基于Fast RCNN模型的车辆阴影去除
2018-03-19潘广贞孙艳青
潘广贞,孙艳青,王 凤
(中北大学 软件学院,山西 太原 030051)
0 引 言
目前视频车辆检测中移动阴影[1]检测去除方法有两种:①基于模型的方法。采用先验知识、如场景、照明条件、三维几何计算阴影位置,建立阴影模型。代表性方法有Li J等提出基于统计模型的阴影检测去除方法,引入统计参数,建立阴影高斯模型,提高不同场景阴影检测去除准确率,然而对于有标记的视频图像检测过程存在缺陷[2]。②基于属性的方法。通过分析几何结构和颜色特征识别阴影,如颜色、纹理、亮度、梯度。代表性方法有Kar A等提出的结合阴影特征和HSV颜色空间的阴影去除算法,利用投影机特征梯度投影分离阴影和车辆特征,提高阴影消除效率,但无法快速检测海量视频图像目标[3]。
针对大量视频车辆检测中需快速检测并去除阴影问题,本文提出基于Fast RCNN目标检测模型,采用Hessenberg分解法和PCA分析法实时快速检测运动车辆并去除阴影,采用深度学习思想自主学习运动车辆特征和阴影区域特征。
1 理论思想介绍
1.1 Fast RCNN目标检测模型
基于RCNN和SPP Net思想,Girshick提出Fast RCNN算法。Fast RCNN模型亮点在于[4]:①训练过程运用多任务损失,实现单步骤完成;②训练过程中所有层都可以得到更新;③不再需要磁盘存储器作为特征缓存;④比RCNN的训练、测试时间快。对比VOC 2007数据可知在PASCAL VOC 2012上获得mAP也更高,见表1。
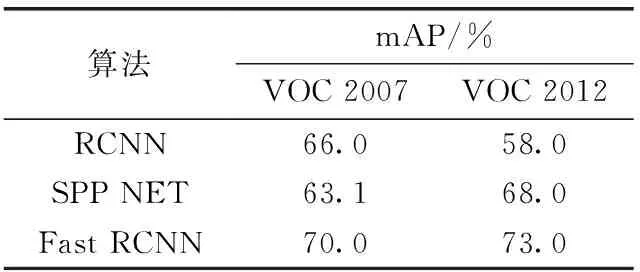
表1 Fast RCNN等算法mAP效率比较
Fast RCNN模型原理[5]如图1所示:通过深度卷积网络(deep ConvNet)得到特征图(feature map),在特征图上以感兴趣区域ROI(region of interesting)投影方式找出原图候选目标区域的对应区域,用ROI池化方式获得统一尺寸的候选目标区域特征图(ROI feature vector),经过全连接层(FC)得到特征向量后,分别得到一个分类器(softmax)和一个回归器(bbox)两个输出向量。
