基于Hash的Top-N推荐方法
2018-03-07唐长兵郑忠龙
朱 婷, 陈 德, 唐长兵, 郑忠龙
(浙江师范大学 数理与信息工程学院,浙江 金华 321004)
0 引 言
随着以计算机网络为核心的信息技术的迅速发展,以及国际互联网在全球的应用和普及,一种崭新的商务模式——电子商务随之产生.纵观全球,每天都有成千上万的商品在网上售卖,数以百计的客户在网上购买.怎样为用户有效而准确地匹配所需商品至关重要,于是,推荐系统应运而生.Top-N推荐系统已经被电子商务网站广泛使用,将最符合客户需求的前N个项目列表推荐给用户.
Top-N推荐系统主要是根据用户的历史信息估计其对于新项目的评分,并且把预测评分高的项目推荐给用户.一般情况下,历史信息分为显性信息(评分)和隐性信息(点击、收藏).在过去的10年里,学者已经提出了许多Top-N推荐系统[1].这些方法大致分为以下几类:基于邻域的协同过滤[2]、基于模型的协同过滤[3]、基于排序的方法[4]和基于内容的推荐方法[5].基于邻域的方法又分为基于用户的协同过滤和基于项目的协同过滤[6],一般的原则是确定用户或项目之间的相似性[7].例如,基于项目的最近邻(itemKNN)协同过滤方法,首先确定一组消费者已经购买过项目的相似项目,然后推荐出最相似的前N个项目给消费者.基于模型的方法一般是先建立一个模型,然后再生成推荐.例如,矩阵分解(MF)方法,利用潜在空间中用户-项目的相似性提取用户-项目的购买模式.纯基于奇异值分解(PureSVD)的矩阵分解方法,通过用户-项目矩阵的主奇异值向量描述用户和项目的特征[8].高斯过程分解机(GPFM)构建了一个非线性的模型,更好地捕获了用户偏好与上下文间的相互作用,再生成推荐[9].本文采用基于邻域的协同过滤Top-N推荐与Hash学习结合的方法构成推荐.
目前,各行各业积累的数据都呈现出爆炸式的增长趋势,已经进入大数据时代.数据是与推荐技术密不可分的因素,而过多的数据会给存储与运算带来困难.Hash学习能通过机器学习机制,将数据映射成二进制串的形式[10],显著减少了数据的存储和通信开销.Hash学习的目的是学到用数据的二进制Hash码表示,使得Hash码尽可能地保持原空间中的近邻关系,即保相似性.更具体地说,每个数据点都将会被编码成一个紧凑的二进制串,并且原空间中相似的数据点会被映射成相似的二进制串.通过使用Hash码,可以使得搜索复杂度呈恒定的或次线性的.此外,数据存储所需的空间急剧下降.直接为给定数据集计算最优的二进制码是一个NP问题,为了避免NP问题,Hash方法通常采用2个步骤[11-12]:首先是投影阶段,用一个线性或非线性的投影函数将样本数据转换成低维的向量;然后是量化阶段,把投影得到的向量量化为二进制码.
Hash学习已经被视为一种很有前景的快速相似性搜索方法[13].大多数Hash方法都采用汉明距度量Hash码空间中点与点之间的相似度.2个字符串之间的汉明距是指字符串间对应位置不相同字符的个数.但是汉明距在保相似性方面存在一定的局限性[14],所以本文采用Manhattan距离来度量Hash码之间的相似性.先通过Hash学习处理数据,找到相似用户或项目,然后进行预测与推荐.
1 相关工作
近邻搜索被广泛运用于机器学习及相关的各个领域,如信息查询及搜索、数据挖掘,还有计算机视觉等.近年来,伴随着互联网技术的高速发展,数据量也在显著增长,这使得近邻搜索的价值变得更大.然而,传统的近邻搜索要求遍历数据集中的每一个数据点,而时间复杂度与数据集的大小成线性关系.因此,在大数据的背景下,传统的近邻搜索方法的计算时间会很长.此外,如果使用传统的存储格式来存储数据,就会增加巨大的存储成本.为了解决这个问题,学者提出了结合Hash技术进行有效近似近邻搜索的方法[11-14].
