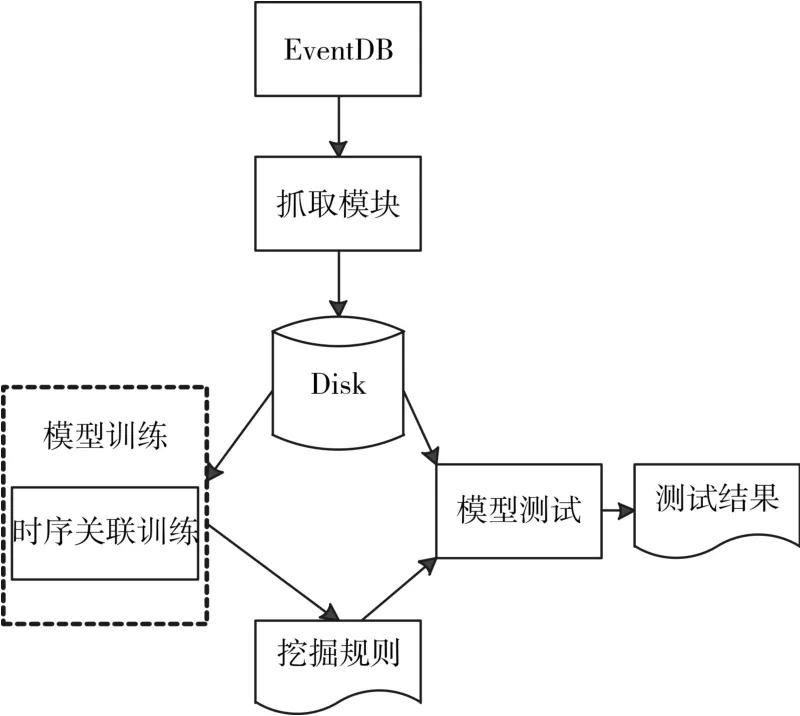
图3 数据挖掘装置框架图
实验过程共分为三个步骤:1)告警历史数据抓取;2)挖掘算法训练;3)测试评估结果。
第一步,需对历史数据进行抓取,该过程包括从各个存储系统中抓取离线数据和将清洗后的数据存入本地磁盘两个步骤。以图1的告警序列为例,采用60s的时间窗口,将抓取的告警数据整理为表1。
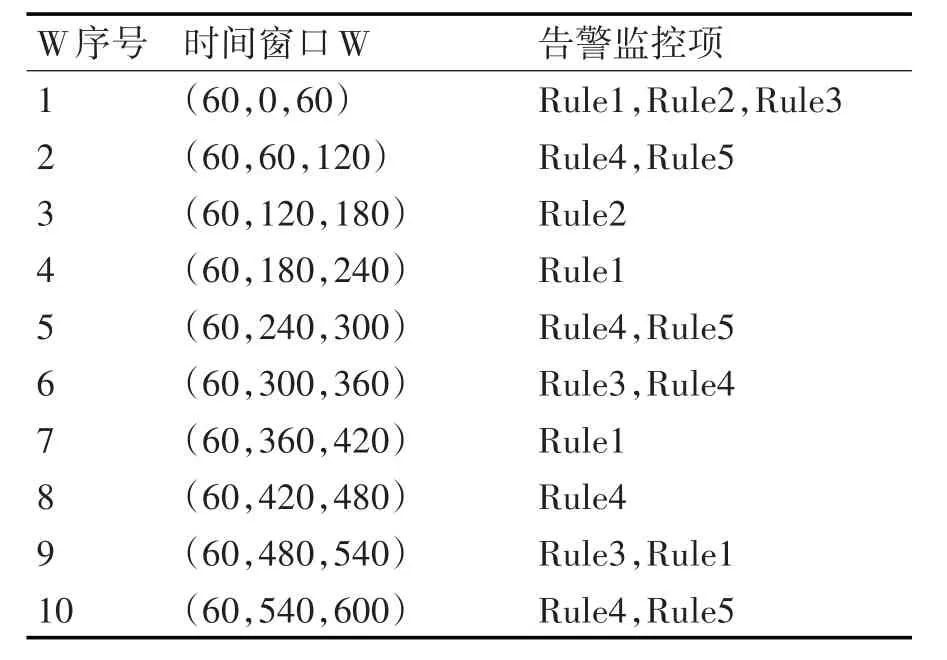
表1 带时间窗口的告警序列
对时序数据流的数据挖掘采用约定起始时间和固定时间间隔的滑动窗口,规定时间窗口为1个时间单位,以Rule1 → Rule4为例,W1⇒W2,W4⇒W5,W7⇒W8,W9⇒W10这四个相邻的时间窗口均支持Rule1→Rule4的关联关系,因此Rule1→Rule4的支持度计数为4。依此规则,计算所得如表2所示。
第二步,对时序关系进行模型训练。关联关系的挖掘包含两个过程:1)找出所有的频繁项集;2)由频繁项集产生强关联(强规则)。
根据步骤一,遍历表1统计每个规则出现的次数,得出所有规则的支持度计数,如表3所示。
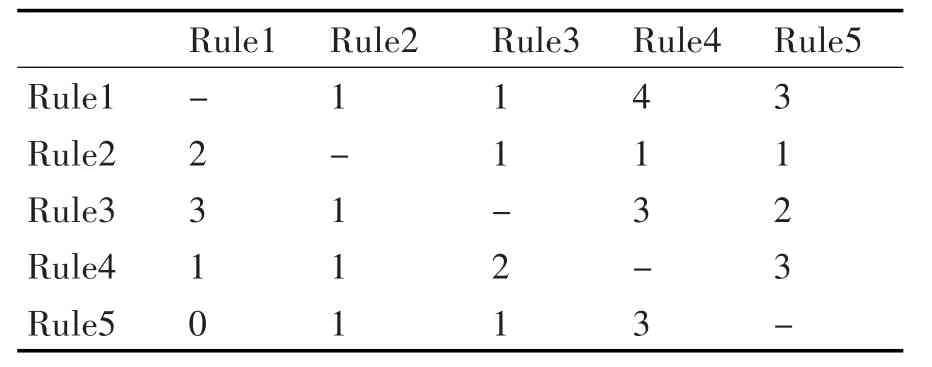
表2 带时间窗口的支持度计数表

表3 支持度计数
由式(4),得出置信度表如表4所示。

表4 置信度
对于S的每个非空子集s,如果
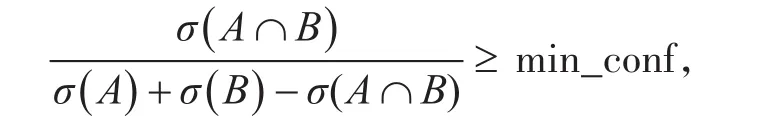
则输出规则A⇒B。
由经验min_conf设置为0.3,则强规则为Rule1→ Rule5,Rule2→ Rule1,Rule3→ Rule4,Rule3 →Rule5,Rule4→ Rule3,Rule4→ Rule5,Rule5→Rule4。
第三步,根据训练得到的关联关系进行数据测试。当遇到有关联关系的告警项时,将其收敛为同一条告警信息,并计算出收敛率。