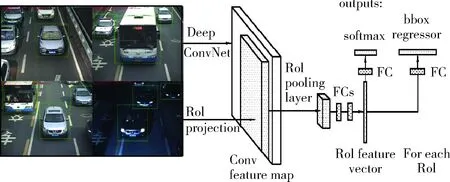
图1 Fast RCNN目标检测模型
1.2 阴影产生原理
阴影由两部分组成:自身和投射阴影。投影是由对象投影在场景上的区域,并且可进一步分类为umbra(本影)和penumbra(半影)[6]。umbra对应于直接光被对象完全阻挡的区域,而penumbra带被部分阻挡,如图2所示。
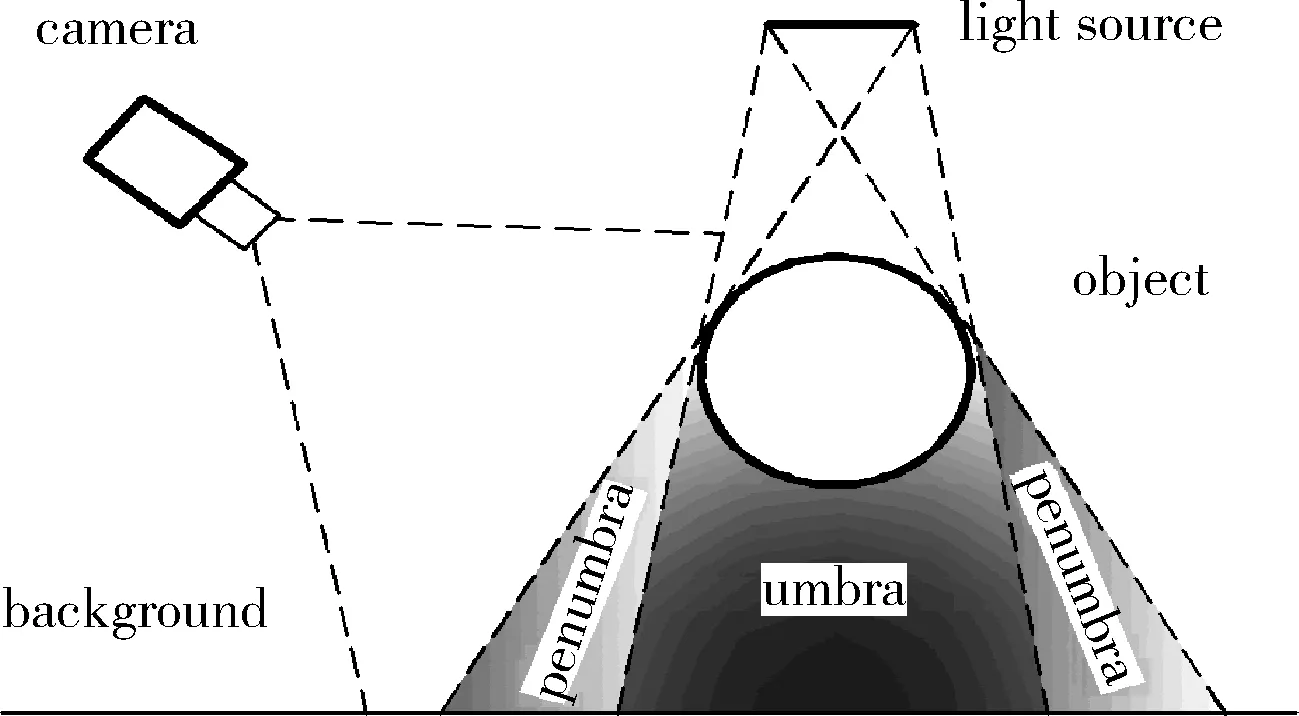
图2 本影,半影的几何关系
1.3 Hessenberg分解法(Hessenberg Decomposition)
Hessenberg分解(HD)是一种特殊的方形矩阵,即上部Hessenberg分解在第一子对角线下方具有零条目,并且较低的Hessenberg分解在第一超对角线上方具有零条目。该矩阵具有与原始矩阵相同特征值。在特征值算法中,Hessenberg分解可通过与缩减步骤结合Shifted QR因式分解进一步简化为三角矩阵[7]。Hessenberg矩阵的形式可通过计算QTAQ获得。
2 原有算法
在监控视频中提取的前景分量包括车辆及其阴影(检测到的阴影作为移动物体),这种现象可能导致对象合并,对象形状畸变,甚至对象损失这些问题。因而基于移动阴影的检测去除问题Moghimi M K等提出一种解决运动阴影存在的算法,首先,检测通过背景减除方法的运动像素,这些移动像素包括车辆及其阴影[8]。然后,识别由Hessenberg分解的可能的阴影区域。关于检测车辆的一些部分作为阴影,需要通过另一种方法检测车辆区域,可使用PCA主成分分析法。因此,在通过PCA分析法进行阴影细化之后,阴影将被正确检测[9]。流程如图3所示。

图3 原有算法框架
3 改进算法
3.1 算法流程
移动阴影会导致运动对象检测中的混乱和错误,前文提出的阴影检测去除方法解决在前景提取中移动阴影被误认为移动车辆的一部分问题,但不能快速有效的检测并去除,当车辆较多,环境比较复杂的情况下(照明情况不同),上述人工特征提取算法已经不能很好地检测并去除阴影,因此本文提出基于Fast RCNN目标检测模型下的运动车辆阴影检测去除的方法[10],算法实现过程如图4所示。
