基于测度矩阵正则化的行人重识别算法
2018-03-19郑舟恒
郑舟恒,刘 凯
(四川大学 电气信息学院,四川 成都 610065)
0 引 言
行人重识别问题是在非重叠区域的摄像头中,对出现的目标进行判断是否为同一目标的过程[1]。由于在现实场景中,不同的摄像头之间存在着巨大光照变化、视角差异以及目标本身的姿态变化,该问题在实际解决的过程中存在着巨大的问题和挑战。目前,比较流行的方法大致可以分为两类:基于特征描述的方法和基于距离度量学习的方法。
首先基于特征描述的方法利用了两幅图片之间具有鲁棒性的特征来提高目标的识别率,一些特有的特征描述由于对视角和光照变化不敏感,所以具有一定的分辨效果。Bazzani等[2]提出一种结合人体全局和局部特征的行人重识别算法,利用连续多帧的图像积累得到全局特征,然后与人体分块得到特征互相融合得到最终的特征向量;Zhao等[3]将两幅图片进行划分,得到不同的小块,在一定约束条件下寻找到最为匹配的方块,然后提取出局部特征;Wang等[4]提出了在图像中寻找一种显著特征来对行人进行匹配的方法。然而,由于相同行人在不同的摄像头中存在光照和视角的差异较大,这些特征通常无法得到较为精确的结果。
基于度量学习的方法主要侧重于对现有的数据进行训练,训练出来投影矩阵进行解决同一行人的不匹配问题。该类方法能够利用较为简单的特征达到较好的分类效果。基于距离度量学习距离的方法的主要思想在于学习一个测度矩阵,将特征向量投影到一个更容易区分的空间下。BoostMetric[5]是一种基于三元组形式约束的度量学习模型,首先利用一个弱分类器得到半正定矩阵,再通过Boosting来学习矩阵的线性组合作为投影矩阵;Pedagadi等[6]将局部Fisher判定应用于行人重识别当中,利用对散列矩阵求解特征值的方法得到测度矩阵,由于通常求解矩阵的维数过大,会使用主成分分析的方法进行一个降维的过程;Kostinger等[7]利用马氏距离的思想,提出了简单有效原则下的度量学习方法,能够有效得降低训练复杂度,并且在实际中有不错的识别效果。
然而,在实际情况中存在遮挡、视角变化、样本不足等情况,存在过拟合现象。现有的各种算法为了解决这类问题,通常需要在测度矩阵学习的过程中加入各种约束,从而计算复杂度极大的增加。对此,本文提出了一种对测度矩阵正则化的算法。文献[7]提出了KISSME算法,计算过程简单且能够很好地应用于大量数据集的情况,但在训练样本过少、样本质量较差的情况下,过拟合现象比较严重。为了对文献[7]中训练得到的测度矩阵进行正则化,本文首先正则化生成测度矩阵的两个协方差矩阵,将两个协方差矩阵特征值分解后,对其特征值进行平滑和优化,然后可以得到正则化后的测度矩阵,算法在公共实验数据集上的实验效果显示改进算法可以有效地提高匹配率。
1 基本原理与方法
1.1 距离测度矩阵学习算法
