基于正强化学习和正交分解的干扰策略选择算法
2018-03-14颛孙少帅杨俊安黄科举
颛孙少帅, 杨俊安, 刘 辉, 黄科举
(1. 国防科技大学电子对抗学院, 安徽 合肥 230037; 2. 安徽省电子制约技术重点实验室, 安徽 合肥 230037)
0 引 言
近年来,随着各种信息技术在军事领域的应用,信息战的地位愈加重要,夺取战场制信息权对战场胜负的影响举足轻重。对于干扰敌方信息传递通道以实现通信拒止而言,其难度随着敌方在通信过程中使用认知无线电、加密、鉴权、新的信号调制样式等技术而变得愈加困难,但是值得注意的是,无线通信的开放性使得对其干扰仍存在较大的可行性,而选择合适的干扰策略对实现成功干扰至关重要[1-3]。当前许多参数优化理论如:博弈论、粒子群算法、遗传算法等相继被用于搜索最佳干扰策略[4-6],然而上述理论成功实施的前提条件是需要有关通信方、环境的部分先验信息,鉴于部分先验信息对干扰方而言是无法获得的,即便获得也与真实信息之间存在偏差,使得此类理论无法适用于缺乏先验信息的场景。强化学习[7-8]作为在线的、与外界环境实时交互的机器学习理论,具有鲁棒性强、实时交互、无需先验信息的特点。文献[8]提出了针对网络优化问题的解决方法,所提方法对模型中的各种可行动作联合操作,但要求明确知道每个动作对应的奖赏信息。文献[9]提出了多臂老虎机算法,并就该算法在有限时间内的收敛性能和学习能力进行了理论论证。文献[11]提出了利用强化学习的Q方法求取最优信道接入策略。文献[12-13]深入研究了利用强化学习算法从物理层、MAC层搜索最佳干扰策略,得出在某些情况下最优干扰信号与被干扰信号具有不相同调制样式,以及干扰MAC层某些帧具有更优干扰性能的结论。
强化学习理论在解决未知、复杂环境问题时具有优异的性能,然而当前强化学习算法却面临着收敛速度慢的困境,需要干扰机同环境进行长时间的交互,特别是当待求解的干扰参数数目较多时,往往会带来“维数灾难”难题。因此,从实用角度出发,如何加快算法收敛速度是亟需解决的问题。本文在对干扰问题建模后,将正强化学习的思想用于干扰动作选择,以有目的性选择动作取代贪婪算法中随机选择动作的做法,通过合理的设置正强化算法相关参数,使得该算法具有快速的收敛速度。此外,在选择需要学习的干扰参数时,提出利用同相分量、正交分量构造不同类型的干扰样式,取代当前利用BPSK、QPSK等干扰样式直接进行干扰的方法,该方法丰富了干扰样式的种类,便于干扰方学习到最佳干扰样式。仿真结果表明,正强化算法能够降低寻优过程中的交互次数,而正交分解算法能够取得更优的干扰效果。
1 系统模型
以通信双方采用MQAM调制(M=4,8,16,…)为例,根据通信协议,接收方对接收信号进行滤波、解调、抽样判决、译码等相关处理后获得信息。对于意图实现通信拒止的干扰方而言,其可通过在特定频率上发送干扰信号的方式扰乱通信信号波形,阻止接收方解调出正确信息。文献[12]指出,干扰方在构造干扰信号时不仅需要准确选择干扰样式,还需要确定干扰信号的功率、脉冲率等干扰参数以实现最佳干扰,其中脉冲率定义为干扰时间与通信信号持续时间的比值。在无先验信息的前提下,Amuru提出了基于强化学习理论的干扰老虎机(jamming bandit, JB)算法,在对功率、脉冲率等连续参数进行离散化处理后,建立了与干扰参数对应的多臂老虎机模型,并根据算法动态从干扰参数集{功率、干扰样式、脉冲率}中选择参数组对通信信号施加干扰,将接收方发射的ACK/NACK帧信息作为对选择参数组的奖赏,经过长时间交互后确定最佳干扰参数组,即最佳干扰策略。当通信信号调制样式为矩形QPSK时,Amuru给出3种干扰样式即,AWGN、BPSK和QPSK。这样设定的明显缺点是:干扰信号的调制样式只能选择上述3种干扰样式中的一种,除非最佳干扰样式确定是三者中的一种,否则最终通过学习获得的干扰样式非最佳干扰样式,进而学习到的功率、脉冲率也并非最优的。在JB算法中,为了能够学习到最优干扰样式,需要干扰方事先准备尽可能多的干扰样式,但直接导致参数空间的维度成倍增加,更大的参数空间意味着需要更多次数的交互来寻找最优参数,进而极大地延长了学习到最佳干扰策略的时间。本文提出了基于正强化学习和正交分解的干扰策略选择算法,该算法利用正交分解实现不同干扰样式的选择,同时利用正强化的思想建立起干扰参数组之间的联系,在选择参数组时更具目的性。
