粗糙集理论和信息熵的AHP改进方法*
2018-03-12陈覃霞梁德翠
陈覃霞,刘 盾+,梁德翠
1.西南交通大学 经济管理学院,成都 610031
2.电子科技大学 经济与管理学院,成都 610054
1 引言
权重问题一直以来是多属性决策问题研究的一个热点。权重设置的合理性直接影响到决策的质量和可靠性。在大多管理问题中,权重的设定主要来自于主观的人为设定,常见的有主观经验法、主次指标排队分类法、专家调查法等。就定性分析而言,人们常常在群决策过程中使用头脑风暴法(Delphi法);就定量分析而言,常见的有线性分配法、简单加权法、层次分析法(analytic hierarchy process,AHP)、TOPSIS(technique for order preference by similarity to an ideal solution)法、ELECTRE法、PROMETHEE法等。在上述众多方法中,AHP是权重获取的一种重要方法,它通过将复杂问题分解成递阶层次结构,并利用判断矩阵来比较各因素的重要性,并在众多工程、信息、管理问题中得到成功应用[1-3]。
随着信息社会的飞速发展,大数据呈现出的体积大、结构复杂、低价值密度和实时性等特征也对传统决策理论带来巨大挑战。只考虑人为因素,不关注数据本身的特征和结构已不能够解决实际决策问题。从权重问题出发,主观和客观兼顾、人机结合的权重获取策略已成为多属性决策领域的主流研究方向之一[4]。就客观权重而言,Pawlak教授1982年提出的粗糙集理论(rough set theory)是一种新兴的处理模糊和不确定性知识的数学工具[5],它利用在决策表中保持系统某种分类能力不变的思想,通过属性约简来获取属性的客观权重。由于粗糙集属性约简过程完全基于数据驱动,不需要任何先验信息,一经问世就在决策分析、机器学习、数据挖掘与模式识别等领域得到广泛应用[6-8]。此外,在粗糙集与其他决策方法的融合研究中,丁晓琴和张德生提出了基于主观AHP和客观CRITIC的综合赋权方法[9];程平和刘伟将主客观权重确定方法应用到多属性群决策问题中[10];张文宇等人利用AHP方法和粗糙集理论获取主客观集成权重[11];金菊良等人提出了一种直接根据单指标相对隶属度的模糊评价矩阵,构造层次分析法中判断矩阵,来获取属性权重的方法[12]。刘盾等人给出了一种基于粗糙集理论的多属性决策权重构造模型[13],并进一步考虑了一种粗糙集与信息熵融合的客观权重获取方法[14]。
基于上述分析,本文将粗糙集理论和信息熵引入到AHP方法中,提出了一种同时考虑主观和客观权重的AHP改进方法。首先,通过粗糙集理论和信息熵构造3种属性重要度,并以此来计算属性的客观权重;其次,利用客观权重对AHP主观判断矩阵进行修正,提出基于主观和客观的权重构造判断矩阵方法步骤;最后,通过对大众点评美食推荐的实证研究,对比不同权重获取方法,验证了本文方法的有效性和可行性。
2 预备知识
本文首先对粗糙集理论和信息熵等基本概念进行简要回顾[5]。在粗糙集理论中,数据集一般采用信息表或者信息系统的形式来表达,它可以用四元组来表示。
定义1(信息系统)假设S=(U,A,V,f)是一个信息系统,其中U表示对象的非空有限集合,即论域;A代表属性全体;是属性值的集合;f:U×A→V是一个信息函数,它为每个对象的每个属性赋予一个信息值,即:∀a∈A,x∈U,f(x,a)∈Va。
定义2(不可分辨关系)对于一个论域U,C是条件属性集,D是决策属性集,R是U上的一个等价关系,U/R表示R的所有等价类构成的集合,[x]R表示包含元素x∈U的R的所有等价类。对于每个属性子集P⊆C,可定义一个不可分辨关系RP={(x,y)∈U×U:f(x,a)=f(y,a),a∈P}。
在定义2中,不可分辨关系是粗糙集理论中的一个重要概念。在信息系统中,每一个不可分辨关系定义一个等价关系。
定义3(上下近似集)假设S=(U,A,V,f)是一个信息系统,R是S上的一个等价关系,对于每个子集X⊆U,定义X的R上近似集和R下近似集分别为:

定义4(正域约简和核)假设S=(U,A,V,f),C和D分别为属性集A中的条件属性和决策属性,则D的C正域可以记为如果一个独立子集B⊂C,对 ∀a∈C,有POSB(D)=POSC(D),POSB-{a}(D)≠POSC(D),则称B为一个C的D正域约简,记C的所有D约简关系为redD(C),则C的所有D约简集的交为C的D核,记coreD(C)=⋂redD(C)。
定义5(信息熵)假设U是一个论域,P是U上的一个知识,且U/P={X1,X2,…,Xn},则知识P的概率分布定义为:

其中,p(Xi)=|Xi|/|U|,1≤i≤n,则知识P的熵定义为
信息熵是总体不确定性的一个度量,一个系统的不确定性程度越小,则其信息熵就越小;反之,系统的不确定性程度越大,则其信息熵就越大。
定义6(条件熵)假设P和Q是U上的两个知识划分,U/P={X1,X2,…,Xn},U/Q={Y1,Y2,…,Ym},则知识Q相对于知识P的条件熵定义为:

3 主观和客观属性权重集结方法
3.1 AHP权重构造方法
AHP方法是20世纪70年代中期美国著名运筹学家Saaty教授提出的一种定性和定量相结合的、系统化的、层次化的分析方法。其主要思想是把一个复杂的决策问题表示为一个有序的递阶层次结构,通过各层次中准则(判断矩阵)对于目标中各指标权重进行求解,最终对决策方案的优劣进行排序。利用AHP方法构造权重的一般步骤为:建立递阶层次结构模型,构造准则层和指标层的比较判断矩阵、层次单排序和层次总排序。其中,在构造各层次之间的判断矩阵时,需要判断其一致性。即需要计算每一个判断矩阵的最大特征根λmax、一致性指标CI=(λmax-n)/(n-1)和随机一致性指标CR=CI/RI。当CR<0.1时,即认为判断矩阵具有满意的一致性;否则,需要调整判断矩阵,使之具有满意的一致性。
3.2 客观权重构造方法
对于客观权重构造部分,本文从粗糙集和信息熵出发,依次来构造属性的客观权重。就粗糙集理论而言,主要考虑正域约简对属性权重的影响;而在信息熵中,主要考虑信息增益对属性权重的影响。具体如下:
(1)基于粗糙集理论的客观权重构造方法
考虑到不同条件属性对决策系统的分类能力不同,其重要程度也是不同的。利用粗糙集来构造客观权重的核心思想为:若去掉某个属性后系统分类变化越大,则该属性的重要性越大。这里定义两个重要度来刻画属性的分类能力,δ重要度和ξ重要度。δ重要度通过定义7中正域约简来构造;ξ重要度通过定义8中属性占约简个数比例来构造。
定义7(δ重要度)对于一个论域U,C和D分别为条件属性和决策属性,记γC(D)=|POSC(D)|/||U。对∀a∈C,属性a关于D的重要度定义为δCD(a)=γC(D)-γC-{a}(D)。δCD(a)越大,说明属性a越重要,则该属性的权重也越大。
定义8(ξ重要度)假设一个信息系统S=(U,A,V,f),Bk(k=1,2,…,r)为所有划分约简集,对∀a∈C,记属性a的重要度k=1,2,…,r。ξa越大,说明属性a在所有约简集中出现的次数越多,它对信息系统的重要程度应该越大,则其权重也就越大。
对于定义7和定义8中的属性重要度,本文主要采用Rosetta软件中基于遗传算法的属性约简算法获取实验所需的约简集。Rosetta是一款适用性广泛的粗糙集算法软件和实验平台,它提供了多种数据预处理功能,如决策表的补齐、离散化、属性约简和规则提取等。文献[15]列出了该遗传算法的基本思想:

其基本算法思路可由下面步骤概括:
步骤1随机初始化种群。
步骤2对种群进行适应度评估。
步骤3执行选择、交叉、变异、倒位、重组操作。
步骤4对新的种群进行适应度评估。
步骤5若满足终止条件则停止,否则转步骤3。
(2)基于信息熵理论的客观权重构造方法
作为条件信息熵的一种重要扩展,信息增益是决策树ID3算法的核心概念,其大小是人们构造决策树节点属性的判断依据[16]。考虑到某属性的信息增益越大,其对论域中对象的区分度就越大,对信息系统的重要性也就越大。因此,信息增益可以一定程度反映属性的重要程度。定义9将其作为属性客观权重的一种构造方法。
定义9(基于信息增益的属性重要度)假设一个信息系统S=(U,A,V,f),C是条件属性,D是决策属性,对 ∀a∈C,记属性a的重要度ga=H(D)-H(D|a)。ga越大,表示属性a对信息系统的重要性越大,则其权重也应越大。
根据定义7~定义9,提出一种基于粗糙集和信息熵结合的客观权重确定方法。对∀a∈C,它主要包括以下5个步骤:
步骤1根据定义7,计算属性a的δ重要度,并进行归一化处理,得
步骤2根据定义8,计算属性a的ξ重要度,并进行归一化处理,得
步骤3根据定义9,计算属性a的g重要度,并进行归一化处理,得
步骤4计算客观权重特别地,当λ=1/3,μ=1/3
步骤5将得到的客观权重进行归一化处理,即
3.3 一种改进的AHP权重构造方法
在多属性决策问题中,权重确定方法一般分为主观赋权法和客观赋权法。一方面,AHP方法是一种常见的主观赋权方法,其核心思想是根据专家自身经验对指标的判断矩阵进行打分,从而获取属性权重。该方法具有一定的主观偏好性且没有考虑属性的冗余性。另一方面,基于粗糙集理论和信息熵的客观赋权法,虽然基于数据驱动且避免人为主观性,但得到的属性权重只与数据本身相关,未能考虑决策问题本身的应用背景和实际语义。
基于上述分析可以发现,仅从主观或客观单一视角来构造属性权重存在各自的不足。因此,本节提出一种改进的AHP权重获取方法,它通过基于数据驱动得到客观集成权重,来修正已有AHP的主观判断矩阵。假设一个信息系统S=(U,A,V,f),条件属性C={c1,c2,…,cn},决策属性D={d},具体步骤如下:
步骤1构造准则层判断矩阵,计算准则层权重。依照AHP方法,由专家根据自身经验对准则层进行两两比较,按照1~9标度法对其进行打分,得到判断矩阵,并计算准则层权重。
步骤2计算客观权重。按照3.2节步骤4提出的客观权重构造方法,对每个条件属性c∈C,计算c的客观权重,得到
步骤3建立新的AHP标度。对∀c∈C,令计算属性间的最大差值Δ=建立与1~9标度一致的新的AHP标度。具体计算过程如表1所示。

Table 1 Scale ofAHP method表1 AHP的1~9标度
步骤4构造新的判断矩阵。根据各属性的客观权重和AHP标度,比较属性间的重要性程度,构造改进后的判断矩阵。其中,属性间的重要性程度cij的计算公式为:

步骤5一致性检验。根据步骤4中得到的判断矩阵,计算每个属性的权重wci′,并进行一致性检验。
步骤6根据步骤1中得到的准则层的判断矩阵和步骤5中得到的指标层的判断矩阵,计算相应的主客观集成权重,并得到权重的最终排序。
4 实证分析
为了验证本文方法的有效性和可行性,以大众点评的美食推荐问题来进行实证分析。随着互联网和移动电商的普及,大众点评、美团网、糯米网、拉手网等已成为人们外出购买团购就餐的重要选择,餐饮团购也逐渐融入人们日常生活,成为衣食住行的一部分。网络团购的兴起也引入了众多学术新问题,其中之一就是如何设计满足消费者个性化的美食推荐模型和方法。美食推荐的主要目的是通过分析消费者的口味爱好、用户偏好以及历史评价,为消费者提供个性化美食推荐服务。在分析消费者网络团购行为方面,文献[17]认为消费者在进行网络团购时,价格为主要影响因素,餐饮种类为次要因素。通过文献[18],可以得到服务品质更好的餐厅消费者回头率更高,同样就餐环境也会影响消费者的购餐决策。本文通过对消费者餐饮团购行为的文献分析和整理,将影响消费者团购的因素分为商家因素、用户因素和其他因素3类。本文首先构建美食推荐系统的AHP层次结构模型,如图1所示。

Fig.1 Hierarchy model of food recommendation system图1 美食推荐系统的层次结构模型
在图1中,第一层是目标层,它表示问题的总目标(目的),这里指对美食的推荐;第二层是准则层,它是总目标的具体体现,也是决策的具体准则,这里用商家相关信息B1、用户相关信息B2和其他相关信息B33个准则表示;第三是指标层,它将第二层中的3个准则进一步细化,这里表现为10个评价指标c1,c2,…,c10。根据图1中的层次结构模型,在征求专家相关意见后,构造准则层的判断矩阵:

对于指标层,根据专家评估可分别构造商家因素、用户因素和其他因素的3个判断矩阵B1、B2和B3:

完成判断矩阵的构造之后,接下来进行AHP层次单排序和一致性检验。
(1)通过特征根法AW=λmaxW,求出λmax及相应的特征向量W,计算结果为:λA=3.038 7,λB1=3.024 7,

(2)计算一致性指标CI=(λmax-n)/(n-1),计算结果分别为
(3)计算一致性比率CR=CI/RI<0.1,计算结果为
根据上述计算结果可以看到各CR值均小于0.1,因此各判断矩阵均满足一致性检验。最后,计算各属性最终的AHP主观权重分别为
上述分析得到的AHP权重仅考虑了专家的主观人为因素,下面利用大众点评网抓取的成都地区餐饮数据来对第3.2节进行分析。表2是整理的38条相关店铺数据。在表2构成的信息系统中,U={x1,x2,…,x38}表示38个店铺;选取菜系、星级、人均消费、口味、环境、服务、有无包间、有无宝宝椅、可否刷卡、有无停车位等10项指标作为条件属性,分别用C={c1,c2,…,c10}表示;人气排行为决策属性d。通过数据预处理,可得到成都市美食推荐系统的一个原始数据表。

Table 2 Data sheet of food recommendation system表2 美食推荐系统的原始数据表
通过对表2的原始数据进行离散化处理后,可以得到属性c2有A、B、C共3个等级,分别表示五星、四星半和四星;属性c3的值域划分为3个等级,分别表示价格低、价格适中和价格高;c4~c6的值域为{A,B,C},分别表示好、中和差;条件属性c7~c10的值域为{Y,N},分别表示有和无;决策属性值域为{A,B,C},其含义分别定义为人气排行高、中和低。离散化后的美食推荐系统决策表如表3所示。

Table 3 Decision tables of food recommendation system表3 美食推荐系统决策表
通过对表3中的数据进行约简,可得到表3的所有约简集合如下:

分别计算各个属性的δ*重要度、ξ*重要度和g*重要度,并通过3.2节的5个步骤计算各属性的客观权重,得到的结果如表4所示。

Table 4 Objective attribute weights表4 客观属性权重
然而,由表4得到的权重仅考虑了决策表(表3)的数据结构,并未考虑美食推荐这一实际应用背景。下面利用第3.3节的分析来构造一种兼顾主观性和客观性的AHP权重。
首先,根据表4中得到的各属性客观权重,将标度转化为AHP 1~9标准标度,结果如表5所示。