文献[7]中提出了一种KISSME的算法,首先一对行人对(i,j)之间的相似关系可以表示为
(1)
其中,S为样本对(i,j)相关的集合,而D为样本对(i,j)不相关的集合,P0(i,j)为一行人对(i,j)属于相关行人对的概率,P1(i,j)表示行人对(i,j)不属于相关行人的概率。δ(i,j)越小则对应行人对属于相关行人对的概率越小。利用特定的特征提取方法,行人对(i,j)的图像特征可以用(xi,xj)表示,由式(1)可以得到
(2)
由于相关和不相关在行人对在特征差空间服从于均值0,协方差分别为ΣS和ΣD的多维正态分布,于是可以得到
(3)
和
(4)
其中
(5)
(6)
将式(3)和式(4)代入式(2)中可以得到
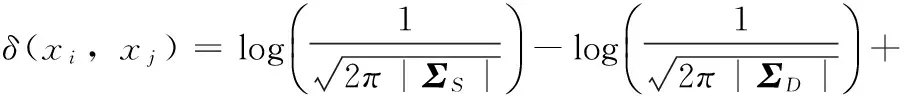
(7)
由于常数项对于最后的结果没有影响,式(7)可以化简为
(8)
式(8)可以看成是马氏距离的度量,由此可以得到测度矩阵M
(9)
可通过
dij=(xi-xj)TM(xi-xj)
(10)
来计算一组行人对之间的相似度。
1.2 正则化测度矩阵
由上一节可以看出,行人重识别的精度是由测度矩阵M的准确与否来决定的。但是在实际情况中,通常无法获得足够的训练样本,同时KISSME计算过程并没有加入过多的约束条件,容易产生过拟合现象。当训练样本过少时,有限的训练集无法很好地反映出真实模型,训练得到的测度矩阵在训练集匹配可以达到非常好的效果,但是在测试集中则无法达到预期的结果。而当训练集中出现了遮挡、姿态严重变化等质量较差的训练样本时,由于无法事先将这些质量较差的样本去除,同样产生提高在训练集合表现,在测试集上效果表现反而欠佳的情况。由于过拟合现象的存在,会对行人重识别的识别精度造成很大的影响,为了防止学习到的测度矩阵过于拟合训练集中的噪声和异常值,提高算法的泛化能力,本文对测度矩阵进行了正则化处理。
由式(9)可知,测度矩阵由两协方差矩阵的逆相减得到,所以分别对协方差矩阵进行正则化,首先对其进行特征值分解,由于对两个协方差矩阵进行同样的操作,所以只介绍针对ΣS的操作
Σs=ΨΛΨT
(11)
其中,Λ=diag(λ1,λ2,…,λd)为ΣS的特征值矩阵,特征值从大到小排列,而Ψ是对之对应的特征向量。这里将特征值分为3个子区间:P区间,L区间和N区间,如式(12)所示,其中P空间为特征值较大的区间,集中了特征值大部分的能量,L空间为特征值相对较小的区间,而N区间则认为是噪声区间,该区间的特征值过小而容易遭受到噪声的干扰
(12)
其中,p和q是预先确定的不同区间的分界点。分别计算为
(13)
和
q=max{q|λq<(λmed-(λp-λmed))}
(14)