1.1 投影阶段
Hash学习的第1阶段为投影阶段,即将数据降维.大多数Hash算法采用的策略可以被分为2类:一类是独立于数据的Hashing,如局部敏感Hashing(Locality Sensitive Hashing)[15]、监督离散Hashing[16]和位移敏感Hashing(Shift Invariant Kernel Hashing)[17];另一类是数据依赖Hashing,顾名思义,即在投影阶段要依赖数据,如谱Hashing(spectral Hashing)[18]、迭代量化(iterative quantization)[19]和主成分分析Hashing(principle component analysis Hashing)[20].
面对海量的数据信息,想要直接从中挖掘出有价值的信息及规律非常困难.主成分分析法能够将数据进行降维,最大限度地降低数据信息的重复叠加.
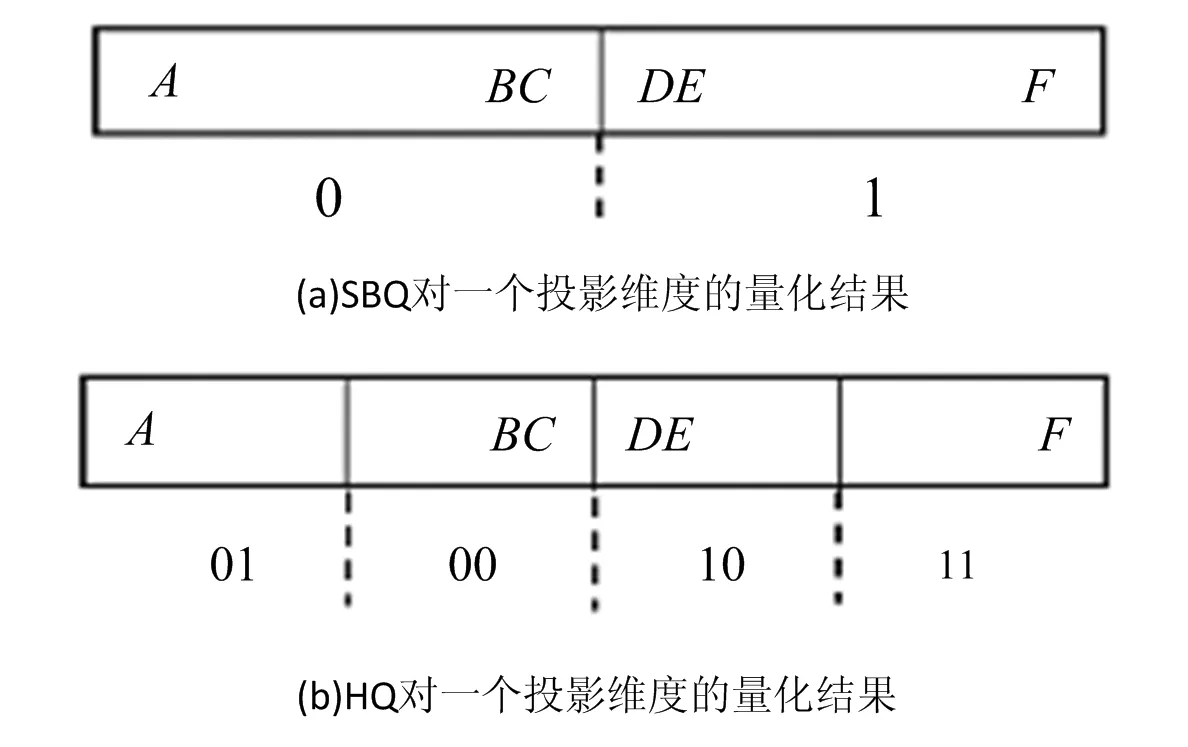
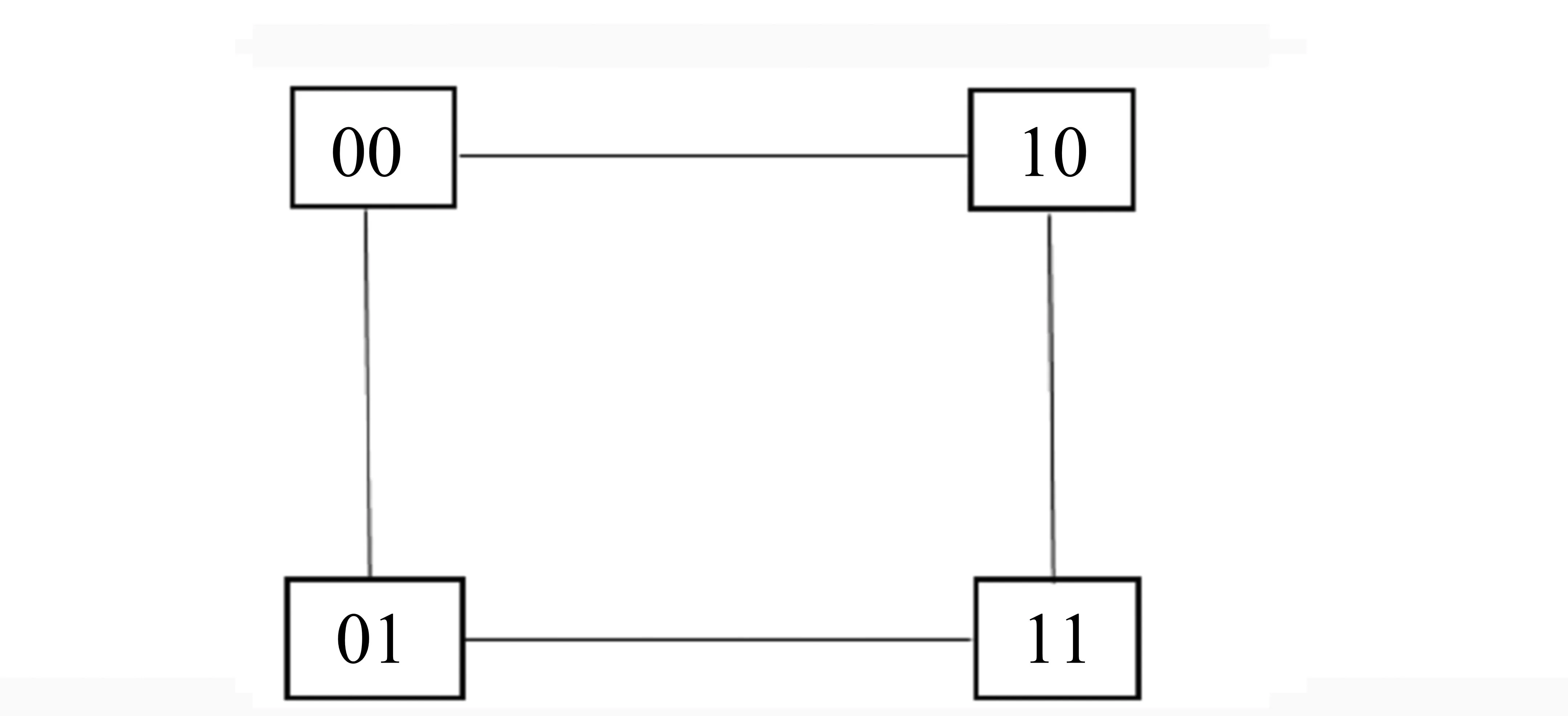
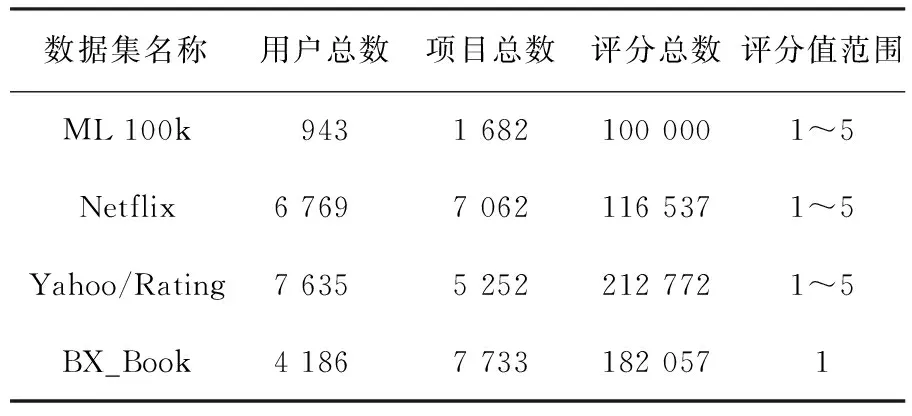
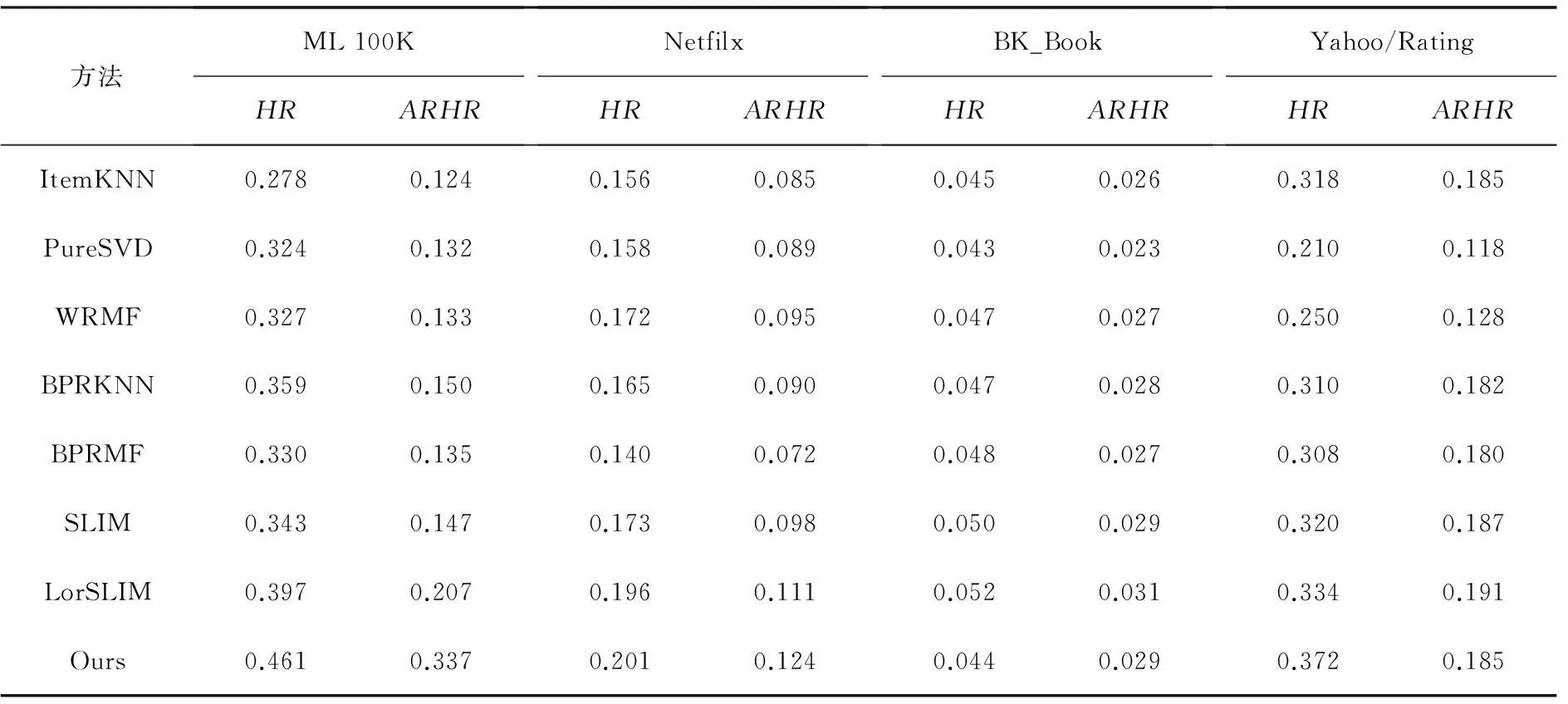
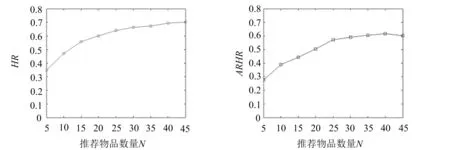
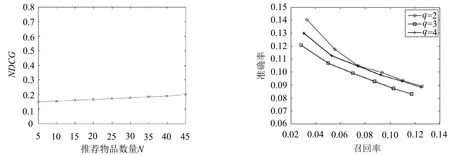
设样本集U={X1,X2,…,Xn},Xi={xi1,xi2,…,xim}(i=1,2,…,n),且m (1) 为了确保样本数据中任何维度的偏移都是以零作为基准点,需对样本数据进行中心化操作,即分别将矩阵每一列中的所有值减去其所在维度的平均值,得到矩阵D.衡量2个样本间的关系,计算样本的协方差矩阵C,即 (2) 通过式(2)计算协方差矩阵C的特征值λ={λ1,λ2,…,λn},将得到的特征值按照从大到小的顺序排列,并去除一些较小的值,得到λ={λ1,λ2,…,λm}.一个特征值对应一个维度,特征值越大表明该维度的数据越重要. det(λE-C)=0; (3) (λiE-C)Z=0,i=1,2,…,m. (4) 式(4)中,Z=(z1,z2,…,zn).将从式(3)解得的特征值λi逐个代入式(4),得到特征向量Σ={ξ1,ξ2,…,ξm}.特征矩阵S由特征向量组成,即 (5) 原始矩阵X通过S作线性变换 Y=SX, (6) 得到降维后的矩阵Y. 在使用汉明距的条件下,SBQ与HQ不能有效地保持原始数据点之间的邻域关系[14].图1(a)是SBQ对一个投影维度的量化结果,其中C和D分别被量化为0和1,但C和D在实值空间中却是相隔很近的;图1(b)表示HQ对一个投影维度的量化结果,若用dh(A,B)表示A,B之间的汉明距,则dh(A,F)=dh(C,D)=1,dh(A,D)=2.然而在实值空间中A,F之间的距离应该大于C,D及A,D之间的距离.为了弥补这些缺陷,一些新的量化方式被逐渐提出,如双比特量化(Double bit quantization 简写为 DBQ)[21]、多比特量化(Mulit-bit quantization)、自适应量化(Adaptive quantization)[22]和可变比特量化(Variable-bit quantization)[23]等. 