Table 5 Scale of improvedAHP method表5 改进AHP的标度
其次,根据表5中的标度分别构造商家因素、用户因素和其他因素的3个改进后的判断矩阵:
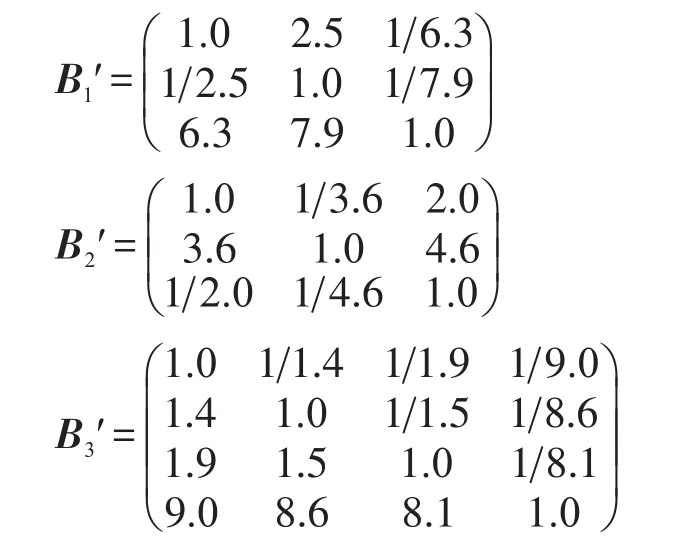
再者,通过对3个判断矩阵进行一致性检验,可计算矩阵B1′、B2′和B3′的一致性比率CR值分别为0.051 1、0.021 5和0.011 8,它们均满足一致性检验要求。利用第3.3节的步骤3~步骤5,可求得各属性的权 重wc1′=0.157 6,wc2′=0.079 4,wc3′=0.763 1,wc4′=0.215 0,wc5′=0.660 0,wc6′=0.125 0,wc7′=0.067 3,wc8′=0.085 2,wc9′=0.114 6 ,wc10′=0.733 0 。
最后,综合考虑基于主观AHP方法构造准则层判断矩阵A,以及通过客观属性权重得到的指标层判断矩阵B1′、B2′、B3′,可计算最终考虑主客观因素的改进AHP集成权重,计算结果如表6所示。

Table 6 Attribute weights of improvedAHP method表6 改进的AHP属性权重
最后,将AHP方法(主观权重)、粗糙集和信息熵结合的方法(客观权重)和改进的AHP方法(主客观结合权重)3种权重方法进行比较,其结果如图2所示。