1.1 干扰样式正交分解
文献[12]中构造的多臂老虎机模型,干扰样式、脉冲率以及信号功率的各种可能组合构成了不同的干扰参数组为{AWGN,BPSK,QPSK}×{1/M,2/M,…,1}×JNRmin+(JNRmax-JNRmin)*{1/M,2/M,…,1},该式中{AWGN, BPSK,QPSK}为备选干扰样式集;{1/M,2/M,…,1}为离散后的脉冲率集;JNRmin+(JNRmax-JNRmin)*{1/M,2/M,…,1}为离散后的功率集;符号“*”表示乘积;“×”为笛卡尔积;JNR为通信方接收到的干扰信号平均功率与噪声功率的比值,即平均干噪比,接收到的通信信号的平均功率与噪声功率的比值,即平均信噪比用SNR表示;策略{BPSK,ρ,JNRt}表示干扰方应构造功率PJ=JNRt/ρ的BPSK信号,以概率ρ对通信信号施加干扰,该策略亦可理解为多臂老虎机的一个“臂”。在上述案例中,由于干扰样式集内元素个数过少,致使干扰样式的学习空间具有局限性,为此需要丰富干扰样式的种类以便于学习到最优干扰样式。通过对干扰信号进行正交分解(orthogonal decomposition, OD),可知信号由功率Pj、正余弦波形、调制信息jm及载波频率fc组成,其表达式为
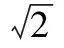
(1)
式中,Ac、As分别作为同相维和正交维的幅值,最优值为0或某一特定值[12]。
通过比较同相分量Ac和正交分量As之间的关系,得出以下结论:
(1) 当Ac=0(或As=0)时,构造BPSK干扰样式,相位信息θ∈(0,2π)取值{0,π}。
(2) 当Ac=As时,构造QPSK干扰样式,在该干扰样式中相位信息θ∈(0,2π)分别为{π/4,3π/4,5π/4,7π/4}。
(3) 当Ac≠As≠0时,构造出另类的矩形4- QAM,相位信息θ∈(0,2π)取决于Ac和As的取值。
星座图畸变通信信号对应的最佳干扰样式如图1所示。
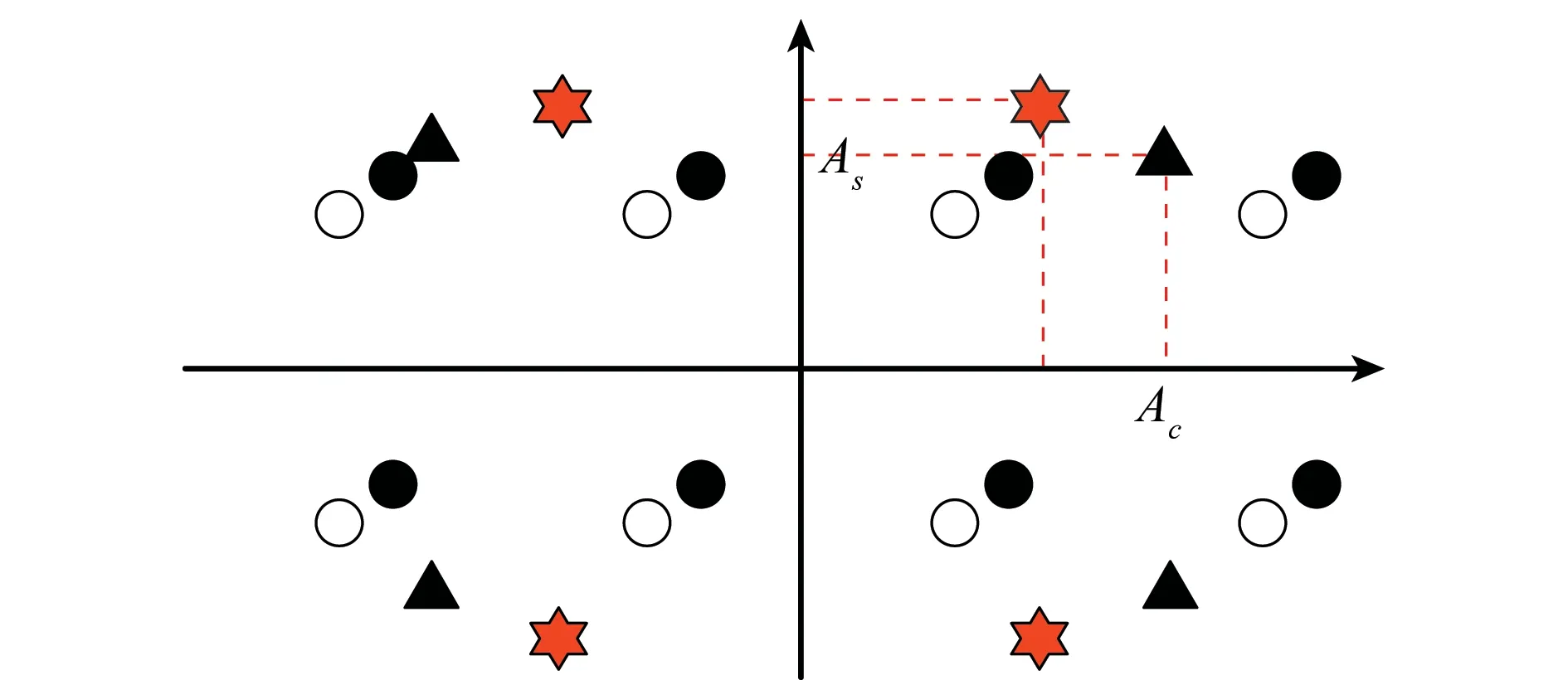
图1 星座图畸变通信信号对应的最佳干扰样式Fig.1 Distorted signal constellation and corresponding optimal jamming scheme
由图1可知,采用矩形8-PSK调制样式的通信信号由于噪声、连续波干扰、载波抑制、压缩增益等因素导致其理想星座图(白色圆圈所示)出现畸变(黑色圆圈所示)。鉴于此,无噪声时最佳干扰信号星座图(六角星所示)也需要相应的改变(三角形所示)以实现最佳干扰,可以看出新干扰信号星座图同相分量与正交分量的幅值已不再相等或成整数倍关系,而是与畸变后的星座图息息相关,存在各种可能的关系。在构造具有此类特殊星座图的干扰样式时,只有利用正交分解方法才能学习最佳同相分量和正交分量值。
正交分解算法不再拘泥于选择某种已知干扰样式,而是从最根本的因素同相分量和正交分量的角度出发,将寻找最优干扰样式问题转化为搜索最优同相分量和正交分量问题。因此,在构造干扰参数组时以变化的同相、正交分量作为干扰样式集的构造依据,可实现干扰样式种类的增多,便于寻找到最优干扰样式。
1.2 正强化学习