图1 SBQ与HQ对一个维度的量化示意图 本文使用q比特量化(q>1),将每个投影维度分成2q个区域,并用q个比特位的自然二进制码去编码每个区域的索引[14].比如,q=2,每个维度分别被分成4个区域,这4个区域的索引{0,1,2,3}的自然二进制码为{00,01,10,11};同理,若q=3,则区域的索引为{0,1,2,3,4,5,6,7},其自然二进制码为{000,001,010,011,100,101,110,111}.量化阶段中另一个重要的因素是阈值.k-means聚类算法是一种有效的学习阈值的方法[24].因此,本文使用k-means聚类算法将每个投影维度的实数值聚类成2q类. 通过Hash学习的2个步骤,将用户-项目矩阵降维、量化为由二进制码表示的矩阵,再选择一个有效的距离来度量相似性,从而进行高质量的推荐.将Hash技术与推荐技术结合起来,能提高推荐的效率. 本文使用k-means算法将每一个投影维度的实值聚类为2q类,并用聚类的质心作为量化的阈值.k-means算法是一种经典的基于距离的聚类算法,即2个对象的距离越近,说明它们越相似. 对于给定的数据Ψ=(ψ(1),ψ(2),…,ψ(m)),计算每个样本点的归属类,具体步骤如下: 第1步,随机选取k(k=2q)个样本点作为聚类质心μ1,μ2,…,μk∈Rm; 第2步,计算每一个样例i(i=1,2,…,m)的归属类c(i)(c(i)=1,2,…,k),即 (7) 当c(i)=j时,x(i)被归为第j类,该聚类的质心为μj; 第3步,重新计算聚类质心的值 (8) 使用新的中心值替代原质心值,重复第2,3步,直到μj值趋于稳定,并确定质心值. 大多数Hash方法采用汉明距测量Hash码空间中点与点之间的相似性,然而汉明距自身存在着一些缺陷,使得整个Hash过程会毁坏原始空间中的邻域结构.例如,图2(b)用汉明距度量2比特二进制码之间的距离,其最大汉明距为2,但却不能有效地诠释4个不同点之间的关系,这有违Hash的原则.因此,想要得到如图2(a)所示的度量效果,就需要用另一种距离dr来代替汉明距. (a)用dr度量2比特二进制码之间距离示意图 (b)用汉明距度量2比特二进制码之间距离示意图 设β=(β1,β2,…,βm)T,δ=(δ1,δ2,…,δm)T,距离dMa为 (9) 称dMa为Manhattan距离[12]. (10) 如果将每一个投影维度量化成q比特的二进制码,那么每一个表示长度为L的二进制码串被分为L/q段,再进行距离计算.例如, dr(10,00)=dMa(2,0)=2; (11) dr(000100,110000)= dMa(0,3)+dMa(1,0)+dMa(0,0)= 3+1+0=4. (12) 根据上一节确定的Manhattan距离衡量用户之间的相似度.对于有些项目而言,将目标用户评论过的项目再次推荐给该用户是没有意义的,如用户购买过的书、观看过的电影等.所以本文在推荐阶段采用排除用户已评论过项目的方式避免重复推荐.但是,并不是所有用户没有评论过的项目都会被同等对待,实际操作中需要根据某些潜在条件对这些项目作出相应的调整.因此,本文根据目标用户与相似用户之间的不同相似性对不同的推荐项目使用不同的权重,以区分来自各个相似用户的推荐项.权重的计算方式如下: (13) 式(13)中:Wij表示用户ui与用户uj之间的权重;sim(ui,uj)表示用户ui与用户uj之间的相似度. 