Fig.2 Comparison of 3 kinds of weights图2 3种权重的比较图
根据图2的结论并结合美食推荐实际应用背景,认为AHP方法得到的结果过分强调了星级的重要性,忽略了餐厅环境的重要性,并且权重的确定完全依赖于专家的经验和偏好,具有一定的主观性。对于粗糙集和信息熵方法得到的结果,虽然该方法基于数据驱动,但将“是否有停车位”这一属性的重要性排在所有属性的第1位,这明显与实际美食推荐过程不符。本文提出的兼顾主观和客观的AHP改进方法,既考虑了专家评价中专家的权威性,又考虑了信息表中数据驱动的数据特征,表现出一种“人机结合”的决策思想。此外,从表6和图2的实验结果来看,本文方法在所有10个属性中:(1)认为人均消费最为重要,这与大多消费者的消费观念比较吻合。(2)认为餐厅环境、菜系、是否有停车位、口味、服务和星级的重要性较高,这也与人们在实际团购过程中,喜欢寻找合适的菜系和考虑餐厅的星级档次这一决策行为较为一致。特别是朋友聚餐、商务谈判等用餐需求,对菜系和星级都有一定的要求和考量。(3)对于现在众多自驾就餐的消费者而言,寻找停车位是一件比较麻烦的事情。因此若餐厅有停车位,在一定程度上解决了部分消费者的个性化需求。(4)对于大部分消费者来说,在网上进行餐厅团购时,对于安静、隐蔽的空间要求不高。因为大多数店铺使用包间需要增加额外费用,且不接受团购用户,所以餐厅是否有包间变得不是很重要。(5)大多数消费者餐厅团购的目的是朋友聚餐,较少情况会带着婴儿,因此餐厅是否有宝宝椅不是很重要。(6)在进行餐饮团购时,消费者会提前购买团购券,或者选用电子支付。因此餐厅是否可以刷卡不是很重要。根据上述分析结果,本文提出的主客观AHP权重获取方法得到的属性重要度排序更加符合消费者的团购行为,因而具有一定的理论意义和应用价值。
5 结束语
考虑到传统AHP评价方法在权重获取中完全取决于专家主观评估这一现象,本文将粗糙集理论和信息熵引入到属性权重构造问题中,提出了一种新的AHP判断矩阵构造和属性权重获取方法。在改进的AHP权重计算方法中,兼顾“专家评估主观性”和“数据驱动客观性”,把二者有机结合,人机交互、优势互补,这在一定程度上改善了单独考虑主观和客观权重各自的不足,也使得改进AHP权重更为合理和有效。最后,通过大众点评美食推荐问题对主观、客观和主客观3种权重进行对比分析,来验证本文方法的有效性和可行性。在后续研究中,将进一步探讨有决策者风险偏好和群决策环境下,多属性决策属性权重的主客观集结与融合方法。
[1]Wang Ling,Liu Jianlin,Zhu Jiwei.Risk evaluation of international EPC hydropower project based on AHP-MF model[J].Journal of Engineering Management,2012,26(4):82-86.
[2]Wang Xinmin,Qin Jianchun,Zhang Qinli,et al.Mining method optimization of Gu Mountain stay ore based on AHP-TOPSIS evaluation model[J].Journal of Central South University:Science and Technology,2013,44(3):1131-1137.
[3]Zhou Shengshi,Zhang Yanmeng,Zhao Minmin.Evaluation of the third-party cold chain logistics enterprises based on AHP and TOPSIS method[J].Logistics Engineering and Management,2016,38(11):65-67.
[4]Zhao Haitao,Liu Chaoying,Tian Shui.A subjective and objective integration method for weight determination[J].Journal of Jianghan University:Natural Sciences,2004,32(4):63-65.
[5]Pawlak Z.Rough sets[J].International Journal of Computer Information Sciences,1982,11(5):342-356.
[6]Chen Jizhou,Luo Ke.Artificial fish-swarm clustering algorithm based on granular computing and rough set[J].Computer Engineering andApplications,2015,51(21):116-120.
[7]Wu Shangzhi,Luo Yichun,Zhai Jingpeng.A minimum attribute reduction algorithm based on genetic&particle swarm optimization and rough sets[J].Computer Engineering&Science,2016,38(5):1007-1013.
[8]Yao Binxiu,Ni Jiancheng,Yu Pingping,et al.CRS-KNN text classification algorithm based on Canopy and rough set[J].Computer Engineering andApplications,2017,53(11):172-177.
[9]Ding Xiaoqin,Zhang Desheng.K-means algorithm based on synthetic weighting of AHP and CRITIC[J].Computer Systems&Applications,2016,25(7):182-186.
