利用logistic回归进行直接标准化*
2018-03-05北京大学公共卫生学院流行病与卫生统计学系100191李嘉琛余灿清李立明
北京大学公共卫生学院流行病与卫生统计学系(100191) 李嘉琛 余灿清 吕 筠 李立明
在流行病学研究中常常要进行不同组间率的比较,如果各比较组之间的重要协变量(如性别、年龄)分布不同,那么直接计算粗率并比较会受到混杂的影响。直接标准化是控制混杂最为常用的方法之一,该方法计算简便、容易理解,得到了广泛的应用。但当需要调整的因素分层较多时,会出现有些层人数过少的情况,此时难以精确估计层别率。此外,对于年龄这类连续型协变量,必须转化为分类变量才能用于标化,可能带来残余混杂。多重回归分析可以同时控制多个混杂因素,利用模型的预测功能计算调整均数或率的思想很早就已出现,由最初的一般线性模型推广到广义线性模型[1]。然而这些方法在实际研究中的应用还不是很多,一个可能的原因是其计算过程并不直观,结果不易解释。基于模型的直接标准化可将回归分析与加权平均的思想相结合,可以发挥两者的优势。利用logistic回归计算直接标准化率主要有两种不同的计算方法,目前应用还不是很广泛,本文将对其进行介绍,探讨其特点和性质,比较不同方法的优势与不足,为研究者选择分析方法提供参考。
计算方法
基于回归进行标准化的基本思想是利用回归模型的预测来代替直接标准化法中层别率的估计,再以标准人口的构成作为权重进行加权平均。其前提假设是回归模型可以正确反映因变量与自变量间的关系。使用y表示二分类的结局变量,x为用于比较的分组变量,z表示混杂,则回归模型可以表示为:logitπ=f(x,z),f(x,z)代表自变量的线性函数。在logistic模型中,概率经过了非线性连接函数的转换,在加权平均计算时有两种不同的方法,分别是对层别预测率进行加权平均和对层别预测logit进行加权平均。
1.对预测率进行加权平均
在各比较组按混杂因素分层后,利用回归方程计算各层的预测结局概率,再以标准人口构成为权重进行加权平均:P=∑wiPi,其中wi代表第i层的权重,Pi代表第i层的预测结局概率。上述过程适用于所有要调整的变量均为分类变量的情形。有时协变量中包含连续变量,而我们又不希望将其转化分类变量损失信息,此时可以计算边际预测率[2]。“边际”的含义是在用回归方程计算预测概率时,除要比较的分组变量以外,所有协变量的取值并不固定,而是使用标准人群的观察值。某一组(x=k)的边际预测率计算过程如下:首先要给定一个标准人群数据集,该数据集要包含每一个体的所有协变量取值。将所有人的x取值固定为k,其他协变量取值保持不变,计算每一个体的预测结局概率,求出预测率的算数平均数即为该组的标化率:
(1)
其中n为标准人群的人数,zj为第j人的协变量取值。由计算过程可以看出,边际预测率在个体层面上预测结局概率,再以相等的权重1/n进行加权平均,因此其含义与直接标准化一致,可以解释为在标准人群的协变量分布下的结局事件概率。
2.对预测logit进行加权平均
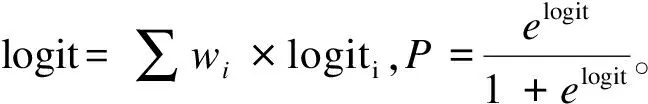
(2)
其中n为标准人群的人数,zj为第j人的协变量取值。
3.标化率的标准误和置信区间
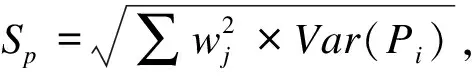
在不同的方法中,标准化率置信区间的估计方法也有所不同。直接标化法和对预测概率加权平均法计算的置信区间为标化率点估计值加减标准误倍数的形式(Wald置信区间)。然而对概率而言,这种以点估计值为中心的对称的置信区间往往是不合理的[5]。对logit加权平均的方法则是计算标化logit的Wald置信区间,再转换为概率的区间。由于logit比概率P更有可能服从正态分布,因此有研究者认为这种方法在统计学上更为合适[3]。
4.软件实现
当调整的变量均为分类变量时,可以直接利用统计软件输出模型的回归系数估计值以及协方差矩阵来计算标准化率和置信区间。当存在连续协变量时,需要计算边际预测率,Stata 11增加了“margins”命令可以便捷地实现这一计算[5]。SAS本身没有对应的过程,不过有研究者编写了宏,可用于计算边际预测率,并且提供了多种置信区间的估计方法[5]。
基于回归的标化率与其他调整率
利用回归模型可以计算控制混杂后的因变量预测值,这一过程也被称为“调整”或“校正”。基于模型的调整预测值分为两类,一类是固定分组变量和协变量取值,计算条件均数或概率,称为条件预测值(conditional prediction),协变量通常是取样本或某个人群的平均数;另一类是固定分组变量取值,保持协变量的实际观察值,计算个体的平均调整预测值,称为边际预测值(marginal prediction)[2,6-8]。在线性回归模型中,两者的结果一致,而在非线性模型中结果不同,一些研究对两类方法进行了比较[2,6-7,9]。调整与直接标准化的概念存在区别和联系,有时会令人困惑。