设Iiv为用户ui的对项目Iv评过分的相似用户的集合,用户ui对项目Iv的预测评分为 (14) 式(14)中:|Iiv|为用户ui的对项目Iv评过分的相似用户的总数;rjv表示用户uj对项目Iv的评分值;j=1,2,…,m;|I|是物品的总数. 相似度计算与推荐的过程如下: 相似度: 输入:用户-项目评分矩阵,用户的二进制码矩阵Data,相似用户数量Γ,推荐项目数量N,项目总数M. 输出:相似用户矩阵sim_user. [t1,U_in]=sort(Data,"descend"); form=1,2,…,Mdo forτ=1,2,…,Γdo W(m,k)=t1(k)/sum(d(1:Γ)); %用户的前τ个相似用户 sim_users(τ)=U_in(1:τ); %每一个用户的M×Γ阶相似用户矩阵 推荐: 输入:用户-项目评分矩阵,相似用户矩阵sim_user,推荐项目数量N,项目总数M,每一个用户的相似用户评论过的项目的矩阵RA. 输出:推荐项目矩阵Re. fori=1,2,…,Mdo rated=find(Rating(i,:)); %无重复 RT(i) =RA(i)-rated; %推荐项对应的评分 rt(i)=[Rating(i,RT(i))]; forj= 1,2,…,Ndo Rr(i,j)=W(i,j)rt(i,j); %W(i,j)是权重 %按Rr降序排列,选取前N项 T1=sort(Rr(i,1:τ),"decent"); Re(i,:)=T1(i,1:N). 使用表1所示的4个数据集评价本文的方法.ML 100K是MovieLens 数据集的子集,是对电影评分的集合,分值为1~5.Netifix是Netifix大赛提供的数据集的子集,其中每一个用户至少对10部视频评过分,分值为1~5.Yahoo/Rating是Yahoo!Movies数据集中的用户评分子集,在此数据集中,每一个用户至少对5部电影评过分,每一部电影至少被3个用户评过分,评分范围为1~5.BX_Book提取了Book-Crossing数据集的隐性反馈,是对于书籍的数据集,其中每一本书至少被10个用户阅读过. 表1 数据集 对于显性反馈,当评分值小于某个阈值时代表用户不太喜欢这项目,所以在预测评分前,可以将该种项目的值都设为0,以减少预测时的计算量.例如,在评分值为1~5的评分系统中,认为当用户给一个项目的评分值小于3时,表示该用户不喜欢这个项目,该项目的评分值可以被设为0. 采用交叉验证的方法证明本文方法的有效性,将每一个数据集随机分为训练集与测试集.训练集用来训练模型,然后为每一个用户形成一个大小为N的推荐列表.对每一个用户的推荐列表和测试集中该用户的交互项进行比较,并用这种方法评价模型[25].本文用命中率(hit-rate,下文使用HR表示)及平均命中等级的倒数(average reciprocal hit-rank,下文用ARHR表示)度量推荐的质量.“命中”表示某个用户测试集中交互过的项目(即经过用户评分、评论或点击、浏览等操作的项目)同样出现在该用户的推荐列表中. HR定义为 (15) 式(15)中:g表示测试集中某用户项目也在其推荐列表中的这类用户数量;G表示测试集中的用户总数.若HR的值为1.0,则表示这个算法可以非常有效地推荐潜在项目;若HR的值为0,则表示这个算法不能推荐任何潜在项目. HR将Top-N推荐列表中的每一项都看作具有相同的地位,但是,在列表中排在前面的项应该比排在后面的项拥有更高的权重.ARHR通过为每一个命中的项目设置权重来弥补HR的不足.