强化学习有4种方式,包括正强化、负强化、正惩罚及负惩罚。正强化是给予行为好的刺激,增加该行为出现的概率;负强化是指去掉坏的刺激,该刺激旨在为引发所希望行为的出现而设立;正惩罚是针对行为施加坏的刺激,即不当的行为出现时给予处罚的方法;负惩罚是指去掉好的刺激,指当不好的行为出现时不再给予原有奖励。强化(正强化、负强化)与惩罚(正惩罚、负惩罚)的区别在于外界给予好的奖赏还是坏的刺激,如果是前者则为强化,后者为惩罚。正、负的区别体现在奖赏或刺激对动作出现概率的影响,提高则为正,降低则为负。
一般情况下,无论给予或去掉刺激,强化学习针对的对象均为具体的单个动作,即假设不同的动作之间是相互独立的关系,从环境中获得的奖赏仅与具体的动作有关,如果想要知道某个动作对应的奖赏值,需要将该动作至少执行一遍,否则无法获悉该动作的任何奖赏信息。诚然,这样的假设具有一般性,然而对于特定的任务如动作之间存在一定的关联时,可适当地利用动作之间的关联性对动作空间进行有目的性选取。以脉冲率参数选择为例,利用动态参数M对区间[0,1]进行离散处理,无论是JB算法还是贪婪算法,对该空间内的动作进行选择时无非采用穷举法和随机选择法两种挑选方式,不同脉冲率下符号错误率如图2所示。
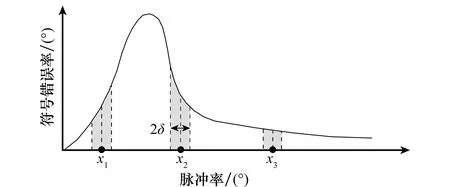
图2 不同脉冲率下符号错误率Fig.2 Symbol error rate under different pulsing ratio
由图2可知,一定距离内(阴影部分)的某些动作往往获得相似的奖赏,带来的启示是:当得知某些动作的奖赏信息后,再一次选择动作时可优先选择最大奖赏动作附近的动作,类似于“爱屋及乌”的表现,但同时也要以一定的概率探索未知动作空间,将上述“爱屋及乌”的行为定义为正强化效应。
正强化效应:对于一个动作元素固定排列且相邻动作间存在关联的动作空间,当该空间内的某个动作被选中后,在该动作获得相应奖赏的同时,对该动作某一维或若干维中距其一定距离δ内的动作相应地提高下一次被选择概率,距离参数由人为根据经验设定。
简单来说,正强化效应具有以下3种性质:
性质1距离参数为非负值,其上限值取决于具体问题。
性质2受强化效应影响的动作应少于或等于动作元素的总数。
性质3动作空间每个维度的强化距离并非完全相同,相互间是独立关系,可分别取不同的值。
特别地,上述动作选择方法可理解为另类的贪婪算法——(ε1,ε2)-Greedy,算法以概率1-ε1-ε2对当前已知最大奖赏动作加以利用,以概率ε1选择已知最大奖赏动作一定距离内的动作执行,以概率ε2对尚未执行过的动作加以探索,其中ε1和ε2的取值人为设定,可为固定值或动态变化值。此外,距离δ的取值依赖于人为经验设置,不同δ对算法性能的影响将在下文给出。
图2给出了脉冲率维度的强化效应,假设x1、x2、x3已被选中执行过且x2对应较大的奖赏,那么,以概率1-ε1-ε2执行动作x2,以概率ε1选择区间[x2-δ,x2+δ]内(不包括x2)的动作执行,以概率ε2对区间[0,x1-δ]∪[x1+δ,x2-δ]∪[x2+δ,x3-δ]∪[x3+δ,1]内的动作随机挑选并执行。
同理,可以将强化效应推广至功率和脉冲率双重维度,如图3所示。
当动作空间功率-脉冲的某个动作被选中后,将提高一定区域内(图中阴影部分)动作被选中的概率,且功率和脉冲率维度可选择不同的强化距离δPower和δρ。
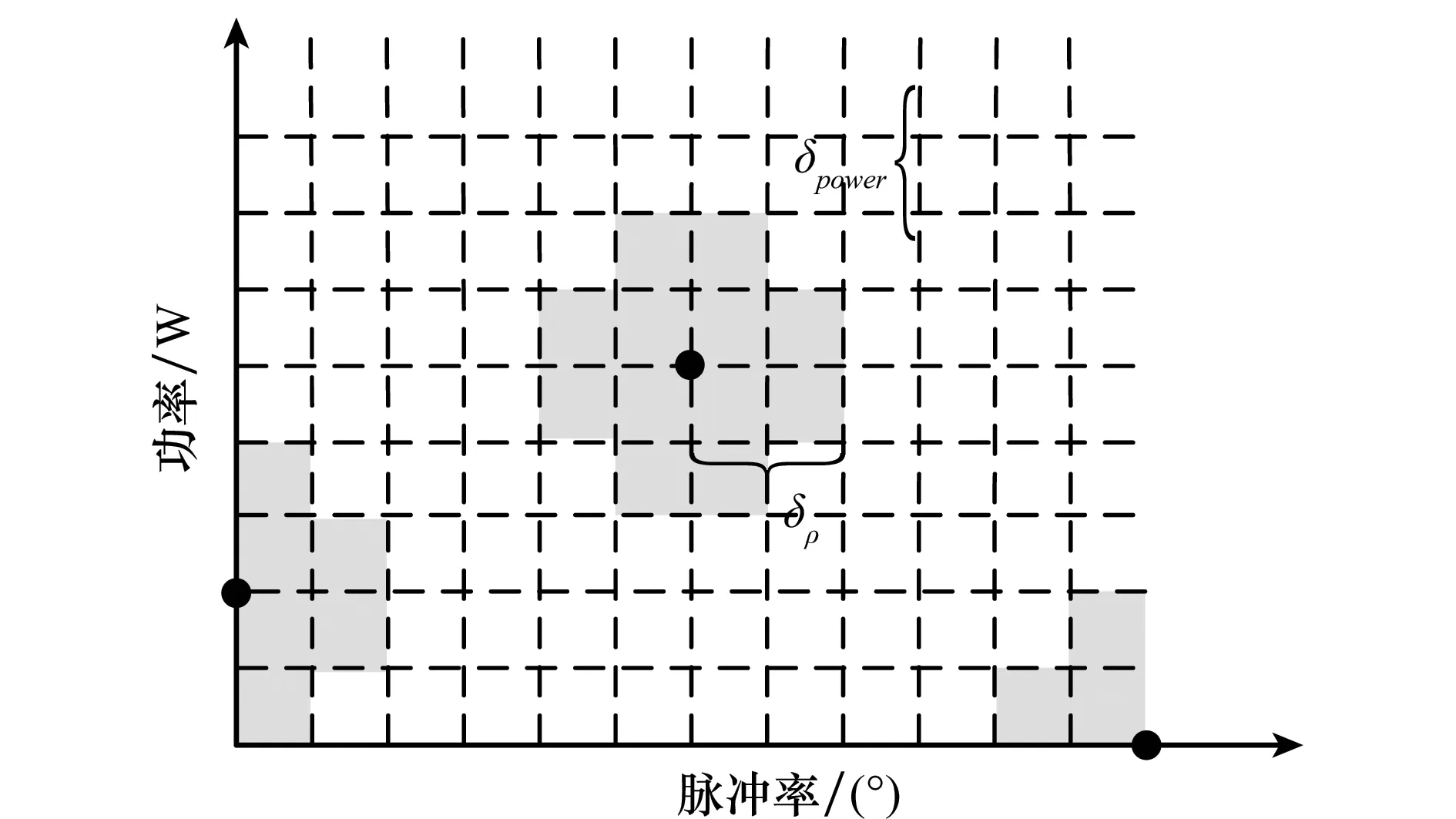
图3 功率-脉冲率维度的正强化效应Fig.3 Positive reinforcement effect in power and pulsing ratio dimensions
2 正强化学习-正交分解算法
2.1 多臂老虎机的构造
对于多臂老虎机问题,面临的任务是如何从有限的次数中尽可能多地选择平均奖赏值较高的“臂”以便获得最大奖赏。这里的“臂”是指采取的动作,当面临的是干扰任务时,动作则具体为干扰信号参数的选择。由于干扰样式集元素数目太少时使得多臂老虎机模型的构造不具有一般性,致使系统学习不到最佳干扰策略;而数目过多时又严重影响系统的学习速度,需要消耗系统与环境间大量的交互次数,为此本节从正交分解的角度着手构造新型的多臂老虎机模型。