其中,η为一能量比例参数,为P区间特征值和所占所有特征值和的比例。λmed为所有特征值的中位数。由于倒数函数能够较好拟合协方差特征值的分布曲线[8],本文提出利用3个参数的倒数函数模型来进行拟合
(15)
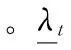
(16)
(17)
(18)
拟合之后的特征值分布曲线变得更加平滑,能够在一定程度上抑制噪声的影响,为了更好估计协方差矩阵的特征值,对拟合得到的特征值进行进一步的处理。当缺乏足够可靠的训练样本时,获得的协方差矩阵中的大特征值相对于真实特征值会偏大,而较小的特征值相对于真实特征值会偏小[9]。本文提出应当对于不同的子区间的特征值采用不同的方法进行正则化处理:适当抑制P区间中大特征值,同时提高L区间中较小特征值的影响,对于N区间,由于其对于噪声十分敏感,所以只进行了平滑处理
(19)
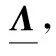
(20)
(21)
2 实验结果与分析
本文算法在不同实验测试集上与现有的算法比较所有实验均基于Matlab实现,实验平台为2GB内存,Intel(R) Core(TM) i3-2120 CPU 2.66 GHz的PC台式机。
2.1 实验设置与说明
在本文使用了广泛使用的公共测试数据集VIPeR,ETHZ,CUHK01,能够有效得对算法性能与其它算法进行比较。在实验过程中,随机选取p张行人图像对为测试集,将余下的行人图像对作为训练集。p值取值越大,则对应的训练样本越少,过拟合现象则更为严重。在测试集中,一对行人图像分为查询集合和行人图像库,给定一种算法后,其性能体现于在行人图像库中能否正确找到查询集合中对应的行人图像。
现有的评价指标为积累匹配特性CMC(cumulative match characteristic)。该评价指标是指在行人图像库中,相似度排名前r的结果中找到正确匹配的待查询人图像的比例。其中最重要的是第1匹配率(Rank1),当r较小时,其对应的匹配率在实际情况中也具有一定的意义,因为可以通过人工搜索的方式寻找到正确匹配的行人对。对于所有的实验,均重复10次后做平均作为最后的实验结果。
2.2 特征提取
为了将本文算法与其它算法进行比较,同文献[7]中相同,本文对行人图像只利用底层颜色特征和纹理特征进行描述。首先将图像分割成重叠的大小为8×16的图像块,步进为8×8,并在每一个图像块中提取特征。采用的颜色空间包括RGB和LAB两种颜色空间,每一个颜色通道都提取了24 bin直方图。纹理特征采用了LBP纹理特征。最后将得到的特征向量进行串联。由此一副图像能够用一个631维度的特征向量进行表示。为了减少冗余信息,利用PCA对特征向量进行降维,将特征维度降低至34维。
2.3 实验数据集结果与比较
2.3.1 VIPeR数据集实验结果