在Top-N推荐列表中,越靠后的命中项目,其权重值越低.ARHR定义如下: (16) 式(16)中,pi表示第i个用户的命中项在其Top-N列表中的位置.当命中的项出现在推荐列表最前面位置时,ARHR的值达到最大;相反,当命中项出现在推荐列表的最后位置时,ARHR的值最小. 本文采用ItemKNN,PureSVD,WRMF,BPRKNN,BPRMF,SLIM,LorSLIM这7种推荐方法与本文的方法作对比,实验结果如表2所示,其中推荐列表项目个数N=10. 表2 实验结果 通过比较可以看出,本文方法在显性数据集上的推荐效果更胜一筹. PureSVD[5]通过用户-项目矩阵的主奇异值向量来描述用户和项目的特征;WRMF[26]采用加权矩阵来区分显性数据与隐性数据;BPRKNN[27]是融合了贝叶斯最大后验估计、k最近邻协同过滤与矩阵分解的新方法;SLIM[28]是一种Top-N推荐方法,从用户-项目矩阵中,将每一个项目编码为其他项目的线性组合,通过求解L1范数和L2范数的优化问题,进而得到一个表征相似度的稀疏矩阵.SLIM只能捕获到被相同用户购买或评论过的项目之间的关系,而通常一个用户能够评论的项目只是总项目的很小一部分;LorSLIM则是对SLIM的改进[20]. 相似用户的个数Γ与推荐项目个数N的取值对推荐效果也有影响.图3为N=Γ时HR与ARHR的变化趋势;图4为Γ=40时HR和ARHR的变化趋势;图5为Γ=40时NDCG的变化趋势. 图3 N=Γ时,HR与ARHR的变化趋势 NDCG(Normalized Discounted Cumulative Gain)通过推荐列表排序质量衡量推荐系统的性能,定义为 (17) (18) 式(17)中,r(i)是用户对第i个项目的评分值;式(18)中,IDCGN是DCGN的最理想值. q的取值关系到每一个投影维度的聚类及其被量化的长度,将q分别取值为2,3,4进行试验比较,结果如图6所示.从图6不难看出,当q=2时,效果更好. 图4 Γ=40时,HR与ARHR的变化趋势 图5 Γ=40时,NDCG的变化趋势 图6 q=2,3,4时召回率-准确率曲线图 本文针对目前电子商务面临的数据过大、信息稀疏等问题,提出了将Hash与协同过滤相结合的推荐模型.先对原始数据进行PCA降维处理,剔除一些冗余信息,降低运算强度;再对降维后的数据进行二进制码量化,减少数据储存空间.采用dr距离作为度量目标用户与邻居用户相似性的手段,直观且有效.从实验结果可以看出,这个方法提高了推荐质量. [1]Deshpande M,Karypis G.Item-based top-Nrecommendation algorithms[J].ACM Trans Inf Syst,2004,22(1):143-177. [2]吴海峰,张书奎,林政宽,等.融合隐语义和邻域算法的兴趣点推荐模型[J].计算机应用研究,2017,21(16):1-8. [3]居斌,钱沄涛,叶敏超.基于结构投影非负矩阵分解的协同过滤算法[J].