有别于文献[12]中的构造方法,本节以{同相分量功率,ρ,JNR}构造多臂老虎机的“臂”,PJ*{1/N,2/N,…,1}×{1/M,2/M,…,1}× JNRmin+(JNRmax-JNRmin)*{1/K,2/K,…,1}。式中,PJ*{1/N,2/N,…,1}为同相分量功率集;后两项分别为脉冲率集和平均干噪比集;N、M、K分别为各集合离散化参数,可分别取不同值或取相同值。此外,由于同相分量与正交分量的功率和为干扰功率,因此仅需要知道某一分量便能够确定另一个分量的值,进而也就不需要在“臂”的构造中额外添加干扰策略集合{正交分量功率}。
2.2 强化距离
正强化效应用于提高某些已知动作周围区域内动作被选中的概率,区域的大小与强化距离有关,该距离的取值可根据经验选取某一合适值,过大或过小都不会对算法的寻优过程有所帮助。例如,当强化距离过大时,被正强化效应作用的区域随之变大,如果该区域包含过多的动作,极端情况是包含所有可能的动作,此时正强化效应对动作的选取是没有帮助的,对问题的求解退化为利用普通的贪婪算法。反之,如果强化距离过小,甚至比连续参数离散化后的最小粒度1/M(M值较大)还要小时,正强化效应作用的区域内除已知动作外将不包含任何动作,这种情况下同样对动作的选取没有任何帮助,反而徒增干扰方算法的计算复杂度,此时算法同样退化为普通的贪婪算法。
2.3 基于正强化学习和正交分解的干扰策略选择算法
将构造的新颖多臂老虎机模型与正强化效应相结合构成了本文提出的正强化学习-正交分解算法。详细的算法流程如算法1所示。
算法1PRL-OD算法
(1)T←1,JNR
(2) WhileT≤ndo
(3)M=100,N=50,duration=M*N/10
(4) Fort=T,T+1,…T+durationdo
(5) 利用正强化选择算法从行为集合PJ*{1/N,2/N,…,1}×{1/M,2/M,…,1}中选择动作,其中“×”表示笛卡尔积。选择行为at并估计相应的rt。
(6) 利用正强化效应确定影响区域。
“duration”表示对当前M值选择执行动作的交互次数,由于适当的正强化效应有助于动作的选择,因此无需对动作空间内的动作逐个进行尝试,第3.1节实验仿真部分根据仿真结果对“duration”值的设定进行分析,便于算法在应用过程中选择合适的初始值。算法中将干扰信号功率N取值为50,这种由人为设定初始值的方法具有普适性,但也可以动态地改变N值。
算法2正强化选择算法
(1) 设定初始值:强化距离δPower和δρ,计算(ε1,ε2)-Greedy算法中ε1和ε2。
(3) 确定区间[Powera-δPower,Powera+δPower]、[ρa-δρ,ρa+δρ]内包含的动作。
(4) 以概率1-ε1-ε2从已知奖赏的动作集合中选择动作,以概率ε1从第3步动作集合中选择动作,以概率ε2对强化区域外未知奖赏动作集合中的动作随机抽取。
(5) 确定了下一步要执行的动作
贪婪算法作为高效策略搜索方法,尽管使用条件苛刻,但经过严格的证明该方法理论可行,可将其与多臂老虎机模型相结合用于搜索最佳干扰策略。与环境间持续不断的交互是强化学习算法得以运行的关键,也是其能够适应复杂变化环境的根本,交互是为了对所采取的动作进行评价,即算法1、算法2中提及的奖赏信息。将通信接收端的符号错误率(symbol error rate, SER)作为奖赏标准,以便于同文献[5,12]中的算法进行性能比较。此外,参数诸如δPower、δρ、ε1、ε2可事先由干扰方根据经验设定固定的值,还可以动态改变参数值的大小。
3 实验仿真