在VIPeR中有1264幅图像,总共632位行人。每一张图像都已经被人为剪裁为128×48像素大小的图片。该数据集即使对于相同的行人对之间也存在比较大的光照、姿态、背景等变化,十分具有挑战性。由于VIPeR是行人重识别问题最主要的数据集,大多数行人重识别算法都在该数据集下进行比较,所以在该数据集下进行了多种实验来验证算法的有效性和先进性。
首先该数据集下分析了参数a和b对于实验结果的影响。由于两个参数对于不同的特征值区域进行调整,两者相对独立,在进行参数分析时,将另一参数设置为0。同时为了观察参数对于过拟合的影响,选择了较少的训练样本,在这里p取值选取为532。图1显示了不同参数a对于算法性能影响比较。
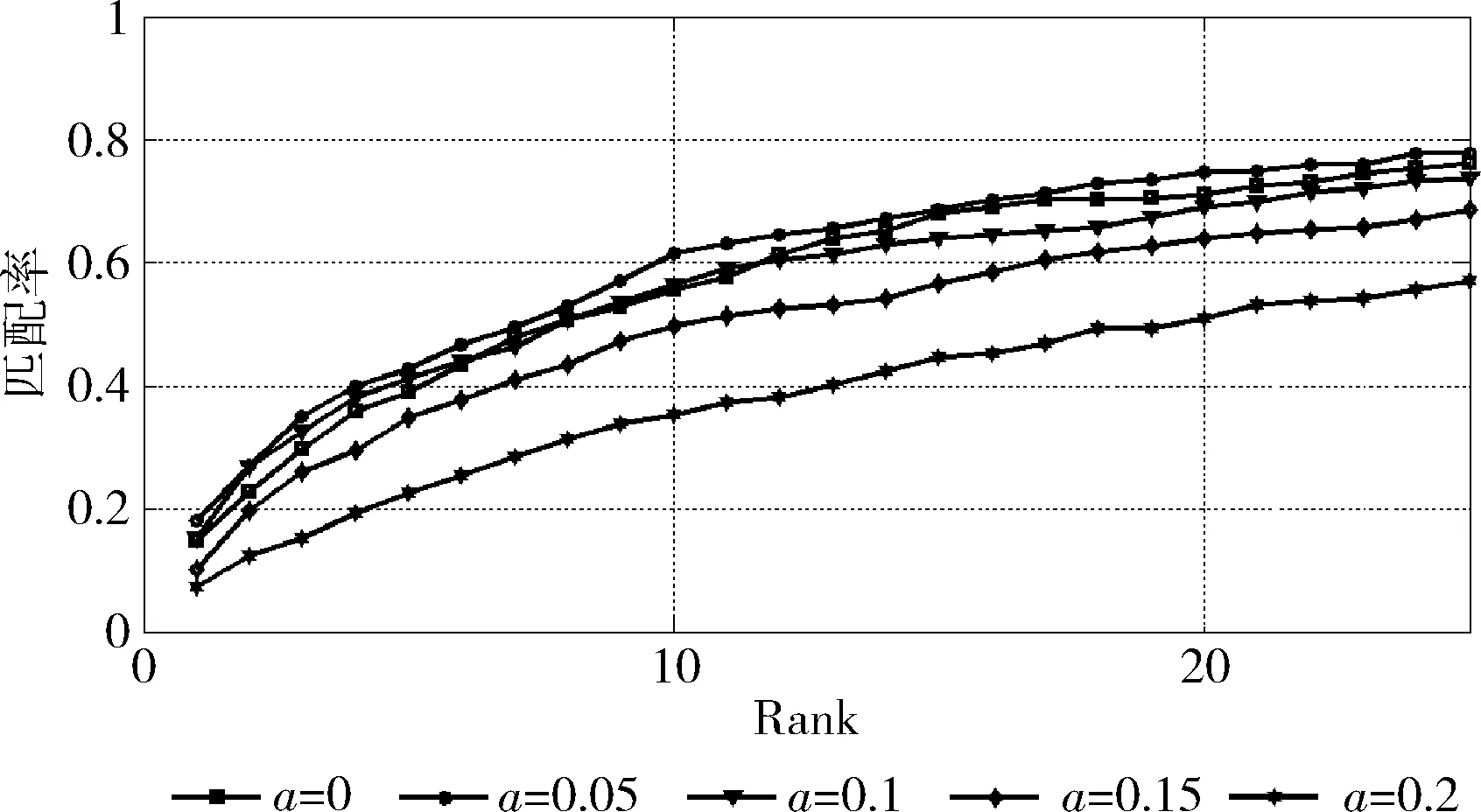
图1 不同a参数对识别结果的影响比较
图1可以看出,当a取值过大时,会导致最后得到的测度矩阵无法很好得适应训练样本,而当a过小,如当a=0时候,相当于只对协方差矩阵的特征值进行了平滑处理,并无法取得较好的实验效果。实验结果表明当a在0.05达到了最优值。所以在本文接下来的实验中,a的取值均采用0.05且保持不变。图2显示了不同参数b对算法性能的影响。
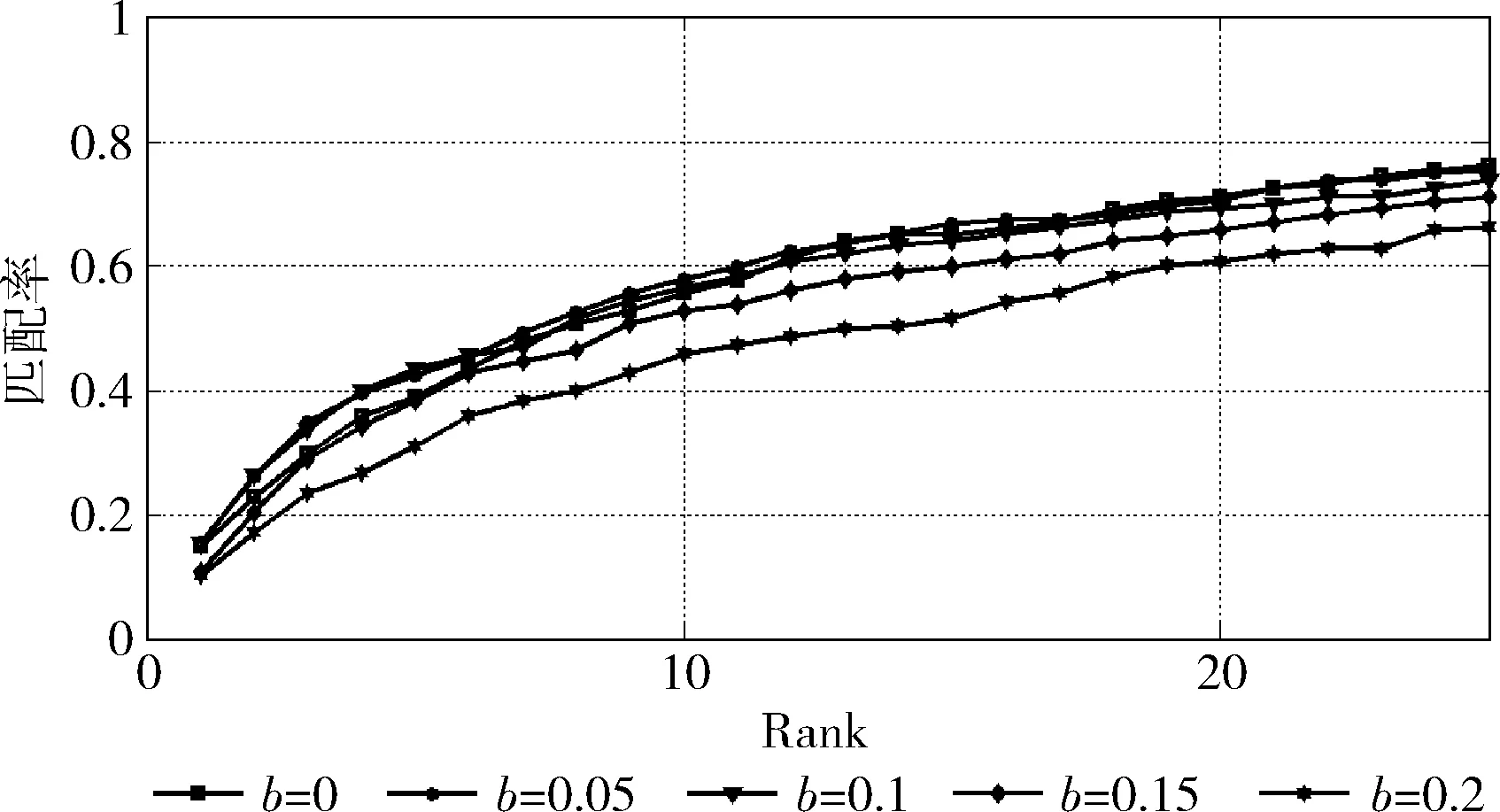
图2 不同b参数对算法性能的影响比较
由图2可以看出,b取值过大会造成测度矩阵过于偏离样本。b在区间(0,0.1)内对最后的识别精度效果较好,但是如果b取0,即没有该参数影响,在r较小的区域性能明显低于有参数进行正则化的情况。所以在本文中b同样选取0.05。由此通过两个较小的参数a和b,可以对测度矩阵进行一个调整,让其不过分适用于训练样本数据。η则根据经验值设定为0.8,由于在P区间附近的特征值均较大,所以η在一定范围内变化并不会对p,q的取值和最后的分区造成太大影响。
为了验证提出的算法优于原算法以及其它正则化方法,本文算法与KISSME、RE_KISS[9]和文献[10]进行了比较,后两种算法都是对KISSME算法进行正则化的算法。RE_KISS算法思想是对于协方差矩阵进行特征值分解,在特征值较小的区域取平均值代替其原有特征值,并将得到的特征值与单位阵做加权平均,文献[10]直接将测度矩阵与单位阵进行加权平均处理。由于不同数量的训练样本的会存在不同程度的过拟合现象,所以p值选取316和532来分别进行比较。4种算法在VIPeR的结果见表1。
从表1中可以看出,本文的提出算法可以有效得提高行人重识别的精度。在Rank1,提出的算法与原算法比较,不同数量训练样本p=316和p=532性能上分别提高了4%和11%,且在Rank10,Rank25和Rank50的匹配率中,均有明显的改善。当p=532时候,即只有少量的训练样本,过拟合现象十分严重,这就导致了其识别效果明显低于p=316时的情况,在实际情况中通过正则化方法提高识别精度就变得尤为重要。而在样本较少的情况下,本文提出的算法对于KISSME算法性能的提升效果更为明显。和RE_KISS算法、文献[10]提出的算法相比,仅仅在p=316,Rank1时,性能指标低于文献[10],其它指标均优于这两种算法。特别是p=532,对于过拟合的抑制效果显著优于另外两种正则化算法。说明了算法的有效性。