5 结果及分析
本文采用python编程实现算法,操作系统为Linux,配置CPU频率为2400.084MHz。实验中采用某公司网管数据库连续一个月的原始告警数据做为测试数据,大约200万条告警记录。
将训练数据的时间设定为2016年9月1日到2016年10月1日,并将测试数据时间设定为2016年11月1日到2016年12月1日,输出如表5。

表5 告警收敛结果
结果显示,通过算法的合并使得原始告警数量有了较大程度的削减。功能上完成了对有关联关系的规则的合并,起到了告警收敛的作用,减少了冗余告警数量。对于最小自信度阈值的选取,既不能过小,不然会使数据关联度增大,本来没有关联的数据进行合并后,对告警信息报警的准确率有一定干扰,也不能选择太大,不然会削弱告警合并的效果,无法达到理想的合并效果。
6 结语
本文通过对Apriori算法的改进和置信度公式的优化,设计并实现了时序关联关系数据挖掘装置,并将其用于大规模网络告警合并场景,从而减少了冗余告警数量,减轻了短信网关的压力,为海量告警信息故障的根因定位起到了积极的作用,减少了核心告警延迟和遗漏的情况。根据告警场景的实际情况,改进后的Apriori算法能更好地挖掘出关联关系规则,进而提高了该算法的实用性。本文的方法对已发生的告警起到了有效的合并作用,下一步的工作是对告警数量进行预测,对未来预期时间的告警数量进行预测,当超过该预测值的时候,则认为疑似出现大规模告警,然后利用本文的方法对告警信息进行合并展示。
[1]Dattatraya V K,Shaila D A.A Universal Object Oriented Expert System Frame Work for Fault Diagnosis[J].Inter⁃national Journal of Intelligence Science,2012,2(3):63-70.