为验证正强化学习以及正交分解算法搜索最佳干扰策略的可行性,第3.1节、第3.2节分别对两种方法的性能进行仿真验证,并就算法中的若干参数对算法性能的影响进行分析。第3.3节验证了PRL-OD算法的寻优性和收敛性,并将仿真结果同文献[12]提出的JB算法及贪婪算法共同进行比较。此外,最佳干扰参数以获悉各种先验信息为前提,通过粒子群算法优化获得,本文以此为依据衡量所提算法的寻优性能。
3.1 正强化学习的策略寻优性能
以通信双方采取BPSK调制样式进行通信为例,SNR=20 dB,JNR=10 dB,干扰信号调制样式同样为BPSK,信道中的噪声均值为0,方差为1的AWGN。文献[12]指出干扰脉冲率ρ=0.078为最优解,能够给通信方造成最大SER。为此,人为将脉冲率区间[0,1]均匀离散成1 000个参数值,最小粒度为0.001,按照不同方法从1 000个值中选择指定个数动作作为干扰信号的待选参数。JB算法采用的随机选择方法与本文提出的正强化方法在寻优性能方面的比较如图4所示。
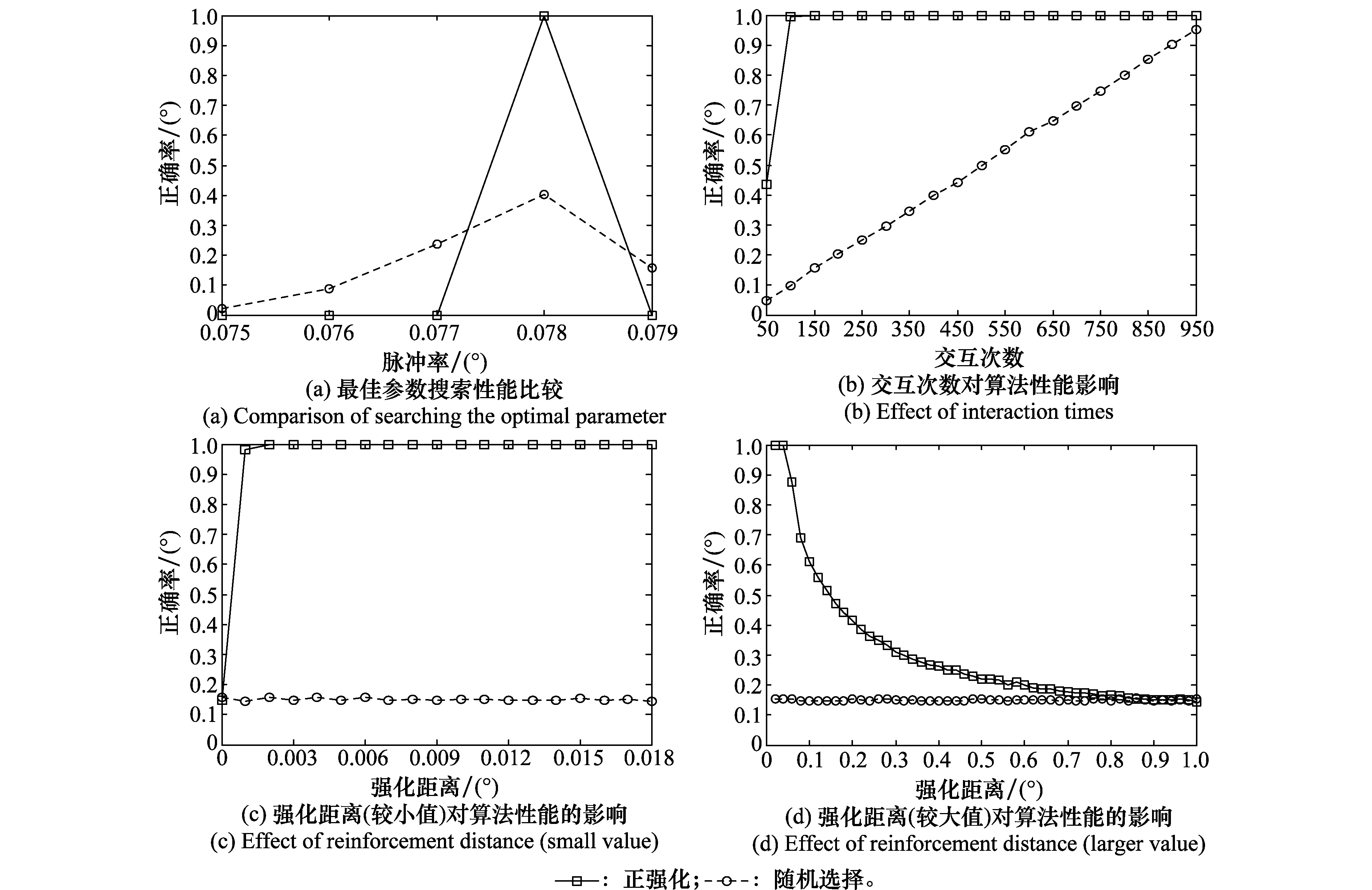
图4 正强化算法与随机选择方法寻优性能比较Fig.4 Comparison of optimal searching performance between positive reinforcement learning and chose randomly
由图4(a)可知正强化算法与随机选择方法在搜索最佳参数时性能之间的比较,当从1 000个参数值中随机选择400个作为干扰动作尝试对象时,仅能以概率0.394搜索到最优脉冲率0.078,以概率0.606搜索到次优值如0.075、0.076、0.077、0.079等。而当采用正强化算法时,以概率0.995搜索到最优脉冲率0.078,以概率0.005搜索到其他次优值。因此,利用正强化算法能够在有限的交互次数中以较大的概率搜索到最优脉冲率。由图4(b)可知交互次数对两种算法寻优性能的影响,强化距离固定为0.004,对于随机选择方法而言,其搜索到最优脉冲率的概率与交互次数呈线性增长关系,而正强化算法在交互次数超过一定阈值后几乎以概率1搜索到最优脉冲率,一般情况下可设定该阈值为干扰动作总数的1/10。强化距离是正强化算法中一个重要参数,选择合适的强化距离有助于提高搜索到最优脉冲率的概率。由图4(c)可知强化距离对正强化算法的影响,交互次数设置为150次,由于随机选择方法与强化距离无关,因此其搜索性能不随强化距离的改变而改变,搜索到最优脉冲率的概率近乎成水平直线。当强化距离为0时,正强化算法退化为普通随机选择方法,此时两种算法的寻优性能相当;当强化距离介于一定范围内时,如[0.001,0.04],正强化算法能够以较高的概率(近似等于1)搜索到最优脉冲率;然而当强化距离过大时,算法的寻优性能反而呈下降趋势,主要原因在于取值过大的强化距离限制了算法搜索强化距离以外区域的可能性,尽管如此,正强化算法较随机选择方法仍然具有更强的寻优能力;当强化距离为1时,正强化算法同样退化为普通的随机选择方法,两种算法的寻优性能几乎一致。
3.2 OD算法的策略寻优性能
3.2.1 AWGN影响下算法的寻优性能
为尽可能准确地获得最佳干扰样式,排除人为、硬件等干扰因素的外在影响,首先考虑信道中仅存在AWGN的情况,并假设噪声均值为0、方差为1。在仅考虑AWGN影响时,通信信号的星座图会变得模糊但仍然关于坐标轴对称,利用正交分解算法学习到的干扰信号最佳调制样式与文献[12]学习到的结果在大部分情况下具有相同的干扰效果。例如,当通信方采取BPSK、I型QPSK(相位分布为{0,π/2,π,3π/2})、4-PAM、Ⅱ型QPSK(相位分布为{π/4,3π/4,5π/4,7π/4},亦称为矩形QPSK)、矩形8PSK、矩形16QAM,SNR=20 dB,JNRmin=0 dB,JNRmax=26 dB时,正交分解算法能够根据干扰功率与通信功率之间的关系学习到不同的干扰样式,使得干扰效果总体上等于或优于JB算法,不同平均干噪比下两种算法的干扰效果如图5所示。