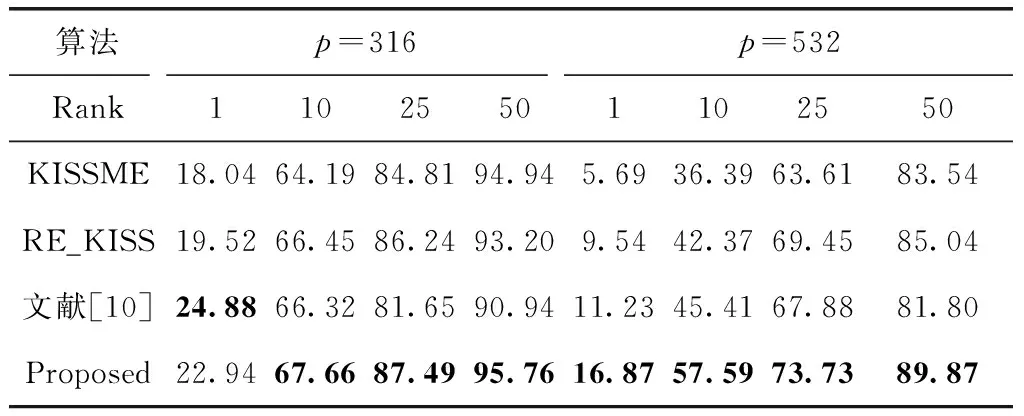
表1 4种算法在VIPeR中的比较
为了验证本文算法的优越性,将本文提出的算法与当前主流的行人重识别算法进行了比较,包括欧式距离,KISSME[7],LMNN,PRDC,ITML,CVDWA[11]和rPCCA[12]。同样对于p的取值为316和532。各个算法的结果见表2。

表2 多种算法在VIPeR中的比较
从表2中可以看出,在两个测试集规模下,每一个Rank等级的正确率均优于目前主流的算法,说明了算法在实际应用中具有良好的识别精度。注意到当p=532,即训练样本数量过少时,目前主流的算法识别精度都受了很大影响,而此时本文算法不同Rank等级的正确率优势体现的更为明显。充分说明了算法对于训练样本不足产生的过拟合起到了很好的效果。
2.3.2 ETHZ数据集实验结果
ETHZ中共计8555张图片由146位行人组成,图像由一个移动摄像机中3个视频序列中提取,同样将每张图像尺寸设置为128×48像素大小。在该数据集下,训练集为73对行人图像,表3分析了本文算法与KISSME算法的比较。

表3 两种算法在ETHZ中的比较
由于该数据集采集的图像由同一个摄像机拍摄,相对于其它数据集而言姿态、光照条件变化较小。从表3中可以看出,KISSME算法本身的精度较高,提出的算法在识别精度上提高效果不明显,在Rank1中仅仅提高了2%,在Rank10中甚至略微低于原算法性能。这也说明了算法的局限性,在样本条件较好的情况下,本文算法对于识别效果的改善空间有限。
2.3.3 CUHK01数据集实验结果
CUHK01中由3884幅图像共971个行人组成。每个行人包含了4幅图像,前两幅图像是摄像头A拍摄一行人前后的图像,后两幅图像是摄像头B拍摄同一行人侧面的图像,从前两幅中随机选取一张,同时从后两幅图像中选取一张,从而构成相关行人对。同时将图像的大小调整为128×48像素。在本文中测试集为485对行人图像,训练集为486对行人图像。从表4中可以看出,本文算法性能在CUHK01数据集上均优于KISSME算法,在Rank1中匹配率提高了5%。

表4 两种算法在CUHK01中的比较
3 结束语
在行人重识别问题中,实际情况训练样本不足、质量较差一直是重要而难以解决的问题。由此而带来的过拟合问题会对算法的准确性造成影响。为了解决这个问题,本文提出了一种基于测度矩阵正则化的方法,实验结果表明能够有效缓解过拟合问题对行人重识别精度带来的不利影响。但是在训练样本足够,样本质量较好时,对于算法性能的提升并不明显,在接下来的研究中,将进一步研究更有效的距离度量方法。