3.2 改进的算法步骤
(1)候选区域生成:一张图像生成1 K~2 K个候选区域(采用Selective Search法)。可采用Hessenberg分解估计候选阴影区域,通过计算前景图像的HD并确定阴影和对象区域,将前景图像分解为阴影和对象两个部分。
Hessenberg特征用于从物体分离阴影区域,必须计算前景区域并且决定前景部分中的哪一个是阴影。因此,可在图像的第一点提供m×m块,向下滚动该块大约1个像素的整个图像,以保留任何区域,然后计算其中心像素在前景中的整个块的Hessenberg分解
HESSENBERG=Hessenberg(blocks)
(1)
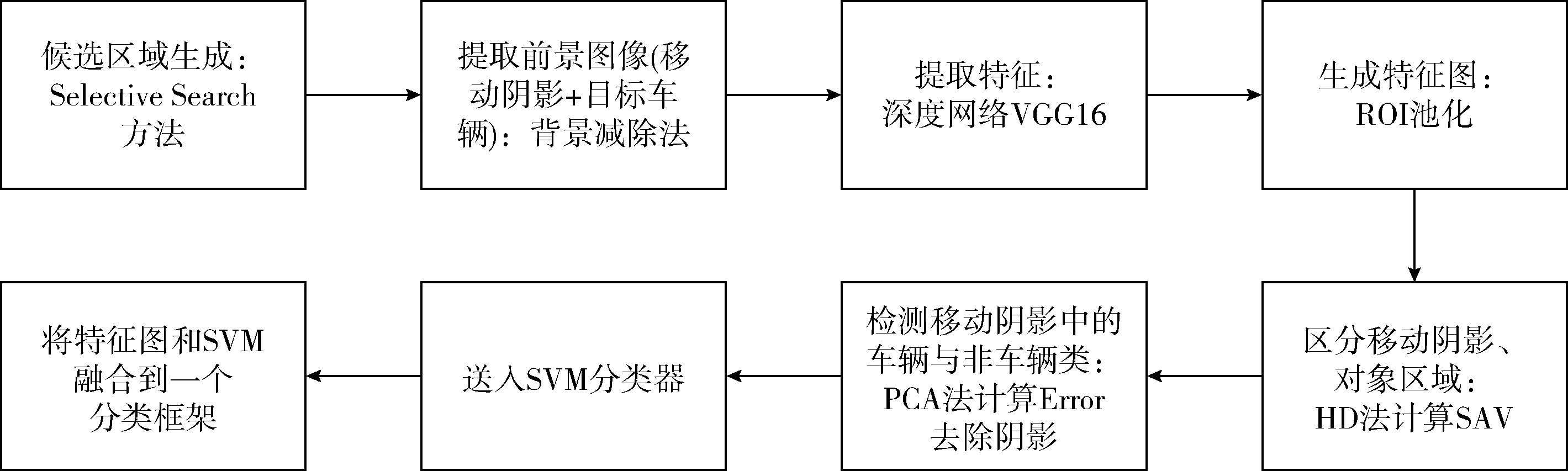
图4 Fast RCNN+HD+PCA算法阴影检测过程
其中,块指示在前景中的可用块,并且HESSENBERG是对这些块计算Hessenberg分解的结果。在下一级中,整个Hessenberg分解元素的绝对值之和被计算为
(2)
其中,SAV是Hessenberg矩阵的绝对值之和,用于将运动像素分类为运动阴影和运动对象。经验证,移动阴影的SAV具有不同分布特征,可以通过对SAV设置合适阈值来检测可能的阴影区域,如图5所示。

图5 HD法得到可能的阴影区域
(2)特征提取:对每个候选区域,使用深度网络(VGG16)进行特征提取。
在(1)过程中,类似于阴影的暗区和挡风的车辆的一些部分被检测为运动阴影。因此,可采用PCA技术降维提取部分特征识别运动阴影和车辆区域,采用深度网络计算特征图。对于通过PCA的车辆检测,需要各种种类车辆的数据库,然后,计算数据库中所有图像的以下平均值,用于删除不当的照明效果
(3)
其中,si是每个数据库图像的列矩阵,其大小为:η是数据库中所有可用图像的平均值,n是数据库中等于576的可用图像的数量。计算的η从所有数据库图像中减去
(4)
其中,M是尺寸矩阵。该矩阵包括所有数据库图像减去方程式中计算的η。然后,计算数据库的协方差矩阵
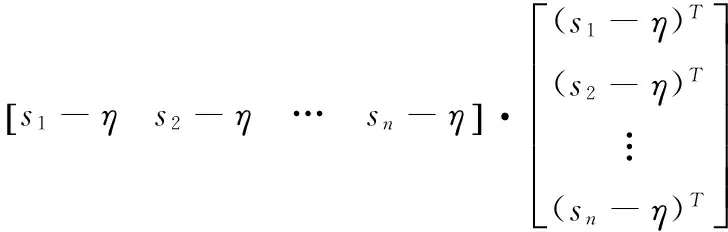
(5)