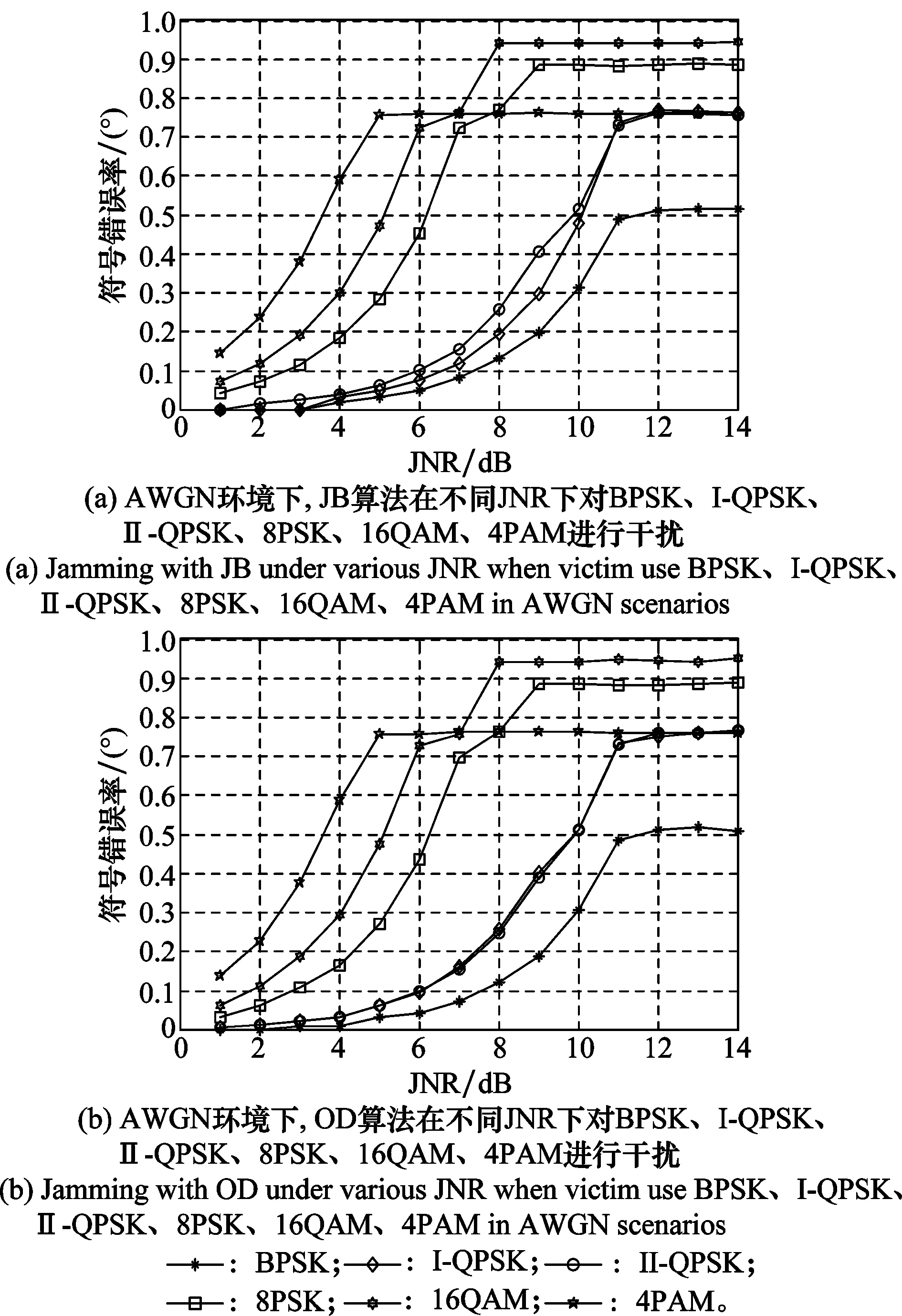
图5 加性高斯白噪声条件下JB算法与OD算法干扰效果比较Fig.5 Comparison of jamming performance between JB and OD in AWGN scenarios
由图5可知,利用OD算法获得最优参数的干扰性能不比JB算法学习的参数差,且在某些情况下要优于JB算法的学习结果,如通信方采取I型QPSK通信,SNR=20 dB,JNR=16 dB的情况。因此,在仅考虑AWGN影响的前提下,OD算法能够学习到最优参数。
3.2.2 星座图畸变情况下算法的寻优性能
尽管在仅考虑AWGN影响的情况下,利用OD算法的学习结果在干扰性能方面与文献[5]提出的算法性能相当,然而在现实情况下许多其他干扰因素是不容忽略且无法忽略的,它们的存在或多或少地会引起通信信号星座图的畸变,正如第2.1节的分析结果,对星座图畸变的通信信号施加干扰时,最佳干扰样式并非是各种标准干扰样式如BPSK、QPSK、矩形8PSK,而是信号的同相分量和正交分量存在各种可能的组合。同样假设通信方采用BPSK、I型QPSK、Ⅱ型QPSK、8PSK、16QAM、4PAM等调制样式进行通信,SNR=20 dB,JNR∈[0,26]dB,信道中噪声是均值为0方差为1的AWGN,信号星座图因I、Q路不平衡的原因向右偏移2单位,向上偏移1单位,分别利用JB算法和OD算法学习最优干扰参数,两种算法在不同平均干噪比条件下学习策略的干扰性能如图6所示。
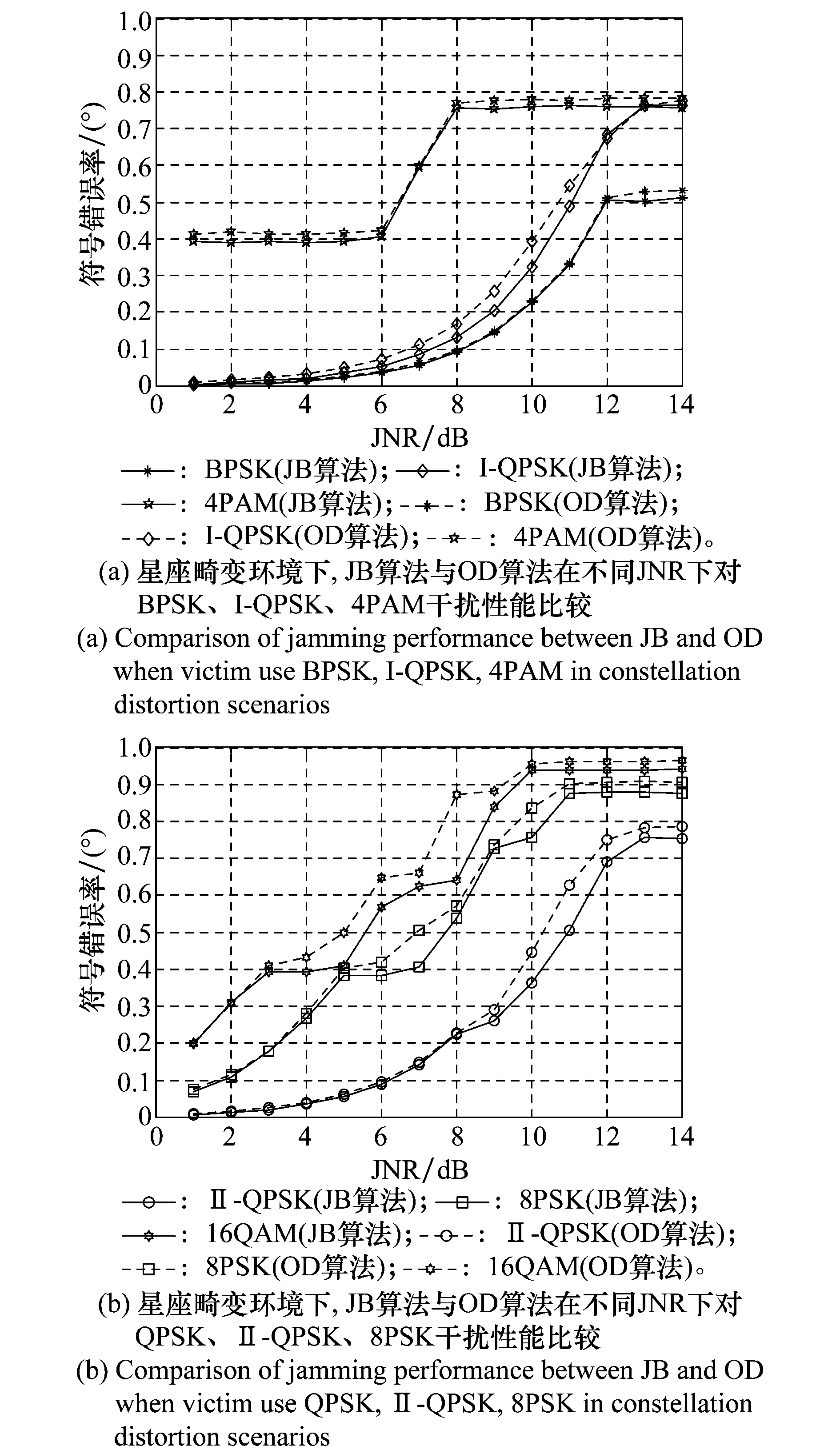
图6 星座畸变环境下OD算法的干扰效果Fig.6 Comparison of jamming performance between JB and OD in constellation distortion scenarios
由图6可知,Ac∶As=1∶0意味着干扰功率全部集中在同相分量上,而Ac∶As=0.78∶0.22意味着干扰功率在同相分量和正交分量之间按照0.78∶0.22的比例进行划分。从表中数据可以看出,当通信方以BPSK方式进行通信时,OD算法与JB算法学习到相同的干扰样式BPSK,由图6(a)可知两种方法具有相同的干扰结果。当通信方以8PSK方式进行通信时,JB算法学习到的最优干扰样式为Ⅱ型QPSK,即干扰能量在同相分量和正交分量之间均匀划分,利用OD算法学习到的结果为0.78∶0.22,即较多的干扰能量应该分配给同相分量。由图6(b)可知,利用OD算法学习的结果较JB算法具有更强的干扰性能,即利用OD算法学习的结果更优。
以SNR=20 dB,JNR=10 dB为例,针对通信方采取不同的调制样式,两种算法学习到的最佳干扰策略在不同条件下存在显著区别,具体如表 1所示。
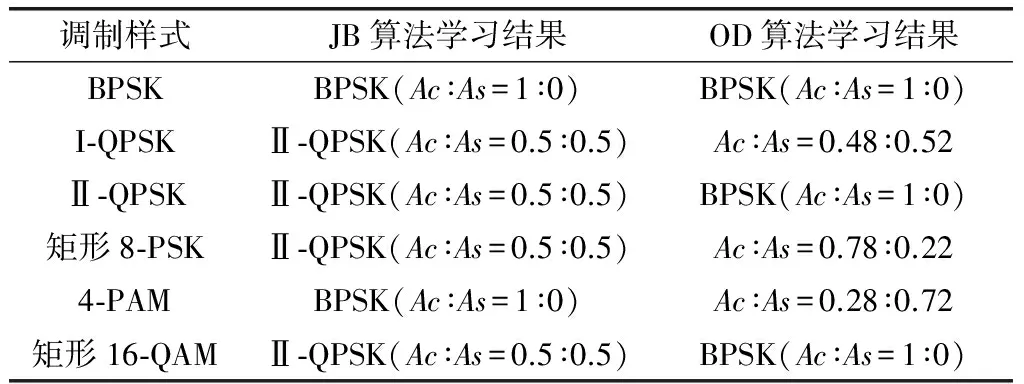
表1 利用OD算法获得的最佳干扰样式
3.3 PRL-OD算法的策略寻优性能
JB算法在计算过程中需要动态地改变连续参数离散值M,当M值寻优效果较差时改变M值并继续尝试,直至寻优效果达到期望值时终止尝试。该算法的不足之处在于绝大多数情况下较小的M值对应的离散值与最优值误差较大,尽管较大的M值对应的离散值与最优值更为接近,但同时又面临需要大量交互次数的矛盾。因此,利用正交分解算法的思想对脉冲率、功率同相分量等参数进行精细划分,如M=50,N=50。值得注意的是,精细的划分在提高准确性的同时会带来策略维数的增加,进而导致交互次数的增加。为解决维数过大的难题,可利用正强化算法降低交互次数以加快学习速度。以通信方采取矩形QPSK调制为例,假设SNR=20 dB,JNR=16 dB,由于各种人为、客观因素的干扰致使星座图向右偏移2单位,向上偏移1单位,JB算法、PRL-OD算法及不同划分方式的贪婪算法各自对应的收敛曲线如图7所示。其中贪婪算法I将脉冲率等分成6份,贪婪算法II将脉冲率等分成50份。