[1]Liu Z,Huang K,Tan T.Foreground object detection using top-down information based on EM framework[J].IEEE Transactions on Image Processing,2012,21(9):4204-4217.
[2]Bazzani L,Cristani M,Perina A,et al.Multiple-shot person re-identification by chromatic and epitomic analyses[J].Pattern Recognition Letters,2012,33(7):898-903.
[3]Zhao R,Ouyang W,Wang X.Unsupervised salience learning for person re-identification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Portland:IEEE,2013:3586-3593.
[4]WANG Cailing,ZHAN Song,JING Xiaoyuan.Pedestrian re-identification based on salient features in non-overlapping areas[J].Journal of Nanjing University of Posts and Telecommunications(Natural Science Edition),2016,36(1):106-111(in Chinese).[王彩玲,詹松,荆晓远.基于图像显著特征的非重叠视域行人再识别[J].南京邮电大学学报(自然科学版),2016,36(1):106-111.]
[5]Shen C,Kim J,Wang L,et al.Positive semi-definite metric learning using boosting-like algorithms[J].Journal of Machine Learning Research,2012,13(4):1007-1036.
[6]Pedagadi S,Orwell J,Velastin S,et al.Local fisher discriminant analysis for pedestrian re-identification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Portland:IEEE,2013:3318-3325.