I是在用于检测形状像列矩阵的车辆的前景图像中应用的窗口,为了归一化输入图像,前景中的窗口I减去等式(3)中获得的η所得到的(具有与剩余数据库相同的照明条件)图像到PC中的投影由下式给出
P=PCT·(I-η)
(6)
其中,PC是主成分矩阵,其总能量是计算方差协方差矩阵(式(5))特征值的总能量的99%,并且P是应用窗口在PC矩阵上的前景图像中的投影。重建图像I′由下式给出
I′=PC·P+η
(7)
其中,I′是数据库的PC的新窗口的重建图像。可以通过比较重建图像和主图像来分类这个新窗口。重建误差由下式给出

(8)
其中,重建误差是重建图像和主图像之间的误差率。然后,可以将此窗口视为车辆类,否则应将其视为非车辆类

(9)
可以通过确定合适的值Th,将前景图像中的应用窗口的可用图像分为两类作为车辆和非车辆。为了合并一个车辆周围所有窗口,需要计算点(x,y)的平均值;指出它们之间的距离应小于两辆车之间的距离。最后,获得的坐标被认为是候选车窗(依次为轿车、卡车、巴士、皮卡)如图6所示。

图6 PCA检测结果
(3)类别判断:将误差率Error作为区分移动阴影与车辆特征送入具体的SVM分类器,判别是否属于该类,也即将特征提取和分类融合到一个分类框架[11]。
(4)最后把得到的特征图作为训练样本进行训练,测试。
4 实验分析及结果
4.1 实验条件
本实验采用的视频数据来源于Pascal VOC2012数据集,采用不同环境、不同车型如轿车、卡车、巴士等大量视频图像,实验环境如下:Intel(R)Pentium(R)CPU G645 @2.90GHz,4.00GB内存Windows7 64位操作系统。开发平台CNTK,可从git-hub中获取基于CNTK深度学习框架的实验代码和训练参数[12]。
4.2 评价指标[13]
为了检验评价阴影消除的结果,需使用多目标检测准确度MODA(multiple object detection accuracy)、多目标检测精度参数MODP(multiple object detection precision),综合指数F。精度参数意味着多少可用的移动阴影检测和分辨率意味着移动物体,像影子不确定阴影。在本文中可以通过使用HD特征影响准确度参数,并利用PCA提高精确度。准确度、精度参数定义如下
(10)
(11)
(12)