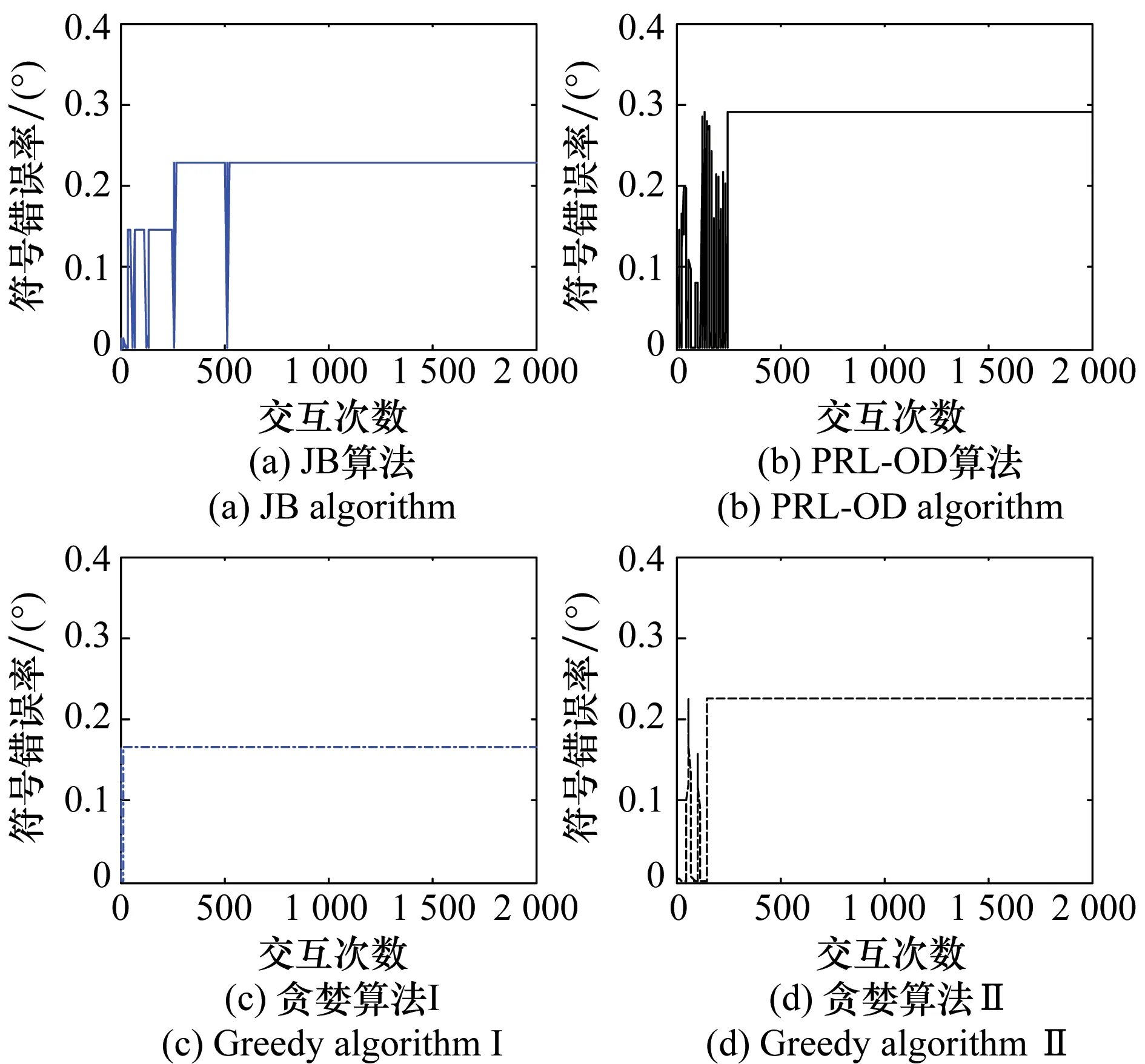
图7 不同算法收敛曲线比较Fig.7 Convergence curve comparison between different algorithms
由图7可知,经过前期不断的试错,3种算法的干扰性能曲线经过若干次数的交互后均收敛至稳定值。从实际造成的SER角度来看,PRL-OD算法学习获得的干扰策略对应的干扰性能最优,由于JB算法无法将星座图畸变因素纳入考虑,干扰性能次之,而贪婪算法在选择合适的划分方式时,干扰效果与JB算法相接近,如贪婪算法II,该结论也与文献[12]得出的结论相符,然而当选择的划分方式不恰当时,干扰效果将大打折扣,如贪婪算法I。从算法收敛需要交互次数的角度来看,PRL-OD算法从可选动作集(M×N=2 500个)中利用正强化算法选择250个动作后便收敛至稳定值,而JB算法在经过517次交互后才收敛至稳定值,由于贪婪算法I和II划分方式的原因,各自划分得到18个和150个干扰动作,需要逐一尝试后才能挑选出最佳动作,进而算法收敛至稳定值。因此,在构造的干扰任务中,PRL-OD算法能够学习到比JB算法、贪婪算法更优的干扰策略,且需要更少的交互次数。
4 结 论
针对当前干扰策略优化算法过分依赖先验信息及现有强化学习算法收敛速度慢的不足,提出了基于正强化学习和正交分解的干扰策略选择算法。该算法利用正交分解方法丰富了干扰样式的种类,并利用正强化的思想极大地降低了算法所需的交互次数。以干扰指定条件下的通信信号为例,分析了正强化学习-正交分解算法中参数设置对学习性能的影响。仿真结果表明,该算法能够在更短的时间内学习到最佳干扰策略,且该最佳干扰策略具有更强的干扰能力。
通信干扰决策关注的重点是如何既快速又准确地学习到最佳干扰策略,因此文中被赋予了新意义的多臂老虎机模型和正强化思想具有一定普遍意义。今后的工作主要围绕如何利用干扰方获得的先验信息进一步加快算法的学习速度,使得算法更加快速高效,向实用性进一步靠拢。
[1] 张春磊, 杨小牛. 认知电子战与认知电子战系统研究[J]. 中国电子科学研究院学报, 2014, 9(6): 551-555.
ZHANG C L, YANG X N. Research on the cognitive electronic warfare and cognitive electronic warfare system[J]. Journal of China Academy of Electronics and Information Technology,2014,9(6): 551-555.
[2] 贾鑫, 朱卫纲, 曲卫, 等. 认知电子战概念及关键技术[J]. 装备学院学报, 2015, 26(4): 96-100.
JIA X, ZHU W G, QU W, et al. Concept of cognitive electronic warfare and its key technology[J].Journal of Equipment Academy, 2015, 26(4): 96-100.
[3] PIETRO R D, OLIGERI G. Jamming mitigation in cognitive radio networks[J]. IEEE Network, 2013, 27(3): 10-15.