[2]李彤岩.基于数据挖掘的通信网告警相关性分析研究[D].成都:电子科技大学,2010.
LI Tongyan.Research on alarm correlation analysis of com⁃munication network based on Data Mining[D].Chengdu:University of Electronic Science and technology,2010.
[3]邓歆,孟洛明.基于贝叶斯学习的告警相关性分析[J].计算机工程,2007,33(12):40-42.
DENG Xin,MENG Luoming.Alarm correlation analysis based on Bayesian learning[J].Computer Engineering,2007,33(12):40-42.
[4]田志宏,张永铮,张伟哲,等.基于模式挖掘和聚类分析的自适应告警关联[J].计算机研究与发展,2009,46(8):1304-1315.
TIAN Zhihong,ZHANG Yongzheng,ZHANG Weizhe,et al.Adaptive alarm correlation based on pattern mining and clustering analysis[J].Journal of Computer research and development,2009,46(8):1304-1315.
[5]J.Han,M.Kamer.数据挖掘概念与技术[M].2版.北京:机械工业出版社,2007.
J.Han,M.Kamer.Data mining concepts and techniques[M].Second Edition,Beijing:China machine press,2007.
[6]Unil Y.Efficient Mining of Weighted Interesting Patterns with a Strong Weight and/or Support Affinity[J].Informa⁃tion Sciences,2007,177(17):3477-3499.
[7]蔡伟杰,张晓辉,朱建秋,等.关联规则挖掘综述[J].计算机工程,2001,(05):31-33,49.
CAI Weijie,ZHANG Xiaohui,ZHU Jianqiu,et al.Survey of Association Rule Generation[J].Computer Engineer⁃ing,2001,(05):31-33,49.
[8]吴扬扬,陈怀南.基于关联规则的通信网络告警相关性分析模型[J].通讯和计算机,2004,12(1):57-63.
WU Yangyang,CHEN Huainan.Alarm correlation analy⁃sis model of communication network based on association rules[J].Journal of Communication and Computer,2004,12(1):57-63.
[9]夏海涛,詹志强.新一代网络管理技术[J].北京邮电大学出版社,2003,05.
XIA Haitao,ZHAN Zhiqiang.New generation network management technology[J].Beijing University of Posts and Telecommunications Press,2003,05.
[10]杨芬.基于约束的关联规则挖掘[D].武汉:华中科技大学,2004.
YANG Fen.Association Rules Mining Based on Con⁃straints[D].Wuhan:Huazhong University of Science and Technology,2004.
[11]Pang-Ning Tan Michael Steinbach Vipin Kumar.Intro⁃duction to Data Mining[M].March 25,2006.
[12]Zhen Yun Liao,Xiu Fen Fu,Ya Guang Wang.The Re⁃search of Improved Apriori Algorithm[J].Applied Me⁃chanics and Materials,2013,2171(263).
[13]Gao H S,Li Y M.An Efficient Communication Network SDH Alarm Association Rule Mining Algorithm[J].Ad⁃vanced Materials Research,2014.
[14]N.Badal,Shruti Tripathi.Frequent Data Itemset Mining Using VS_Apriori Algorithms[J].International Journal on Computer Science and Engineering,2010,2(4).
[15]Li Rong Tong,Jun Zhang,Lei Ma,Li Xin,Shuang Hu,Ji⁃an Feng He.An Improved Apriori Algorithm Based on LinkedList for the Prevention of Clinic Pharmaceutical Conflict[J].Applied Mechanics and Materials,2014,2987(513).