[10]Cheng Ping,Liu Wei.Method of determining attributes weights based on subjective preference in multi-attribute group decision-making[J].Control and Decision,2010,25(11):1645-1650.
[11]Zhang Wenyu,Ma Yue,Chen Xing,et al.Combined with rough set and AHP to determine the attribute weight[J].Measurement&Control Technology,2013,32(10):125-128.
[12]Jin Juliang,Wei Yiming,Ding Jing.Fuzzy comprehensive evaluation model based on improved analytic hierarchy process[J].Journal of Hydraulic Engineering,2004,35(3):65-70.
[13]Liu Dun,Hu Pei,Jiang Chaozhe.New methodology of attribute weights acquisition based on rough sets theory[J].Systems Engineering and Electronics,2008,30(8):1481-1484.
[14]Liu Dun,Hu Pei,Li Tianrui,et al.An approach for attribute weights acquisition based on rough sets theory and information gain[C]//Proceedings of the 2007 International Conference on Intelligent Systems and Knowledge Engineering,Chengdu,Oct 16-15,2007:1296-1302.
[15]Vinterbo S,Øhrn A.Minimal approximate hitting sets and rule templates[J].International Journal of Approximate Reasoning,2000,25(2):123-143.
[16]Chen Yuan,Yang Dong.Attribute reduction algorithm based on information entropy and its application[J].Journal of Chongqing University of Technology:Natural Science,2013,7(1):42-46.
[17]Ning Lianju,Zhang Yingying.An empirical study on groupbuying consumers'preferences—illustrated by catering groupbuying[J].Journal of Northeastern University:Social Science,2011,13(5):404-410.
[18]Zhang Shuai.Study on the impact of quality of team purchase website service on consumers'repurchases intention[J].Journal of Changchun University,2012,22(7):797-802.
附中文参考文献:
[1]王玲,刘建林,朱记伟.基于AHP-MF模型的国际水电EPC项目风险评价研究[J].工程管理学报,2012,26(4):82-86.
[2]王新民,秦健春,张钦礼.基于AHP-TOPSIS评判模型的姑山驻留矿采矿方法优选[J].中南大学学报:自然科学版,2013,44(3):1131-1137.
[3]周盛世,张艳萌,赵敏敏.基于AHP和TOPSIS方法的第三方冷链物流企业评价研究[J].物流工程与管理,2016,38(11):65-67.
[4]张海涛,刘超英,田水.权重确定的主客观综合法[J].江汉大学学报:自然科学版,2004,32(4):63-65.
[6]陈济舟,罗可.基于粒计算与粗糙集的人工鱼群聚类算法[J].计算机工程与应用,2015,51(21):116-120.
[7]吴尚智,罗艺纯,翟敬鹏.基于遗传粒子群和粗糙集的最小属性约简算法[J].计算机科学与工程,2016,38(5):1007-1013.
[8]姚彬修,倪建成,于苹苹,等.一种基于Canopy和粗糙集的CRS-KNN文本分类算法[J].计算机工程与应用,2017,53(11):172-177.
[9]丁晓琴,张德生.基于AHP和CRITIC综合赋权的K-means算法[J].计算机系统与应用,2016,25(7):182-186.
[10]程平,刘伟.多属性群决策中一种基于主观偏好确定属性权重的方法[J].控制与决策,2010,25(11):1645-1650.
[11]张文宇,马月,陈星,等.基于粗糙集与AHP结合的属性权重确定方法[J].测控技术,2013,32(10):125-128.
[12]金菊良,魏一鸣,丁晶.基于改进层次分析法的模糊综合评价模型[J].水利学报,2004,35(3):65-70.
[13]刘盾,胡培,蒋朝哲.一种基于粗集理论的属性权重构造方法[J].系统工程与电子技术,2008,30(8):1481-1484.
[16]陈媛,杨栋.基于信息熵的属性约简算法及应用[J].重庆理工大学学报:自然科学版,2013,7(1):42-46.
[17]宁连举,张莹莹.网络团购消费者购买选择行为偏好及其实证研究——以餐饮类团购为例[J].东北大学学报:社会科学版,2011,13(5):404-410.
[18]张帅.团购网站服务质量对顾客再购意愿的影响研究[J].长春大学学报,2012,22(7):797-802.