4.3 实验结果分析
该实验是在训练样本和测试样本同等光照条件下进行的,HD参数SAV一定,PCA参数Threshold为0~4,将传统HSV颜色空间、统计参数SNP方法、原有算法及本文算法运用到视频车辆图像上,得到算法的阴影检测准确度MODA,检测精度MODP,综合指数F见表2。

表2 各种方法评价指标分析
实验采用由低到高三阶段的光照强度,通过对不同运动车辆阴影检测去除方法的应用,对比MODA的结果,得出如图7所示(图中的白色区域表示检测到的阴影)。

图7 不同光照条件下的MODA比较
不同光照条件下传统算法和改进算法在MODA的结果比较见表3。

表3 不同光照条件下的MODA比较
本实验在不同阈值Threshold基础上将原有算法和改进后加入的深度学习算法运用到视频图像数据库中,运用CNTK工具对数据进行训练以及测试得到如下结果[14],如图8所示。
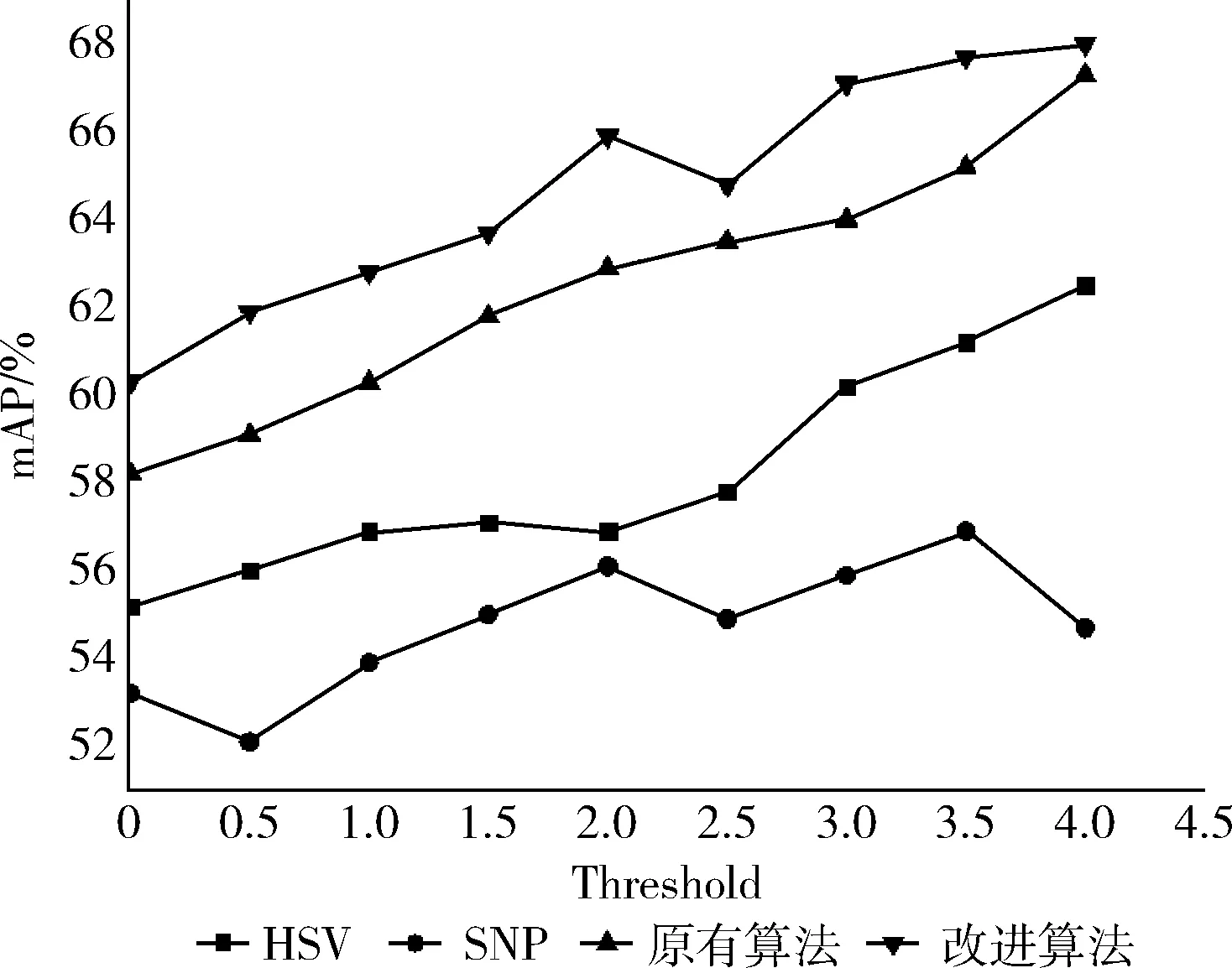
图8 不同阈值Threshold下mAP比较
实验结果表明:由表2知在加入深度学习思想基础上,改进后的算法在准确度MODA、精度MODP方面都有所提升,由表3知在不同光照强度下改进后的算法在MODA、mAP指标方面也优于原先算法。
5 结束语
移动对象的阴影通常会导致图像分析中的严重错误,正确检测目标阴影并去除在智能交通系统应用中至关重要。因此本文通过分析基于改进的HD在监控视频中的车辆模型,引入一种移动阴影检测算法。实验过程引入深度学习思想,采用Fast RCNN模型对大量视频车辆图像进行阴影检测去除处理,将特征提取和分类结合,实现端到端的训练、测试。实验结果表明,该方法在不同光照条件下可有效检测运动阴影,比以往检测算法MODA提高3.16%,mAP提高2.78%。
[1]Movia A,Beinat A,Crosilla F.Shadow detection and removal in RGB VHR images for land use unsupervised classification[J].ISPRS Journal of Photogrammetry & Remote Sensing,2016,119:485-495.