浙江大学学报:工学版,2015,49(6):1319-1325. [4]Li H.Learning to rank for information retrieval and natural language processing[J].Synth Lect Hum Lang Technol,2009,4(1):113-119. [5]Arora G,Kumar A,Devre G S,et al.Movie recommendation system based on users′ similarity[J].Int J Comp Sci Mob Comp,2014,3(4):765-770. [6]Patra B K,Launonen R,Ollikainen V,et al.A new similarity measure using Bhattacharyya coefficient for collaborative filtering in sparse data[J].Knowl-Based Syst,2015,82(2):163-177. [7]Ricci F,Rokach L,Shapira B.Introduction to recommender systems handbook[J].Rec Syst Handb,2010,35(3):1-35. [8]Cremonesi P,Koren Y,Turrin R.Performance of recommender algorithms on top-Nrecommendation tasks[C]//Recommender Systems Recsys 2010.Barcelona:Association for Computing Machinery,2010:39-46. [9]Shi Y,Karatzoglou A,Baltrunas L,et al.TFMAP:optimizing MAP for top-Ncontext-aware recommendation[C]//Special Interest Group on Information Retrieval.Portland:Association for Computing Machinery,2012:155-164. [10]李武军,周志华.大数据哈希学习:现状与趋势[J].科学通报,2015,60(5):485-490. [11]Kong Weihao,Li Wujun.Double-bit quantization for hashing[C]//The Twenty-Sixth Artificial Intelligence.Toronto:Association for the Advance of Artificial Intelligence,2012:385-407. [12]Gong Y,Lazebnik S,Gordo A,et al.Iterative quantization:A procrustean approach to learning binary codes for large-scale image retrieval[J].IEEE Trans Pattern Anal Mach Intell,2013,35(12):2916-2929. [13]Wang J,Liu W,Kumar S,et al.Learning to Hash for Indexing big data:A survey[J].Proc IEEE,2015,104(1):34-57. [14]Kong W,Li W J,Guo M.Manhattan Hashing for large-scale image retrieval[C]//The 35th International