两种标准化的计算方法虽是基于同样的回归模型,却会得出不相等的结果。对预测概率进行加权平均(边际预测率)是被许多研究者所接受的计算方法。对层别logit加权平均的方法自提出后也已被一些研究所采用[10-11],但还没有研究者将其与边际预测率、直接标化率进行比较。下面通过实例分析来说明两种方法的计算过程,并展示出两种方法标化结果的差异。
分析实例
利用中国慢性病前瞻性研究(China Kadoorie Biobank)基线调查数据[12]分析教育程度与吸烟的关系。以教育程度为自变量,分为大学及以上、大学以下两组;吸烟为二分类结局变量,分为当前每日吸烟与其他两组。直接计算两组的粗吸烟率,大学及以上者为21.0%,大学以下者为26.6%。在分析中发现,不同教育程度人群的性别构成不同,而性别与吸烟行为关联较强。为了控制性别因素的影响,按性别分层计算吸烟率,结果见表1。为进行综合比较,合并全部样本作为标准人群,进行直接标准化。首先采用传统的计算方法,直接估计两组的层别吸烟率,经加权平均计算后得出标化率。

表1 不同教育程度人群分性别吸烟率
建立吸烟率与教育和性别的回归方程:logitP=1.1481×edu+4.1992×gender-4.8574,其中edu代表学历水平,取值为0和1,以大学及以上组(edu=0)为参照;gender为性别,取值为0和1,以女性为参照(gender=0)。分别用两种基于logistic回归的方法计算标化率,各层权重以及层别率和层别logit的预测值见表2。
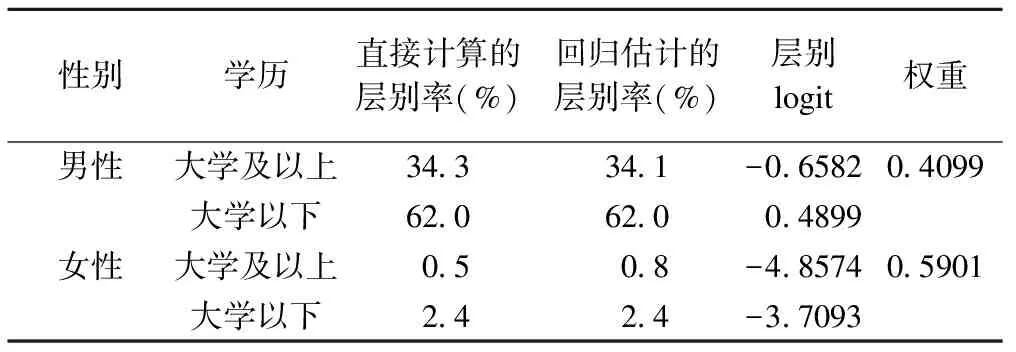
表2 按性别分层的权重以及层别率、层别logit
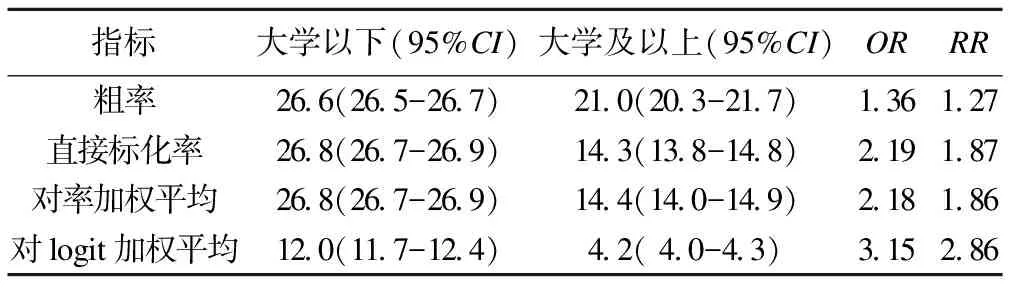
表3 不同方法计算标化吸烟率的比较(%)
表3显示了几种直接标准化法的结果比较,并利用两组的标化率计算了关联强度指标OR值和RR值。从两组粗率的比较可以看出,大学及以上学历的人吸烟率低于大学以下的人。由于低学历者中女性比例较高,而女性吸烟率远低于男性,从理论上讲性别的混杂会使关联强度被低估。采用任何一种方法进行标准化后,RR值和OR值均增大,说明这三种方法都对混杂偏倚起到了一定的控制作用。在本例中吸烟并不是一个罕见事件,因此OR值并不能很好地近似RR值[13]。直接标化法与对率加权平均方法的结果基本相同,这是由于直接计算的层别率与使用logistic模型计算的层别率高度一致(表2),表明在本例中模型对数据的拟合是比较好的。
由于样本中大学以下人数比例较大(97.7%),合并后标准人群的性别构成十分接近大学以下人群,所以大学以下组的标化率理应与粗率相差不大,直接标准化和对预测率加权平均方法得到的结果都是如此。而对logit加权平均法得到的大学以下组的调整吸烟率为12.0%,这显然不是标准人口构成下的大学以下人群吸烟率,出现这种现象的根源就是ln(P/1-P)和P的非线性关系。在这里,12.0%和4.2%只能理解为对直接标化率的有偏差的估计值,并没有现实意义。如果错误地将其理解为直接标化率,那么当前每日吸烟者的比例将被严重低估。理论分析表明,当协变量与结局关联较强时,对logit加权平均法得到的调整率与直接标化率相差较大,在本例中,混杂因素性别与吸烟率关联极强(OR=67),因此两种基于回归的标准化方法结果有明显的差别。
讨 论
通过比较,可以总结两种基于logistic回归的标准化方法的特点:边际预测率与传统的直接标准化法一致,结果容易理解,得到的置信区间以率的点估计值为中心;对logit进行加权平均的方法可以得到非对称的置信区间,利用其调整率计算出的OR值等于模型估计的OR值。其不足之处在于其结果并不等于直接标化率,当混杂因素与结局关联较强时,用这种方法估计直接标准化率会产生较大偏差。
基于多重回归的标准化在调整连续变量、控制多个混杂因素时具有优势,传统的直接标准化对分层因素各水平的所有组合分别估计结局概率,相当于考虑所有可能的交互作用,而回归模型可以帮助我们忽略其中一些没有意义的交互作用,得到比较精确的层别率估计值。以往有人认为边际预测率只能以合并样本为标准人群,也就是只能进行样本内部调整[6],然而实际上并非如此,利用回归进行标准化可以使用外部的标准人群,从而实现不同研究之间的比较。
使用回归模型进行标准化同样要注意一些问题。首先,与传统的直接标准化法相同,当各比较组的层别率间比较出现明显差异甚至交叉时,不宜计算一个综合的标化率,此时权重的选择会成为影响最终各组标化率比较的主要因素,是否适宜进行标准化可以通过检验模型中的交互项来判断[14]。对于结果的理解要正确,标化率不再反映实际水平,是假定在特定协变量分布人群中的预测概率。与直接标准化不同的是,利用模型进行标准化的前提假设是回归模型可以正确估计层别率,因此能够较好拟合数据的回归方程是必要的。