[2]Li J,Wang G.A shadow detection method based on improved Gaussian mixture model[C]//International Conference on Electronics Information and Emergency Communication.IEEE,2014:62-65.
[3]Kar A,Deb K.Moving cast shadow detection and removal from video based on HSV color space[C]//International Conference on Electrical Engineering and Information Communication Technology.IEEE,2015:1-6.
[4]Mao H,Yao S,Tang T.Towards real-time object detection on embedded systems[J].IEEE Transactions on Emerging Topics in Computing,2016,PP(99):1-1.
[5]LU Hongtao,ZHANG Qinchuan.Application of deep convolutional neural network in computer vision[J].Journal of Data Acquisition and Processing,2016,31(1):1-17(in Chinese).[卢宏涛,张秦川.深度卷积神经网络在计算机视觉中的应用研究综述[J].数据采集与处理,2016,31(1):1-17.]
[6]LI Haoliang,SHUI Qinghe,FAN Wenbing,et al.A new method of vehicle shadow removal based on edge detection[J].Journal of Zhengzhou University (Engineering Science),2014,35(5):11-14(in Chinese).[李浩亮,水清河,范文兵,等.一种新颖的基于边缘检测的车辆阴影去除方法[J].郑州大学学报(工学版),2014,35(5):11-14.]
[7]Moghimi M K,Pourghassem H.Shadow detection based on combinations of hessenberg decomposition and principal component analysis in surveillance applications[J].IETE Journal of Research,2015,61(3):269-284.
[8]WANG Yang,YAN Yunyang,WANG Hongyuan.Bidirectional 2DPCA and SVM face recognition algorithms based on difference space[J].Computer Science,2012,39(12):268-271(in Chinese).[汪洋,严云洋,王洪元.基于差空间的双向2DPCA和SVM人脸识别算法[J].计算机科学,2012,39(12):268-271.]
[9]TU Zhengzheng.Research on video target detection and segmentation based on visual cognition theory[D].Hefei:Anhui University,2015(in Chinese).[涂铮铮.基于视觉认知理论的视频目标检测及分割研究[D].合肥:安徽大学,2015.]
[10]Ren S,He K,Girshick R,et al.Faster R-CNN:Towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2016,39(6):1137.
[11]Gao C,Li P,Zhang Y,et al.People counting based on head detection combining Adaboost and CNN in crowded surveillance environment[J].Neurocomputing,2016,208(C):108-116.
[12]SUN Xiao,PAN Ting,REN Fuji,et al.Facial expression recognition based on ROI-KNN convolutional neural network[J].Journal of Automation,2016,42(6):883-891(in Chinese).[孙晓,潘汀,任福继,等.基于ROI-KNN卷积神经网络的面部表情识别[J].自动化学报,2016,42(6):883-891.]
[13]Oron S,Bar-Hillel A,Avidan S.Real-time tracking-with-detection for coping with viewpoint change[J].Machine Vision and Applications,2015,26(4):507-518.
[14]HUANG Jianqiang,CAO Tengfei,GUO Wenjing,et al.Joint shadow detection algorithm for two color spaces[J].Computer Technology and Development,2014(7):95-98(in Chinese).[黄建强,曹腾飞,郭文静,等.联合两种颜色空间的阴影检测算法[J].计算机技术与发展,2014(7):95-98.]