Conference on Research and Development in Information Retrieval.Portland:Association for Computing Machinery,2012:45-54. [15]Andoni A,Indyk P.Near-optimal Hashing algorithms for approximate nearest neighbor in high dimensions[J].Found Comp Sci Ann Sym,2006,51(1):459-468. [16]Shen F,Shen C,Liu W,et al.Supervised discrete Hashing[J].Comp Sci,2015,62(2):37-45. [17]Chua T S,Tang J,Hong R,et al.NUS-WIDE:A real-world web image database from National University of Singapore[C]//International Conference on Image and Video Retrieval.Santorini Island:Association for Computing Machinery,2009:1-9. [18]Weiss Y,Torralba A,Fergus R.Spectral Hashing[C]//Conference on Neural Information Processing Systems.Vancouver:Neural Information Processing Systems,2008:1753-1760. [19]Gong Y,Lazebnik S.Iterative quantization:A procrustean approach to learning binary codes[C]//Conference on Computer Vision and Pattern Recognition.Colorado:Computer Society,2011:817-824. [20]Cheng Y,Yin L,Yu Y.LorSLIM:Low rank sparse linear methods for top-Nrecommendations[C]//International Conference on Data Mining.Atlantic City:Computer Society,2015:90-99. [21]Kong Weihao,Li Wujun.Double-bit quantization for Hashing[C]//The Twenty-Sixth Conference on Association for the Advance of Artificial Intelligence.Toronto:Association for the Advance of Artificial Intelligence,2012:346-355. [22]Xiong C,Chen W,Chen G,et al.Adaptive quantization for Hashing:An information-based approach to learning