[7]Köstinger M,Hirzer M,Wohlhart P,et al.Large scale metric learning from equivalence constraints[C]//Computer Vision and Pattern Recognition.Providence:IEEE,2012:2288-2295.
[8]Sharma A,Paliwal K K.A two-stage linear discriminant analysis for face-recognition[J].Pattern Recognition Letters,2012,33(9):1157-1162.
[9]Tao D,Jin L,Wang Y,et al.Person re-identification by re-gularized smoothing kiss metric learning[J].IEEE Transactions on Circuits and Systems for Video Technology,2013,23(10):1675-1685.
[10]QI Meibin,WANG Yunxia,TAN Shengshun,et al.Person re-identification based on regularization of independent measure matrix[J].Pattern Recognition and Artificial Intelligence,2016,29(6):511-518(in Chinese).[齐美彬,王运侠,檀胜顺,等.正则化独立测度矩阵的行人再识别[J].模式识别与人工智能,2016,29(6):511-518.]
[11]Chen Y C,Zheng W S,Lai J H,et al.An asymmetric distance model for cross-view feature mapping in person re-identification[J].IEEE Transactions on Circuits and Systems for Video Technology,2016,PP(99):1-1.
[12]Xiong F,Gou M,Camps O,et al.Person re-identification using kernel-based metric learning methods[C]//European Conference on Computer Vision.Zurich:Springer,2014:1-16.