[4] BAYRAM S. Optimum power allocation for average power constrained jammers in the presence of non-Gaussian noise[J]. IEEE Communications Letters, 2012, 8(16): 1153-1156.
[5] AMURU S, BUEHRER R M. Optimal jamming strategies in digital communications-impact of modulation[C]∥Proc.of the Global Communication Conferance, 2014: 1619-1624.
[6] AMURU S, BUEHRER R M. Optimal jamming against digital modulation[J].IEEE Trans.on Information Forensics Security,2015,10(10): 2212-2224.
[7] 于乃功, 李倜, 方略. 基于直接强化学习的面向目标的仿生导航模型[J]. 中国科学:信息科学, 2016(3): 78-86.
YU N G, LI T, FANG L. Biological plausible goal-directed navigation model based on direct reinforcement learning algorithm[J]. SCIENCE CHINA Information Sciences, 2016(3): 78-86.
[8] GAI Y, KRISHNAMACHARI B, JAIN R. Combinatorial network optimization with unknown variables: Multi-armed bandits with linear reward[J]. IEEE/ACM Trans.on Networking, 2012, 20(5): 1466-1478.
[9] AUER P, BIANCHI N C, FISCHER P. Finite-time analysis of the multi-armed bandit problem[J].Machine Learning,2002,47(2):235-256.
[10] WU Y, WANG B, LIU K J R, et al. Anti-jamming games in multi-channel cognitive radio networks[J]. IEEE Journal on Selected Areas in Communications, 2014, 30(1): 4-15.
[11] GWON Y L, DASTANGOO S, FOSSA C E, et al. Competing mobile network game: embracing antijamming and jamming strategies with reinforcement learning[C]∥Proc.of the Communication Netword Security, 2013: 28-36.
[12] AMURU S, TEKIN C, SCHAAR M VAN DER, et al. Jamming bandits-a novel learning method for optimal jamming[J].IEEE Trans.on Wireless Communications,2016,4(15):2792-2808.
[13] AMURU S, BUEHRER R M. Optimal jamming using delayed learning[C]∥Proc.of the IEEE Military Communication, 2014: 1528-1533.