binary codes[C]//The 14th Society for Industrial and Applied Mathematics International Conference on Data Mining.Bethlehem:American Statistical Association,2014:1-9. [23]Moran S,Lavrenko V,Osborne M.Variable bit quantisation for LSH[C]//Meeting of the Association for Computational Linguistics.Sophia:Association for Computational Linguistics,2013:753-758. [24]He K,Wen F,Sun J.k-means Hashing:An affinity-preserving quantization method for learning binary compact codes[J].Proc IEEE,2013,9(4):2938-2945. [25]Kang Z,Peng C,Cheng Q.Top-Nrecommender system via matrix completion[C]//Association for the Advancement of Artificial Intelligence.Tucson:Association for Computational Linguistics,2016:38-49. [26]Pan R,Zhou Y,Cao B,et al.One-class collaborative filtering[J].Data Mining,2008,29(5):502-511. [27]Rendle S,Freudenthaler C,Gantner Z,et al.BPR:Bayesian personalized ranking from implicit feedback[C]//Conference on Uncertainty in Artificial Intelligence.Montreal:Association for Uncertainty in Artificial Intelligence,2009:452-461. [28]Ning X,Karypis G.SLIM:Sparse linear methods for top-Nrecommender systems[J].Data Mining,2011,11(3):497-506.1.2 量化阶段
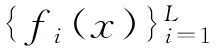
2 算法框架
2.1 聚类量化
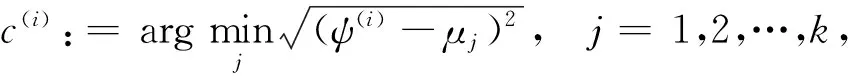
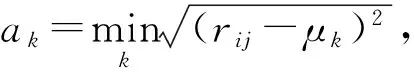
2.2 距离选择

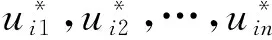
2.3 预测过程
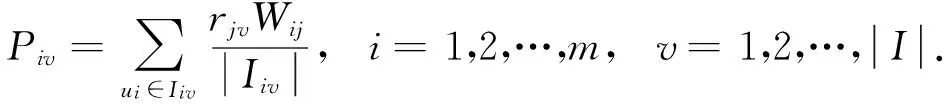
3 实 验
3.1 数据集
3.2 实验结果
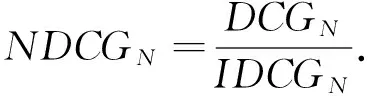
4 结 语