本文介绍了两种基于logistic回归的标准化方法,在一般情况下,两者都可以用于估计直接标准化率。但是当调整的因素与结局关联很强时,对logit进行加权平均的方法会造成误导,计算边际预测率是更好的选择。由于基于回归的调整率计算方法较多,研究者应具体说明所使用的方法以及选择的标准人群,使读者能正确理解研究结果。
[1] Lee J.Covariance adjustment of rates based on the multiple logistic regression model.J Chronic Dis,1981,34(8):415-426.
[2] Lane PW,Nelder JA.Analysis of covariance and standardization as instances of prediction.Biometrics,1982,38(3):613-621.
[3] Roalfe AK,Holder RL,Wilson S.Standardisation of rates using logistic regression:a comparison with the direct method.BMC Health Serv Res,2008,8(1):275.
[4] Flanders WD,Rhodes PH.Large sample confidence intervals for regression standardized risks,risk ratios,and risk differences.J Chronic Dis,1987,40(7):697-704.
[5] Zou GY.Assessment of risks by predicting counterfactuals.Stat Med,2009,28(30):3761-3781.
[6] Wilcosky TC,Chambless LE.A comparison of direct adjustment and regression adjustment of epidemiologic measures.J Chronic Dis,1985,38(10):849-856.
[7] Muller CJ,MacLehose RF.Estimating predicted probabilities from logistic regression:different methods correspond to different target populations.Int J Epidemiol,2014,43(3):962-970.
[8] Graubard BI,Korn EL.Predictive margins with survey data.Biometrics,1999,55(2):652-659.
[9] Chang IM,Gelman R,Pagano M.Corrected group prognostic curves and summary statistics.J Chronic Dis,1982,35(8):669-674.
[10]Ursano RJ,Kessler RC,Stein MB,et al.Suicide Attempts in the US Army During the Wars in Afghanistan and Iraq,2004 to 2009.JAMA Psychiatry,2015,72(9):153-159.
[11]Gilman SE,Bromet EJ,Cox KL,et al.Sociodemographic and career history predictors of suicide mortality in the United States Army 2004-2009.Psychol Med,2014,44(12):2579-2592.
[12]李立明,吕筠,郭彧,等.中国慢性病前瞻性研究:研究方法和调查对象的基线特征.中华流行病学杂志,2012,33(3):249-255.
[13]李鹏声,梁融,周舒冬,等.应用logistic回归模型间接估计RR/PR的方法探讨.中国卫生统计,2014,31(6):949-951.
[14]Freeman DH Jr,Holford TR.Summary rates.Biometrics,1980,36(2):195-205.
